



{kind=link}
Задачи оптимизации (поиска наилучшего решения) не самые популярные в среде 1С-негов. Действительно, одно дело - учет выполнения каких-либо решений, и совершенно другое дело - принятие этих самых решений. В последнее время, однако, мне кажется 1С бросилась догонять конкурентов в данном вопросе. Действительно захватывающе объединить под одной крышей все, что может потребоваться современному менеджеру, догоняя в этом вопросе SAP и заменяя MS Project и другие системы планирования.
Впрочем, разговор о дальнейших путях развития 1С - это тема отдельной публикации и дискуссии, а пока я задумал цикл статей, объясняющих и демонстрирующих современные математические и алгоритмические подходы к многомерной нелинейной оптимизации, или, если хотите - механизмов поиска решений. Все статьи будут сопровождаться демо обработками с универсальными процедурами и функциями многомерной оптимизации - Ваше дело найти при желании им применение или принять на баланс полезного знания и инструментария (только тем, естественно, кто осилит данную статью до конца). Честно обещаю высшую математику излагать наиболее доступным языком и с примерами того, как эти жуткие формулы можно превратить в программно решаемые задачи:) Поехали...
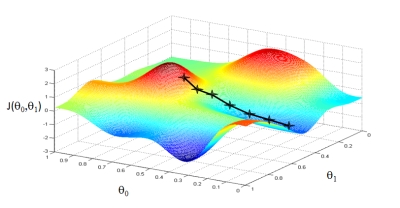
Итак, первая тема - метод градиентного спуска.
Сфера применения метода - любые задачи на нахождения массива из n переменных, обеспечивающих минимальное (максимальное) значение целевой функции. Целевая функция при этом - функция от этих самых n переменных самого произвольного вида - единственное условие, накладываемое методом на целевую функцию - ее непрерывность по крайней мере на отрезке поиска решения. Непрерывность на практике обозначает, что для любого сочетания значений переменных можно найти действительное значение целевой функции.
Давайте введем обозначения:
- Множество переменных Х, от которых зависит значение целевой функции
![]()
И сама целевая функция Z, вычисляемая самым произвольным образом из множества Х
![]()
Теперь поясним, что же такое градиент. Градиент это вектор многомерного пространства, указывающий направление наибольшего возрастания некоторой функции. Компонентами градиента являются дифференциалы всех переменных функции Z.
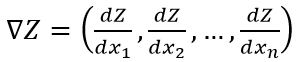
Вот отсюда и вытекает главное ограничение применимости метода градиентного спуска - дифференцируемость (непрерывность) функции на всем протяжении области поиска решения. Если данное условие соблюдается, то поиск оптимального решения вопрос чисто технический.
Классический метод градиентного спуска реализовывается для минимизации целевой функции через антиградиент (то есть вектор противоположный градиенту), который получается из градиента самым простым образом - умножением на -1 всех компонентов градиента. Или в обозначениях:
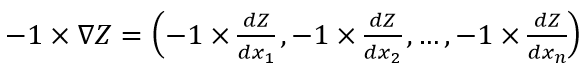
Теперь самый главный вопрос: а как нам найти эти самые dZ и dX1, dX2 и т.д.? Очень просто! dXn - это бесконечно малое приращение переменной Xn, скажем 0,0001 от ее текущей величины. Или 0,0000000001 - главное, чтобы оно (приращение) было действительно малым:)
А как же вычисляется dZ? Тоже элементарно! Вычисляем Z для набора переменных X , а затем изменяем в этом наборе переменную Xn на величину dXn. Снова вычисляем значение целевой функции Z для этого слегка модифицированного набора (Zn) и находим разницу - это и будет dZ = Zn - Z. Ну а теперь коль нам известны dXn и dZ найти dZ/dXn проще пареной репы.
Найдя последовательно все компоненты градиента и антиградиента мы получаем направление изменения переменных, которое наискорейшим образом позволит достичь минимума функции.
На следующем (k+1) этапе, нужно вычислить новые значения массива переменных X. Очевидно, что для приближения к минимуму целевой функции Z мы должны корректировать значения X предыдущего (k-го) этапа в направлении антиградиента по такой формуле:
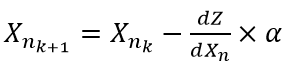
Остается разобраться с этой самой альфой в формуле. Зачем она нужна и откуда она берется.
α - это коэффициент на который домножается антиградиент для обеспечения достижения возможного минимума функции в заданном направлении. Сам по себе градиент или антиградиент не являются мерой сдвига переменной, а указывают лишь направление движения. Геометрический смысл градиента - это тангенс угла наклона касательной к функции Z в точке Xn (отношение противолежащего катета dZ к прилежащему dXn), но двигаясь по касательной мы неизбежно отклонимся от линии функции до достижения ее минимума. Смысл касательной в том, что она дает отображение в виде прямой произвольной криволинейной функции в очень узком промежутке - окрестностях точки Xn.
Поиск значения параметра α выполняется одним из методов одномерной оптимизации. Значения переменных {X} нам известны, известны и их градиенты - остается минимизировать целевую функцию в окрестностях текущего решения по одному единственному параметру: α.
Останавливаться на одномерной оптимизации я здесь на буду - методы достаточно просты для понимания и реализации, скажу лишь, что я использовал в своем решении метод "золотого сечения". ОДЗ для α находится в промежутке от 0 до 1.
Итак, резюмируя написанное, сформулируем последовательность шагов для поиска решения методом градиентного спуска:
- Формируем начальное опорное решение, присваивая искомым переменным случайные значения из ОДЗ.
- Находим градиенты и антиградиенты для каждой переменной как отношения прироста целевой функции при относительно малом увеличении значения переменной к значению приращения этой самой переменной.
- Находим коэффициент α, на который нужно умножать антиградиенты перед добавлением к исходным значениям опорного решения методом одномерной оптимизации. Критерий оптимизации - наименьшее из возможных значение целевой функции для скорректированных таким образом значений {X}.
- Пересчитываем {X} в соответствии с наденными значениями антиградиентов и коэффициента сдвига α.
- Проверяем достигнута ли необходимая точность (ε) вычисления минимума целевой функции:
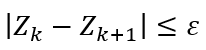
6. Если условие выполнено и от этапа к этапу значение целевой функции изменилось ниже установленного нами же критерия это значит, что необходимая точность достигнута и текущее множество {X} является решением задачи, иначе - переход к шагу 2.
Теперь давайте перейдем к практической задаче, которая решена в обработке.
По условию задачи необходимо установить цену на некий товар таким образом, чтобы прибыль от его реализации в планируемом периоде была максимальной. При этом нужно учитывать, что объем реализации зависит от установленной нами цены, а закупочная цена товара (влияющая на валовую прибыль) также зависит от объема закупки товара: поставщик готов предоставлять скидки тем больше, чем больше будет объем нашей закупки. То есть нам нужно одновременно с установлением цены понимать, сколько товара мы сможем реализовать и по какой цене и, следовательно, сколько товара нам нужно для этого закупить, и тогда мы будем знать, какова будет закупочная цена. В общем, такая немного рекурсивная логика поиска решения:)
Самое главное, что мы имеем - это непрерывность переменных (цены и объема закупки / реализации) и целевой функции (прибыль есть всегда и может принимать любое значение, даже если она с минусом, то называется убыток), а значит, метод градиентного спуска - самое оно.
Для решения задачи данный метод применяется дважды: на первом этапе мы находим параметры уравнения спроса на продукцию по данным продаж предыдущих периодов. То есть, предполагая некий вид зависимости спроса от цены, вычисляем значения параметров этой зависимости, минимизируя сумму квадратов отклонений между расчетными и фактическими данными о продажах. На втором этапе, пользуясь найденными параметрами зависимости между объемом продаж и ценой реализации, мы оптимизируем прибыль и тоже методом градиентного спуска, хотя бы применяемым всего для одной переменной. Так как метод градиентного спуска минимизирует целевую функцию, а прибыль как ничто другое нуждается в максимизации, мы используем не твиальную целевую функцию с названием "МинусПрибыль", которая всего-то и делает, что вычисляет прибыль по полученному значению цены, а перед возвратом умножает ее на -1:) И ведь работает! Теперь чем меньше становится "МинусПрибыль", тем больше на самом деле самая что ни на есть реальная прибыль от продаж.
Пример решения в обработке, как и универсальная функция поиска решения методом градиентного спуска. Суть универсальности в том, что переменные {X} передаются в нее в виде массива, а целевая функция передается как параметр строкой. Целевую же функцию, которая принимает массив переменных и возвращает значение, пишите сами какого угодно вида - главное, чтобы она возвращала число. И такое число, что чем меньше оно будет, тем ближе поданный массив аргументов к оптимальному решению.
Почему не привел здесь готовую процедуру, а выкладываю обработку? Во-первых, процедура и без того длинновата, а во-вторых, без целевых функций она не работает, так что нужно затаскивать все, да и еще во взаимосвязи. Я надеюсь, что изложенной в статье теории вполне достаточно для того, чтобы Вы смогли реализовать свое решение, возможно, даже лучшим, чем у меня, образом. Ну если уж совсем не будет получаться - качайте готовую обработку и пользуйтесь:)
Вот, собственно, и все. Вопросы, пожелания и замечания жду в комментах. Спасибо за внимание.
Вступайте в нашу телеграмм-группу Инфостарт