О чем доклад

Доклад состоит из двух частей. В первой части расскажу про некоторые интересные задачи, которые пришлось решать нашим командам. Там будет немного наших особенностей, которые, я так понимаю, не у всех есть. И в конце я расскажу, как мы переводили нашу систему на новый релиз платформы. Это тоже, я считаю, достаточно уникальный опыт, потому что многие это делают и все по-разному.
Немного о себе

Я работаю в мире 1С давно – с 1999 года. В основном занимаюсь интеграцией. На текущем месте работы в компании «БКС-Технологии» занимаюсь развитием команд, обучением, передачей опыта. Возглавляю свою небольшую команду, которая занимается интеграцией.
Почему я решил приехать на конференцию Инфостарт? Я очень люблю смотреть конференции. Там находишь очень много знаний, много пищи для размышлений. Иногда этими знаниями нужно делиться. Я считаю, что это хорошая практика. И вообще, я стараюсь вместе со своей командой сделать жизнь прекрасной.
О компании

Что представляет собой наша компания:
-
Мы представляем брокерский бизнес. У нас большая финансовая группа, мы являемся лидером в России на российской бирже. Кроме брокерского бизнеса, в группу компаний входят еще и компании банковского бизнеса, различные фонды, управляющие компании и так далее.
-
Также в структуру компании входит компания «БКС-Технологии», в которой работают ИТ-специалисты. Они занимаются тем, что поддерживают бизнес. Задач у нас очень много, и нам с ними зачастую даже тяжело справляться. Потому что у нас большая компания, которая быстро растет. Мы за последние 2 года, грубо говоря, выросли в 4 раза, и у нас от этого роста очень большой драйв
-
Бизнес от нас хочет быструю и непрерывную поставку ценностей. Из этого рождается очень много требований, в частности, к инфраструктуре, которая должна работать 24/7, 365 дней в году. Непрерывность поставки ценностей – это ограничения на процессы компании. Они у нас тоже достаточно сложные, большие. У нас Large Agile и т.д. – я дальше об этом упомяну.
-
Но при всем этом, наши программисты – это простые люди, ИТ-шники. В нашей компании работает несколько сотен ИТ-специалистов, из них специалистов 1С – больше 80 человек. Самое главное требование, которое к ним предъявляется, и мы об этом всегда говорим на собеседованиях, они должны знать, что делают и как это работает. Больше от них ничего не надо.
В каких условиях мы работаем
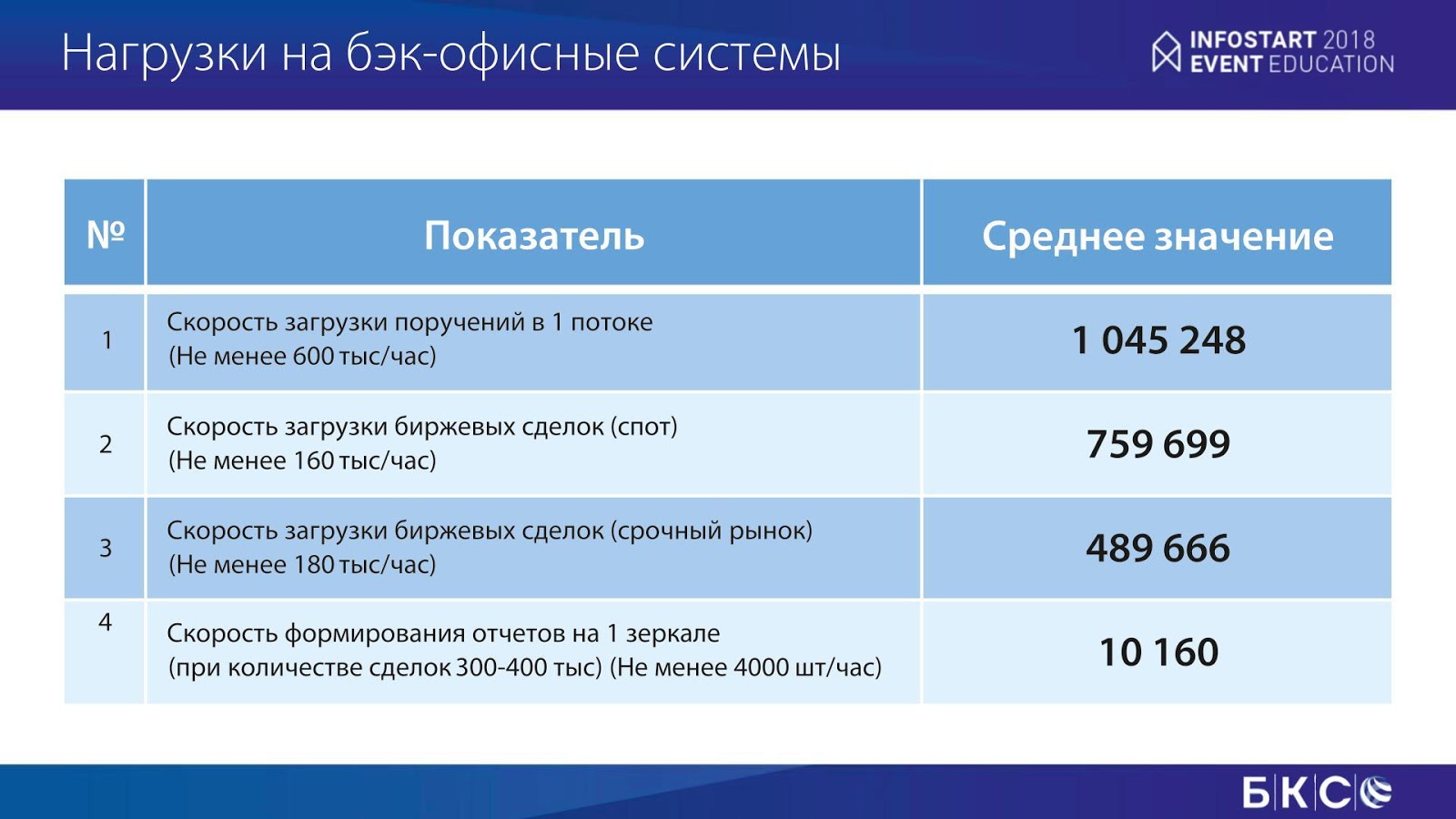
Данный слайд – это пример наших нагрузок в соответствии со SLA. Здесь показано количество сделок, которые мы должны загружать за час, чтобы справиться с существующим потоком нагрузки. Это средние значения, не пиковые. У нас были такие случаи, например, в декабре 14-го года, когда все рынки упали, и мы молились на нашу инфраструктуру, чтобы у нас все было хорошо.
Кроме большой обработки данных мы еще формируем десятки тысяч отчётов в час. Это сложная брокерская отчетность, мы должны каждый день поставлять ее клиентам, и я покажу, как это работает.
Примеры наших задач

На слайде показаны примеры наших задач. Тут есть простые задачи, которые встречаются достаточно часто. И есть, я считаю, уникальные.
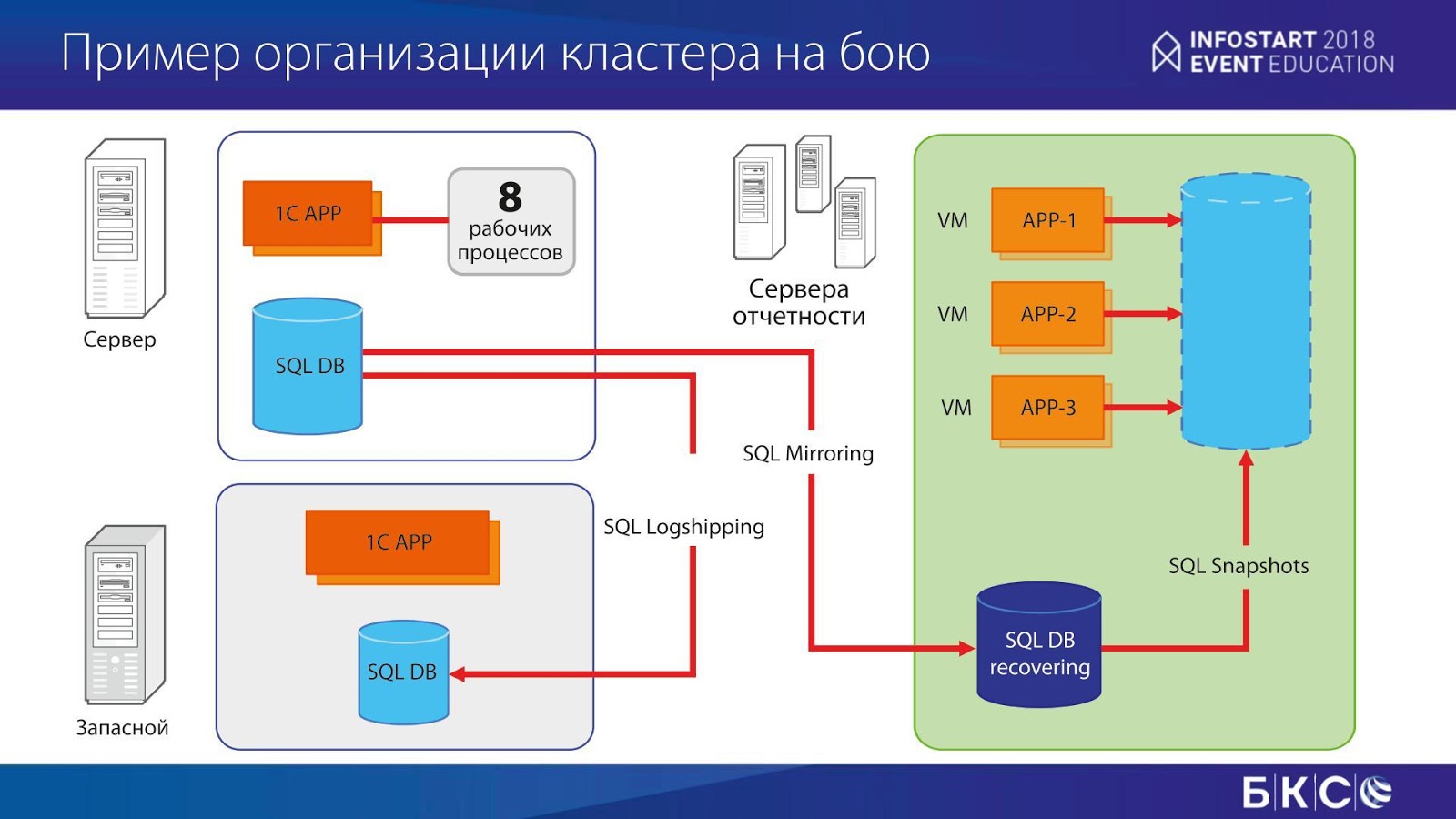
Итак, пример организации нашего кластера.
Структура достаточно простая. У нас есть два сервера – основной и запасной. На запасной сервер мы мигрируем лог транзакций с помощью технологии SQL Log Shipping. Это стандартный механизм. SQL Server Agent в течение нескольких минут перегоняет лог транзакций на запасной сервер, там фиксируется копия лога транзакций. Так получается копия базы.
На основном сервере у нас, если это интересно, 512 гигабайт памяти, 20 ядер, там крутится 8 рабочих процессов. Основная особенность – у нас мало пользователей, их чуть больше ста. Но при этом крутится около 50 фоновых заданий, и все нагрузки падают на них.
Кроме этого, есть сервер отчетности. Собственно, те самые 10 тысяч отчётов в час, которые мы должны отдавать, крутятся на этом сервере. Этот сервер примерно в два раза больше – там около терабайта оперативной памяти. При этом сейчас используется немного другая технология – SQL Mirroring. Раньше мы для сервера отчетности также использовали технологию SQL Log Shipping, также лог транзакций мигрировал, было много всяких разных серверов – с хорошим и не очень хорошим железом, и с этих серверов мы делали отчеты. Но с ростом все это поддерживать стало тяжело, поэтому мы перешли на другую технологию – SQL Mirroring. Эта технология очень похожа на предыдущую, только перегоняются зафиксированные транзакции, причем самим движком SQL. При этом SQL база данных, в которую все мигрируется, постоянно находится в режиме восстановления: из неё по-хорошему можно делать только снэпшоты (SnapShot). На эти снэпшоты у нас цепляются три настроенные виртуалки с АРР-никами, и с них уже делается отчетность.
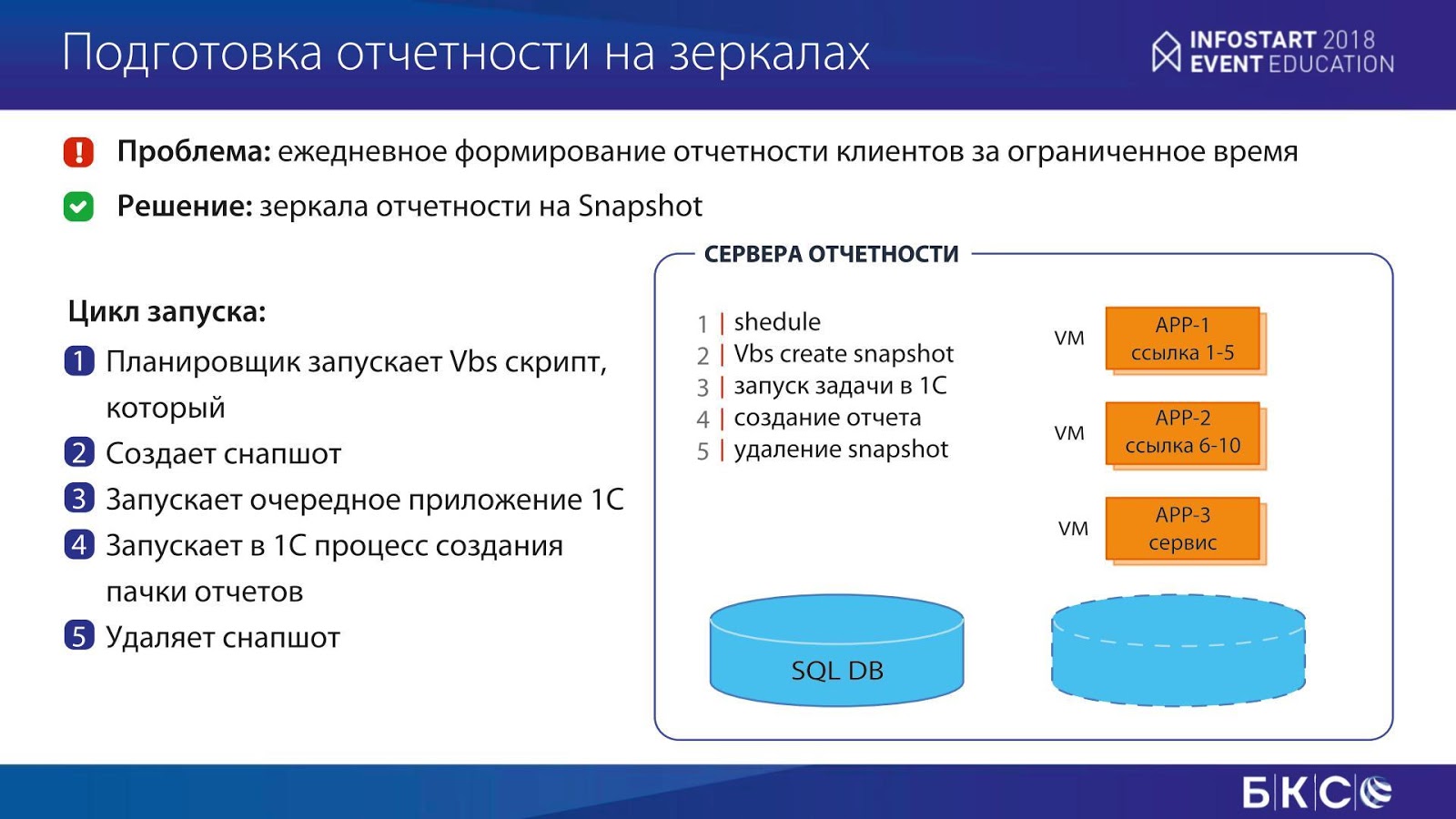
Как она делается? Достаточно простой алгоритм: планировщик по расписанию запускает скрипт, который создает снэпшот, запускает приложение 1С, в приложении 1С запускается пачка отчетов на выполнение, после чего снэпшот удаляется, и процесс повторяется заново.
Отчеты запускаются не по одному, а пачками. Причем, третий APP-ник у нас используется как сервисный, например, для рассылки и прочего. А два других APP-ника занимаются непосредственно формированием отчетов (каждый отчет привязан к определенному APP-нику). Это позволяет справляться с нагрузками по созданию отчетности.

Еще одна стандартная задача – как мы грузим наши сделки. У нас загружается 2 миллиона сделок.
Больше года назад, когда онлайн был относительный, это происходило ночью и занимало пару часов. При этом стандартные механизмы 1С не позволяют загрузить просто так. А бизнес, как всегда, говорит: «Ребята, вы должны». Что делать?
-
Обычно в Highload первый метод – это все параллелить, чтобы решить задачу. Мы берем и распараллеливаем 20 потоков, и, естественно, скорость должна увеличиться в 20 раз.
-
Но нам этого недостаточно. Нам нужно сделать еще некие действия, чтобы мы укладывались в это время. Какие это действия? Мы принудительно генерируем для сделок ГУИДы. Потому что если создавать для 2 миллионов сделок ГУИД-ы стандартно средствами 1С, то затраты уже получаются значительными.
-
Потом начинаем поэтапно проводить документ для снижения вероятности блокировок. Туда входят:
-
запись без проведения;
-
формирование отдельно движений;
-
запись движений;
-
установка флага проведения в транзакции.
-
Отлично, мы все распараллелили, уменьшили блокировки. Но по факту это еще не все. Потому что этого иногда тоже не хватает. И приходится лезть на уровень базы данных в таблице, играться с эскалациями и так далее. Иногда, скажем честно, это не соответствует лицензионному соглашению. Но это уже больше вопрос к фирме 1С и ориентации на крупные компании.
В общем, после всех этих настроек мы начинаем укладываться в заданное время.
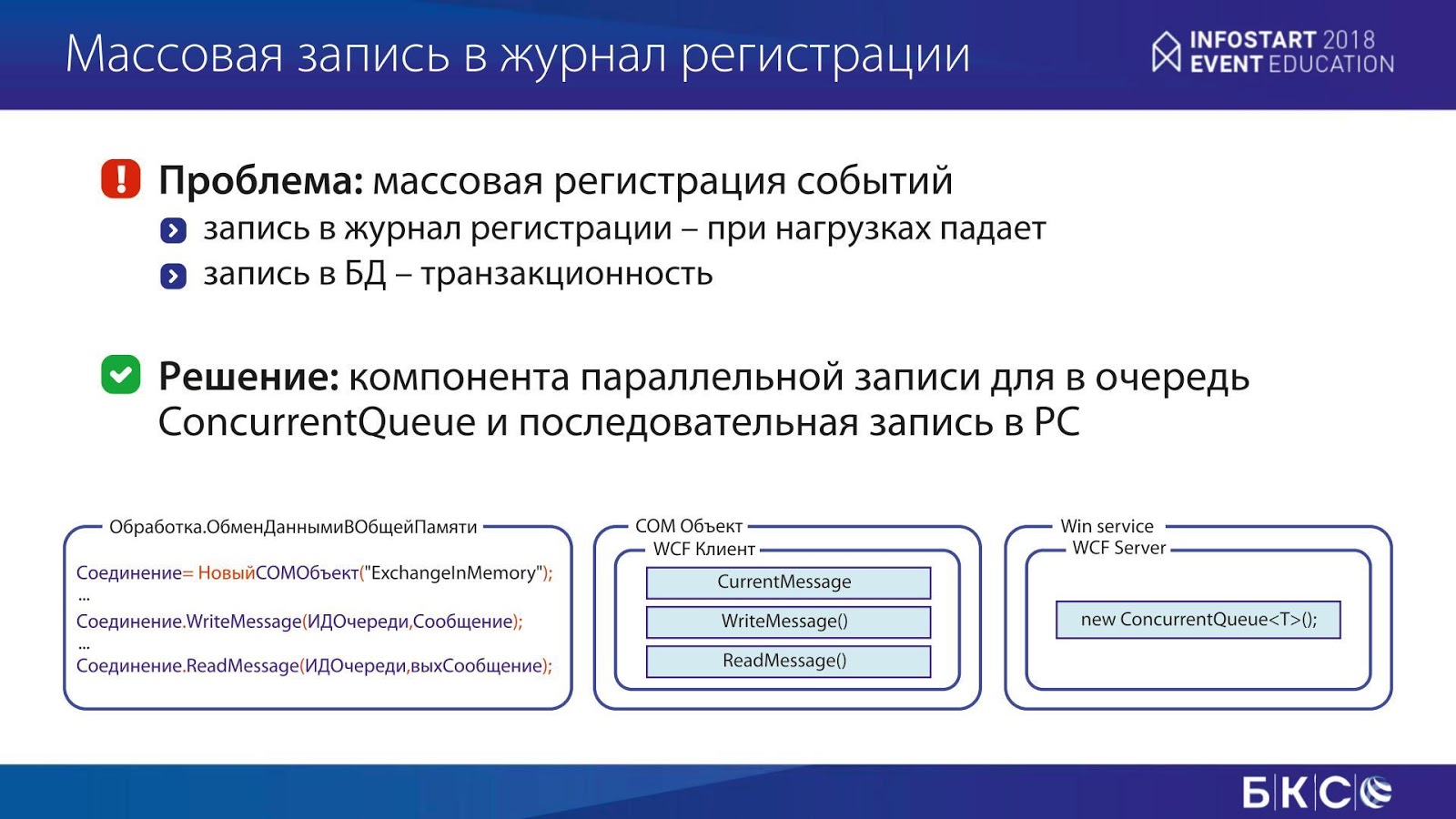
Следующая задача – массовая запись в журнал регистрации.
В одной из наших мидл-офисных систем, где было очень много сделок и движений, у нас случилась такая проблема – при попытке записать события в журнал регистрации, он просто «падал». Решили записывать события в ту же самую базу данных, в регистр сведений. Однако возникла существенная проблема: когда мы пишем в свою же базу данных, у нас есть транзакционность. И если что-то пошло не так (случилась какая-то ошибка), мы откатываемся, и записей о событии уже не видим.
Что можно сделать? Можно сделать разные вещи.
На Инфостарте очень часто предлагается такое решение – взять другой продукт. Вариант отличный, всё работает.
Но в данном случае мы пошли немного другим путем, потому что у нас есть свой стек технологий, свои специалисты по Си, и, исходя из этого, мы решили проблему достаточно просто.
-
Мы использовали класс ConcurrentQueue – это очередь в памяти, в которую можно писать параллельно, без блокировок.
-
Плюс написали COM-компонент для 1С.
-
С помощью этого компонента мы, фактически, в несколько потоков пишем информацию из 1С в очередь, читаем с помощью одной очереди и пишем. Блокировок нет, все классно, все пишется. Да, есть задержки, но это не принципиально.
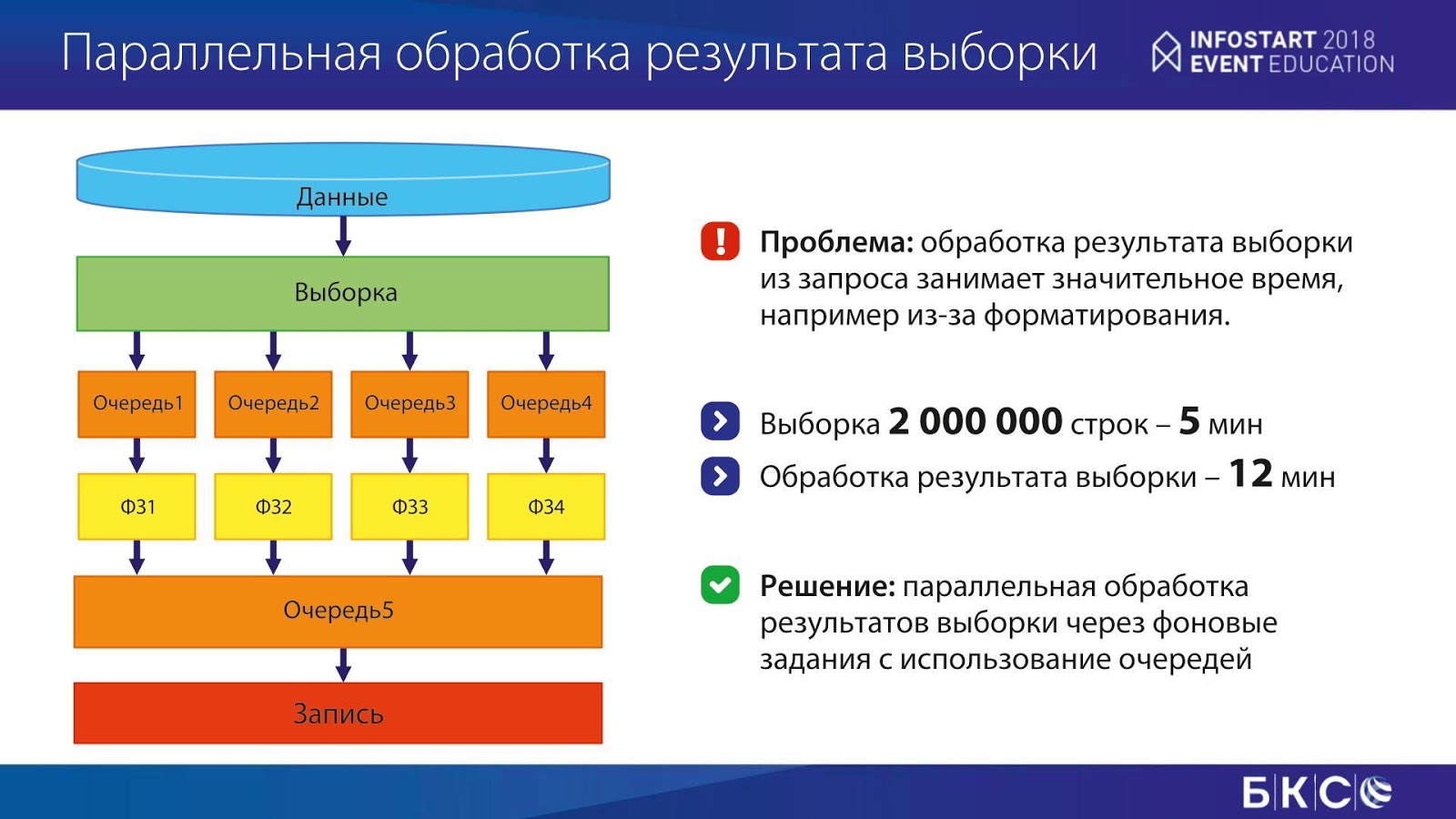
Далее мы эту компоненту начали использовать для других задач, чтобы оптимизировать, либо решить какие-то вопросы с производительностью.
Вот конкретный пример. У нас была выборка, как ни странно, те же 2 миллиона строк, которая занимала пять минут. В большинстве задач, связанных с Highload, требуется оптимизация запросов – проблема обычно в этом. Но иногда ты упираешься в то, что запрос уже некуда оптимизировать, на этом железе он работает пять минут. И это минимально возможное время.
Но обработка полученного результата (в данном случае нам нужно было записать в файл форматированный текст) занимала 12 минут. То есть проблема была не с SQL-запросом. Запрос, можно сказать, был прекрасен.
Что мы сделали? Мы разбили обработку результата на четыре потока в фоновые задания: результаты запроса записывались в очереди, фоновые задания слушали эти очереди, обрабатывали и писали еще одну очередь, из которой уже производилась запись. Скорость увеличилась в четыре раза. Это устроило бизнес.

Еще один интересный момент. Кто знает или использовал асинхронную запись в базу данных? Я рад, что есть хотя бы один человек. Отлично.
Есть простое решение, которое позволяет увеличить скорость записи – у нас при решении этой задачи скорость увеличилась на порядок.
Все очень просто. Есть многим знакомый СОМОбъект – ADODB.Command. В нем есть маленький параметр – adAsyncExecute. Он запускает выполнение SQL запроса, и можно после этого о нем забыть.
У нас есть один обмен через SQL-базу данных. Он сделан для режима онлайн, туда пишутся большие объемы. Выполнение этой записи занимало около получаса. Это не сильно похоже на онлайн, и нам нужно было решить этот вопрос.
Как он решился? Мы запускали пачку асинхронных инсертов, которые писались в базу данных, при этом параллельно готовили вторую пачку. Размер пачки тоже не просто так выбирался. На SQL сервере оказалось, что есть некая деградация. При увеличении количества инсертов в пачке скорость тоже падала. Поэтому экспериментально мы пришли к цифре около 5 тысяч записей, которые тоже делались в транзакции, потому что это ускоряет выполнение. В итоге продолжительность выполнения с получаса у нас уменьшилась до 3-4 минут. Это позволило нам работать и не мучиться.
Что нам помогает справляться со сложными задачами

Вопрос роста – это вопрос устранения незнания, по большому счету. Мы в компании применяем Agile Spotify, у нас множество кросс-функциональных команд/
Между ними, естественно, поддерживаются коммуникации – все классно. Но некоторые вещи позволяют быстрее расти.
-
Например, база знаний. Люди в чем-то разбираются, фиксируют какие-то вещи и потом, когда им приходится возвращаться, не дай бог, через год-два, все можно поднять. Либо приходят новые сотрудники, смотрят материалы, не отвлекая других специалистов, и разбираются, делают.
-
Кроме этого, у нас существует митапы – это нечто вроде внутренних конференций. Если человек в чем-то разобрался, считает, что это интересно, он рассказывает своей команде об этом.
-
На слайде я еще написал слово «исследования». В мире развивается такая тенденция, что сама разработка начинает занимать времени, чем дальше, тем меньше. В основном, специалисты начинают тратить больше времени на исследования. Потому что не нужно разрабатывать все с нуля – проще найти готовое решение проблемы: скачать какой-то продукт, который позволит быстро поставить ценность. Эти исследования иногда начинают занимать до 40% времени.
Наша архитектура

Расскажу про нашу архитектуру.
У нас, как я сказал, есть фронт-, мидл- и бэк-офисные системы.
-
Ранее они представляли собой кучу монолитов с невероятным количеством Legacy code. Эти системы обменивались между собой по шинам через события. Все это работает, все классно – когда при проведении документа, допустим, формируется один пакетик, на него подписываются все системы, и он сразу по всем разошелся. Эти шины у нас появились больше десяти лет назад, и они помогли решить многие вопросы. Кроме архитектурных.
-
Потому что когда наш бизнес решил выйти в онлайн и сказал, что нужно обслуживать больше миллиона мобильных клиентов, то возник вопрос, как это будет работать. По факту это привело к тому, что у нас на фронте появилась микросервисная архитектура – контейнеры и прочее, что позволяет масштабировать нагрузку и т.д.
-
Появилась смешанная модель архитектуры. То есть у нас, кроме событийной модели, обмены в массовом порядке начали происходить по RESTful-архитектуре, то есть по запросу.
-
Это привело к необходимости смены платформы. У нас не интерфейсная разработка, у нас Highload на 1С. Есть системы на 8.1, на 8.2 и на 8.3. Старые платформы перестали соответствовать требованиям, нужно было переходить на новую.
Переход на новую платформу

Как мы решили перейти на 8.3?
-
В мире 1С принято, что мы доверяем в стандартных конфигурациях тому, что там сделано. Нажимаем одну кнопку, просто берем и переходим. Я сам много раз так делал, в большинстве случаев это отлично работает. Но иногда бывают вопросы. В нашем случае это было недопустимо в принципе.
-
Второй вариант (тоже частый способ) – создаем копию базы на новой конфигурации, мигрируем туда данные. Если вылезли ошибки, исправляем. Потом мигрируем до пользователей, ставим миграцию в обратную сторону, чтобы можно было вернуться назад, подстраховаться. После того как все стало хорошо, просто убираем старую базу, и все работает. Я думаю, многие так делали. Я так делал неоднократно. Я думаю, вы знаете, сколько это занимает времени. Обычно это занимает год, иногда больше, иногда меньше – в зависимости от многих обстоятельств и рисков.
-
Мы пошли немного другим путем. Так как тема тестирования достаточно модная, мы решили покрыть регрессионными тестами всю нашу конфигурацию, чтобы точно быть уверенными, что все у нас будет хорошо.

Что нам это дало?
-
Возможность все сделать в ограниченные сроки, ведь в теории время выполнения теста – это то, с какой скоростью можем переходить, плюс какие-то инфраструктурные вещи.
-
А самое главное – уверенность в изменениях. То есть, если тесты «падают», значит, что-то пошло не так.

Что в эти тесты входит?
-
Основная масса – это регресс.
-
Также разнообразное дымовое тестирование, включая открытие/закрытие форм, справочников, запросов, работу с фоновыми заданиями, много чего. Обработок дымового тестирования на рынке много, за основу можно взять любую, она будет работать.
-
Кроме всего прочего, у нас есть специализированная система статистики, которая показывает, что делали пользователи во время тестирования. По нажатию одной кнопки мы можем повторить этот тест и второй раз пользователя не напрягать.
-
Еще есть нагрузочное тестирование, которое тоже делалось через регресс, и т.д.

Нам пришлось написать свой тестовый фреймворк, потому что те, которые есть на рынке, нам не подошли. Почему не подошли?
-
Потому что у нас уже есть куча тестов для основного прогона функциональности, эти тесты покрывают меньше половины, но основную ветвь функциональности покрывают. Все это работает как часы: перед каждым релизом происходит прогон, все работает.
-
Также есть тесты у QA (те же регрессионные), у программистов есть какие-то свои тесты.
-
Чтобы это все использовать, мы просто «допилили» инструмент, в котором это все гонялось изначально.
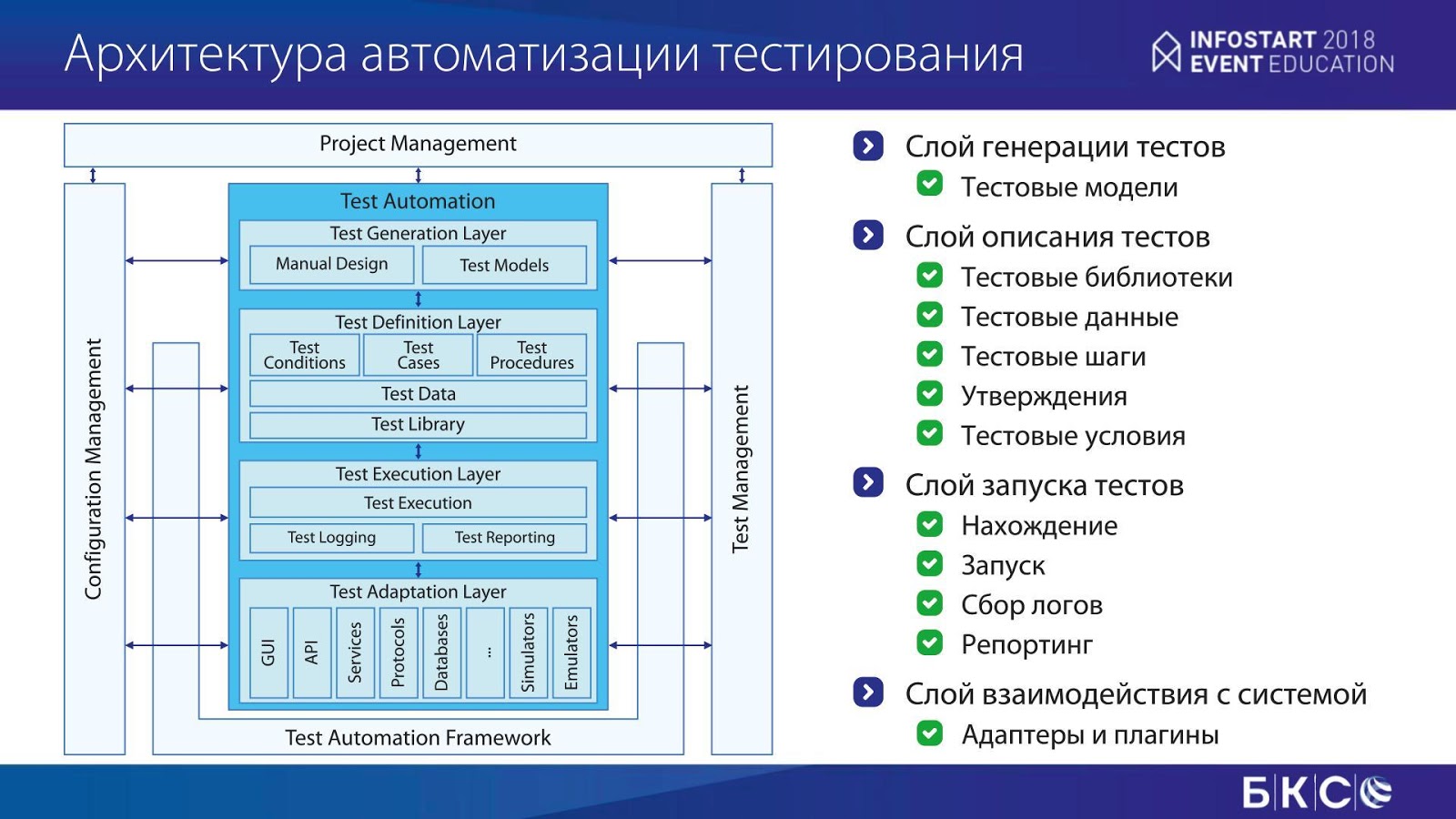
Требования к инструменту были достаточно стандартными для фреймворков по автоматизации тестирования. Есть такой документ «Архитектура автоматизации тестирования», который говорит, что в тесте должны быть определенные пункты:
-
слой взаимодействия с системой;
-
слой запуска тестов (нахождение тестов, запуск, сбор логов, репортинг – в Allure или другие системы);
-
слой описания тестов (тестовые библиотеки, тестовые шаги, проверка утверждений, тестовые условия и так далее);
-
тестовые модели (в данном случае, возможно, создание тестов не вручную, а какими-то библиотеками).
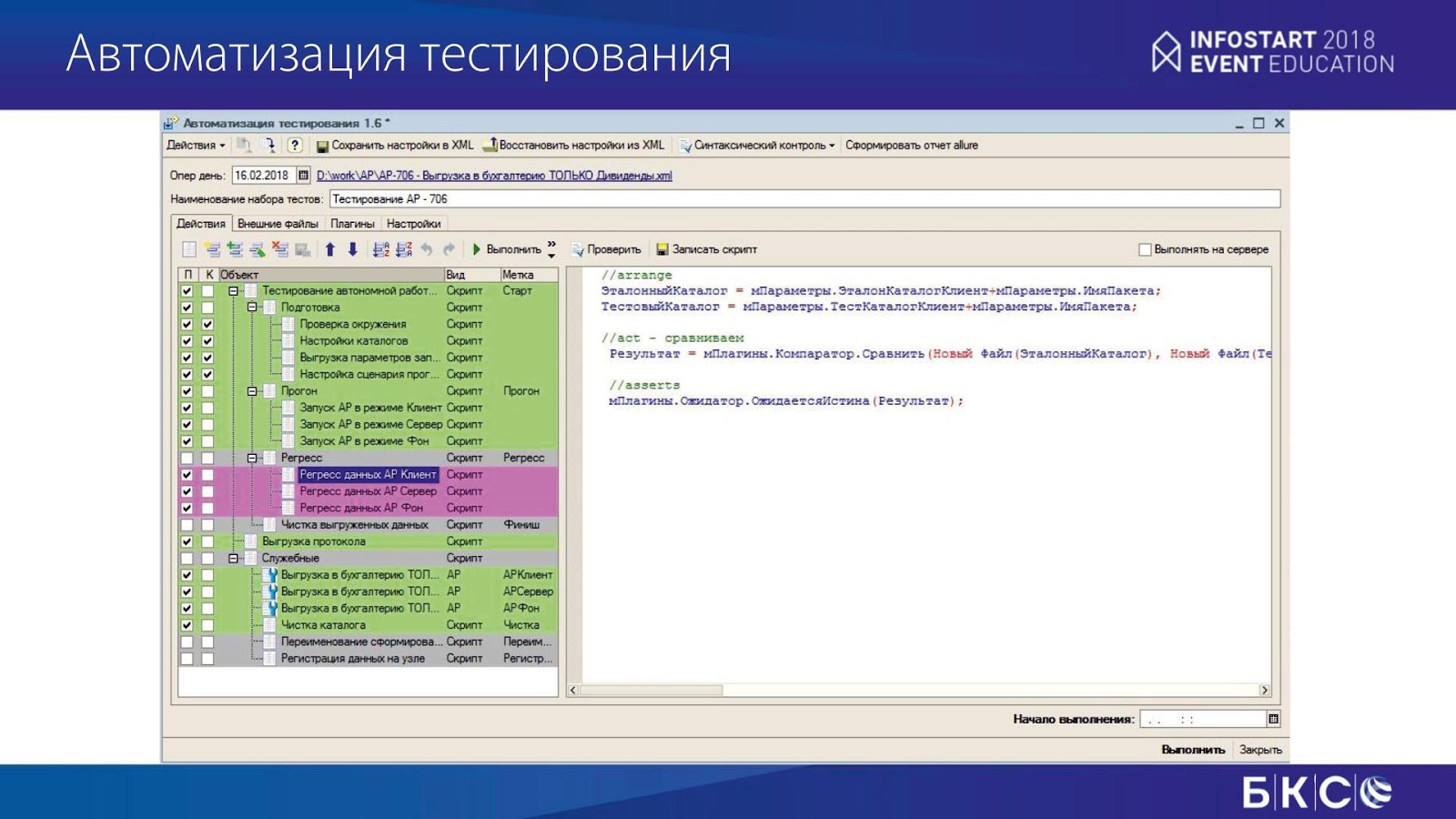
Фреймворк тестирования выглядит очень просто – это обработка.
На слайде слева – тестовые шаги, справа – текст теста. Сам тест пишется в понятиях «arrange», «act», «assert».
Он подключается к библиотеке, в которой содержатся «проверка утверждений», «наборы тестов» и прочее, прочее.

Как проверить, что тест отработал? Платформа практически ничего не предоставляет нам, кроме единственного инструмента – замера производительности.
На слайде видно, что есть некие дырки, которые не прошли замер производительности. Что нужно сделать? Проверить граф управления, изменить условия, и добиться полного прохождения.

Как запускаются тесты? Примерно так же, как отчетность:
-
создается снэпшот;
-
запускается 1С;
-
запускается обработка, которая запускает пачку шагов;
-
после выполнения снэпшот удаляется.

К чему это привело?
-
Количество регрессионных тестов у нас достигло 500.
-
Время прогона самого длинного теста – 36 часов примерно. Да, меня тут можно закидать всякими вещами. Но это именно регрессионные тесты. Я знаю, что такое пирамида тестирования, знаю, что такое Unit-тестирование, у нас есть свой фреймворк, по Unit-тестированию, он немного другой, и это, к сожалению, не тема данного доклада.
-
Покрытие тестами выросло примерно до 90%. В оставшиеся 10% вошло то, про что бизнес сказал, что это при переходе ему не важно.
Наши выводы

1С может многое. У нас – отличная платформа, которая позволяет решить много вопросов. Она, по большому счету, ограничена только базой данных.
Кроме всего прочего, программисты 1С могут расти профессионально, как в области типовых конфигураций, так и в области Highload. Нужно просто найти, где этот Highload. Я даже знаю одну компанию, где есть Highload.
Полезные ссылки
-
В чем разница между технологией Log Shipping и зеркалированием базы данных (Log Shipping vs database mirroring)
https://social.msdn.microsoft.com/Forums/sqlserver/en-US/ee05954e-0934-4305-8936-b9226e231d06/log-shipping-vs-database-mirroring?forum=sqldatabasemirroring -
ConcurrentQueue изнутри
https://habr.com/post/245837/ -
Англоязычная документация по подготовке инженера автоматизации тестирования ISTQB (advanced test automation engineer syllabus)
https://www.istqb.org/downloads/category/48-advanced-level-test-automation=engineer-documents.html
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2018 EDUCATION.

