Оглавление:
1. Вступление
2. Краткий экскурс в работу конвейера
3. Примеры использования
4. Проверка скорости фоновых
5. Исходный код
1. Вступление
Итак, данные копятся, методы оптимизации экономят 10-15%, которые вскоре съедаются вновь возросшими аппетитами, мысли переходят к многопоточному выполнению, тем более данные не взаимосвязанные и могут обрабатываться вне зависимости друг от друга в произвольной последовательности. А может быть, вам просто нужно побыстрее обработать большой массив данных запроса, и ресурсы при прямом выполнении тратятся неэффективно. В таких случаях обычно обращаются к многопоточному выполнению, и здесь нам не обойтись без фоновых заданий.
Так как нам обработать массив данных быстрее? Конечно, разделить его выполнение между параллельными потоками. Для чего нам, собственно, понадобятся:
1. сам массив данных, который можно обрабатывать в любом порядке
2. процедура в общем модуле или модуле менеджера объекта, которая будет делать полезную работу с порцией этого массива. Как показывает практика, если данные можно обработать параллельно, то переработка функции в обработку порции занимает несколько минут.
3. фоновые задания для параллелизации. Конечно, ведь фоновые задания - это по сути новые сеансы, которые могут делать полезную работу.
4. немного времени. Да, к сожалению, операция разбиения между потоками фоновых заданий не бесплатная и каждый вызов нового потока занимает десятые доли секунды - у меня где-то 0,110 с. что на работе, что дома - завершение тоже не быстрое. Демонстрацию и проверку этого см. 4 раздел
5. конвейер, который будет контролировать как количество потоков, так и выгрузку данных в них и, если нужно, сбор результатов выполнения. Собственно, этот конвейер уже несколько раз был представлен в различных статьях (раз, два и три). От первой я и оттолкнулся, чтобы сделать более универсальный алгоритм, который можно будет многократно применять без доработки с любыми имеющимися входными данными, будь то массив или выборка.
2. Краткий экскурс в работу конвейера потоков
Проведу небольшой экскурс в особенности своего конвейера многопоточной обработки, он достаточно простой и уже не раз меня выручал в двух типах ситуаций: нужно обработать большой массив данных, медленный в обработке, и есть задача, результат которой зависит от случайности, хотелось бы получить несколько вариантов. Для первого служит процедура ВыполнитьФункциюПорциями, для второго - ВыполнитьНесколькоПотоковРасчета. Входными данными, как я уже сказал, может быть как простой массив (документов, например), так и массив структур, таблица значений или ВыборкаИзРезультатовЗапроса. На входе определяем структуру записи и потом заполняем ее для заполнения массива структур или простого массива для передачи в порцию.
Думаю, будет несложно переработать эту функцию для передачи в порцию Таблицы значений, но я остановился именно на массиве структур, потому что не знал о сериализуемости ТЗ, и он меня пока устраивает для моих задач. P.S. Сделано
Когда данные собраны, можно запускать поток, если он, конечно, не лишний:
// запуск фонового задания и его фиксация
МассивПараметров = Новый Массив;
МассивПараметров.Добавить(ДанныеДляЗадания);
Если НастройкиВыполнения.ВозвращатьРезультаты Тогда
Адрес = ПоместитьВоВременноеХранилище(Неопределено, Новый УникальныйИдентификатор);
МассивПараметров.Добавить(Адрес);
КонецЕсли;
Для Каждого Запись Из МассивПоследующихПараметров Цикл
МассивПараметров.Добавить(Запись);
КонецЦикла;
Если НастройкиВыполнения.ВыполнятьБезопасноИлиИзМенеджера Тогда
ПараметрыЗадания = Новый Массив;
ПараметрыЗадания.Добавить(ВыполняемыйМетод);
ПараметрыЗадания.Добавить(МассивПараметров);
ПараметрыЗадания.Добавить(Неопределено);
ФЗ = ФоновыеЗадания.Выполнить("ДлительныеОперацииСервер.ВыполнитьБезопасно", ПараметрыЗадания,, КлючЗадания);
Иначе
ФЗ = ФоновыеЗадания.Выполнить(ВыполняемыйМетод, МассивПараметров, , КлючЗадания);
КонецЕсли;
АктивныеЗадания.Добавить(Новый Структура("ИдентификаторФЗ, АдресХранилища", ФЗ.УникальныйИдентификатор, Адрес));
Как видно, первым параметром для функции обработки порции должна быть собственно порция, вторым в случае необходимости возвращения результата адрес хранилища, в который результат и помещается, далее остальные параметры, которые для каждого потока будут одинаковыми. Разумеется, если результат не нужен, резервировать второй параметр под адрес хранилища не нужно. Как видим, сам поток организуется очень просто: это вызов функции менеджера фоновых заданий Выполнить.
Далее нужно отследить выполнение потока, для чего используется функция ОбработкаОчередиЗаданий, вот основной цикл:
ОбнаруженаАвария = Ложь;
// проверка наличия свободных потоков
Индекс = АктивныеЗадания.Количество();
Пока Индекс > 0 Цикл
Индекс = Индекс - 1;
// смысл в том, чтобы проверить статус у запущенного задания, и если он не активен - освободить место в массиве ФЗ
ТекущееЗадание = ФоновыеЗадания.НайтиПоУникальномуИдентификатору(АктивныеЗадания[Индекс].ИдентификаторФЗ);
Если ТекущееЗадание.Состояние = СостояниеФоновогоЗадания.Завершено Тогда
Если НастройкиВыполнения.ВозвращатьРезультаты Тогда
ПополнитьРезультаты(АктивныеЗадания[Индекс].АдресХранилища, НастройкиВыполнения.ОбъединятьРезультаты,
РезультатыВыполнения);
КонецЕсли;
ИначеЕсли ТекущееЗадание.Состояние <> СостояниеФоновогоЗадания.Активно Тогда
ОбнаруженаАвария = Истина;
ОчередьБезаварийная = Ложь;
Если ТекущееЗадание.Состояние = СостояниеФоновогоЗадания.Отменено Тогда
ЗаписьЖурналаРегистрации(НастройкиВыполнения.ПотокЖурналаРегистрации, УровеньЖурналаРегистрации.Ошибка, , ,
"Одна из порций задания с вызовом метода """ + ТекущееЗадание.ИмяМетода +
""" была отменена. Выполнение будет остановлено");
НастройкиВыполнения.ОстанавливатьПриАвариях = Истина;
КонецЕсли;
Иначе
Продолжить;
КонецЕсли;
АктивныеЗадания.Удалить(Индекс);
Для Каждого Сообщение Из ТекущееЗадание.ПолучитьСообщенияПользователю(Истина) Цикл
Сообщение.Сообщить();
КонецЦикла;
КонецЦикла;
Как видим, здесь проверяется статус завершения фонового задания и если оно отменено, отменяется все, если обнаружена авария, то в случае необходимости также останавливается дальнейший процесс. Ну и бонусом транслируются все сообщения из процедуры обработки порции, если они были. Разумеется в случае успешного завершения задания мы освобождаем поток и при необходимости пополняем результаты.
Насчет пополнения результатов - функция нифига не универсальная, возвращает либо массив результатов каждой обработки порции, который потом самому разгребать, либо если результатом является тот же массив (структур), то результаты можно объединить в общий массив. Не нравится - переделывайте!
Для подведения итогов запуска используется функция ФоновыеЗадания.ПолучитьФоновыеЗадания с ключом по Наименованию. Поскольку все задания в потоке запускались с уникальным названием (ключ UID), их легко отследить и обработать результаты.
3. Примеры использования
Представим, что на входе есть большой массив информации, который нужно загрузить в справочник. Для примера просто нагрузим справочник товары словами из всем известной книги "Война и Мир". Слов уникальных там немало, прибавляются французские и исторические, так что сойдет для простого примера наполнения:
Текст = Обработки.ДемонстрацияФоновыхЗаданий.ПолучитьМакет("ВойнаИМирДляПроверкиУведомлений").ПолучитьТекст();
НаборСлов = ДлительныеОперацииСервер.РазделитьСтроку(Текст, " ,.-""«»[{@#}]'…();:!?" + Символы.ПС
+ Символы.НПП + Символы.ВК + Символы.Таб);
НастройкиВыполнения = ДлительныеОперацииСервер.НастройкиВыполнения(15, , , Ложь);
ДлительныеОперацииСервер.ВыполнитьФункциюПорциями(НаборСлов,
"Обработки.ДемонстрацияМногопоточнойРаботы.НагрузитьСправочникТоварыПоПорциям",
Новый Массив, НастройкиВыполнения);
ОбщегоНазначения.СообщитьПользователю("Готово! Справочник ""Товары"" загружен в количестве "
+ НаборСлов.Количество() + " элементов.");
Первые две строчки мы собираем данные, вторыми запускаем конвейер, пятой строчкой сообщаем о результатах. Как видим, все очень и очень просто (было бы также с новыми функциями БСП для многопоточной работы, этой статьи бы не было). Не буду приводить здесь функцию обработки порции, она слишком простая (ищем в справочнике по слову в цикле, если такого слова еще нет, создаем элемент справочника). Если вам интересно, сколько уникальных слов в первых двух томах, то я вас не порадую, ибо данный алгоритм абсолютно не учитывает словоформы, да и разделители не все найдены точно. Так что их набралось более 30 тысяч, да.
Разумеется, нужно рассказать и о методе НастройкиВыполнения. В эти самые настройки входят:
1. КоличествоПотоков - количество одновременно запускаемых потоков
2. ВыполнятьБезопасноИлиИзМенеджера - в старом БСП есть метод ВыполнитьБезопасно, который тем не менее не использует безопасный режим, но предоставляет способ выполнения из менеджера объекта - используем его или прямое выполнение (думал, будет разница в производительности - нет ее)
3. ОбъединятьРезультаты - если результаты - это массив, то можно воспользоваться объединением результатов в один массив
4. СтрокВПорции - можно не задавать, тогда объем данных будет поделен между потоками, а так размер одной порции
5. ОстанавливатьПриАвариях - если при любой критической ошибке в любом потоке нужно останавливать выполнение конвейера, ставим Истину
6. ВозвращатьРезультаты - будет это процедура или процедура, которая помещает результат по адресу, переданному вторым параметром функции обработки порции
7. ПотокЖурналаРегистрации - я беру на себя смелость писать некоторые факты в журнал регистрации, это собственно ИмяСобытия
8. ПередаватьТаблицуЗначений - что передавать в задание - таблицу значений или массив (структур, например)
Первый пример был простым, поскольку не требовал возвращения результата, давайте испытаем что-нибудь, что все таки требует отчета, например, подчистим наш справочник от неиспользуемых товаров и вернем используемые:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Товары.Ссылка КАК Ссылка
|ИЗ
| Справочник.Товары КАК Товары";
РезультатЗапроса = Запрос.Выполнить();
ВыборкаДетальныеЗаписи = РезультатЗапроса.Выбрать();
НастройкиВыполнения = ДлительныеОперацииСервер.НастройкиВыполнения(15);
НеудаляемаяНоменклатура = ДлительныеОперацииСервер.ВыполнитьФункциюПорциями(ВыборкаДетальныеЗаписи
, "Обработки.ДемонстрацияМногопоточнойРаботы.ПодчиститьСправочникТоварыПоПорциям",
Новый Массив, НастройкиВыполнения);
ОбщегоНазначения.СообщитьПользователю("Готово! Справочник ""Товары"" очищен от неиспользуемой номенклатуры");
ОбщегоНазначения.СообщитьПользователю("Неудаляемая номенклатура: ");
Для Каждого Товар Из НеудаляемаяНоменклатура Цикл
ОбщегоНазначения.СообщитьПользователю(Символы.Таб + Товар.Наименование);
КонецЦикла;
Нда, сложнее не получилось, наоборот, в функции настроек не нужно указывать четвертый параметр (возвращать ли результаты - по умолчанию возвращать). Зато функция возвращает нам простой массив номенклатуры, которую нельзя удалять, о каждой из которых мы и сообщаем. Как видим, мы запускаем 15 потоков. На моем домашнем ПК 18 потоков (ядер 14) - часть потоков нужна ОС и базе данных, поэтому выбор такой. Поскольку мы не указываем размер порции (второй параметр), то выборка будет распределена между 15 потоками, которые все сразу и запустятся. Можно сделать количество потоков меньшим, но указать размер порции (не забывайте, что вызов фонового задания не бесплатный, да и в фоновое задание нельзя передавать больше 1ГБ данных (это сотни тысяч строк, если не миллионы, в зависимости от количества и наполнения колонок)). Транзакциями занимайтесь в функции обработки порции, если хотите - фоновые задания сами по себе транзакцией быть не могут, ха-ха.
Кстати, приведу ради примера функцию, которую я использовал для очистки товаров порциями, чтобы вы не думали, что она чем-то усложнена:
НеудаляемыеСсылки = Новый Массив;
Для Каждого Товар Из НаборТоваров Цикл
СсылкиНаОбъект = НайтиПоСсылкам(ОбщегоНазначенияКлиентСервер.ЗначениеВМассиве(Товар.Ссылка));
Если СсылкиНаОбъект.Количество() = 0 Тогда
ТоварОбъект = Товар.Ссылка.ПолучитьОбъект();
ТоварОбъект.Удалить();
Иначе
НеудаляемыеСсылки.Добавить(Товар.Ссылка);
КонецЕсли;
КонецЦикла;
ПоместитьВоВременноеХранилище(НеудаляемыеСсылки, АдресРезультата);
Ну и третьим примером покажу использование многократного повторения процедуры для одних и тех же данных (ВыполнитьНесколькоПотоковРасчета). Есть такое понятие как "каламбургер", то есть слово, которое состоит из двух других пересекающихся слов. Представим, что нам быстро нужно найти большое количество таких каламбургеров для демонстрации (по требованию пользователя - от 50 до 750). Поскольку алгоритм крайне простой, он скорее всего не будет вами распараллеливаться, но как мы убедимся, даже на достаточно небольшом размере требуемых данных многопоточное исполнение победит однопоточное, несмотря на издержки:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Товары.Наименование КАК Наименование
|ИЗ
| Справочник.Товары КАК Товары";
РезультатЗапроса = Запрос.Выполнить();
СписокСлов = РезультатЗапроса.Выгрузить();
Отметка = ТекущаяУниверсальнаяДатаВМиллисекундах();
НаборыКаламбургеров = ДлительныеОперацииСервер.ВыполнитьНесколькоПотоковРасчета(СписокСлов,
"Обработки.ДемонстрацияМногопоточнойРаботы.НайтиКаламбургеры",
ОбщегоНазначенияКлиентСервер.ЗначениеВМассиве(Цел(КоличествоКаламбургеров / 5)), 10, Истина, Ложь);
Каламбургеры.Очистить();
Для Каждого Набор Из НаборыКаламбургеров Цикл
Для Каждого Запись Из Набор Цикл
СтруктураПоиска = Новый Структура("Каламбургер", Запись.Каламбургер);
Если Каламбургеры.НайтиСтроки(СтруктураПоиска).Количество() = 0 Тогда
ЗаполнитьЗначенияСвойств(Каламбургеры.Добавить(), Запись);
КонецЕсли;
Если Каламбургеры.Количество() = КоличествоКаламбургеров Тогда
Прервать;
КонецЕсли;
КонецЦикла;
Если Каламбургеры.Количество() = КоличествоКаламбургеров Тогда
Прервать;
КонецЕсли;
КонецЦикла;
ОбщегоНазначения.СообщитьПользователю("Многопоточным алгоритмом за "
+ (ТекущаяУниверсальнаяДатаВМиллисекундах() - Отметка) + " мс найдено "
+ Каламбургеры.Количество() + " каламбургеров");
Отметка = ТекущаяУниверсальнаяДатаВМиллисекундах();
Каламбургеры.Загрузить(Обработки.ДемонстрацияМногопоточнойРаботы.НайтиКаламбургеры(
СписокСлов, , КоличествоКаламбургеров));
ОбщегоНазначения.СообщитьПользователю("Сплошным алгоритмом за "
+ (ТекущаяУниверсальнаяДатаВМиллисекундах() - Отметка) + " мс найдено "
+ Каламбургеры.Количество() + " каламбургеров");
На моем ПК многопоточные начинают побеждать на 420-450 штук каламбургеров, но алгоритм хорошо оптимизирован, а основная нагрузка идет на составлении быстрого потом соответствия.
Здесь вызов немного сложнее. Кроме таблицы со словами, которая является основным набором для функции и собственно самой функции передается массив последующих параметров (здесь это только число каламбургеров), количество потоков (10), выполнение из менеджера объектов (стоит Истина) и объединять или нет результаты. Поскольку результатом одного потока будет таблица значений, объединять результаты мы здесь не будем (стоит Ложь). Отдельной функции для настроек я делать не стал, поскольку параметров у функции итак немного. Потом мы обрабатываем полученные с запасом таблицы каламбургеров, вставляя уникальные в таблицу на форме.
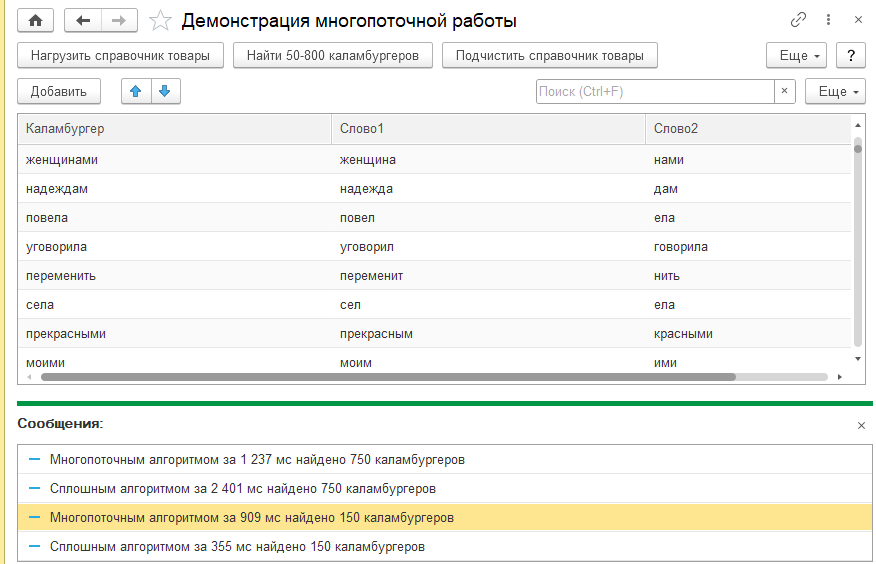
Как видно по результатам, пресловутые накладные расходы держат результат многопоточного выполнения около секунды независимо от объема работы, а в вот прямой подход показывает превосходство только на малых объемах.
4. Проверка скорости фоновых заданий
В какой-то момент стало интересно, почему, несмотря на все мои ухищрения, добиться многопоточного поиска быстрее 700 мс практически невозможно, поэтому я добавил в обработку команду "Проверка скорости фоновых", которая делает 5 вещей:
1. запускает (количество) фоновых заданий, которые ничего не делают, сразу завершаются - для проверки скорости чистого механизма отработки фоновых. Завершение заданий проверяется в бесконечном цикле без паузы
2. собирает миллион в массив такого же размера - для последующего сравнения продолжительности с фоновыми
3. раздает задание собрать миллион между (количеством) потоков - общее время также замеряется для сравнения с пустыми заданиями и линейными алгоритмом
4. передает собранный миллион (массив) в (количество) потоков и добирает там миллион теми же долями, что и в 3) - для проверки времени, которое тратится на передачу данных в фоновое задание
5. передает массив в (количество) потоков, а собирает там новый. Дело в том, что сравнивая результаты замеров по фоновым заданиям и линейному алгоритму, заподозрил, что с входными данными задание работает медленнее, чем с внутренними, поэтому сравниваю с 4)
1 пустых фоновых заданий (параллельно) выполнилось за 276 мс.
Ты собрал миллион за 2 353 мс.
1 фоновых заданий (параллельно) собрали миллион за 2 699 мс.
1 фоновых заданий (параллельно) удвоили миллион за 3 083 мс.
1 фоновых заданий (параллельно) собрали свой миллион, глядя на ваш, за 3 156 мс.
5 пустых фоновых заданий (параллельно) выполнилось за 305 мс.
Ты собрал миллион за 2 388 мс.
5 фоновых заданий (параллельно) собрали миллион за 1 056 мс.
5 фоновых заданий (параллельно) удвоили миллион за 1 918 мс.
5 фоновых заданий (параллельно) собрали свой миллион, глядя на ваш, за 1 948 мс.
10 пустых фоновых заданий (параллельно) выполнилось за 290 мс.
Ты собрал миллион за 2 325 мс.
10 фоновых заданий (параллельно) собрали миллион за 772 мс.
10 фоновых заданий (параллельно) удвоили миллион за 2 460 мс.
10 фоновых заданий (параллельно) собрали свой миллион, глядя на ваш, за 2 431 мс.
То есть видно, что удвоение числа потоков не приводит к удвоению скорости в самом простом случае (хотя ядер, как я говорил, у меня с запасом), а при большом объеме входных данных даже замедляет процесс, поскольку накладные расходы уже превышают внутренние. Ну и нужно понимать, что после сбора в фоновых еще нужно бы собрать массив воедино, но мы здесь этого не делаем. Не забываем и о том, что не все алгоритмы такие простые, как этот, а то еще загрустите! На некоторых можно добиться ускорения и на порядок, что будет очень сильно заметно. Кстати, многопоточное заполнение справочника из примера быстрее однопоточного более чем в 6 раз (230 секунд против 37.8)!
5. Исходный код
Привожу здесь исходный код всего модуля ДлительныеОперацииСервер, может, кому пригодится:
Исходный код ДлительныеОперацииСервер
#Область ПрограммныйИнтерфейс
// Выполнить экспортную процедуру по имени.
//
// Параметры:
// ИмяЭкспортнойПроцедуры - Строка - имя экспортной процедуры в формате
// <имя объекта>.<имя процедуры>, где <имя объекта> - это
// общий модуль или модуль менеджера объекта.
// Параметры - Массив Из Тип - параметры передаются в процедуру <ИмяЭкспортнойПроцедуры>
// в порядке расположения элементов массива.
// ОбластьДанных - Число - задает область данных, в которой необходимо выполнить процедуру.
//
// Пример:
// ВыполнитьБезопасно("МойОбщийМодуль.МояПроцедура");
//
Процедура ВыполнитьБезопасно(ИмяЭкспортнойПроцедуры, Параметры = Неопределено, ОбластьДанных = Неопределено) Экспорт
// Проверка предусловий на формат ИмяЭкспортнойПроцедуры.
ЧастиИмени = РазделитьСтроку(ИмяЭкспортнойПроцедуры, ".");
Если ЧастиИмени.Количество() <> 2 И ЧастиИмени.Количество() <> 3 Тогда
ВызватьИсключение "Неправильный формат параметра ИмяЭкспортнойПроцедуры (" + ИмяЭкспортнойПроцедуры + ")";
КонецЕсли;
ИмяОбъекта = ЧастиИмени[0];
Если ЧастиИмени.Количество() = 2 И Метаданные.ОбщиеМодули.Найти(ИмяОбъекта) = Неопределено Тогда
ВызватьИсключение "Неправильный формат параметра ИмяЭкспортнойПроцедуры (" + ИмяЭкспортнойПроцедуры + ")";
КонецЕсли;
Если ЧастиИмени.Количество() = 3 Тогда
ДопустимыеИменаТипов = Новый Массив;
ДопустимыеИменаТипов.Добавить("КОНСТАНТЫ");
ДопустимыеИменаТипов.Добавить("РЕГИСТРЫСВЕДЕНИЙ");
ДопустимыеИменаТипов.Добавить("РЕГИСТРЫНАКОПЛЕНИЯ");
ДопустимыеИменаТипов.Добавить("РЕГИСТРЫБУХГАЛТЕРИИ");
ДопустимыеИменаТипов.Добавить("РЕГИСТРЫРАСЧЕТА");
ДопустимыеИменаТипов.Добавить("СПРАВОЧНИКИ");
ДопустимыеИменаТипов.Добавить("ДОКУМЕНТЫ");
ДопустимыеИменаТипов.Добавить("ОТЧЕТЫ");
ДопустимыеИменаТипов.Добавить("ОБРАБОТКИ");
ДопустимыеИменаТипов.Добавить("БИЗНЕСПРОЦЕССЫ");
ДопустимыеИменаТипов.Добавить("ЖУРНАЛЫДОКУМЕНТОВ");
ДопустимыеИменаТипов.Добавить("ЗАДАЧИ");
ДопустимыеИменаТипов.Добавить("ПЛАНЫСЧЕТОВ");
ДопустимыеИменаТипов.Добавить("ПЛАНЫОБМЕНА");
ДопустимыеИменаТипов.Добавить("ПЛАНЫВИДОВХАРАКТЕРИСТИК");
ДопустимыеИменаТипов.Добавить("ПЛАНЫВИДОВРАСЧЕТА");
ИмяТипа = ВРег(ЧастиИмени[0]);
Если ДопустимыеИменаТипов.Найти(ИмяТипа) = Неопределено Тогда
ВызватьИсключение "Неправильный формат параметра ИмяЭкспортнойПроцедуры (" + ИмяЭкспортнойПроцедуры + ")";
КонецЕсли;
КонецЕсли;
ИмяМетода = ЧастиИмени[ЧастиИмени.ВГраница()];
ВременнаяСтруктура = Новый Структура;
Попытка
// Проверка на то, что ИмяМетода является допустимым идентификатором.
// Например: МояПроцедура
ВременнаяСтруктура.Вставить(ИмяМетода);
Исключение
ЗаписьЖурналаРегистрации(НСтр("ru = 'Безопасное выполнение метода'"),
УровеньЖурналаРегистрации.Ошибка, , , ОбработкаОшибок.ПодробноеПредставлениеОшибки(ИнформацияОбОшибке()));
ВызватьИсключение "Неправильный формат параметра ИмяЭкспортнойПроцедуры (" + ИмяЭкспортнойПроцедуры + ")";
КонецПопытки;
ПараметрыСтрока = "";
Если Параметры <> Неопределено И Параметры.Количество() > 0 Тогда
Для Индекс = 0 По Параметры.ВГраница() Цикл
ПараметрыСтрока = ПараметрыСтрока + "Параметры[" + Индекс + "],";
КонецЦикла;
ПараметрыСтрока = Сред(ПараметрыСтрока, 1, СтрДлина(ПараметрыСтрока) - 1);
КонецЕсли;
//@skip-check server-execution-safe-mode
Выполнить ИмяЭкспортнойПроцедуры + "(" + ПараметрыСтрока + ")";
КонецПроцедуры
// Функция - Выполнить несколько потоков расчета
//
// Параметры:
// МассивДанных - ТаблицаЗначений, Массив ИЗ Структура, ВыборкаИзРезультатаЗапроса - Определяет основной
// входной массив данных, по которым идет большой цикл пригодной к распараллеливанию обработки
// ВыполняемыйМетод - Строка - Метод из Общего модуля, а при ВыполнитьБезопасноИлиИзМенеджера = Истина еще и
// метод менеджера объекта (например, "ОбщийМодуль.ОбщийМетод" или "Обработки.ЗагрузкаСловаря.УбратьДубликаты")
// МассивПоследующихПараметров - Массив Из Тип - Массив сериализуемых параметров, которые будут применены к запуску
// в прямом порядке, т.е. МояФункция(МассивДанных, АдресХранилища, Массив[0], Массив[1]...
// Обратите внимание! Адрес хранилища, куда будут закладываться результаты
// в МассивеПоследующихПараметров ОТСУТСТВУЕТ, но должен стоять ВТОРЫМ у вызываемой функции
// КоличествоПотоков - Число - С этим (особенно при записи данных) нужно быть осторожным и опытным путем
// определять допустимое число фоновых заданий, которое будет параллельно вести расчеты/запись
// ВыполнитьБезопасноИлиИзМенеджера - Булево - По умолчанию фоновые задания могут выполняться только из общих модулей,
// однако это легко расширить (ставим Истина)
// ОбъединятьРезультаты - Булево - По умолчанию результаты выполнения будут объединяться в один массив, но в они должны быть массивом
//
// Возвращаемое значение:
// Массив Из Тип - Массив результатов всех потоков выполнения, чем бы они ни были
// (используется временное хранилище - должны быть сериализуемые)
//
Функция ВыполнитьНесколькоПотоковРасчета(МассивДанных, ВыполняемыйМетод, МассивПоследующихПараметров,
КоличествоПотоков, ВыполнитьБезопасноИлиИзМенеджера = Ложь, ОбъединятьРезультаты = Истина) Экспорт
АктивныеЗадания = Новый Массив; // Список Активных фоновых заданий
РезультатыВыполнения = Новый Массив;
КлючЗадания = Строка(Новый УникальныйИдентификатор);
Для Индекс = 1 По КоличествоПотоков Цикл
МассивПараметров = Новый Массив;
МассивПараметров.Добавить(МассивДанных);
Адрес = ПоместитьВоВременноеХранилище(Неопределено, Новый УникальныйИдентификатор);
МассивПараметров.Добавить(Адрес);
Для Каждого Запись Из МассивПоследующихПараметров Цикл
МассивПараметров.Добавить(Запись);
КонецЦикла;
Если ВыполнитьБезопасноИлиИзМенеджера Тогда
ПараметрыЗадания = Новый Массив;
ПараметрыЗадания.Добавить(ВыполняемыйМетод);
ПараметрыЗадания.Добавить(МассивПараметров);
ПараметрыЗадания.Добавить(Неопределено);
ФЗ = ФоновыеЗадания.Выполнить("ДлительныеОперацииСервер.ВыполнитьБезопасно", ПараметрыЗадания,, КлючЗадания);
Иначе
ФЗ = ФоновыеЗадания.Выполнить(ВыполняемыйМетод, МассивПараметров, , КлючЗадания);
КонецЕсли;
АктивныеЗадания.Добавить(Новый Структура("ИдентификаторФЗ, АдресХранилища", ФЗ.УникальныйИдентификатор, Адрес));
КонецЦикла;
// ждем, пока все задания выполнятся или грохнутся - дальше другой код
Настройки = НастройкиВыполнения(КоличествоПотоков);
Настройки.ОбъединятьРезультаты = ОбъединятьРезультаты;
ОбработкаОчередиЗаданий(АктивныеЗадания, Настройки, РезультатыВыполнения, Истина);
Возврат РезультатыВыполнения;
КонецФункции
// Функция - Выполнить функцию порциями
//
// Параметры:
// МассивДанных - ТаблицаЗначений, Массив ИЗ Структура, ВыборкаИзРезультатаЗапроса - Определяет основной
// входной массив данных, по которым идет большой цикл пригодной к распараллеливанию обработки
// ВыполняемыйМетод - Строка - Метод из Общего модуля, а при свойстве ВыполнятьБезопасноИлиИзМенеджера = Истина
// еще и метод Менеджера объекта (например, "ОбщийМодуль.ОбщийМетод" или "Обработки.ЗагрузкаСловаря.УбратьДубликаты")
// МассивПоследующихПараметров - Массив Из Тип - Массив сериализуемых параметров, которые будут применены к запуску
// в прямом порядке, т.е. МояФункция(МассивДанных, [Если ВР тогда АдресХранилища,] Массив[0], Массив[1]...
// Обратите внимание! Адрес хранилища, куда будут закладываться результаты при ВозвращатьРезультаты = ИСТИНА
// в МассивеПоследующихПараметров отсутствует, но должен стоять ВТОРЫМ у вызываемой функции
// НастройкиВыполнения - Структура - см. НастройкиВыполнения()
//
// КоличествоПотоков - Число - С этим (особенно при записи данных) нужно быть осторожным и опытным путем
// определять допустимое число фоновых заданий, которое будет параллельно вести расчеты/запись
// СтрокВПорции - Число - Если выбрать слишком маленький размер порции можно получить и замедление процесса
// из-за инициализации дополнительных сеансов. 100 или 1000 определяем по продолжительности
// ВозвращатьРезультаты - Булево - Вернуть результаты через помещение в во временное хранилище или нет,
// при Истине в параметрах функции ВТОРЫМ должен стоять АдресХранилища
// ОстанавливатьПриАвариях - Булево - Если при авариях оставшиеся данные нам уже неинтересны, тогда ставим Истину
// ВыполнятьБезопасноИлиИзМенеджера - Булево - По умолчанию фоновые задания могут выполняться только из Общих модулей,
// однако это легко расширить (ставим Истина)
// Возвращаемое значение:
// Массив Из Структура - Результаты выполнения всех потоков так, как если бы их объединили в одну таблицу
//
Функция ВыполнитьФункциюПорциями(МассивДанных, ВыполняемыйМетод, МассивПоследующихПараметров,
НастройкиВыполнения) Экспорт
КоличествоДанных = МассивДанных.Количество();
Если НастройкиВыполнения.КоличествоПотоков < 1 Тогда
НастройкиВыполнения.КоличествоПотоков = 1;
КонецЕсли;
Если НастройкиВыполнения.СтрокВПорции = 0 Тогда
НастройкиВыполнения.СтрокВПорции = Цел(КоличествоДанных / НастройкиВыполнения.КоличествоПотоков) + 1;
КонецЕсли;
АктивныеЗадания = Новый Массив; // Список Активных фоновых заданий
РезультатыВыполнения = Новый Массив;
СтруктураЗаписи = ОпределитьСтруктуруЗаписи(МассивДанных);
Если НастройкиВыполнения.ПередаватьТаблицуЗначений % 2 = 1 Тогда
ДанныеДляЗадания = Новый ТаблицаЗначений;
Для Каждого КлючЗначение Из СтруктураЗаписи Цикл
ДанныеДляЗадания.Колонки.Добавить(КлючЗначение.Ключ); // нет описания типов - в запрос ТЗ не передать
КонецЦикла;
Иначе
ДанныеДляЗадания = Новый Массив;
КонецЕсли;
КлючЗадания = Строка(Новый УникальныйИдентификатор);
ЭтоВыборка = (ТипЗнч(МассивДанных) = Тип("ВыборкаИзРезультатаЗапроса"));
ЭтоМассив = (ТипЗнч(МассивДанных) = Тип("Массив") И СтруктураЗаписи.Количество() = 0);
Если ЭтоМассив И НастройкиВыполнения.ПередаватьТаблицуЗначений > 0 Тогда
ВызватьИсключение "Использование простого массива для передачи в таблицу значений недоступно";
КонецЕсли;
Отметка = ТекущаяДатаСеанса();
Для Счетчик = 1 По КоличествоДанных Цикл
Если НастройкиВыполнения.ПередаватьТаблицуЗначений % 2 = 1 Тогда
//@skip-check bsl-legacy-check-dynamic-feature-access
Запись = ДанныеДляЗадания.Добавить();
Иначе
Запись = Новый Структура;
Для Каждого КлючЗначение Из СтруктураЗаписи Цикл
Запись.Вставить(КлючЗначение.Ключ);
КонецЦикла;
КонецЕсли;
Если ЭтоВыборка Тогда
МассивДанных.Следующий();
ЗаполнитьЗначенияСвойств(Запись, МассивДанных);
ИначеЕсли ЭтоМассив Тогда
Запись = МассивДанных.Получить(Счетчик - 1);
Иначе
ЗаполнитьЗначенияСвойств(Запись, МассивДанных.Получить(Счетчик - 1));
КонецЕсли;
Если НастройкиВыполнения.ПередаватьТаблицуЗначений % 2 = 0 Тогда
ДанныеДляЗадания.Добавить(Запись);
КонецЕсли;
Если Счетчик % НастройкиВыполнения.СтрокВПорции = 0 ИЛИ Счетчик = КоличествоДанных Тогда
// проверка потоков
БезаварийнаяОчередь = ОбработкаОчередиЗаданий(АктивныеЗадания, НастройкиВыполнения, РезультатыВыполнения);
Если НастройкиВыполнения.ОстанавливатьПриАвариях И БезаварийнаяОчередь = Ложь Тогда
Прервать;
КонецЕсли;
// запуск фонового задания и его фиксация
МассивПараметров = Новый Массив;
Если НастройкиВыполнения.ПередаватьТаблицуЗначений = 2 Тогда
МассивПараметров.Добавить(МассивЗаписейВТаблицуЗначений(ДанныеДляЗадания)); // подхватываем описания типов
Иначе
МассивПараметров.Добавить(ДанныеДляЗадания);
КонецЕсли;
Если НастройкиВыполнения.ВозвращатьРезультаты Тогда
Адрес = ПоместитьВоВременноеХранилище(Неопределено, Новый УникальныйИдентификатор);
МассивПараметров.Добавить(Адрес);
КонецЕсли;
Для Каждого Запись Из МассивПоследующихПараметров Цикл
МассивПараметров.Добавить(Запись);
КонецЦикла;
Если НастройкиВыполнения.ВыполнятьБезопасноИлиИзМенеджера Тогда
ПараметрыЗадания = Новый Массив;
ПараметрыЗадания.Добавить(ВыполняемыйМетод);
ПараметрыЗадания.Добавить(МассивПараметров);
ПараметрыЗадания.Добавить(Неопределено);
ФЗ = ФоновыеЗадания.Выполнить("ДлительныеОперацииСервер.ВыполнитьБезопасно", ПараметрыЗадания,, КлючЗадания);
Иначе
ФЗ = ФоновыеЗадания.Выполнить(ВыполняемыйМетод, МассивПараметров, , КлючЗадания);
КонецЕсли;
АктивныеЗадания.Добавить(Новый Структура("ИдентификаторФЗ, АдресХранилища", ФЗ.УникальныйИдентификатор, Адрес));
#Если НЕ (Сервер ИЛИ ВнешнееСоединение) Тогда
Состояние(Строка(Счетчик) + " из " + КоличествоДанных);
#КонецЕсли
Если НастройкиВыполнения.ПередаватьТаблицуЗначений % 2 = 1 Тогда
ДанныеДляЗадания.Очистить();
Иначе
ДанныеДляЗадания = Новый Массив;
КонецЕсли;
КонецЕсли; // СтрокВПорции
КонецЦикла; // КоличествоДанных
// ждем, пока все задания выполнятся или грохнутся - дальше другой код
ОбработкаОчередиЗаданий(АктивныеЗадания, НастройкиВыполнения, РезультатыВыполнения, Истина);
ВыполненныеЗадания = ФоновыеЗадания.ПолучитьФоновыеЗадания(Новый Структура("Наименование", КлючЗадания));
ПоискАварий = Новый Структура("Наименование, Состояние", КлючЗадания, СостояниеФоновогоЗадания.ЗавершеноАварийно);
ПоискОтмен = Новый Структура("Наименование, Состояние", КлючЗадания, СостояниеФоновогоЗадания.Отменено);
КоличествоАварийЗадания = ФоновыеЗадания.ПолучитьФоновыеЗадания(ПоискАварий).Количество();
Если КоличествоАварийЗадания > 0 Тогда
Если Счетчик = КоличествоДанных + 1 Тогда
Сообщение = "Метод: """ + ВыполняемыйМетод + """. Из " + ВыполненныеЗадания.Количество() + " заданий "
+ КоличествоАварийЗадания + " завершилось аварийно!";
Иначе
Сообщение = "Метод: """ + ВыполняемыйМетод + """. Создание заданий остановилось на " + Счетчик + " строке из "
+ КоличествоДанных;
КонецЕсли;
ЗаписьЖурналаРегистрации(НастройкиВыполнения.ПотокЖурналаРегистрации, УровеньЖурналаРегистрации.Ошибка,,, Сообщение);
Если НастройкиВыполнения.ОстанавливатьПриАвариях Тогда
ВызватьИсключение "При обработке задания порциями возникли проблемы";
КонецЕсли;
Иначе
КоличествоОтмененныхЗаданий = ФоновыеЗадания.ПолучитьФоновыеЗадания(ПоискОтмен).Количество();
ЗатраченоМинут = (ТекущаяДатаСеанса() - Отметка) / 60;
Если КоличествоОтмененныхЗаданий > 0 Тогда
ЗаписьЖурналаРегистрации(НастройкиВыполнения.ПотокЖурналаРегистрации, УровеньЖурналаРегистрации.Ошибка, , ,
"Обработка задания порциями шла без ошибок, но была отменена. Задание: " + ВыполняемыйМетод
+ ", обработано данных: " + Счетчик + ", затрачено минут: " + ЗатраченоМинут);
Иначе
ЗаписьЖурналаРегистрации(НастройкиВыполнения.ПотокЖурналаРегистрации, УровеньЖурналаРегистрации.Информация, , ,
"Обработка задания порциями завершилась без ошибок! Задание: " + ВыполняемыйМетод + ", обработано данных: "
+ КоличествоДанных + ", затрачено минут: " + ЗатраченоМинут);
КонецЕсли;
КонецЕсли;
Возврат РезультатыВыполнения;
КонецФункции
// Функция - Массив записей в таблицу значений
// Параметры:
// МассивЗаписей - Массив Из Структура - Массив однообразных структур для преобразования в таблицу
//
// Возвращаемое значение:
// ТаблицаЗначений - (Нет описания типов, в запрос не пойдет)
//
Функция МассивЗаписейВТаблицуЗначений(Знач МассивЗаписей) Экспорт
Таблица = Новый ТаблицаЗначений;
Если МассивЗаписей.Количество() > 0 Тогда
ОписаниеКолонок = Новый Структура;
Для Каждого КЗ Из МассивЗаписей[0] Цикл
ОписаниеКолонок.Вставить(КЗ.Ключ, Новый Соответствие);
КонецЦикла;
Для Каждого Запись Из МассивЗаписей Цикл
Для Каждого КЗ Из ОписаниеКолонок Цикл
КЗ.Значение.Вставить(ТипЗнч(Запись[КЗ.Ключ]), 1);
КонецЦикла;
КонецЦикла;
Для Каждого КЗ Из ОписаниеКолонок Цикл
ТипыКолонки = Новый Массив;
Для Каждого Запись Из КЗ.Значение Цикл
ТипыКолонки.Добавить(Запись.Ключ);
КонецЦикла;
Таблица.Колонки.Добавить(КЗ.Ключ, Новый ОписаниеТипов(ТипыКолонки));
КонецЦикла;
Для Каждого Запись Из МассивЗаписей Цикл
ЗаполнитьЗначенияСвойств(Таблица.Добавить(), Запись);
КонецЦикла;
КонецЕсли;
Возврат Таблица;
КонецФункции
// Выполняет приостановку выполнения кода на указанное количество секунд.
//
// Параметры:
// Секунд - Число - Количество секунд для паузы
Процедура Пауза(Знач Секунд) Экспорт
Если Секунд <= 0 Тогда
Возврат;
КонецЕсли;
Отметка = ТекущаяУниверсальнаяДатаВМиллисекундах();
ТекущийСеансИнформационнойБазы = ПолучитьТекущийСеансИнформационнойБазы();
ФоновоеЗадание = ТекущийСеансИнформационнойБазы.ПолучитьФоновоеЗадание();
Если ФоновоеЗадание = Неопределено Тогда
УстановитьПривилегированныйРежим(Истина);
ЗаданияКурить = ФоновыеЗадания.ПолучитьФоновыеЗадания(Новый Структура("Состояние, Наименование",
СостояниеФоновогоЗадания.Активно, "Курить"));
Если ЗаданияКурить.Количество() > 0 Тогда
// отгрузите мне немного
ЗаданияКурить[0].ОжидатьЗавершенияВыполнения(Секунд);
Секунд = Секунд - (ТекущаяУниверсальнаяДатаВМиллисекундах() - Отметка) / 1000;
КонецЕсли;
Если Секунд > 0 Тогда
// запрашиваю новую поставку!
Параметры = Новый Массив;
Параметры.Добавить(300);
ФоновоеЗадание = ФоновыеЗадания.Выполнить("ДлительныеОперацииСервер.Пауза", Параметры, , "Курить");
Смещение = (ТекущаяУниверсальнаяДатаВМиллисекундах() - Отметка) / 1000;
Если Смещение < Секунд Тогда
ФоновоеЗадание.ОжидатьЗавершенияВыполнения(Секунд - Смещение);
КонецЕсли;
КонецЕсли;
УстановитьПривилегированныйРежим(Ложь);
Иначе
ВызватьПаузу(Цел(Секунд * 1000));
КонецЕсли;
КонецПроцедуры
// Функция - Разделить строку по любому из разделителей (без включения пустых строк) - Для совместимости
//
// Параметры:
// Строка - Строка - Входная строка к разделению по разделителю
// НаборРазделителей - Строка - Список символов, разделяющих строку на части
//
// Возвращаемое значение:
// Массив Из Строка - Массив строк, разделенных по разделителю
//
Функция РазделитьСтроку(Знач Строка, Знач НаборРазделителей) Экспорт
ЧастиСтроки = Новый Массив;
Слово = "";
Для Индекс = 1 По СтрДлина(Строка) Цикл
Символ = Сред(Строка, Индекс, 1);
Если СтрНайти(НаборРазделителей, Символ) > 0 Тогда
Если Не ПустаяСтрока(Слово) Тогда
ЧастиСтроки.Добавить(Слово);
КонецЕсли;
Слово = "";
Иначе
Слово = Слово + Символ;
КонецЕсли;
КонецЦикла;
Если Не ПустаяСтрока(Слово) Тогда
ЧастиСтроки.Добавить(Слово);
КонецЕсли;
Возврат ЧастиСтроки;
КонецФункции
// Функция - Соединить строку разделителем - Для совместимости
//
// Параметры:
// ЧастиСтроки - Строка - Входная строка к разделению по разделителю
// Разделитель - Строка - Набор символов, разделяющих строку на части
//
// Возвращаемое значение:
// Строка - Строка после соединения массива
//
Функция СоединитьСтроку(Знач ЧастиСтроки, Знач Разделитель) Экспорт
Слово = "";
Для Индекс = 1 По ЧастиСтроки.Количество() Цикл
Слово = Слово + ЧастиСтроки[Индекс - 1] + Разделитель;
КонецЦикла;
Слово = Лев(Слово, СтрДлина(Слово) - СтрДлина(Разделитель));
Возврат Слово;
КонецФункции
// Функция - Таблица значений в массив записей
//
// Параметры:
// Таблица - ТаблицаЗначений, ВыборкаИзРезультатаЗапроса - Переводимый в сериализуемый набор данных
//
// Возвращаемое значение:
// Массив Из Структура - Сериализуемый массив структур для удобной обработки полей (нет НайтиСтроки и Сортировать)
//
Функция ТаблицаЗначенийВМассивЗаписей(Знач Таблица) Экспорт
КоличествоДанных = Таблица.Количество();
СтруктураЗаписи = ОпределитьСтруктуруЗаписи(Таблица);
ЭтоВыборка = (ТипЗнч(Таблица) = Тип("ВыборкаИзРезультатаЗапроса"));
МассивЗаписей = Новый Массив; // Передаем массив структур, таблица значений не катит
Для К = 1 По КоличествоДанных Цикл
Запись = Новый Структура;
Для Каждого КЗ Из СтруктураЗаписи Цикл
Запись.Вставить(КЗ.Ключ);
КонецЦикла;
Если ЭтоВыборка Тогда
Таблица.Следующий();
ЗаполнитьЗначенияСвойств(Запись, Таблица);
Иначе
ЗаполнитьЗначенияСвойств(Запись, Таблица.Получить(К - 1));
КонецЕсли;
МассивЗаписей.Добавить(Запись);
КонецЦикла;
Возврат МассивЗаписей;
КонецФункции
#КонецОбласти
#Область СлужебныйПрограммныйИнтерфейс
// Функция - Настройки выполнения
//
// Параметры:
// КоличествоПотоков - Число - Количество разрешенных потоков одновременно запускаемых фоновых заданий
// СтрокВПорции - Число - 0 ИЛИ Число строк из массива данных на одно фоновое задание
// ОстанавливатьПриАвариях - Булево - Останавливать ли выполнение всех заданий при ошибке в одном из них,
// при отмене одного из заданий, отменяются и все последующие
// ВозвращатьРезультаты - Булево - Собирать и возвращать результаты выполнения, сохраненные по адресу хранилища
//
// Возвращаемое значение:
// Структура - Структура со свойствами:
// * КоличествоПотоков - Число - Количество разрешенных потоков одновременно запускаемых фоновых заданий
// * ВыполнятьБезопасноИлиИзМенеджера - Булево - Выполнять напрямую (только общие модули) или через менеджер
// * ОбъединятьРезультаты - Булево - Объединять ли результаты выполнения в один массив
// * СтрокВПорции - Число - 0 ИЛИ Число строк из массива данных на одно фоновое задание
// * ОстанавливатьПриАвариях - Булево - Останавливать ли выполнение всех заданий при ошибке в одном из них
// * ВозвращатьРезультаты - Булево - Собирать и возвращать результаты выполнения, сохраненные по адресу хранилища
// * ПотокЖурналаРегистрации - Строка - Имя потока журнала регистрации
// * ПередаватьТаблицуЗначений - Число - 0 - Передавать массив (структур, например), 1 - передавать простую ТЗ,
// 2 - таблицу значений с описаниями типов
//
Функция НастройкиВыполнения(КоличествоПотоков, СтрокВПорции = 0, ОстанавливатьПриАвариях = Ложь,
ВозвращатьРезультаты = Истина) Экспорт
Настройки = Новый Структура("КоличествоПотоков, СтрокВПорции", КоличествоПотоков, СтрокВПорции);
Настройки.Вставить("ОстанавливатьПриАвариях", ОстанавливатьПриАвариях);
Настройки.Вставить("ВозвращатьРезультаты", ВозвращатьРезультаты);
Настройки.Вставить("ВыполнятьБезопасноИлиИзМенеджера", Истина);
Настройки.Вставить("ОбъединятьРезультаты", Истина);
Настройки.Вставить("ПотокЖурналаРегистрации", "Обработка заданий порциями");
Настройки.Вставить("ПередаватьТаблицуЗначений", 0);
Возврат Настройки;
КонецФункции
#КонецОбласти
#Область СлужебныеПроцедурыИФункции
// Функция - Ожидание свободных потоков исполнения, завершение очереди по необходимости, пополнение результатов
//
// Параметры:
// АктивныеЗадания - Массив ИЗ Структура - Массив заданий с полями Идентификатор и АдресХранилища
// НастройкиВыполнения - Структура - см. НастройкиВыполнения()
// РезультатыВыполнения - Массив Из Тип - Массив сериализуемых значений, полученных из Хранилища по Адресу хранилища
// по завершении задания
// Окончательная - Булево - Дожидаться завершения всех заданий или нет
//
// Возвращаемое значение:
// Булево - Возвращает Истина, когда есть свободные потоки и не было аварий
//
Функция ОбработкаОчередиЗаданий(АктивныеЗадания, НастройкиВыполнения, РезультатыВыполнения = Неопределено,
Окончательная = Ложь)
ОчередьБезаварийная = Истина;
ПроверкаВыполнена = Ложь;
ПаузаПриОбработкеОчереди = 0.1;
ПаузаПриОшибке = 180;
Если Окончательная ИЛИ НастройкиВыполнения.КоличествоПотоков < 1 Тогда
КоличествоПотоков = 1;
Иначе
КоличествоПотоков = НастройкиВыполнения.КоличествоПотоков;
КонецЕсли;
Пока АктивныеЗадания.Количество() >= КоличествоПотоков ИЛИ Не ПроверкаВыполнена
ИЛИ ОчередьБезаварийная = Ложь И АктивныеЗадания.Количество() > 0 Цикл
#Если Клиент Тогда
ОбработкаПрерыванияПользователя();
#КонецЕсли
ОбнаруженаАвария = Ложь;
// проверка наличия свободных потоков
Индекс = АктивныеЗадания.Количество();
Пока Индекс > 0 Цикл
Индекс = Индекс - 1;
// смысл в том, чтобы проверить статус у запущенного задания, и если он не активен - освободить место в массиве ФЗ
ТекущееЗадание = ФоновыеЗадания.НайтиПоУникальномуИдентификатору(АктивныеЗадания[Индекс].ИдентификаторФЗ);
Если ТекущееЗадание.Состояние = СостояниеФоновогоЗадания.Завершено Тогда
Если НастройкиВыполнения.ВозвращатьРезультаты Тогда
ПополнитьРезультаты(АктивныеЗадания[Индекс].АдресХранилища, НастройкиВыполнения.ОбъединятьРезультаты,
РезультатыВыполнения);
КонецЕсли;
ИначеЕсли ТекущееЗадание.Состояние <> СостояниеФоновогоЗадания.Активно Тогда
ОбнаруженаАвария = Истина;
ОчередьБезаварийная = Ложь;
Если ТекущееЗадание.Состояние = СостояниеФоновогоЗадания.Отменено Тогда
ЗаписьЖурналаРегистрации(НастройкиВыполнения.ПотокЖурналаРегистрации, УровеньЖурналаРегистрации.Ошибка, , ,
"Одна из порций задания с вызовом метода """ + ТекущееЗадание.ИмяМетода +
""" была отменена. Выполнение будет остановлено");
НастройкиВыполнения.ОстанавливатьПриАвариях = Истина;
КонецЕсли;
Иначе
Продолжить;
КонецЕсли;
АктивныеЗадания.Удалить(Индекс);
Для Каждого Сообщение Из ТекущееЗадание.ПолучитьСообщенияПользователю(Истина) Цикл
Сообщение.Сообщить();
КонецЦикла;
КонецЦикла; // АктивныеЗадания
// запуск паузы или отмена всего, если что-то пошло не так
Если ОбнаруженаАвария Тогда
Если НастройкиВыполнения.ОстанавливатьПриАвариях Тогда
Для Каждого Запись Из АктивныеЗадания Цикл
ФоновыеЗадания.НайтиПоУникальномуИдентификатору(Запись.ИдентификаторФЗ).Отменить();
КонецЦикла;
АктивныеЗадания.Очистить();
Иначе
// ждем 3 минуты, возможно, сервер просто крепко занят
Пауза(ПаузаПриОшибке);
КонецЕсли;
Иначе
Если АктивныеЗадания.Количество() >= КоличествоПотоков Тогда
Пауза(ПаузаПриОбработкеОчереди);
КонецЕсли;
КонецЕсли;
ПроверкаВыполнена = Истина;
КонецЦикла; // КоличествоПотоков
Возврат ОчередьБезаварийная;
КонецФункции
// Функция - Определить структуру записи для передачи в параметр сериализуемого значения вызываемой в фоне процедуры
//
// Параметры:
// МассивДанных - ТаблицаЗначений, Массив ИЗ Структура, ВыборкаИзРезультатаЗапроса - Определяет
// основной входной массив данных
//
// Возвращаемое значение:
// Структура - Структура со всеми полями/колонками, в копии которой будут записываться данные основного массива
//
Функция ОпределитьСтруктуруЗаписи(МассивДанных)
СтруктураЗаписи = Новый Структура;
ТипМассива = ТипЗнч(МассивДанных);
Если ТипМассива = Тип("Массив") Тогда
Если МассивДанных.Количество() > 0 И ТипЗнч(МассивДанных.Получить(0)) = Тип("Структура") Тогда
Для Каждого КЗ Из МассивДанных.Получить(0) Цикл
СтруктураЗаписи.Вставить(КЗ.Ключ);
КонецЦикла;
КонецЕсли;
ИначеЕсли ТипМассива = Тип("ТаблицаЗначений") Тогда
Для Каждого Колонка Из МассивДанных.Колонки Цикл
СтруктураЗаписи.Вставить(Колонка.Имя);
КонецЦикла;
ИначеЕсли ТипМассива = Тип("ВыборкаИзРезультатаЗапроса") Тогда
Для Каждого Колонка Из МассивДанных.Владелец().Колонки Цикл
СтруктураЗаписи.Вставить(Колонка.Имя);
КонецЦикла;
Иначе
ВызватьИсключение "Неподдерживаемый тип входного массива данных";
КонецЕсли;
Возврат СтруктураЗаписи;
КонецФункции
Процедура ПополнитьРезультаты(Знач Адрес, Знач ОбъединятьРезультаты, Знач РезультатыВыполнения)
Если ЭтоАдресВременногоХранилища(Адрес) И РезультатыВыполнения <> Неопределено Тогда
РезультатыЗадания = ПолучитьИзВременногоХранилища(Адрес);
Если РезультатыЗадания <> Неопределено Тогда
Если ОбъединятьРезультаты Тогда
Для Каждого Результат Из РезультатыЗадания Цикл
РезультатыВыполнения.Добавить(Результат);
КонецЦикла;
Иначе
РезультатыВыполнения.Добавить(РезультатыЗадания);
КонецЕсли;
КонецЕсли;
КонецЕсли;
КонецПроцедуры
#КонецОбласти
Также можно скачать проект для EDT на сайте gitflic по ключевым словам "фоновые задания". Там кроме БСП-шных будет две обработки, одна по статье Фоновые задания для новичков, другая по этой - Демонстрация многопоточной работы. Кстати, БСП для внедрения необязательна. Приятной многопоточной работы всем!

{kind=link}