


{kind=link}
Блочный поиск в больших массивах: эффективный метод организации и поиска данных
Определение "блочного поиска" в контексте обработки больших массивов данных представляет собой стратегию, направленную на повышение эффективности процесса поиска конкретного элемента. В отличие от традиционных методов, осуществляющих поиск по всему массиву, блочный поиск разбивает массив на упорядоченные блоки. Этот метод предполагает предварительную организацию данных, при которой исходный массив разделяется на последовательные блоки равного или близкого размера, в каждом из которых элементы также могут быть упорядочены, либо по возрастанию, либо по убыванию значений ключа. Основная идея блочного поиска заключается в том, чтобы сначала определить, в каком из блоков может находиться искомый элемент. Это достигается путем последовательного сравнения искомого значения с некоторыми ключевыми характеристиками каждого блока, например, с максимальным или минимальным значением элемента в блоке. После определения подходящего блока, поиск сужается к этому блоку, где уже может быть применен, например, линейный поиск, или если элементы внутри блока отсортированы - бинарный поиск. Преимущество блочного поиска заключается в сокращении количества сравнений, необходимых для нахождения элемента, особенно в больших массивах. Вместо последовательного перебора всех элементов, метод быстро исключает из рассмотрения большинство элементов, концентрируясь лишь на небольшом подмножестве данных. Это существенно снижает вычислительную сложность и время, затрачиваемое на поиск. Эффективность метода во многом зависит от размера блоков и от того, насколько хорошо элементы распределены в каждом блоке. Ключевой фактор – это упорядоченность данных, так как именно она позволяет блочному поиску эффективно исключать ненужные блоки. Блочный поиск предоставляет баланс между простотой реализации и эффективностью, делая его привлекательным для решения задач поиска в различных прикладных областях, где требуется быстрая обработка больших объемов информации. Он особенно полезен в тех случаях, когда данные изменяются относительно редко, и можно позволить себе затраты на предварительную организацию данных. Размер блока представляет собой компромисс между количеством блоков и количеством элементов в каждом блоке, и оптимальный размер блока может зависеть от характеристик конкретного набора данных и вычислительных ресурсов. Разделение данных на блоки позволяет эффективно использовать кэш-память процессора, так как при обработке блока, связанные с ним данные, скорее всего, будут уже загружены в кэш.
История возникновения блочного поиска тесно связана с развитием информатики и необходимостью эффективной обработки больших объемов данных. В период, когда объемы данных начали стремительно расти, возникла потребность в разработке методов, превосходящих по эффективности традиционные алгоритмы поиска, такие как линейный поиск. Линейный поиск, несмотря на свою простоту, оказался неэффективным для больших наборов данных, так как требовал последовательного перебора всех элементов массива. Бинарный поиск, требующий предварительной сортировки данных, предлагал более высокую эффективность, но его реализация была сложнее, а сортировка больших массивов представляла собой ресурсоемкую операцию. Блочный поиск возник как компромисс между этими двумя подходами, предлагая метод, который был проще в реализации, чем бинарный поиск, но обеспечивал достаточную производительность. С ростом объемов данных и расширением возможностей компьютеров, алгоритмы поиска стали широко использоваться для обработки данных, и возникла острая необходимость в эффективных алгоритмах поиска. Потребность в эффективном поиске данных возникала в различных областях, таких как разработка компиляторов, баз данных и поисковых систем. Разработчики программного обеспечения и ученые, где требовалось сбалансировать сложность алгоритма и время поиска. Блочный поиск позволил существенно сократить время, затрачиваемое на поиск, по сравнению с линейным поиском, особенно в случаях, когда данные были упорядочены. Благодаря своей простоте, блочный поиск легколочный поиск нашёл широкое применение в различных областях, где требуется эффективный поиск информации в больших упорядоченных наборах данных. В базах данных, например, этот метод часто используется для индексации данных, ускоряя процесс поиска записей по заданным критериям. Индексы, в свою очередь, организуются в блоки, что позволяет быстро находить блоки, содержащие искомые записи. Это значительно повышает производительность запросов к базе данных, особенно при работе с большими таблицами. Также блочный поиск находит применение в информационно-поисковых системах, где он может использоваться для индексации текстовых документов. Каждый документ разбивается на блоки слов или фраз, и эти блоки организуются в индекс, что позволяет быстро находить документы, содержащие заданные ключевые слова. Такой подход позволяет существенно ускорить процесс поиска, особенно при работе с большими объемами текстовой информации. В компиляторах блочный поиск может использоваться для поиска идентификаторов в таблицах символов. Таблицы символов хранят информацию о переменных, функциях и других элементах программы, и блочный поиск позволяет быстро находить нужные идентификаторы во время компиляции. Это ускоряет процесс компиляции, что особенно важно при работе с большими проектами. Блочный поиск также применяется в системах управления памятью, где он может использоваться для поиска свободных блоков памяти. Когда программа запрашивает память, система использует блочный поиск для поиска подходящего блока, что позволяет быть полезен в научных вычислениях, например, при обработке больших массивов данных, полученных в результате экспериментов. В целом, блочный поиск является универсальным методом, который можно приспособить к различным типам данных и задачам. Его эффективность делает его востребованным инструментом в областяхменимости в различных сценариях. Одним из главных преимуществ блочного поиска является его относительная простота реализации. В отличие от более сложных алгоритмов, таких как бинарный поиск, блочный поиск легко понять и реализовать, что делает его доступным для широкого круга разработчиков. Это снижает затраты времени и ресурсов на разработку и отладку. Блочный поиск обеспечивает хорошую производительность для умеренно больших наборов данных, особенно когда данные организованы в блоки и внутри блоков поддерживается упорядоченность. Он значительно быстрее линейного поиска, поскольку исключает из рассмотрения целые блоки данных. Это позволяет существенно сократить время поиска. Блочный поиск хорошо подходит для динамических данных, когда добавление и удаление элементов происходят часто. Изменение размера блоков, а также добавление или удаление блоков, требует меньших усилий, чем пересортировка всего массива. Это делает его удобным для работы с данными, которые постоянно изменяются. Также блочный поиск эффективно использует кэш-память процессора, поскольку при поиске в блоке данные, связанные с этим блоком, скорее всего, уже находятся в кэше. Это позволяет сократить время доступа к памяти и повысить общую производительность. Однако, у блочного поиска есть и недостатки. Производительность блочного поиска зависит от размера блоков и от того, насколько хорошо данные распределены по блокам. Неоптимальный размер блока может привести к ухудшению производительности. Блочный поиск требует предварительной организации данных, то есть разбиения данных на блоки и, возможно, сортировки элементов внутри блоков. Это может потребовать дополнительных затрат времени и ресурсов. Хотя блочный поиск быстрее, чем линейный, он, как правило, медленнее бинарного поиска, особенно для больших отсортированных наборов данных. В худшем случае, когда искомый элемент находится в последнем блоке, блочный поиск может потребовать перебора всех блоков, что снижает его эффективность. В целом, выбор блочного поиска должен основываться на анализе конкретной задачи, данных и требований к производительности. Блочный поиск является отличным выбором для задач, где важна простота реализации, умеренная производительность и динамичность данных.
Сравнение блочного поиска с другими методами, такими как бинарный поиск и интерполяционный поиск, позволяет выявить сильные и слабые стороны каждого из них. Бинарный поиск является одним из самых эффективных методов поиска в отсортированных массивах. Он работает путем многократного деления области поиска пополам. На каждом шаге алгоритм сравнивает искомое значение со средним элементом текущего диапазона. Если искомое значение меньше среднего, поиск продолжается в левой половине диапазона; если больше – в правой. Этот процесс повторяется до тех пор, пока искомый элемент не будет найден или диапазон не станет пустым. Преимущества бинарного поиска включают высокую эффективность, особенно для больших отсортированных массивов, и гарантированное логарифмическое время поиска (O(log n)). Недостатки бинарного поиска заключаются в необходимости предварительной сортировки данных, что может потребовать дополнительных затрат времени и ресурсов, и в более сложной реализации по сравнению с блочным поиском. Интерполяционный поиск является методом поиска, который пытается улучшить производительность бинарного поиска, используя информацию о распределении значений в массиве. Вместо деления области поиска пополам, интерполяционный поиск использует формулу для оценки положения искомого элемента в массиве, основываясь на его значении и значениях крайних элементов текущего диапазона. Преимущества интерполяционного поиска заключаются в его потенциальной эффективности, особенно для равномерно распределенных данных, и в меньшем количестве шагов поиска по сравнению с бинарным поиском. Недостатки интерполяционного поиска включают его чувствительность к распределению данных, худшую производительность для неравномерно распределенных данных и более сложную реализацию по сравнению с бинарным и блочным поисками. Блочный поиск, в отличие от бинарного и интерполяционного, не требует полной сортировки массива. Он требует только упорядочивания блоков и, возможно, сортировки элементов внутри блоков. Это делает его более подходящим для динамических данных, где добавление и удаление элементов происходит часто. Блочный поиск, как правило, менее эффективен, чем бинарный поиск для полностью отсортированных данных, но проще в реализации. Интерполяционный поиск может быть более эффективным, чем блочный поиск, для равномерно распределенных данных, но его производительность хуже для неравномерно распределенных данных. Выбор между этими методами зависит от конкретной задачи, характеристик данных и требований к производительности. Бинарный поиск является лучшим выбором для полностью отсортированных данных, а интерполяционный поиск подходит для равномерно распределенных данных. Блочный поиск является хорошим компромиссом между простотой реализации и производительностью, особенно для динамических данных.
Применение блочного поиска в "1С:Предприятие" имеет свои особенности, обусловленные спецификой платформы и задачами, решаемыми на её базе. В первую очередь, стоит отметить, что "1С:Предприятие" – это среда разработки, ориентированная на автоматизацию бизнес-процессов, управление данными и учет. В контексте этой платформы блочный поиск может быть полезен в нескольких сценариях. Одним из примеров является поиск данных в больших таблицах базы данных. Например, при работе с большими объемами информации о клиентах, товарах или финансовых операциях, блочный поиск может быть использован для ускорения процесса поиска. Для этого можно разбить таблицу на блоки, отсортировать блоки по определенным критериям (например, по наименованию клиента, коду товара) и использовать блочный поиск для быстрого нахождения нужных записей. Другой пример – это поиск информации в больших справочниках. В "1С:Предприятие" справочники используются для хранения различных типов данных, таких как номенклатура, контрагенты, сотрудники и т.д. Если справочник содержит большое количество элементов, блочный поиск может быть применен для ускорения поиска по заданным критериям, таким как наименование, код, или другие атрибуты элемента. Для реализации блочного поиска в "1С:Предприятие”" можно использовать встроенный язык, позволяющий создавать и управлять структурами данных, а также выполнять операции поиска и сортировки. Например, можно создать массив, представляющий собой блоки данных, и использовать циклы и условные операторы для реализации алгоритма блочного поиска. и выбрать оптимальный размер блоков и алгоритм сортировки. В целом, применение блочного поиска в "1С:Предприятие" может быть полезным инструментом для повышения производительности при работе с большими объемами данных. Он может быть особенно эффективным при работе с динамическими данными, когда часто требуется добавление, удаление или изменение элементов. Применение блочного поиска требует понимания особенностей платформы "1С:Предприятие", а также умения эффективно использовать встроенный язык и методы работы с базами данных.
&НаСервере
Процедура ВыполнитьПоискНаСервере()
// Получаем массив и искомое значение из формы
Массив = ПолучитьИзВременногоХранилища(Объект.СлучайныйМассив);
ИскомоеЗначение = Объект.ИскомоеЗначение;
// Проверяем, что массив не пустой и искомое значение задано
Если Массив = Неопределено ИЛИ ТипЗнч(Массив) <> Тип("Массив") Тогда
Объект.Индексы = "Ошибка: Не сгенерирован массив!";
Возврат;
КонецЕсли;
Если ИскомоеЗначение = Неопределено ИЛИ ПустаяСтрока(Строка(ИскомоеЗначение)) Тогда
Объект.Индексы = "Ошибка: Не указано искомое значение!";
Возврат;
КонецЕсли;
// Выполняем блочный поиск
ИндексыВхождений = Новый Массив;
РазмерБлока = Окр(SQRT(Массив.Количество())); // Оптимальный размер блока
Для НомерБлока = 0 По Окр((Массив.Количество() - 1) / РазмерБлока,0) Цикл
НачалоБлока = НомерБлока * РазмерБлока;
КонецБлока = Мин((НомерБлока + 1) * РазмерБлока - 1, Массив.Количество() - 1);
// Проверяем, может ли искомое значение быть в блоке (если хотя бы один элемент в блоке МОЖЕТ быть равен искомому)
НашлиПотенциально = Ложь;
Для ИндексПроверки = НачалоБлока По КонецБлока Цикл
Если Массив[ИндексПроверки] = ИскомоеЗначение Тогда
НашлиПотенциально = Истина;
Прервать;
КонецЕсли;
КонецЦикла;
Если НашлиПотенциально Тогда
// Линейный поиск внутри блока
Для Индекс = НачалоБлока По КонецБлока Цикл
Если Массив[Индекс] = ИскомоеЗначение Тогда
ИндексыВхождений.Добавить(Индекс);
КонецЕсли;
КонецЦикла;
КонецЕсли;
КонецЦикла;
// Формируем строку с индексами
ТекстИндексов = "";
Для Каждого Индекс Из ИндексыВхождений Цикл
ТекстИндексов = ТекстИндексов + Индекс + Символы.ПС;
КонецЦикла;
Объект.Индексы = ТекстИндексов;
КонецПроцедуры
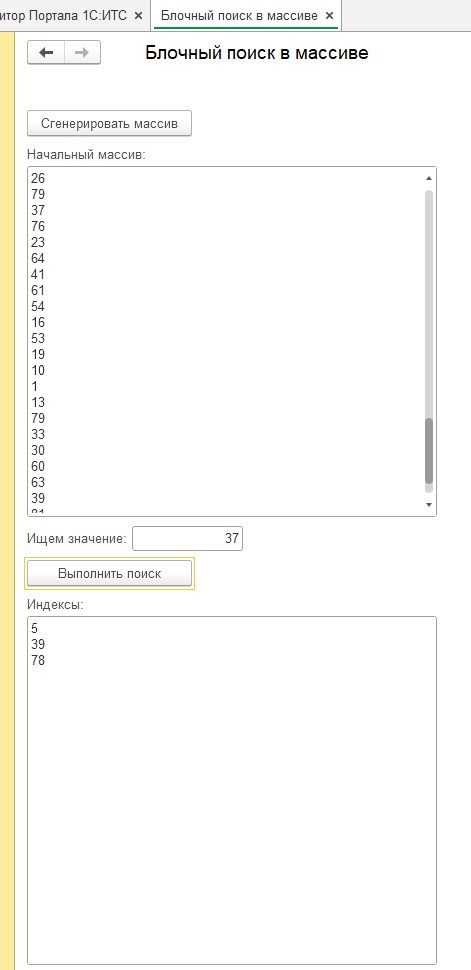
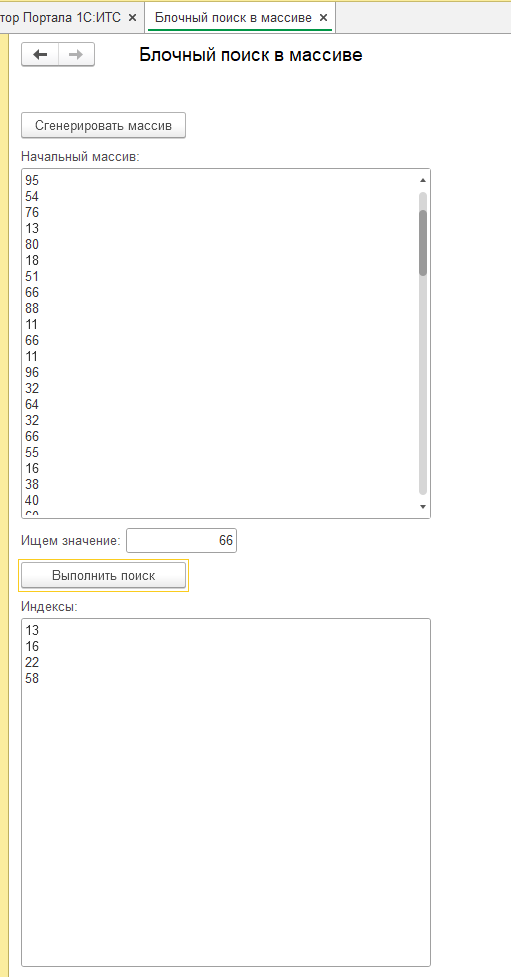
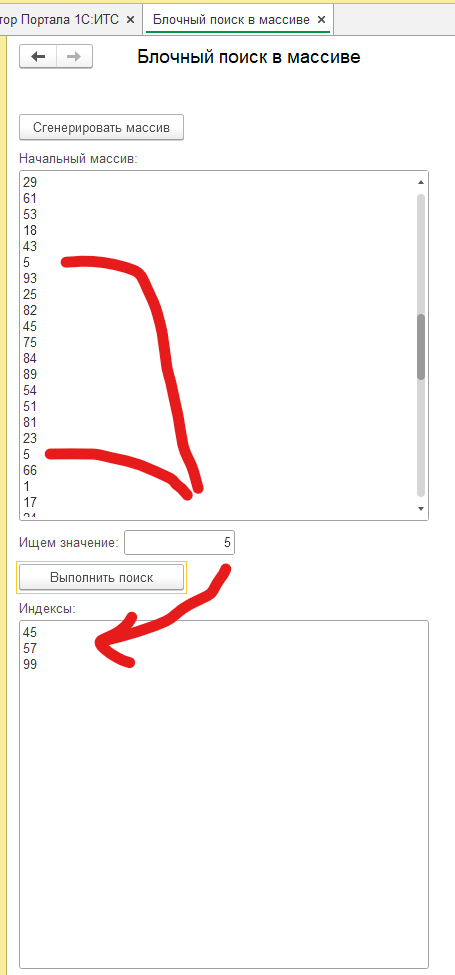
В представленной серверной процедуре реализован алгоритм блочного поиска, предназначенный для обнаружения индексов вхождений заданного значения в предварительно созданном массиве данных. Для обеспечения репрезентативности поиска, в качестве начальных данных используется массив, состоящий из ста элементов, заполненных посредством генератора случайных чисел. Это позволяет имитировать реальные условия, когда данные распределены неравномерно и содержат повторяющиеся значения. При этом, для усложнения задачи и демонстрации работы алгоритма в условиях неоднозначности, значения нескольких элементов в массиве намеренно устанавливаются одинаковыми.
Прежде чем приступить к непосредственному поиску, процедура выполняет ряд проверок для обеспечения корректности входных данных. В частности, она убеждается, что массив не является пустым и соответствует типу "Массив", а также что искомое значение задано и не является пустой строкой. В случае, если какая-либо из этих проверок не проходит, процедура присваивает соответствующее сообщение об ошибке реквизиту формы и завершает свою работу, сигнализируя о невозможности выполнения поиска.
Основная идея блочного поиска заключается в разделении исходного массива на блоки определенного размера и последовательном просмотре этих блоков. Размер блока выбирается таким образом, чтобы минимизировать общее время поиска. В данном случае, в процедуре используется эвристическая оценка размера блока, равная квадратному корню из количества элементов в массиве. Это позволяет достичь баланса между количеством блоков и временем, затрачиваемым на просмотр каждого блока.
Для каждого блока алгоритм сначала проверяет, может ли искомое значение потенциально находиться в данном блоке. Для этого осуществляется последовательный просмотр элементов блока и сравнение их с искомым значением. Если в блоке обнаруживается хотя бы один элемент, равный искомому значению, это означает, что искомое значение может присутствовать в данном блоке, и алгоритм переходит к следующему этапу. В противном случае, если в блоке не найдено ни одного элемента, равного искомому значению, алгоритм пропускает данный блок и переходит к следующему.
Если на предыдущем этапе было установлено, что искомое значение может присутствовать в блоке, то внутри данного блока выполняется линейный поиск. Линейный поиск заключается в последовательном просмотре всех элементов блока и сравнении их с искомым значением. В случае, если элемент блока равен искомому значению, его индекс добавляется в массив индексов вхождений. Таким образом, после просмотра всех блоков формируется массив, содержащий индексы всех элементов исходного массива, равных искомому значению.
После завершения поиска процедура формирует строку, содержащую индексы всех найденных вхождений искомого значения. Индексы разделяются символами перевода строки для обеспечения удобства чтения. Сформированная строка присваивается реквизиту формы, что позволяет отобразить результаты поиска в пользовательском интерфейсе.
Таким образом, представленная серверная процедура реализует эффективный алгоритм блочного поиска, который позволяет быстро находить индексы всех вхождений заданного значения в массиве данных. Алгоритм сочетает в себе преимущества блочного подхода, позволяющего сократить количество просматриваемых элементов, и линейного поиска, обеспечивающего полноту результатов. Проверки входных данных и обработка возможных ошибок делают процедуру надежной и устойчивой к некорректным данным. Полученные результаты поиска представляются в удобном для пользователя формате, что облегчает их анализ и использование. В целом, данная процедура представляет собой полезный инструмент для решения задач поиска в "1С:Предприятие".
Готовый пример в приложенной обработке.
Внимание! : код прост для понимания даже начинающему программисту, никаких сложных процедур, должно работать в любой 1с 8.3!
Другие статьи:
Бинарный поиск в 1С: эффективный поиск в упорядоченных данных
Интерполяционный поиск: как ускорить поиск в больших массивах 1С
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.13.82
Вступайте в нашу телеграмм-группу Инфостарт