Меня зовут Елена Загибалова, я специалист по развитию инноваций в компании Programming Store. Хочу поделиться нашим опытом работы с внутренними инструкциями предприятия с помощью виртуального помощника сотрудника на базе технологии ChatGPT.
Я расскажу:
-
Какие технологии мы рассматривали при реализации виртуального помощника, и почему выбрали именно ChatGPT.
-
Как работает дообученный ChatGPT, и что представляет собой сама технология дообучения.
-
Какие мы обнаружили плюсы и минусы, а также наши выводы после использования помощника.
Предпосылки и цели проекта

Когда мы начинали проект, на предприятии наблюдались следующие проблемы:
-
Инструкции компании хранились в разных местах. Что-то было в локальных каталогах, что-то – на сервере, что-то – на Google-диске.
-
Все это затрудняло поиск необходимой информации.
-
Специалистам бухгалтерии постоянно задавали одни и те же вопросы: «Я уезжаю в командировку, какие документы мне необходимо оформить?» Постоянно отвлекали.
Мы хотели реализовать единое хранилище документов – получить систему, способную отвечать на вопросы пользователей без человека.

На старте проекта в компании было:
-
170 сотрудников.
-
Порядка 10 инструкций, которые являются общими для всех сотрудников компании.
-
20 специализированных инструкций, которые относятся только к работе определенных отделов.
-
Совокупный объем всех инструкций – примерно 300 страниц Word.
-
У сотрудников бухгалтерии в день уходило порядка 30 минут на консультирование по обращениям пользователей. Причем во время внедрения кадрового ЭДО это время порой даже увеличивалось. Кто внедрял, те знают – там на первом этапе очень много вопросов.

Какие у нас были ожидания от проекта:
-
Мы хотели протестировать систему «быстро и дешево».
-
Инструкции у нас уже написаны – мы не хотели больше их редактировать.
-
Система должна быть простой и удобной, иначе мы просто не будем ей пользоваться.
-
Приоритет отдавался решениям на базе ИИ, потому что это направление для нас интересно, мы считаем его перспективным.
Рассматриваемые решения

В первую очередь мы рассматривали специализированные решения для управления базами знаний компаний. Часть логотипов вы видите на слайде. Мы рассматривали не только эти решения, но и другие.
В теории это специализированные решения, которые должны закрывать задачу, но на практике оказалось, что они нам не подходят:
-
Первое «но», с которым мы столкнулись – это их стоимость. В среднем стоимость подобных решений составляет 1000 рублей за одного пользователя в месяц. Напомню, у нас 170 человек, значит, решение будет стоить 170 тысяч в месяц. Для «быстро и дешево» это не очень подходит (прим. ред. доклад от 11 октября 2023 года).
-
Второе «но», в которым мы столкнулись: часть из этих решений требует размещения инструкций на своей платформе. Это означает, что инструкции нужно будет туда загружать, а потом дополнительно корректировать – получается, что для работы с этими платформами нам необходимо будет иметь еще и администратора. Опять же, для старта протестировать «быстро и дешево» – это не совсем удобно. Поэтому эти мы решения рассматривать не стали.

Далее мы рассмотрели решения на базе искусственного интеллекта (прим. ред. доклад от 11 октября 2023 года):
-
Microsoft Bing как самостоятельное решение мы не рассматривали, потому что он использует ту же самую технологию, что и ChatGPT.
-
Что касается Yandex и Bard – в теории это вопросно-ответная система, то, что нам необходимо. Но технологий дообучения у этих инструментов нет, дообучить их на своих инструкциях мы бы не смогли.

Следующим мы рассмотрели решение от Сбербанка – RuGPT (прим. ред. доклад от 11 октября 2023 года). У него есть несколько моделей, которые различаются по объему, по мощности и функциональности.
Сначала мы думали, что это решение нам подойдет. Но на практике с ним тоже обнаружились проблемы.
-
Оказалось, что эти модели требуют обучения в формате «вопрос-ответ». Это подойдет для предприятий, у которых есть базы часто задаваемых вопросов и ответов – только так вы сможете дообучить эти модели. У нас же были просто инструкции компании – сплошной текст в Word о том, как сделать то или иное, вопросов и ответов у нас не было.
-
И второй момент – если вы будете рассматривать эти решения, имейте в виду, что они требуют размещения на своих мощностях. Для работы с этими моделями необходим свой сервер с достаточно высокими требованиями к производительности.
Так что в теории эти решения есть, их можно использовать, но для нашей конкретной задачи они оказались неудобны и неприменимы.
В результате мы остановились на технологии ChatGPT, поскольку она закрывает все наши задачи.
Технические решения для проекта
Итак, какие технические решения мы выбрали для себя:
-
Первое – сервер для развертывания программы. Если мы говорим про технологию ChatGPT, то там все вычисления происходят на сервере фирмы OpenAI. Это значит, что у нас нет необходимости держать свой высокопроизводительный сервер, мы вполне можем использовать свой обычный, который у нас уже есть.
-
Инструкции мы будем размещать на Google-диске. Это удобно – 15 гигабайт бесплатно, нам этого хватает.
-
ChatGPT 3.5 Turbo (прим. ред. доклад от 11 октября 2023 года). Почему 3.5, а не 4, расскажу чуть позднее.
-
Интерфейс взаимодействия с пользователями – Telegram. Удобно, всем нравится, нам тоже.
Самый простой способ, чтобы получить доступ:
-
Регистрируемся на сервере OpenAI, получаем ключ для работы с API.
-
OpenAI дает нам 5 бесплатных долларов, которые мы можем впоследствии использовать на всю свою работу (прим. ред. доклад от 11 октября 2023 года).
-
Далее просто пополняем аккаунт.
5 долларов – это достаточно много: нам этих 5 долларов хватило как на этап разработки, так и на этап тестирования и опытной эксплуатации.
Напомню, на специализированные решения для управления базами знаний нужно было тратить 170 тысяч в месяц, а здесь нам на несколько месяцев вместе с разработкой хватило, по сути, 5 долларов. Достаточно выгодно.

Далее необходимо настроить Telegram-бота:
-
Мы регистрируем бота через BotFather.
-
Получаем токен.
-
Важный момент: нам нужно было ограничить бота, чтобы он работал только с сотрудниками нашей компании. В пользовательском интерфейсе такой настройки не предусмотрено, поэтому мы просто доработали это в коде.
Как работает технология ChatGPT
На слайде показан ответ на вопрос «Как работает ChatGPT» по версии самого ChatGPT.
В нашем случае мы будем использовать эту технологию так: пользователь задает вопрос в боте Telegram, а ChatGPT готовит ответ на основании внутренних инструкций предприятия.

Познакомимся с теми понятиями, с которыми нам предстоит иметь дело при работе с ChatGPT.
Для получения корректных ответов по инструкциям нам нужно будет использовать промт – это ситуация и роль, в которую мы помещаем ChatGPT.
В нашем случае мы скажем: «ChatGPT, ты администратор компании, отвечающий на вопросы по инструкциям предприятия. Пожалуйста, используй только эти инструкции и не используй информацию из интернета».
Последнее очень важно, потому что нам нужно, чтобы наш чат-бот при ответе на вопросы использовал только ту информацию, которую мы ему дали, и ни в коем случае не брал что-то первое попавшееся из интернета.
Следующее понятие – контекст. Контекст для ChatGPT – это та информация, которой он обладает до того, как пользователь ему задает вопрос. В нашем случае контекстом будет информация по внутренним инструкциям предприятия.

Следующее понятие – токены. У ChatGPT есть несколько разных моделей, каждая из которых ограничена определенным количеством токенов.
Токен – это внутренняя единица измерения контекста от фирмы OpenAI. Для русского языка один токен можно примерно приравнять к 1-2 символам, английскому языку повезло чуть больше – токеном может являться целое слово. Вся тарификация при использовании ChatGPT будет осуществляться за каждую 1000 токенов.
Ограничение в 4000 токенов (прим. ред. доклад от 11 октября 2023 года) говорит о том, что ChatGPT способен единомоментно запомнить информацию только в этом объеме. 4000 токенов – это примерно полторы страницы Word: шрифт Times New Roman 12.
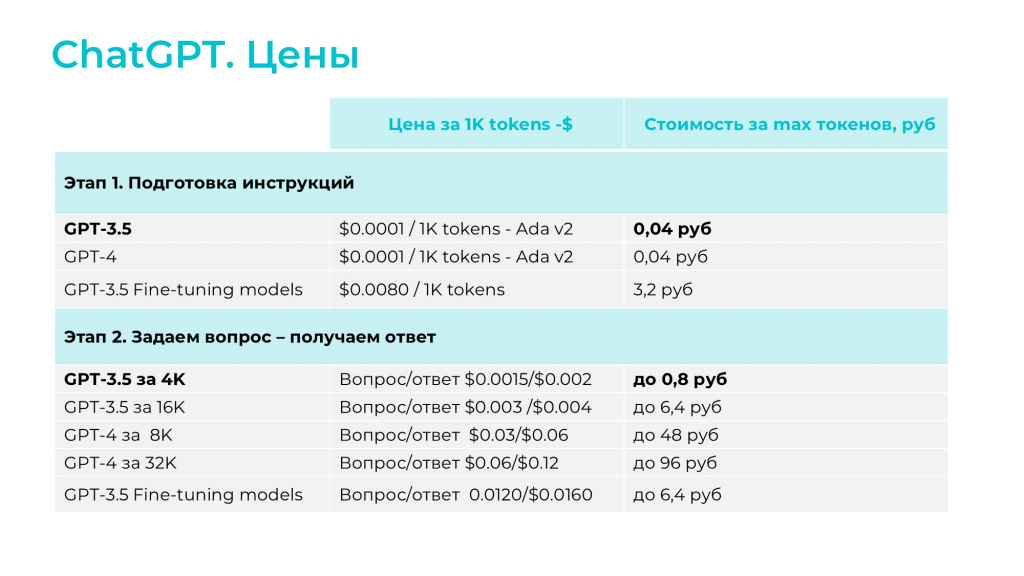
Я обещала рассказать, почему мы используем модель GPT-3.5 (прим. ред. доклад от 11 октября 2023 года).
Все обучение ChatGPT будет состоять из двух этапов:
-
На первом этапе мы будем готовить инструкции в том формате, в котором ChatGPT способен их воспринять.
-
На втором этапе уже будем использовать систему «вопрос-ответ».
Для подготовки инструкций мы будем использовать самую легковесную и дешевую модель Ada. Мы протестировали на своих данных несколько версий и решили, что Ada нам вполне хватает, поэтому будем использовать ее.
Для системы «вопрос-ответ» мы использовали GPT-3.5 и GPT-4. Причем наш Telegram-бот мы настроили только для работы с текстовыми данными – на тестовом периоде мы не использовали картинки. Возможно, мы реализуем работы с картинками позднее, но пока работаем только с текстовыми данными.
Качество ответов GPT-3.5 нас вполне устроило – нет необходимости переплачивать за GPT-4. И объема в 4000 токенов нам для решения нашей задачи тоже хватило – больше нам не надо, это будет просто переплата (прим. ред. доклад от 11 октября 2023 года). Именно из-за того, что нас устроили самые дешевые модели, нам и хватило 5 долларов, которые выдаются на тестовый период. Если вы будете выбирать более дорогие модели, имейте в виду, что тарификация будет выше.
Есть еще один момент – у GPT есть Fine-tuning models. Эти модели обучаются примерно по тому же методу, как и решение RuGPT от Сбера – для них требуются данные в формате «вопрос-ответ». Если данные в формате «вопрос-ответ» у вас есть, вы можете дообучить на них такую модель.
Но, во-первых, эти модели, как видите, чуть подороже. Во-вторых, эти модели уже обладают какими-то знаниями, и если мы в них догрузим свои знания по нашим внутренним инструкциям, сможем ли мы их впоследствии отделить? Сможем ли мы сказать этой дообученной модели, чтобы она использовала только наши данные? Это вопрос. Мы эти модели не использовали, поэтому у нас ответа нет, но если вы будете использовать, обязательно разберитесь.
Технология работы виртуального помощника ChatGPT
Далее подробно расскажу, как выглядит технология дообучения.
Дообучать будем на примере инструкции, которая, условно, занимает объем в 4500 токенов.

Инструкция состоит из четырех условных смысловых блоков:
-
Первый блок – это абзац «Человеку нужно завести кота».
-
Второй блок – инструкция по взаимодействию.

-
Третий блок – это «Если ты не фанат котов, то заводи капибару!»
-
Четвертый блок – «Но если ты все же хочешь кота».
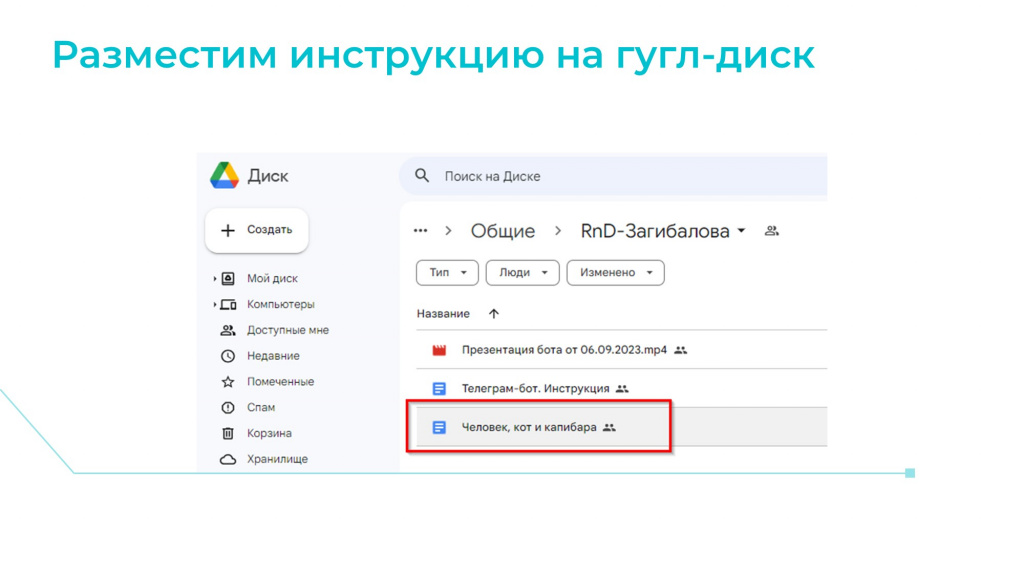
Мы решили, что все написанные инструкции мы будем размещать на Google-диске.
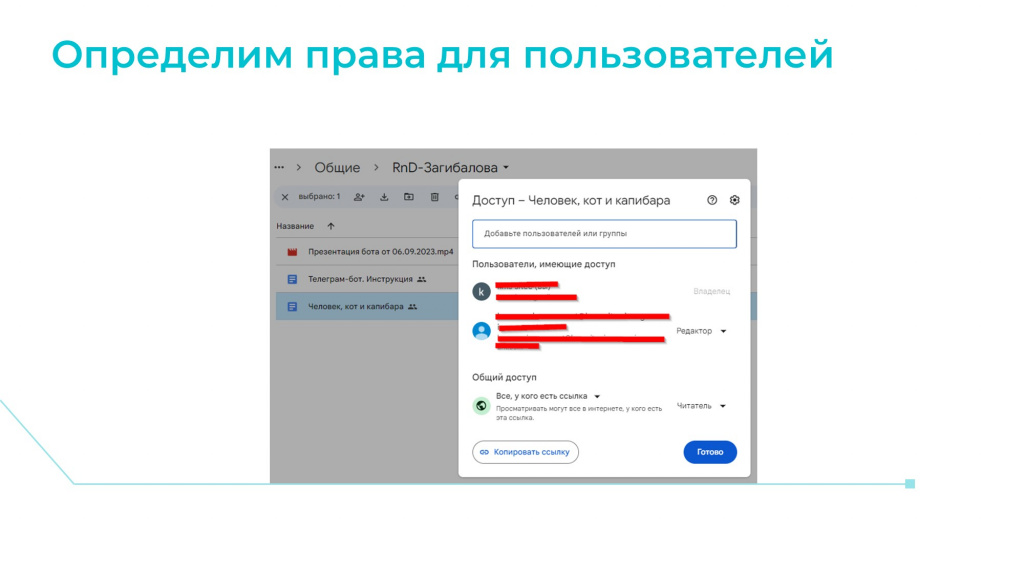
Когда инструкция размещена, выдаем всем пользователям компании необходимые права на доступ к этому документу. Это нужно, потому что мы будем использовать наш чат-бот следующим образом: когда пользователь будет задавать вопрос, он будет получать ответ от ChatGPT плюс ссылку на документ, из которого этот ответ получен.
Это очень удобно и очень важно. Поэтому все документы должны быть расшарены либо на чтение, либо на редактирование – в зависимости от того, какие права будут у пользователя.

Инструкцию нам необходимо механически разделить на определенные блоки.
Это важно, потому что мы выбрали модель ChatGPT 3.5 на 4000 токенов, а она способна единомоментно запоминать информацию только в 1,5 страницы.
Но как сделать так, чтобы ChatGPT запомнил все наши 300 страниц инструкций и был способен отвечать на вопросы? Правильный ответ – никак. Мы этого делать не будем.
Мы поступим по-другому. Когда пользователь будет задавать вопрос, мы сначала подготовим необходимую информацию – алгоритм подберет наиболее релевантные для ответа блоки и подаст их ChatGPT, чтобы он, используя уже только этот объем информации, подготовил нам необходимый ответ.

В результате наши 4000 токенов будут расходоваться на следующее:
-
На ту информацию, которую мы подадим ChatGPT в виде внутренних инструкций, это условно Блок 1, Блок 2.
-
На промт, который мы передаем в ChatGPT. Напомню, промт – это роль и ситуация: «Ты администратор, отвечай только по переданным инструкциям».
-
И на сам вопрос пользователя, потому что он тоже съедает наши токены.

Итак, для нашей технологии необходимо разделить инструкцию на блоки. Как это сделать? Как нам разделить нашу полуторастраничную инструкцию на определенное количество блоков?
Вариант первый – мы делим информацию по количеству символов. Но тогда может получиться ситуация, как на слайде – в один из блоков информация попадет некорректно, с незаконченным предложением или даже неполным словом.
В результате может нарушиться смысл и смысловые блоки окажутся разбиты – то, что изначально относилось к одному блоку, попадет в разные. И если ChatGPT потом будет использовать эти блоки для ответа, информация будет некорректна. Поэтому этот вариант нам не подходит.

Второй вариант, который мы рассмотрели – это вариант классификации.
Есть специальные библиотеки на Python, которые выполняют задачу классификации текста. Мы можем подать на вход такой библиотеке документ Word на полторы страницы и сказать: «Раздели на три блока по смыслу», она разделит.
Мы протестировали ряд подобных решений, но результат нам не понравился, и мы решили их не использовать.

Третий вариант – если бы у нас инструкции были в формате Markdown, нам было бы проще разбить их на части. Но у нас инструкции писали пользователи, и они делали это так, как им было удобно, поэтому разметки Markdown у нас нет.

Мы разработали свою нейросеть, которая разделяет текст на блоки так, как это сделал бы человек. При этом длина каждого блока будет плавающей – мы накладываем ограничение только на максимальную длину одного блока. Нам это необходимо, чтобы впоследствии ограничить в ChatGPT количество текста, которое мы будем подавать на вход.
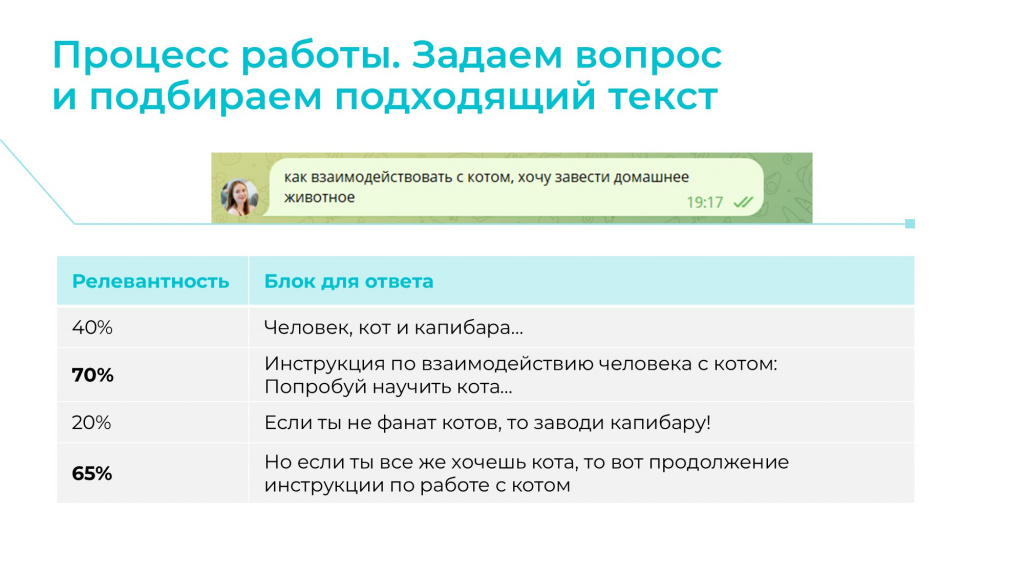
Благодаря этой разбивке при поступлении вопроса от пользователя определенный алгоритм сначала готовит подходящие для ответа блоки и устанавливает для них релевантность – степень, насколько этот блок подойдет для ответа на данный вопрос.
И далее уже ChatGPT использует эту информацию для того, чтобы подготовить ответ.
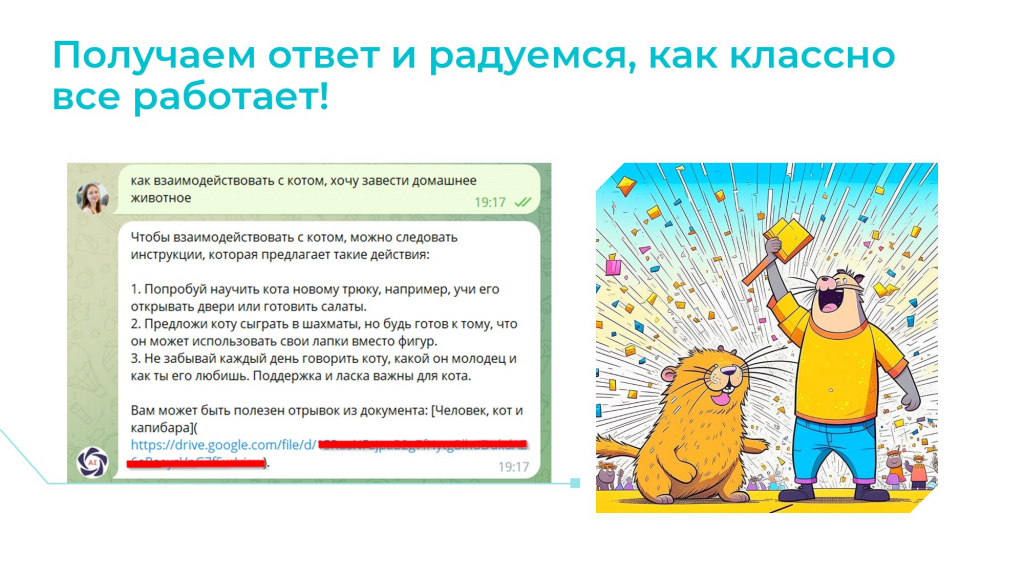
В данном случае:
-
пользователь задал вопрос;
-
алгоритм подготовил для ответа несколько блоков, и передал в ChatGPT два блока с наиболее высоким процентом релевантности;
-
ChatGPT подготовил ответ и предоставил ссылку на документ.
В этом вся суть технологии – это то, что мы хотели получить. И очень круто, что это работает – можно только порадоваться, что современные технологии меняют мир и помогают нам жить лучше.
Но что осталось за кадром? Есть неудачные дубли…

Однако не все оказалось так замечательно, как мы изначально предполагали.
Первое: даже для тестового примера мы получили корректный ответ не с первого раза.
Изначально ChatGPT не понял, какие инструкции ему нужно использовать для ответа на вопрос, и выбрал то, что ему понравилось. Пришлось доуточнить вопрос, чтобы все-таки он выбрал необходимую инструкцию.
Причем так происходило не только с тестовым примером – были и реальные пользовательские вопросы, когда ChatGPT мог взять информацию не из той инструкции. Такое бывает.

Второе, с чем мы столкнулись – путаница с ЭДО и КЭДО.
У нас существовали инструкции как ЭДО – по взаиморасчетам с контрагентами, так и по КЭДО – по работе в Кабинете сотрудника. И когда мы задавали вопрос по КЭДО, система могла подобрать в качестве наиболее подходящих как блоки по КЭДО, так и блоки по ЭДО.
Но ChatGPT почему-то выбирал из этих блоков только информацию по ЭДО. Скорее всего, потому что он обучен на данных до 2021 года и про КЭДО просто меньше слышал. И когда ему дают блоки про КЭДО, он думает: «Скорее всего, КЭДО – это опечатка. Вот ЭДО – это то, что тебе нужно».

Напомню, мы ему говорили: «Пожалуйста, не бери информацию из интернета». В 95% случаев он слушался. Но не всегда.
Видимо искусственный интеллект действует по модели человека: «Да-да, я тебя услышал, а сейчас я решил, что вот так лучше», и поэтому иногда все-таки выдавал информацию из интернета.

И еще один момент – он не особо критичный, но просто позабавил.
Мы поручили ChatGPT при каждом ответе выдавать ссылку на документ. Причем заложили это именно в промт – не стали добавлять ссылку принудительно кодом.
Мы сделали так, потому что заранее не знаем, какие именно блоки будет использовать ChatGPT в ответе. Мы ему при подготовке ответа можем выдать несколько блоков, которые будут относиться к разным документам, а он может взять отсюда одно предложение, а отсюда – другое. Поэтому мы добавляем в промт поручение: «Когда ты будешь отвечать пользователю на вопрос, вышли ему дополнительно ссылку на инструкцию».
В результате, как вы видите на слайде, ChatGPT иногда просто добавлял в ответ: «Вот тебе ссылка», но самой ссылки не давал. Такое случалось редко, но тоже было.

Еще момент: важно учитывать разделение на блоки.
-
Если мы сделаем блоки слишком маленькими, например, токенов по 500, мы получим ситуацию, когда один смысловой блок будет разбит на несколько. И когда потом ChatGPT будет использовать эти блоки для ответа, ответ будет некорректен, потому что некоторые блоки к нему вообще не попадут.
-
И наоборот: если блок будет рассчитан на слишком большое количество токенов мы можем получить ситуацию, когда нужный блок просто не попадет в контекст ChatGPT из-за ограничения по количеству токенов. У одного блока релевантность 90%, у другого 89%, у третьего – 88%. И тот, у которого релевантность 88%, в контекст уже не поместится.
Поэтому размер каждого блока подбирался опытным путем – это важно.

Процент релевантности. Релевантность изначально определяют алгоритмы, которые уже существуют в используемой нами библиотеке, а при подаче информации на вход ChatGPT мы можем управлять порогом релевантности.
-
Но если скажем ему: «Используй для ответов только блоки с релевантностью более 80%», мы можем получить ситуацию, что ответа вообще не будет.
-
И наоборот, если мы скажем: «Используй для ответа блоки с релевантностью больше, чем 20%», информации будет столько, что ChatGPT в ней запутается и выдаст совершенно некорректный ответ.
Поэтому здесь все аналогично: процент релевантности для вашей базы инструкций вычисляется опытным путем.
Распространенная беда – скорость ответа.
Время передачи контекста и дообучения ChatGPT на наших инструкциях обычно занимает 3-8 секунд и иногда даже затягивается до 20 секунд (прим. ред. доклад от 11 октября 2023 года).
Здесь мы ничего сделать не можем, только принять, что это – то время, которое отрабатывают алгоритмы на стороне сервера OpenAI. Можно только надеяться, что у них в дальнейшем все нормализуется – тогда все будет классно.
Какие выводы делаем?

Прежде чем сделать выводы, еще раз вспомним всю технологию:
-
Мы размещаем инструкции на Google-диске и разделяем их на блоки с помощью нейросети, которую разработали сами.
-
Далее эти блоки загружаются в поисковый индекс и переводятся в формат, который уже подойдет для ChatGPT.
-
Когда пользователь задает вопрос, система его обрабатывает и находит наиболее подходящие для ответа блоки, которые будут переданы на контекст ChatGPT.
-
В ChatGPT передается промт, который содержит весь необходимый контекст.
-
И на основании поданного контекста ChatGPT уже готовит ответ.

Плюсы полученного решения:
-
Относительно невысокая стоимость – опять же: 5 долларов за пару месяцев вместо 170 тысяч в месяц.
-
Удобство использования инструмента конечными пользователями. Telegram достаточно удобен и привычен как инструмент взаимодействия с базой знаний, кроме того, он не требует постоянно заходить на сервер, авторизоваться или еще что-то.
-
Удобство наполнения базы знаний инструкциями. Не знаю, как у вас, у нас пользователи очень любят пользоваться Google-диском. Нет ничего проще загрузить туда инструкцию, расшарить и выслать на нее ссылку. А когда необходимо заходить в базу знаний на какой-то своей платформе, это всегда стресс. Поэтому Google-диск любят все.

Минусы:
-
Верные ответы ChatGPT 3.5 дает приблизительно в 70% случаев (прим. ред. доклад от 11 октября 2023 года).
-
Причем ChatGPT 4 даст предположительно такую же точность. У нас вся фишка в том, что мы ChatGPT фактически не дообучаем, мы готовим ему информацию заранее и подаем ее в качестве контекста – вся подготовка происходит предварительно, и ChatGPT уже просто использует отобранную информацию. В результате ответ зависит от того, какая информация будет подана в контекст ChatGPT, и насколько эти инструкции будут непротиворечивыми. Плюс мы зависим от того, насколько эти инструкции качественно написаны. Некоторые инструкции читаешь – их и человек не поймет, а чего уж ожидать от искусственного интеллекта. Поэтому здесь неважно, какая используется модель – ChatGPT 3.5 или ChatGPT 4.
-
В теории Fine-tuning модели могут дать лучшую точность. Напомню, Fine-tuning модели – это те, которые обучаются в формате «вопрос-ответ», но они требуют специальной подготовки данных. Они всегда дороже в сотни или даже тысячи раз. И эти модели нужно заранее дообучать – а время обучения может измеряться минутами, часами, днями и даже неделями.
-
Ответы ChatGPT могут быть неполными, но в нашем случае мы спасаемся тем, что выдаем ссылку на исходный документ.
-
Ответы готовятся долго (прим. ред. доклад от 11 октября 2023 года) – напомню, это 3-8 секунд, и мы с этим смирились.
-
Технологии часто меняются. Когда мы разрабатывали нашу систему, мы делали ее на версии ChatGPT 3. И когда в процессе разработки вышло 3.5, нам для обновления оказалось достаточно поменять всего одну строчку кода – 5 секунд и все заработало. Но кроме ChatGPT мы использовали и другие библиотеки, а там при обновлении сломалось все. Мы переписывались с разработчиками, они что-то исправляли, мы это тестировали. В какой-то момент мы уже от всего этого устали и просто откатились к предыдущей версии, потому что разработчики так и не поправили ошибки. Поэтому имейте в виду, что такое есть – наверное, многие из вас встречались.
-
Сервисы OpenAI недоступны в России. Мы об этом помним. Не буду рассказывать, как сделать так, чтобы они были доступны.
-
Человеческий фактор. У нас была задача – организовывать систему для базы знаний, а это не только техническая часть с интерфейсом взаимодействия, но и люди, которые эту базу знаний наполняют и ею пользуются. И если в результате окажется, что ни один человек в такую систему инструкции не загружает и вопросы не задает, то что-то идет не так. Такие моменты тоже необходимо учитывать и до старта проекта регулярно общаться с пользователями – объяснять им ценность того дара, который у них появится, доносить информацию, почему им станет легче, и какое светлое будущее их вообще ожидает.
Как применять ChatGPT?

-
Дообученный через контекст ChatGPT имеет смысл использовать в следующих случаях:
-
Как инструмент для работы с внутренними инструкциями – правда он подойдет не всем, и его результат будет сильно зависеть от инструкций, которые есть на предприятии. Но в целом использовать ChatGPT для этой цели возможно, нужно просто тестировать и смотреть, как получается – устраивает результат, не устраивает, насколько хорошо, насколько плохо.
-
Как помощника в создании контента для маркетинговых задач. Например, ему можно сказать: «ChatGPT, наше предприятие оказывает вот такие услуги, помоги подготовить информацию для такого-то мероприятия. На мероприятии мы будем делать вот это, это и это. Наша целевая аудитория такая-то и такая-то». В результате он может подготовить для вас нужный контент. Это достаточно удобно. Конечно, подготовленную информацию необходимо будет проверять, корректировать, тем не менее она уже есть, и это достаточно удобно.
-
Как помощника в создании контента для HR-задач. Например, у нас есть описание вакансий, мы передаем эти требования ChatGPT и говорим: «Подготовь описание сочно, классно, так, чтобы потенциально разработчику оно понравилось». И ChatGPT перепишет контент таким образом, как посчитает необходимым. Тоже достаточно удобно и особенно полезно для вдохновения, потому что ChatGPT даст какие-то интересные идеи, решения, которые вы потом сможете использовать.
-
-
Мы не рискнем использовать дообученный через контекст ChatGPT для работы с клиентами, потому что ошибки встречаются достаточно часто. Мы ценим наших клиентов, ценим их время, и не будем отпускать к ним на работу виртуального менеджера по продажам.
-
Базовая функциональность ChatGPT без дообучения достаточно удобно использовать в задачах на разработку – например, он вполне подходит в качестве помощника разработчика на Python.
Сейчас новые решения в сфере ИИ появляются ежедневно, и очень классно, что мы с вами живем в такое время, когда можем их использовать.
Это невероятно интересное событие, поэтому открывайте новое, творите и радуйтесь жизни!
P.S. в презентации использовались изображения из паблика https://vk.com/yesbut
Вопросы и ответы
Как вы решали вопрос с безопасностью? Вы говорили, что заложили ограничение в коде на то, что этим инструментом могут пользоваться только сотрудники компании. А как-то технически это решалось дополнительно?
Кроме доработок в коде и расшаривания доступа к документам на самом Google-диске, никаких дополнительных настроек с точки зрения безопасности мы не делали.
Но и инструкции, которые мы использовали, не содержат каких-то персональных данных, не содержат логинов, паролей на сервер и так далее. Там этого нет.
Если ChatGPT станет недоступен тем способом, который вы используете, есть ли у вас какой-то запасной план? И сохраняете ли вы, например, существующие боевые вопросы-ответы для того, чтобы можно было на них уже обучать, например, сберовскую модель?
Запасной план – как раз сберовская модель. Например, GigaChat от Сбера работает по такой же модели, как и ChatGPT. Единственный недостаток – сейчас (прим. ред. доклад от 11 октября 2023 года) у GigaChat сейчас ограничение контекста – 2000 токенов. Для наших инструкций этого маловато. Было бы лучше, если бы они сняли это ограничение. Но попробовать перейти на GigaChat можно. Поэтому запасной вариант – мы немного поменяем код в системе и перейдем на GigaChat.
Вы рассказали о том, что сделали свою нейросеть, которая разбила вашу документацию на блоки. Сколько времени у вас на это ушло и, главное, на чем вы ее обучали?
Свою нейросеть мы обучали на внутренних инструкциях нашего предприятия – готовили данные, разделяли их на блоки и так далее.
Это у нас заработала у нас достаточно быстро, потому что не самая сложная нейросеть – она даже не потребовала обучения на GPU.
А что она дает на выходе? Просто блоки инструкций, разбитые по вопросам?
Да, результатом работы этой нейросети будет просто текст, разбитый на блоки.
Вы пробовали использовать LangChain или другие подобные инструменты для индексирования?
Мы изначально рассматривали LangChain, но потом решили использовать для индексирования напрямую Chroma или Chroma DB, потому что не нашли, как сделать для LangChain так, чтобы после редактирования документа обновился не весь поисковый индекс со всеми 500 документами, а только один маленький отредактированный кусочек.
В Chroma DB такой механизм был, поэтому мы вместо LangChain использовали Chroma DB напрямую. Т.е. если пользователи отредактировали какое-нибудь слово или добавили что-то на Google-диск, поисковый индекс обновляется, и в ChatGPT передается его новая версия.
И как часто вы обновляете индексы? И где они у вас хранятся?
У наших внутренних инструкций скорость изменения не такая частая, поэтому обновления индекса раз в 5 минут нам было вполне достаточно. А индексы у нас хранятся на сервере.
Но ведь документация в Google-диске? Получается, что вы с ваших внутренних серверов ходите на Google-диск, собираете информацию, у себя индексируете, и индексы храните тоже у себя?
Да. Для тестового варианта сделали так. Изначально пробовали их хранить там же на Google-диске, но это было долго.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT.

Вступайте в нашу телеграмм-группу Инфостарт