Вступайте в нашу телеграмм-группу Инфостарт
Использование нарастающих итогов в партионном учете и не только
25.08.11
Разработка - Математика и алгоритмы
Данный материал является иллюстрацией способов работы с запросами, использующими методику вычисления «нарастающих итогов». Также в данной статье рассматриваются вопросы практического использования запросов такого рода при партионном учете и расчете задолженностей.
Фактически в данной статье рассматриваются альтернативы запросам, приведенным в статьях http://infostart.ru/public/61295/ и http://infostart.ru/public/68225/.
Полный текст статьи можно также найти на http://nashe1c.ru/materials-view.jsp?id=383.
Фактически в данной статье рассматриваются альтернативы запросам, приведенным в статьях http://infostart.ru/public/61295/ и http://infostart.ru/public/68225/.
Полный текст статьи можно также найти на http://nashe1c.ru/materials-view.jsp?id=383.
Файлы
ВНИМАНИЕ: Файлы из Базы знаний - это исходный код разработки. Это примеры решения задач, шаблоны, заготовки, "строительные материалы" для учетной системы. Файлы ориентированы на специалистов 1С, которые могут разобраться в коде и оптимизировать программу для запуска в базе данных. Гарантии работоспособности нет. Возврата нет. Технической поддержки нет.
Подписка PRO — скачивайте любые файлы со скидкой до 85% из Базы знаний
Оформите подписку на компанию для решения рабочих задач
Оформить подписку и скачать решение со скидкойВы можете заказать платную доработку или адаптацию этой разработки под вашу конфигурацию на «Бирже заказов».
- 0% комиссии — оплата напрямую исполнителю;
- Исполнители любого масштаба — от отдельных специалистов до команд под проект;
- Прямой обмен контактами между заказчиком и исполнителем;
- Безопасная сделка — при необходимости;
- Рейтинги, кейсы и прозрачная система откликов.
См. также
Математика и алгоритмы Программист 1С 8.3 Абонемент ($m)
Данная внешняя обработка для платформы 1С:Предприятие реализует усовершенствованный алгоритм Левенштейна для вычисления схожести строк с учетом различных лингвистических особенностей русского языка. В отличие от классической реализации, этот алгоритм учитывает фонетические, визуальные и контекстные особенности набора текста.
1 стартмани
07.11.2025 5908 14 InFlach 17
Математика и алгоритмы Запросы Программист 1С:Предприятие 8 Бесплатно (free)
Рассмотрим быстрый алгоритм поиска дублей с использованием hash функции по набору полей шапки и табличных частей.
08.07.2024 6705 ivanov660 9
Математика и алгоритмы Программист 1С:Предприятие 8 1C:Бухгалтерия Россия Абонемент ($m)
На написание данной работы меня вдохновила работа @glassman «Переход на ClickHouse для анализа метрик». Автор анализирует большой объем данных, много миллионов строк, и убедительно доказывает, что ClickHouse справляется лучше PostgreSQL. Я же покажу как можно сократить объем данных в 49.9 раз при этом: 1. Сохранить значения локальных экстремумов 2. Отклонения от реальных значений имеют наперед заданную допустимую погрешность.
1 стартмани
30.01.2024 14576 stopa85 12
Математика и алгоритмы Бесплатно (free)
Разработка алгоритма, построенного на модели симплекс-метода, для нахождения оптимального раскроя.
19.10.2023 22735 user1959478 57
Математика и алгоритмы Разное 1С:Предприятие 8 1C:Бухгалтерия Россия Абонемент ($m)
Расширение (+ обработка) представляют собою математический тренажер. Ваш ребенок сможет проверить свои знание на математические вычисление до 100.
2 стартмани
29.09.2023 13627 maksa2005 8
Математика и алгоритмы Инструментарий разработчика Программист 1С:Предприятие 8 Россия Абонемент ($m)
Что ж... лучше поздно, чем никогда. Подсистема 1С для работы с регулярными выражениями: разбор выражения, проверка на соответствие шаблону, поиск вхождений в тексте.
1 стартмани
09.06.2023 23537 11 SpaceOfMyHead 20
Математика и алгоритмы Программист 1С:Предприятие 8 Бесплатно (free)
Три задачи - три идеи - три решения. Мало кода, много смысла. Мини-статья.
03.04.2023 15455 RustIG 10
Механизмы платформы 1С Математика и алгоритмы Программист 1С:Предприятие 8 Россия Бесплатно (free)
В статье анализируются средства платформы для решения системы линейных уравнений в 1С. Приводятся доводы в пользу некорректной работы встроенных алгоритмов, а значит потенциально некорректного расчета себестоимости в типовых конфигурациях.
23.11.2022 14481 gzharkoj 17
Комментарии
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
За рекламу - спасибо.
Пробежал мельком . Пока замечание :
в статье никак не отмечено : использование нарастающих итогов "в лоб"
(т.е. использвание содинения по неравенству в запросе) для больших таблиц приведет к "падению" всего алгоритма.
По оформлению : лучше оформить статью на ИС как полагается , а не предлагать файл со статьей к скачиванию.
Пробежал мельком . Пока замечание :
в статье никак не отмечено : использование нарастающих итогов "в лоб"
(т.е. использвание содинения по неравенству в запросе) для больших таблиц приведет к "падению" всего алгоритма.
По оформлению : лучше оформить статью на ИС как полагается , а не предлагать файл со статьей к скачиванию.
Формально эта статья опубликована на (если кому "лень качать файло" :) ).
Позже еще покопаюсь здесь - не нашел сразу как вставлять в статью картинки при публикации на этом сайте.
To Ish_2: аргументируйте, пожалуйста, как именно может повлиять размер таблиц на работу этого алгоритма?
Позже еще покопаюсь здесь - не нашел сразу как вставлять в статью картинки при публикации на этом сайте.
To Ish_2: аргументируйте, пожалуйста, как именно может повлиять размер таблиц на работу этого алгоритма?
Пока по мелочи . Что бросилась в глаза .
В объяснении текста запроса
Написано :
Ошибка. То есть использование функции "МАХ" в данном случае не является необходимым
Правильно :
В объяснении текста запроса
SELECT
tab1.Номенклатура,
tab1.Партия,
( SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + MAX( tab1.КоличествоОстаток ) ) AS НарастающийИтог ...Написано :
вместо простого прибавления к сумме остатков по предыдущим партиям текущего остатка мы прибавляем функцию «MAX» от текущего остатка. Это необходимо по правилу использования группировок в запросе – все данные, не вошедшие в поля группировки, должны выражаться через функции языка запросов.
Ошибка. То есть использование функции "МАХ" в данном случае не является необходимым
Правильно :
SELECT
tab1.Номенклатура,
tab1.Партия,
SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + tab1.КоличествоОстаток AS НарастающийИтог ...
На всякий случай уточню, что представленный в статье вид запроса как-раз и позволяет сильно ограничить количество записей в результирующем наборе. Сам по себе запрос может быть транслирован в SQL без изменений и, тем самым, позволяет работать с большими начальными таблицами, получая только необходимые выходные данные (без дополнительных обработок в последующих запросах или в текстах модулей).
(6) В конфигурации прикрепленной к теме "ФИФО для любопытных"
использован именно такой запрос без МАХ.
Почему для больших таблиц соединение по неравенству работает оч. медленно можно прочитать в теме "Подведем итоги.Нарастающме" .
Можно убедиться в этом самостятельно : создайте таблицу tab1 с количеством записей 1 000 000 .
Запустите Ваш запрос - соединение по неравенству tab1 "сама с собой" засеките время. И всё поймете... назавтра.
использован именно такой запрос без МАХ.
Почему для больших таблиц соединение по неравенству работает оч. медленно можно прочитать в теме "Подведем итоги.Нарастающме" .
Можно убедиться в этом самостятельно : создайте таблицу tab1 с количеством записей 1 000 000 .
Запустите Ваш запрос - соединение по неравенству tab1 "сама с собой" засеките время. И всё поймете... назавтра.
В упомянутой конфигурации используется конструкция вида:
SELECT
Поле1,
СУММА( Поле2 ) + Поле1
FROM
GROUP BY Поле1
Здесь да, наличие MAX/MIN не нужно. Но в моем запросе используется поле, по которому отсутствует группировка. Так что это поле ОБЯЗАТЕЛЬНО должно включаться в выражения запроса в виде функции языка запросов. Насчет скорости исполнения - я проведу такие испытания, но еще раз скажу, что суммирование или простое сравнение по индексу для SQL выполняется очень быстро. Размер таблиц в миллион записей никак не влияет на скорость исполнения. Возможно здесь будет влиять сама 1С, но это уже другой вопрос.
SELECT
Поле1,
СУММА( Поле2 ) + Поле1
FROM
GROUP BY Поле1
Здесь да, наличие MAX/MIN не нужно. Но в моем запросе используется поле, по которому отсутствует группировка. Так что это поле ОБЯЗАТЕЛЬНО должно включаться в выражения запроса в виде функции языка запросов. Насчет скорости исполнения - я проведу такие испытания, но еще раз скажу, что суммирование или простое сравнение по индексу для SQL выполняется очень быстро. Размер таблиц в миллион записей никак не влияет на скорость исполнения. Возможно здесь будет влиять сама 1С, но это уже другой вопрос.
(9) Мда.. Зачем спорить ? Вы попробуйте.
Вот Ваш вариант с "МАХ" :
Вот мой без "МАХ":
Ну как ? Получилось ?
Вот Ваш вариант с "МАХ" :
SELECT
tab1.Номенклатура,
tab1.Партия,
( SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + MAX( tab1.КоличествоОстаток ) ) AS НарастающийИтог
FROM РегистрНакопления.ОстаткиНоменклатуры.Остатки AS tab1
LEFT JOIN РегистрНакопления.ОстаткиНоменклатуры.Остатки AS tab2
ON ( tab1.Номенклатура = tab2.Номенклатура ) AND ( tab1.Партия > tab2.Партия )
GROUP BY tab1.Номенклатура, tab1.Партия;Вот мой без "МАХ":
SELECT
tab1.Номенклатура,
tab1.Партия,
SUM( ISNULL( tab2.КоличествоОстаток, 0 ) ) + tab1.КоличествоОстаток AS НарастающийИтог
FROM РегистрНакопления.ОстаткиНоменклатуры.Остатки AS tab1
LEFT JOIN РегистрНакопления.ОстаткиНоменклатуры.Остатки AS tab2
ON ( tab1.Номенклатура = tab2.Номенклатура ) AND ( tab1.Партия > tab2.Партия )
GROUP BY tab1.Номенклатура, tab1.Партия;Ну как ? Получилось ?
(15) Платформа 8.2.13.205.
Проверена в работе конфигурация . Содержит запрос:
Ищите ошибку у себя.
Проверена в работе конфигурация . Содержит запрос:
|ВЫБРАТЬ
| Приход.Период,
| Приход.МоментВремени,
| Приход.Партия,
| Приход.Номенклатура,
| Приход.Количество,
| Приход.Сумма,
//
| СУММА(Приход1.Количество) - Приход.Количество КАК КоличествоДо, // Внимание ! Приход.КОличество без МАХ
//
| СУММА(Приход1.Количество) КАК КоличествоПосле
|ПОМЕСТИТЬ НарПриход
|ИЗ
| Приход КАК Приход
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Приход КАК Приход1
| ПО Приход.Номенклатура = Приход1.Номенклатура
| И Приход.МоментВремени >= Приход1.МоментВремени
|
|СГРУППИРОВАТЬ ПО
| Приход.Партия,
| Приход.Период,
| Приход.МоментВремени,
| Приход.Номенклатура,
| Приход.Количество,
| Приход.Сумма
|; ПоказатьИщите ошибку у себя.
Я тут подумал: может Вы просто перепутали конструкции запроса? То есть существует такая конструкция как "ИТОГИ Поле1, СУММА(Поле2) ПО Поле1". Вот там в самом тексте запроса функции употреблять не надо - они применяются только в итогах. На всякий случай: по-английски это пишется как "TOTALS Поле1, SUM(Поле2) BY Поле1".
Я хотел бы внимание обратить на другую ошибку. В запросе оперируют данными виртуальной таблицы Остатки, что методологически неверно, т.к. остатки - это УЖЕ результат расчета с нарастающими итогами. И использование остатков в запросе с нарастающими итогами чрезвычайно ограничено.
Пока я не вижу новизну в статье, а только ошибку.
Такое объединение в запросе существенно ограничено количеством объединяемых записей.
1
2 > 1
3 > 1 + 2
4 > 1 + 2 + 3
5 > 1 + 2 + 3 + 4
в итоге получаем таблицу
1
2 1
3 1
3 2
4 1
4 2
4 3
5 1
5 2
5 3
5 4
Вместо 5 изначальных записей, получили 11. И прогрессия эта даже не геометрическая.
Пока я не вижу новизну в статье, а только ошибку.
Такое объединение в запросе существенно ограничено количеством объединяемых записей.
1
2 > 1
3 > 1 + 2
4 > 1 + 2 + 3
5 > 1 + 2 + 3 + 4
в итоге получаем таблицу
1
2 1
3 1
3 2
4 1
4 2
4 3
5 1
5 2
5 3
5 4
Вместо 5 изначальных записей, получили 11. И прогрессия эта даже не геометрическая.
Про "неправильное методологическое поведение" я комментарий опущу. А вот насчет "геометрической прогрессии": в запросе нет объединения "все со всеми", соединение с "правой" таблице нужно только для вычисления функции суммы по остаткам.
(22) Сумма остатков! Это фигня получится.
Нач.ост = 0
Приход 10 Остаток = 10
Приход 11 Остаток = 21
Приход 5 Остаток = 26
Расход 1 Остаток = 25
Теперь нарастающий итог для последней строки с суммой остатков будет.... пырым-пым-пым ---- 10 + 21 + 26 = 57... фигня какая-то.
Нач.ост = 0
Приход 10 Остаток = 10
Приход 11 Остаток = 21
Приход 5 Остаток = 26
Расход 1 Остаток = 25
Теперь нарастающий итог для последней строки с суммой остатков будет.... пырым-пым-пым ---- 10 + 21 + 26 = 57... фигня какая-то.
(29) в регистре накопления есть Вид движения Приход и Расход. Знак при этом не меняется. Это в запросе можно получить уже Приход = Количество, а Расход = Количество*-1 или в две отдельные колонки. Знак тут не принципиален. Главное невразумительность сложения ОСТАТКОВ.
(32) Тут хитрость методологии.
Складываются остатки не по операциям движений по регистрам, а остатки по партиям. Т.е. для списания нужно набрать пул списываемых партий и, собственно, всё.
Простая задачка. Не нужно усложнять.
См. (18)
Складываются остатки не по операциям движений по регистрам, а остатки по партиям. Т.е. для списания нужно набрать пул списываемых партий и, собственно, всё.
Простая задачка. Не нужно усложнять.
См. (18)
Пока я не вижу новизну в статье
Конечно, ничего сложного! Просто мне было нужно, чтобы все вычислялось в рамках одного запроса, а не 7-ми как в . Я долго копался в Интернете, думал, что кто-то ведь наверняка должен был до этого додуматься - не нашел. Если есть ссылки на другие варианты решения задач, описанных в моей статье - буду очень благодарен!
(35) решение "в лоб" опубликовано на мисте уже давно. Я ещё повторю, ничего нового, кроме непонятного практического значения остаток по партии + сумма остатков партий до него. Хотя нет. Понял. Новизны нет. Всё тот же запрос в "лоб"
7 запросов нужно для оптимизации расчетов.
7 запросов нужно для оптимизации расчетов.
(22) а про объединение...Вот именно, что ВЫЧИСЛЕНИЕ. Для каждой из 5 записей будет производится свой расчет суммы с увеличением числа слагаемых.
т.е. будет не 1+2+3+4+5 = 5 действий сложений, как если это делать с помощью цикла в коде, а будет 11 действий сложений. И число операций сложений будет расти ОЧЕНЬ быстро.
т.е. будет не 1+2+3+4+5 = 5 действий сложений, как если это делать с помощью цикла в коде, а будет 11 действий сложений. И число операций сложений будет расти ОЧЕНЬ быстро.
Скажем так: подсчет суммы по любому числовому полю любой SQL таблицы с помощью запроса и функции SUM() вычисляется в разы быстрее, чем с помощью перебора всех строк и дальнейшего подсчета суммы с помощью любых алгоритмов. Я придерживаюсь этого мнения.
(31) Вопрос в том, что sum() будет вызываться столько раз, сколько записей в таблице. И каждый раз ему для расчетов будет передаваться такое число все большее число записей. В отличие от этого подхода, в цикле можно хранить предыдущий итог и прибавлять уже к нему (в sql это тоже можно организовать, но речь идет о запросе 1с, которые не умеет делать такого). В результате наступит такой момент, когда время выполнения Sum() с n записей будет выполнятся дольше, чем сложение двух цифр ПромежуточныйИтог + ТекущееЧисло в очередной итерации цикла. Это одна сторона. Другая сторона, что вообще время выполнения запроса 1с СУЩЕСТВЕННО увеличится. Проблема такого подхода в запросе, что вычисления для каждой записи каждый раз выполняеются ЗАНОВО с возрастающей нагрузкой на выч.ресурсы. В коде же нагрузка постоянна (ну кроме, увеличения объема памяти под хранения итогов).
Запрос "в лоб" выигрывает на маленьких объемах данных, цикл на больших. Но они оба проигрывают оптимизированному алгоритму запроса 1с или прямому запросу sql с организацией цикла прямо в запросе.
Запрос "в лоб" выигрывает на маленьких объемах данных, цикл на больших. Но они оба проигрывают оптимизированному алгоритму запроса 1с или прямому запросу sql с организацией цикла прямо в запросе.
Приведу преимущества приведенного в моей статье подхода:
1) Использование только одного запроса для получения полного списка партий для списания для всего перечня номенклатуры;
2) Относительная простота применяемого запроса для понимания;
3) Применение функций языка запросов для ускорения обработки вместо прямого перебора в коде;
4) Возможность дальнейшей оптимизации использования данного запроса;
1) Использование только одного запроса для получения полного списка партий для списания для всего перечня номенклатуры;
2) Относительная простота применяемого запроса для понимания;
3) Применение функций языка запросов для ускорения обработки вместо прямого перебора в коде;
4) Возможность дальнейшей оптимизации использования данного запроса;
Насчет "полный код процедуры списания на замену штатному":
1) Выполняем запрос, получаем все реквизиты для формирования движений списания (период, вид движений, номенклатура, партия, количество, сумма);
2) Загружаем в реквизит объекта документа "Движения" результат выполнения запроса;
3) Записываем "Движения";
Провести полноценный тест запроса не имею возможности. Но чисто теоретически он должен выполнятся крайне быстро и эффективно. Я верю в него :)
1) Выполняем запрос, получаем все реквизиты для формирования движений списания (период, вид движений, номенклатура, партия, количество, сумма);
2) Загружаем в реквизит объекта документа "Движения" результат выполнения запроса;
3) Записываем "Движения";
Провести полноценный тест запроса не имею возможности. Но чисто теоретически он должен выполнятся крайне быстро и эффективно. Я верю в него :)
На мой взгляд приведенный "запрос в лоб на мисте" выглядит неоптимальным: применяется вложенный запрос по периодом (получается список неповторяющихся периодов), потом соединяется с полным списком периодов (не уникальный список периодов), а потом еще и группируется вновь по периодам, подсчитывая сумму.
Более логичным было бы использование такого запроса:
SELECT
tab1.Период КАК Время,
SUM( tab2.СуммаОборот ) КАК Сумма
FROM РегистрНакопления.ПродажиПоДисконтнымКартам.Обороты(, , Регистратор, ДисконтнаяКарта = &Ссылка) AS tab1
LEFT JOIN РегистрНакопления.ПродажиПоДисконтнымКартам.Обороты(, , Регистратор, ДисконтнаяКарта = &Ссылка) AS tab2
ON tab1.Период >= tab2.Период
GROUP BY tab1.Период
Более логичным было бы использование такого запроса:
SELECT
tab1.Период КАК Время,
SUM( tab2.СуммаОборот ) КАК Сумма
FROM РегистрНакопления.ПродажиПоДисконтнымКартам.Обороты(, , Регистратор, ДисконтнаяКарта = &Ссылка) AS tab1
LEFT JOIN РегистрНакопления.ПродажиПоДисконтнымКартам.Обороты(, , Регистратор, ДисконтнаяКарта = &Ссылка) AS tab2
ON tab1.Период >= tab2.Период
GROUP BY tab1.Период
(49) это просто подход к проблеме - простое соединение по условию ">="
и вообще вложенные запросы признаны самой 1с неэффективными. Нужно использовать пакетные запросы. Кстати, формально, те 7 запросов, объединенные в качестве пакетных, являются 1 запросом.
и вообще вложенные запросы признаны самой 1с неэффективными. Нужно использовать пакетные запросы. Кстати, формально, те 7 запросов, объединенные в качестве пакетных, являются 1 запросом.
На мисте используется точно такое же соединение по условию ">=" :) В моем варианте запроса исправлены недостатки запроса с мисты.
Еще раз по запросу на мисте:
1) В первом вложенном запросе выбирается список уникальных периодов;
2) Затем во втором вложенном запросе выбирается полный список периодов () вместе с их суммами оборотов;
3) Затем эти два подзапроса соединяются: получается что весь список уникальных периодов соединяется со списком неуникальных периодов;
4) Затем происходит группировка по периодом, то есть опять происходит процедура формирования списка уникальных периодов;
Очевидно, что запрос на мисте не оптимален.
Насчет "7 запросов, объединенных в качестве пакетных": у меня запрос только один :) Судя по текстовому алгоритму из упоминаемой статьи этот алгоритм может быть разбит МИНИМУМ на 3 подзапроса. Еще раз - у меня эта задача решена в один запрос, понятный и ясный для понимания.
Еще раз по запросу на мисте:
1) В первом вложенном запросе выбирается список уникальных периодов;
2) Затем во втором вложенном запросе выбирается полный список периодов () вместе с их суммами оборотов;
3) Затем эти два подзапроса соединяются: получается что весь список уникальных периодов соединяется со списком неуникальных периодов;
4) Затем происходит группировка по периодом, то есть опять происходит процедура формирования списка уникальных периодов;
Очевидно, что запрос на мисте не оптимален.
Насчет "7 запросов, объединенных в качестве пакетных": у меня запрос только один :) Судя по текстовому алгоритму из упоминаемой статьи этот алгоритм может быть разбит МИНИМУМ на 3 подзапроса. Еще раз - у меня эта задача решена в один запрос, понятный и ясный для понимания.
А вообще-то мой запрос еще можно оптимизировать: если "РегистрНакопления.ПродажиПоДисконтнымКартам" является только оборотным регистром, то можно вместо виртуальной таблицы оборотов и детализации периодов до регистратора использовать просто полный список движений по регистру. Получилось бы еще быстрее и понятнее.
Вот как-то так:
SELECT
tab1.Период КАК Время,
SUM( tab2.СуммаОборот ) КАК Сумма
FROM РегистрНакопления.ПродажиПоДисконтнымКартам AS tab1
LEFT JOIN РегистрНакопления.ПродажиПоДисконтнымКартам AS tab2
ON tab1.Период >= tab2.Период
WHERE (tab1.ДисконтнаяКарта = &Ссылка) AND (tab2.ДисконтнаяКарта = &Ссылка)
GROUP BY tab1.Период
Вот как-то так:
SELECT
tab1.Период КАК Время,
SUM( tab2.СуммаОборот ) КАК Сумма
FROM РегистрНакопления.ПродажиПоДисконтнымКартам AS tab1
LEFT JOIN РегистрНакопления.ПродажиПоДисконтнымКартам AS tab2
ON tab1.Период >= tab2.Период
WHERE (tab1.ДисконтнаяКарта = &Ссылка) AND (tab2.ДисконтнаяКарта = &Ссылка)
GROUP BY tab1.Период
54.
ildarovich
8063
25.08.11 16:19
Сейчас в теме
Если автор более точно сформулирует решаемую им задачу, станет понятно, что утверждение
ошибочно.
Как я понял, автор предлагает вместо получения запросом таблицы партий из регистра накопления "остатки партий товаров" и последующего построения в цикле таблицы списания партий, решать задачу в запросе. Не вижу в этом проблемы. Думаю, что в большинстве решений, поддерживающих партионный учет, так и сделано.
Чаще всего таблице ненулевых остатков партий (по одной номенклатуре) - одна - две строки, что там оптимизировать?
Фактически в данной статье рассматриваются альтернативы запросам, приведенным в статьях и .
ошибочно.
Как я понял, автор предлагает вместо получения запросом таблицы партий из регистра накопления "остатки партий товаров" и последующего построения в цикле таблицы списания партий, решать задачу в запросе. Не вижу в этом проблемы. Думаю, что в большинстве решений, поддерживающих партионный учет, так и сделано.
Чаще всего таблице ненулевых остатков партий (по одной номенклатуре) - одна - две строки, что там оптимизировать?
В моей статье в качестве последнего запроса приведено прямое решение для задачи из . Приведенное мною решение более компактно и понятно. Использования запросов такого вида где-либо еще (в типов ли конфигурациях или просто на просторах Интернета) я не нашел - буду благодарен за любую ссылку на подобный материал!
(55) Вышел с "больничного".
Реализация метода ФИФО предполагает получение движений для всех документов расхода за период.
Именно в такой постановке рещается задача в "ФИФо для любопытных".
В Вашей постановке задачи априори мы имеем таблицу, определяющую количество списания , с колонками :
• Столбец «Номенклатура»;
• Столбец «Количество» - общее количество, которое должно быть списано со всех партий для данной номенклатурной единицы;
Т.е. здесь мы имеем суммарное по всем документам расхода количество для списания - это серьезное упрощение
задачи. Вычислить движения по партиям нужно ведь в разрезе каждого документа расхода .
На практике при реализации метода ФИФО на входе имеем не таблицу с итогами количества по списанию ,
а таблицу с колонками
• Столбец «ДокументРасходнаяНакладная»;
• Столбец «Номенклатура»;
• Столбец «Количество» - количество списания по накладной
А это значит на выходе мы должны получить НЕ Вашу таблицу с колонками :
• Столбец «Номенклатура»;
• Столбец «Партия»;
• Столбец «КоличествоСписания» - количество списания по накладной
• Столбец «СуммаСписания» - количество списания по накладной
А другую таблицу
• Столбец «ДокументРасходнаяНакладная»;
• Столбец «Номенклатура»;
• Столбец «Партия»;
• Столбец «КоличествоСписания» - количество списания по накладной
• Столбец «СуммаСписания» - количество списания по накладной
Реализация метода ФИФО предполагает получение движений для всех документов расхода за период.
Именно в такой постановке рещается задача в "ФИФо для любопытных".
В Вашей постановке задачи априори мы имеем таблицу, определяющую количество списания , с колонками :
• Столбец «Номенклатура»;
• Столбец «Количество» - общее количество, которое должно быть списано со всех партий для данной номенклатурной единицы;
Т.е. здесь мы имеем суммарное по всем документам расхода количество для списания - это серьезное упрощение
задачи. Вычислить движения по партиям нужно ведь в разрезе каждого документа расхода .
На практике при реализации метода ФИФО на входе имеем не таблицу с итогами количества по списанию ,
а таблицу с колонками
• Столбец «ДокументРасходнаяНакладная»;
• Столбец «Номенклатура»;
• Столбец «Количество» - количество списания по накладной
А это значит на выходе мы должны получить НЕ Вашу таблицу с колонками :
• Столбец «Номенклатура»;
• Столбец «Партия»;
• Столбец «КоличествоСписания» - количество списания по накладной
• Столбец «СуммаСписания» - количество списания по накладной
А другую таблицу
• Столбец «ДокументРасходнаяНакладная»;
• Столбец «Номенклатура»;
• Столбец «Партия»;
• Столбец «КоличествоСписания» - количество списания по накладной
• Столбец «СуммаСписания» - количество списания по накладной
Вспомнилась фраза из старого фильма, сказанная со смешной интонацией - "Не вижу препятствий!" :) Этот вопрос я уже обсуждал в : очень просто вместо таблицы только с номенклатурой и количеством получить таблицу с документом, всей номенклатурой и всеми количествами. Точно также используем ее в запроса, добавляя только группировку по регистратору. То есть в "ТаблицеНоменклатуры" будет еще одно поле - "РасходнаяНакладная" (или лучше назвать это поле сразу "Регистратор" для последующей выгрузки результата запроса в набор записей движений).
Повторюсь - запросы в статье открыты для экспериментов и оптимизаций, все в Ваших руках! :)
Повторюсь - запросы в статье открыты для экспериментов и оптимизаций, все в Ваших руках! :)
(57) Статья была обозначена как альтернатива статье "Фифо для любопытных".
Я из этого и исхожу.
Но Ваша постановка задачи есть частный случай и сильное упрощение постановки задачи в "ФИФО для любопытных".
Т.е. никакая НЕ альтернатива.
С другой стороны , если Вы представите текст запроса для случая , когда на входе
таблица
• Столбец «ДокументРасходнаяНакладная»;
• Столбец «Номенклатура»;
• Столбец «КоличествоСписания»;
нам будет легко сравнивать альтернативные запросы.
И будет о чем поговорить. Пока нечего сравнивать.
Я из этого и исхожу.
Но Ваша постановка задачи есть частный случай и сильное упрощение постановки задачи в "ФИФО для любопытных".
Т.е. никакая НЕ альтернатива.
С другой стороны , если Вы представите текст запроса для случая , когда на входе
таблица
• Столбец «ДокументРасходнаяНакладная»;
• Столбец «Номенклатура»;
• Столбец «КоличествоСписания»;
нам будет легко сравнивать альтернативные запросы.
И будет о чем поговорить. Пока нечего сравнивать.
Моя статья предназначена для демонстрации другого способа получения списка партий для списания вместе со всеми количествами/суммами. Демонстрация превосходств того или иного метода - тема для отдельного исследования и статьи :) Возможно я этим и займусь, но позже.
Но все, что нужно для модификации моего запроса я уже даже описал сам :)
Но все, что нужно для модификации моего запроса я уже даже описал сам :)
(59) Жаль.
1. При решении задачи полноценного ФИФО , т.е. получения движений для каждого документа расхода Вас ждут сюрпризы. И описанной Вами модификацией - лишь "добавляя только группировку по регистратору" - Вы ничего не добьетесь.
2. Остался без проверки главный подводный камень, на который налетают при использовании соединения по неравенству. При приличных объемах входных данных Ваш алгоритм - "рухнет".
См. Пример с таблицей 1 000 000 записей, которая соединяется сама с собой по неравенству.
Если бы было найдено решение , учитывающее 1 и 2 и которое принципиально отличалось бы от уже опубликованных на ИС - тогда бы мы поговорили всерьез.
1. При решении задачи полноценного ФИФО , т.е. получения движений для каждого документа расхода Вас ждут сюрпризы. И описанной Вами модификацией - лишь "добавляя только группировку по регистратору" - Вы ничего не добьетесь.
2. Остался без проверки главный подводный камень, на который налетают при использовании соединения по неравенству. При приличных объемах входных данных Ваш алгоритм - "рухнет".
См. Пример с таблицей 1 000 000 записей, которая соединяется сама с собой по неравенству.
Если бы было найдено решение , учитывающее 1 и 2 и которое принципиально отличалось бы от уже опубликованных на ИС - тогда бы мы поговорили всерьез.
(78) обязательно нужно указать в статье, что запросы эти ресурсоёмкие, у чем больше записей в начальный таблицах, тем дольше он будет выполняться - по нарастающей. Я не привык читать сложные запросы из текста, но постараюсь разобраться в них.
(81) насчет статистики не могу помочь пока. Но запрос с нарастающими итогами по взаиморасчетам за 3 года выполнялся около 30 минут. Просто логически рассуди - к каждой записи присоединяются все предыдущие и конечная таблица перед группировкой возрастает многократно. Представь 10 записей в начальной - это 1 + (1+1) + (1 + 1 + 1) + (1 + 1 + 1 + 1). Формула f(n) = (n² + n) / 2. 10 объединяемых записей выльется в 55 записей, которые нужно сгруппировать, 100 в 5050
График.
График.
Прикрепленные файлы:
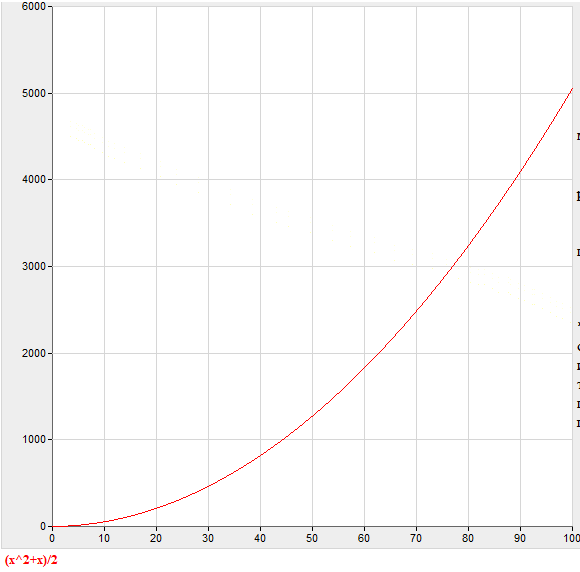
(82) anig99, то, что я привел в статьях это вычисление нарастающего итога с одновременным применением больших ограничений на размер выборки. Так что однозначно говорить о "ресурсоемкости" приведенных мною запросов нельзя, по-крайней мере нельзя без предварительных практических экспериментов.
(82) Кхы.. кхы..
Сумму членов арифметической прогресии находил когда -то маленький Гаусс на уроке:
(А1+АN)*N/2
Если в начальной таблице 100 записей, то при соединении каждой записи со всеми предыдущими получаем :
А1=1,АN=100,N=100.
(1+100)*100/2 = 5050
Итак ,При соединении каждой записи со всеми предыдущими получаем получаем в итоговой таблице 5050 записей.
Промежуточная таблица возросла в 55 раз.
(83) Игнорировать такое возрастание невозможно. Любые алгоритмы , игнорирующие это обстоятельство нельзя рассматривать всерьез.
Сумму членов арифметической прогресии находил когда -то маленький Гаусс на уроке:
(А1+АN)*N/2
Если в начальной таблице 100 записей, то при соединении каждой записи со всеми предыдущими получаем :
А1=1,АN=100,N=100.
(1+100)*100/2 = 5050
Итак ,При соединении каждой записи со всеми предыдущими получаем получаем в итоговой таблице 5050 записей.
Промежуточная таблица возросла в 55 раз.
(83) Игнорировать такое возрастание невозможно. Любые алгоритмы , игнорирующие это обстоятельство нельзя рассматривать всерьез.
(86) Я к эксперименту и призываю . Месяц назад в (7) был предлжено :
Попробуете ?
Можно убедиться в этом самостятельно : создайте таблицу tab1 с количеством записей 1 000 000 .
Запустите Ваш запрос - соединение по неравенству tab1 "сама с собой" засеките время. И всё поймете... назавтра.
Запустите Ваш запрос - соединение по неравенству tab1 "сама с собой" засеките время. И всё поймете... назавтра.
Попробуете ?
(92) alexk-is, супер! К статье прикреплена конфигурация. Там все очень "заточено" под одну задачу, но тем не менее данная конфигурация подходит для тестирования. Если у Вас получиться прогнать на ней нагрузочное тестирования и представить результаты я буду очень благодарен.
(93) Скачал. Установил. Как её подготовить к нагрузочным тестам? И где эти тесты?
Вообще-то я расчитывал на что-то вроде этого
В плане того, что мне останется только понажимать кнопочки и опубликовать результаты. А тут получается, что нужно и данные набить, и методику нагрузочного тестирования придумать?
Вообще-то я расчитывал на что-то вроде этого
В плане того, что мне останется только понажимать кнопочки и опубликовать результаты. А тут получается, что нужно и данные набить, и методику нагрузочного тестирования придумать?
(96) alexk-is, на самом деле я решил провести тестирование сам на SQL Server 2008R2: сделаю имитацию таблиц партий и документов, затем заполню необходимым количеством данных и запущу запрос. Заодно нормально просмотрю план выполнения запроса.
Насчет "алгоритм рухнет". На самом деле "сравнение по неравенству" применяется в базах повсеместно. Прежде всего при сортировке строк - ведь всем известно, что любые алгоритмы сортировки используют "сравнение по неравенству", иначе отсортировать строки невозможно. Естественно, что для эффективной сортировки необходимо чтобы на сортируемых столбцах стоял уникальный индекс. Сортировка будет работать и без него, вот только в этом случае конечно "алгоритм рухнет" - будет выполнятся ооочень долго и с огромными затратами памяти. Но все в наших руках, и установить индекс по измерению регистра мы можем. Так что все впорядке :)
(66) Разумеется , предварительно для таблицы, которая соединятся сама с собой , создается индекс по полю соединения. Лишь после получения индекса мы запускаем соединение "сама с собой" и засекаем время (таблица
имеет 1 000 000 записей).
..Дольше мне писать , чем Вам попробовать.
имеет 1 000 000 записей).
..Дольше мне писать , чем Вам попробовать.
63.
ildarovich
8063
25.08.11 18:21
Сейчас в теме
(55)
- опять ошибаетесь!
Вы решаете другую задачу.
Вы считаете известной на ткущий момент ТаблицуДолгов с колонками: Контрагент, Накладная, СуммаДолга.
Чтобы ее получить, нужно один за другим последовательно провести документы по регистру взаиморасчетов по документам расчетов.
В решении этого не требуется.
То есть оно работает при отсутствии в конфигурациях регистра взаиморасчетов по документам расчетов.
Как, кстати и не требуется перепроведения при изменении документов задним числом.
Другая задача - другие методы, как можно сравнивать?
Вы привели очевидное решение своей задачи.
Очевидное потому, что по-другому запрос и не записать, поставив задачу получить запросом списываемые партии из регистра партий.
И если бы не заблуждения относительно того, что это решение чего-то проще и компактней, то статья вполне может здесь пригодиться.
приведено прямое решение для задачи из - опять ошибаетесь!
Вы решаете другую задачу.
Вы считаете известной на ткущий момент ТаблицуДолгов с колонками: Контрагент, Накладная, СуммаДолга.
Чтобы ее получить, нужно один за другим последовательно провести документы по регистру взаиморасчетов по документам расчетов.
В решении этого не требуется.
То есть оно работает при отсутствии в конфигурациях регистра взаиморасчетов по документам расчетов.
Как, кстати и не требуется перепроведения при изменении документов задним числом.
Другая задача - другие методы, как можно сравнивать?
Вы привели очевидное решение своей задачи.
Очевидное потому, что по-другому запрос и не записать, поставив задачу получить запросом списываемые партии из регистра партий.
И если бы не заблуждения относительно того, что это решение чего-то проще и компактней, то статья вполне может здесь пригодиться.
65.
ildarovich
8063
25.08.11 18:42
Сейчас в теме
(64) Именно так! - Путаете! В в таблице долги нет колонки "Накладная".
Там для одного контрагента - одна строка: Сумма долга (текущая) и дата отсрочки.
Не знаю, насколько кому это решение известное.
Оно очевидное.
Потому что любой опытный программист напишет такое же.
Труднее написать по-другому.
Ну а очевидность для публикации здесь не препятствие.
Там для одного контрагента - одна строка: Сумма долга (текущая) и дата отсрочки.
Не знаю, насколько кому это решение известное.
Оно очевидное.
Потому что любой опытный программист напишет такое же.
Труднее написать по-другому.
Ну а очевидность для публикации здесь не препятствие.
76.
ildarovich
8063
25.08.11 23:34
Сейчас в теме
(54) (63) (65) - в этих комментариях я ошибся в части задачи задолженности :cry: : задача о просроченной задолженности одна и та же!
Тем не менее, когда документов по одному контрагенту станет достаточно много,
приведенный запрос будет работать слишком долго - зависимость от числа документов квадратичная (показано в комментарии (18)).
А ведь срок давности документов в запросе не ограничен.
А вот запрос для списания партий вполне рабочий: ведь не списанных партий обычно немного (чаще даже одна).
(71) внимания, как я уже говорил, статья достойна.
Цель моих комментариев - исправить замеченные неточности относительно "альтернативности" подхода.
То есть в итоге мои выводы таковы:
1. для просроченных долгов запрос в приведенном виде не годится. Это не альтернатива.
2. для списания партий в самописных конфигурациях, если считать, что решается другая и даже более распространенная задача, вполне подходит.
Мог бы изложить свое понимание того, почему в типовых используется предварительная выгрузка остатков в таблицу, но не буду отвлекать от темы.
Простоту также считаю большим плюсом.
Тем не менее, когда документов по одному контрагенту станет достаточно много,
приведенный запрос будет работать слишком долго - зависимость от числа документов квадратичная (показано в комментарии (18)).
А ведь срок давности документов в запросе не ограничен.
А вот запрос для списания партий вполне рабочий: ведь не списанных партий обычно немного (чаще даже одна).
(71) внимания, как я уже говорил, статья достойна.
Цель моих комментариев - исправить замеченные неточности относительно "альтернативности" подхода.
То есть в итоге мои выводы таковы:
1. для просроченных долгов запрос в приведенном виде не годится. Это не альтернатива.
2. для списания партий в самописных конфигурациях, если считать, что решается другая и даже более распространенная задача, вполне подходит.
Мог бы изложить свое понимание того, почему в типовых используется предварительная выгрузка остатков в таблицу, но не буду отвлекать от темы.
Простоту также считаю большим плюсом.
Приведенный запрос успешно посчитает "просроченные долги" при любом количестве документов. Долго ли, али нет - дело ума того, кто будет применять это на практике :)
Вопросы оптимизации умышленно вынесены за рамки моей статьи в угоду простоте изложения материала и его понятности, о чем и сказано в последнем абзаце текста статьи.
Вопросы оптимизации умышленно вынесены за рамки моей статьи в угоду простоте изложения материала и его понятности, о чем и сказано в последнем абзаце текста статьи.
В моей статья я показал другой метод получения списка партий для списания, отличный от всего, что я нашел на просторах Интернета. Он реально работает, он компактен и по своему красив. Среди всего множества людей наверняка есть и такие, кто его уже знают - я это допускаю. Кому-то он поможет, кому-то нет. Но своей цели я уже достиг - несколько человек посчитали статью стоящей и полезной.
Я полностью уверен, что при любых условиях хранения движений (остатков/оборотов), будь то регистр или справочник - этот запрос будет работать. Еще раз - доказывать кому-то что мой запрос лучше или хуже у меня цели нет. Считаете, что моя статья недостойна внимания - я буду работать с другими, которым она полезна.
Я полностью уверен, что при любых условиях хранения движений (остатков/оборотов), будь то регистр или справочник - этот запрос будет работать. Еще раз - доказывать кому-то что мой запрос лучше или хуже у меня цели нет. Считаете, что моя статья недостойна внимания - я буду работать с другими, которым она полезна.
Я плюсую за простоту кода и его дальнейшую понятность для остальных программистов в случае доработок даже без коммментариев.
Сегодня этот код успешно применен и протестирован на рабочей базе.
Оговорюсь, что вместо виртуальных таблиц Обороты использовала уже заранее сформированные временные таблицы в одном немаленьком запросе (таким образом СКЛю будет несложно выбрать оптимальный план запроса).
Так как запрос изначально был немаленьким, то вставлять в него еще 7 подзапросов считаю перегрузом. А так всего десяток строк - и наглядно и просто. Keep it simple!
P.S. У меня в соединяемых временных таблицах никогда не будет 1 000 000 записей, поэтому не боюсь, что запрос рухнет на огромном массиве данных.
Спасибо автору!
Сегодня этот код успешно применен и протестирован на рабочей базе.
Оговорюсь, что вместо виртуальных таблиц Обороты использовала уже заранее сформированные временные таблицы в одном немаленьком запросе (таким образом СКЛю будет несложно выбрать оптимальный план запроса).
Так как запрос изначально был немаленьким, то вставлять в него еще 7 подзапросов считаю перегрузом. А так всего десяток строк - и наглядно и просто. Keep it simple!
P.S. У меня в соединяемых временных таблицах никогда не будет 1 000 000 записей, поэтому не боюсь, что запрос рухнет на огромном массиве данных.
Спасибо автору!
Автор:
Подписаться
Вы можете заказать платную консультацию или разработку у автора. Будет создан приватный заказ на «Бирже заказов» для автора.
Публикация:
№ 88999
Создание 25.08.11 10:02
Обновление 25.08.11 10:02
Статистика:
Просмотры 19569
Загрузки 81
Рейтинг
11
Комментарии 107
Характеристики:
Код открыт Не указано
Рубрики Математика и алгоритмы
Кому Программист
Тип файла Архив с данными
Платформа 1С:Предприятие 8
Конфигурация Универсальные
Операционная система Не имеет значения
Страна Россия
Отрасль Не имеет значения
Налоги Не имеет значения
Вид учета Не имеет значения
Доступ к файлу Абонемент ($m)