Меня зовут Евгений Филиппов, я работаю экспертом в компании IBS. Расскажу про свой опыт создания инфраструктуры на импортозамещенной платформе, который сформировался в ходе нескольких крупных проектов. Считаю важным донести до людей те вещи, которые мы там увидели.

В процессе любого крупного внедрения нужно обеспечить не просто строительство системы, но и сделать так, чтобы эта система устойчиво развивалась.
Чтобы крупная система устойчиво развивалась, недостаточно учитывать только экономические факторы – стоимость лицензий и необходимое оборудование.
Если бы мы говорили про внедрение на 50 или 70 пользователей, там, наверное, можно было бы обойтись какими-нибудь серверами или рабочими станциями, которые есть в загашнике.
Но когда мы говорим про внедрение большого масштаба, нужно учитывать не только экономические факторы (ядра, память, скорость и размер дисков и т.д.) Нужно учитывать еще экологические и социальные факторы.
Если возникает дисбаланс, система начинает перекашиваться в одну из сторон, и устойчивого развития не возникает. Получается, что «хвост вытащили – нос увяз, а нос вытащили – хвост увяз».
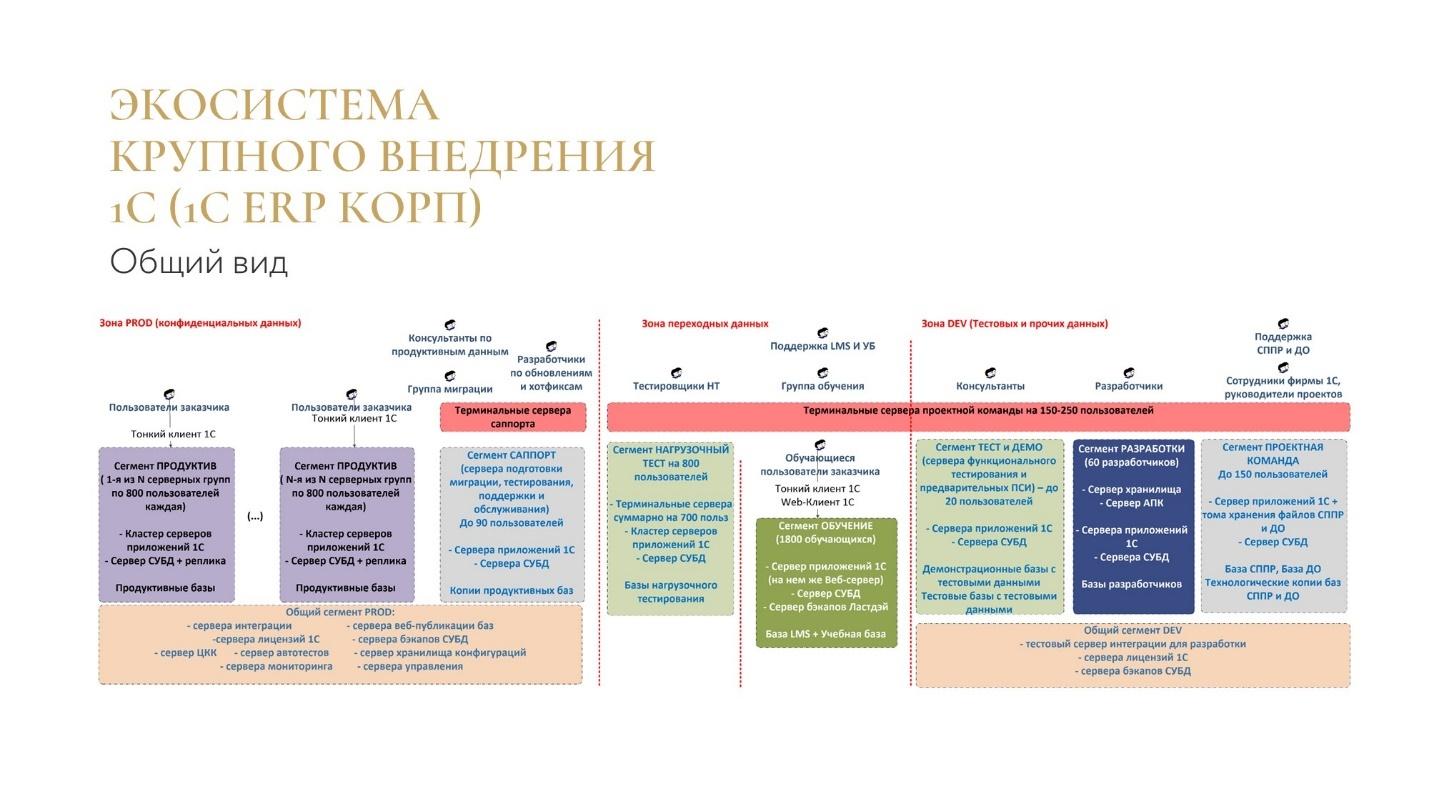
Меня часто просят посчитать оборудование для продуктивного контура внедрения. Но в экосистеме всей компании продуктив – это только фиолетовая часть (см. рис. выше). Почему-то считается, что остальное можно где-то раздобыть по остаточному принципу: либо взять «на сдачу», либо найти какой-то сервер на складе.
Но на крупном внедрении таких возможностей практически нет.
А если мы переходим на импортозамещенную платформу, то таких возможностей может не быть в принципе. Потому что если у вас есть сервера под Windows и MS SQL Server, то совершенно не факт, что у вас есть все нужное для того, чтобы поднять всю инфраструктуру на Linux и PostgreSQL.
Вкратце по слайду. Здесь я поделил всю инфраструктуру на три зоны.
-
Первая зона – зона продуктивных данных, в которой работают специалисты заказчика. Здесь находятся конфиденциальные данные, к которым посторонние вообще не должны иметь доступа. И речь не идет о каком-то особом режиме секретности – это просто нормальный продуктив, куда не нужно пускать посторонних.
-
Вторая зона – зона переходных данных, она на разных этапах проекта может относиться то к конфиденциальным, то к не конфиденциальным данным. Например, сегмент нагрузочного тестирования. Пока у нас нет базы с мигрировавшими данными, у нас там какие-то тестовые данные, которые мы сгенерировали с помощью обработок. Туда можно пускать всю команду разработки. Но после того, как в этом сегменте появляются копии продуктивных баз для нагрузочных тестов, мы его уже начинаем относить к проду. Именно поэтому он называется зоной переходных данных. Аналогично с сегментом обучения, который сразу выстраивается из того, на каких НСИ мы пользователей учим. Если пользователи заводят собственные НСИ: «Организация1», «Организация2», организация «Ромашка», понятно, что это ничего секретного. Если у нас все-таки там есть продуктивные НСИ, то мы этот сегмент относим к проду.
-
И, наконец, третья зона – зона DEV – это зона прочих данных, где может работать вся команда разработки, внешние подрядчики, специалисты субподрядчиков. Туда можно пускать всех, кто вообще работает на проекте. Здесь никаких конфиденциальных данных в принципе быть не должно, только какие-то тестовые.
Все это на крупном проекте нужно каким-то образом создать, поднять, настроить, а также нужно посчитать и выделить на это бюджет.
-
Если мы рассчитываем только продуктив, то хорошо, когда у нас в поддержке, консультировании и разработке работают 5 человек – мы их где-то на чем-то можем посадить работать.
-
Но когда в поддержке, консультировании и разработке начинают работать сотни человек, мы их «где-то на чем-то» посадить работать уже не сможем.
-
А если нам надо одновременно обучить порядка 1800 пользователей за три недели, то понятно, что на ноутбуке это не сделаешь. И люди, которые готовят эту работу, они тоже просто так откуда-то не возьмутся. Подготовка трех недель обучения может составить примерно 9 месяцев работы команды обучения.
Здесь начинают соединяться и экономические факторы, и социальные.
Обзор сегментов экосистемы и основные драйверы требований к оборудованию в каждом из них
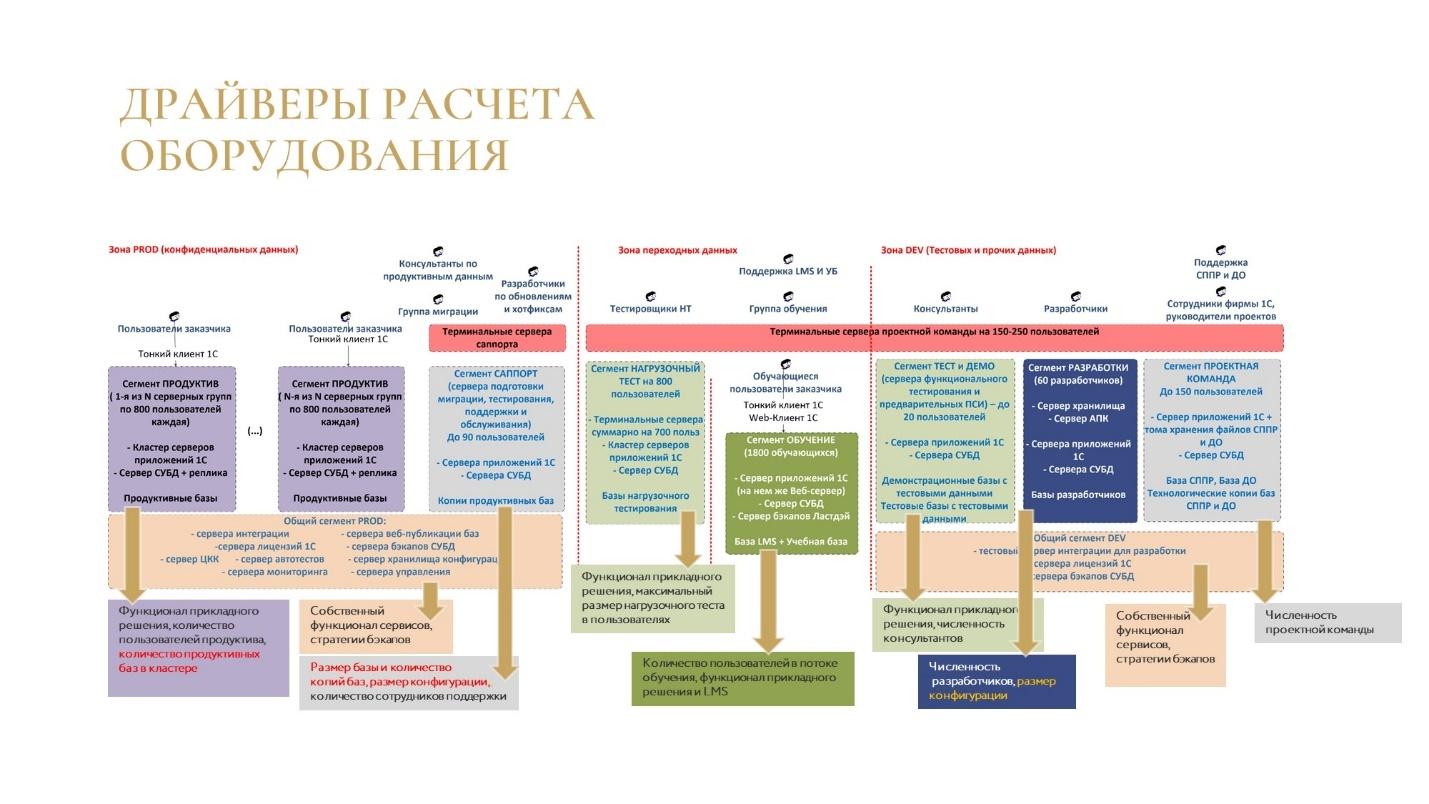
Но еще немного про экономику.
Когда мы говорим про крупные внедрения, начинают проявляться драйверы роста мощностей, которые не проявляются в условиях, когда мы работаем не с ERP УХ.
-
Например, если у нас используется ERP УХ, и у нас в продуктиве в одном кластере несколько баз, то количество баз в кластере начинает являться драйвером роста ресурсов.
-
Дальше посчитайте, сколько места нужно на бэкап и на зону саппорта. Допустим, у вас суммарный размер основных баз занимает 2 терабайта. Чтобы консультанты могли нормально работать и могли делать какие-то эксперименты для пользователей, вам нужно от 3 до 7 копий каждой базы. 2 умножить на 7 – это уже 14 терабайт. Это еще один драйвер роста ресурсов.
-
Теперь прикиньте ресурсы под команду разработки. Самый часто используемый драйвер здесь – это численность команды разработчиков. Но если мы работаем с большой конфигурацией, нам нужно еще учитывать и размер этой конфигурации – а это и оперативная память на серверах, и скорость дисков, с которыми разработчик должен работать.
Реальные сроки формирования команды с навыками Linux и PostgreSQL у заказчиков, ключевые моменты ее обучения и вовлечения

Теперь перейдем к социальным факторам.
То, что нужно обучать сотрудников (пользователей) заказчика – это понятно. Но сначала задумайтесь о том, кто все это хозяйство будет поддерживать. Если ранее ваша информационная система размещалась на какой-то другой платформе, то, как правило, у вас не выстроены связи между специалистами по Линуксу, 1С-никами и специалистами по PostgreSQL.
Я не говорю о том, что какой-нибудь разработчик не может поднять PostgreSQL у себя на ноутбуке. Конечно, может. Большинство это умеет делать. Но человек, который умеет профессионально сопровождать 1С, Linux и PostgreSQL, именно сопровождать, отвечать на вопросы, консультировать – это уже уровень 1С:Эксперта по ТВКВ с соответствующим ценником и дефицитом на рынке.
Чтобы команда заказчика могла эффективно администрировать эту систему, она должна с самого начала выстраивать свою «социалку» – должна заботиться о людях, которые будут эту систему сопровождать. Для заказчика – это совсем не короткий и совсем не простой процесс.
Да и со стороны партнера тоже нужно понимать, что нам нужны админы, которые будут сопровождать часть этой системы длительное время, на весь период ее разработки и внедрения.
За что я сразу агитирую:
Сразу отдавайте прод заказчику. Не должны партнеры-аутсорсеры администрировать прод. Прод должны администрировать собственные сотрудники с самого начала.
Тогда:
-
во-первых, они все шишки набьют на этапе внедрения;
-
и затем у вас не будет проблем с длительной передачей системы на поддержку заказчика – тем более, что эти работы аутсорсятся довольно плохо.
Опять же, здесь вопрос не в том, что кто-то что-то не умеет делать. Свою часть работы умеет делать каждый. Но связки могут выстраиваться неэффективно.
Чтобы связки заработали нормально, требуется время. И нужно внедрять новые регламенты для запуска определенных изменений в командах, которые привыкли администрировать Linux или PostgreSQL по старым регламентам для других систем.
Неожиданные, но показательные сложности с логистикой при использовании Z-платформы 1С, их решение

Следующая вещь связана с экологией. Под «экологией» я понимаю процессы жизнеобеспечения системы, которые связывают ее с другими.
Например, есть неожиданные, но показательные сложности с логистикой при использовании Z-версии платформы.
Дело в том, что фирма «1С» выпускает версии платформ релиз за релизом. И некоторые из этих релизов 1С направляет на сертификацию для использования в системах соответствующего класса защищенности. Эти сертифицированные Z-релизы. Это та же самая платформа, просто для них получен ряд формуляров с посчитанными контрольными суммами. По сути, ничем, кроме наличия формуляра, они от обычных платформ не отличаются. Но, если у вас система определенного класса, и вам нужно использовать Z-платформу, то с Z-платформы вы можете перейти только на следующую Z-платформу.
Это не особенности программного продукта, это особенности перехода с одной системы, имеющей формуляр, на другую систему, имеющую формуляр. Чистая бюрократия.
Но в этом случае получается, что у нас не работает традиционный способ исправления ошибок: «А давайте обновимся на следующий релиз». Потому что следующий релиз появляется совсем не часто. А использовать часть от следующего релиза вы не можете – контрольная сумма не сойдется.
Может возникнуть желание: давайте разработку будем вести на простой платформе, а на продуктиве будет стоять Z. Вот тоже нет. Потому что в этом случае вы получаете очень серьезные сложности с логистикой внутри экосистемы. У вас могут возникнуть необъяснимые ошибки при передаче информации с одной платформы на другую, и вы их не отловите. Но это скорее умозрительная сложность.
Если у вас платформа Z, вам нельзя разводить зоопарк релизов внутри экосистемы, потому что это может вызвать и реальные сложности:
-
На сервере Linux не может быть штатным способом установлено несколько платформ. Умельцы ставят, но это внештатная возможность.
-
Если у нас используются серверы лицензирования под Windows, на них нужно ставить несколько серверов разных версий, что вызывает большие сложности с точки зрения администрирования этих серверов.
-
В случае с платформой Z нельзя просто так взять и поднять релиз платформы – вы можете перейти только на следующий релиз Z.
-
А еще вам нужно обучить админов быстро обновлять релизы у пользователей и избегать большого количества ручной работы. Если обновлять через автоматическую раздачу нового релиза тонкого клиента, то в случае, когда много пользователей утром в понедельник откроют 1С, это приведет к тому, что у вас все каналы связи лягут.
Все это влияет на экологию системы в целом.
Точки опоры при сайзинге оборудования

Я рассказал про социальную часть и про экологическую. В итоге все это влияет на экономику системы, потому что сайзинг оборудования начинает расти.
-
Мы подключили к системе саппорт – оборудование подросло.
-
У нас увеличился расход оперативной памяти на продуктивных серверах из-за размещения нескольких баз ERP УХ в кластере – у нас оборудование подросло.
-
Мы включили сегмент обучения на 1000 пользователей – оборудование подросло.
-
У нас стало 100 разработчиков вместо 5 – оборудование подросло.
Когда этот бег в песчаную горку вообще закончится? На что можно опереться?
-
Единственная надежная точка опоры – это собственные экспериментальные данные. Экспертные оценки в этом случае – это хорошо. И мнение вендора – это хорошо. Но собственные экспериментальные данные собственные вам в этом случае никто не заменит. Поэтому, пожалуйста, закладывайте в план и в бюджет проекта работы по регулярному нагрузочному тестированию.
-
Одним нагрузочным тестом тут не обойтись, поэтому планируйте, что циклов тестирования у вас будет несколько. Особенно если функциональность развивается или команда меняется, если у вас идет пилот, а не тираж, вам нагрузочных тестирований нужно будет проводить несколько – это работа, которая требует регулярного проведения.
-
Более того, эту работу нужно будет потом передать заказчику, чтобы они могли это делать в проде. А нормально заказчик сможет ее делать после появления в штате эксперта по технологическим вопросам крупных внедрений. Потому что эффективное взаимодействие с ЦКТП 1С возможно только при наличии 1С:Эксперта в команде – оно идет только через 1С:Эксперта.
Конечно, нагрузочный тест нужно проводить и на демо-функциональности. Сам я не очень это люблю делать – на мой взгляд, это то же самое, что тестировать сферического коня в вакууме (а скорее даже пони, который никакого отношения к нормальному коню, который потом появится, иметь не будет). Тем не менее, это делать надо. Потому что иногда это – единственная вещь, на которую можно опереться.
Система регулярных бэкапов и призыв к компании Postgres Professional

Еще один фактор, где сливается экономика с социалкой – это обслуживание бэкапов. И вообще администрирование продуктивных серверов. Но проблема бэкапов в случае импортозамещенной платформы вылезает просто во весь рост.
-
Потому что dt-шниками здесь не обойдешься.
-
Если баз много, ручками даже через средства СУБД не накопируешь.
-
А штатный способ архивирования резервного копирования в PostgreSQL, который указан на ИТС, подразумевает необходимость архивирования кластера целиком. И если у нас в кластере несколько баз, тратится очень много времени на восстановление этого большого кластера на отдельный сервер, а потом на перекачку всего этого хозяйства по сети на другой сервер. И хорошо если при этом админы не ошибутся и не забудут заблокировать базу, которая восстанавливается. то есть, эта операция – очень затратна и по ресурсам, и по времени и по человеческому фактору.

Здесь вот у меня большое желание обратиться с призывом к компании Postgres Professional.
Уважаемые коллеги! В рамках развития крупных экосистем обратите ваше внимание на то, что вашу систему администрируют люди, которые не являются ее полными владельцами. Это люди, которые выполняют какую-то одну отдельную функцию.
Пожалуйста, сделайте Postgres Pro более admin friendly!
Потому что это тоже социалка – универсального админа, который будет владельцем этой системы, в такой системе не будет.
Восстановление баз с использованием очень крупных аппаратных и людских ресурсов для крупных систем является нарушает баланс факторов: проседает и экология, и социалка. Да, мы можем использовать дорогих консультантов, дорогое оборудование и очень мощные каналы. Но этого все равно может не хватать, а кроме того, это все равно не получится использовать на постоянной основе.
Импортозамещение – это не только про продуктив
Подытожим. Перевод продуктива на импортонезависимую платформу – это не только про экономику и стоимость железа на продуктиве. Это про саппорт, про обучение, про администрирование, про рынок ресурсов, которые будут обучать, администрировать и так далее.
Чтобы создать новую экосистему крупного внедрения 1С, все это нужно учитывать.
Многие из этих вещей придется делать с нуля. Удачи вам в этом нелегком деле.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.