Меня зовут Руслан Жданов, я занимаюсь релиз-инженерией с 2018 года.
В последнее время меня зацепило новое интересное направление – Kubernetes. И я решил поделиться своим интересом со всеми.
Тема Kubernetes довольно сложная, в связи с тем, что этот продукт для 1С мало применим. так как в основном, он используется для работы различных микросервисов. А 1С назвать микро сервисом, что то язык не поворачивается. Т.е. где-то есть, но зачем он нужен – непонятно.
И я попытаюсь рассказать о Kubernetes немного упрощенным способом. Для этой цели мы вспомним старенькую детскую игру, которая называется «Воображариум».
Будем фантазировать по поводу 1С в Kubernetes, а потом посмотрим, что получилось из того, что мы напридумывали.
Зачем нам Kubernetes для 1С?

Меня многие спрашивают: «Зачем это нужно? Куда это применить? Какой профит от бизнеса будет по поводу использования Kubernetes?»
Специально для ответов на такие вопросы я сделал слайд, показывающий, что мы из этого получим. Опять же, вспоминаем, что мы пока еще просто фантазируем о том, что у нас происходит.
- Первое, что хотелось бы сказать по использованию контейнеризированных приложений и вообще систем оркестрации – это возможность масштабирования приложений. Представьте себе ситуацию, когда у вас есть кластер 1С из одного сервера. И у вас в какой-то момент начинает возрастать нагрузка – бухгалтера начинают отчеты формировать, либо закрытие месяца у вас идет. И за счет возросшей нагрузки ваша инфраструктура способна сама увеличивать ресурсы – добавлять в кластер сервера. Допустим, вам нужно пять серверов. Он арендовал мощности у облачного провайдера, дал вам сервера. Вы за то время, которое вам нужно, заплатили, а потом эти ресурсы отдали обратно облачному провайдеру. Ночью у вас нет нагрузки, вам для вашей базы достаточно, допустим, одного сервера с четырьмя ядрами и 12-ю гигабайтами оперативы для выполнения фоновых заданий. А днем при каких-то объемах работы вам этого не хватает. Это даст вам масштабируемость(auto scaling).
- Далее – отказоустойчивость. Здесь даже можно объединить эти пункты в один. Когда вы разворачиваете сервера, вы задумываетесь о том, что мне делать, если сервер упал, жесткий диск отказал или еще что-нибудь? Было бы классно, если бы вы не заморачивались по этому поводу. Например, если у вас какой-то один сервер упал, в этот же момент поднялся и добавился в кластер точно такой же сервер. Да, возможно отвалятся клиентские соединения, но общий суммарный объем мощности вашего кластера в этот момент останется тем же.
- Также хорошо будет, если вы сможете использовать инфраструктуру как код –например, чтобы развернуть весь ваш кластер полностью одной командой. Причем разворачивать его в различных версиях самой 1С, использовать для тестирования и каких-то других мифических задач.
При использовании оркестрации придумывайте, что хотите – все это можно, все это классно и интересно.
Задачи, которые требуется реализовать

Конечная цель этого проекта – это:
- Запустить в Kubernetes полноценный кластер из определенного количества узлов – из одного или из пяти. Причем эти узлы сервера должны не просто запуститься, а собраться при запуске в единый кластер.
- Естественно, нам нужно будет решить проброс серверной лицензии. С клиентской лицензией все проще – у нас есть USB-ключи и менеджер лицензирования, который может передать лицензию по сети. С серверной лицензией немного сложнее – мы дальше рассмотрим, что с этим можно сделать.
- Прикрутить туда HiRAC со сбором метрик и выгрузкой их в Prometheus, и настроить scale notes на основе этих метрик – допустим, у нас появилась нагрузка, и мы начинаем увеличивать объемы наших серверов.
- Естественно, нам нужны будут рабочие лошадки – клиенты 1С для тестирования или еще чего-нибудь.
- И все это должно запускаться в одном файле.
Вот такая наша конечная цель.

Для этого нам нужно будет подготовить:
- Образы для 1С – их большое количество и требования к ним достаточно большие. Причем, большинство дистрибутивов 1С проприетарные, поэтому мы их можем использовать только в рамках своей компании, выкладывать готовые образы в публичный доступ мы не можем.
- Мы должны будем создать несколько манифестов для запуска самих объектов кластера внутри Kubernetes.
- Должны будем решить кучу сопутствующих задач – по лицензиям, по масштабированию и т. д.
- Задач, по факту, много. Чтобы все их решить, потребуется достаточно большое количество времени. Но опять же, возвращаясь к слайду с совой на глобусе, на текущий момент это – экспериментальное решение. И мы мечтаем.
Что такое Kubernetes?

Kubernetes – это сложная штука, ее проще всего представить как военно-морской флот.
- У ВМФ есть штаб группы войск – тот, который управляет войском.
- Есть различные военно-морские базы, на которых сидят генералы и управляют задачами, которые приходят на эту военно-морскую базу.
- И есть суда, которые ходят по морям – они выполняют свои задачи, заходят на эти базы и т.д.
Вот такая инфраструктура.
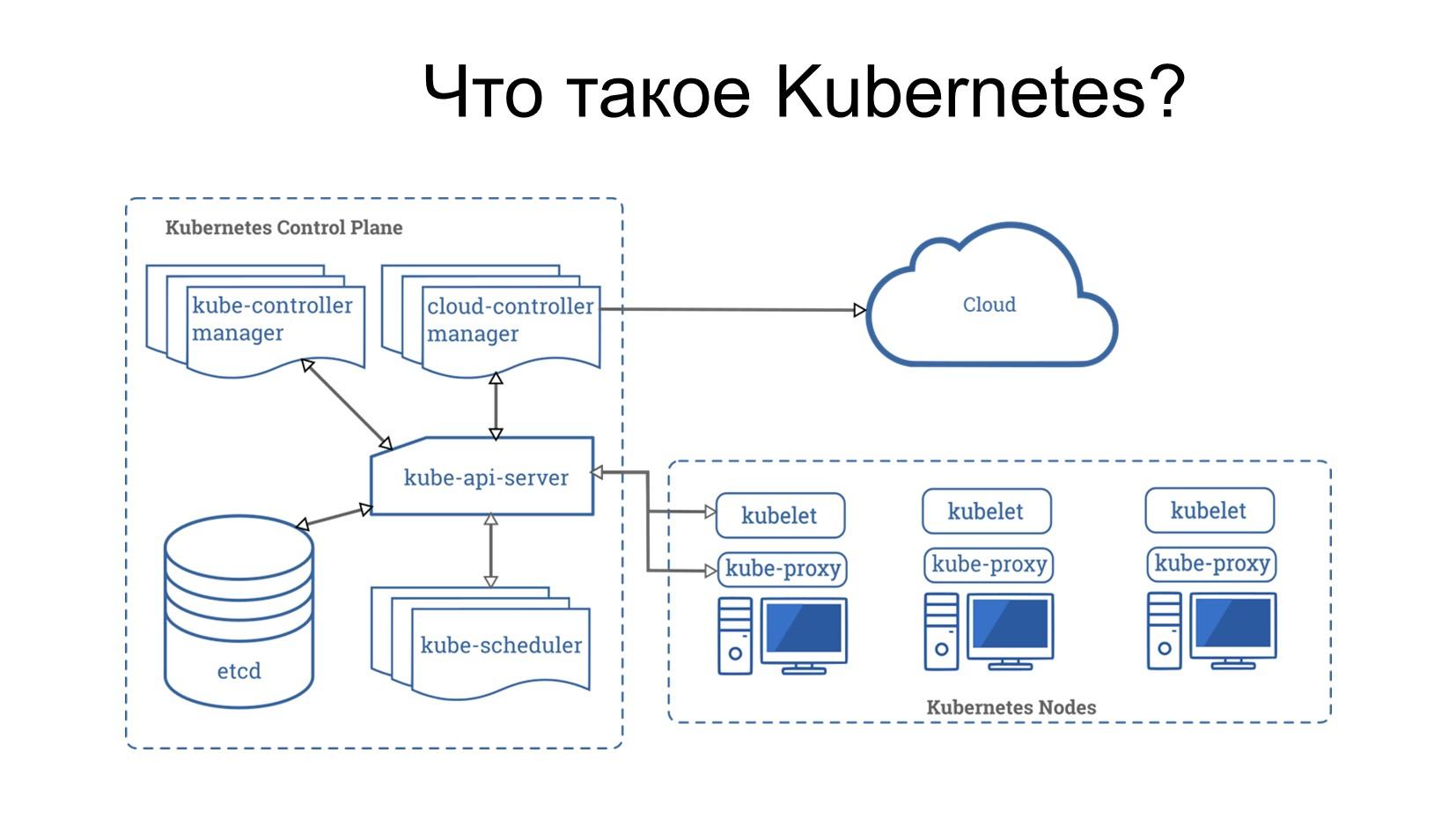
Что мы можем про нее сказать?
- Мастер-ноду Kubernetes, которая осуществляет управление всем кластером, можно представить как штаб войск. Такие штабы войск в армии полагается масштабировать – их должно быть несколько. Потому что если штаб один, и по нему неприятель ракетой ударит – все, войско обездвижено. Поэтому их децентрализуют, собирают в кластер и если вдруг что, они могут между собой делить задачи, координироваться – один ушел, второй пришел. У Kubernetes так же. Kubernetes Control Plane – это сам мастер. Он так же масштабируется – в продуктивных средах стандартно 3-5 мастеров.
- А те военно-морские базы, на которые приходят корабли, про которые я говорил, являются нодами.
- На этих нодах сидят кублеты (kubelet) – командиры, которые принимают задачи от группы штаба войск и своим подчиненным ставят задачи – возьми корабль, загрузи его и пусть он плывет туда-то. Либо сделай то-то. Это – так называемый исполнитель на рабочей ноде. Этих исполнителей может быть много.
Когда я говорил про масштабирование в Kubernetes, он поддерживает два вида масштабирования.
- Первый вид масштабирования – на уровне контейнеров (подов), про них я буду дальше рассказывать.
- И на уровне нод. Т.е. в случае, если нам не хватает ресурсов, мы можем заказать у облака заказывать дополнительные ноды (военно-морские базы), чтобы делать там свои задачи.
Таким образом в коротком приближении выглядит кластер Kubernetes.
POD
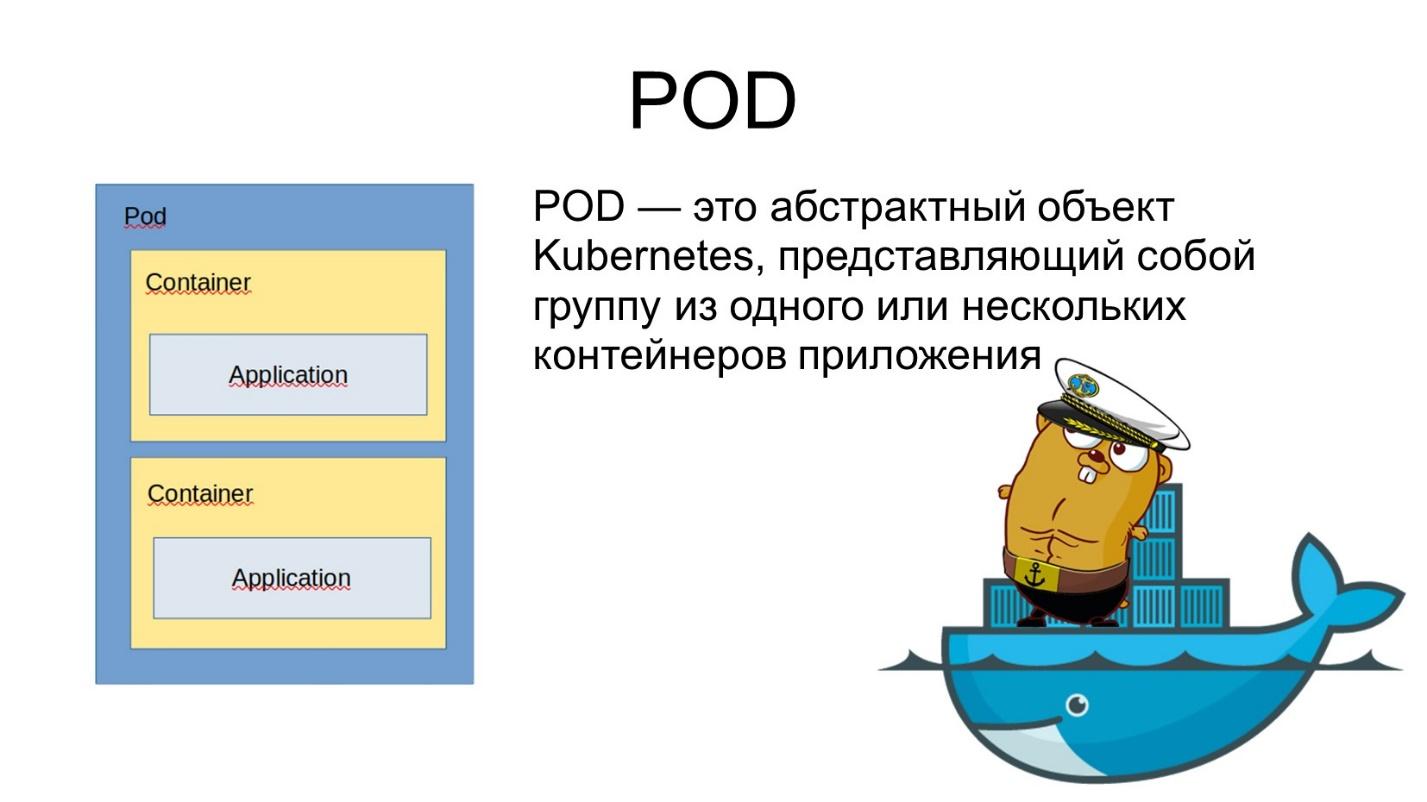
Что такое Pod? Это единичный абстрактный объект Kubernetes. Подом можно назвать какое-то судно. Наиболее приближенной аналогией является какая-нибудь баржа, на которую мы грузим контейнеры, и она плывет.
Pod – это, условно, неделимый объект в Kubernetes.
Если мы берем Docker, там неделимым объектом является контейнер. В Kubernetes неделимым объектом является Pod. А внутри пода может быть как один, так и несколько контейнеров.
Получается, что вы, когда разворачиваете кластер Kubernetes, у вас в нем крутится колоссальное количество подов. Они рождаются, живут, умирают, что-то с ними происходит. Так же, как и в военно-морском флоте, количество кораблей, находящихся в текущий момент в плавании, просто колоссальное количество.
Deployment и StatefulSet

Управление отдельным кораблем довольно сложное, но нам нужно управлять целыми армадами таких кораблей.
Чтобы дальше понимать, что мы собираемся делать с 1С, нужно разобрать несколько абстракций.
Первая абстракция, самая популярная, называется Deployment. С точки зрения военно-морского флота, это армада барж, на которых перевозят контейнеры. Правда, это ближе относится, наверное, к грузовым перевозкам, но пусть будет так.
Итак, у нас есть армада, в которой есть некоторое количество этих барж, и у каждой баржи есть какой-то случайный номер.
Причем, нам все равно, какой номер у этой баржи, и что она делает. Нам главное, знать, что их там плавает пять штук, на каждой по два моих контейнера.
Если эта баржа затонула, мы добавим туда новую с другим номером, но мой контейнер там также есть. Больше нас ничего не волнует.
Это – Deployment. Он характеризует объекты, которые работают по принципу «стада». Нам неважно, как его зовут, и кто он такой. Нам главное, чтобы он был. Если с этим объектом что-то случилось, сделаем новый, и все будет хорошо.

Другой объект называется StatefulSet. Это – армада больших военных кораблей.
Представьте, что есть военный корабль «Адмирал Кузнецов» – авианосец, флагман нашего военно-морского флота. Он – один-единственный авианосец в нашем военно-морском флоте.
Если с ним что-то случится, нам нужен точно такой же корабль, с таким же именем и с теми же параметрами.
То есть StatefulSet – это абстрактный объект Kubernetes для Stateful-приложений, в котором все объекты должны иметь четкое наименование. Это не только само судно (Pod, в частности), а именно класс объектов с таким именем – армада авианосцев, у которых есть определенные параметры. Причем при перезапуске этого пода он запустится с такими же параметрами.
Никогда не будет два одинаковых пода. Kubernetes гарантирует, что в армаде два одинаковых корабля не будет. Будут два разных корабля Адмирал Кузнецов-1 и Адмирал Кузнецов-2, но если второй упал, он поднимет такой же второй.
Сервер и клиент 1С в кластере k8s - как это работает?
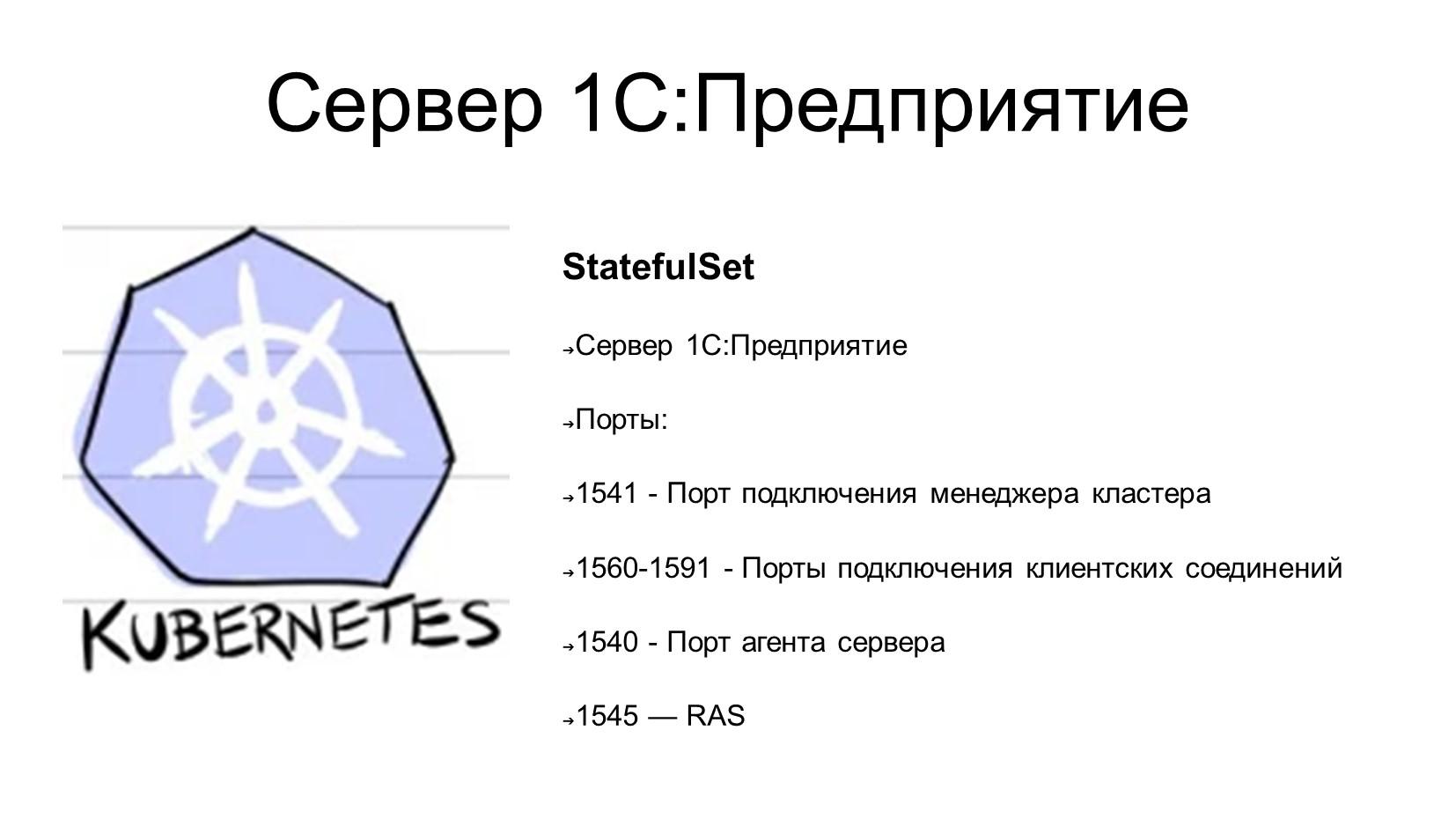
В нашем инстансе нам нужно будет запустить некоторые объекты.
Первым и самым важным для нас является сервер 1С:Предприятие. Это – stateful-приложение, наш «Адмирал Кузнецов», который должен для этого контейнера опубликовать определенный набор портов:
- это группа портов для подключения клиентских приложений;
- для агента сервера;
- для RAS и т.д.
Причем, нам нужно будет научиться запускать как один сервер, так и группу серверов – у нас есть задача, чтобы эти сервера собирались в кластер.

Следующим объектом, который нам нужно будет запустить, является сервер баз данных.
Предвижу вопрос: «Нам же нельзя запускать базу данных в контейнерах». Да, я согласен с утверждением, что базы данных не должны работать в docker и в Kubernetes, их лучше разворачивать в специальных сервисах, но для наших целей сейчас этого вполне достаточно. Потому что в текущей реализации, которую я буду показывать, я даже не храню при перезапуске базу данных – она мне нужна только для того, чтобы подтвердить мою гипотезу, что все работает.

Далее – сервер администрирования кластера RAS.
Мы уже начинаем собирать нашу флотилию, которая идет в бой. Это 1С-ная флотилия, и нам нужен для этого еще один корабль, который будет управлять нашей флотилией.
Для этого мы берем поднимаем сервер администрирования кластера RAS. Нам не важно его имя, нам главное, чтобы этот кораблик был и чем-то управлял.
А рядом с ним мы поднимаем еще один контейнер.
Т.е. в одном поде будут два контейнера.
- Один – с сервером администрирования RAS.
-
А во втором – будет API-инструмент для управления этим кластером.
-
Я использую в своей реализации ODIN – это решение от Алексея Хорева. Мне оно понравилось, потому что оно не требует использовать RAC, оно обращается непосредственно к RAS. И оно написано на Go, и Алексей обещал сделать упрощенную версию для работы в Kubernetes.
-
Также я планирую прикрутить туда в качестве альтернативы и HiRAC – для тех, кому не нравится ODIN. В принципе, HiRAC решает те же самые задачи, но, в связи с тем, что пока требуется наличие RAC, это немного увеличивает объем контейнера, и мне в текущий момент это было не совсем удобно.
-
К тому, что такое ODIN, и как он работает, мы потом еще вернемся.

Далее наши рабочие лошадки – маленькие кораблики, которые, собственно, и будут вести эту мини-войну – клиенты 1С:Предприятие. Они также разворачиваются в Deployment, потому что их там должно быть очень много, и они там периодически могут пристреливаться и появляться – с ними может происходить что угодно, нам несильно важно, что с ними происходит в текущий момент.
Управление объектами Kubernetes с помощью файла манифеста
Теперь подумаем о том, как это вообще все выглядит в Kubernetes.
Все объекты Kubernetes представляются в виде манифеста – в формате JSON или YAML.
Это – декларативный способ описания объектов. Он не сильно сложный, но он разномастный:
- Во-первых, объектов Kubernetes очень много.
- А во-вторых, у этих объектов большое API – каждый объект может иметь несколько реализаций, в зависимости от того, какую версию API мы используем. Есть API, которое сейчас является релизным. Есть то, которое находится в beta-версии, в alpha-версии. У них могут быть отличия. Поэтому чтение документации по написанию объектов Kubernetes – это основная задача.
Из этого возникает некоторая проблема – очень много копипаста. Но чтобы как-то упростить непосредственную работу с этими манифестами, использовать переменные в JSON нет возможности.

Для этих целей умные люди придумали такой инструмент, как Helm. Это пакетный менеджер для Kubernetes, который позволяет одной командой развернуть полностью какой-то объект.
Есть умные люди, которые написали для этого сервиса helm chart – условно, репозиторий. Написали какое-то приложение и сделали для него конфигурационные YAML-файлы.
Ты набираешь команду
install myApp
и все, он тебе разворачивает твое приложение на основе этих конфигов.
Очень простое решение – если у вас в наличии кластер Kubernetes, вы можете одной командой развернуть тот же GitLab, Jenkins, и все это будет работать сразу «из коробки».
Там довольно простой синтаксис, но к нему нужно подходить и читать.

Напомню, что Helm – это пакетный менеджер, который нам потребуется, чтобы развернуть наш кластер Kubernetes.
Для этого есть репозиторий Kubeonec – это helm chart, который я сейчас разрабатываю, чтобы мы могли развернуть полноценный кластер 1С в Kubernetes по тем идеям, которые мы сейчас только что обговорили.
Как мониторить сервер и решить вопрос с лицензиями?
Мечтать – это хорошо, но не все получается. И тут мы сталкиваемся с реальностью.
Первая проблема – это автоматическое масштабирование кластера. Поднять новый сервер и скриптом добавить его в кластер – это несложная задача, ее можно реализовать. Но дело в том, что сама 1С не всегда работает так, как от нее ожидаешь. И не всегда увеличение серверов в кластере увеличивает производительность самого кластера, поскольку там еще требуются дополнительные настройки в рамках назначения функциональности и другие специфичные настройки самого кластера. Для этого потребуется довольно большой объем работы. Плюс туда надо еще идти и копать. Поэтому серверы-то создать можно, но в кластер их пока не собрать.
Дальше – проброс серверной лицензии в кластер. Это – самая большая проблема, которая на текущий момент существует. Дело в том, что у 1С нет возможности получать пинкоды или лицензии через REST API. Было бы неплохо – поднял запрос по REST API, он тебе вернул лицензию. Но пока что такого нет. Я знаю два варианта для проброса USB-ключа через TCP, которые, возможно, будут работать:
- USB-redirector для Linux, который используют для проброса ЭЦП в кластер Kubernetes или на виртуальные машины.
- И второй вариант – Fabulatech USB Over Network. Есть подтверждение, что через него также можно пробросить HASP-ключи. Допустим, у тебя есть Raspberry PI и, если для нее существует драйвер для USB-ключа, на ней можно поднять VPN и закинуть ее в Kubernetes, чтобы Pod получил USB-ключ. Все должно работать.
Еще один вариант – использование программных лицензий. Как мы говорили, приложения в StatefulSet сохраняют свое состояние. Если этот StatefulSet запускается на одной и той же ноде, а это можно сделать настройками кластера, используя Node Affinity или еще какие-то инструменты, то мы, в принципе, можем эмулировать проброс лицензии. Поскольку лицензия для конфигурации хранится в контейнере Linux в виде файла, а мы этот файл пробрасываем в Volume, то есть вероятность того, что лицензия при перезапуске этого пода не отвалится. Эту гипотезу я еще не прорабатывал, но мне кажется, что так можно будет решить эту проблему с лицензированием. Может быть, к тому времени, пока я это решу, что-нибудь изменится и в 1С. Но пока (прим. ред. февраль 2021 года) подвижек со стороны 1С, к сожалению, нет.
И третий вопрос – это мониторинг сервера. Для него можно использовать HiRAC от Артема Кузнецова, который тоже нужно прикрутить, но я пока еще не до конца разобрался, как это сделать.
Сборка образа

В заключение презентации я хочу показать, как собираются образы.
Я собираю их с использованием объекта Kubernetes под названием JOB. Это тот же самый Pod, который запускается, выполняет работу и при успешном выполнении переходит в статус «Выполнен». На этом он заканчивает свою работу. Он не висит долгое время, а просто выполнился и закончился.
JOB – это классный инструмент, чтобы выполнить какую-то определенную задачу, допустим, запустить GitSync. Он выполнит свою задачу и закроется, а потом специальный мусоросборщик будет удалит эти выполненные джобы.
Я для сборки образов использую инструмент kaniko – это крутой инструмент, написанный на Go.
Тем, кто использует Docker в своих CI-контурах, я очень сильно советую посмотреть kaniko, потому что этот инструмент позволяет вам собирать образы безопасно. Вам не нужно внутрь контейнера прокидывать docker-socket – это ужасная дырка в безопасности.
И далее производится публикация этих образов в приватный docker-registry.
Когда мы запускаем наш инстанс, у нас из этого приватного docker-registry забираются образа, и нам наступает счастье.
Кластер Kubernetes
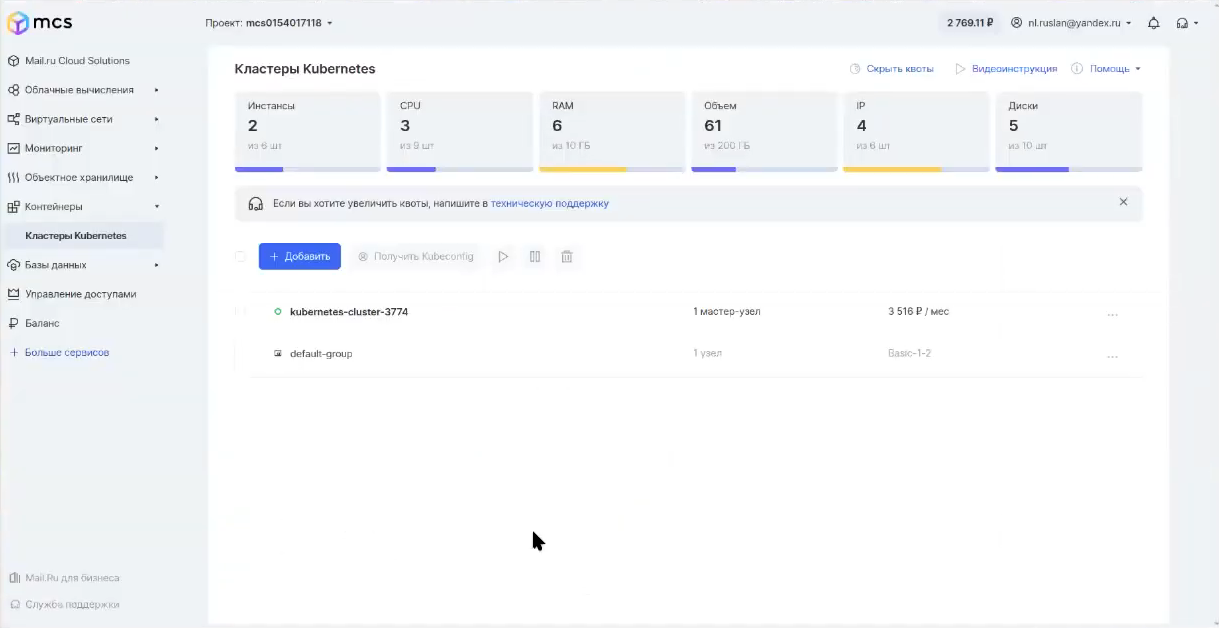
Перейду к внешнему виду. У меня есть кластер Kubernetes, который поднят в MCS (Mail.ru Cloud Solutions).
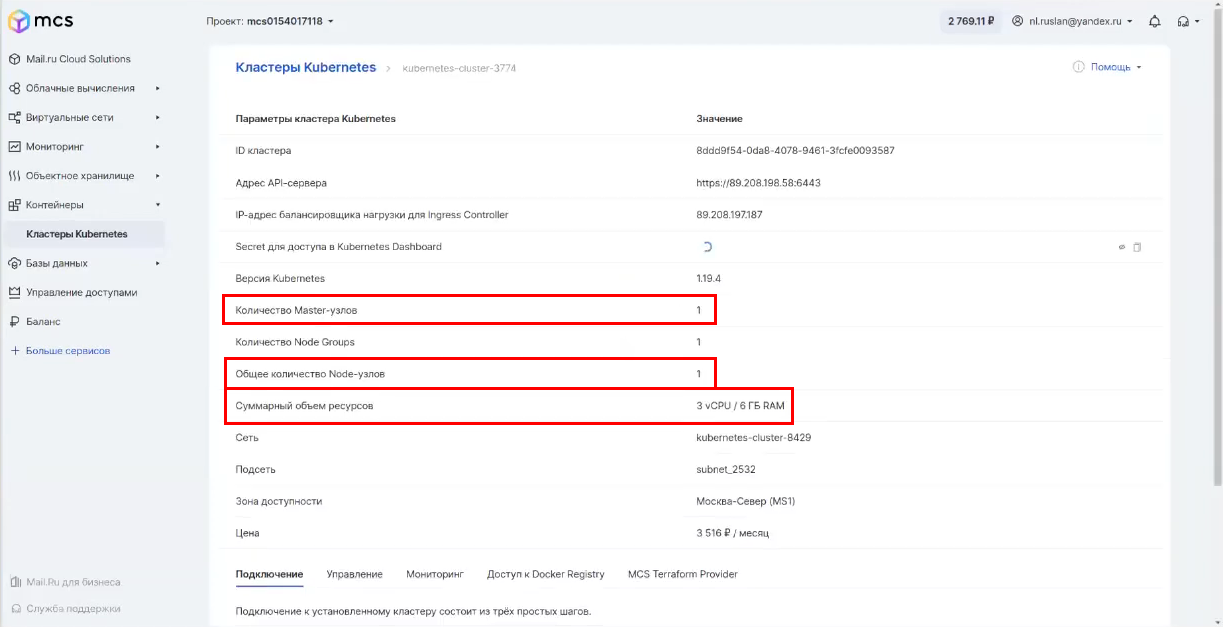
Это – простейший кластер, он состоит из одного мастер-узла и одной ноды.
Суммарный объем ноды – 3 процессора, 6 ГБ оперативы.
Возможно ли использование кластера k8s в качестве тестового сервера для 1С?
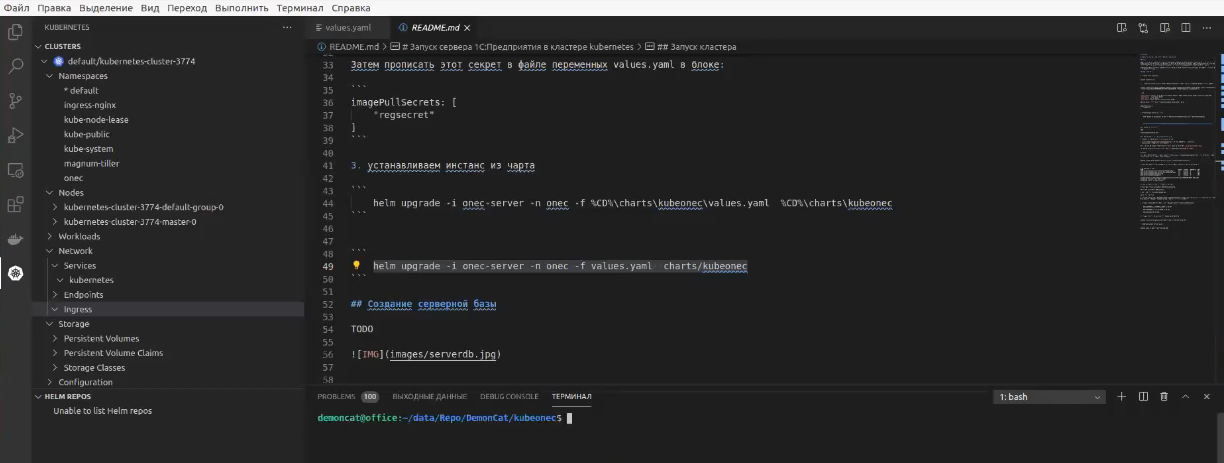
У меня есть репозиторий Kubeonec, я его открываю в Visual Studio Code.
Helm chart я уже развернул, разворачивается он в течение 15 минут по инструкции из репозитория https://github.com/thedemoncat/kubeonec/README.md. Вам нужно будет собрать образы и создать несколько секретов для доступа.
Как посмотреть, что у меня запущено?
Небольшое введение – Kubernetes тоже поддерживает неймспейсы. Когда у вас большой кластер Kubernetes, вы можете его поделить на отдельные неймспейсы, и каждому из своих разработчиков отдать свой неймспейс. Если там еще и правильно настроены права доступа, то разработчик никогда не сможет навредить объектам, находящимся в другом неймспейсе. У меня для моего сценария создан неймспейс – я назвал его onec.
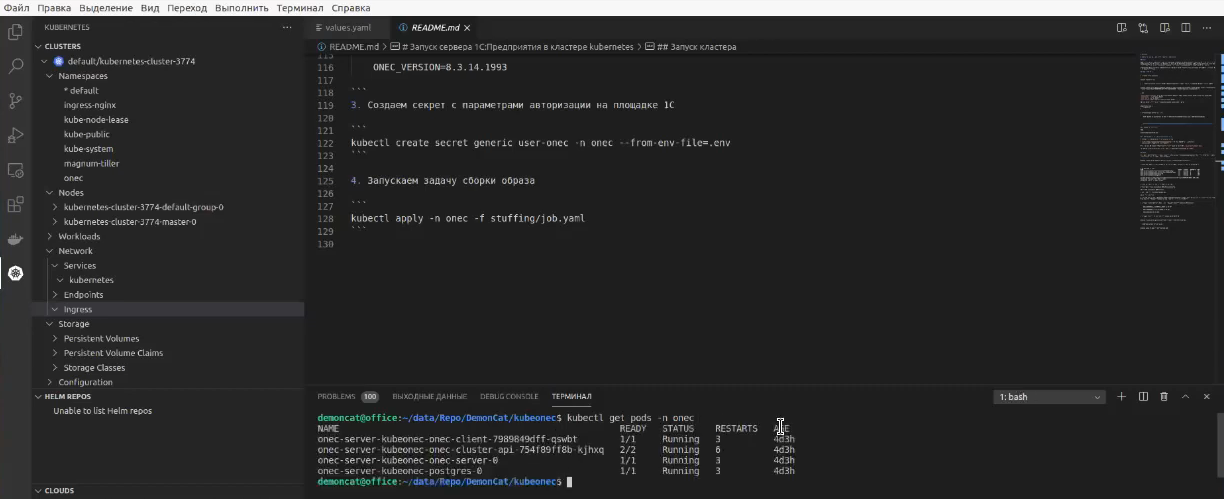
Т.е. я себе сейчас через команду
kubectl get pods -n onec
запрашиваю те поды, которые у меня сейчас работают. И мы видим, что у меня сейчас подняты поды для:
- PostgreSQL
- Сервера 1С
- Кластера управления API – этот под состоит из двух контейнеров
- И клиента 1С
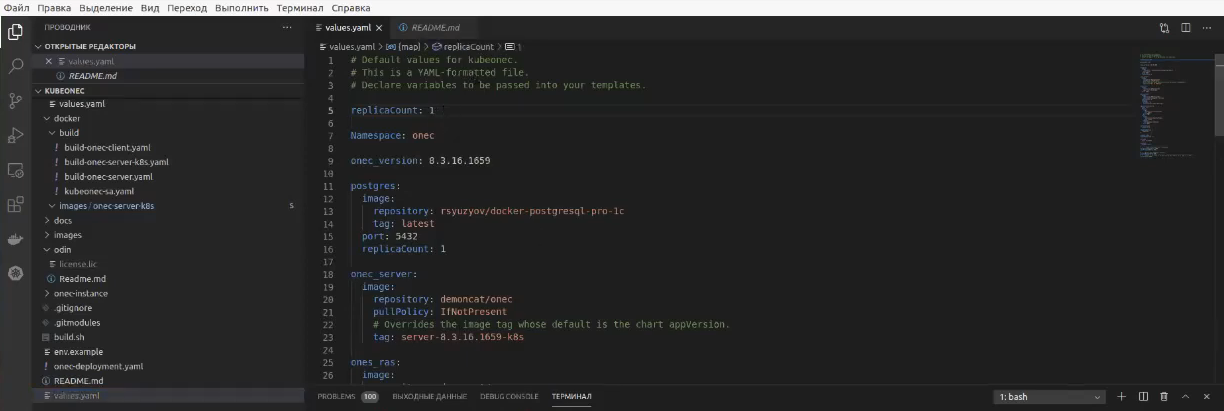
Когда я говорил о том, что иметь конфигурационный файл – это классно, я имел в виду вот такой yaml-файл.
Если мне нужен не один сервер, а три, я ставлю параметр
replicaCount: 3
и выполняю команду
helm upgrade -i onec-server -n onec -f values.yaml charts/kubeonec
с просьбой к helm chart, чтобы он обновил инстанс.
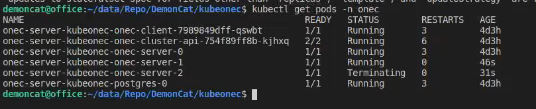
Смотрите, он начал мне создавать новые сервера. Если есть Prometheus, метрики и правильно настроен scale, контейнеры с серверами должны добавляться в кластер автоматически.
Далее у нас есть API-контейнер, в котором находится управлялка нашим кластером. К ней мы перейдем чуть позже. Для начала мы посмотрим, что у нас происходит в клиенте, и насколько это все работает.

Зайдем внутрь контейнера клиента и откроем там bash по команде
kubectl exec -it -n onec onec-server-kubeonec-onec-client-798974dff-qswbt -- bash
Здесь принцип похож на работу с docker.
- -n onec – это неймспейс, в который мы заходим.
- onec-server-kubeonec-onec-client-798974dff-qswbt – имя контейнера
- -- bash – с помощью bash мы полезем вовнутрь.
Я заметил, что если зайти в контейнер и долго ничего не делать, автоматически выбрасывает из подключения. Это – нормальное явление. Так что периодически подключение будет отваливаться, к нему нужно будет еще раз возвращаться.
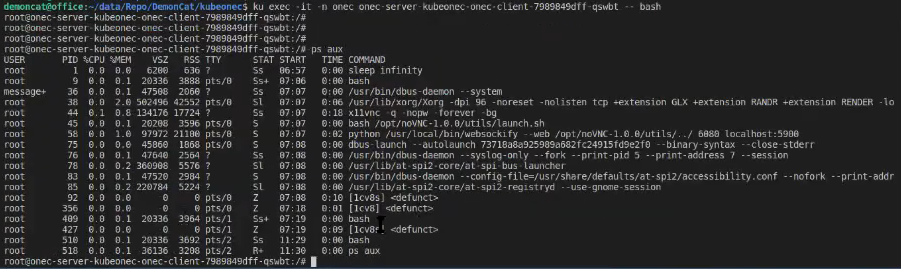
По команде ps aux мы можем посмотреть, какие процессы здесь запущены
У нас здесь запущен Xorg для 1С и noVNC, чтобы мы в браузере могли посмотреть, что происходит.

В отдельном терминале я сделаю проброс порта, чтобы мы могли посмотреть, что там вообще происходит. Пишу
kubectl port-forward -n onec onec-server-kubeonec-onec-client-798974dff-qswbt 6080:6080
У меня noVNC публикуется на порту 6080, и я хочу его просмотреть локально на порту 6080.

Теперь заходим в браузер по адресу http://127.0.0.1:6080 и видим – noVNC запустился.
Попробуем подключиться – все черное, потому что пока у нас ничего не запущено.

Возвращаемся к нашей консоли - вызрвем bash
kubectl exec -it -n onec onec-server-kubeonec-onec-client-798974dff-qswbt -- bash
И запустим здесь 1С – она у нас находится в папке
/opt/1C/v8.3/x86_64/1cestart
Сейчас у нас запустится клиент, в котором мы будем пробовать создавать серверную базу.
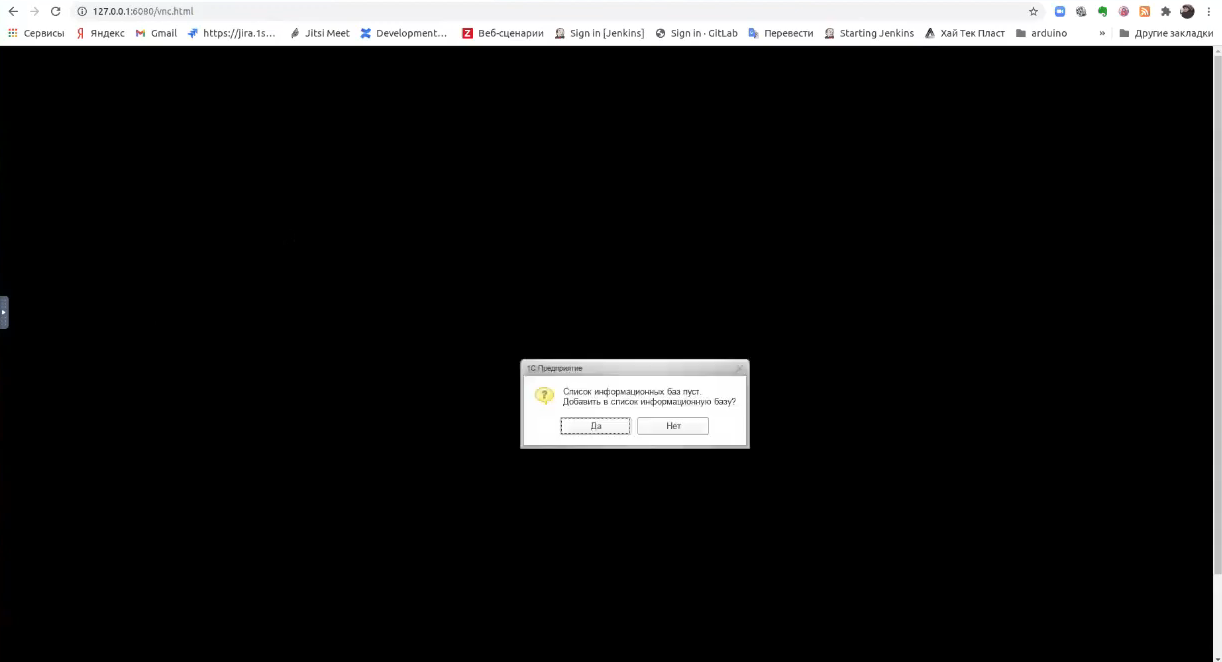
Мы видим, что 1С запускается.
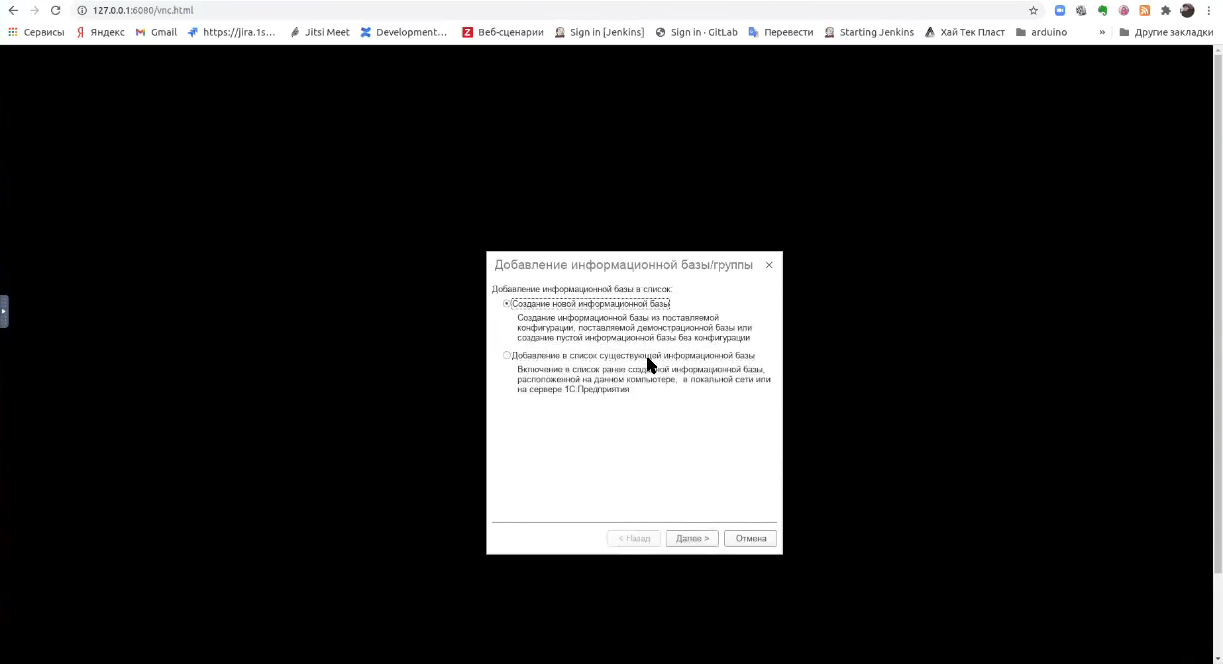
И начинаем создавать новую серверную базу.
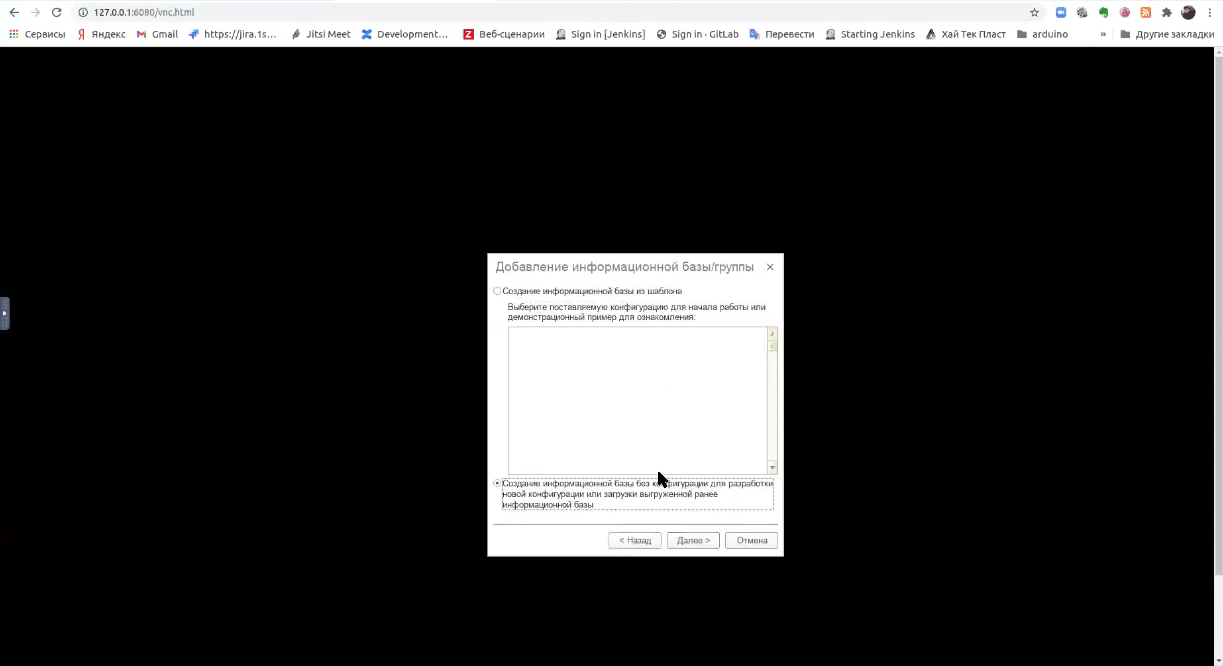
Создаем базу без конфигурации.
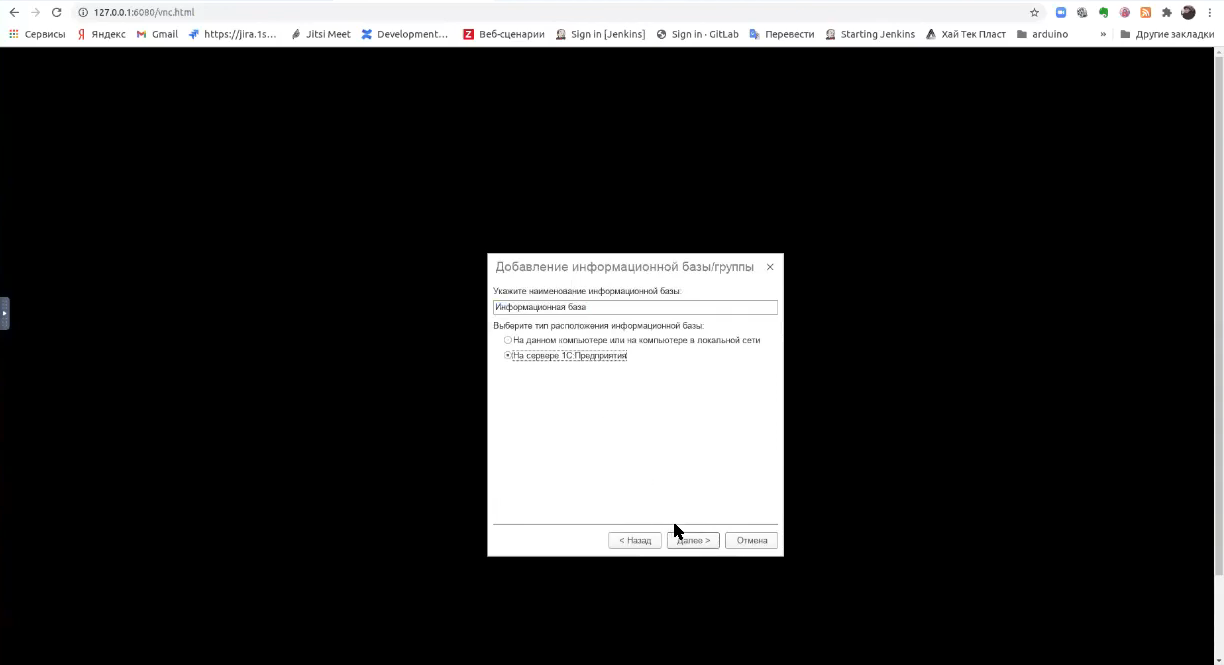
Выбираем создание на сервере.
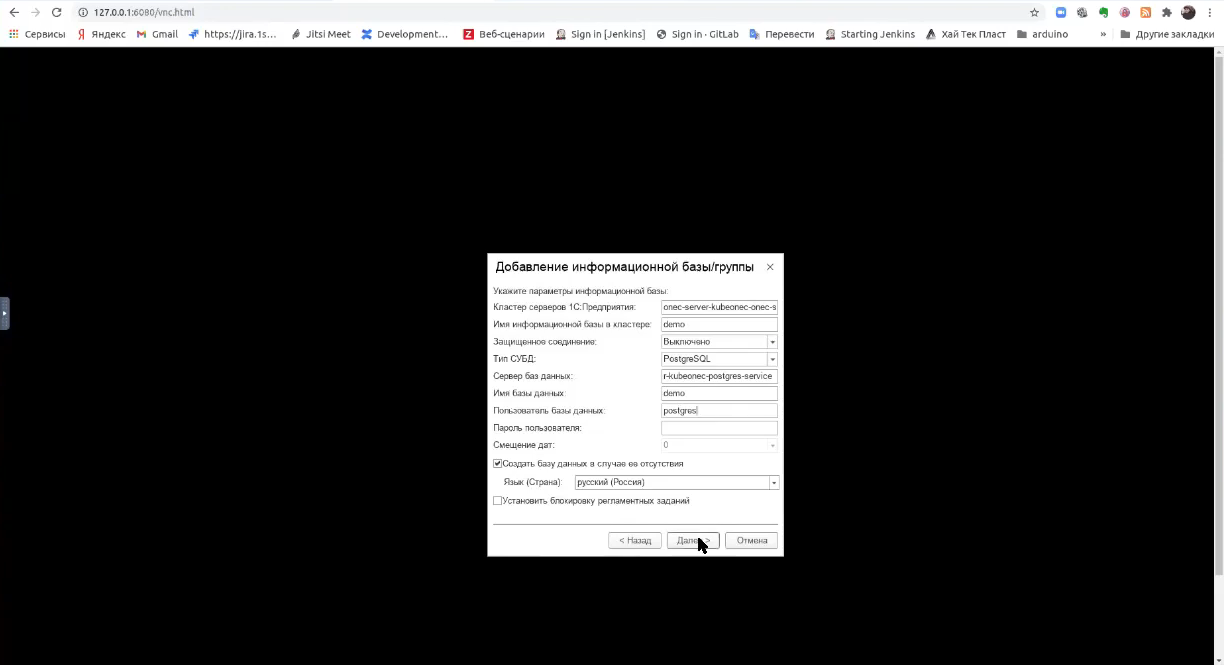
Указываем параметры.
- Имя сервера у нас – onec-server-kubeonec-onec-server-0
- Имя информационной базы в кластере – demo
- Тип СУБД – PostgreSQL
- Сервер баз данных у нас тоже имеет красивое название
onec-server-kubeonec-postgres-service - Имя базы данных – demo
- Пользователь у меня – postgres (без пароля)
Нажимаем и ждем.
В защиту Kubernetes я могу сказать, если бы вы поднимали 1С в docker, у вас часто могла возникнуть ошибка принадлежности сервера из-за того, что имя сервера 1С возвращается неправильное. Когда клиент стучится к кластеру, он сперва обращается к менеджеру кластера и говорит – дай мне, пожалуйста, имя сервера, с которым я могу установить соединение. Если это в docker, он возвращает имя docker-хоста, в котором он работает. Оно зачастую короткое, при этом клиент не знает, о том, какое у него DNS-имя. Из-за этого возникает ошибка принадлежности сервера либо ошибка определения хоста – там есть два варианта этой ошибки. В Kubernetes за счет специального объекта service этой проблемы нет.
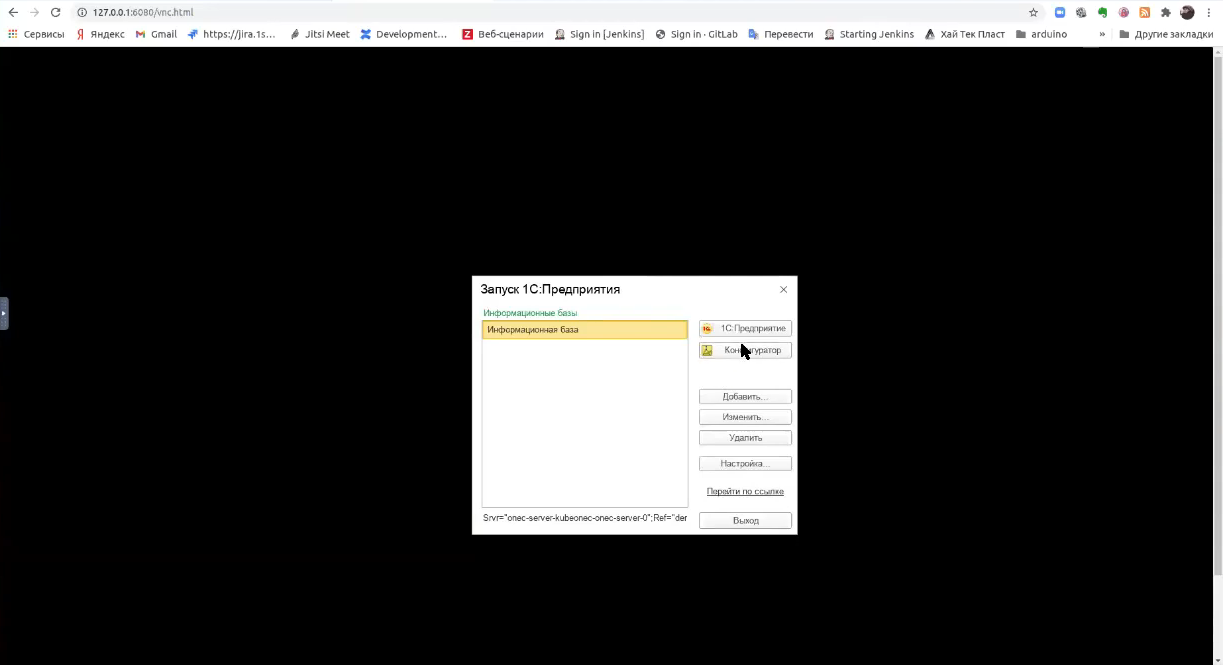
Все, мы видим, серверная база создалась.
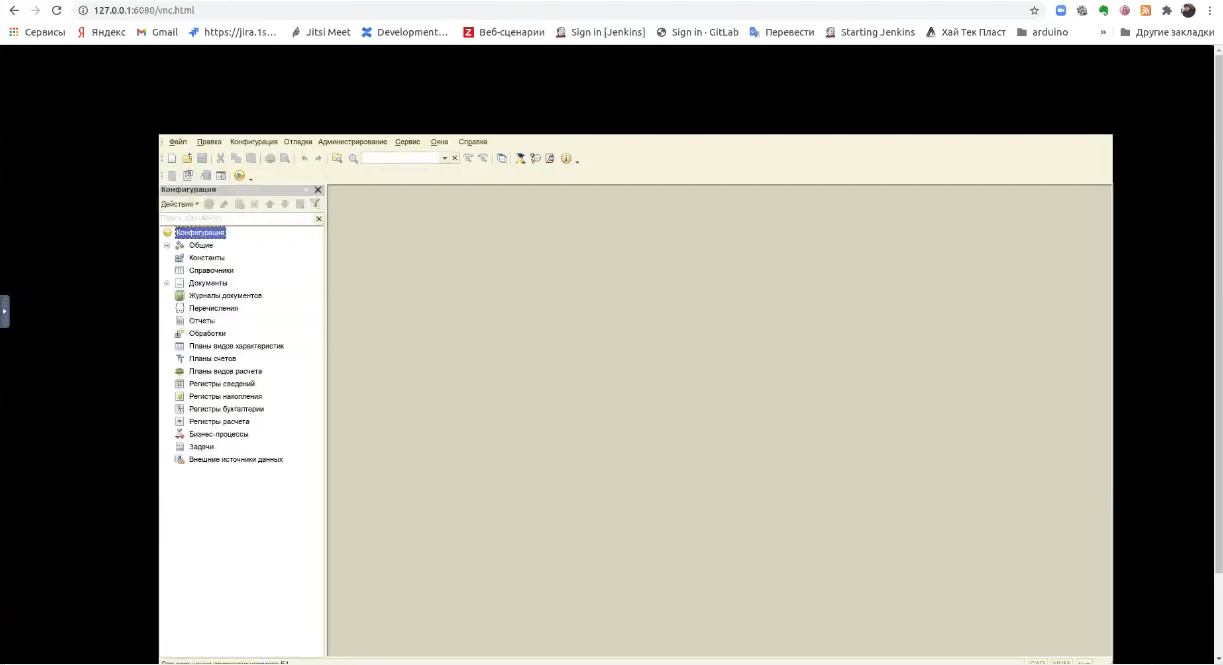
Проверяем – все работает.
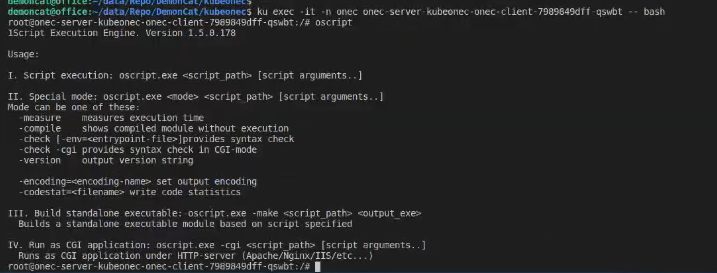
Если мы посмотрим, в контейнере клиента есть OneScript. Это значит, что в этом контейнере можно запускать любое тестирование – все, что касается тестирования на Linux.

Теперь пойдем в контейнер с API – опять посмотрим, как он у нас называется и пробрасываем его на порт 3001.
ku port-forward -n onec onec-server-kubeonec-onec-cluster-api-754f89ff8b-kjhxq 3001:3001
Здесь в качестве управления API, я использую решение ODIN от Алексея Хорева, но с таким же успехом сюда может быть прикручен и HiRAC.
Теперь заходим по адресу http://localhost:3001.
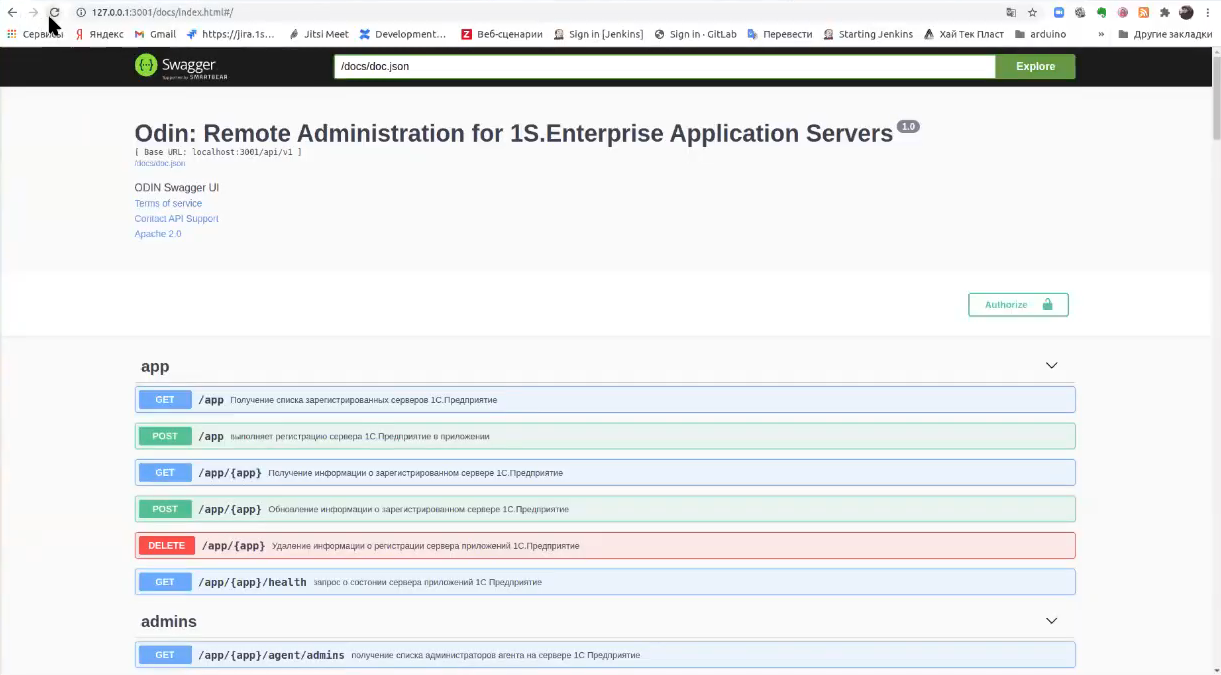
У ODIN есть веб-интерфейс и большое количество методов. Часть методов еще нереализована.
Теперь давайте посмотрим, что у нас есть.
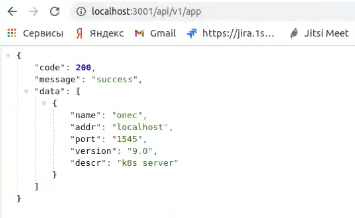
Так как он может работать с кучей различных серверов, у него есть такое абстрактное понятие как app. И вот он мне возвращает, что есть приложение, которое сидит на localhost, к нему можно обращаться. Это по факту, возвращает мне приложение для взаимодействия с RAS.
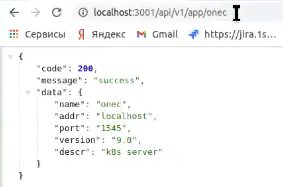
Я могу сказать, что у меня есть конкретное приложение onec.
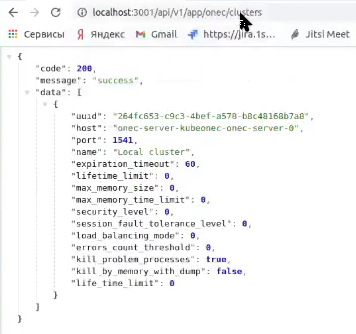
Если я хочу посмотреть его кластер, он мне возвращает данные по кластеру.

Также я могу посмотреть, какие подключения к этому серверу установлены. И какие базы на этом сервере сейчас созданы.
Таким образом работает инстанс Kubeonec с 1С.
Если вам интересно погрузиться в дебри Kubernetes, попробуйте скачать его с GitHub https://github.com/thedemoncat/kubeonec и развернуть.
Мое личное мнение – это достаточно перспективное направление. В любом случае 1С должна будет прийти к стеку облачных технологий – ей от этого не уйти. Да, это, возможно, займет много лет, в любом случае, она к этому когда-нибудь придет.
Вопросы
Вы используете контейнеризацию 1С для запуска тестов на разных версиях платформы, в разных окружениях?
Да, мы делали параллельное тестирование в docker. ADD запускала BDD-тесты в параллели – в различных контейнерах, на разных версиях платформы. В репозитории add лежит Jenkinsfile, как мы это делали.
Квест с лицензиями в docker мы прошли, и это было реально интересно.
А так – да, docker много где используется. GitSync на нем классно запускать, работает. Хранилище можно в docker запускать – вполне нормально работает без запроса лицензий. Есть множество возможностей, где docker для 1С будет нормально работать.
*************
Статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "DevOps в 1С: CI/CD. Непрерывная интеграция и поставка решений на 1С".

Вступайте в нашу телеграмм-группу Инфостарт