
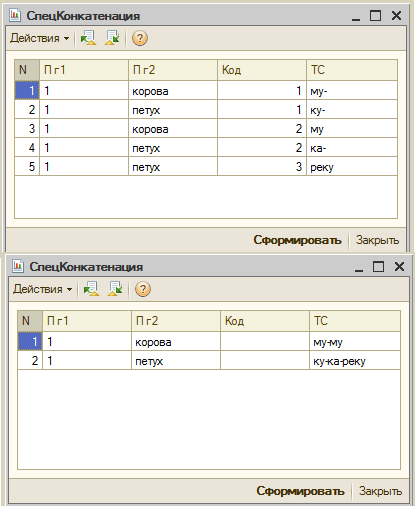
Во многих типовых конфигурациях в документах есть реквизит «Содержание» типа строка, где перечислены фамилии сотрудников, упоминающиеся в строках табличной части, или список номенклатуры, имеющейся в таблице товаров. При заполнении этого реквизита естественно было бы сгруппировать строки по ссылке на документ, определив реквизит «Содержание» с помощью агрегатной функции суммы как СУММА(СсылкаНаОбъектТЧ.Наименование). К сожалению, агрегатная функция СУММА не воспринимает аргумент строкового типа.
Подобных задач довольно много, но если число исходных строк не фиксировано и достаточно велико, все они в общем случае решаются дополнительной обработкой результата запроса. Начиная с релиза 8.2.13(?), в СКД для решения этой задачи даже появилась специальная функция «СоединениеСтрок», что также свидетельствует о популярности задачи «агрегатной конкатенации». Многие сомневаются в возможности решения этой задачи одним пакетным запросом, а зря!
Далее будет приведено доказательство такой возможности. В качестве метода доказательства использован самый простой способ – через демонстрацию построения работающего запроса.
Для начала придется пояснить, чем конкатенация отличается от других агрегатных функций: суммирования, усреднения, выбора максимума и минимума. Дело в том, что все перечисленные функции коммутативны, то есть их результат не зависит от порядка операций. А у конкатенации – зависит. Это означает, что для конкатенации недостаточно одного столбца. Обязательно должен существовать второй (а лучше - первый) столбец, который будет определять порядок подстрок в результирующей строке. Это следует из теории реляционных СУБД, с точки зрения которой таблицы
| А | Т | О | Т | Р | ||||
| В | О | Т | А | В | ||||
| Т | В | В | В | О | ||||
| О | А | А | Р | Т | ||||
| Р | Р | Р | О | А |
это представление одной и той же таблицы. По которой нельзя определить, что должно получиться в результате конкатенации. А по таблице
| 3 | Р |
| 4 | А |
| 5 | В |
| 1 | Н |
| 2 | И |
| 6 | Н |
| 7 | А |
можно.
Если же вдруг порядкового столбца нет, его можно скопировать из столбца строк (это предложил наш коллега andrewks), что будет означать, что перед конкатенацией строки будут отсортированы по алфавиту.
Для простоты будем считать, что порядок соединения задан числами от 1 до N, где N – число строк. Следовательно, исходная таблица «Таб» имеет вид
| ё | а |
| 1 | Строка1 |
| 2 | Строка2 |
| N | СтрокаN |
Соединим для начала попарно все соседние нечетные и четные строки. Для этого определим число «е» как округление результата деления номера строки на два и построим таблицу «Шаг»
| е | ё | а |
| 1 | 1 | Строка1 |
| 1 | 2 | Строка2 |
| 2 | 3 | Строка3 |
| 2 | 4 | Строка4 |
| 3 | 5 | Строка5 |
После этого сгруппируем строки по полю «е», соединив операцией «+» две строки: левую – нечетную, которая отличается тем, что «2 * е – ё = 1», и правую – четную, для которой «2 * е – ё <> 1». В результате получим таблицу
| ё | а |
| 1 | Строка1Строка2 |
| 2 | Строка3Строка4 |
| 3 | Строка5Строка6 |
Повторяя этот приём нужное количество раз, получим в первой строке конкатенацию всех строк.
Соответствующий описанному приему запрос имеет вид:
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб;
УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е;
УНИЧТОЖИТЬ Шаг;
В запросе нарочно сокращены необязательные поля, чтобы его запись было короче, а местами имела смешной вид. Например, такой вид имеют рядом написанные буквы «е» и «ё».
Если в исходной таблице было 2 строки, для завершения алгоритма понадобится один повтор, 4 и менее – два, 8 и менее – три, 16 и менее – четыре,32 и менее - пять, 64 и менее – шесть, 128 и менее – семь, 256 и менее – восемь, … 2048 и менее – одиннадцать. Принцип, думаю, понятен, обойдемся без формулы с логарифмом по основанию два.
А как определить нужное число повторений заранее? Не зная числа соединяемых строк? И вот тут-то и нужно вспомнить, что хотя число строк ничем не ограничено, но ограничен размер строки, который будет принимать результат наших вычислений. Результирующая строка – это строка ограниченного типа, которая в 1С не может содержать больше 2047 символов! Следовательно, использовать более 11-ти соединений вообще не нужно, так как результат будет просто некуда поместить.
Можно успокоить тех, кого это обстоятельство будет расстраивать: не поместившиеся в первой строке символы с помощью этого алгоритма волшебным образом окажутся записанными во второй строке и так далее.
Кроме того, если ограничение будет когда-либо повышено, то нужно будет всего немного увеличить число повторений. Даже строка неограниченного типа не может быть длиннее 2^31 -1 символов. Что означает, что будет нужно добавить еще всего лишь двадцать повторений. Отметим, что операции группировки для данного случая выполняются достаточно быстро. Притом, что строки идут по порядку.
На практике есть еще два обстоятельства, которые требуется учесть и которые существенно усложняют, а главное, к сожалению, – замедляют вычисления.
Первое обстоятельство - это способ реализации суммирования двух полей строкового типа при получении нового поля в запросе, о котором мы обычно не задумываемся. Точнее, способ вычисления длины поля строкового типа, содержащего результат. Во-первых, можно складывать только поля строк ограниченного типа (ну или приведенного к нему неограниченного типа с использованием оператора «ВЫРАЗИТЬ»). Во-вторых, результирующее поле будет также строкой ограниченного типа, длина которой будет равна сумме длин соединяемых полей. Независимо от того, сколько символов на самом деле занято в этих полях!
Для нас это означает, что имея на первом шаге строки длины 32, например, мы не сможем выполнить более шести повторений (64->128->256->512->1024->2048), так как длины строк будут на каждом шаге считаться по-максимуму, а не по реальному содержанию. А шесть повторений – это всего 64 сложенные строки, причем в результирующей 2047-символьной строке может быть реально занято совсем немного места.
Максимальную плотность упаковки символов в результирующей строке можно обеспечить, если перед соединением предварительно разбить строки на отдельные символы. И не только разбить, но и затем правильно последовательно пронумеровать. Это может быть довольно дорогая в вычислительном отношении операция, поскольку глобальный номер отдельного символа конкретной строки будет зависеть от числа символов в строках впереди нее. То есть потребуется медленное тэта-соединение таблицы строк с самой собой.
В самом сложном случае также нужно предусмотреть разбивку на отдельные символы 2047-символьных строк. Если изначально строки будут короче, время разбивки сократится.
Разбивка строк на символы выполняется с использованием соединения с искусственной таблицей, содержащей числа от 0 до 2047, полученной методом «Порождающего запроса» [//infostart.ru/public/90367/].
Числа от 0 до 2047 записываются в таблицу РА9876543210, название которой составлено из первой буквы слова «Разряд» и номеров содержащейся в ней двоичных разрядов (в шестнадцатеричной системе – цифр не хватило, десятый разряд обозначен буквой «А»). Это делает следующий фрагмент запроса:
ВЫБРАТЬ РАЗЛИЧНЫЕ Дано.Колонка НомерСтроки, Дано.Колонка а ПОМЕСТИТЬ Дано ИЗ &Дано КАК Дано;
ВЫБРАТЬ 0 ё ПОМЕСТИТЬ Р0 ОБЪЕДИНИТЬ ВЫБРАТЬ 1;
ВЫБРАТЬ 2 * Р1.ё + Р0.ё ё ПОМЕСТИТЬ Р10 ИЗ Р0 Р1, Р0;
ВЫБРАТЬ 4 * Р32.ё + Р10.ё ё ПОМЕСТИТЬ Р3210 ИЗ Р10 Р32, Р10;
ВЫБРАТЬ 16 * Р7654.ё + Р3210.ё ё ПОМЕСТИТЬ Р76543210 ИЗ Р3210 Р7654, Р3210;
ВЫБРАТЬ 8 * Р76543210.ё + 2 * Р10.ё + Р0.ё + 1 ё ПОМЕСТИТЬ РА9876543210 ИЗ Р76543210, Р10, Р0 ГДЕ 8 * Р76543210.ё + 2 * Р10.ё + Р0.ё < &ШиринаКолонки
Параметр «ШиринаКолонки» обозначает длину строки в поле «КОЛОНКА» (если 0, то 2047).
Собственно разбивка на символы выполняется в следующем фрагменте запроса. Результат помещается в таблицу «Буквы»
ВЫБРАТЬ НомерСтроки, ё, ПОДСТРОКА(а, ё, 1) а ПОМЕСТИТЬ Буквы ИЗ Дано, РА9876543210 ГДЕ ПОДСТРОКА(а, ё, 1) + "!" <> "!"
После этого получается таблица длин строк и с ее использованием буквы «а» получают глобальные номера «ё» в таблице «Таб».
ВЫБРАТЬ НомерСтроки, МАКСИМУМ(ё) СтрДлина ПОМЕСТИТЬ Длины ИЗ Буквы СГРУППИРОВАТЬ ПО НомерСтроки;
ВЫБРАТЬ ё + СУММА(ЕСТЬNULL(СтрДлина, 0)) ё, а Поместить Таб ИЗ Буквы КАК Буквы ЛЕВОЕ СОЕДИНЕНИЕ Длины ПО Буквы.НомерСтроки > Длины.НомерСтроки
СГРУППИРОВАТЬ ПО Буквы.НомерСтроки, ё, а
Второе усложняющее обстоятельство – это «проблема пробелов». Дело в том, что при работе со строками в запросе к результату как будто бы автоматически применяется функция «СокрП». То есть становится невозможно зафиксировать добавление пробела справа. Операция вроде бы выполняется, а добавленные пробелы сразу же пропадают. В результирующей строке это выглядит как исчезнувшие пробелы. «пока лечили» превращается в «покалечили», "несу разное" в "несуразное" и так далее.
Выход был найден в том, что обычный пробел в строках при их разбивке на символы заменялся на неразрывный пробел – символ с кодом 160 (Символы.НПП). Поскольку внешне эти символы выглядят неотличимо, то запрос принимает крайне любопытный вид. Он получает буквально неочевидные свойства. Честно говоря, такой «невидимый» трюк приходится использовать впервые. Кроме того, при каком-либо копипасте запроса этот особенный пробел может подмениться обычным. Будьте внимательнее – следите за своими пробелами!
С учетом последнего уточнения предпоследний фрагмент принимает следующий вид (в кавычках после "Тогда" - неразрывный пробел!):
ВЫБРАТЬ НомерСтроки, ё, ВЫБОР ПОДСТРОКА(а, ё, 1) КОГДА " " ТОГДА " " ИНАЧЕ ПОДСТРОКА(а, ё, 1) КОНЕЦ а ПОМЕСТИТЬ Буквы ИЗ Дано, РА9876543210
ГДЕ ПОДСТРОКА(а, ё, 1) + "!" <> "!"
Ну а весь собранный в единое целое запрос получает в итоге следующий законченный вид:
ВЫБРАТЬ РАЗЛИЧНЫЕ Дано.Колонка НомерСтроки, Дано.Колонка а ПОМЕСТИТЬ Дано ИЗ &Дано КАК Дано;
ВЫБРАТЬ 0 ё ПОМЕСТИТЬ Р0 ОБЪЕДИНИТЬ ВЫБРАТЬ 1;
ВЫБРАТЬ 2 * Р1.ё + Р0.ё ё ПОМЕСТИТЬ Р10 ИЗ Р0 Р1, Р0;
ВЫБРАТЬ 4 * Р32.ё + Р10.ё ё ПОМЕСТИТЬ Р3210 ИЗ Р10 Р32, Р10;
ВЫБРАТЬ 16 * Р7654.ё + Р3210.ё ё ПОМЕСТИТЬ Р76543210 ИЗ Р3210 Р7654, Р3210;
ВЫБРАТЬ 8 * Р76543210.ё + 2 * Р10.ё + Р0.ё + 1 ё ПОМЕСТИТЬ РА9876543210 ИЗ Р76543210, Р10, Р0 ГДЕ 8 * Р76543210.ё + 2 * Р10.ё + Р0.ё < &ШиринаКолонки;
ВЫБРАТЬ НомерСтроки, ё, ВЫБОР ПОДСТРОКА(а, ё, 1) КОГДА " " ТОГДА "_" ИНАЧЕ ПОДСТРОКА(а, ё, 1) КОНЕЦ а ПОМЕСТИТЬ Буквы ИЗ Дано, РА9876543210 ГДЕ ПОДСТРОКА(а, ё, 1) + "!" <> "!";
ВЫБРАТЬ НомерСтроки, МАКСИМУМ(ё) СтрДлина ПОМЕСТИТЬ Длины ИЗ Буквы СГРУППИРОВАТЬ ПО НомерСтроки;
ВЫБРАТЬ ё + СУММА(ЕСТЬNULL(СтрДлина, 0)) ё, а Поместить Таб ИЗ Буквы КАК Буквы ЛЕВОЕ СОЕДИНЕНИЕ Длины ПО Буквы.НомерСтроки > Длины.НомерСтроки СГРУППИРОВАТЬ ПО Буквы.НомерСтроки, ё, а;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК ЧИСЛО(15,0)) е, ё, а ПОМЕСТИТЬ Шаг ИЗ Таб; УНИЧТОЖИТЬ Таб;
ВЫБРАТЬ е ё, МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА а ИНАЧЕ "" КОНЕЦ) + МАКСИМУМ(ВЫБОР е*2-ё КОГДА 1 ТОГДА "" ИНАЧЕ а КОНЕЦ) а ПОМЕСТИТЬ Таб ИЗ Шаг СГРУППИРОВАТЬ ПО е; УНИЧТОЖИТЬ Шаг;
ВЫБРАТЬ а ИЗ Таб
Здесь приведена версия «лайт» запроса. Рабочий запрос отличается от данного тем, что во фрагментах со второго по четвертый добавлена еще одна группировка по полю, по которому собственно и выполняется «агрегатная конкатенация». К статье приложена обработка (отчет), с помощью которой можно испытать данный запрос, замерить время его выполнения. Впрочем, он будет работать и в консоли, если она умеет задавать параметры в виде таблицы значений. Приведен также скриншот формы обработки.
Как уже говорилось, основной мотив составления этого запроса был спортивный интерес и разубеждение скептиков.
Ну, а насколько этот достаточно сложный запрос практичен, судите сами. Его можно использовать не только для генерации реального или виртуального реквизита «Содержание» документов, но и для других задач простой обработки текстовой информации непосредственно в запросах. Например, для замены или удаления символов в наименованиях, артикулах, транслитерации, перевода слов, для форматирования адресов, телефонов и прочее, прочее, прочее. То есть везде, где есть желание использовать несуществующую агрегатную функцию СУММА(ТекстоваяСтрока).
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}