










Бухгалтеры и юристы ежедневно сталкиваются с задачей сравнения версий договоров, актов и счетов. Ручное сравнение отнимает значительное время и повышает риск ошибок. Современные технологии оптического распознавания символов (OCR) и больших языковых моделей (LLM) позволяют автоматизировать этот процесс. После ухода с рынка решения 1С-ABBYY Comparator возникла необходимость поиска альтернативных инструментов. В результате анализа была выявлена перспективная связка открытых технологий: Tesseract OCR для распознавания текста и LM Studio для интеллектуального анализа различий.
Цель и архитектура решения
Цель статьи — продемонстрировать практическую реализацию автоматического распознавания и сравнения документов с использованием открытых технологий.
Архитектура решения включает три основных компонента:
- Tesseract OCR — библиотека распознавания текста из изображений
- LM Studio — локальный сервер LLM с REST API
- Внешняя обработка 1С — интерфейс загрузки файлов и отображения результатов
Этап 1. Установка и настройка Tesseract OCR
Tesseract — это открытая библиотека оптического распознавания символов, поддерживаемая Google. Она работает с форматами PNG, TIFF, JPEG и требует предварительной конвертации PDF в изображения. Поддерживает более 130 языков с кодировкой Unicode, включая кириллицу.
Основные форматы вывода:
- TXT — простой текст
- hOCR — HTML с координатами элементов
- TSV — табличный формат
- PDF — PDF с текстовым слоем
- ALTO XML — формат для архивов
Установка на Windows:
- Скачать установщик с https://github.com/UB-Mannheim/tesseract/wiki
- Выбрать языковые пакеты (русский и английский)
- Добавить путь в переменную среды PATH
Запустите скачанный exe-файл и следуйте мастеру установки:
- Выберите язык установщика и нажмите OK
- Нажмите Next для продолжения
- Примите лицензионное соглашение Apache License 2.0, нажав I Agree
- Выберите, для какого пользователя устанавливать (текущий или все пользователи)
- В разделе Choose Components обязательно выберите нужные языковые пакеты в секции Additional language data. Для распознавания русского текста выберите Russian в списке языков. Я выбрала еще Английский.
- Укажите папку установки (по умолчанию C:\Program Files\Tesseract-OCR) и обязательно запомните этот путь
- Выберите папку в меню "Пуск" для ярлыков или отключите создание ярлыков
- Нажмите Install и дождитесь завершения установки
- Нажмите Finish
Далее переходим к установке переменных сред. Необходимо добавить Tesseract в переменную PATH для доступа из командной строки:
- Откройте поиск Windows и введите "переменные среды" или "environment variables"
- Выберите Изменение системных переменных среды
- Нажмите кнопку Переменные среды в нижней части окна
- В разделе Системные переменные найдите переменную Path и нажмите Изменить.
- Нажмите Создать и вставьте путь к папке установки Tesseract (например, C:\Program Files\Tesseract-OCR).
- Нажмите OK для сохранения изменений
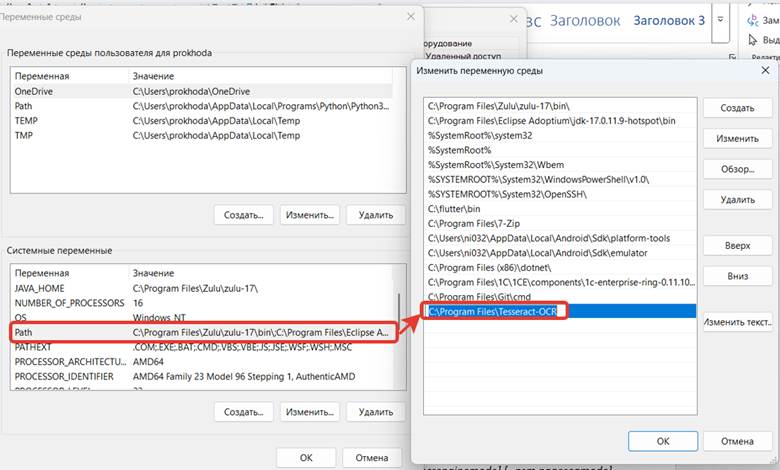
Если вы установили Tesseract в нестандартную папку или если Tesseract не может найти файлы языковых данных, необходимо Создание переменной TESSDATA_PREFIX
Аналогично заходим в переменные среды:
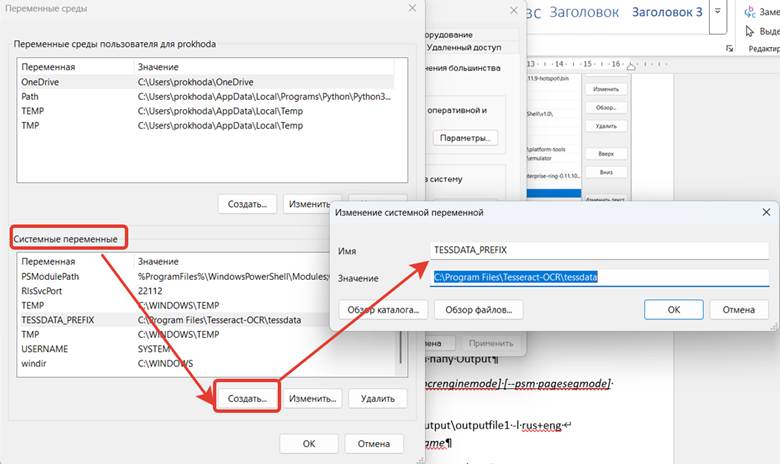
Через командую строку проверяем версию. Команда tesseract -v

Если остались ошибки, ознакомьтесь с подробной статьей по установке на Windows Подробная установка на английском – по ссылке https://docs.coro.net/featured/agent/install-tesseract-windows/
!!! После добавления переменных обязательно перезапустите командную строку или PowerShell.
- Настройка языковых пакетов (русский + английский)
Если вы не выбрали языковые пакеты при установке, их можно добавить.
-
- https://github.com/tesseract-ocr/tessdata - скачиваем необходимые языки.
- Скачанные файлы *.traineddata (например, rus.traineddata для русского языка) нужно поместить в папку tessdata. Для Windows: C:\Program Files\Tesseract-OCR\tessdata или /usr/local/share/tessdata/. Если путь нестандартный, установите переменную окружения TESSDATA_PREFIX на родительскую папку для tessdata (делали выше).
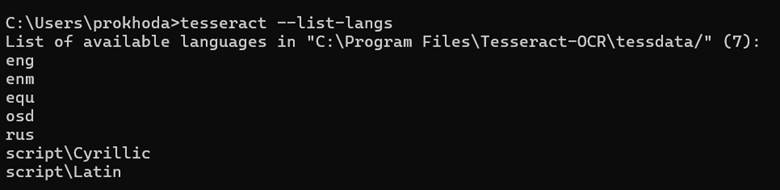
- Проверяем установленные языки по команде: tesseract --list-langs
Для указания языка при запуске Tesseract используется флаг -l с кодом языка:
русский: tesseract image.png output -l rus
английский: tesseract image.png output -l eng
Можно комбинировать несколько языков: tesseract image.png output -l rus+eng
- Запускаем Командную строку (cmd/PowerShell): пробуем распознать текст из картинки png, проверяем вывод в папу Output по команде:
tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...]
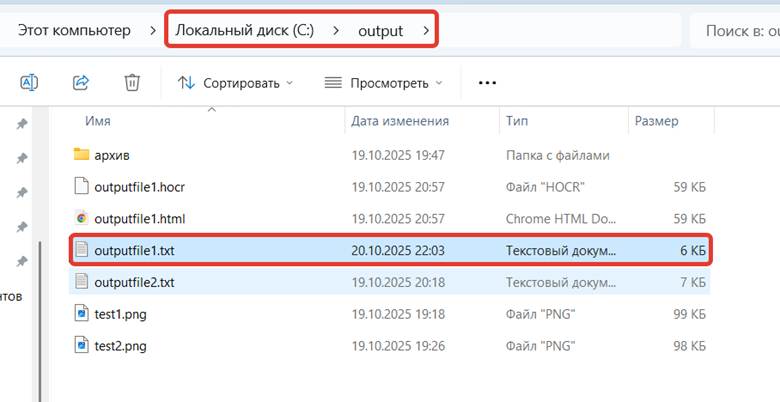
Моя команда: tesseract C:\output\test1.png C:\output\outputfile1 -l rus+eng
где C:\output\test1.png – файл картинки imagename
C:\output\outputfile1 – католог вывода файла outputbase

Файл распознан в текст и сохранен в указанную папку с указанным именем:
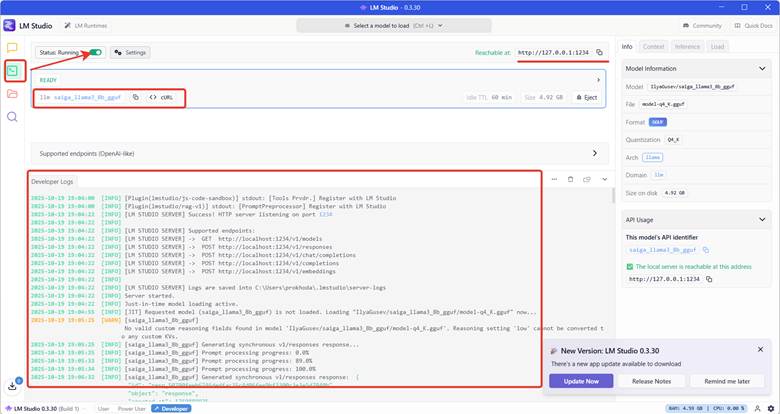
Этап 2. Развертывание LM Studio
LM Studio — это платформа для работы с локальными языковыми моделями (LLM). Сервис устанавливается на Windows, Mac или Linux и может работать как REST API сервер. Преимущество — полная автономность и конфиденциальность работы: документы не покидают ваш компьютер.
Настройка и запуск:
- Скачать с https://lmstudio.ai/
- Выбрать модель saiga_llama3_8b_gguf
- Настроить контекст до 8192 токенов
- Запустить сервер REST API
Развертывание LM Studio:
- Установка LM Studio на локальный компьютер (ссылка выше)
- Выбор и загрузка подходящей модели. Почитала и выбрала saiga_llama3_8b_gguf
Ограничения модели:
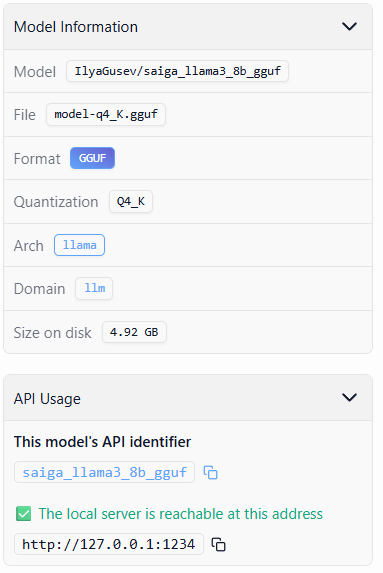
8.192 токена у этой модели. Для обработки больших объемов информации это мало.
У меня настроено 4096 токенов, можно выставить по максимум.
Я загружала 2 страницы изображения текста договора Аренды помещения, при этом 1 страница составляет 3420символов. На это я потратила 3279токенов.
При последующем запросе я выбрала весь контекст.
Может, стоит подумать, как загружать договоры по-странично, чтобы выбирать меньше токенов?!.
- Запуск в режиме REST API сервера – запускаем Status Runing, теперь наша AI может принимать rest-запросы
- Настройка endpoint
Теперь можем отправлять Http – запросы к LLM.
Пример промпта для сравнения:
Этап 3. Создание внешней обработки 1С
Для удобства создается внешняя обработка 1С, объединяющая OCR, LLM и визуализацию результата в одном интерфейсе.
Основные элементы:
- Два поля выбора файлов
- Кнопка «Сравнить»
- Поле HTML для вывода результата
Код в обработке (модуль Формы):
&НаКлиенте
Процедура ЗагрузитьИзФайла(Команда)
ВыборФайла(Файл1);
КонецПроцедуры
&НаКлиенте
Процедура ЗагрузитьИзФайла2(Команда)
ВыборФайла(Файл2);
КонецПроцедуры
&НаКлиенте
Процедура ВыборФайла(Файл)
ДиалогФыбораФайла = Новый ДиалогВыбораФайла(РежимДиалогаВыбораФайла.Открытие);
ДиалогФыбораФайла.Фильтр = "Картинка формата png (*.png)|*.png";
ДиалогФыбораФайла.Заголовок = "Выберите файл";
ДиалогФыбораФайла.ПредварительныйПросмотр = Истина;
ДиалогФыбораФайла.ИндексФильтра = 0;
Если ДиалогФыбораФайла.Выбрать() Тогда
Файл = ДиалогФыбораФайла.ПолноеИмяФайла;
КонецЕсли;
КонецПроцедуры
&НаКлиенте
Процедура Сравнить(Команда)
//Запускаем tesseract, указываем языки (русский/английский)
ВыходнойФайл1 = "C:\output\outputfile1";
ВыходнойФайл2 = "C:\output\outputfile12";
СтрокаКоманды = "tesseract "+ Файл1 + " " + ВыходнойФайл1 +" -l rus+eng";
СтрокаКоманды2 = "tesseract "+ Файл2 + " " + ВыходнойФайл2 +" -l rus+eng";
КомандаСистемы(СтрокаКоманды);
КомандаСистемы(СтрокаКоманды2);
ВыполнитьPostЗапросСФайлом(ВыходнойФайл1, ВыходнойФайл2);
КонецПроцедуры
Процедура ВыполнитьPostЗапросСФайлом(ВыходнойФайл1, ВыходнойФайл2)
// Читаем содержимое текстового файла
ПутьКФайлу1 = ВыходнойФайл1 + ".txt";
ПутьКФайлу2 = ВыходнойФайл2 + ".txt";
ЧтениеФайла = Новый ЧтениеТекста(ПутьКФайлу1, КодировкаТекста.UTF8);
СодержимоеФайла1 = " Первый договор " + ЧтениеФайла.Прочитать();
ЧтениеФайла.Закрыть();
ЧтениеФайла = Новый ЧтениеТекста(ПутьКФайлу2, КодировкаТекста.UTF8);
СодержимоеФайла2 = " Второй договор "+ ЧтениеФайла.Прочитать();
ЧтениеФайла.Закрыть();
Промт = "У меня есть два договора. Тебе надо их сравнить и найти различия.
|Сравнение вывести в таблицу, состоящей из 4 столбцов: номер строки (и пункта договора),
|данные из Договора 1, данные из Договора 2, различия.
|Если различий нет, то в колонке «Различия» ничего не указывается.
|Цвет текста в колонке «Различия» должны быть красным. Эту в таблицу со сравнением договоров поместить в документ в формате html.
|Ответ предоставь только в формате html без комментариев";
Промт = Промт + СодержимоеФайла1 + СодержимоеФайла2;
// Формируем данные через структуру
Данные = Новый Структура;
Данные.Вставить("model", "saiga_llama3_8b_gguf");
Данные.Вставить("input", Промт); // Вставляем промт
Reasoning = Новый Структура;
Reasoning.Вставить("effort", "low");
Данные.Вставить("reasoning", Reasoning);
// Преобразуем в JSON
ЗаписьJSON = Новый ЗаписьJSON;
ЗаписьJSON.УстановитьСтроку();
ЗаписатьJSON(ЗаписьJSON, Данные);
ТелоЗапроса = ЗаписьJSON.Закрыть();
// Создаем HTTP соединение и запрос
Соединение = Новый HTTPСоединение("localhost", 1234);
Запрос = Новый HTTPЗапрос("/v1/responses");
Запрос.Заголовки.Вставить("Content-Type", "application/json");
Запрос.УстановитьТелоИзСтроки(ТелоЗапроса, КодировкаТекста.UTF8, ИспользованиеByteOrderMark.НеИспользовать);
// Отправляем запрос
Попытка
Ответ = Соединение.ОтправитьДляОбработки(Запрос);
Ответ = Ответ.ПолучитьТелоКакСтроку();
ПолеHTML = ПолучитьТекстИзJSON(Ответ);
Исключение
Сообщить("Ошибка: " + ОписаниеОшибки());
КонецПопытки;
КонецПроцедуры
Функция ПолучитьТекстИзJSON(СтрокаJSON)
// Создаем объект для чтения JSON
ЧтениеJSON = Новый ЧтениеJSON;
ЧтениеJSON.УстановитьСтроку(СтрокаJSON);
// Преобразуем JSON в структуру/соответствие 1С
// Второй параметр Истина позволяет читать в Соответствие
ДанныеJSON = ПрочитатьJSON(ЧтениеJSON, Истина);
ЧтениеJSON.Закрыть();
// Извлекаем текст из вложенной структуры
// Путь: output[0].content[0].text
HTMLContent = ДанныеJSON["output"][0]["content"][0]["text"];
Возврат HTMLContent;
КонецФункции
В 1С выглядит следующим образом:

Файлы png, загружаемые в Tesseract:
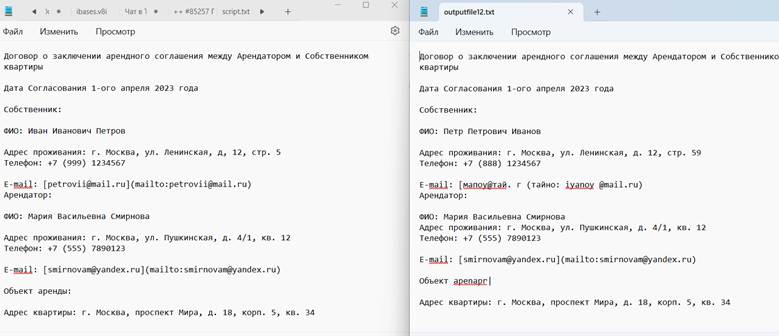
Файлы outputfile.txt, полученные из png Tesseract
Выводы
Преимущества:
- Автономность — работает без интернета
- Бесплатные open-source компоненты
- Гибкость и расширяемость
- Безопасность — локальная обработка
- Высокая скорость и невысокие требования
Ограничения:
- Качество распознавания зависит от сканов
- Нужна достаточная мощность LLM
- Модель может "фантазировать" и выдавать разные результаты при одинаковых входных данных
Перспективы:
- Добавление предобработки изображений,
- Работать "по-строчно"/по абзацам: результат OCR разбивать на абзацы, их генерировать в эмбенденги, которые и будем "отдавать " в LM для сравнения.
- Поддержка DOCX и XLSX
- Пакетная обработка
- Интеграция с базой 1С
Заключение
Комбинация OCR и LLM открывает новые возможности для автоматизации рутинных операций с документами в 1С. Решение демонстрирует практическое применение современных AI-технологий и дает компаниям безопасный и экономичный способ ускорить работу с документами.
Проверено на следующих конфигурациях и релизах:
- Управление торговлей, редакция 11, релизы 11.5.11.70
Вступайте в нашу телеграмм-группу Инфостарт