
{kind=link}
Интерполяционный Поиск: Путь к Быстрому Нахождению Данных
В необъятном мире алгоритмов поиска, где каждый метод стремится к более быстрому и эффективному извлечению информации из упорядоченных наборов данных, интерполяционный поиск занимает особое место. Это алгоритм, который, подобно опытному следопыту, умеет находить нужные элементы, используя не только порядок расположения данных, но и их числовые значения, делая его особенно эффективным для определенных типов наборов данных. Интерполяционный поиск, в своей сути, является улучшенной версией бинарного поиска, приспособленной для работы с данными, имеющими равномерное распределение. В отличие от бинарного поиска, который всегда делит область поиска пополам, интерполяционный поиск оценивает положение искомого элемента, основываясь на его значении относительно минимального и максимального значений в текущей области поиска. Это позволяет алгоритму делать более "умные" предположения о том, где находится искомый элемент, что значительно сокращает количество необходимых шагов, особенно для больших наборов данных с равномерным распределением. Интерполяционный поиск — это не просто способ нахождения данных, это отражение стремления к оптимизации и использованию доступной информации для достижения максимальной эффективности.
История Интерполяционного Поиска: От Идеи к Реализации
История интерполяционного поиска, к сожалению, не изобилует яркими именами и точными датами, как это бывает с некоторыми другими известными алгоритмами. Он не является плодом гениального озарения одного конкретного ученого, а скорее результатом эволюционного развития методов поиска, направленных на повышение их эффективности. Сама идея интерполяции, лежащая в основе алгоритма, имеет долгую историю и использовалась в для ускорения процесса поиска возникла как естественное развитие алгоритмов, основанных на сравнении и делении области поиска. Вероятно, первые упоминания об интерполяционном поиске в том виде, в котором мы его знаем сегодня, появились в научных публикациях и технических отчетах, посвященных анализацию поиска информации в различных областях, от баз данных до систем искусственного интеллекта.
Применение Интерполяционного Поиска: Кто, Когда и Для Чего
Интерполяционный поиск, благодаря своей способности быстро находить данные в упорядоченных наборах, нашел широкое применение в различных областях, где скорость доступа к информации играет критическую роль. Его начали использовать там, где бинарный поиск, хотя и эффективный, оказывался недостаточно быстрым, особенно при работе с очень большими объемами данных. Одними из первых, кто оценил преимущества интерполяционного поиска, стали разработчики баз данных и файловых систем. В этих областях, где данные хранятся в упорядоченном виде на дисках или других носителях информации, скорость поиска нужной записи или файла имеет огромное значение для общей производительности системы. Интерполяционный поиск позволял значительно сократить время доступа к данным, особенно если они были равномерно распределены в диапазоне значений. Например, если база данных содержала информацию о клиентах, упорядоченную по их идентификационным номерам, то интерполяционный поиск мог эффективно использоваться для быстрого нахождения записи о конкретном клиенте, зная его номер. их положения в массиве и выполнения различных статистических расчетов. Со временем, интерполяционный поиск начал применяться и в других областях, где требовался быстрый поиск в упорядоченных данных. Он нашел свое место в системах автоматизированного управления производством, где необходимо быстро находить информацию о дета его характеристикам. В целом, интерполяционный поиск является ценным инструментом для решения задач поиска в упорядоченных данных, и его применение позволяет значительно повысить скорость доступа к информации и улучшить производительность различных систем и приложений.
Интерполяционный Поиск vs. Бинарный Поиск: Сравнение Алгоритмов
Чтобы полностью оценить преимущества и недостатки интерполяционного поиска, необходимо сравнить его с одним из самых известных и широко используемых алгоритмов поиска – бинарным поиском. Бинарный поиск, в своей основе, представляет собой простой, но эффективный метод нахождения элемента в упорядоченном массиве. Он работает путем многократного деления области поиска пополам. На каждом шаге алгоритм сравнивает искомый элемент со средним элементом в текущей области поиска. Если искомый элемент меньше среднего, то область поиска сужается до левой половины массива. Если искомый элемент больше среднего, то область поиска сужается до правой половины массива. Этот процесс повторяется до тех пор, пока искомый элемент не будет найден, или пока область поиска не станет пустой, что означает, что элемент не присутствует в массиве. Бинарный поиск характеризуется логарифмической временной сложностью O(log n), где n – количество элементов в массиве. Это означает, что количество необходимых шагов для нахождения элемента растет очень медленно с увеличением размера массива. Благодаря этому, бинарный поиск является очень эффективным для работы с большими объемами данных. Однако, бинарный поиск не учитывает числовые значения элементов в массиве, а только их порядок. Он всегда делит область поиска пополам, независимо от того, где, предположительно, находится искомый элемент. В отличие от бинарного поиска, интерполяционный поиск пытается "угадать" положение искомого элемента, основываясь на его значении относительно минимального и максимального значений в текущей области поиска. Он использует формулу интерполяции для оценки индекса, где, вероятно, находится искомый элемент. Эта формула учитывает значения искомого элемента, минимального и максимального элементов в области поиска, а также индекcная сложность интерполяционного поиска приближается к O(log log n), что значительно лучше, чем O(log n) у бинарного поиска. Однако, в худшем случае, когда данные распределены неравномерно, временная сложность интерполяционного поиска может достигать O(n), что делает его менее эффективным, чем бинарный поиск. Таким образом, выбор между интерполяционным поиском и бинарным поиском зависит от характеристик конкретного набора данных. Если данные распределены равномерно, то интерполяционный поиск может обеспечить значительное ускорение поиска. Однако, если данные распределены неравномерно, то лучше использовать бинарный поиск, который гарантирует логарифмическую временную сложность в любом случае.
Плюсы и Минусы Интерполяционного Поиска: Взвешенный Подход
Как и любой алгоритм, интерполяционный поиск обладает своими преимуществами и недостатками, которые необходимо учитывать при выборе метода для решения конкретной задачи. К числу основных преимуществ интерполяционного поиска можно отнести:
Высокая скорость поиска для равномерно распределенных данных: В идеальном случае, когда данные распределены равномерно, интерполяционный поиск может работать значительно быстрее бинарного поиска, приближаясь к временной сложности O(log log n). Это делает его особенно привлекательным для работы с большими объемами данных, где скорость доступа к информации имеет критическое значение.
Адаптивность к данным: Интерполяционный поиск использует числовые значения элементов для оценки их положения в массиве. Это позволяет ему адаптироваться к особенностям данных и делать более "умные" предположения о том, где находится искомый элемент.
Простота реализации: Интерполяционный поиск достаточно прост в реализации, особенно если уже есть понимание принципов работы бинарного поиска. Это позволяет быстро внедрить его в существующие системы и приложения.
Однако, интерполяционный поиск имеет и ряд недостатков, которые необходимо учитывать:
Низкая эффективность для неравномерно распределенных данных: Если данные распределены неравномерно, то производительность интерполяционного поиска может значительно снизиться и даже стать хуже, чем у бинарного поиска. В худшем случае, его временная сложность может достигать O(n), что делает его непригодным для работы с такими данными.
Требование упорядоченности данных: Интерполяционный поиск, как и бинарный поиск, требует, чтобы данные были упорядочены по возрастанию или убыванию. Если данные не упорядочены, то алгоритм не будет работать правильно.
Ограничение на тип данных: Интерполяционная эффективность напрямую зависит от характеристик данных, и необходимо тщательно оценивать целесообразность его применения в каждом конкретном случае.
Применение Интерполяционного Поиска в "1С:Предприятие 8.3": Практические Аспекты
"1С:Предприятие 8.3", как платформа для разработки бизнес-приложений, предоставляет широкие возможности для реализации различных алгоритмов, включая интерполяционный поиск. В "1С:Предприятие 8.3" интерполяционный поиск может быть реализован как на встроенном языке "1С:Предприятие", так и с использованием внешних компонент, разработанных на других языках программирования, таких как C++ или Java. Реализация интерполяционного поиска на встроенном языке "1С:Предприятие" может быть достаточно простой и понятной, особенно если уже есть опыт работы с бинарным поиском. Для этого необходимо создать функцию, которая будет принимать на вход упорядоченный массив данных, искомый элемент и границы области поиска. Внутри функции необходимо реализовать логику интерполяции для оценки индекса, где, вероятно, находится искомый элемент, и выполнить сравнение искомого элемента с элементом по этому индексу. В зависимости от результата сравнения, необходимо сузить область поиска до левой или правой части массива и повторить процесс до тех пор, пока искомый элемент не будет найден, или пока область поиска не станет пустой. Важно учитывать возможность деления на ноль и добавлять соответствующие проверки в код функции.
Интерполяционный поиск можно использовать для поиска данных в различных объектах "1С:Предприятия", таких как справочники, документы, регистры сведений и регистры накопления. Например, его можно использовать для быстрого поиска контрагента в справочнике контрагентов по его идентификационному коду, если коды контрагентов упорядочены по возрастанию. Также его можно использовать для поиска записи в регистре сведений по дате или другому числовому измерению. Однако необходимо помнить, что эффективность интерполяционного поиска напрямую зависит от характера распределения данных в этих объектах. Для реализации интерполяционного поиска с использованием многопоточных вычислений, что позволит значительно ускорить поиск на многоядерных процессорах, можно использовать внешнюю компоненту, разработанную на C++.
В целом, интерполяционный поиск является ценным инструментом, который может быть полезен для решения задач поиска данных в "1С:Предприятие 8.3". Однако, необходимо тщательно оценивать целесообразность его применения в каждом конкретном случае и учитывать особенности конкретного набора данных.
В заключение, интерполяционный поиск — это эффективный инструмент в арсенале разработчика, позволяющий существенно ускорить процесс поиска данных при определенных условиях. Его грамотное применение в "1С:Предприятие 8.3" может повысить производительность системы и улучшить пользовательский опыт. Однако, важно помнить о его ограничениях и выбирать наиболее подходящий алгоритм для каждой конкретной задачи.
// --- Функция интерполяционного поиска ---
Функция ИнтерполяционныйПоиск(Массив, ИскомыйЭлемент)
Начало = 0;
Конец = Массив.Количество() - 1;
Пока Начало <= Конец Цикл
// Оценка позиции
Если Массив[Конец] = Массив[Начало] Тогда // Обработка случая одинаковых значений
Если Массив[Начало] = ИскомыйЭлемент Тогда
Возврат Начало;
Иначе
Возврат -1; // Элемент не найден
КонецЕсли;
КонецЕсли;
ПредполагаемаяПозиция = Начало + Цел(((Конец - Начало) / (Массив[Конец] - Массив[Начало])) * (ИскомыйЭлемент - Массив[Начало]));
// Проверка границ
Если ПредполагаемаяПозиция < Начало ИЛИ ПредполагаемаяПозиция > Конец Тогда
Возврат -1; // Элемент не найден
КонецЕсли;
Если Массив[ПредполагаемаяПозиция] = ИскомыйЭлемент Тогда
Возврат ПредполагаемаяПозиция;
КонецЕсли;
Если Массив[ПредполагаемаяПозиция] < ИскомыйЭлемент Тогда
Начало = ПредполагаемаяПозиция + 1;
Иначе
Конец = ПредполагаемаяПозиция - 1;
КонецЕсли;
КонецЦикла;
Возврат -1; // Элемент не найден
КонецФункции
Рассмотрим более детально реализацию функции. В начале работы определяются переменные "Начало" и "Конец", указывающие на границы поиска в массиве. Затем, в цикле, происходит последовательное сужение области поиска до тех пор, пока искомый элемент не будет найден, либо пока не станет ясно, что он отсутствует в массиве. Внутри цикла вычисляется предполагаемая позиция искомого элемента. Важно отметить, что функция содержит проверку на случай, когда все значения в рассматриваемой части массива оказываются одинаковыми. В этом случае, если искомый элемент равен этому значению, то возвращается индекс начала массива, иначе считается, что элемент не найден.
После вычисления предполагаемой позиции, функция проверяет, не вышла ли эта позиция за границы массива. Если это произошло, то считается, что элемент не массива, иначе – в левой. Таким образом, на каждой итерации цикла область поиска сужается, пока не будет найден искомый элемент, либо пока не станет ясно, что он отсутствует в массиве. Если элемент не найден, то функция возвращает значение -1.
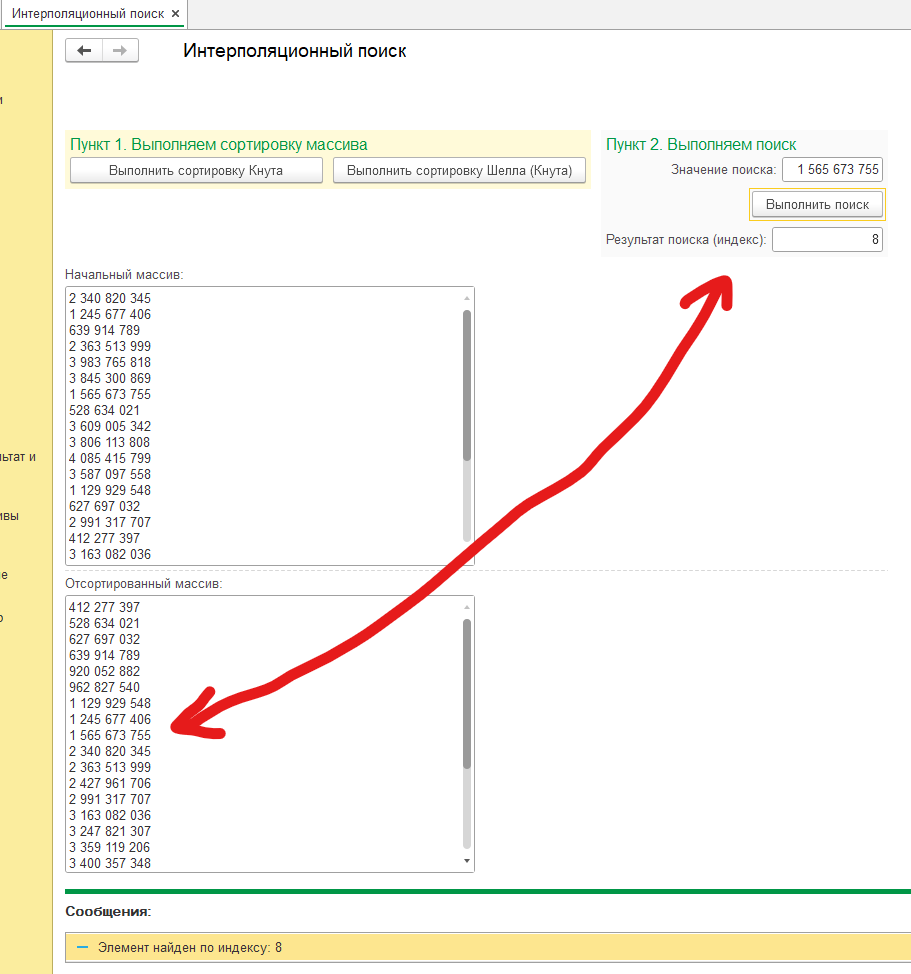
К статье прикладываю обработку реализующую Интерполяционный Поиск, начальный массив задается случайными (рандомными) числами.
Статья про бинарный поиск: Бинарный поиск в 1С: эффективный поиск в упорядоченных данных
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.13.82
Вступайте в нашу телеграмм-группу Инфостарт