

Для работы вам понадобится Библиотека искусственного интеллекта для 1С. Она распространяется бесплатно и вы можете использовать ее для создания своих коммерческих продуктов.
Когда клиенты заводят разговор о RAG, довольно часто приходится слышать об "обучении нейросетей". Дескать, давайте обучим нейросеть нашими данными с помощью RAG. Строго говоря, это неправильно. Обучение нейросетей, это отдельная сложная тема, а с RAG все несколько проще.
Представим, что мы хотим давать ответы на вопросы клиентов, задействовав для этого искусственный интеллект. Мы берем большую и умную нейросеть. Ее уже обучили всему, чему надо и она может поддерживать непринужденный разговор. Но вот конкретно про нас она не знает ничего, или почти ничего. Клиент приходит с простым вопросом: какой у вас график работы? Нам нужно сделать что-то, чтобы нейросеть смогла ответить на него. Для этого ее не надо обучать. Можно поступить проще. Добавить ответ в вопрос. Это и будет тем самым augment, т.е. расширением.
Вопрос клиента:
Какой у вас график работы?
Наше расширение:
Мы работаем по будням, с 9:00 до 18:00
Что получает на вход нейросеть:
Мы работаем по будням, с 9:00 до 18:00 Какой у вас график работы?
Понятно, что получив такой вопрос, нейросеть даст на него верный ответ. Разумеется, мы не станем ограничивать себя ответом на один-единственный вопрос. В наше расширение мы загрузим вообще все, что посчитаем нужным так или иначе сообщать клиенту: перечень товаров и услуг, порядок работы, инструкции и т.д.
Здесь и проявляется сила нейросети. Она без проблем найдет в этой массе информации именно то, что нужно для ответа на конкретный вопрос. Но есть одна техническая сложность. Размер этой самой "массы" сильно ограничен.
Во-первых, есть размер контекста. У разных моделей он разный. У gpt-4o от OpenAI это 128К токенов. У Claude Sonnet 3.7 от Anthropic 200K. У Gemini 2.5 pro от Google 1 миллион токенов и обещают 2 вскорости. Миллион токенов, это достаточно много. Практически "Война и мир" (на английском языке около 700К токенов). Но существует мнение, что с увеличением контекста качество ответов падает. Так что, миллион токенов, это только в теории. На практике и 32К уже многовато. Потому еще, что во-вторых, есть плата за входящие токены. У gpt-4o сейчас 2.5$ за миллион токенов, у Sonnet 3.7 это 3$. Платить по 10 рублей за каждую реплику в диалоге с клиентом может оказаться накладным.
И вот тут возникает идея подмешивать в запрос пользователя не все-все-все, а только то, что имеет отношение к этому запросу. Как определить, что имеет отношение к запросу пользователя? И тут на помощь приходит нейросеть. Она умеет превращать текст в вектор (embedding). Вектор, это много чисел, например 512. А по сути, точка в 512-мерном пространстве. Теперь мы можем разделить наш большой текст, в котором все-все-все, на маленькие части. Для каждой части получим вектор или точку в 512-мерном пространстве. Далее, получив от пользователя запрос, мы и для него рассчитаем точку и определим к какой из ранее рассчитанных точек она ближе всего. Так мы получим ту самую часть большого текста, которую надо добавить в запрос.
Конечно, трудно себе представить 512-мерное пространство, но работает это прекрасно. А еще более прекрасно то, что в Response API от OpenAI (как и в скоропостижно устаревшем Assistant API) вся эта сложная работа с векторной базой скрыта "под капотом". Вы создаете векторную базу одной простой командой, загружаете туда файл или файлы (это не важно, все равно все будет порезано на кусочки неким оптимальным способом). И все готово к работе. Все что нам нужно для того, чтобы заработало "подмешивание", это указать id векторной базы в специально выделенной для этого опции.
В библиотеке искусственного интеллекта для 1С, начиная с версии 19, появились функции: СоздатьВекторнуюБазу(), ЗагрузитьФайл(), РазместитьФайл()
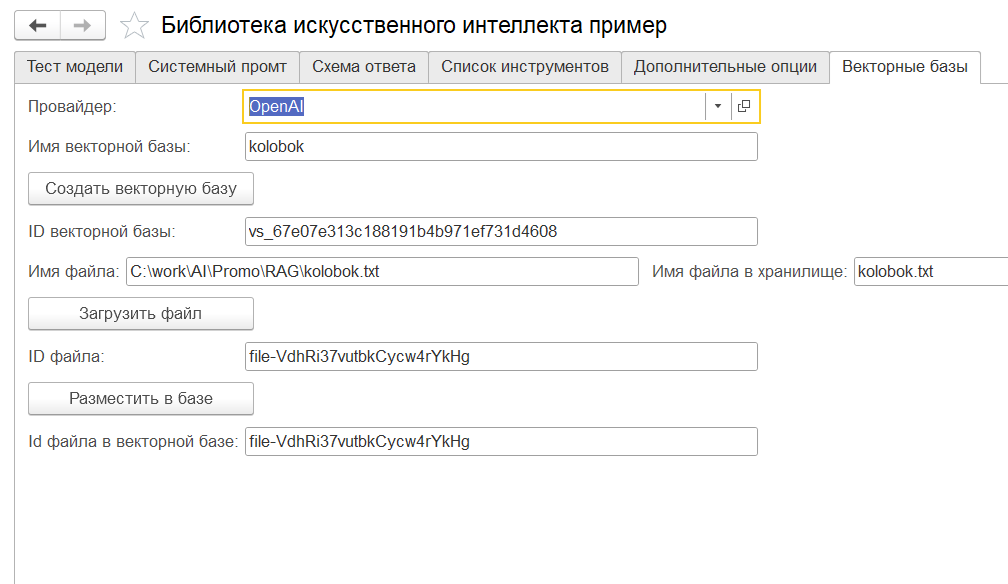
В результате мы получаем подготовленную векторную базу с неким id. Этот id мы передаем в опции "vector_store_id" и получаем RAG.
Вы можете самостоятельно поэкспериментировать с этим, пользуясь обработкой БИИ_Пример, которая входит в состав библиотеки.
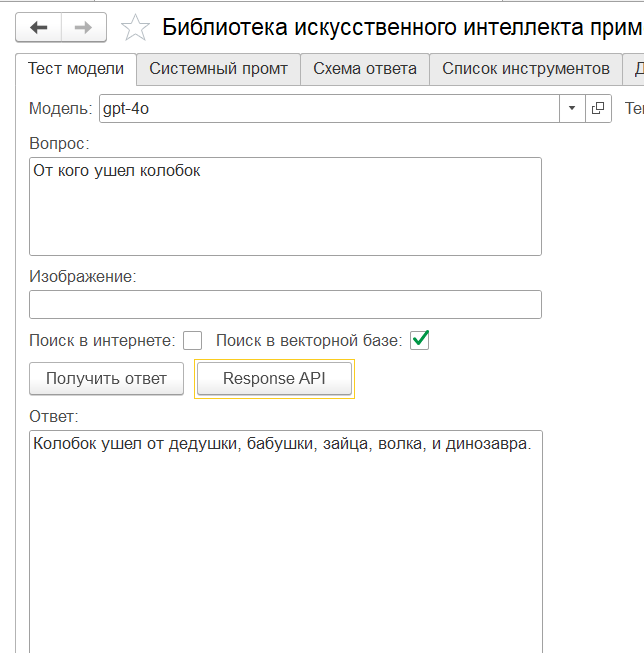
Файл kolobok.txt, на котором экспериментировал я, прилагаю.
Как видите, RAG относительно простая вещь. А с библиотекой искусственного интеллекта для 1С это становится просто, как раз-два-три.
Вступайте в нашу телеграмм-группу Инфостарт