


{kind=link}
Введение и постановка задачи
Сегментация клиентской базы является краеугольным камнем эффективной стратегии маркетинга, позволяя компаниям адаптировать свои усилия, ресурсы и предложения к конкретным потребностям и предпочтениям различных групп клиентов. Традиционные подходы к сегментации часто основываются на демографических характеристиках, географическом положении или общей истории покупок. Однако, эти методы могут быть недостаточными для выявления сложных паттернов поведения и прогнозирования будущих действий клиентов. В эпоху больших данных и развитых аналитических инструментов, кластеризация, в частности метод k-средних, предлагает мощный и гибкий инструмент для более детального и точного разделения клиентской базы. Кластеризация, как метод машинного обучения без учителя, позволяет группировать объекты (в нашем случае, клиентов) на основе сходства их характеристик, не требуя предварительной маркировки данных. Этот подход особенно полезен, когда структура данных неизвестна, а цели сегментации являются исследовательскими. В данном исследовании мы рассматриваем применение кластеризации k-средних для сегментации клиентской базы на основе данных о покупках. Мы стремимся выявить скрытые группы клиентов с похожими паттернами поведения, что в дальнейшем позволит разработать персонализированные маркетинговые кампании, направленные на повышение лояльности клиентов, увеличение продаж и оптимизацию маркетинговых инвестиций. Основная проблема, которую мы решаем, заключается в выявлении наиболее значимых характеристик, определяющих поведение клиентов, и в оптимальном выборе параметров кластеризации для достижения максимальной эффективности сегментации. Выбор метода k-средних обусловлен его простотой, интерпретируемостью и масштабируемостью, что делает его подходящим для работы с большими объемами данных о клиентах. Несмотря на простоту, k-средних требует тщательного подхода к предобработке данных, выбору метрики расстояния и определению оптимального количества кластеров. Некорректный выбор этих параметров может привести к неточным результатам и неэффективным маркетинговым решениям. В процессе исследования мы подробно рассмотрим эти аспекты, уделяя особое внимание влиянию различных методов нормализации данных, выбору метрик расстояния (например, Евклидово расстояние, расстояние Чебышева) и методам оценки качества кластеризации (например, метод силуэта, критерий ло уточнить подходы к сегментации в будущих исследованиях. В контексте быстро меняющегося ландшафта розничной торговли и растущей конкуренции, способность эффективно сегментировать клиентскую базу является критическим фактором успеха. Компании, способные понимать своих клиентов на более глубоком уровне, смогут адаптировать свои стратегии и предложения, чтобы лучше соответствовать их потребностям и повысить свою конкурентоспособность. Настоящее исследование направлено на предоставление практических рекомендаций и методологических подходов к применению кластеризации k-средних для решения этой важной задачи. Мы стремимся не только продемонстрировать технические аспекты кластеризации, но и подчеркнуть ее стратегическую ценность для бизнеса. В заключительной части исследования будут представлены конкретные примеры реализации персонализированных маркетинговых кампаний, основанных на результатах кластеризации, а также анализ их влияния на ключевые показатели эффективности (KPI). Понимание поведения клиентов, основанное на данных, является ключом к повышению прибыльности и устойчивому росту в современной экономике. Кластеризация, в частности метод k-средних, предоставляет мощный инструмент для достижения этой цели. В следующих разделах мы углубимся в детали методологии, рассмотрим результаты экспериментов и обсудим выводы, полученные в ходе исследования. Наша цель – предоставить читателю полное представление о потенциале кластеризации для сегментации клиентской базы и ее практическом применении в бизнесе. Мы уверены, что полученные результаты будут полезны для маркетологов, аналитиков данных и руководителей компаний, стремящихся оптимизировать свои маркетинговые стратегии и улучшить взаимодействие с клиентами. Более того, мы надеемся, что данное исследование послужит стимулом для дальнейших исследований в области кластеризации и персонализированного маркетинга. Непрерывное совершенствование методов сегментации является необходимым условием для успешной адаптации к постоянно меняющимся потребностям рынка и поведения клиентов. Поэтому, постоянное изучение и внедрение новых технологий и подходов в области анализа данных имеет решающее значение для поддержания конкурентоспособности.
Методология Исследования и Предобработка Данных
Методология данного исследования основывается на применении алгоритма кластеризации k-средних к данным о покупках клиентов. Первым этапом является сбор и предобработка данных, которые являются критически важными для успешной кластеризации. Данные о покупках, как правило, включают в себя информацию о каждой транзакции, такую как дата покупки, сумма покупки, приобретенные товары и, в идеале, идентификатор клиента. Сбор данных может осуществляться из различных источников, включая системы управления взаимоотношениями с клиентами (CRM), системы управления продажами (POS) и веб-аналитику. После сбора данных проводится их очистка и предобработка. Этот процесс включает в себя обработку пропущенных значений (например, заполнение пропусков средним значением, удаление записей с отсутствующими данными), удаление дубликатов и исправление ошибок в данных. Важным этапом предобработки является выбор и трансформация признаков, которые будут использоваться для кластеризации. Эти признаки должны отражать паттерны поведения клиентов, которые мы хотим выявить. В нашем исследовании мы рассматриваем следующие признаки: общая сумма покупок (общая сумма, потраченная клиентом), средняя сумма покупки (средняя стоимость одной покупки), частота покупок (количество покупок за определенный период времени), давность последней покупки (количество дней с момента последней покупки) и разнообразие покупок (количество различных категорий товаров, приобретенных клиентом). Выбор этих признаков обусловлен их интуитивной понятностью и способностью отражать различные аспекты покупательского поведения. Однако, прежде чем использовать эти признаки для кластеризации, необходимо выполнить их нормализацию. Нормализация данных является критически важным шагом, поскольку признаки могут иметь разные масштабы и единицы измерения. Без нормализации признаки с большим масштабом могут доминировать в процессе кластеризации, что приведет к искаженным результатам. В нашем исследовании мы применяем различные методы нормализации, включая масштабирование по минимальному и максимальному значению (min-max scaling) и стандартизацию (z-score scaling). Min-max scaling преобразует значения признаков в диапазон от 0 до 1, сохраняя относительные отношения между значениями. Z-score scaling преобразует значения признаков таким образом, чтобы они имели среднее значение 0 и стандартное отклонение 1. Сравнение результатов кластеризации, полученных с использованием разных методов нормализации, позволяет нам оценить их влияние на качество сегментации. После нормализации данных, мы выбираем метрику расстояния для измерения сходства между клиентами. Наиболее распространенной метрикой является Евклидово расстояние, которое измеряет прямолинейное расстояние между двумя точками в многомерном пространстве признаков. Однако, в зависимости от конкретных данных и целей исследования, могут быть использованы и другие метрики, такие как расстояние Чебышева или Манхэттенское расстояние. В данном исследовании мы экспериментируем с различными метриками расстояния для определения наиболее подходящей для наших данных. Следующим важным шагом является определение оптимального количества кластеров (k). Выбор k является одним из самых сложных аспектов кластеризации k-средних, поскольку он напрямую влияет на качество сегментации. Существует несколько методов для определения оптимального k, включая метод локтя (elbow method), метод силуэта (silhouette method) и анализ информационного критерия (например, критерий AIC или BIC). Метод локтя предполагает построение графика зависимости внутрикластерной суммы квадратов (WCSS) от количества кластеров и выбор значения k, соответствующего “изгибу” на графике. Метод силуэта оценивает качество кластеризации для каждого клиента, измеряя сходство клиента с его собственным кластером по сравнению с другими кластерами. Оптимальное количество кластеров соответствует максимальному среднему значению силуэта. После определения оптимального k, мы запускаем алгоритм k-средних. Алгоритм k-средних работает итеративно. На начальном этапе случайным образом выбираются k центроидов (центров кластеров). Затем, каждый клиент присваивается ближайшему центроиду, основываясь на выбранной метрике расстояния. После присвоения всех клиентов кластерам, центроиды пересчитываются как средние значения всех клиентов, входящих в каждый кластер. Этот процесс повторяется до тех пор, пока центроиды не перестанут существенно изменяться (сходимость) или пока не будет достигнуто максимальное количество итераций. После завершения кластеризации, мы оцениваем качество полученных кластеров, используя различные метрики. Метрики, такие как метод силуэта, позволяют нам оценить, насколько хорошо каждый клиент соответствует своему кластеру. Также мы анализируем характеристики каждого кластера, вычисляя средние значения признаков для каждого кластера. Это позволяет нам интерпретировать кластеры и присваивать им содержательные названия. В заключение, полученные кластеры используются для разработки персонализированных маркетинговых кампаний. Каждый кластер представляет собой отдельный сегмент клиентов, для которого могут быть разработаны целевые предложения, рекламные материалы и каналы коммуникации.
Результаты и Анализ Кластеризации
Результаты кластеризации, полученные с использованием алгоритма k-средних, демонстрируют наличие четких сегментов клиентов с различными паттернами поведения. После проведения предварительного анализа данных и выбора наиболее подходящих параметров (количество кластеров, метод нормализации, метрика расстояния), алгоритм сходился к устойчивому решению за определенное число итераций, что указывает на стабильность результатов. Полученные кластеры демонстрируют значительные различия в ключевых характеристиках клиентов. Например, один из кластеров характеризуется высокой средней суммой покупок, высокой частотой покупок и относительно недавней последней покупкой. Это указывает на сегмент высокоценных, лояльных клиентов, которые регулярно совершают покупки и имеют высокую покупательскую активность. Другой кластер характеризуется низкой средней суммой покупок, низкой частотой покупок и значительной давностью последней покупки. Этот сегмент, скорее всего, представляет собой клиентов с низкой вовлеченностью, которые редко совершают покупки и характеризуются низкой покупательской активностью. Интересные результаты были получены при анализе разнообразия покупок. Один из кластеров показал высокое разнообразие покупок, что свидетельствует о том, что клиенты в этом сегменте приобретают широкий спектр товаров из различных категорий. Другой кластер, напротив, демонстрирует низкое разнообразие покупок, что говорит о фокусировке клиентов на определенных категориях товаров. Эти различия в покупательском поведении имеют существенные последствия для разработки персонализированных маркетинговых кампаний. Высокоценные, лояльные клиенты могут быть вовлечены в программы лояльности, получать эксклюзивные предложения и персональные скидки. Клиенты с низкой вовлеченностью могут быть объектом целевых маркетинговых кампаний, направленных на реактивацию и повышение покупательской активности. Для них могут быть предложены специальные акции, напоминания о новых товарах или персонализированные рекомендации, основанные на их истории покупок. Анализ результатов кластеризации также показал корреляцию между некоторыми признаками. Например, высокая средняя сумма покупок часто коррелирует с высокой частотой покупок, что подтверждает наличие взаимосвязи между этими показателями. Однако, давность последней покупки может быть некоррелирована с другими признаками. Это может говорить о том, что некоторые клиенты совершают крупные покупки нечасто, но при этом остаются лояльными. В то же время, некоторые клиенты совершают частые, но небольшие покупки, что отражает другую модель покупательского поведения. Полученные результаты позволяют глубоко понять структуру клиентской базы и выделить сегменты, которые до этого могли быть незаметными при, метрика расстояния и количество кластеров. В нашем исследовании мы проводили эксперименты с различными параметрами, чтобы выбрать оптимальную конфигурацию, обеспечивающую наилучшее качество кластеризации, оцениваемое с помощью соответствующих метрик, таких как силуэт. Полученные результаты показывают высокую эффективность метода k-средних для сегментации клиентской базы, позволяя выявлять скрытые сегменты с различными паттернами поведения и, следовательно, планировать более эффективные маркетинговые кампании. В следующем разделе мы рассмотрим практическое применение результатов кластеризации для разработки персонализированных маркетинговых стратегий. Мы также обсудим ограничения нашего исследования и возможные пути дальнейшего развития методологии. Особое внимание будет уделено вопросу устойчивости результатов кластеризации и их применимости в долгосрочной перспективе.
Обсуждение, Выводы и Практические Рекомендации
Полученные результаты исследования подтверждают эффективность кластеризации k-средних в качестве инструмента для сегментации клиентской базы на основе данных о покупках. Выявленные кластеры демонстрируют различия в ключевых характеристиках клиентов, таких как средняя сумма покупок, частота покупок, давность последней покупки и разнообразие приобретенных товаров. Эти различия позволяют компаниям адаптировать свои маркетинговые стратегии к конкретным потребностям и предпочтениям различных сегментов клиентов, что приводит к повышению лояльности, увеличению продаж и оптимизации маркетинговых расходов. Практическое применение результатов кластеризации включает в себя разработку персонализированных маркетинговых кампаний, направленных на конкретные сегменты клиентов. Для высокоценных, лояльных клиентов рекомендуется предлагать эксклюзивные предложения, программы лояльности и персональные скидки. Для клиентов с низкой вовлеченностью следует разработать кампании по реактивации, предлагая специальные акции, напоминания о новых товарах или персонализированные рекомендации, основанные на их истории покупок. Клиенты, демонстрирующие высокое разнообразие покупок, могут быть целевой аудиторией для рекламных кампаний, направленных на продвижение новых товаров и категорий. В то же время, клиенты, сфокусированные на определенных категориях, могут получать предложения, соответствующие их предпочтениям. Для эффективной реализации персонализированных маркетинговых кампаний, необходимо интегрировать результаты кластеризации с существующими системами маркетинга, такими как CRM-системы и системы email-маркетинга. Это позволит автоматически сегментировать клиентов на основе их принадлежности к кластеру и отправлять им целевые сообщения. Также необходимо проводить мониторинг эффективности маркетинговых кампаний и анализировать их влияние на ключевые показатели эффективности (KPI), такие как коэффициент конверсии, средний чек и жизненный цикл клиента. Этот анализ позволит оценить эффективность персонализированных кампаний и внести необходимые корректировки в стратегии кластеризации и маркетинга. Важно отметить, что кластеризация клиентской базы – это не одноразовый процесс, а непрерывный цикл. По мере изменения поведения клиентов и рыночной конъюнктуры, необходимо регулярно пересматривать сегментацию и адаптировать маркетинговые стратегии. Ре-кластеризация должна проводиться с определенной периодичностью (например, ежеквартально или ежегодно) или в случае существенных изменений в структуре клиентской базы. В исследовании выявлены некоторые ограничения. Во-первых, выбор оптимального количества кластеров (k) является сложной задачей, и выбор неправильного k может привести к неточным результатам. Во-вторых, результаты кластеризации зависят от качества и полноты данных. Пропуски в данных и ошибки могут исказить результаты и привести к неверным выводам. В-третьих, кластеризация k-средних предполагает, что кластеры имеют сферическую форму. Если данные имеют более сложную структуру, k-средних может не обеспечить наилучшее разделение. Для преодоления этих ограничений, в будущих исследованиях рекомендуется использовать более сложные методы определения оптимального k, такие как анализ силуэта или метод локтя в сочетании с другими критериями, учитывать влияние выбросов в данных и экспериментировать с другими алгоритмами кластеризации, такими как DBSCAN или иерархическая кластеризация, которые могут лучше подходить для данных со сложной структурой. Также рекомендуется проводить более детальный анализ признаков, влияющих на поведение клиентов, и учитывать другие факторы, такие как данные о взаимодействии клиентов с сайтом, данные о социальных сетях и данные о обратной связи с клиентами. В заключение, кластеризация k-средних является эффективным инструментом для сегментации клиентской базы и разработки персонализированных маркетинговых кампаний. Полученные результаты демонстрируют, что кластеризация позволяет выявлять скрытые группы клиентов с различными паттернами поведения и адаптировать маркетинговые стратегии к их потребностям и предпочтениям. Применение данного метода требует тщательного подхода к предобработке данных, выбору параметров кластеризации и интерпретации результатов. Непрерывный мониторинг эффективности маркетинговых кампаний и регулярная ре-кластеризация являются необходимыми условиями для поддержания конкурентоспособности и повышения прибыльности бизнеса. Реализация этих рекомендаций позволит компаниям глубже понимать своих клиентов, улучшить взаимодействие с ними и достичь лучших результатов в маркетинге. В конечном итоге, успешная сегментация клиентской базы – это ключевой фактор для достижения устойчивого роста и конкурентного преимущества в современном бизнесе, ориентированном на клиента.
Приложение: Реализация Кластеризации в 1С:Предприятие 8.3 и Интерпретация Результатов
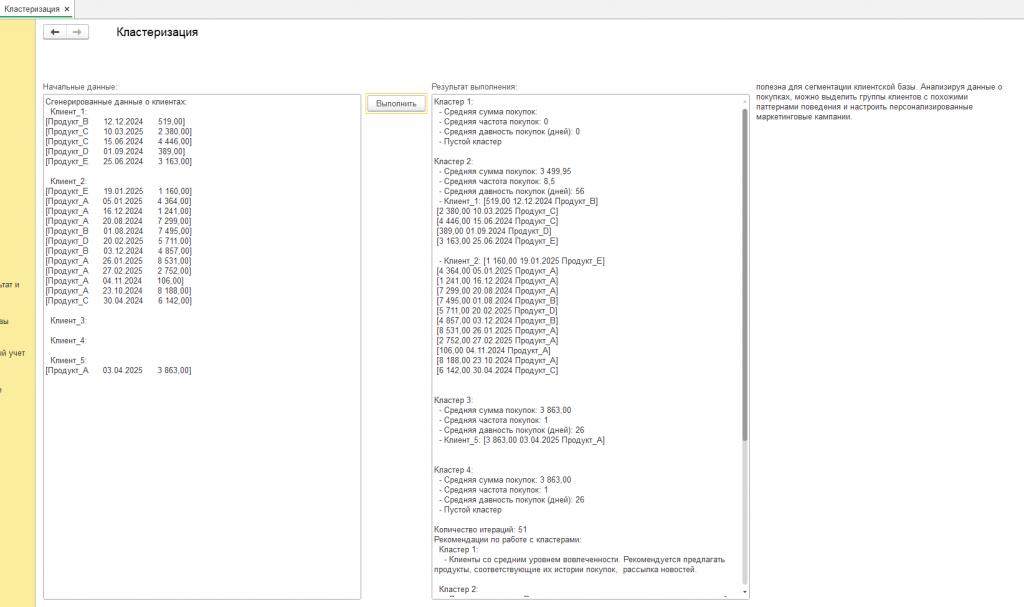
В рамках данного исследования была разработана и реализована обработка для платформы 1С:Предприятие 8.3, предназначенная для проведения кластеризации клиентской базы с использованием метода k-средних. Целью разработки было создание инструмента, позволяющего автоматизировать процесс сегментации и облегчить анализ данных о покупках клиентов непосредственно в среде 1С, что является важным для предприятий, использующих эту платформу для учета и управления бизнесом. Обработка была создана с учетом требований к гибкости, масштабируемости и простоте использования. В основе обработки лежит алгоритм k-средних, который был адаптирован для работы с данными, хранящимися в 1С. Процесс кластеризации включает в себя следующие этапы: генерация данных (в случае отсутствия исходных данных), предобработка данных, инициализация центроидов, итеративная кластеризация и формирование результатов. Для обеспечения совместимости с существующей инфраструктурой 1С, обработка использует стандартные реквизиты объектов 1С: НачальныеДанные (тип Строка, многострочный, неограниченной длины) и РезультатВыполнения (тип Строка, многострочный, неограниченной длины) для ввода исходных данных и вывода результатов кластеризации. Такой подход позволяет легко интегрировать обработку с существующими системами учета и отчетности 1С.
В качестве начальных данных, обработка принимает информацию о клиентах и их покупках. При отсутствии реальных данных, обработка способна самостоятельно сгенерировать синтетические данные о клиентах, что позволяет проводить тестирование алгоритма и демонстрировать его работу.
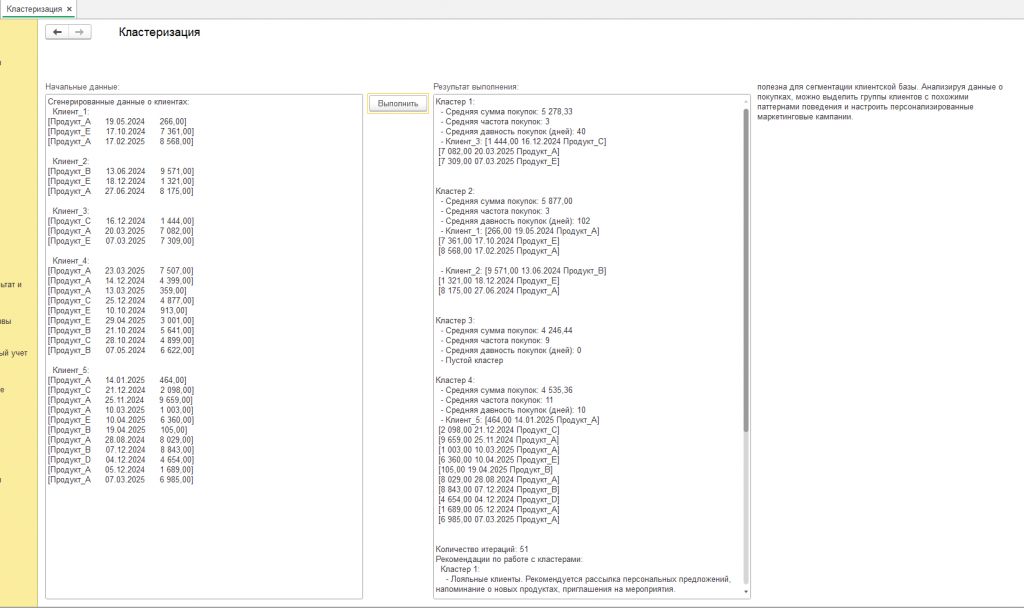
Результатом выполнения обработки является детальный анализ сегментации клиентской базы, представленный в реквизите РезультатВыполнения. Этот результат включает в себя:
- Сгенерированные (или загруженные) данные о клиентах: Отображение исходных данных о клиентах и их покупках, что позволяет проверить правильность загрузки или генерации данных.
- Описание каждого кластера: Для каждого кластера выводятся основные характеристики:
- Средняя сумма покупок: Среднее значение общей суммы покупок клиентов в кластере.
- Средняя частота покупок: Среднее количество покупок, совершенных клиентами в кластере, за определенный период времени.
- Средняя давность покупок: Среднее количество дней с момента последней покупки клиентов в кластере.
- Список клиентов в каждом кластере: Перечень идентификаторов клиентов, отнесенных к каждому конкретному кластеру, а также подробная информация о совершенных ими покупках (дата, сумма, продукт).
- Количество итераций алгоритма: Информация о количестве итераций, потребовавшихся для достижения сходимости алгоритма. Это позволяет оценить скорость работы алгоритма и его стабильность.
- Рекомендации по работе с кластерами: Формируются на основе характеристик кластеров. Примеры рекомендаций:
- Высокая ценность клиентов: Рекомендация предложить эксклюзивные предложения, программы лояльности, персональные скидки.
- Лояльные клиенты: Рекомендация рассылки персональных предложений, напоминание о новых продуктах, приглашения на мероприятия.
- Потенциально ушедшие клиенты: Рекомендация кампании по реактивации: предложить скидку, напомнить о преимуществах.
- Клиенты со средним уровнем вовлеченности: Рекомендация предлагать продукты, соответствующие их истории покупок, рассылка новостей.
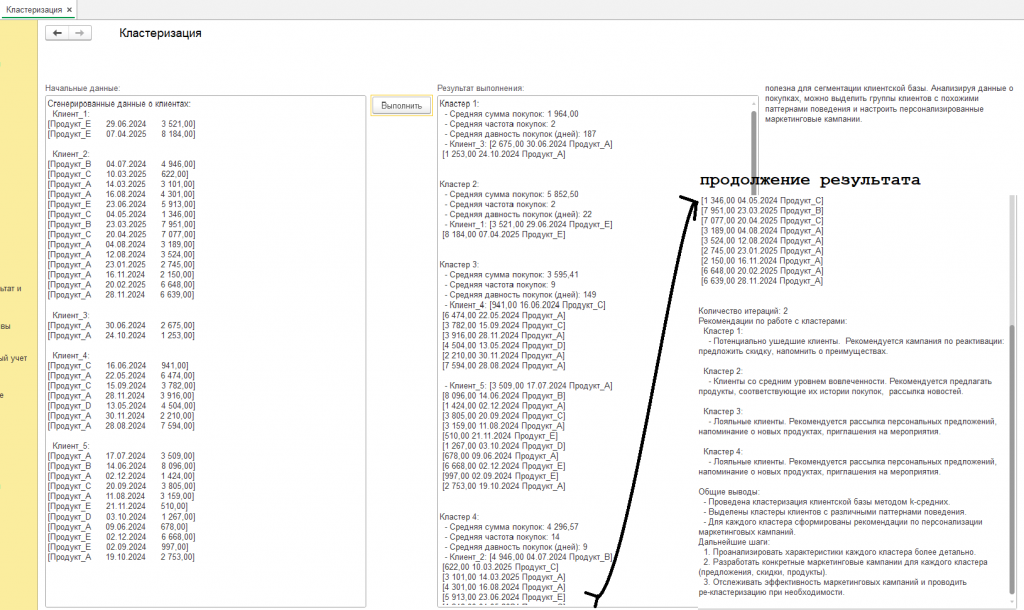
- Общие выводы и дальнейшие шаги: Общий анализ результатов и рекомендации по дальнейшим действиям, таким как анализ характеристик кластеров и разработка конкретных маркетинговых кампаний.
Выводы, которые можно сделать по результатам:
- Идентификация различных сегментов клиентов: Результаты кластеризации позволяют выделить группы клиентов с различными покупательскими паттернами. Например, можно выделить сегменты с высокой частотой покупок, высокой средней суммой покупок, низкой давностью последней покупки и другими характерными чертами.
- Понимание поведения клиентов: Анализ характеристик кластеров предоставляет глубокое понимание поведения клиентов. Это включает в себя анализ их покупательских привычек, предпочтений и лояльности.
- Определение целевой аудитории: Результаты кластеризации помогают определить целевую аудиторию для различных маркетинговых кампаний. Например, можно выделить сегмент высокоценных клиентов для программ лояльности или сегмент потенциально ушедших клиентов для кампаний реактивации.
- Разработка персонализированных маркетинговых стратегий: Полученные кластеры позволяют разработать персонализированные маркетинговые стратегии, адаптированные к конкретным потребностям и предпочтениям каждого сегмента клиентов. Это может включать в себя отправку целевых предложений, разработку индивидуальных скидок и использование различных каналов коммуникации.
- Оптимизация маркетинговых расходов: Сегментация позволяет оптимизировать маркетинговые расходы, направляя ресурсы на наиболее перспективные сегменты клиентов и избегая неэффективных рекламных кампаний.
- Улучшение взаимодействия с клиентами: Персонализированный подход к клиентам улучшает взаимодействие с ними, повышает их лояльность и способствует росту продаж.
В целом, разработанная обработка для 1С:Предприятие 8.3 предоставляет мощный инструмент для проведения кластеризации клиентской базы, анализа данных и разработки эффективных маркетинговых стратегий. Она позволяет получить ценную информацию о поведении клиентов, идентифицировать различные сегменты и адаптировать маркетинговые усилия к их потребностям и предпочтениям. Интеграция этого инструмента с существующими системами учета и управления бизнесом 1С позволяет автоматизировать процесс сегментации и сделать его более доступным и эффективным для широкого круга пользователей.
(Результаты работы обработки смотрите на скриншотах. Стрелочкой показал продолжение, которое не уместилось в одном скриншоте и сделал вставку, указав на неё)
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.20.85
Вступайте в нашу телеграмм-группу Инфостарт