Поговорим о том, как ИТ влияет на бизнес, и что с этим делать.
Доклад будет в лайтовом стиле, из серии «а как у них сделано». Мы поговорим:
-
как устроено ИТ в крупнейшей МФО в России;
-
основной упор сделаем на эксплуатацию 1С на больших объемах данных;
-
какие проблемы у нас бывают;
-
бонусом расскажу про нашу техподдержку.

Для начала представьте ситуацию: у вас ничего не работает, все системы сломались, гендиректор смотрит вам в глаза и просит назвать сроки.
А вы, как в мемасике на слайде, говорите: «Все очень страшно, мы не знаем, что происходит, если бы мы только знали, что происходит!»
Это – страшная ситуация, когда весь бизнес стоит. Непередаваемые ощущения. Нервы умирают миллиардами. Очень страшно. Особенно эта история актуальна для 1С, работающего в режиме highload.
О компании

Расскажу про микрофинансовую организацию (МФО), в которой я работаю, чтобы убрать негатив, потому что в основном люди негативно относятся к микрофинансовой деятельности.
-
Нашей компании «Центрофинанс» уже 10 лет. Это самая старая МФО в России, мы работаем в правовом поле.
-
У нас минимальные процентные ставки.
-
Все МФО поднадзорны Центробанку, и это означает, что на нас распространяются требования по подаче отчетности, по соблюдению законов и т.д. У нас почти банк.
-
В нашем офисе есть выделенный кабинет для сотрудников ЦБ РФ – они настолько часто приходят нас проверять, что мы им выделили специальное помещение.

Чтобы понимать масштаб бизнеса, покажу несколько цифр.
-
У компании 950 офисов от Калининграда до Камчатки, которые работают с 2 ночи до 9 часов вечера.
-
3000 сотрудников.
-
Больше 5 миллионов клиентов.
-
Плюс в связи с пандемией мы активно развиваем онлайн-сервис, и, по сути, в личных кабинетах на сайте мы работаем 24/7.
С чего все начиналось и какая была задача

Мы прошли в ИТ большой путь.
-
В 2015 году компания была полностью офлайн, все офисы были автономные.
-
Управленческие решения принимались очень долго, доносились очень медленно.
-
Между офисами были настроены распределенные базы, для которых мы раз в сутки совершали обмены.
-
Лаги менеджмента были большие, а система была неуправляемой.
В какой-то момент руководство поняло, что нужно что-то менять, нужно двигаться в онлайн. Клиенты тоже привыкают к онлайну, они не хотят приходить ногами в офис, они хотят использовать именно интернет.
Бизнес понимает, что теперь решения должны приниматься быстро, доноситься быстро, управлять сотрудниками в офисах тоже нужно быстро. А для этого ничего нет, вообще ничего.
Как раз в тот момент я пришел в компанию, и моя задача была – вывести ИТ на новый уровень, чтобы ИТ был драйвером развития компании.
Когда я пришел, в ИТ было 10 сотрудников: два админа, техподдержка, полтора разработчика. И кто-то на аутсорсе переводил 1С 7.7 на 1С 8.3 – это тоже досталось мне.
Сам я в ИТ с 2004 года, а в МФО работаю ИТ-директором с 2015 г. Открывал свои стартапы, которые, правда, неудачно закончились, но они тем не менее были.

Теперь немного об ИТ-цифрах – что мы имеем на текущий момент.
-
У нас 1,5 тысячи рабочих мест, которые непрерывно работают в онлайне в 1С.
-
У нас собственный кредитный конвейер на 1С – база порядка 8 ТБ. Это сама база, а к ней еще куча файлов и все тоже больших размеров. Все офисы, все подразделения, все сотрудники работают в этой системе. Это – основная центральная система компании, в которой ведется бизнес. Если мы отключим ее, нет компании. Проблема в том, что эта система одновременно и OLAP, и OLTP. С ней работают и аналитики, и менеджеры, которые обслуживают клиентов.
-
У нас громадное количество интеграций систем как с внутренними сервисами, так и с внешними – через API, через очереди сообщений RabbitMQ и т.д.
-
Бизнес у нас хочет все очень быстро, time to market, поэтому мы в 1С делаем 5 релизов в неделю.
-
В день совершается 250 тысяч звонков – это все фиксируется документами взаимодействий.
-
Плюс порядка 200 тысяч начислений по договорам в день.
-
У нас есть куча других баз: УПП, ERP, 1С:Документооборот. Их тоже громадное количество и, соответственно, много различных копий под разные цели. Причем все эти базы требуют ежедневного обновления, а каждая из них – примерно по 4-5 ТБ.
-
У нас было окно для техобслуживания всех наших систем. Ключевое слово «было». Сейчас этого окна нет, мы работаем 24/7, поэтому нам приходится крутиться и обслуживать это все на ходу.
Теперь про айтишников.
-
Сейчас у нас в ИТ-отделе работает 65-70 человек.
-
Из них 40 – это 1С-разработчики.
-
10 сотрудников техподдержки,
-
есть сисадмины, DBA, веб-разработчики, бэк-разработчики, немного аналитиков.
Из фреймворков мы используем все, что есть на рынке. Мы на Инфостарт ездим достаточно давно, и когда на конференции только начали говорить, что в 1С можно общаться через RabbitMQ, мы на тот момент уже активно использовали это в продакшене. Без таких технологий мы просто не смогли бы работать.
Что касается инфраструктуры – у нас собственный ЦОД, где мы размещаем инфраструктуру своих клиентов. У нас не один клиент, у нас небольшая группа компаний, и мы делаем отказоустойчивую инфраструктуру для всех. По сути, это облако.
Если говорить про архитектуру, так получилось, что кредитный конвейер у нас построен на 1С, и сейчас это большой высоконагруженный монолит с большим количеством транзакций.
Мы потратили очень много времени, чтобы это все работало. Но сейчас, поскольку мы выходим активно в онлайн, запускаем мобильные приложения, вопрос отклика стоит очень остро. И в ближайшие год-два мы будем решать вопрос, что делать дальше – как мы это будем делить на микросервисы. Это новая проблема, которую нам предстоит решить.
Как ИТ сейчас влияет на бизнес
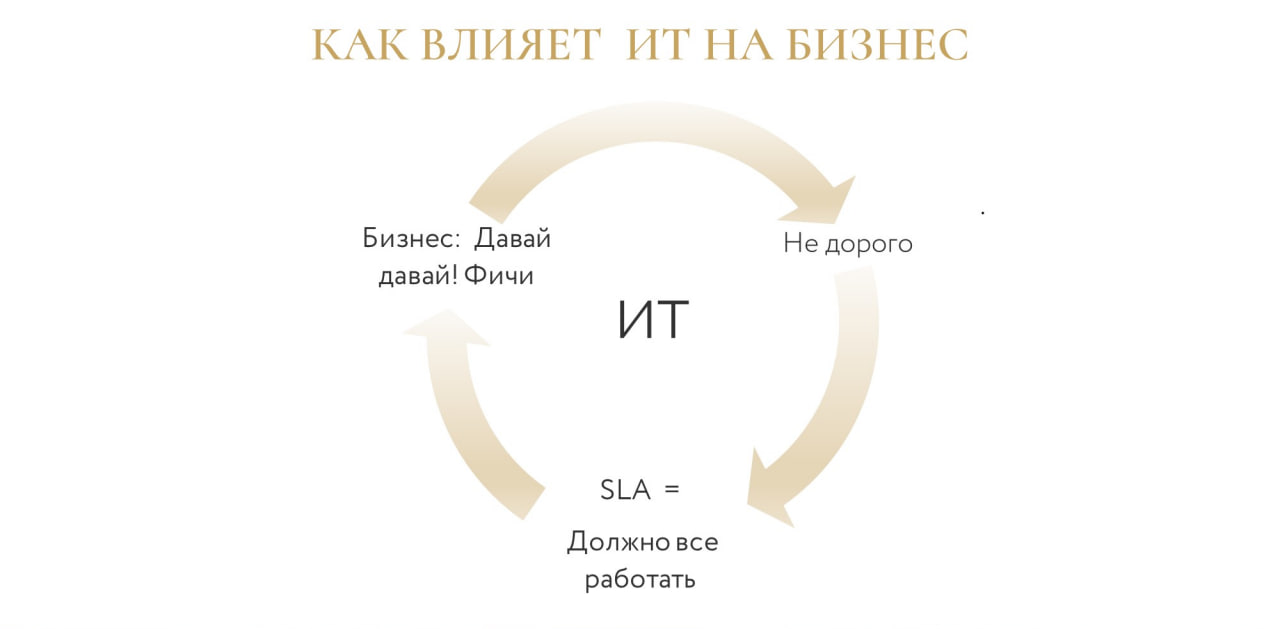
У ИТ есть четыре большие роли.
-
Поиск и внедрение новых инструментов, которые помогают бизнесу развиваться. Т.е. не бизнес к нам приходит и просит подобрать инструмент, чтобы решать какие-то задачи – это происходит примерно в 10% случаев. В основном мы сами видим проблемы и находим инструменты, пытаемся их имплементировать в бизнес. Мы ищем инструменты как по рынку, так и сами разрабатываем какие-то вещи, которые помогают бизнесу развиваться.
-
Формирование, управление и развитие команды. Последние 4 года мы работаем по Agile, у нас много кросс-функциональных команд – мы распределяем разработчиков по этим командам.
Небольшое лирическое отступление. Основная проблема Agile в том, что разработчики подвержены влиянию продактов. Как правило, продакты, которые делают проекты, делают по принципу «максимально быстро, максимально эффективно запилить проект» и особо не думают про техдолг. А техдолг у любого проекта копится. Допустим, проект запустили в работу, а техдолг оставили на потом. А там уже стоят следующие проекты, и этот техдолг копится. Задача центрального управления по ИТ – видеть такие вещи и стараться командам возвращать этот техдолг на исправление, чтобы он не тормозил реализацию основных задач, и больше этого техдолга не было. У нас это достаточно эффективно.
-
Третий блок работ – это эксплуатация систем: планирование архитектуры и инфраструктуры, обеспечение работоспособности.
-
И четвертый блок, который сейчас остается мейнстримом, – это развитие ИТ-мышления у не айтишных сотрудников. Мы внедряем громадное количество инструментов в бизнес, и бухгалтеры или юристы вынуждены говорить с айтишниками на одном языке. И мы сейчас стараемся растить людей, обычных юристов и бухгалтеров, чтобы они были хотя бы в теме, понимали, о чем мы говорим с ними. У нас сейчас нередко бывают ситуации, когда какой-нибудь топ-менеджер сидит в консоли PostgreSQL и дергает данные для какой своей гипотезы. У нас даже гендиректор пытается Python изучать.
В итоге получается замкнутый круг, когда:
-
бизнес просит новые фичи;
-
нам нужно их реализовать недорого и эффективно;
-
а потом это все должно работать с учетом SLA – не просто «продали и забыли».
И для меня блок «все должно работать» – один из главных. Потому что если что-то сломается, колесо остановится, придется потратить громадное количество времени, чтобы система стабилизировалась – чтобы она работала, чтобы люди работали, чтобы бизнес работал. На этом блоке я остановлюсь подробнее, мы как раз про него и поговорим.
С какими проблемами сталкивается ИТ и как их решить
Когда мы перевели первые 100 офисов на работу в онлайне на новой самописной системе 1С, мы с удивлением обнаружили, что это вообще не работает. У нас каждый день появлялась какая-то новая проблема.
Поскольку проблемы возникали постоянно, мы даже в одно время начали искать альтернативу 1С. Но когда посмотрели ценники на другие решения, поняли, что все-таки 1С не так плоха.
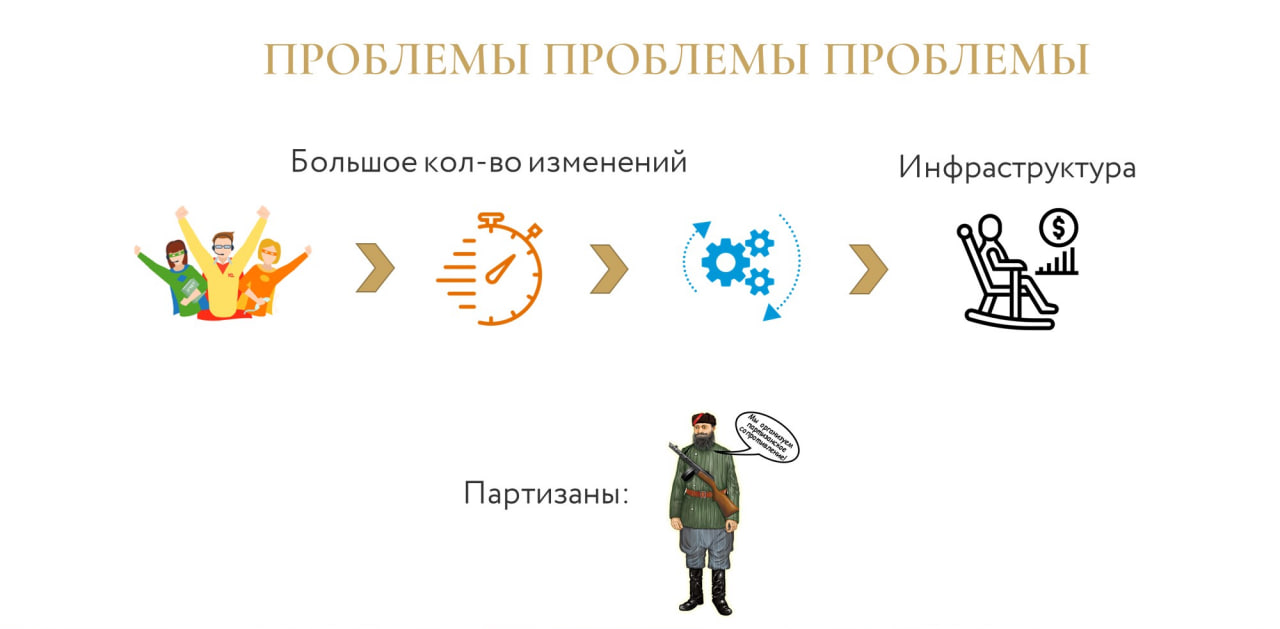
Чтобы понять, какие проблемы бывают, я сгруппировал их в 3 большие группы.
-
Первая – это большое количество изменений, когда одно вытекает из одного, бесконечный поток. Любая статичная система работает по принципу «сделал – забыл». Это очень классный кейс. Но когда бизнес развивается, когда развивается ИТ, это не работает. Поэтому большое количество изменений является основной проблемой любого ИТ. Большое количество изменений генерируют разработчики, а у нас их 40. И эти 40 разработчиков каждый день пишут код, делают новые фичи, исправляют баги. Дальше все это попадает в продакшн 5 раз неделю. Этот код создает изменения: появляются новые объекты в системе, новая функциональность, растут объемы данных. Все это вынуждает инфраструктуру меняться. У нас не хватает ресурсов, мы меняем серверы, мы постоянно делаем что-то в инфраструктуре, чтобы догнать бизнес и сделать небольшой запас.
-
Как следствие, вторая проблема – инфраструктура устаревает, ее необходимо апгрейдить. Плюс у инфраструктуры есть такие бонусы как обновление. Обновление серверов, обновление операционных систем, обновление 1С, в том числе платформы. Это все необходимо делать, это тоже вызывает определенные проблемы.
-
Третий блок проблем самый веселый – это партизаны. Это люди из разряда: «а запущу-ка я этот отчет в 5 различных вариантах за 3 последних года одновременно». Или у админов/разработчиков: «Я же уже 100 раз так делал, зачем ждать вечера, можно же сделать это сейчас». И самое классное: он что-то сделал, никому не сказал и ушел домой. А потом все сломалось, и никто не понимает, что происходит.

Расскажу, что мы с этим делаем.
-
По факту задача – сделать проблемы управляемыми. Мы должны понимать, что делать в случае возникновения проблем, должны иметь на этот случай какой-то план действий.
-
И второе – мы должны сделать развитие системы тоже управляемым процессом. Чтобы понимать – то, что ты делаешь, не поломает другое.
Мы вывели простые правила, которые помогают нам решить 90% любых проблем, возникающих при эксплуатации нашей продакшн системы.
-
Основное правило – соблюдение регламентов, как бы банально это ни звучало. Регламенты нужно писать. Мы писали регламенты из собственной практики, после аварий, каких-то прецедентов, когда поняли, что пошло не так и что нужно сделать, чтобы такое больше не повторялось.
-
Например, у нас есть регламент ограничения доступа на продакшн. Мы никого не пускаем на продакшн (руки прочь от прода).
-
Есть регламент highload – чуть позже о нем скажу.
-
Есть регламент планирования работ, в котором сказано, все работы нужно планировать заранее. Что в плане должно быть описано, какие изменения будут, что нужно с этим делать (план А, план Б), что можно делать в это время. Потому что у бизнеса тоже есть какие-то циклы, пиковые дни и т.д.
-
У разработчиков есть свои регламенты. Поскольку разработчиков много, должна быть какая-то стандартизация кода. У нас есть требования к запросам, к транзакциям, к реструктуризации базы данных, к изменению типового кода конфигурации поставщика, к правам доступа, к качеству кода. Все это проверяют тесты, SonarQube и т.д.
-
-
Второе правило – это автоматизация. Мы стараемся автоматизировать все, чтобы процессы того же деплоя, тесты и мониторинг проходили автоматически, без участия человека, а любые баги сразу возвращались на доработку, чтобы все было управляемым.
-
И третье правило – руки прочь с прода. Доступ к проду у нас выдается только дежурным и только в нужные дни. Работы на продакшене разрешены только в нерабочее время или во время минимального трафика.
Казалось бы всего три правила. Но когда мы сделали то, что я перечислил, это примерно на 80% уменьшило возникающие проблемы и позволило нам контролировать изменения.
Эксплуатация
Систему highload нужно эксплуатировать, поэтому следующий блок – эксплуатация.
Эксплуатация – это уже непрерывный процесс, который мы делаем каждый день, и его приходится обслуживать. За любой системой, которая создана, нужно следить постоянно. У нас для этого используется мониторинг.

У нас мониторится очень много метрик. Из ПО используется Zabbix, Prometheus, GreyLog и т.д.

Но и для нас, и для бизнеса важна одна метрика – среднее время всех ключевых операций. Эта метрика показывает, что система работает – ее видим мы, видит бизнес, видит техподдержка, видят все.
Любые отклонения тоже сразу видны, поэтому мы сразу начинаем как-то решать проблемы.
Остальные метрики помогают раскрутить проблему, выявить, в какой части системы возникли проблемы. По опыту 1С скажу, что проблема возникает каждый раз в новом месте.
Все эти метрики мы придумали не просто так – они возникли после аварий.
Каждый раз, когда возникала авария, мы добавляли очередной график, чтобы и это тоже мониторить. В итоге у нас получилась такая сложная система, с помощью которой мы пытаемся искать проблемы.
Поскольку у нас транзакционный бизнес, мы замеряем все операции, которые происходят в системе. Мы до секунды знаем, когда конкретный менеджер что конкретно сделал, за сколько времени сделал. Мы это все видим.
Коммуникации
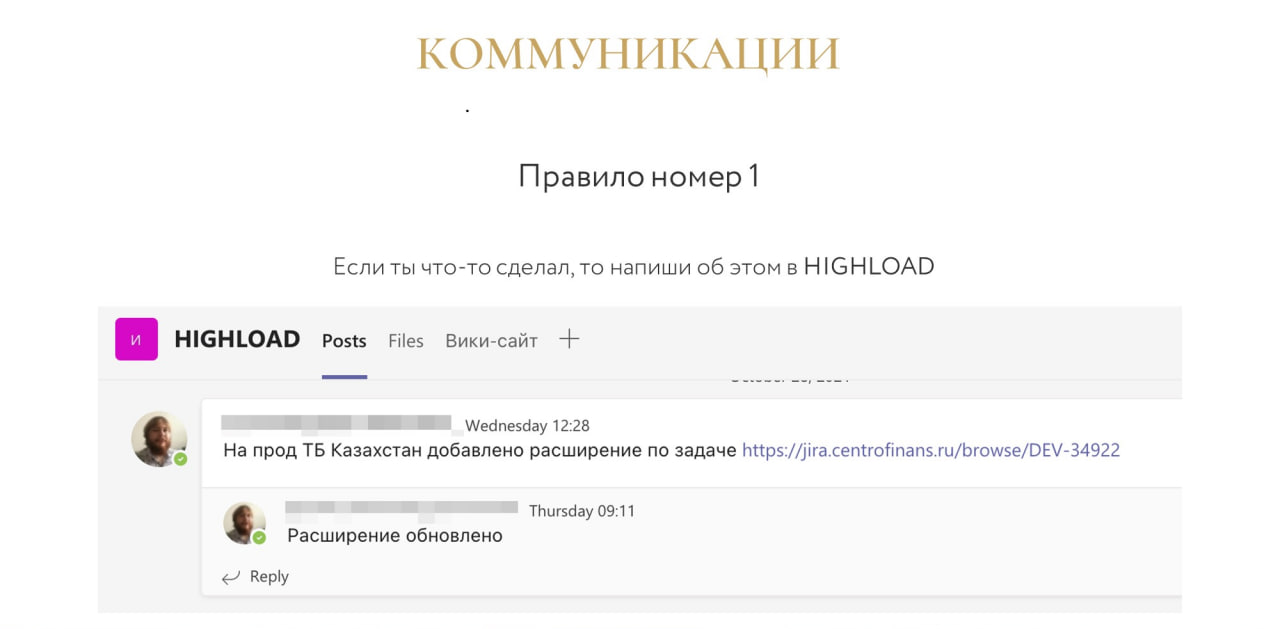
Следующий блок – это блок коммуникаций.
Коммуникации мы ведем в Teams – у нас там есть две очень важные группы. Я даже отписался от всего в Teams, остался только в этих двух группах.
И вообще блок коммуникаций – очень важный, с ним связаны два правила, самые важные в моем докладе.
Правило №1: если ты что-то сделал, напиши об этом в группе Highload. Любые работы, которые происходят на продакшене, обновления, релизы – все постится сюда. Это позволяет нам решить громадное количество операций.
Потому что когда админ уведомляет, что собирается что-то делать на продакшене, ты сразу можешь понять, можно ли это делать сейчас в business time, сопоставляешь риски, можешь человека вовремя остановить.
Или другой пример. Человек что-то сделал, появились какие-то проблемы, ты зашел в Highload, посмотрел и увидел, что проблемы начались после того, как такой-то Вася делал такую-то работу. Остается очень быстро этого человека найти, чтобы он откатил изменения. Если вы так не делаете, обязательно пользуйтесь, это must have!
Правило №2. У нас есть канал «ИТ Опасносте», куда постятся аварии, которые произошли. Если ребята из техподдержки понимают, что проблема уже произошла, они постят это в группу, и айтишники бросают все свои дела и начинают чинить.
Мы приучили своих менеджеров в таких случаях очень быстро локализовать массовые инциденты. В свое время мы делали это по телефону, но пока дозвонишься до техподдержки, проходило много времени.
Теперь у менеджеров есть собственный мессенджер, в котором они общаются. Мы для них там создали отдельную комнату и приучили, что о любой проблеме они пишут туда.
А если возникает массовая проблема, например, о ней написали 10 человек одновременно, информация попадает в канал «ИТ Опасносте», и дальше мы начинаем все чинить. Так что этот инструмент тоже эффективный и позволяет нам очень быстро взаимодействовать по проблемам.
У нас есть еще один чат. На картинке вы видите его реальное название.
Он действительно невеселый, потому что в этом чате решаются все эксплуатационные задачи.
Уже много раз договорилось о том, что админы ненавидят 1С-ников, а 1С-ники ненавидят админов. Это вечный круг, и с этим ничего не сделать, потому что одни ругают 1С, другие – сервер. В этом чате постоянно ведутся баталии, поэтому он так и называется.
Сейчас тенденция такая, что мы все-таки подружили админов и 1С-ников, они там стараются вести конструктивные разговоры, и любые проблемы решаются более-менее эффективно.
У нас стандартная практика – DBA ежедневно смотрят метрики базы данных, выискивает какие-то проблемы, неоптимальные запросы. Если видят их, скидывают в чат, а 1С-ники уже подхватывают и смотрят, что в них можно оптимизировать.
Факапы
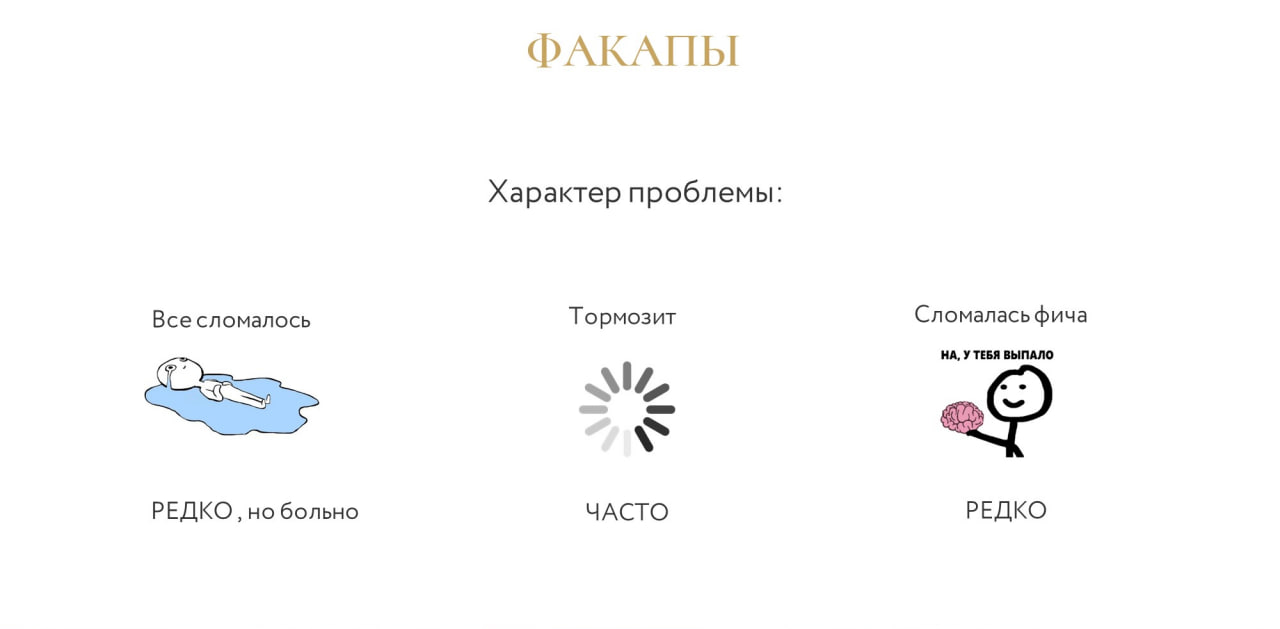
Расскажу про характер проблем, которые у нас есть:
-
«все сломалось» – достаточно редкая проблема, но если появляется, всем больно;
-
«тормозит» – достаточно частая проблема;
-
«сломалась какая-то фича» – тоже достаточно редко.
Картинка на слайде описывает состояние системы сейчас, три года назад все три категории проблем были частыми.
Сейчас по большей части, на 90%, мы занимаемся проблемой производительности. Потому что у нас в системе одновременно работает около 1,5 тысячи сотрудников. Они используют систему в режимах OLAP и OLTP – это транзакции и тяжелые отчеты для аналитиков и топ-менеджмента.
То, что сейчас все работает – результат ежедневной доработки системы за последние три года. Мы научились идеально оптимизировать запросы, у нас есть регистры, в которых больше миллиарда записей, ежедневно используемых в работе. В свое время там было по 100-200 миллионов записей, каждые полчаса делались выборки, и серверу баз данных становилось плохо. Сейчас там ежедневно проходит не меньше миллиона таких операций, и все очень хорошо.
Но проблема производительности очень актуальна для нас. Когда мы выходим в онлайн, 1С становится бэк-системой, поэтому вопрос стоит очень остро, мы будем его решать.
У нас сейчас в Kubernetes работает порядка 100 микросервисов, и мы стараемся какие-то куски функциональности из 1С выносить, потому что понимаем, что с таким монолитом очень тяжело работать. Быстро, но тяжело.

Вкратце расскажу про причины самых долгих аварий, которые у нас были.
-
Самая долгая авария на картинке слева: 5 лет назад вылетел предохранитель из блока розеток, и из-за этого мы потеряли ЦОД на 8 часов. Мы не могли попасть в помещение, там был выходной, поэтому на 8 часов потеряли ЦОД, 8 часов мы не знали, что происходит.
-
Вторая долгая проблема: отключился автомат, который электрики из ЦОДа нам поставили ниже номинала, и у нас вылетела стойка. Подняли стойку, включили серверы, но виртуализация отказалась заводиться. И мы 4 часа мучились, чтобы это все поднять. 4 часа бизнес просто курил.
-
Бешеный тракторист, который стандартно перекапывает траншеи, – это наша третья долгая авария. В прошлом году далеко за городом делали траншею, но перекопали не только основной канал, но и все резервные. У оператора, благо, были какие-то запасные каналы, мы еле работали, но можно сказать, что даже не работали.
-
И четвертый момент – это добрый человек, который хочет сделать что-то полезное, но, как правило, это приводит к печальным последствиям. Особенно на продакшене без уведомления в Highload. Но в таком случае можно сразу писать заявление на увольнение.
Техподдержка

При анонсе доклада я обещал рассказать про нашу техподдержку, но пока готовил этот слайд, я чувствовал себя примерно вот так. Я заявил тему заранее, но потом понял, что это все-таки тема другой презентации, другой конференции. Потому что техподдержка для 1С-ников – это скучно.
-
У нас в техподдержке 10 человек.
-
Они обслуживают 1,5 тысячи рабочих мест,
-
работают с 3 утра до 20:00 по МСК,
-
им прилетает 40 тысяч инцидентов.
-
У нас есть единый портал техподдержки, который покрывает все отделы. Например, менеджер создает какую-то проблему, а задача уходит юристу, и все это делается через единый портал.
Задач у техподдержки достаточно много:
-
это поддержка работоспособности всех рабочих мест;
-
видеонаблюдение;
-
корпоративная сотовая связь;
-
и еще порядка 20 обязанностей.
В чем наш секрет?
-
Мы стараемся все максимально автоматизировать и настраивать рабочие места по одной кнопке.
-
У менеджеров есть инструменты, которые позволяют им самим решать проблемы – например, у них есть инструмент диагностики. Если что-то не работает, менеджер нажимает диагностику, система сама проводит диагностику проблем. Если видит, что нужно перезапустить, она перезапускает, уведомляет сотрудников техподдержки, что проблему починила сама, все работает.
-
Также мы используем мониторинг рабочих мест, чтобы видеть, где были проблемы, и смотреть на динамику.
Для оценки работы саппорта я использую метрику «количество закрытых обращений». И если все довольны, никаких жалоб от заказчиков нет, значит техподдержка работает.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.
