













Конфигурация "Полигон" включает :
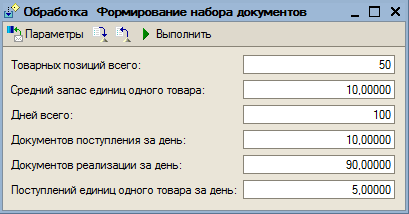
- обработку для автоматического формирования тестового массива документов поступления и реализации по заданным параметрам на основе модели теории массового обслуживания;
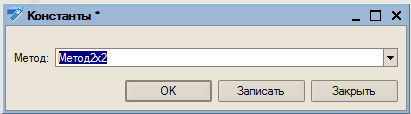
- окно настройки конфигурации (выбора испытываемого метода);
- обработку для автоматического изменения документов при тестировании быстродействия метода;
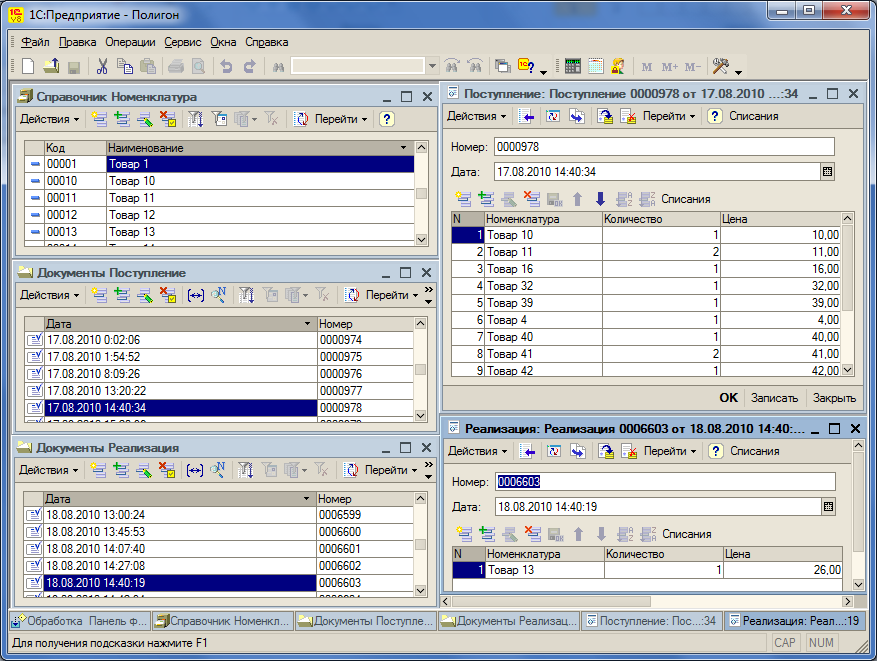
- справочник товаров;
- документы поступления и реализации с одной табличной частью, содержащей колонки номенклатура, количество, цена;
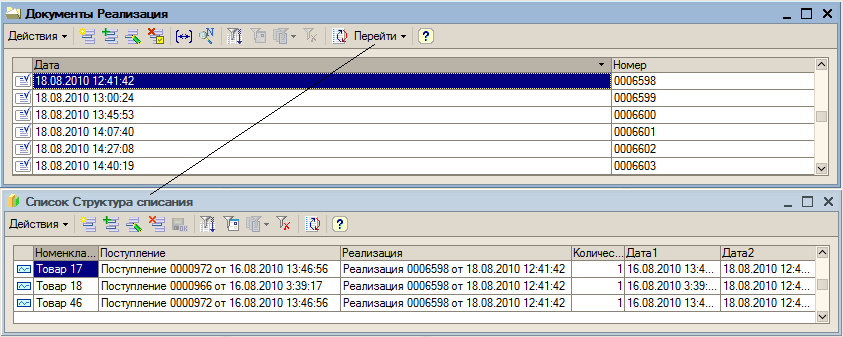
- основную структуру данных в виде непериодического независимого регистра сведений для хранения структуры списаний, имеющего измерения номенклатура, поступление, реализация, ресурс количество и два служебных реквизита;
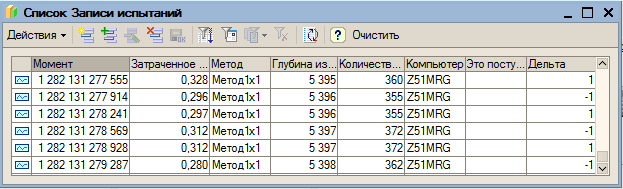
- вспомогательный регистр сведений для хранения результатов тестирования времени записи измененных документов;
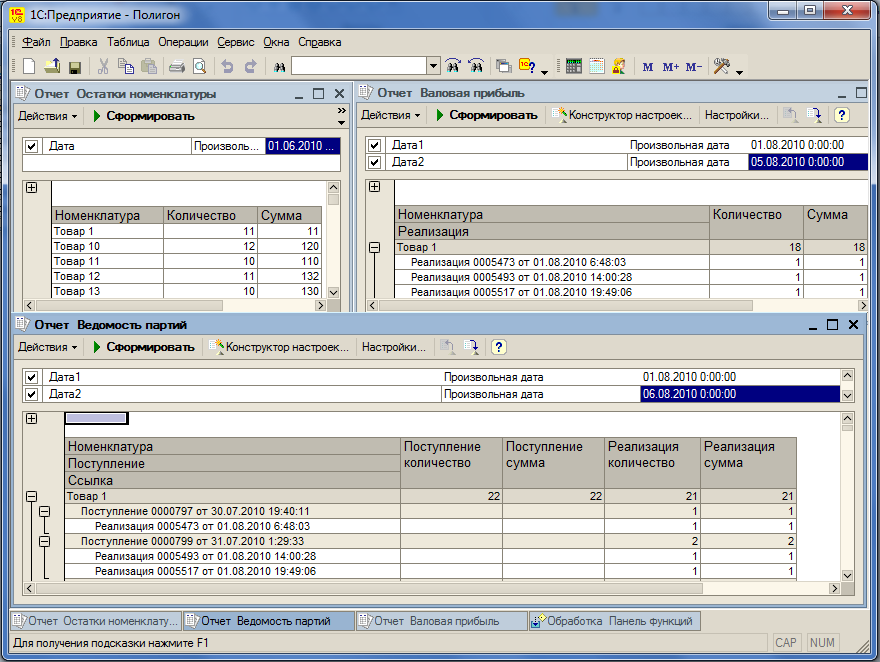
- отчет на СКД по количественным и суммовым остаткам партий товаров;
- отчет на СКД по количественному и суммовому движению партий товаров;
- отчет на СКД по прибыли;
- диаграмму на СКД для результатов тестирования метода;
- общие модули, начинающиеся со слова «метод», реализующие различные алгоритмы корректировки списания партий.
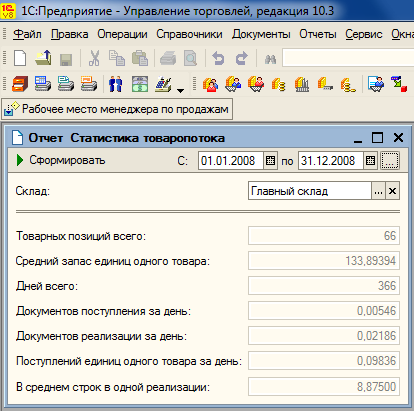
В виде отдельного файла прилагается отчет для конфигурации УТ, позволяющий получить параметры синтетического теста из реальной информационной базы для выбранного склада (число товаров, приходов, расходов, средний запас). Значения полученных параметров передаются в конфигурацию «Полигон» через буфер обмена Windows.
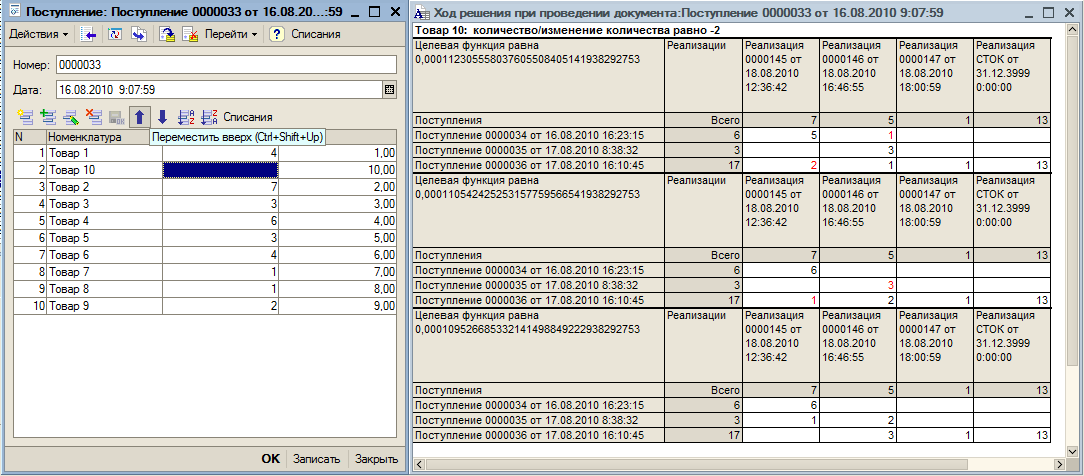
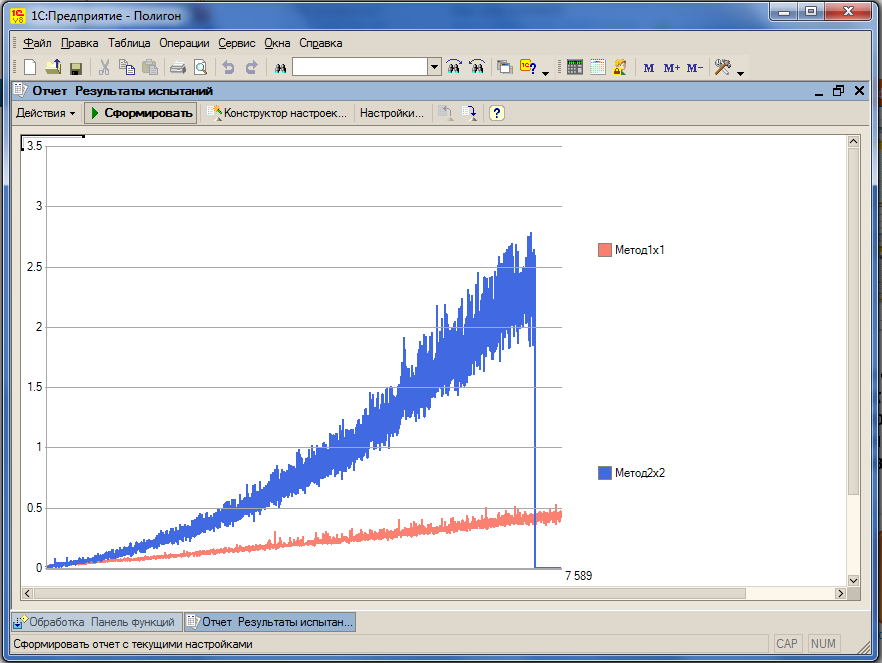
Для работы с конфигурацией рекомендуется сначала соответствующей обработкой сформировать некоторый массив документов, затем выбрать в настройках «Метод22Наглядно» и попробовать изменить одну позицию в любом документе. При записи этого документа программа покажет ход решения в виде последовательности таблиц с рассчитанными значениями целевой функции. Время обработки при этом может быть весьма существенным. Оно уходит на подготовку таблиц для комментариев решения. Далее рекомендуется выбрать в настройках «Метод2х2» и попробовать менять документы (количество товара в строках документов поступления или реализации), оценивая время отработки изменений. Рекомендуется сначала увеличивать поступление, а затем уже его уменьшать, либо уменьшать количество в реализации, а затем его увеличивать, так как в другом случае велика вероятность отказа в записи из-за контроля остатков при последующих списаниях. При отключенном комментировании результаты измерений времени работы метода будут записываться. Далее можно запустить автоматическую процедуру для изменения документов в цикле. Затем можно посмотреть диаграмму, показывающую среднее время, затраченное алгоритмом на изменение количества в одной позиции документа в зависимости от глубины изменений или длины цепочки документов по данной номенклатуре, следующих за изменяемым.
Внимание! При запуске обработки формирования массива документов регистр результатов испытаний очищается!
В двух словах об основных идеях…
Для баланса введена особая расходная накладная с номером «СТОК», которая 31.12.3999 списывает все остатки товара.
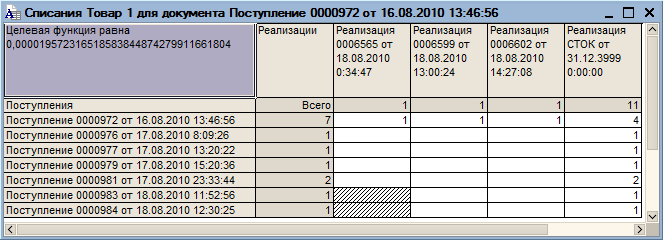
Корректировка структуры списания производится перед записью документов. Для этого:
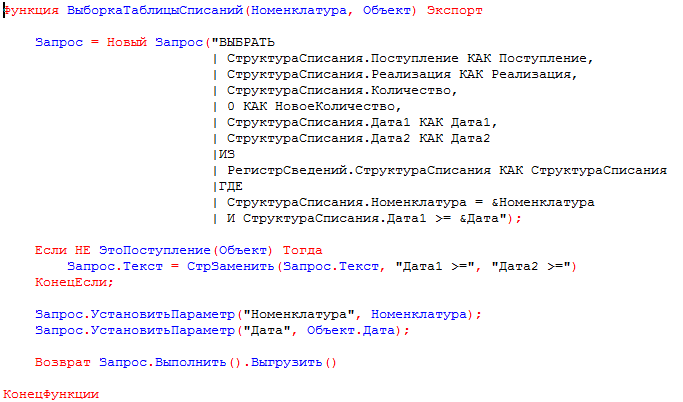
- Запросом вычисляется разница (дельта) количества товара в табличной части и структуре списаний.
- Для каждой номенклатуры с ненулевой дельтой в таблицу значений «ТаблицаСписаний» (или в дерево значений «ДеревоСписаний») запросом выбираются все списания, произведенные позже изменяемого документа.
- В таблицу (дерево) списаний вносятся изменения в зависимости от вида документа и знака дельты для соблюдения ограничений в смысле [1]. Например, при увеличении прихода, просто увеличивается списание расходом «СТОК».
- Таблица (дерево) списаний «оптимизируется» в смысле [1]. То есть меняется для достижения минимума целевой функции при соблюдении ограничений [1].
- Изменившиеся строки таблицы (дерева) списаний (в колонке «база» хранится начальное количество) записываются в набор данных регистра, обнуленные строки удаляются.
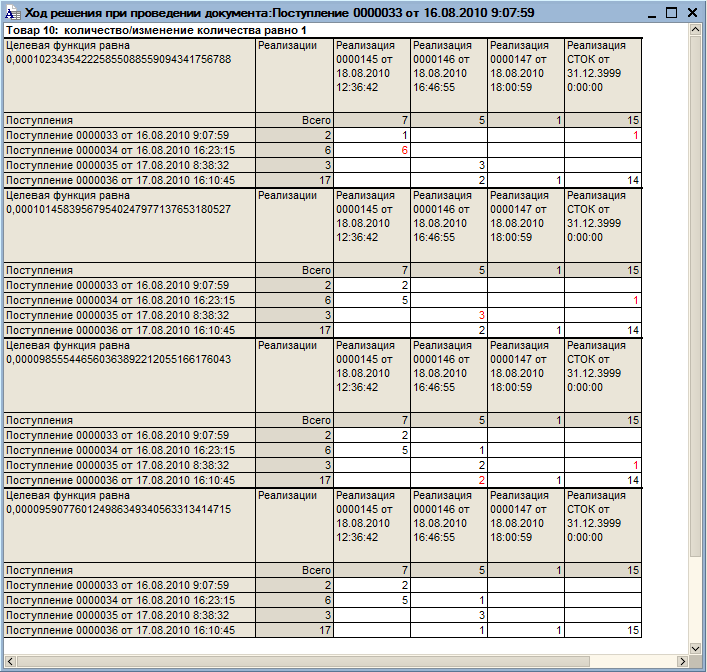
«Оптимизация» таблицы (дерева) списаний заключается в следующем:
- Ищутся пары строк - списаний (П1, Р2) и (П2, Р1), для которых выполняется условие П1 раньше П2, а Р1 раньше Р2. Наличие таких пар свидетельствует о «дефекте» в структуре списания и возможности уменьшения ЦФ. При отсутствии таких пар алгоритм заканчивается, найдя оптимум.
- Минимальное количество из найденных «перекрещивающихся» списаний забирается и добавляется к списаниям, составленных парами (П1, Р1) и (П2, Р2) (два списания меняются на два, поэтому метод назван «2х2»). Это позволяет не нарушить ограничения.
- Повторяется шаг 1.
Поиск пар строк ведется как поиск пересекающихся отрезков-списаний. Отрезки соединяют ось времени поступлений с параллельной осью времени реализаций, причем начало каждого отрезка-списания соответствует моменту поступления, а конец – моменту реализации. Для экономии времени поиска «дефекта» отрезки группируются в узлах дерева значений по поступлениям, а внутри одного узла – сортируются по времени реализации. Далее проверяются только пары из смежных поступлений.
Главной отличительной особенностью технической стороны предлагаемого решения является выбор независимого непериодического регистра сведений для хранения информации о списании партий в информационной базе. То есть в конфигурации для работы с остатками не используются регистры накопления. Регистр сведений СписаниеПартий имеет измерения: номенклатура, документ поступления, документ реализации; ресурс количество и два реквизита: дата поступления и дата списания. На основе информации из этого регистра по номенклатуре и документу поступления легко находятся документы реализации данной партии и решаются остальные задачи партионного учета.
Формирование тестового массива документов производится на основе представления товаропотока как совокупности случайных потоков поступлений и реализаций одной единицы товара. То есть товар поступает через случайные интервалы, затем также случайное время лежит на складе. Интенсивности потоков поступления и обслуживания определяются моделью СМО (системы массового обслуживание) из заданных параметров. Приходы разделяются случайными интервалами и объединяют товары, поступившие раньше следующего прихода. Аналогично расходы разделяются случайными интервалами и объединяют товары, поступившие позже предыдущего расхода. Все случайные интервалы подчиняются экспоненциальному закону распределения, то есть потоки являются пуассоновскими.
В целом после проверки предлагаемого метода с помощью данной тестовой конфигурации, можно сделать вывод, что метод работоспособен. Он решает возложенные на него задачи за приемлемое время. Например, на запись измененного в одной позиции документа трехмесячной давности уходит примерно две секунды при 7 500 всех последующих документов и 500 документов по данной номенклатуре. Очевидно, именно последний параметр определяет затраты времени на корректировку.
Анализ возможностей дальнейшего ускорения предлагаемого метода показал, что ускорение возможно. При этом может потребоваться достаточно далеко отойти от идеи,
изложенной в работе [1]. Поэтому данную публикацию следует рассматривать как пояснение идеи из работы [1] в виде программного кода и доказательство работоспособности подхода и только как промежуточный результат при поиске еще более эффективных методов.
Например, в той же конфигурации запрограммирован более очевидный метод «1х1», который на длинных цепочках документов в данный момент работает примерно в четыре раза быстрее метода «2х2». С точки зрения алгоритмов решения транспортной задачи этот метод является способом получения опорного решения методом «северо-западного угла». Найден и еще более быстрый алгоритм, о котором можно будет рассказать отдельно.
Возвращаясь к заголовку статьи "жизнь без последовательностей"...
После практического опробования одного из подходов к решению данной проблемы, можно еще раз, но более точно высказать следующую мысль: за счет некоторых дополнительных расходов при записи документов можно отказаться от механизма последовательностей платформы 1С:Предприятие. Само понятие последовательности документов остается. Оно используется при получении правильной структуры списания. Просто мы восстанавливаем последовательность списания сразу при изменении документа, не откладывая эти действия «на потом». За что и платим некоторым дополнительным временем записи документа. Совершенствуя алгоритмы корректировки списания партий, можно сделать это время достаточно малым, а в среднем - ничтожным. За это мы получаем постоянный контроль остатков при неоперативном проведении и актуальное состояние списания партий, снимаем необходимость перепроведений.
Можно спорить: насколько это нужно? Есть документы и за и против. Они известны. Видимо, отталкиваться необходимо от требований конкретной задачи.
Кстати, интересный дополнительный аргумент для сторонников перманентного пор ядка в учете партий товаров: при таком подходе можно отказаться от механизма резервирования, заменив его проведением накладной в будущем - контроль остатков не даст нам продать "зарезервированный" таким образом товар!
Предупреждая возможные замечания к реализации методов, необходимо добавить, что:
1. Использование регистра сведений вместо регистра накопления для хранения информации о списании партий применено осознанно, с полным пониманием того, что при этом увеличится время получения отчетов по суммовым оборотам партий. Ставилась задача посмотреть: каким в принципе может быть минимальное время корректировки, чтобы затем утяжелять метод дополнительными механизмами типа итогов или агрегатов.
2. В отчетах, выводящих суммовую оценку партий, производится обращение к цене прихода из табличной части документа поступления, что не согласуется с канонами 1С. В практических задачах так лучше не делать, так как приход может делаться документами различного вида.
3. Рассмотрение ограничено только методом «ФИФО».
4. Вместо момента времени всюду используется просто время документов. Учет этой детали нетруден, но усложняет понимание логики алгоритмов и отчетов.
5. В практических задачах логику корректировки структуры списания лучше перенести в процедуру проведения документа, что упростит управление блокировками.
6. Модель СМО, выбранная для генерации тестового набора документов, не позволяет по отдельности регулировать число товаров и среднее число строк в документах. Поэтому для экспериментов не следует брать реальное число товаров в базе – в документах будет слишком много строк.
7. Замеры времени указаны применительно к файловому варианту платформы 8.1, установленной на ноутбуке PCG-6122V.
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}