Оглавление
Пропорциональное распределение
Приемы работы с результатом распределения
Досчет итоговых колонок после матричного распределения
Списание партий товаров по номенклатуре - пожалуй самая хрестоматийная задача распределения по порядку. Такого рода задачи весьма распространены в учете: зачет авансов, определение лимитов, распределение заказа по складам, определение факта БДДС по оплаченным заявкам и т.д. Удивительно, но решая множество таких задач мне и в голову не приходило, что их можно объединить в единый класс задач по распределению. Вначале каждую такую задачу я решал по месту. В какой-то момент я понял, что пора уже выделить распределение в отдельную универсальную функцию.
Наверное это естественный путь эволюции кода, когда вначале возникает множество разрозненных решений, чтобы затем их можно было бы обобщить. И здесь возникает множество вопросов реализации: какой класс задач будет решаться, какие входящие и исходящие параметры будут нужны. Класс задач можно определить из уже имеющегося опыта и написанного кода. С параметрами тут может возникнуть следующая проблема - возможно класс задач очень широк и потому состав параметров для каждой задачи из класса может быть разным, а общее их количество достаточно большим.
Вот пример того, что у меня получалось в 1-ой версии:
ТаблицаРаспределения(МенеджерВременныхТаблиц, ИмяТаблицы, ИмяБазы, КлючевыеПоля, КлючУникальный, ПоляБазы, ПоляРесурсов, ПоляПорядка, ТаблицаПревышения, ТаблицаОстатков, Разрядность)
Вот пример того, что у меня получалось во 2-ой версии:
ТаблицаРаспределенияЧерезОтношение(МенеджерВременныхТаблиц, ИмяТаблицы, ИмяБазы, КлючевыеПоля, КлючУникальный, ПоляБазы, ПоляРесурсов, ПоляПорядка, ТаблицаПревышения, ТаблицаОстатков, Разрядность, ИмяТаблицыОтношения, ПоляОтношения)
Получилось, что мне потребовалось от 11 до 13 параметров! Использовать такие функции все-таки лучше, чем каждый раз решать задачу занова. Однако с таким большим количеством параметров терялась наглядность и как ни странно - гибкость.
Наглядность терялась из-за необходимости использовать разный набор параметров. Гибкость ограничивалась набором параметров, количество которых не может быть бесконечным. Обе эти проблемы хорошо решаются при использовании DSL.
Для повышения наглядности можно было бы разбить одну универсальную функцию на несколько и создать своего рода фреймворк по распределению. Но тогда возникает вопрос, а где хранить контекстную информацию? Создание множества переменных и манипуляция ими мне тоже не показалось лучшим решением (см. мой фреймворк по работе со схемой запроса). Однако мои эксперименты в области решения подобной задачи повышения наглядности через реализацию текучего интерфейса навели на мысль, что подобное решение можно применить и в этот раз. Оставалось дело за малым - придумать DSL и сделать его поддержку на базе реализации текучего интерфейса (см. мою библиотеку МодельЗапроса).
Гибкость при таком подходе достигается за счет использования операторов и параметров к ним. Например для описания входящей таблицы распределения можно предусмотреть операторы для установки измерений, ресурсов и реквизитов таблицы. Причем можно использовать не весь набор операторов, а только те, которые нужны для конкретного результата или являются обязательными. Кроме того, даже отдельные операторы можно также иерархически описывать вложенными операторами - и так до бесконечности :).
Конечно у такого подхода есть и свои недостатки. Такой подход очень зависим от соблюдения синтаксиса. Для использования решения на базе DSL необходимо знать этот новый, хоть и очень ограниченный, язык программирования. Однако у этого подхода есть и преимущества: необычайная гибкость и выразительность. Первое достигается за счет операторов и вложенности, 2-ое через синтаксис и отсутствие необходимости сохранять контекст в переменных.
Как было отмечено вначале статьи задачи распределения весьма распространены. Я в своей практике написал много таких решений. Пройдя путь от кода по месту, использование универсальной функции, представляю вам решение на базе DSL. Суть решения заключается в том, что задача описывается декларативно. После описания задачи распределения вызывается метод Распределить и дальше можно обращаться к результатам: результат распределения, остаток распределения, остаток базы распределения. Такой подход очень похож на работу с запросом: вначале запрос описывается на языке запросов, затем вызывается метод Выполнить и дальше можно обращаться к результату выборки из базы данных.
Всего я выделяю два основных вида распределения: пропорционально и по порядку. Каждое из этих распределений можно также представить через промежуточную таблицу - Отношение. В распределении участвуют таблицы. Результат распределения представляет собой также таблицу, состоящую из реквизитов таблицы распределения и реквизитов таблицы базы распределения. Реквизиты поделены на роли: Измерения, Ресурсы, Реквизиты.
Измерения - это поля таблицы распределения, по которым связываются строки исходной таблицы с таблицей базы распределения. Способ описание полей измерений, как впрочем и полей ресурсов, сделан по аналоги с построением схемы запроса (см. Модель запроса). В ряде задач таблица распределения и база могут быть не связаны. В этом случае измерения будут отсутствовать, а связь будет установлена путем распределения.
Ресурсы - это числовые поля, участвующие в распределении из исходной таблицы по ресурсам базы. В простом случае участвует один ресурс или поле, сумма из которого распределяется по суммам базы. Если же ресурсов несколько, то первый ресурс будет суммой всех остальных. Более математически для нескольких ресурсов должно соблюдаться равенство: Ресурс 1 = Сумма(Ресурс 2 ... n).
При использовании нескольких ресурсов должно также соблюдаться правило, что их количество в исходной таблице и базовой должно либо совпадать, либо в одной из таблиц должен быть один ресурс. Распределение в этом случае производится вначале по первому ресурсу, а затем по остальным: по ресурсам 2...n в исходной таблице и в базе. Для нескольких ресурсов сумма распределения определяется наименьшей суммой по исходной и базовой таблиц.
И наконец Реквизиты - это дополнительные поля, которые должны попасть в результат распределения.
Использование отношения между таблицей распределения и базой позволяет описать нелинейную связь между ними. Например, в задаче определения лимитов вполне может быть такая ситуация, когда лимиты устанавливаются с меньшей детализацией. Или в той же задаче про лимиты используются разные уровни: детальный, общий, непредвиденные расходы и неприкосновенный запас. Если в 1-ом случае вполне можно обойтись и без промежуточной таблицы, то для второго случая без нее уже нельзя, т.к. в этом случае одной строке исходной таблицы будет соответствовать несколько строк представления: детальный, общий, непредвиденные и неприкосновенный.
В примере рассматривается распределение товаров по лимитам с приоритетом. Здесь детальный уровень соответствует лимитам по товару и статье, общий - по статье по всем товарам, общий - по всем статьям и товарам, Непредвиденные. Где общий лимит по всем товарам представлен пустым значением измерения базы Товар, а по всем статьям - пустое значение измерения базы Статья. Непредвиденные представлены статьей по всем товарам.
В примере "Списание лимитов" используется отношение для определения лимитов по приоритетам.
Формула распределения: Товары х Приоритеты х Лимиты => Лимиты по товарам по приоритетам
МодельРаспределения
.Таблица("ВТ_ТОВАРЫ")
.Измерения()
.Поле("Товар", "ТоварИсходный")
.Поле("Статья", "СтатьяИсходная")
.Реквизиты()
.Поле("*")
.Ресурсы()
.Поле("Сумма")
.Отбор("НЕ Корректировка")
.Отношение("ВТ_ПРИОРИТЕТЫ_ЛИМИТОВ")
.ИзмеренияТаблицы()
.Поле("*")
.ИзмеренияБазы()
.Поле("Товар")
.Поле("Статья")
.Порядок("Приоритет")
.База("ВТ_ЛИМИТЫ")
.Измерения()
.Поле("*")
.Реквизиты()
.Поле("*")
.Ресурсы()
.Поле("Сумма")
;
Модель распределения "Списание лимитов"
В хрестоматийном примере задачи распределения номенклатуры по партиям товаров с одной стороны есть список товаров с их количеством, а с другой - остатки партий товаров. Необходимо рассчитать количество товаров по партиям по порядку FIFO. Обычная задачка из экзамена на 1С Специалиста решается стандартно одним запросом.
Пример "Товары по партиям".
Формула распределения: Товары х Партии (по FIFO) => Товары по партиям, Нераспределенные товары, Нераспределенные партии. Декларативное описание будет следующим:
МодельРаспределения
.Таблица("ВТ_ТОВАРЫ")
.Измерения()
.Поле("Товар")
.Реквизиты()
.Поле("*")
.Ресурсы()
.Поле("Количество")
.Отбор("НЕ Корректировка")
.База("ВТ_ПАРТИИ")
.Измерения()
.Поле("*")
.Реквизиты()
.Поле("*")
.Ресурсы()
.Поле("Количество")
.Порядок("ДатаПартии")
;
Модель распределения "Товары по партиям"
Задача в предыдущем примере может быть решена и по другому, например, проворционально всем партиям товаров. Для этого достаточно было не указывать порядок базы.
В следующем примере "Пропорция" сумма распределяется по строкам товаров и по суммам: Сумма без НДС, Сумма НДС.
МодельРаспределения
.Таблица("ВТ_СУММА_РАСПРЕДЕЛЕНИЯ")
.Ресурсы()
.Поле("Сумма")
.База("ВТ_ТОВАРЫ")
.Ресурсы()
.Поле("Сумма")
.Поле("СуммаБезНДС")
.Поле("СуммаНДС")
.Реквизиты()
.Поле("*")
.Отбор("НЕ Корректировка")
;
Модель распределения "Пропорция"
Распределение нескольких ресурсов в исходной таблице по нескольким ресурсам в базе и есть матричное распределение. Как было указано выше, количество полей ресурсов может быть неограниченно при выполнении условий: поля ресурсов совпадают в исходной таблице и в базе, сумма в первом поле ресурса равна сумме всех остальных ресурсов.
В данном примере решается задача распределения авансовых платежей по товарам методом FIFO. Сумма аванса распределяется по общей сумме товара и по её составляющим: НДС, без НДС.
Пример "Зачет".
Формула распределения: Авансы х Товары => Зачет авансов по товарам в сумме НДС, без НДС
МодельРаспределения
.Таблица("ВТ_ТОВАРЫ")
.Реквизиты()
.Поле("*")
.Ресурсы()
.Поле("Сумма")
.Поле("СуммаБезНДС")
.Поле("СуммаНДС")
.Отбор("НЕ Корректировка")
.База("ВТ_АВАНСЫ")
.Реквизиты()
.Поле("*")
.Ресурсы()
.Поле("Сумма")
.Порядок("ДатаАванса")
;
Модель распределения "Зачет"
Еще одним примером такой задачи является реклассификация затрат по статьям (использована таблица Товары). Сами затраты учитываются как сумма НДС и без НДС. Необходимо распределить корректировочные строки с отрицательной суммой на строки с положительной суммой.
Пример "Реклассификация".
Формула распределения: Товары корр х Товары => Товары корр по строкам товаров, где соответствие задается через НомерСтрокиКорр -> НомерСтроки
МодельРаспределения
.Таблица("ВТ_ТОВАРЫ")
.Реквизиты()
.Поле("НомерСтроки", "НомерСтрокиКорр")
.Поле("*")
.Ресурсы()
.Поле("-Сумма", "Сумма")
.Поле("-СуммаБезНДС", "СуммаБезНДС")
.Поле("-СуммаНДС", "СуммаНДС")
.Отбор("Корректировка")
.База("ВТ_ТОВАРЫ")
.Реквизиты()
.Поле("*")
.Ресурсы()
.Поле("*")
.Отбор("НЕ Корректировка")
.Порядок("Сумма", "-")
;
Модель распределения "Реклассификация"
Вполне возможна ситуация, когда ресурсы образуют группы с промежуточными итогами. Например по строке может представлять сумму затрат материалов и работ:
- Сумма = НДС + Сумма без НДС
- Сумма = Сумма Материалы + Сумма Работы
- Сумма = Сумма Материалы НДС + Сумма Материалы без НДС + Сумма Работы НДС + Сумма Работы без НДС
Тогда в результате распределения будут получены самые мелкие составляющие общей суммы затрат. После распределения нужно будет досчитать промежуточные суммы по строкам: Сумма Материалы, Сумма Работы.
Еще один интересный класс задач решается через организацию конвейерной обработки. В таких задачах требуется несколько распределений, где на каждое последующее распределение передаются остатки от предыдущих.
Приведу пример из моей практики. По бизнес-процессу вначале оформляется заявка на расходование денежных средств в разрезе статей БДДС. Затем эта заявка размещается по определенному счету для резервирования денежных средств. При формировании платежного поручения в документе выбирается список заявок. Могут быть указаны как просто заявки, так и размещения заявок по счету. Для определения состава статей необходимо выполнить два распределения: вначале распределить заявки с явным указанием размещения, затем остальные заявки. Остальные заявки тоже размещены, однако конкретное размещение в платежном поручении по ним не указано. Второе распределение как раз устанавливает соответствие заявок с их размещениями.
Хотя DSL модели распределения не позволяет строить конвейерную обработку, этот недостаток компенсируется легкостью передачи результатов предыдущего распределения в новое. Для этого достаточно прочитать таблицы остатков во временные таблицы и таким образом они становятся доступными для следующего распределения.
МодельРаспределения
.Таблица(МодельРаспределения.ТаблицаРаспределения)
.Измерения()
.Поле("Товар")
.Ресурсы()
.Поле("Количество")
.Реквизиты()
.Поле("*")
.База(МодельРаспределения.БазаРаспределения)
.Измерения()
.Поле("*")
.Ресурсы()
.Поле("*")
.Реквизиты()
.Поле("*")
;
Передача результата предыдущего распределения (см. пример "Конвейер")
Объектная модель распределения состоит из описания трех таблиц: Таблица, Отношение, База. Если Отношение не требуется, то оно не должно участвовать в описании модели. Таблицы передаются в модель по имени временной таблицы или через таблицу (табличная часть, таблица значений, данные формы коллекция).
Таблица описывается группами полей: Измерения, Реквизиты, Ресурсы. Каждое поле представляет собой выражение и псевдоним. Описание поля аналогично как в Модели запроса. Допускается использование обобщенного символа "*" (см. Снежинка для запроса).
Кроме описания полей для таблицы можно также задать Порядок и Отбор (см. Модель запроса). Использование порядка в описании таблицы базы приводит к однозначному выбору распределения по порядку.
Описание Отношения отличается от описания таблиц Таблица и База наличием двух групп измерений: ИзмеренияТаблицы, ИзмеренияБазы.
В конструктор объекта модели распределения можно передать МенеджерВременныхТаблиц и количество знаков после запятой (по-умолчанию 2).
МодельРаспределения = Общий.МодельРаспределения(МодельЗапроса.МенеджерВременныхТаблиц);
Модель описывается в виде структуры: Таблица-Состав полей (см. примеры выше). Результат распределения получается после вызова метода Распределить().
// Конструктор
МодельРаспределения = Общий.МодельРаспределения(МенеджерВременныхТаблиц);
// Описание модели
МодельРаспределения
.Таблица("ВТ_СУММА_РАСПРЕДЕЛЕНИЯ")
.Ресурсы()
.Поле("Сумма")
.База("ВТ_ТОВАРЫ")
.Ресурсы()
.Поле("Сумма")
.Поле("СуммаБезНДС")
.Поле("СуммаНДС")
.Реквизиты()
.Поле("*")
.Отбор("НЕ Корректировка")
;
МодельРаспределения.Распределить();
// Результат
МодельРаспределения.РезультатРаспределения;
МодельРаспределения.БазаРаспределения;// остаток базы
МодельРаспределения.ТаблицаРаспределения;// остаток распределения
Пример работы с моделью
Поставка
В демо базе есть примеры реализации распределений. В разделе Демо модель распределения выборать обработку Демо распределение. Для каждого примера есть демо данные в табличных частях и отчет по выполнению.
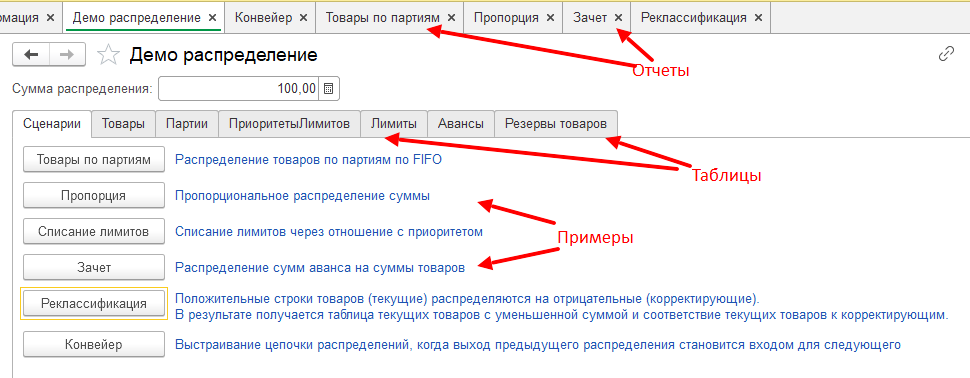
Обработка для демонстрации работы распределения
Зависимости: БСП, МодельЗапроса, Платформа 8.3.18 (8.3.18.1520)
Вступайте в нашу телеграмм-группу Инфостарт