



{kind=link}
Представьте, что вы работаете в службе поддержки крупной компании и хотите автоматизировать процесс определения приоритета обращений клиентов. У вас есть данные о тысячах обращений: тема обращения, срочность, тип клиента (обычный, премиум), предыдущая история обращений клиента, оценка удовлетворенности клиента, и, самое главное, информация о том, насколько быстро было решено каждое обращение. Как вам, как аналитику службы поддержки, понять, какие факторы наиболее важны для определения приоритета новых обращений и обеспечения быстрого и качественного решения проблем клиентов?
В этом случае логистическая регрессия становится вашим незаменимым инструментом для автоматизации принятия решений. Это как если бы у вас был интеллектуальный ассистент, который может мгновенно оценить важность каждого обращения и направить его к наиболее компетентному специалисту, гарантируя, что ни один клиент не останется без внимания.
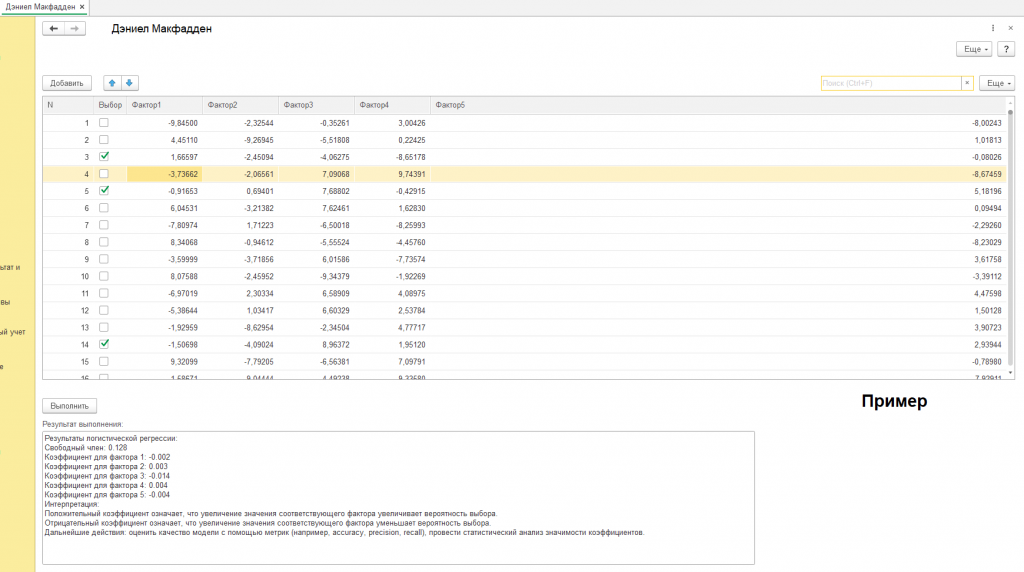
В нашем примере мы имитируем ситуацию (см. скриншот с подписью "пример"), когда у нас есть данные о 1000 обращениях (или, как мы их назвали в коде, “записей”), и для каждого обращения известно, было ли оно решено быстро (в течение определенного времени) (“да”) или нет (“нет”). Мы также предполагаем, что на скорость решения обращения влияют 5 различных факторов. Эти факторы могут быть любыми из тех, что я перечислил выше: тема обращения, срочность, тип клиента, история обращений, оценка удовлетворенности. Важно понимать, что это лишь упрощенная модель, и в реальности факторов, влияющих на скорость решения обращения, может быть гораздо больше.
Что же мы задали в начальных данных?
“КоличествоЗаписей = 1000” означает, что мы создали 1000 виртуальных обращений клиентов, и для каждого обращения мы знаем, было ли оно решено быстро или нет. Это как если бы мы собрали данные о 1000 реальных обращениях и зафиксировали, какие из них были решены в срок.
“КоличествоФакторов = 5” означает, что мы предположили, что на скорость решения обращения у каждого из этих 1000 обращений влияют 5 различных факторов. Значения этих факторов для каждого обращения могут быть разными, но в целом, мы считаем, что есть 5 ключевых факторов, определяющих, будет ли обращение решено быстро.
“СкоростьОбучения = 0.1” и “КоличествоИтераций = 100” – это параметры, которые помогают нашей “логистической регрессии” учиться на данных и выявлять закономерности. Представьте, что мы хотим настроить нашего “интеллектуального ассистента” так, чтобы он лучше определял приоритет обращений. Мы делаем это постепенно, шаг за шагом, анализируя данные каждого обращения. “СкоростьОбучения” определяет, насколько большим будет каждый шаг анализа. Если шаг слишком большой, мы можем пропустить важные детали. Если шаг слишком маленький, мы будем учиться слишком медленно. “КоличествоИтераций” определяет, сколько шагов анализа мы сделаем. Чем больше шагов, тем лучше наш “ассистент” сможет понять взаимосвязи между факторами и скоростью решения обращения.
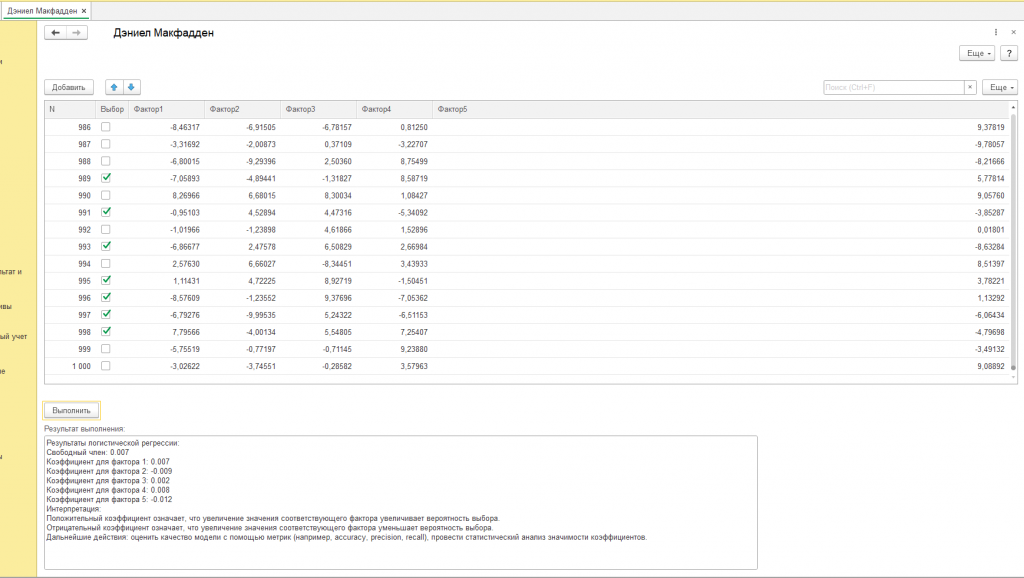
Итак, после того как мы создали нашу виртуальную службу поддержки и настроили параметры обучения, мы запустили процесс анализа данных. В результате мы получили следующие коэффициенты:
- Свободный член: 0.128
- Коэффициент для фактора 1: -0.002
- Коэффициент для фактора 2: 0.003
- Коэффициент для фактора 3: -0.014
- Коэффициент для фактора 4: 0.004
- Коэффициент для фактора 5: -0.004
Что это значит для нас, как для сотрудников службы поддержки? Эти коэффициенты показывают, как каждый из факторов влияет на вероятность того, что обращение будет решено быстро. Положительный коэффициент означает, что увеличение значения фактора увеличивает вероятность быстрого решения обращения. Отрицательный коэффициент означает, что увеличение значения фактора уменьшает вероятность быстрого решения обращения.
“Свободный член” – это как бы базовый уровень вероятности быстрого решения обращения, когда все факторы находятся на нейтральном уровне. В нашем примере, если все факторы равны нулю, то вероятность быстрого решения обращения будет немного выше 50% (так как свободный член положительный). Это можно интерпретировать как “среднюю скорость” решения обращений, не зависящую от конкретных факторов.
Теперь давайте рассмотрим факторы по отдельности, учитывая, что начальные данные у нас выглядят так:
“Нет -3,73662 -2,06561 7,09068 9,74391 -8,67459 Да -0,91653 0,69401 7,68802 -0,42915 5,18196”
Видя эти данные, мы понимаем, что факторы уже представлены числовыми значениями, и нам нужно интерпретировать, какие факторы могли бы соответствовать этим числовым значениям. Поскольку сами значения малоинформативны без контекста, мы будем исходить из предположения, что большие положительные значения соответствуют факторам, требующим большего внимания, а большие отрицательные значения – факторам, которые могут подождать.
Фактор 1 имеет отрицательный коэффициент (-0.002). Это означает, что увеличение значения фактора 1 немного уменьшает вероятность быстрого решения обращения. Учитывая отрицательные значения в начальных данных, можно предположить, что фактор 1 – это, например, сложность обращения. Чем сложнее обращение (чем меньше значение, так как оно отрицательное), тем меньше вероятность его быстрого решения.
Фактор 2 имеет положительный коэффициент (0.003). Это означает, что увеличение значения фактора 2 немного увеличивает вероятность быстрого решения обращения. С учетом отрицательных и положительных значений в начальных данных, фактор 2 может быть, например, срочностью обращения. Чем срочнее обращение (чем больше значение, тем ближе к положительному), тем больше вероятность его быстрого решения.
Фактор 3 имеет отрицательный коэффициент (-0.014). Это означает, что увеличение значения фактора 3 значительно уменьшает вероятность быстрого решения обращения (по сравнению с факторами 1 и 2). Учитывая большие значения (по модулю) в начальных данных, фактор 3 может быть, например, темой обращения, требующей узкой специализации. Если тема сложная и требует эксперта (большое положительное или отрицательное значение), решение может занять больше времени.
Фактор 4 имеет положительный коэффициент (0.004). Это означает, что увеличение значения фактора 4 немного увеличивает вероятность быстрого решения обращения. Фактор 4 может быть, например, типом клиента (премиум или обычный). Премиум клиенты (большие положительные значения) могут получать более приоритетное обслуживание.
Фактор 5 имеет отрицательный коэффициент (-0.004). Это означает, что увеличение значения фактора 5 немного уменьшает вероятность быстрого решения обращения. Фактор 5 может быть, например, общей загруженностью службы поддержки. Чем больше загрузка (чем меньше значение), тем меньше вероятность быстрого решения обращения.
Важно помнить, что коэффициенты в нашем примере очень маленькие. Это связано с тем, что мы работаем с искусственными данными, и факторы не оказывают сильного влияния на выбор слушателей. В реальных данных коэффициенты могут быть гораздо более выраженными, и их интерпретация должна основываться на анализе реальных данных и экспертном мнении специалистов службы поддержки.
Теперь давайте разберемся, что за “Выбор Фактор1 Фактор2 Фактор3 Фактор4 Фактор5” выводятся в начальных данных.
В каждой строке начальных данных содержится информация об одном виртуальном обращении и о том, как быстро оно было решено.
- “Выбор” – это решение, было ли обращение решено быстро (Истина - “Да”) или нет (Ложь - “Нет”).
- “Фактор1”, “Фактор2”, “Фактор3”, “Фактор4”, “Фактор5” – это значения соответствующих факторов для данного обращения. Важно, что эти значения уже представлены в числовом виде, как и в вашем примере (“Нет -3,73662 -2,06561 7,09068 9,74391 -8,67459 Да -0,91653 0,69401 7,68802 -0,42915 5,18196”). Вам нужно будет сопоставить эти числовые значения с реальными факторами (сложность, срочность, тема и т.д.) на основе вашей экспертной оценки и знания специфики работы службы поддержки.
Таким образом, каждая строка начальных данных представляет собой один “случай” - информацию об обращении и о том, как быстро оно было решено, а также значения факторов, которые могли повлиять на это решение.
Итак, мы получили коэффициенты, которые показывают, как факторы влияют на вероятность быстрого решения обращения. Но что делать дальше с этой информацией? Нам нужно оценить, насколько хорошо наша модель предсказывает, будет ли новое обращение решено быстро.
Представьте, что мы хотим проверить, насколько хорошо наш “интеллектуальный ассистент” определяет приоритет обращений. Мы можем взять данные о новых обращениях, которые еще не были решены, и посмотреть, насколько точно наша модель предсказывает, будут ли они решены быстро.
Для этого мы используем метрики качества, такие как “accuracy”, “precision” и “recall”. “Accuracy” показывает, какую долю обращений наша модель предсказала правильно (было ли обращение решено быстро или нет). “Precision” показывает, какую долю предсказаний “обращение будет решено быстро” действительно оказались правдой. “Recall” показывает, какую долю всех обращений, которые были решены быстро, наша модель смогла предсказать.
Кроме того, нам нужно провести статистический анализ, чтобы убедиться, что наши коэффициенты действительно отражают реальные закономерности между факторами и скоростью решения обращений, а не просто случайные совпадения, возникшие из-за особенностей нашей выборки данных.
Например, если мы получили коэффициент 0.003 для фактора “срочность”, мы должны убедиться, что это действительно так, и что увеличение срочности действительно повышает вероятность быстрого решения обращения, а не является результатом случайной флуктуации в нашей выборке. Для этого мы используем статистические тесты, которые позволяют нам оценить, насколько вероятно, что этот коэффициент появился случайно.
Если мы убедились, что наши коэффициенты значимы, и что наша модель имеет хорошее качество, мы можем использовать ее для автоматической приоритизации новых обращений. Это как если бы мы могли заглянуть в будущее и узнать, какие обращения необходимо решить в первую очередь, чтобы обеспечить высокий уровень удовлетворенности клиентов.
В заключение, логистическая регрессия – это мощный инструмент, который помогает службе поддержки оптимизировать свою работу, автоматизировать приоритизацию обращений и обеспечивать быстрое и качественное обслуживание клиентов. Она позволяет нам построить модель, которая предсказывает вероятность быстрого решения обращения и помогает нам принимать более обоснованные решения о распределении ресурсов и направлении усилий. Но важно помнить, что это всего лишь инструмент, и что его результаты нужно интерпретировать с осторожностью, учитывая специфику каждого обращения и другие факторы, которые могут повлиять на скорость его решения. В нашем примере, мы создали упрощенную модель, которая не учитывает все аспекты работы службы поддержки. Тем не менее, она дает нам представление о том, как работает логистическая регрессия и как ее можно использовать для анализа данных в сфере обслуживания клиентов.
Задача аналитика службы поддержки - правильно интерпретировать результаты анализа, учитывая знания о работе службы и потребностях клиентов, и использовать их для улучшения качества обслуживания и повышения эффективности работы команды. Логистическая регрессия - это ценный помощник, но не замена опыту специалистов службы поддержки и их способности находить индивидуальный подход к каждому клиенту.
Помните, что в реальной практике анализа данных службы поддержки – это сложный и многогранный процесс. Вам может потребоваться учитывать больше факторов, проводить более сложные статистические анализы, использовать другие методы машинного обучения и регулярно обновлять модель, чтобы она соответствовала меняющимся потребностям клиентов и условиям работы службы поддержки. Главное – не останавливаться на достигнутом, постоянно совершенствовать свои знания и использовать все доступные инструменты для улучшения качества обслуживания и повышения эффективности работы службы поддержки.
В мире экономического анализа, где царят сложные математические модели и абстрактные концепции, встречаются имена, чьи работы оказывают ощутимое влияние на нашу повседневную жизнь. Одно из таких имен – Дэниел Макфадден.
Дэниел Макфадден — лауреат Нобелевской премии (2000). Разработал модели дискретного выбора (логит, пробит). Эти несколько слов описывают фундамент его вклада в экономическую науку, вклад, который изменил наше понимание процессов принятия решений. Макфаддену удалось создать инструменты, позволяющие анализировать и предсказывать выбор человека из ограниченного набора возможностей. Это важно, потому что большинство решений, которые мы принимаем каждый день, именно таковы: выбрать один продукт из нескольких представленных на полке магазина, проголосовать за одного кандидата из списка, выбрать один способ добраться на работу из нескольких доступных.
В чем принципиальное отличие моделей дискретного выбора от других экономических моделей? Дело в том, что они учитывают не только объективные характеристики доступных вариантов, но и субъективные предпочтения людей. Каждый человек имеет свой уникальный набор вкусов, приоритетов, ценностей и ограничений, которые влияют на его выбор. Модели дискретного выбора позволяют учесть эти индивидуальные различия и построить более точные прогнозы поведения.
Наиболее известные модели, разработанные Макфадденом, – это логит и пробит. Эти модели используют математические функции для оценки вероятности выбора каждого варианта в зависимости от различных факторов. Модель логит, благодаря своей относительной простоте и удобству интерпретации, получила широкое распространение в самых разных областях. Модель пробит, в свою очередь, может быть более подходящей для анализа ситуаций, где факторы, влияющие на выбор, имеют определенное статистическое распределение.
Теоретические разработки Макфаддена нашли широкое применение на практике. Они используются в транспорте для планирования маршрутов и развития инфраструктуры, в маркетинге для разработки эффективных рекламных кампаний и ценообразования, в социологии для анализа общественного мнения и политического поведения, в экономике для изучения трудовых решений и инвестиционных стратегий.
Модели дискретного выбора помогают организациям лучше понимать потребности и предпочтения людей, адаптировать свои продукты и услуги к этим потребностям, оптимизировать процессы и принимать более обоснованные решения. Они позволяют, например, предсказать, как изменение цен на билеты повлияет на выбор вида транспорта, как изменение характеристик продукта повлияет на его популярность среди потребителей, как различные факторы повлияют на результаты выборов.
Однако, важно помнить, что модели дискретного выбора не являются совершенными. Они основаны на упрощенных предположениях о поведении людей и не могут учесть все факторы, влияющие на выбор. Кроме того, для построения и оценки этих моделей требуется большой объем качественных данных и специализированные знания.
Тем не менее, вклад Дэниела Макфаддена в экономическую науку трудно переоценить. Он создал мощный инструмент для анализа человеческого поведения, который нашел применение в самых разных областях и продолжает приносить пользу обществу. Его работы стимулировали дальнейшие исследования и разработки в области дискретного выбора, и его имя навсегда останется в истории экономической мысли. Макфадден заложил основу для понимания, что выбор – это не случайность, а результат сложного взаимодействия объективных факторов и субъективных предпочтений, и что, изучая это взаимодействие, мы можем лучше понимать мир вокруг нас. В заключение, говоря о Дэниеле Макфаддене, мы говорим о человеке, который научил нас видеть закономерности в хаосе выбора и сделал экономическую науку ближе к реальной жизни.
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.20.85
Вступайте в нашу телеграмм-группу Инфостарт