
Итак, несколько лет назад на собеседовании в одной московской IT-компании в обычном франче я получил тестовое задание. Выполнить его нужно было дома, а результат прислать по электронной почте. Вместе с описанием задания поставлялась и обработка. В одну из процедур этой обработки требовалось ввести свой алгоритм поиска подстроки в строке.
Сначала задание показалось мне простым, но как говорится, есть один нюанс - ограничение по времени выполнения не более 10 секунд.
Решить задание у меня получилось не сразу. Я перебрал несколько вариантов с каждым разом улучшая результат и через некоторое количество часов алгоритм получился быстрый и компактный, что меня полностью и устроило. Примерное общее время выполнения всех тестов, встроенных в обработку, составило 0.14 секунды (замер выполнялся на пустой конфигурации без метаданных).
На текущий момент других вариантов решения этого задания мне найти не удалось, кроме одного обсуждения на форуме инфостарта.
В общем, задание мне понравилось. Возможно, кому-то так же будет интересным решить его, а может и посоревноваться с коллегами, чей алгоритм оптимальнее. Поэтому к публикации прикладываю два файла: обработка для ввода своего алгоритма и обработка с моим вариантом решения.
По итогам собеседования оффер мне предложили, но принимать его конечно же я не стал.
Далее привожу описание задания полностью как есть, без изменений.
Описание задания
В строке символов найти минимальную по длине подстроку, в которой есть все буквы, необходимые для того, чтобы сложить из них слово «счастье».
Если есть несколько вариантов с минимальной длиной, то результатом будет подстрока, расположенная ближе остальных к началу входной строки.
Если из символов входной строки слово «счастье» сложить невозможно, результат должен быть равен «Нет счастья».
На регистр букв (строчные/прописные) внимания не обращать. Т.е. подстрока «Есть час» может быть корректным ответом, несмотря на то, что в этой строке прописная «Е».
Английское «c» (си) и русское «с» (эс) считаются разными буквами. Перевод строки считается одним символом.
Входные данные – строка символов (см. примеры ниже).
Ограничения:
- Длина входной строки <= 10000
- Ограничение по времени (ориентировочное) – 10 секунд.
Пример 1
Входные данные:
Собака бывает кусачей
Только от жизни собачьей
Правильный ответ:
сачей
Только от жизни с
Объяснение: из всех подстрок, имеющих как минимум 2 буквы «с», и как минимум по одной букв «ч», «а», «е», «т» и «ь», эта имеет минимальную длину.
Пример 2
Входные данные:
Всё упало, всё пропало
Правильный ответ:
Нет счастья
Объяснение: во входной строке для счастья не хватает букв «е», «т», «ь» и «ч».
Другие примеры
Всего в обработку встроено 8 примеров.
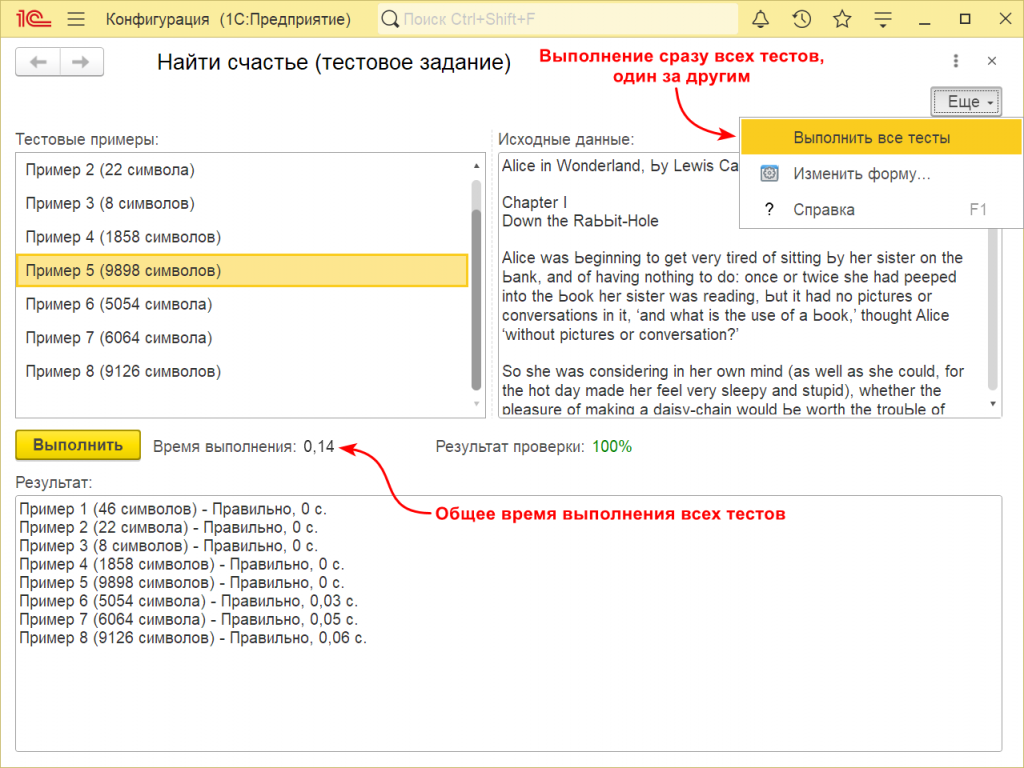
Если решение проходит все тесты, то 5 баллов. Если проходит все тесты со строками длиной < 2000, то 4 балла, если проходит все тесты со строками длиной < 1000, то 3 балла.
Куда вписать алгоритм
Алгоритм вписать в заранее созданную функцию «НайтиСчастье» (расположена в самом начале модуля формы обработки):

Рекомендации проверяющему
- Проверять на любой файловой базе (чтобы легко снять задачу в случае зависания), работающей под управляемыми формами.
- Не ограничиваться формальным фактом прохождения тестов, смотреть код.
- Плагиат, подгонка ответов под примеры и любая другая форма читерства – без разговоров 0 баллов.
Вступайте в нашу телеграмм-группу Инфостарт