


Итак, смоделируем сначала условие задачи.
Задача
Необходимо написать функцию, которая возвращает в строковую переменную текст вида:
Это тестовая строка 1
Это тестовая строка 2
Это тестовая строка 3
...
Это тестовая строка N
Где N - число строк.
Разобрать несколько способов получения такой переменной.
Так же сделать график скорости работы в зависимости от N и сравнить получившиеся функции по производительности.
Решение
На самом деле, несмотря на вымышленность задания подобная задача в реальной жизни, в том или ином виде встречается сплошь и рядом. Есть большой цикл в котором мы результат складываем в текстовую переменную суммой нескольких строк. Так вот, было замечено, что для большого цикла и текста, время выполнения операции сложения строк растет нелинейно и для большого количества итераций не позволительно долго.

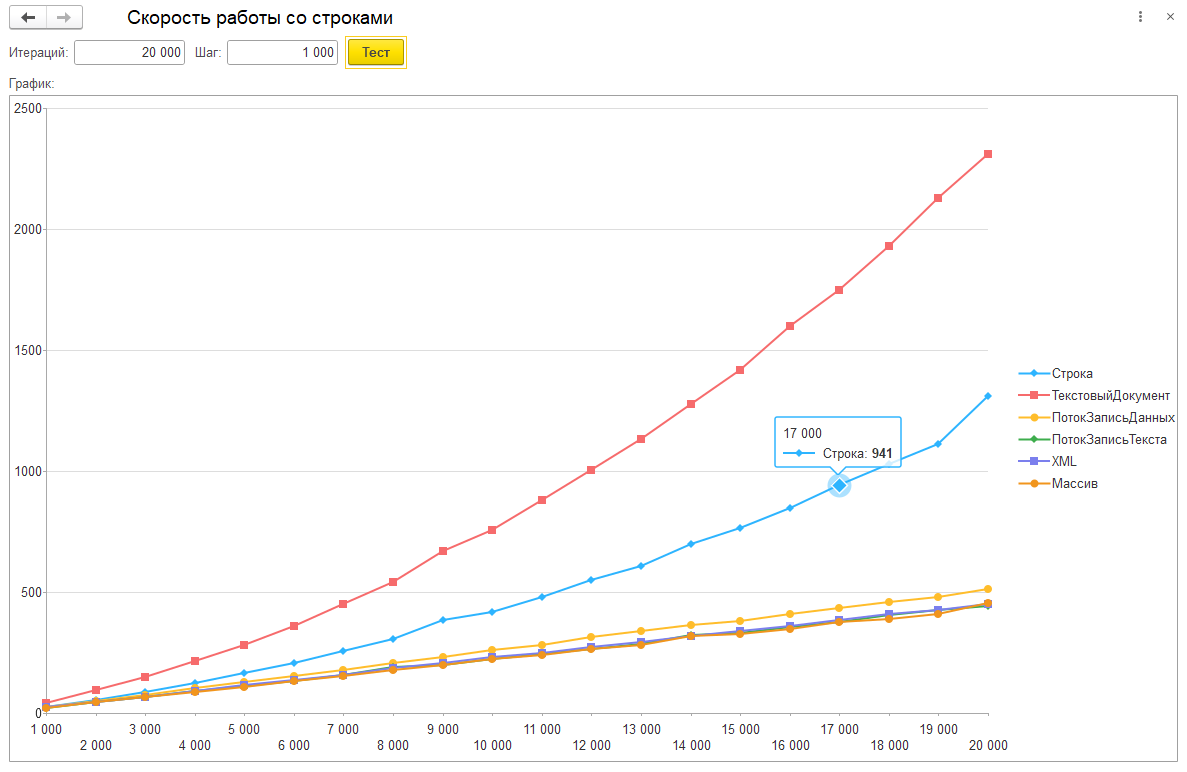
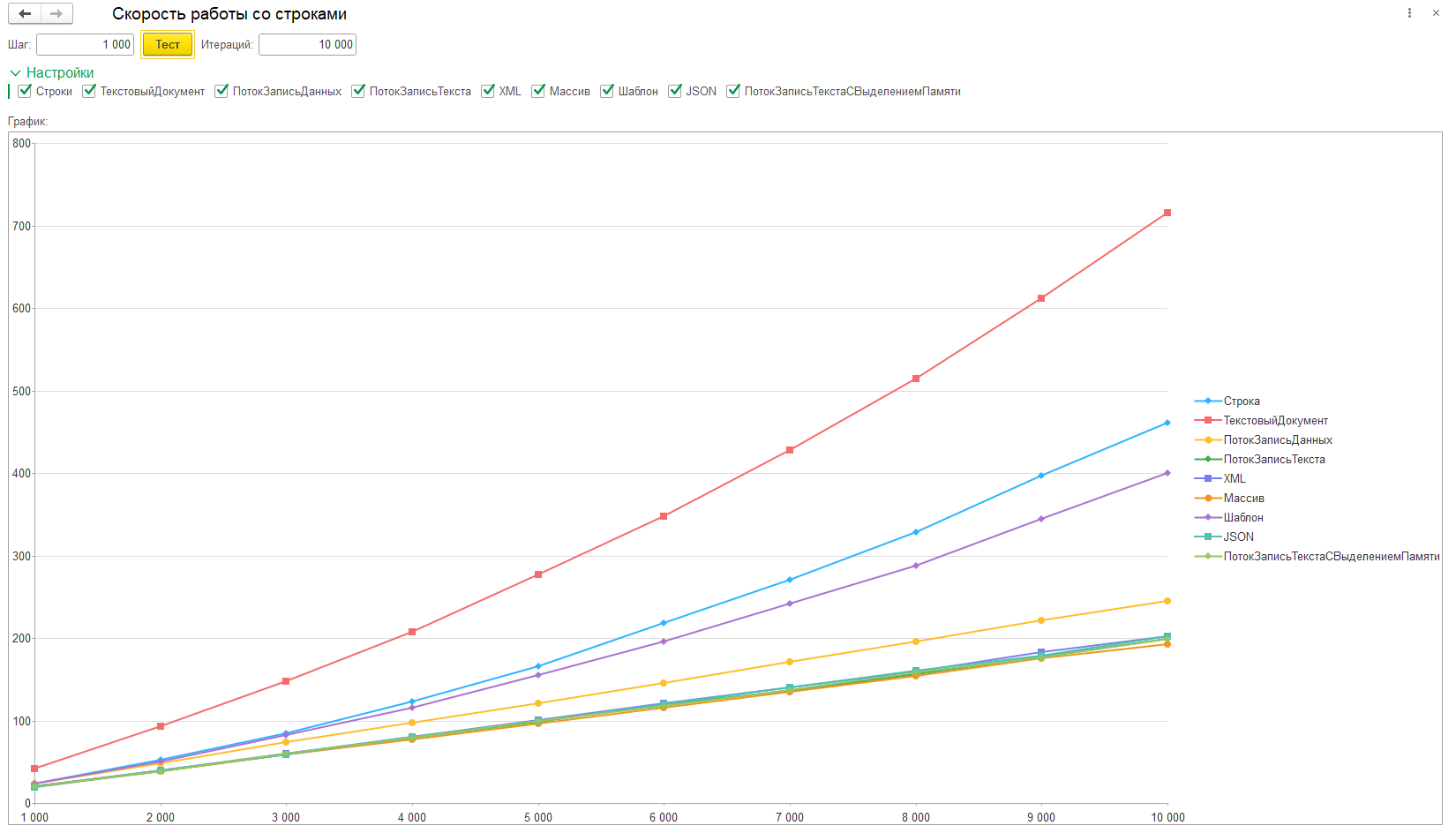
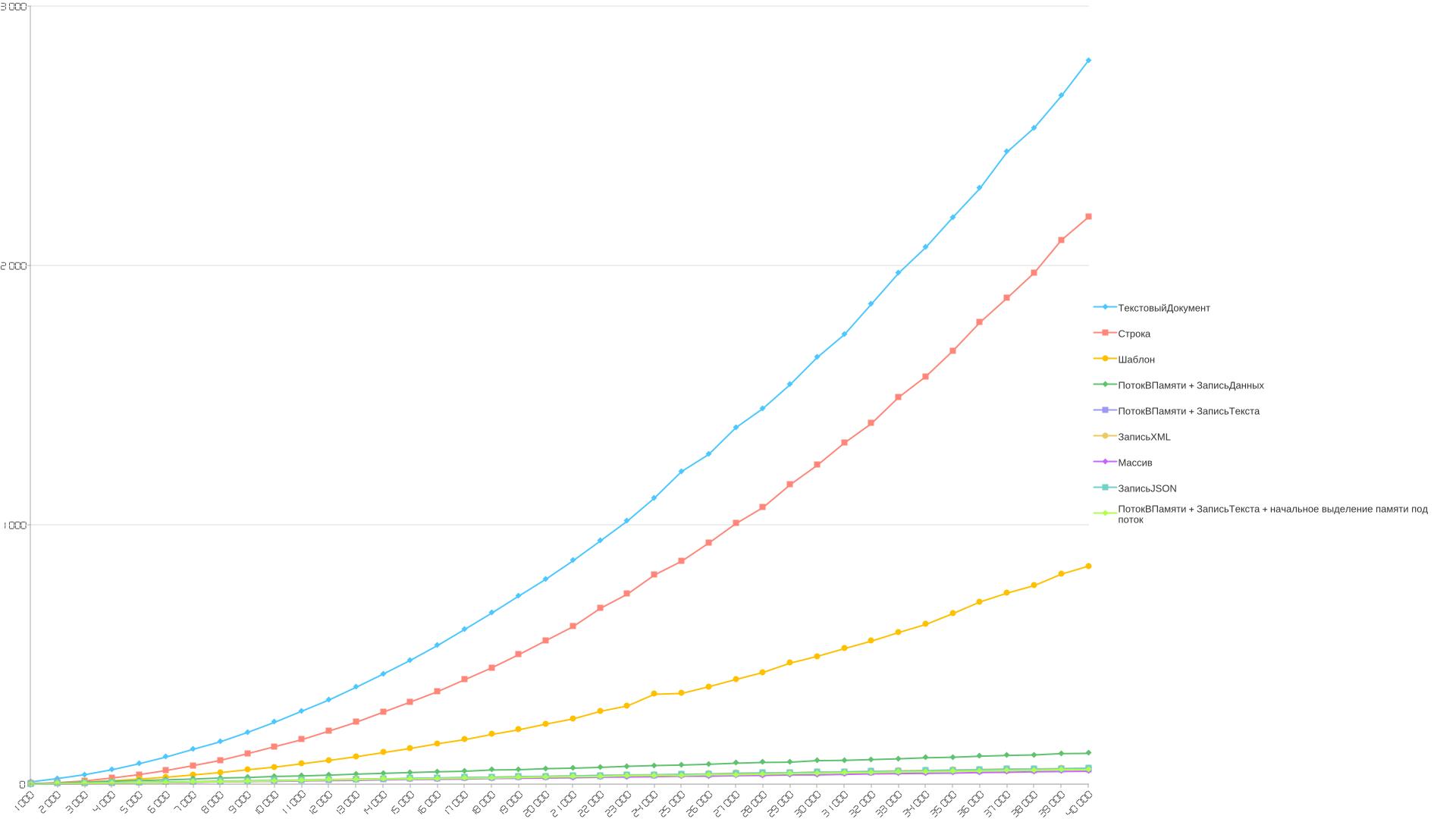
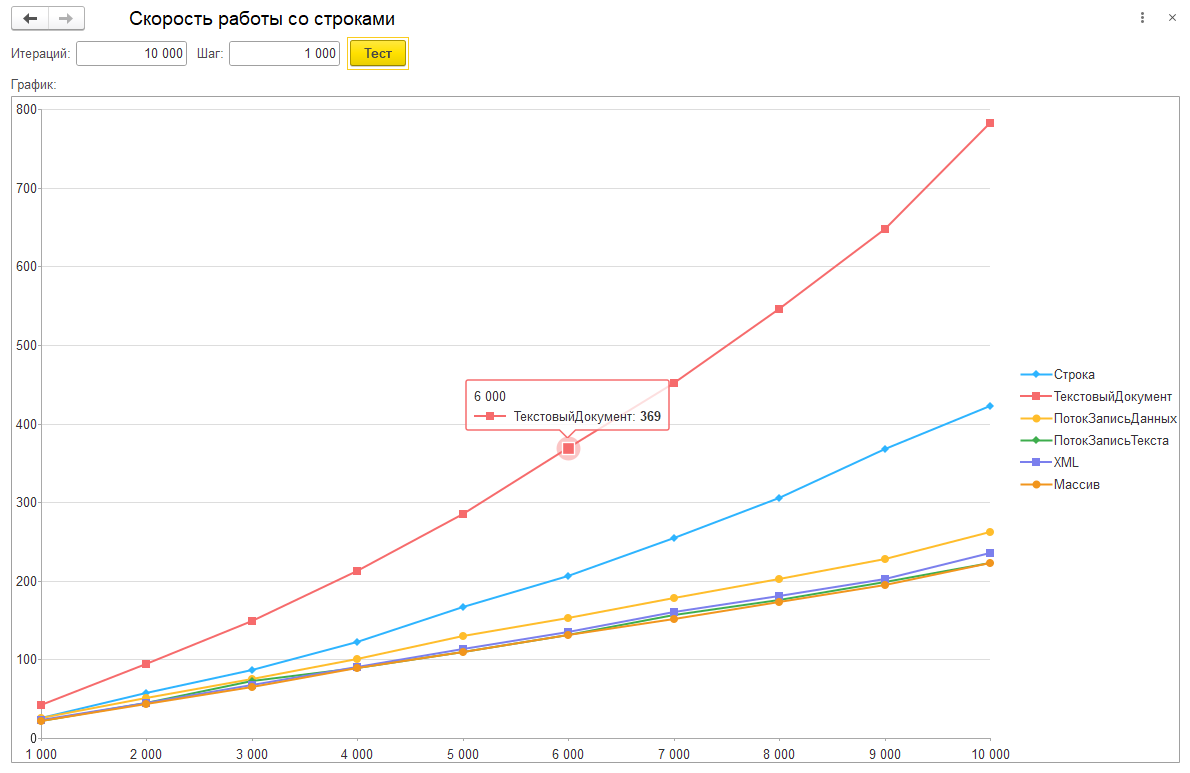
Где по оси Х у нас идет количество итераций, а по Y - время в миллисекундах.
1. ТекстовыйДокумент. Как мы видим, этот способ работает медленнее всего:
Результат = Новый ТекстовыйДокумент;
Для Индекс = 1 По КоличествоИтераций Цикл
Результат.ДобавитьСтроку("Это тестовая строка " + Строка(Индекс));
КонецЦикла;
Строка = Результат.ПолучитьТекст();
2. Строка. Затем у нас идет обычная работа со строкой:
Результат = "";
Для Индекс = 1 По КоличествоИтераций Цикл
Результат = Результат + "Это тестовая строка " + Строка(Индекс) + Символы.ПС;
КонецЦикла;
3. Шаблон. Интересный предложение по реализации от coollerinc. Отнесся к этому методу скептически изначально, т.к. работа со строками никуда не девается, но ради чистоты эксперимента, добавил тест.
Результат = "";
Шаблон = "%1 %2";
Для Индекс = 1 По КоличествоИтераций Цикл
Результат = СтрШаблон(Шаблон, Результат, "Это тестовая строка " + Строка(Индекс) + Символы.ПС);
КонецЦикла;
Как я и ожидал, результат не очень... После 10000 итераций способ становится самым медленным (на скриншоте этого не видно, но по факту это так).
4. Далее по скорости идет работа с ПотокВПамяти + ЗаписьДанных:
Результат = Новый ПотокВПамяти;
ЗаписьДанных = Новый ЗаписьДанных(Результат);
Для Индекс = 1 По КоличествоИтераций Цикл
ЗаписьДанных.ЗаписатьСтроку("Это тестовая строка " + Строка(Индекс));
КонецЦикла;
ЗаписьДанных.Закрыть();
Строка = ПолучитьСтрокуИзДвоичныхДанных(Результат.ЗакрытьИПолучитьДвоичныеДанные());
5. ПотокВПамяти + ЗаписьТекста. Как оказалось, со строками этот способ работает быстрее, чем ПотокВПамяти + ЗаписьДанных, хотя по идее, корни у них общие, в плане механизмов работы:
Результат = Новый ПотокВПамяти;
ЗаписьТекста = Новый ЗаписьТекста(Результат);
Для Индекс = 1 По КоличествоИтераций Цикл
ЗаписьТекста.ЗаписатьСтроку("Это тестовая строка " + Строка(Индекс));
КонецЦикла;
ЗаписьТекста.Закрыть();
Строка = ПолучитьСтрокуИзДвоичныхДанных(Результат.ЗакрытьИПолучитьДвоичныеДанные());
6. ЗаписьXML, тоже работает быстро. Выглядит как какая-то магия:
Результат = Новый ЗаписьXML;
Результат.УстановитьСтроку();
Для Индекс = 1 По КоличествоИтераций Цикл
Результат.ЗаписатьБезОбработки("Это тестовая строка " + Строка(Индекс) + Символы.ПС);
КонецЦикла;
Строка = Результат.Закрыть();
7. Массив. В массив можно складывать строки и в конце использовать функцию СтрСоединить:
Результат = Новый Массив;
Для Индекс = 1 По КоличествоИтераций Цикл
Результат.Добавить("Это тестовая строка " + Строка(Индекс));
КонецЦикла;
Строка = СтрСоединить(Результат, Символы.ПС);
8. ЗаписьJSON, работает быстро. Спасибо Rustig, который подсказал добавить и такой вариант для тестирования.
Результат = Новый ЗаписьJSON;
Результат.УстановитьСтроку();
Для Индекс = 1 По КоличествоИтераций Цикл
Результат.ЗаписатьБезОбработки("Это тестовая строка " + Строка(Индекс) + Символы.ПС);
КонецЦикла;
Строка = Результат.Закрыть();
Изначально было подозрение, что это будет работать быстрее чем ЗаписьXML, но это оказалось не так. Тесты показывают примерно одинаковое время работы с вариантом 6. Видимо все дело в том, что есть общие механизмы в реализации этих объектов платформы и, видимо, реализация метода ЗаписатьБезОбработки одинаковая.
9. ПотокВПамяти + ЗаписьТекста + начальное выделение памяти под поток. Думалось, что это хороший вариант для тех случаев, когда изначально известен размер данных. Спасибо Perfolenta.
Результат = Новый ПотокВПамяти(КоличествоИтераций * 16 * (СтрДлина("Это тестовая строка ") + 4));
ЗаписьТекста = Новый ЗаписьТекста(Результат);
Для Индекс = 1 По КоличествоИтераций Цикл
ЗаписьТекста.ЗаписатьСтроку("Это тестовая строка " + Строка(Индекс));
КонецЦикла;
ЗаписьТекста.Закрыть();
Строка = ПолучитьСтрокуИзДвоичныхДанных(Результат.ЗакрытьИПолучитьДвоичныеДанные());
Длину строки умножаем на 16 накинул на кодировку в UTF-8 и на количество итераций. Получаем примерный размер для потока. Именно примерный. В таки у нас эксперимент и выделенного размера должно быть достаточно. Но оказалось, что по скорости, что с выделением начального объема памяти, что без выделения, все работает примерно одинаково. В комментариях к статье есть мои размышления на эту тему в сторону Capacity.
Замечания и оговорки
При тестировании наткнулся на интересное. На рабочем компьютере медленнее всего работал ТекстовыйДокумент, а потом Строки, а в форуме, на скриншотах, уже самые медленные Строки, а потом ТекстовыйДокумент вместе с Шаблоном. Вопрос. Почему на разных машинах не одинаковая тенденция? Речь именно о тенденции графиков, а не времени выполнения. Т.е. если ТекстовыйДокумент самый медленный на одном компьютере по сравнению с другими, то по идее он должен и на другом быть самым медленным в сравнении, ведь механизм один и тот же. Но это не так. Вопрос остается открытым... Это хорошо видно в обсуждении.
Предварительные выводы
Если у вас строки не большой длины, то можно обойтись и простой суммой двух строковых переменных, вида: Строка1 + Строка2. Если строк достаточно, много то ни в коем случае не использовать работу с ТекстовымДокументом. Лучше выбрать что-то другое. Например, ПотокВПамяти + ЗаписьТекста. Это способ, который позволит работать с длинными строками как в памяти, так и из файла.
Удивило так же, что ПотокВПамяти с начальным выделением памяти не дает прибавки в скорости. Причем не только ощутимой, а вообще нет никакой прибавки.
Почему при работе со строками разными методами, такой большой разброс по времени выполнения - вопрос и, на мой взгляд, самое удивительное в этом, что конкатенация обычных строк - это не самый быстрый способ сложения строк...
Ну а какой из способов использовать - выбирать вам.
Прилагаю обработку, в которой можно поэкспериментировать введя свои значения итераций.
Тестировалось на платформе 8.3.19.1264
PS: Приготовьтесь, что ждать результата теста придется долго :)
PPS: В процессе написания обработки были использованы публикации:
Формирование строки большой длины
Варианты конкатенации строк в 1С и замеры производительности
Готовое решение
ККТ-ОНЛАЙН 54-ФЗ: Обработка для работы онлайн касс АТОЛ, ШТРИХ, VIKI PRINT и т.д. МАРКИРОВКА (Разрешит. режим) + ЭКВАЙРИНГ + БЕСПЛАТНЫЙ ДЕМО
Универсальная обработка для фискальных регистраторов! Подключайте любые ККТ, включая Веб сервер АТОЛ, без обновления 1С и работайте с несколькими кассами одновременно. Тестовый доступ — бесплатно!
Вступайте в нашу телеграмм-группу Инфостарт










{kind=link}