Общая информация
Ollama - это платформа с открытым исходным кодом, разработанная для облегчения развертывания больших языковых моделей (LLM) в локальных средах. Она направлена на упрощение сложностей, связанных с запуском этих моделей и управлением ими, обеспечивая беспрепятственный доступ пользователей к различным операционным системам. Т.е. буквально любой на своём домашнем компьютере может использовать большую языковую модель. Характеристики моего ноута я описывал тут, мне писали, что даже для EDT слабоват, но небольшую LLM запустить получилось.
Моё личное знакомство с LLM и их возможностями началось с приложения Alpaca под Linux с FlatHub, там настолько просто, что и писать нечего. Выбрал модель, загрузил, начал пользоваться.
Alpaca - это графический интерфейс, построенный на платформе Ollama, что делает использование LLM доступным даже для пользователей без опыта работы в командной строке. Без Alpaca работа с Ollama осуществляется в командной строке.
Установка и настройка
Буду описывать установку для Linux, у кого Windows, сами разберётесь, у вас проще. Ollama ставится скриптом, он там прямо на главной странице написан.
Конфигурирование службы осуществляется через редактирование unit-файла /etc/systemd/system/ollama.service, описание убрал под спойлер
Перезапускаем службу заходим браузером на http://localhost:11434, видим фразу "Ollama is running" и радуемся. Но не долго. Конкретно для Alt Linux я не нашёл готовых приложений, которые умеют работать с сервером Ollama через API. Сразу скажу искал плохо, т.к. всё равно нужно писать своё.
Загрузка моделей
Дальше идём на сайт проекта, в раздел Models, видим там большой список, отсортированный по популярности, начать можно с модели llama3.1:8b, она маленькая и быстрая. Даём в консоли команду
ollama pull llama3.1:8b
и пока загружается, смотрим список моделей и читаем про них... По каждой популярной модели есть обзоры на русском языке, там описаны параметры и под какие задачи обучалась.
После окончания загрузки даём команду
ollama run llama3.1:8b
и погружаемся в мир генеративного ИИ. Можно прямо в консоли начинать общение.
Аппаратные требования
Вся модель должна поместиться в память, поэтому смотрим размер модели и соизмеряем возможности. Например llama3.1:8b занимает 4.7 Гб и должна поместиться в память почти любого современного компа. Соответственно смотрим на реально большие модели с 405 млрд. параметров, которые весят > 200 Гб и копим деньги...
Но не только память нужна для работы генеративного ИИ, но и ядра, желательно графические и чем больше, тем лучше. Но для маленьких моделей и 8 ядер обычного ноутбука хватит попробовать.
Аппаратные возможности
Имеем довольно бюджетный сервер на двух Intel Xeon 2200, 12 ядер, 24 потока в каждом и память 512 Гб. Все эксперименты будем делать на виртуалке с 16 ядрами, 256 Гб оперативки, ОС Astra Linux 1.8 Orel.
Описание API
Официальная документация API доступна на сайте и достаточно проста для понимания. В ней описаны два основных режима работы с моделями: генерация и чат.
В режиме генерации клиент отправляет на сервер Ollama имя модели и промпт. Ответ может поступать частями, имитируя набор текста, или возвращаться целиком. Также в этом режиме можно передать на сервер массив изображений в формате Base64 для анализа мультимодальными моделями, например llava.
В режиме чата вместо промпта используется массив сообщений с указанием роли отправителя (user – пользователь, assistant – ИИ). Контекст диалога сохраняется за счет постоянной передачи истории сообщений между клиентом и сервером.
Общий модуль расширения включает функции для получения списка доступных моделей, работы в режимах генерации и чата, а также процедуру загрузки модели в память (например, перед началом рабочего дня). Загрузка модели llama3.1:405b с медленных дисков может занимать около 20 минут. Расширение также включает обработки, позволяющие непосредственно выбрать модель и начать с ней работу.
Для чего всё это нужно?
А это очень не простой вопрос. Сейчас генеративный ИИ очень популярен, но в основном, как маркетинговая замануха. Я не смог найти в Инете статьи, где показали бы конкретный кейс, как ИИ смог ускорить какой-нибудь бизнес-процесс.
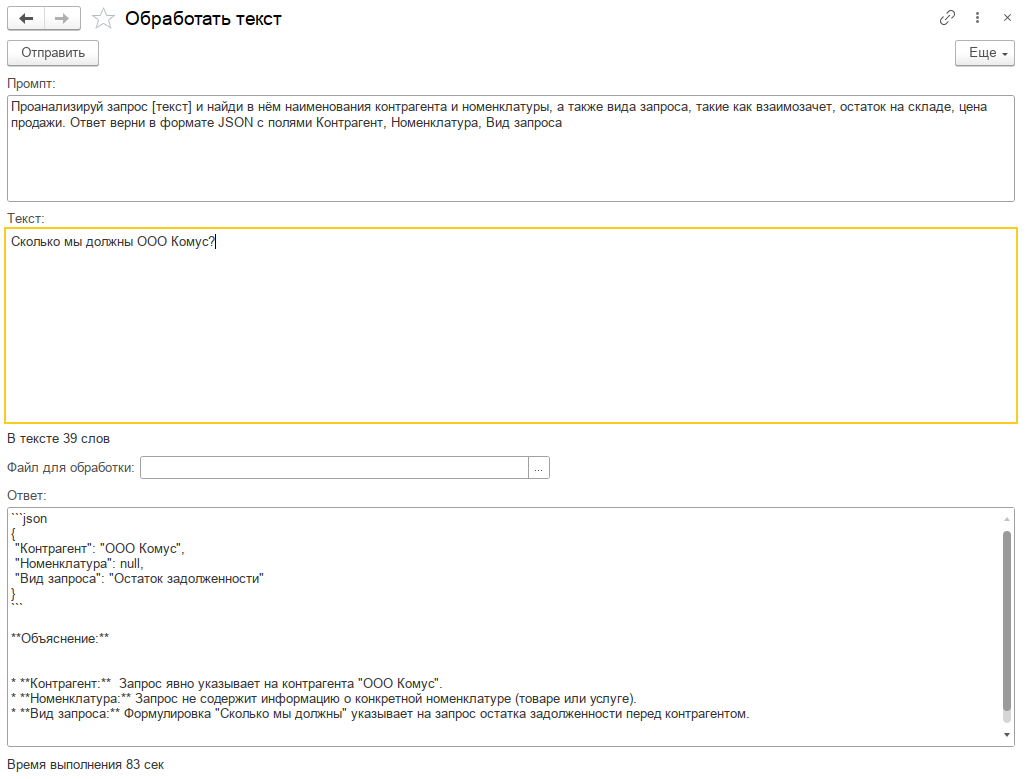
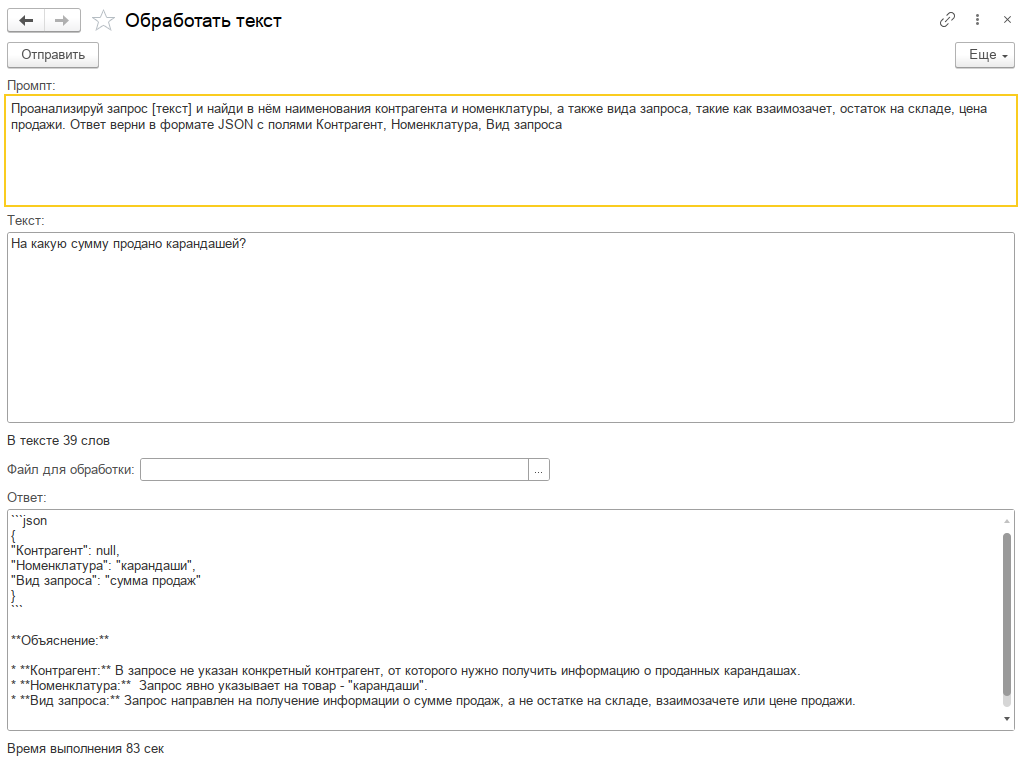
Предлагаю пофантазировать на эту тему. Предположим у нас организация, в которой установлен 1С:Документооборот. Входящая электронная корреспонденция приходит в виде сканов в формате PDF (в основном), бумажная сканируется. Поле краткое содержание в карточке документа никто не заполняет. А было бы удобно, открываешь карточку и через 10 сек. понятно о чём документ. Пусть его заполняет ИИ. Сначала документ нужно распознать, для этого можно воспользоваться приложением OCR Cuneiform, а можно взять более прогрессивную OCR Tesseract (тут). А потом сверху (или снизу) к текстовому образу при писать фразу «Сформулируй краткое содержание текста» и... примерно через минуту у нас будет вполне корректный ответ.
Не будем себя ограничивать и попросим ИИ подготовить данные для заполнения задач в процессе «Рассмотрение», обычно оно заполняется по резолюции начальника, но можно и помощь ему с правильным решением. Сверху к текстовому образу припишем «Подготовь список задач для исполнителей по документу, ответ в формате JSON». И мы получим JSON со списком задач. Нет, мы получим хрень.
А ещё представьте комплексный процесс, в котором есть такая задача «Подготовить положительный ответ», т.е. какой-то запрос прошёл все согласования и нужно просто ответить «Да». Можно у этой задачи сделать вспомогательный предмет в виде текстового файла, содержимое которого сгенерировать следующим промптом: «Подготовь положительный ответ по документу в деловом стиле».
Выбор модели и подбор промптов
А какая модель самая лучшая и подходит именно для вашего бизнеса? Как формулировка промпта влияет на конечный результат? На эти вопросы ответить сложно, нужно вручную готовить запросы к ИИ, потом анализировать ответы, сводить в таблицу... А вот если бы такая таблица сама заполнилась!
В расширении есть специальная обработка, которая на вход получает каталог с образцами текстовых файлов, список моделей и список управляющих промптов, потом долго думает и возвращает большую таблицу с ответами всех моделей по всем текстам и промптам, и с замерами времени.
Поделюсь своими результатами:
- обработка текстов большими моделями, такими, как mistral-large:123b и llama3.1:405b занимает более 20 минут, что неприемлемо;
- модели mistral-nemo:12b и phi3:14b плохо работают с русским языком;
- очень порадовали результатом llama3.1:70b и gemma2:27b, причём вторая по качеству не сильно хуже первой не смотря на разницу в параметрах, модели думают долго (120 – 800 секунд), но для фоновой обработки сгодится;
- ну и для для чата подойдут llama3.1:8b и gemma2:9b не очень умные, но быстрые, обычно отвечают от 25 секунд до 1,5 минут (llama3.1:8b иногда использует английские слова, а gemma2:9b везде суёт эмодзи);
- модель для обработки изображений (llava:7b) не хочет отвечать на русском, но её ответ можно перевести с помощью другой модели.

Общие впечатления
Чувства смешанные. С одной стороны ощущается вкус новых технологий, с другой не понятно, как им пользоваться.
Всю мощь новых технологий можно ощутить только если есть могучий видеоускоритель, но и на среднем уровне можно работать.
Есть ощущение, что всё дело в правильных промптах, на эти мысли навёл ответ ChatGPT, уж он то должен знать
Вопрос был такой: «Представь, что есть организация и в неё пришло письмо, помоги составить промпт который по тексту письма сформулирует задачу, которую необходимо решить» ответ был такой

Я попробовал этот совет и получил более развёрнутый ответ, чем раньше. Пойду думать, спасибо за внимание.
В расширении используется функционал длительных операций БСП 3.1
UPD 29.11.2024. Тут МТС выкатила в свободный доступ модель MTSAIR, сделанную на основе Qwen 2. Она быстрая и достаточно умная, можно использовать для чата. Это очень просто. Сайт huggongface.co умеет отдавать модели на сервер Ollama. Заходим на страницу модели MTSAIR/Cotype-Nano-GGUF, нажимаем справа вверху кнопку "Use this model", выбираем Ollama и получаем код для запуска на своём сервере. Если просто скачиваем, а не запускаем, то команду run меняем на pull
ollama pull hf.co/MTSAIR/Cotype-Nano-GGUF
Проверено на следующих конфигурациях и релизах:
- 1С:Библиотека стандартных подсистем, редакция 3.1, релизы 3.1.10.295
Вступайте в нашу телеграмм-группу Инфостарт