

{kind=link}
Целевая аудитория:
- Разработчики 1С, интересующиеся машинным обучением и алгоритмами оптимизации.
- Специалисты по логистике и управлению складом, ищущие способы автоматизации планирования маршрутов.
Q-learning — это алгоритм обучения с подкреплением, который позволяет компьютеру находить оптимальные решения в сложных ситуациях, просто “играя” и учась на своих ошибках. Представьте себе, как вы учитесь водить машину: вы не знаете заранее идеального маршрута, но пробуете разные дороги, анализируете результаты и постепенно выбираете лучший путь. Q-learning делает то же самое, но для компьютерных задач.
В 1С, платформе для автоматизации бизнеса, Q-learning можно использовать для оптимизации различных процессов. Например, для автоматического построения маршрутов доставки, чтобы курьеры тратили меньше времени в пути и успевали сделать больше заказов. Или для управления складской техникой, чтобы погрузчики быстрее находили нужные товары и перемещали их по складу. Или для планирования работы персонала.
В отличие от других алгоритмов поиска маршрутов, таких как A* или Dijkstra, Q-learning не требует заранее знать всю информацию о среде. Он исследует ее методом проб и ошибок, адаптируясь к изменяющимся условиям. Это делает его особенно полезным в ситуациях, когда информация неполная или постоянно меняется, например, при изменении дорожной обстановки или появлении новых заказов. Q-learning создает не просто один маршрут, а целую стратегию, показывающую лучшее действие в любой ситуации.
Отличия Q-learning от других алгоритмов поиска маршрутов
Отличие Q-learning от других алгоритмов, таких как A* или Dijkstra, заключается в фундаментально разных подходах к решению задачи поиска маршрута.
-
A и Dijkstra:* Это классические алгоритмы, работающие на основе заранее известной карты (графа). Они требуют, чтобы были известны все узлы (точки на карте), ребра (соединения между точками) и веса (стоимость проезда по ребру). Они находят оптимальный маршрут, просматривая все возможные пути, пока не найдут самый короткий или самый дешевый. Это эффективный подход, если карта статична и известна.
-
Q-learning: Это алгоритм обучения с подкреплением. Ему не нужна полная карта. Вместо этого Q-learning учится, взаимодействуя со средой (лабиринтом, дорожной сетью, складом). Он пробует разные действия (двигаться в разных направлениях), получает “награды” (положительные или отрицательные) и на основе этих наград строит Q-таблицу. Q-таблица показывает “ценность” каждого действия в каждой точке. Со временем Q-learning “выучивает” оптимальную стратегию поведения, даже если изначально не знал карты.
Основные отличия:
- Необходимость модели среды: A* и Dijkstra требуют полной модели среды (знания всех элементов графа). Q-learning этого не требует, он учится непосредственно из опыта.
- Адаптивность: Q-learning лучше адаптируется к изменяющимся условиям (например, к пробкам на дороге или изменению планировки склада), так как может переобучаться на ходу. A* и Dijkstra требуют пересчета маршрута при изменении графа.
- Стратегия vs. Одиночный путь: A* и Dijkstra обычно находят один оптимальный путь. Q-learning формирует общую стратегию, определяющую наилучшие действия в каждой ситуации (Q-таблица).
Как мы уже говорили, Q-learning может быть полезен в различных задачах 1С, требующих адаптивного планирования маршрутов:
- Оптимизация маршрутов доставки: Алгоритм может учитывать текущую дорожную обстановку, количество заказов и другие факторы.
- Управление складской техникой: Погрузчики могут оптимизировать свои маршруты по складу, учитывая текущую загрузку, местоположение товаров и другие факторы.
- Планирование работы персонала: Алгоритм может помочь распределить задачи между сотрудниками, учитывая их специализацию, доступность и приоритеты.
Математическая основа Q-learning
В основе Q-learning лежит простая, но мощная идея: оценка качества (Q-value) каждого действия в каждом состоянии. Алгоритм стремится найти оптимальную стратегию, максимизирующую общую награду.
- Основные понятия:
- Состояние (State, s): В нашем примере - это текущая вершина графа (A, B, C, D, E, F).
- Действие (Action, a): Переход из текущей вершины в соседнюю (например, из A в B).
- Награда (Reward, r): Числовое значение, отражающее полезность совершенного действия. В нашем случае это отрицательная стоимость перехода (чем меньше стоимость, тем больше награда, так как мы стремимся минимизировать затраты).
- Q-значение (Q-value, Q(s, a)): Оценка качества действия a в состоянии s. Отражает, насколько выгодно совершить это действие, учитывая возможные будущие награды.
- Фактор дисконтирования (Gamma, γ): Определяет, насколько важны будущие награды по сравнению с текущими (значение от 0 до 1).
- Скорость обучения (Alpha, α): Определяет, насколько быстро Q-значения будут обновляться в процессе обучения (значение от 0 до 1).
- Формула Q-learning:
Основная формула, по которой обновляются Q-значения, выглядит следующим образом:
Q(s, a) = Q(s, a) + ^5; * [r + ^7; * max(Q(s', a')) - Q(s, a)]
Где:
- Q(s, a) - текущее Q-значение для действия a в состоянии s.
- a - скорость обучения.
- r - награда, полученная после выполнения действия a в состоянии s.
- γ - фактор дисконтирования.
- s' - новое состояние, в которое мы перешли после выполнения действия a в состоянии s.
- max(Q(s', a')) - максимальное Q-значение для всех возможных действий a' в новом состоянии s'. Это оценка лучшего, что мы можем сделать из нового состояния.
Формула говорит, что мы обновляем текущее Q-значение (Q(s, a)) на основе разницы между:
- Предполагаемой будущей наградой: r + γ * max(Q(s', a')) (текущая награда плюс дисконтированная лучшая возможная награда в следующем состоянии).
- Текущей оценкой: Q(s, a)
Чем больше разница между предполагаемой наградой и текущей оценкой, тем сильнее изменится Q-значение (это регулируется скоростью обучения a).
- Пример:
Предположим:
- s = A (мы находимся в вершине A)
- a = B (собираемся перейти в вершину B)
- r = -5 (стоимость перехода из A в B равна 5, награда -5)
- γ = 0.9
- α = 0.1
- Q(A, B) = -10 (текущее Q-значение для перехода из A в B равно -10)
- s' = B (после перехода мы окажемся в вершине B)
- max(Q(B, a')) = -2 (максимальное Q-значение для всех возможных действий из B равно -2)
Подставляем значения в формулу:
Q(A, B) = -10 + 0.1 * [-5 + 0.9 * (-2) - (-10)]
Q(A, B) = -10 + 0.1 * [-5 - 1.8 + 10]
Q(A, B) = -10 + 0.1 * [3.2]
Q(A, B) = -10 + 0.32
Q(A, B) = -9.68
Таким образом, Q-значение для перехода из A в B обновилось и стало равно -9.68. Алгоритм постепенно уточняет свои оценки, приближаясь к оптимальным значениям.
Теперь, когда мы понимаем математическую основу, перейдем к практической реализации в 1С, связывая код с описанными понятиями.
Практическая реализация: Q-learning в 1С
Теперь рассмотрим ключевые фрагменты кода обработки 1С, демонстрирующие реализацию алгоритма Q-learning
1. Определение среды (граф):
Граф = Новый Соответствие;
Граф.Вставить("A", Новый Массив()); // Вершина A
Граф.Вставить("B", Новый Массив()); // Вершина B
// ...
Граф["A"].Добавить("B"); Граф["A"].Добавить(5); // A -> B, стоимость 5
Граф["A"].Добавить("C"); Граф["A"].Добавить(2); // A -> C, стоимость 2
// ...
- Этот код задает структуру нашей задачи, определяя состояния (вершины графа) и возможные действия (переходы между вершинами). Стоимость перехода (например, 5 для перехода из A в B) определяет награду (r) - в нашем случае, награда равна -стоимости.
- Граф["A"]: По сути, определяет, в какие состояния можно перейти из состояния "A".
- Граф["A"].Добавить("B"); Граф["A"].Добавить(5); : Задает, что из состояния "A" можно совершить действие "переход в B", и это действие повлечет за собой награду -5.
2. Параметры Q-learning:
Альфа = 0.1; // Скорость обучения (^5;)
Гамма = 0.9; // Фактор дисконтирования (^7;)
Эпсилон = 0.1; // Вероятность исследования (exploration rate)
Эпизоды = 1000; // Количество эпизодов обучения
НачальнаяВершина = "A"; // Начальное состояние (s)
КонечнаяВершина = "F"; // Целевое состояние
Эти переменные напрямую соответствуют параметрам в формуле Q-learning.
- Альфа: Определяет, насколько быстро Q-значения будут адаптироваться к новой информации.
- Гамма: Влияет на то, насколько алгоритм будет учитывать будущие награды при оценке текущего действия.
- Эпсилон: Регулирует баланс между исследованием (случайным выбором действия) и использованием (выбором действия с максимальным Q-значением).
- Эпизоды : Определяет, сколько раз алгоритм будет "играть" в графе, чтобы улучшить свои знания.
- НачальнаяВершина : Задает начальное состояние s для каждого эпизода обучения.
- КонечнаяВершина: Определяет целевое состояние, к которому алгоритм должен стремиться.
3. Инициализация Q-таблицы:
QТаблица = Новый Соответствие;
Для Каждого ЭлементГрафа Из Граф Цикл
КлючВершины = ЭлементГрафа.Ключ;
QТаблица.Вставить(КлючВершины, Новый Соответствие());
Для Каждого Сосед Из Граф[КлючВершины] Цикл
Если ТипЗнч(Сосед) = Тип("Строка") Тогда
QТаблица[КлючВершины].Вставить(Сосед, 0); // Начальное Q-значение равно 0
КонецЕсли;
КонецЦикла;
КонецЦикла;
Этот код создает структуру для хранения Q-значений Q(s, a). Изначально все Q-значения инициализируются нулем, что означает, что алгоритм пока не имеет никаких знаний о "ценности" действий.
- QТаблица[КлючВершины].Вставить(Сосед, 0); : Устанавливает начальное Q-значение равным 0 для действия "переход из вершины КлючВершины в вершину Сосед".
4. Обучение Q-learning (основной цикл):
ГСЧ = Новый ГенераторСлучайныхЧисел(); // Создание генератора случайных чисел
Для i = 1 По Эпизоды Цикл
ТекущаяВершина = НачальнаяВершина;
Пока ТекущаяВершина <> КонечнаяВершина Цикл
// 4.1. Выбор действия (exploration vs. exploitation)
СлучайноеЧисло = ГСЧ.СлучайноеЧисло(0, 10000);
Если СлучайноеЧисло < Эпсилон * 10000 Тогда // Используем ГСЧ для генерации случайного числа
// Exploration: выбираем случайного соседа
// ... (код выбора случайного соседа) ...
Действие = Соседи[СлучайныйИндекс];
Иначе
// Exploitation: выбираем соседа с максимальным Q-значением
// ... (код выбора соседа с максимальным Q-значением) ...
Действие = Сосед.Ключ;
КонецЕсли;
// 4.2. Получение награды (reward)
Награда = -ПолучитьСтоимостьПерехода(ТекущаяВершина, Действие, Граф); // Отрицательная стоимость (минимизируем)
// 4.3. Обновление Q-значения
ПредыдущееQЗначение = QТаблица[ТекущаяВершина][Действие];
МаксQСосед = -999999;
Если Действие <> "" Тогда // Добавлена проверка на пустую строку
Для Каждого Сосед Из QТаблица[Действие] Цикл
Если QТаблица[Действие][Сосед.Ключ] > МаксQСосед Тогда
МаксQСосед = QТаблица[Действие][Сосед.Ключ];
КонецЕсли;
КонецЦикла;
КонецЕсли; // Добавлено закрытие условного оператора
НовоеQЗначение = ПредыдущееQЗначение + Альфа * (Награда + Гамма * МаксQСосед - ПредыдущееQЗначение);
QТаблица[ТекущаяВершина][Действие] = НовоеQЗначение;
// 4.4. Переход в следующее состояние
ТекущаяВершина = Действие;
КонецЦикла;
КонецЦикла;
- Этот код реализует основной цикл обучения Q-learning, многократно "играя" в графе и обновляя Q-значения в соответствии с формулой.
-
Для i = 1 По Эпизоды Цикл: Внешний цикл, повторяющий процесс обучения Эпизоды раз. Каждый проход цикла - это отдельный эпизод обучения.
-
ТекущаяВершина = НачальнаяВершина: В начале каждого эпизода мы помещаем агента в начальное состояние (НачальнаяВершина).
-
Пока ТекущаяВершина <> КонечнаяВершина Цикл: Внутренний цикл, продолжающийся до тех пор, пока агент не достигнет целевого состояния (КонечнаяВершина).
-
4.1. Выбор действия (exploration vs. exploitation):
- Этот блок кода реализует стратегию "эпсилон-жадности" для выбора действия. С вероятностью Эпсилон (исследование) выбирается случайное действие, а с вероятностью 1 - Эпсилон (использование) - действие с максимальным Q-значением.
- Действие = Соседи[СлучайныйИндекс]; // Exploration
- Действие = Сосед.Ключ; // Exploitation
-
4.2. Получение награды (reward):
- Награда = -ПолучитьСтоимостьПерехода(ТекущаяВершина, Действие, Граф); : Определяется награда (r) за совершённое действие. В нашем случае, это отрицательная стоимость перехода.
-
4.3. Обновление Q-значения:
- НовоеQЗначение = ПредыдущееQЗначение + Альфа * (Награда + Гамма * МаксQСосед - ПредыдущееQЗначение);
- QТаблица[ТекущаяВершина][Действие] = НовоеQЗначение;
- Именно здесь реализуется основная формула Q-learning! Мы обновляем Q-значение для текущего состояния и действия, используя формулу, которую мы рассмотрели ранее.
- ПредыдущееQЗначение : Q(s, a) - текущее Q-значение.
- Альфа : α - скорость обучения.
- Награда : r - награда за переход.
- Гамма : γ - фактор дисконтирования.
- МаксQСосед: max(Q(s', a')) - максимальное Q-значение для всех возможных действий в следующем состоянии.
- НовоеQЗначение: новое вычисленное значение Q(s, a)
-
4.4. Переход в следующее состояние:
- ТекущаяВершина = Действие; : Агент переходит в новое состояние (s'), выполнив выбранное действие.
-
Этот цикл повторяется много раз, позволяя алгоритму Q-learning постепенно улучшать свои оценки Q-значений и находить оптимальную стратегию.
5. Поиск оптимального пути после обучения:
Путь = Новый Массив;
ТекущаяВершина = НачальнаяВершина;
Путь.Добавить(ТекущаяВершина);
Пока ТекущаяВершина <> КонечнаяВершина Цикл
Действие = "";
МаксQЗначение = -999999;
Для Каждого Сосед Из QТаблица[ТекущаяВершина] Цикл
Если QТаблица[ТекущаяВершина][Сосед.Ключ] > МаксQЗначение Тогда
МаксQЗначение = QТаблица[ТекущаяВершина][Сосед.Ключ];
Действие = Сосед.Ключ;
КонецЕсли;
КонецЦикла;
ТекущаяВершина = Действие;
Путь.Добавить(ТекущаяВершина);
КонецЦикла;
После того, как алгоритм Q-learning обучился (т.е. Q-значения в Q-таблице стабилизировались), мы можем использовать эту таблицу для поиска оптимального пути. Этот код реализует жадный алгоритм выбора действий, всегда выбирая действие с максимальным Q-значением в текущем состоянии.
- Путь = Новый Массив;: Создаем массив для хранения оптимального пути.
- ТекущаяВершина = НачальнаяВершина;: Начинаем с начального состояния.
- Пока ТекущаяВершина <> КонечнаяВершина Цикл: Продолжаем, пока не достигнем целевого состояния.
- Внутри цикла:
- Мы ищем действие (Действие) с максимальным Q-значением (МаксQЗначение) в текущем состоянии (ТекущаяВершина).
- ТекущаяВершина = Действие;: Переходим в следующее состояние, выполнив выбранное действие.
- Путь.Добавить(ТекущаяВершина);: Добавляем текущую вершину в массив Путь
Вывод результатов:
Сообщение = Новый СообщениеПользователю;
Сообщение.Текст = "Оптимальный путь: " + СтрСоединить(Путь, " -> ");
Сообщение.Сообщить();
Сообщение.Текст = "Q-таблица (для отладки):";
Сообщение.Сообщить();
Для Каждого Вершина Из QТаблица Цикл
Для Каждого Действие Из Вершина.Значение Цикл
Сообщение.Текст = "Вершина: " + Вершина.Ключ + ", Действие: " + Действие.Ключ + ", Q-значение: " + Формат(Действие.Значение, "ЧДЦ=3");
Сообщение.Сообщить();
КонецЦикла;
КонецЦикла;
Этот код просто выводит результаты работы алгоритма:
- Оптимальный путь, найденный на основе Q-таблицы.
- Содержимое Q-таблицы (для отладки и анализа результатов). Q-таблица показывает, как алгоритм оценивает каждое действие в каждом состоянии после обучения.
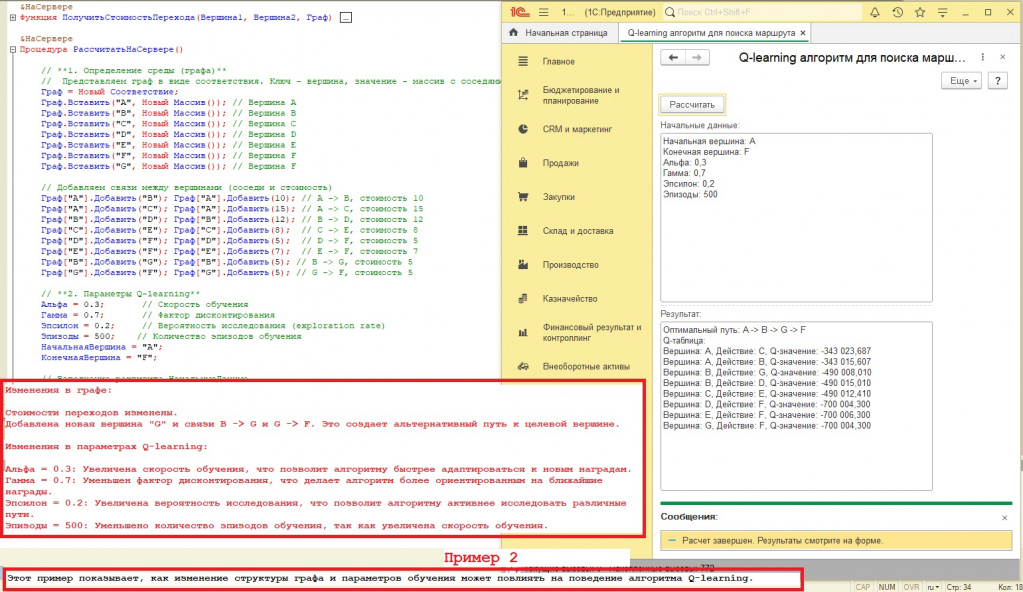
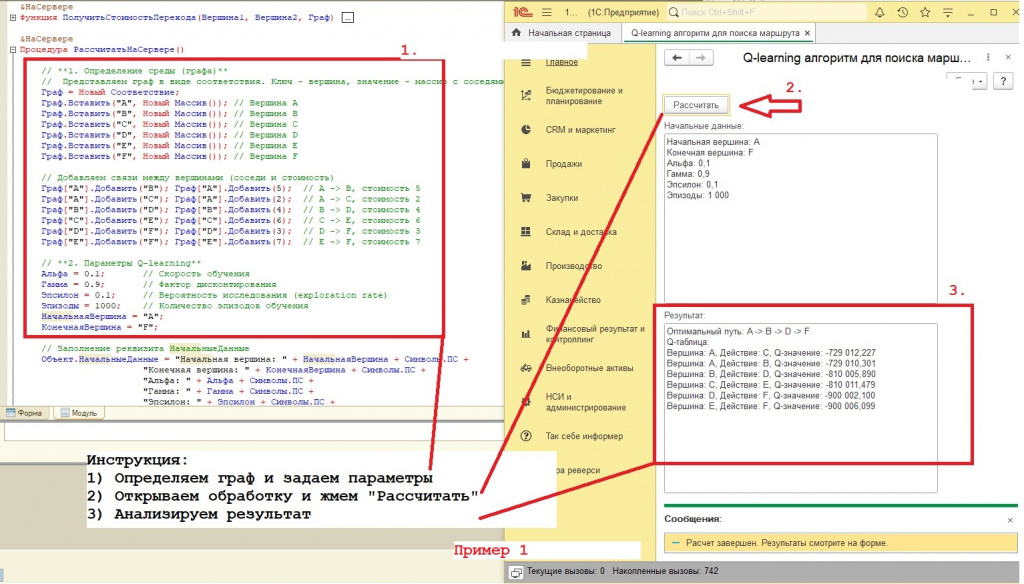
И,вот, написали обработку, ввели параметры/данные:
// Представляем граф в виде соответствия. Ключ - вершина, значение - массив с соседями и стоимостями.
Граф = Новый Соответствие;
Граф.Вставить("A", Новый Массив()); // Вершина A
Граф.Вставить("B", Новый Массив()); // Вершина B
Граф.Вставить("C", Новый Массив()); // Вершина C
Граф.Вставить("D", Новый Массив()); // Вершина D
Граф.Вставить("E", Новый Массив()); // Вершина E
Граф.Вставить("F", Новый Массив()); // Вершина F
// Добавляем связи между вершинами (соседи и стоимость)
Граф["A"].Добавить("B"); Граф["A"].Добавить(5); // A -> B, стоимость 5
Граф["A"].Добавить("C"); Граф["A"].Добавить(2); // A -> C, стоимость 2
Граф["B"].Добавить("D"); Граф["B"].Добавить(4); // B -> D, стоимость 4
Граф["C"].Добавить("E"); Граф["C"].Добавить(6); // C -> E, стоимость 6
Граф["D"].Добавить("F"); Граф["D"].Добавить(3); // D -> F, стоимость 3
Граф["E"].Добавить("F"); Граф["E"].Добавить(7); // E -> F, стоимость 7
// 2. Параметры Q-learning
Альфа = 0.1; // Скорость обучения
Гамма = 0.9; // Фактор дисконтирования
Эпсилон = 0.1; // Вероятность исследования
Эпизоды = 1000; // Количество эпизодов обучения
НачальнаяВершина = "A";
КонечнаяВершина = "F";
Который стоит рассматривать как:
(Определение среды) Мы определили граф, состоящий из 6 вершин (A, B, C, D, E, F) и связей между ними с указанием стоимости перехода:
A -> B (стоимость 5)
A -> C (стоимость 2)
B -> D (стоимость 4)
C -> E (стоимость 6)
D -> F (стоимость 3)
E -> F (стоимость 7)
Параметры Q-learning:
Альфа = 0.1: Скорость обучения (насколько быстро Q-значения будут обновляться).
Гамма = 0.9: Фактор дисконтирования (насколько важны будущие награды по сравнению с текущими).
Эпсилон = 0.1: Вероятность исследования (как часто агент будет выбирать случайное действие вместо использования текущей стратегии).
Эпизоды = 1000: Количество эпизодов обучения (сколько раз агент будет "играть" в графе, чтобы улучшить свою стратегию).
НачальнаяВершина = "A": Вершина, с которой начинается поиск маршрута.
КонечнаяВершина = "F": Вершина, в которую нужно прийти.
Получили результат:
Оптимальный путь: A -> B -> D -> F
Q-таблица (для отладки):
Вершина: A, Действие: B, Q-значение: -729 010,301
Вершина: B, Действие: D, Q-значение: -810 005,890
Вершина: C, Действие: E, Q-значение: -810 011,479
Вершина: D, Действие: F, Q-значение: -900 002,100
Вершина: E, Действие: F, Q-значение: -900 006,099
Q-таблица (для отладки) - это таблица, показывающая Q-значения (оценки качества) для каждого действия (перехода к соседней вершине) в каждой вершине после обучения. Рассмотрим пример:
Вершина: A, Действие: B, Q-значение: -729 010,301: Это означает, что после обучения Q-learning, переход из вершины A в вершину B оценивается в -729 010,301. Чем больше (ближе к 0) это значение (учитывая, что мы используем отрицательные награды), тем лучше действие.
Важно: Обратите внимание, что Q-значения очень большие и отрицательные. Это связано с тем, что мы используем большое количество эпизодов (Эпизоды = 1000) и отрицательные награды (награда равна отрицательной стоимости перехода). Со временем Q-значения накапливаются, поэтому становятся очень большими. Важно понимать, что алгоритм не "выбрал" этот путь, а просто оценил его. Оптимальный путь определяется путем выбора действия с максимальным Q-значением на каждом шагу.
Оптимальный путь: A -> B -> D -> F: Это путь, который алгоритм Q-learning считает оптимальным после обучения. Он состоит из последовательности вершин, которые нужно посетить, чтобы добраться от начальной вершины (A) до конечной вершины (F) с минимальными затратами. (см. скриншоты)
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.13.82
Вступайте в нашу телеграмм-группу Инфостарт