
Сущность и зарождение алгоритма бинарного поиска
Алгоритм бинарного поиска, фундаментальный инструмент в области информатики, представляет собой эффективный метод нахождения целевого элемента в отсортированном списке. Его суть заключается в последовательном делении области поиска пополам, что позволяет быстро сужать диапазон рассматриваемых значений до тех пор, пока не будет найден искомый элемент или не будет установлено его отсутствие. Этот подход кардинально отличается от простого линейного поиска, при котором каждый элемент списка проверяется по очереди, что делает бинарный поиск чрезвычайно полезным для работы с большими объемами данных. Определение алгоритма подчеркивает его ключевые особенности: работа с отсортированными данными и способность к экспоненциальному сокращению области поиска. Это свойство делает его незаменимым в ситуациях, когда скорость поиска критически важна.
История алгоритма бинарного поиска, как и история многих фундаментальных концепций в информатике, не имеет четкой даты рождения, однако, его истоки можно проследить в древних математических практиках. Принцип последовательного деления пополам, лежащий в основе этого алгоритма, использовался уже в античные времена для решения различных задач, например, для нахождения корней уравнений или определения местоположения. В более формализованном виде, алгоритм бинарного поиска начал развиваться с появлением вычислительных машин и необходимостью эффективной обработки данных. В этот период математики и инженеры осознали потенциал этого метода для ускорения операций поиска в памяти компьютеров.
Применение бинарного поиска в ранние эпохи развития вычислительной техники было связано с задачами сортировки и поиска данных в таблицах и базах данных. По мере роста объемов хранимой информации, потребность в быстрых алгоритмах поиска возрастала, что привело к широкому распространению бинарного поиска. Важно отметить, что формализация и анализ эффективности алгоритма бинарного поиска стали возможны благодаря развитию теории вычислимости и анализу сложности алгоритмов. Исследования в этой области позволили оценить временную сложность алгоритма бинарного поиска как логарифмическую, что подчеркивает его высокую эффективность по сравнению с линейным поиском.
Среди известных математиков, внесших вклад в развитие алгоритмов поиска, можно упомянуть ученых, которые работали над проблемами сортировки и поиска данных, создавая основы для более сложных алгоритмов, таких как бинарный поиск. Имена этих ученых часто остаются в тени, поскольку их вклад, хотя и значительный, не всегда связан с непосредственным изобретением алгоритма. Тем не менее, их работы по анализу сложности алгоритмов и разработке эффективных методов сортировки подготовили почву для развития бинарного поиска и оценки его преимуществ. Алгоритм бинарного поиска – это не просто способ найти элемент, это элегантное решение, демонстрирующее эффективность деления задачи на более мелкие части для достижения оптимального результата.
Развитие вычислительных технологий и появление новых языков программирования сделали бинарный поиск еще более доступным и удобным в использовании. Современные библиотеки и фреймворки содержат готовые реализации бинарного поиска, что позволяет программистам легко интегрировать его в свои проекты. Это делает алгоритм бинарного поиска одним из самых распространенных инструментов в арсенале разработчиков программного обеспечения, применяемым в широком спектре приложений, от простых утилит до сложных систем управления базами данных.
Реализация и применение бинарного поиска в 1С 8.3
Применение алгоритма бинарного поиска в среде 1С:8.3 предоставляет разработчикам мощный инструмент для оптимизации операций поиска в различных структурах данных, особенно в тех случаях, когда скорость обработки информации является критически важной. 1С:8.3, платформа для автоматизации бизнеса, активно использует различные типы данных, такие как массивы, списки значений, таблицы значений, и для всех них бинарный поиск может стать полезным решением. Важно понимать, что эффективность бинарного поиска напрямую зависит от предварительной сортировки данных. Поэтому, прежде чем применять этот алгоритм, необходимо убедиться в том, что искомый список отсортирован по критерию, по которому будет выполняться поиск.
В 1С:8.3 реализация бинарного поиска может быть осуществлена несколькими способами. Самый простой подход – использование встроенных возможностей языка 1С для работы с отсортированными структурами данных. Например, если данные хранятся в списке значений, то можно использовать методы для поиска элемента по значению, при этом, список должен быть предварительно отсортирован. Также, можно реализовать бинарный поиск вручную, написав соответствующий код на встроенном языке 1С. Этот подход позволяет более гибко управлять процессом поиска и адаптировать алгоритм под конкретные задачи и особенности данных.
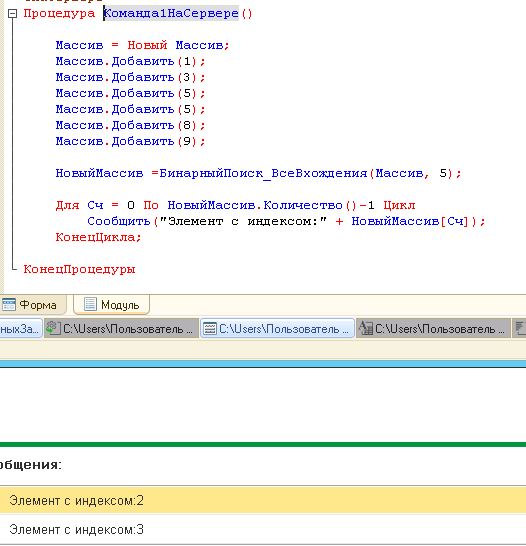
Одним из примеров практического применения бинарного поиска в 1С:8.3 является поиск элемента в таблице значений, отсортированной по определенному полю. Предположим, у нас есть таблица с информацией о товарах, отсортированная по артикулу. Если требуется найти товар по известному артикулу, то бинарный поиск может существенно ускорить этот процесс по сравнению с линейным перебором всех строк таблицы. Для этого необходимо написать функцию, которая будет принимать в качестве аргументов таблицу значений, артикул для поиска и параметры, определяющие границы поиска (начальный и конечный индексы). Внутри функции происходит деление области поиска пополам, сравнение артикула с артикулом в средней строке и корректировка границ поиска в зависимости от результата сравнения. Процесс повторяется до тех пор, пока искомый артикул не будет найден или границы поиска не пересекутся.
Еще одним примером является использование бинарного поиска для оптимизации работы с большими массивами данных. В 1С:8.3 массивы могут быть использованы для хранения различных данных, таких как списки кодов, идентификам массива по индексу. В заключение, бинарный поиск в 1С:8.3 является ценным инструментом для ускорения операций поиска.
При реализации бинарного поиска в 1С:8.3 следует учитывать особенности платформы и оптимизировать код для достижения максимальной производительности. Например, реальных данных и сравнивать ее с производительностью других методов поиска, таких как линейный поиск, для определения наиболее эффективного решения для конкретной задачи.
Помимо оптимизации производительности, при применении бинарного поиска в 1С:8.3 следует уделять внимание удобству использования и поддержке кода и удобным для работы. Бинарный поиск – это простой, но мощный инструмент, который может значительно улучшить производительность ваших 1С:8.3 приложений.
Преимущества и недостатки бинарного поиска
Алгоритм бинарного поиска, как и любой алгоритм, имеет свои сильные и слабые стороны. Понимание этих аспектов позволяет разработчикам принимать обоснованные решения о его применении в конкретных ситуациях. Одним из главных преимуществ бинарного поиска является его высокая эффективность при работе с большими объемами отсортированных данных. Логарифмическая временная сложность, о которой говорилось ранее, делает его значительно быстрее, чем линейный поиск, временная сложность которого линейно зависит от размера входных данных. Это особенно важно в системах, где скорость поиска является критически важным фактором.
Кроме того, бинарный поиск легко реализуется и понимается, что делает его доступным для широкого круга разработчиков. Существуют готовые реализации бинарного поиска во многих языках программирования и библиотеках, что упрощает его интеграцию в различные проекты. Простота реализации и понимания также облегчает отладку и поддержку кода. Преимущество бинарного поиска заключается также в его универсальности. Он может быть применен к различным типам данных, включая числа, строки, даты и любые другие данные, которые можно отсортировать.
Однако у бинарного поиска есть и недостатки, которые необходимо учитывать. Основным недостатком является требование предварительной сортировки данных. Если данные не отсортированы, то бинарный поиск не может быть применен, и потребуется дополнительное время на сортировку данных, что может снизить общую производительность. В худшем случае, если сортировка данных занимает больше времени, чем поиск в неот к дополнительным затратам времени и ресурсов. В таких случаях, использование других алгоритмов поиска, таких как хеш-таблицы, может быть более эффективным. Бинарный поиск не является оптимальным выбором, когда требуется часто добавлять или удалять элементы из списка, так как это требует пересортировки данных.
Также следует учитывать, что бинарный поиск требует реализации доступа к элементам данных по индексу. Это означает, что он хорошо подходит для работы с массивами, таблицами значений и другими структурами данных, которые обеспечивают прямой доступ к элементам. Однако, для работы с другими структурами данных, такими как связанные списки, бинарный поиск может быть менее эффективным, так как доступ к элементам по индексу может потребовать дополнительного времени.
В заключение, бинарный поиск является мощным и эффективным алгоритмом для поиска в отсортированных данных, но его применение ограничено определенными условиями.
Хотя алгоритм бинарного поиска является чрезвычайно эффективным для поиска в отсортированных данных, он не является единственным методом поиска. Существуют другие алгоритмы, для больших объемов данных.
Хеш-таблицы представляют собой еще один распространенный метод поиска, который обеспечивает очень быструю производительность в среднем случае. Хеш-таблицы используют функцию хеширования для отображения ключей в индексы таблицы, что позволяет быстро найти элемент. Преимущество хеш-таблиц заключается в их почти мгновенном доступе к элементам в среднем случае. Недостатки хеш-таблиц включают в себя необходимость разрешения коллизий (ситуации, когда разные ключи отображаются в один и тот же индекс) и потенциальную потерю производительности в худшем случае.
Деревья поиска, такие как бинарные деревья поиска, являются еще одним методом поиска, который обеспечивает баланс между эффективностью и сложностью. Бинарные деревья поиска позволяют быстро находить, добавлять и удалять элементы, сохраняя при этом структуру данных в отсортированном слабые стороны. Он превосходит линейный поиск по скорости, но требует предварительной сортировки данных. Хеш-таблицы обычно обеспечивают более быструю производительность, но требуют более сложной реализации и могут иметь проблемы с коллизиями. Деревья поиска обеспечивают баланс между эффективностью и гибкостью, но могут быть более сложными в реализации. Выбор конкретного алгоритма поиска зависит от конкретных требований к производительности, типу данных и частоте изменений данных.
Актуальность алгоритма бинарного поиска в среде 1С:8.3 остается высокой, несмотря на появление может значительно ускорить операции поиска, что особенно важно при работе с большими объемами данных, например, в базах данных.
Несмотря на развитие технологий и появление новых подходов к обработке данных, бинарный поиск остается актуальным инструментом в арсенале разработчиков 1С:8.3. Он прост в реализации, эффективен для работы с отсортированными данными и может быть легко интегрирован в существующие 1С:8.3 приложения. В заключение, алгоритм бинарного поиска – это не устаревшая технология, а надежный и проверенный временем инструмент, который продолжает быть востребованным в сфере разработки программного обеспечения, особенно в контексте платформы 1С:8.3. Его знание и умение применять его – это важный навык для любого разработчика.
В предыдущей работе, посвященной эффективным методам упорядочивания данных, мы рассматривали алгоритмы сортировки, разработанные Дональдом Кнутом и Джозефом Шеллтом, предложив практическую реализацию в среде "1С:Предприятие 8.3". Вот эта статья: Сортировка массивов большой размерности: практическое применение алгоритмов Кнута и Шелла. Данная статья является логическим продолжением, углубляющим наше понимание обработки данных за счет применения алгоритма бинарного поиска. Стремление к повышению производительности и оптимизации операций поиска подтолкнуло нас к интеграции данного метода в уже существующую разработку.
Бинарный поиск, являясь одним из наиболее эффективных алгоритмов поиска в упорядоченных массивах, представляет собой изящное решение для быстрого нахождения конкретного элемента. Его основная идея заключается в последовательном делении пространства поиска пополам. Алгоритм начинает с проверки элемента, находящегося в середине массива. Если искомое значение совпадает с найденным, то поиск завершен, и возвращается индекс этого элемента. Если же искомое значение меньше, чем элемент в середине, то поиск продолжается в левой половине массива; в противном случае - в правой. Этот процесс повторяется до тех пор, пока искомое значение не будет найдено или пока область поиска не станет пустой, что свидетельствует об отсутствии элемента в массиве.
Функция БинарныйПоиск(Массив, ИскомоеЗначение) Экспорт
Лев = 0;
Прав = Массив.Количество() - 1;
Пока Лев <= Прав Цикл
Середина = Цел((Лев + Прав) / 2);
Если Массив[Середина] = ИскомоеЗначение Тогда
Возврат Середина; // Значение найдено, возвращаем индекс
КонецЕсли;
Если Массив[Середина] < ИскомоеЗначение Тогда
Лев = Середина + 1; // Ищем в правой половине
Иначе
Прав = Середина - 1; // Ищем в левой половине
КонецЕсли;
КонецЦикла;
Возврат -1; // Значение не найдено
КонецФункции
Функция, используемая для реализации бинарного поиска, является ключевым компонентом данной оптимизации. Её код лаконичен, но в то же время обладает высокой эффективностью. Рассмотрим подробнее её структуру.
Изначально, функция получает два параметра: упорядоченный массив данных и искомое значение. Для реализации алгоритма, вводим две переменные: "Лев" (Лев = 0) и "Прав" (Прав = Массив.Количество() - 1), которые определяют границы области поиска. В начале, "Лев" указывает на первый элемент массива, а "Прав" - на последний.
Далее, начинается цикл "Пока", который выполняется до тех пор, пока левая граница не превысит правую. Внутри цикла вычисляется "Середина" (Середина = Цел((Лев + Прав) / 2)), представляющая собой индекс центрального элемента текущей области поиска.
Затем, происходит сравнение элемента массива по индексу "Середина" с искомым значением. Если они равны, функция немедленно возвращает индекс "Середина", указывая на найденный элемент. В противном случае, выполняется сравнение, определяющее, в какой половине массива следует продолжить поиск.
Если элемент в середине меньше искомого значения, то поиск продолжается в правой половине, сдвигая левую границу (Лев = Середина + 1). В противном случае, искомое значение, вероятно, находится в левой половине, и правая граница сдвигается (Прав = Середина - 1).
Этот процесс повторяется, сужая область поиска на каждом шаге, до тех пор, пока искомый элемент не будет найден, или пока границы поиска не сойдутся, сигнализируя об отсутствии искомого элемента в массиве. Если элемент не найден, функция возвращает значение -1, обозначающее неудачу.
Применение бинарного поиска в рамках существующей обработки, будь то алгоритмы Кнута или Шелла, значительно ускорит поиск и анализ данных в среде "1С:Предприятие", обеспечивая тем самым конкурентное преимущество и повышая общую эффективность работы.
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.13.82
Вступайте в нашу телеграмм-группу Инфостарт
{kind=link}