Хочу рассказать о том, как от микросервиса для хранения данных перейти к простой и доступной каждому BI-системе. Поделюсь своим опытом того, как мы объединили эти два актуальных понятия – микросервисы и BI-система – и за 6-7 месяцев выстроили эффективное решение.
Этот мастер-класс будет практическим:
-
В первую очередь я расскажу, как создавать микросервис на языке Go и покажу, как работает готовая программа.
-
Потом расскажу, как можно переносить данные между разными базами с помощью достаточно простых инструментов, которые есть в Яндекс.Облаке.
-
Покажу, что можно некоторые моменты пропустить и записывать данные напрямую в базу Яндекс.Облака.
-
Разберем логику работы DataLens.
-
И покажу, как можно анализировать данные.
Чтобы пройти этот мастер-класс вместе со мной, вам понадобится:
-
Установленный Go и редактор кода (например, Visual Studio Code или другая программная оболочка, в которой вы привыкли программировать).
-
Сама программа, которую можно скачать из вложения к публикации.
-
Установленные MySQL и Workbench, чтобы делать запросы и смотреть, какие данные попадают в таблицы.
-
И аккаунт в Яндекс.Клауд – без него уже никуда.

Итак, моя история – о том, как из небольшого микросервиса выросла недорогая BI-система. Или баллада о том, как 1С-разработчик в Яндекс.Облако сходил, и что он там нашел.
Что-то у нас много всего накопилось... Лучше это хранить отдельно

Расскажу об исходной ситуации – с какой проблемы началась вся эта история.
-
У нас была сеть магазинов – много торговых точек, много операций, много продаж.
-
Была разработанная с нуля конфигурация на платформе 1С для управленческого и оперативного учета, которая собирала данные о продажах и производстве, выдавая определенные аналитические результаты руководителям подразделений и руководителю компании.
-
Для работы этой базы данных был настроен свой физический сервер 1С в облаке, ресурсы которого не безграничны.
-
И был руководитель, который везде ищет интенсивный и эффективный путь развития. И всегда открыт к новым технологиям.
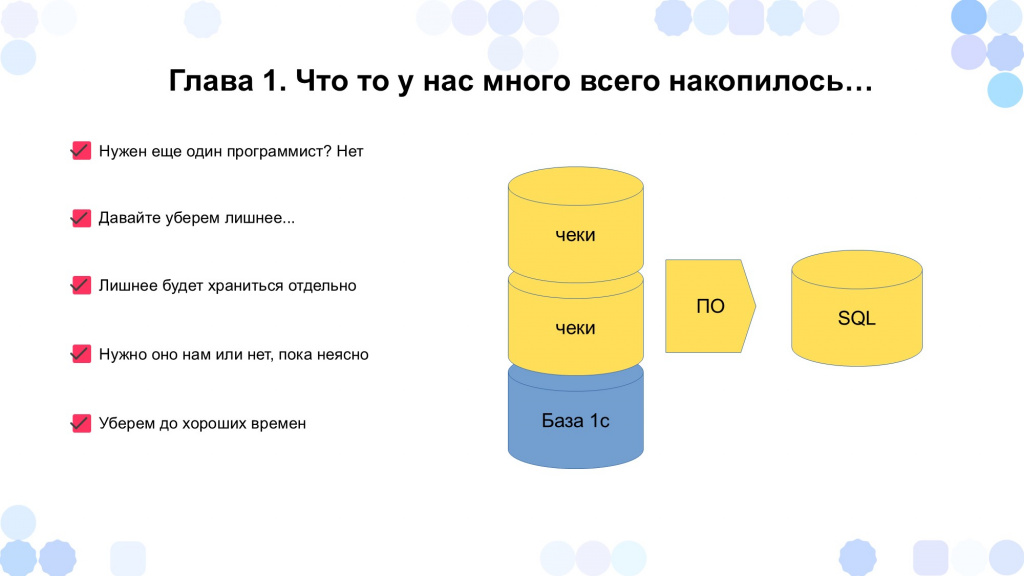
В какой-то момент база данных нашей самописной 1С-конфигурации разрослась до гигантских масштабов – достигла объема 100 гигабайт.
Возникла проблема: такая база потребляет много ресурсов, ее нужно обслуживать. Необходимо было проанализировать, что занимает в этой базе основное место, и как с этим работать.
Было предложено решение – нанять еще одного программиста. Но руководитель сразу же отклонил этот вариант, назвав его экстенсивным: пригласишь одного – появится второй, третий и так далее. Вместо этого он предложил пойти по другому пути и как-то это оптимизировать.
Мы провели анализ данных и выяснили, что основной объем в базе занимают чеки, поступающие из торговых терминалов. Далее эти чеки агрегируются в документы «Отчеты о розничных продажах» и используются для расчета зарплаты кассиров. Но эти чеки мы один раз загрузили, собрали из них данные и более ими не пользуемся – по идее, их можно удалить и не потерять при этом никакой управленческой информации.
Однако, как это часто бывает, руководство выразило сомнение: а что, если они всё же когда-нибудь понадобятся? Удалить – значит потерять навсегда. Поэтому было принято компромиссное решение: архивировать эти данные и вынести их за пределы основной базы. Если возникнет необходимость – их можно будет вернуть обратно. Если нет – впоследствии удалить без ущерба.
Так появилась идея новой архитектуры.
С СУБД для хранения этих данных мы определись достаточно быстро, потому что одним из ключевых требований ко всем нашим продуктам было использование open source в сочетании с разработками и идеями наших программистов. Поэтому выбрали MySQL: PostgreSQL слишком большой и слишком сложный, а MySQL – достаточно популярный, и его знают много специалистов.
А вот по поводу ПО для переноса этих данных из 1С в отдельную базу возникло достаточно много споров.

Мы рассмотрели три возможных подхода к реализации программы, которая будет забирать чеки:
-
Написать эту программу на PHP.
-
Использовать для выгрузки и хранения чеков отдельную базу данных на платформе 1С.
-
Или же попробовать очень модный язык, который ориентирован на сетевые и серверные приложения – язык Go.
В результате мы выявили следующие преимущества и недостатки каждого из вариантов:
-
PHP – простой и доступный, по нему легко найти специалистов, и если программа небольшая, ее можно в дальнейшем передать на сопровождение стороннему исполнителю. Но для использования PHP требуется поднимать веб-сервер (IIS), и такая архитектура не выдерживает большого количества запросов. Т.е. с учетом того, что в системе обрабатываются тысячи чеков, есть вероятность, что PHP на определенном этапе не выдержит.
-
Второй вариант – 1С. Его большое преимущество состоит в том, что мы знаем, как на нем создать HTTP-сервис и принимать нужные нам данные. Однако 1С – это не open source, и поскольку данные нужно хранить отдельно, придется покупать лицензию. Плюс сама платформа 1С довольно требовательна к ресурсам – мы не можем просто взять выделенный виртуальный сервер (VDS), установить на нем программу 1С и забирать в нее эти данные.
-
И третий вариант, который нам показался самым перспективным – это программа на языке Go. Язык Go изначально создан для серверных и сетевых приложений, поддерживает высокую производительность и масштабируемость. Можно свободно выбрать порт, который будет общаться с другими компонентами системы. Нет необходимости поднимать веб-сервер. Главный минус этого варианта – язык Go надо изучать, а у нас никого, кроме 1С-программистов, не было.
А теперь как получить обратно то, что выгрузили?
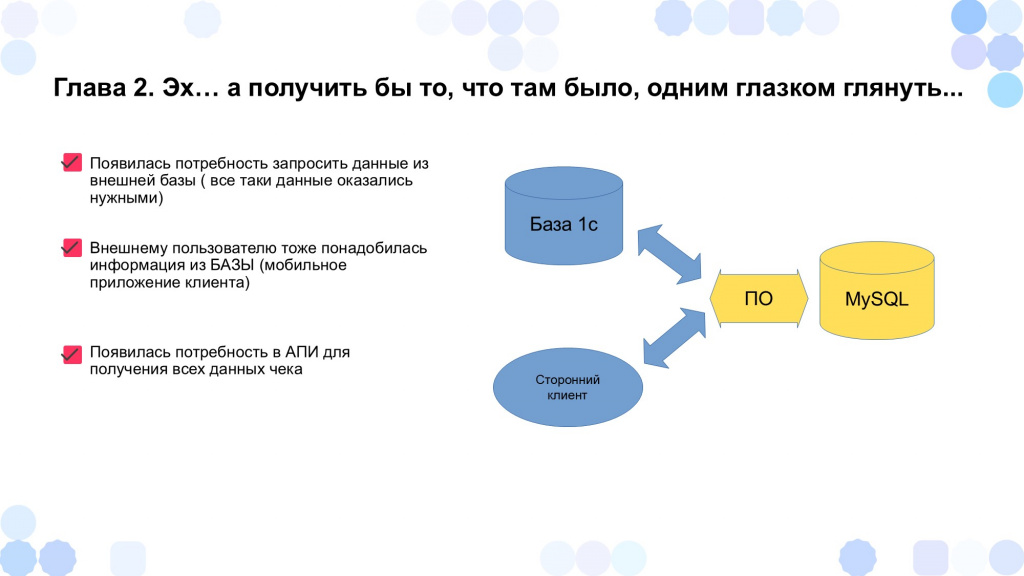
После того как мы разработали и внедрили первую версию программы, система успешно заработала. Мы обошлись без привлечения дополнительного программиста и закрыли основную задачу – освободили место в базе данных.
Но оказалось, что те данные, которые мы вынесли в стороннюю базу, нам нужны:
-
В первую очередь, для 1С – например, чтобы загрузить чеки обратно и пересчитать отчеты о розничных продажах или организовать пересчет зарплаты кассирам, если изменились какие-то алгоритмы.
-
Кроме того, у нас появилось мобильное приложение, в котором каждый управляющий хотел видеть информацию – какие чеки пробились, когда они пробивались и так далее.
В результате нам понадобилось доработать программу, чтобы она возвращала данные – не только забирала их из 1С в стороннюю базу данных, но и возвращала из этой базы в 1С или же в сторонний клиент, который знает идентификаторы этих чеков.

Кратко покажу, из чего состоит эта система.

Чтобы создать аналогичный микросервис для приема данных, вы можете воспользоваться материалом, который приложен к этой публикации.
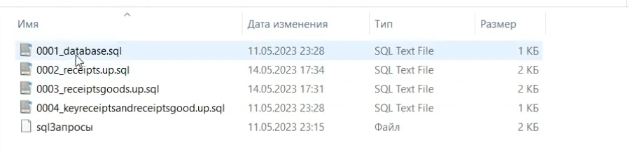
Там в папке migrations выложены тексты запросов, с помощью которых вы можете автоматически создать базу данных и определенные таблицы – их достаточно просто копировать и вставить в среду Workbench.
Для этого я открываю Workbench – пока здесь никаких нужных нам баз нет. И первое мы делаем – это создаем базу, вставив сюда текст из файла 0001_database.sql. У нас появилась база «microserv».
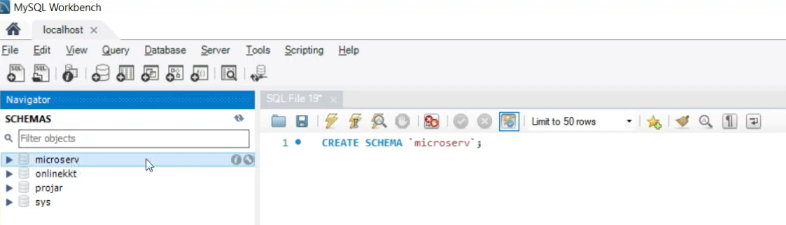
В этой базе у нас должна быть таблица со списком чеков, где для каждого чека прописано, какая у него сумма, во сколько он был пробит, сколько наличными, кто продавец и от какой организации.
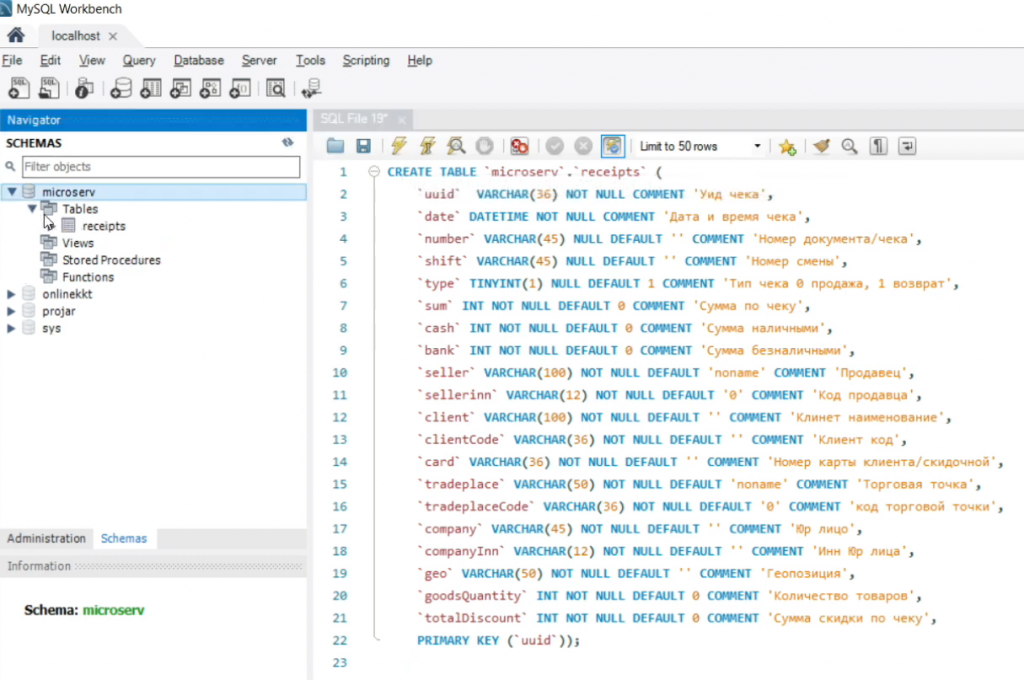
Вставляем в среду Workbench текст из второго запроса 0002_receipts.sql, запускаем его и проверяем – у нас появилась табличка с чеками receipts.
Переходим к третьему этапу. Нам нужно создать табличку по товарам – у каждого чека есть список товаров, которые продавались по этому чеку.

Вставляем сюда текст из третьего запроса 0003_receiptsgoods.up.sql, запускаем и видим, что у нас появилось две таблицы – receipts и receiptsgoods.
И с помощью четвертого запроса 0004_keyreceiptandreceiptsgoods.up.sql добавим внешний ключ, который связывает UUID чека и UUID таблицы каждой позиции по товарам – чтобы товар был привязан к чеку.
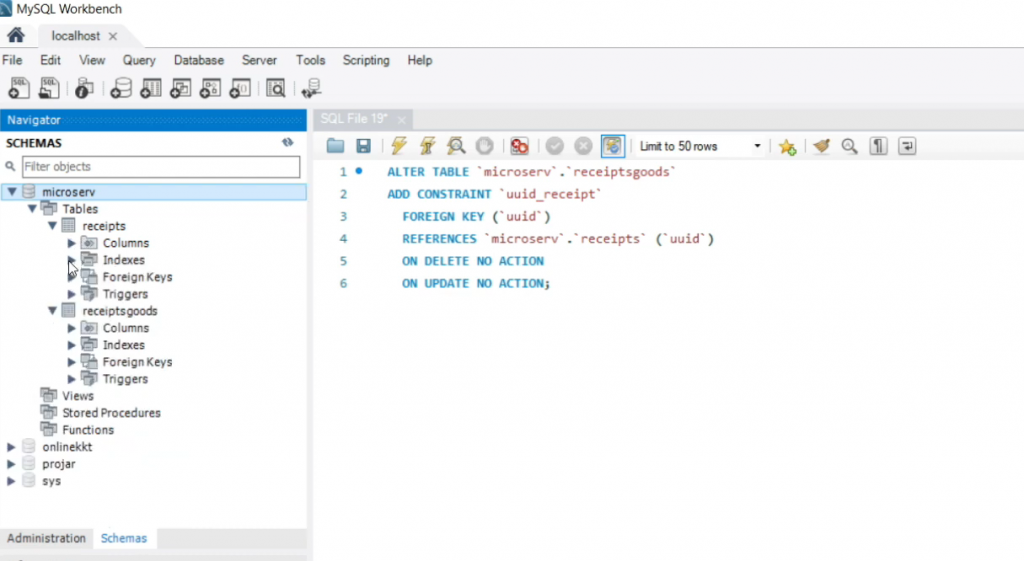
Таким образом у нас готова база, которая будет принимать чеки – мы создали и настроили в ней все нужные таблицы. Как видите, в MySQL это было сделать очень просто – у нас есть графическая оболочка Workbench, с помощью которой, если что, можно посмотреть данные и, если надо, какие-то таблички доработать, обработать или что-то дополнить.
Структура микросервиса на Go
Теперь о том, почему мы выбрали Go. Главное его преимущество – это компилируемый язык. В отличие от PHP, для которого нужно устанавливать IIS и настраивать интерпретатор, в случае с Go достаточно просто скомпилировать программу и скопировать ее на выделенный сервер. Никакой дополнительной настройки не требуется – исполняемый файл просто запускается и работает.
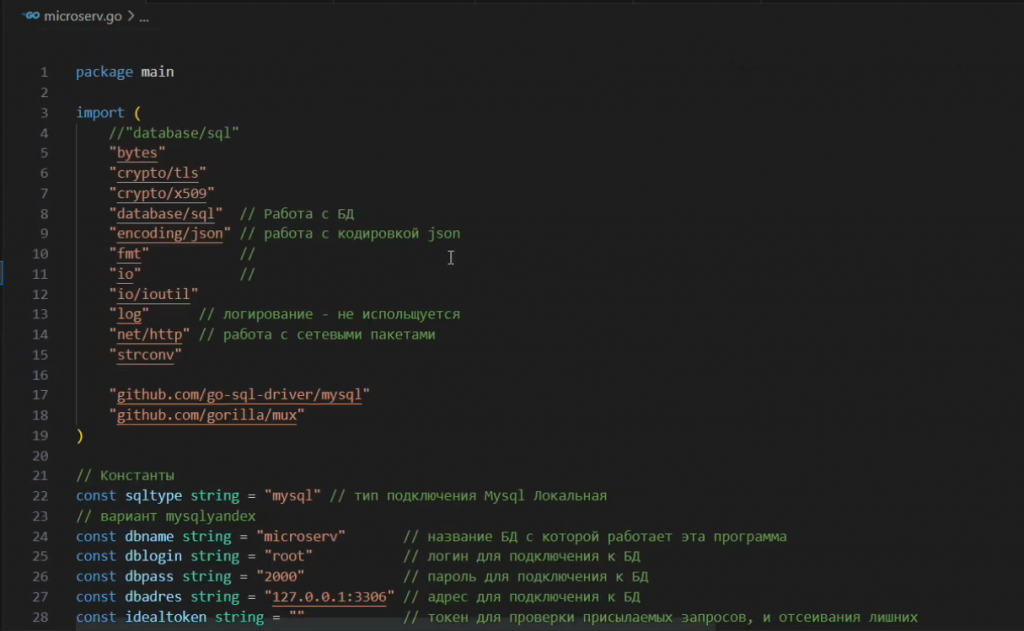
Давайте посмотрим, из чего состоит программа.

Программа достаточно небольшая – основной код для создания сервера, который принимает данные и отвечает, занимает буквально 285 строк.
Основное, на что здесь стоит обратить внимание – это порт, по которому будет идти обмен – он указывается в строке:
err := http.ListenAndServe(":8080", nil) // устанавливаем порт веб-сервера
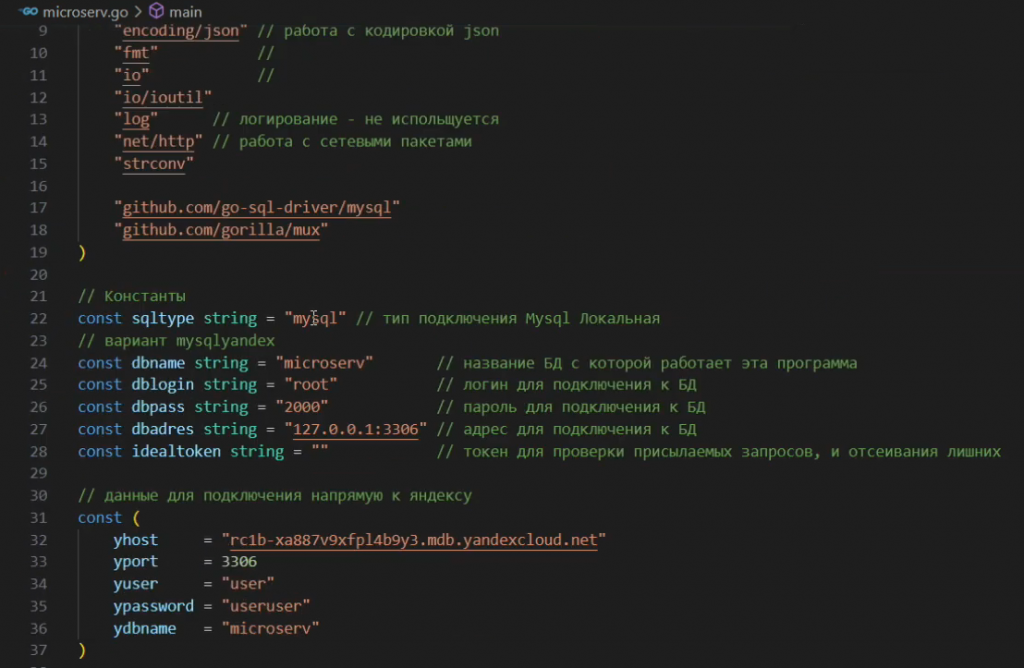
И параметры подключения к базе MySQL – название базы данных, логин, пароль и адрес, где у вас СУБД локально находится.
Достаточно правильно установить эти настройки и программа уже готова к компиляции – вы можете ее запустить.
В комплекте с программой есть файл build.bat, в котором прописана команда для компиляции:
go build microserv
После выполнения этого батника в каталоге появляется программа microserv.exe размером около 7 мегабайт.
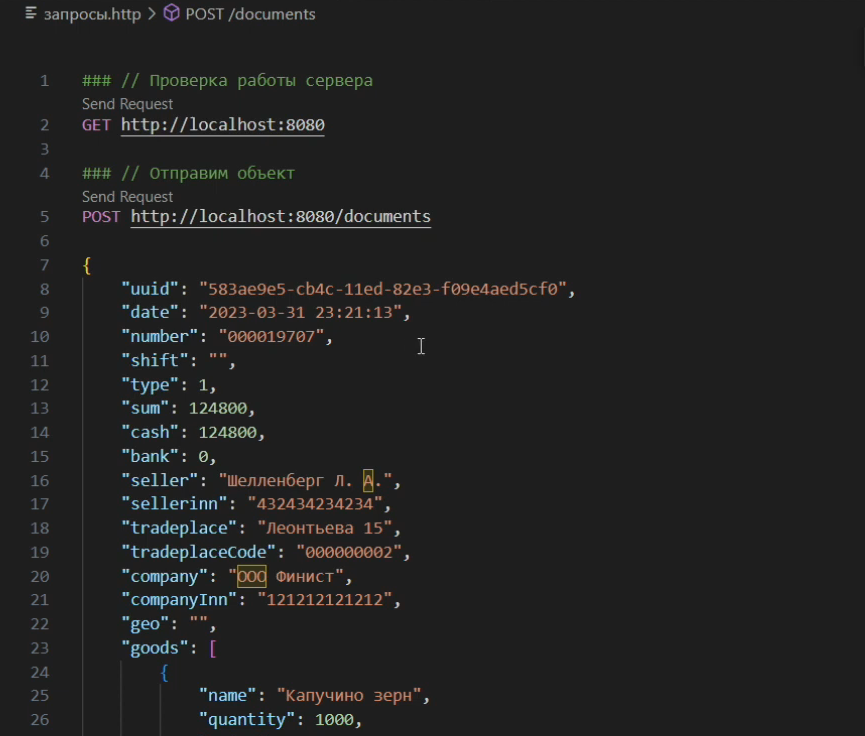
Поскольку эта программа должна уметь отвечать на определенные запросы, для проверки ее работы подготовлен файл «запросы.http» с тремя запросами:
-
GET http://localhost:8080 – проверка работоспособности сервера.
-
POST http://localhost:8080/documents – отправка чека
-
GET http://localhost:8080/documentinfo?uuid=583ae9e5-cb4c-11ed-82e3-f09e4aed5cf0 – получение чека с конкретным UUID из базы данных.
Перед отправкой запросов необходимо запустить файл microserv.exe. После этого нажимаем в редакторе для первого запроса гиперссылку Send Request.
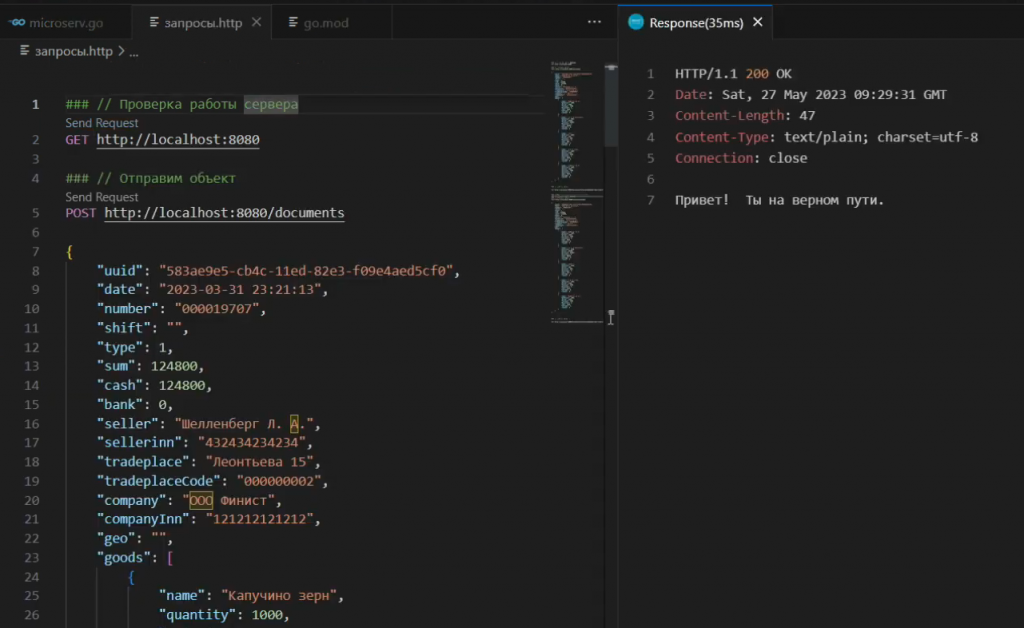
Приходит ответ: «Привет! Ты на верном пути»
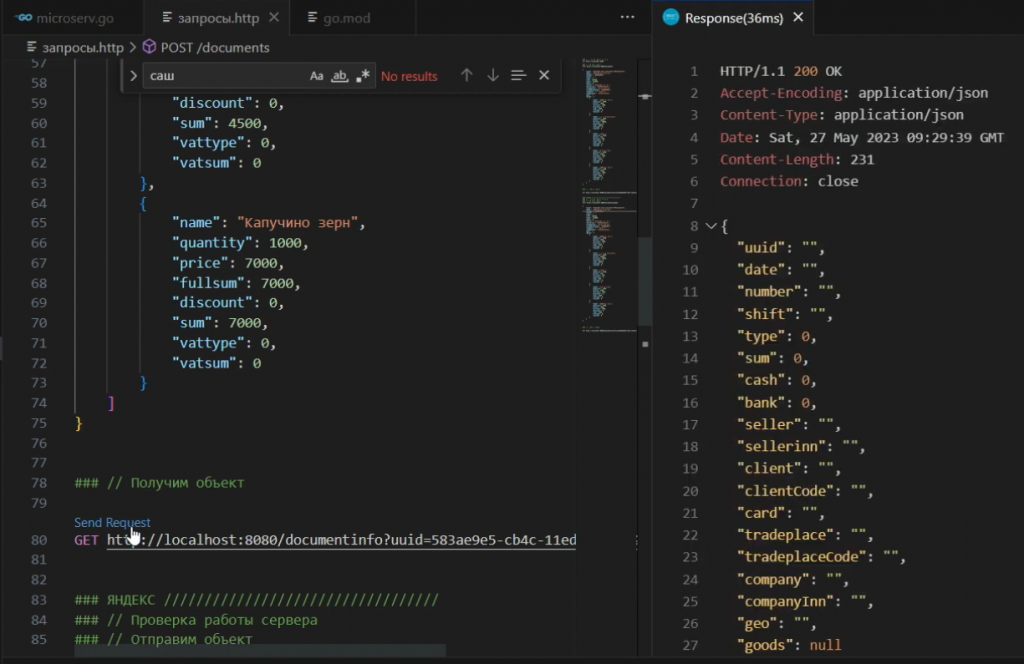
Давайте попробуем запросить чек по UUID – сервер сообщает, что данных по этому UUID в нашей базе пока нет.
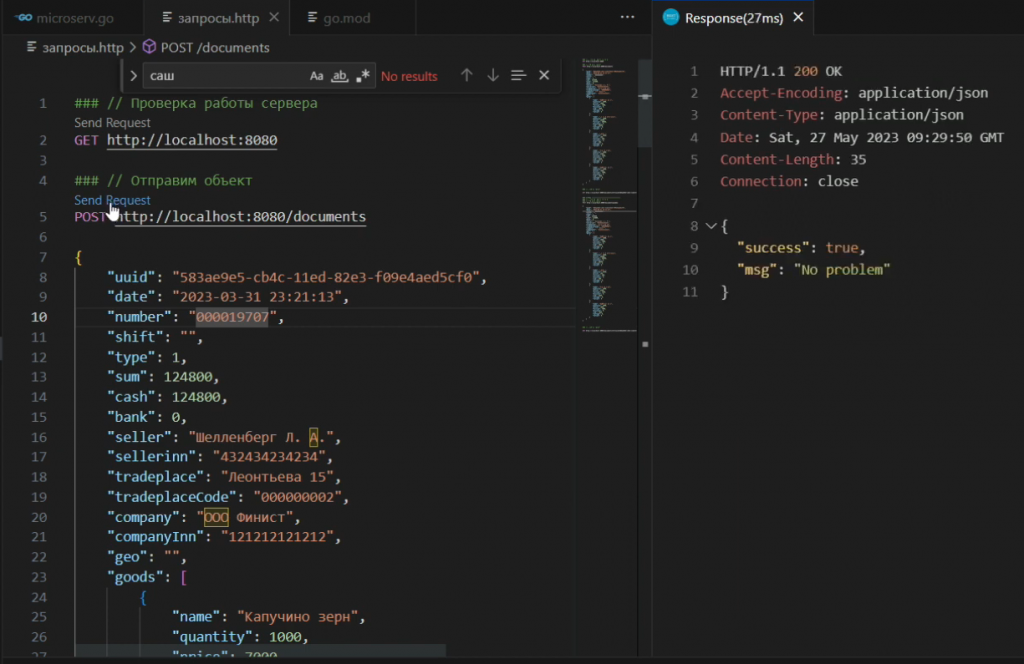
Попробуем отправить подготовленный массив с данными этого чека на сервер – система сообщает, что все в порядке, чек пришел.
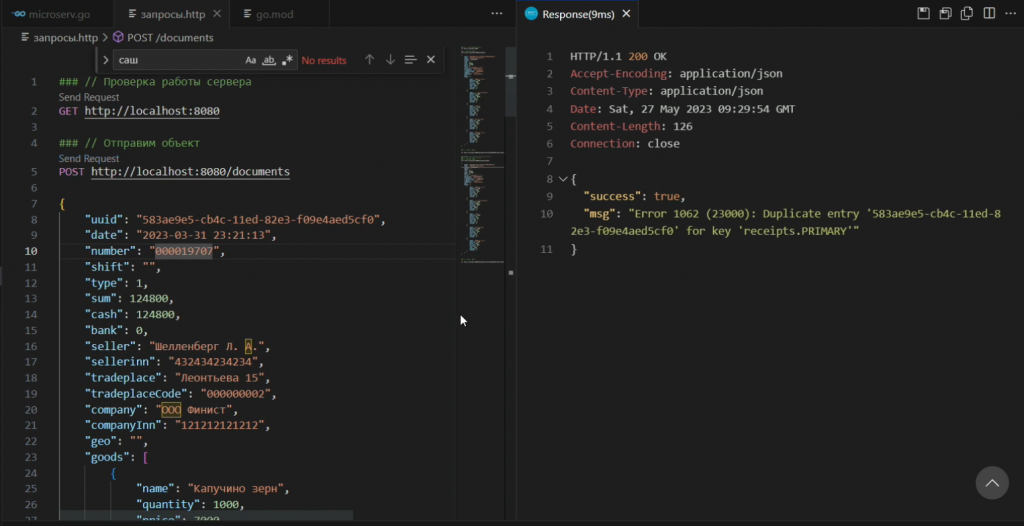
Причем если мы попытаемся отправить данные еще раз, программа выдаст ошибку, что такая запись уже существует.

И далее, когда мы запрашиваем этот чек по UUID, сервер уже возвращает нам о нем корректную информацию.
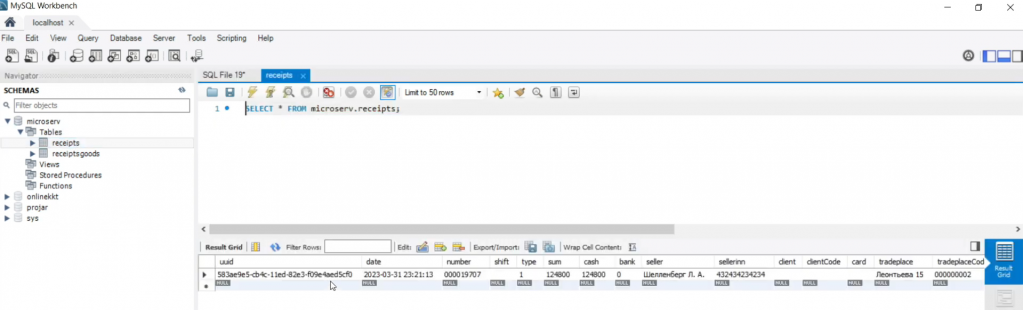
Проверим, что эти данные попали в базу. Как видите, в таблице receipts появилась запись по чеку.
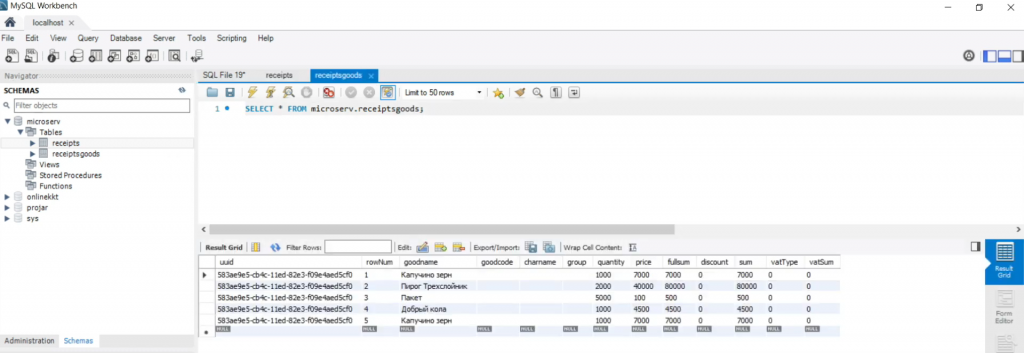
А в таблице receiptsgoods – записи товаров, которые были по этому чеку.
Поскольку мы не хотели перегружать основную инфраструктуру, у нас все это работает на недорогом виртуальном сервере (около 500-600 руб/мес) – эта архитектура не требует больших ресурсов.
Единственное требование – у этого виртуального сервера (VDS) должен быть открыт нужный порт (например, 8080 или тот, который вы указали в программе), иначе программа не сможет принимать соединения.
После этого достаточно будет проверить по IP что сервер доступен. Если приходит ответ «Вы на верном пути», все работает корректно.

Далее хочу показать вам функции, которые отвечают за прием и возврат чеков.

Рассмотрим код функции priemdoc, которая отвечает за прием документа:
-
Сначала проверяется, что запрос, который ее вызывает, имеет метод POST
-
Далее в запросе проверяется наличие токена определенного вида – если токен совпадает, данные попадают в базу. Если токен неверный, никакие данные не уходят. В первую очередь это сделано для защиты системы от неавторизованных запросов. И для того, чтобы разделить среду разработки и среду тестирования, так как иногда можно забыть поменять порт или IP и данные уйдут не туда, куда нужно.

-
Далее мы читаем содержимое пришедшего к нам запроса и превращаем его данные в структуру.
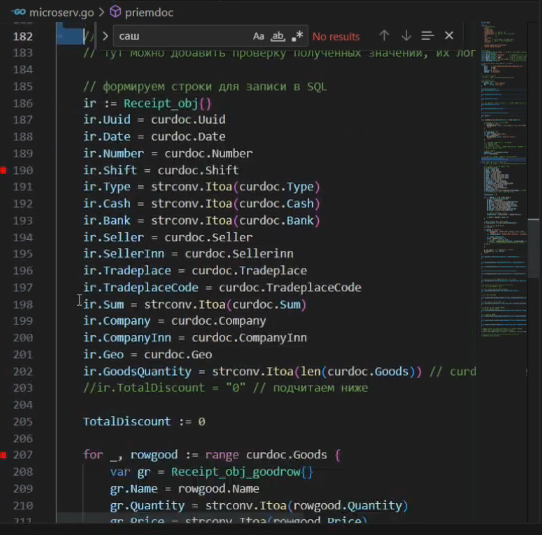
-
Обрабатываем эту структуру так, как необходимо.
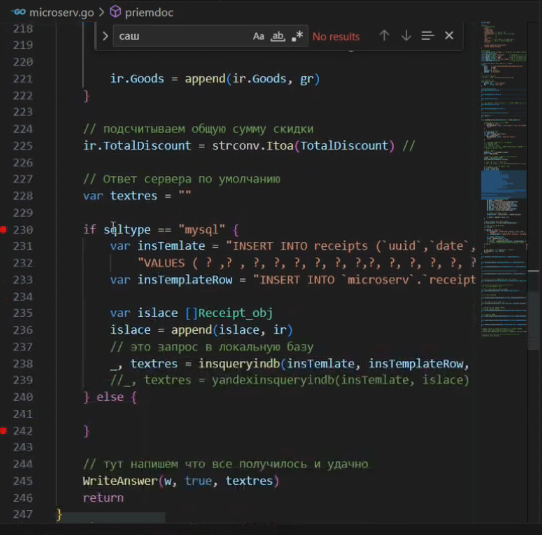
-
Готовим SQL-запрос и отправляем его в базу данных.
Как видите, это достаточно небольшая программа. Для ее написания, конечно, пришлось много изучать, но это того стоило.
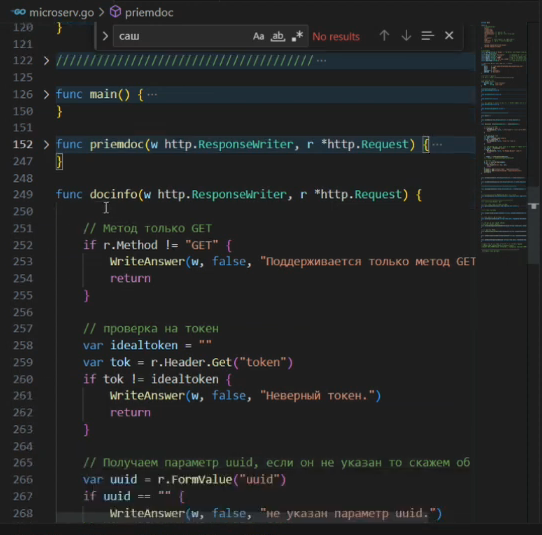
Для отправки информации все еще проще.
-
Мы также проверяем метод у запроса – но в данном случае запрос должен использовать метод GET.
-
Проверяем токен, чтобы никто лишний наши данные не смотрел.
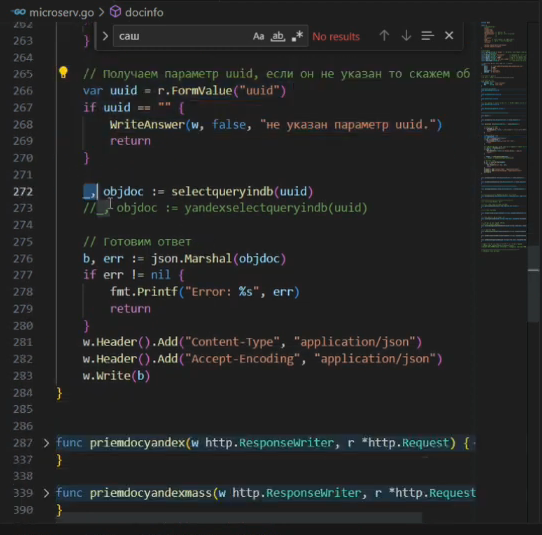
-
Проверяем, что в запросе есть параметр uuid.
-
Забираем SQL-запросом из базы данных этот чек и его товары.
-
И готовим ответ – упаковываем информацию по чеку в JSON.
Как видите, выдачу данных в этом микросервисе организуют всего лишь 50 строчек – это достаточно небольшой код, который доступен каждому.
Нужно подробнее детализировать данные... И выгрузить их в облако
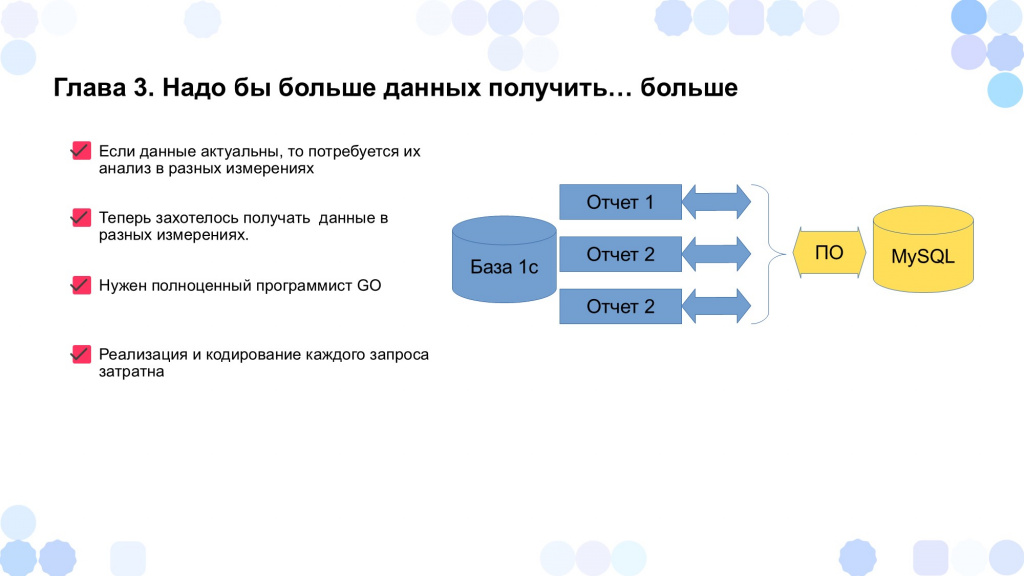
Казалось бы, все прекрасно – микросервис успешно принимает и отдает данные, и на этом его история могла бы закончиться. Но не тут-то было.
-
Когда в нашей базе MySQL накопилось большое количество чеков, мы поняли, что можем использовать эти данные для анализа и принятия управленческих решений. Например, узнать: В какое время совершается больше всего покупок? Какие товары продаются утром, а какие вечером? Какие товары продаются в будние дни, а какие – в выходные? Какой средний чек в определенные часы? Сколько продаж до 9 часов, а сколько после 9 часов? И так далее.
-
Чтобы микросервис мог делать нужные нам SQL-запросы в базу MySQL и выгружать итоговые таблицы для анализа в 1С, потребовалась его доработка. На этом этапе стало особенно тяжело, потому что проверка гипотез вроде: «Стоит ли открываться в 9 утра?» или «Какие товары продаются в разное время суток?» – порождала массу одноразовых отчётов. Их подготовка занимала много времени, а использовались они – максимум раз в месяц. Если учесть, что над доработкой микросервиса и отчетов работал, по сути, один человек, то постоянные переключения между стилями кодирования, проверка SQL-запросов, настройка логики вызывали путаницу и перегрузку.
-
Так возник логичный вопрос: а правильно ли всё время дорабатывать программу под каждый новый отчёт? Особенно если отчёт нужен один раз, а на его создание уходит много времени. Может, ресурсы программиста лучше направить на более приоритетные задачи?
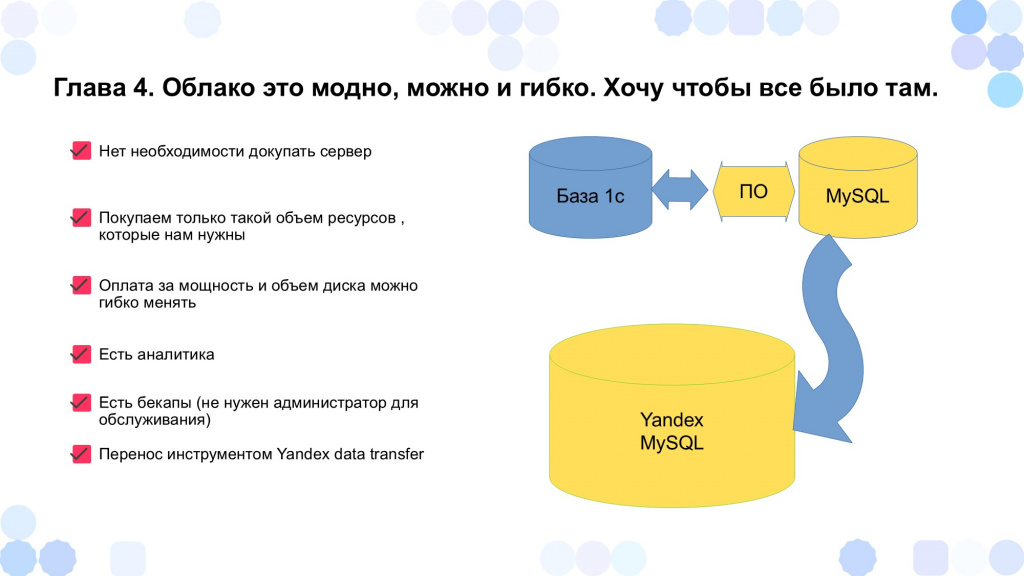
Параллельно возникла ещё одна проблема.
-
Изначально наша система работала на выделенном виртуальном сервере с объёмом диска около 60 ГБ, где хранилась база и ее бэкапы. Но когда объем базы достиг 40 ГБ, делать бэкапы уже стало проблемой, потому что под их хранение тоже нужно выделить достаточное количество места. Стало понятно: нужно переходить на более мощную инфраструктуру.
-
Так появилась идея перейти на Яндекс.Облако. Платформа предоставляет готовый кластер MySQL, где можно не только хранить данные, но и автоматически создавать резервные копии и при необходимости масштабироваться.
-
Например, когда в конце месяца требуются новые отчеты, можно временно докупить ресурсы, а потом снова перейти на более экономичный тариф. А если заканчивается место – просто докупить жесткий диск и работать дальше безо всяких проблем.
-
При этом нам не надо никого напрягать – все управляется через интерфейс, без участия системных администраторов. Просто передвигаешь ползунок – и у тебя больше места или ресурсов.
-
Единственная проблема – было непонятно, как перенести данные из нашей базы, размещенной на виртуальном сервере, в Яндекс.Облако. Здесь нам помог инструмент Yandex Data Transfer. Это простой и удобный сервис, позволяющий копировать базы данных между серверами – достаточно только настроить эндпоинты (источник и приемник).
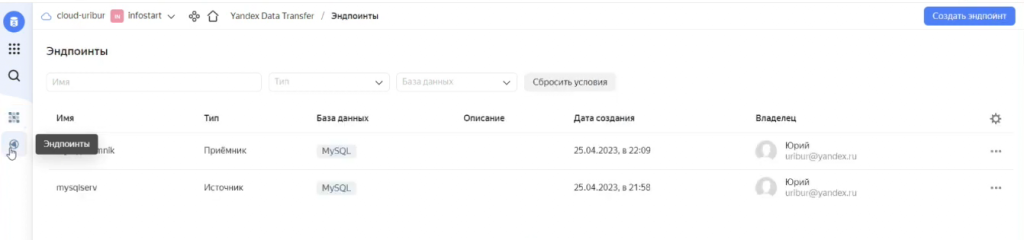
Давайте я покажу, как выглядит настройка источника и приемника в Yandex Data Transfer.
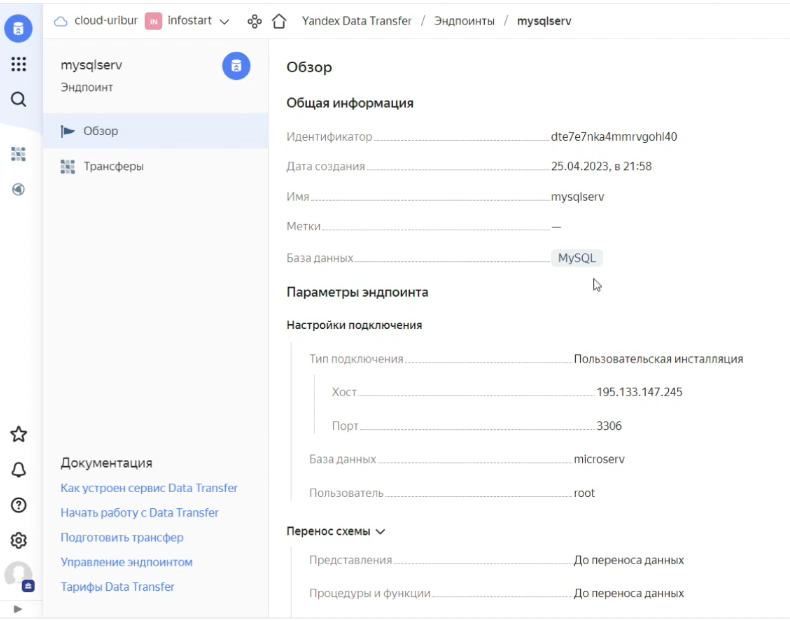
В качестве источника указываем базу данных, которая находится на нашем виртуальном выделенном сервере. Указываем ее внешний IP-адрес и порт, а также открываем доступ к этому порту, чтобы он смотрел во внешнюю среду. И предоставляем пользователю права, чтобы он мог входить в базу данных не только с локального компьютера, но и с внешнего.

Далее мы настраиваем приемник – это база данных MySQL, которая уже находится в Яндекс.Облаке. Указываем кластер, базу данных, логин и пароль.

После этого трансфер переносит все эти данные автоматически.
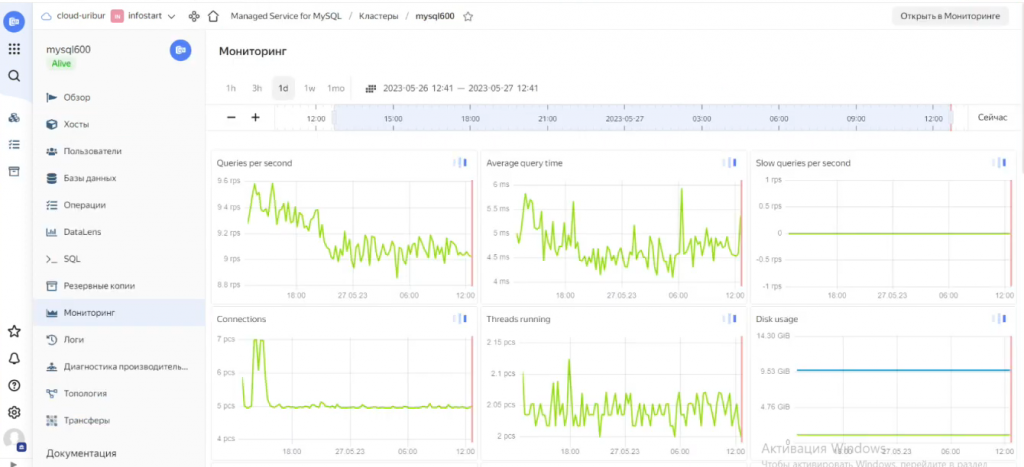
В результате мы получили не только стабильное и надёжное хранилище, но и возможность отслеживать метрики: объём базы, частоту запросов, нагрузку и т.д.

До определенного момента эти данные переносились с нашего сервера VDS через инструмент Yandex Data Transfer, но со временем мы задались новым вопросом – а зачем нам промежуточный шаг через виртуальный сервер? Почему бы не отправлять данные из 1С сразу в облако?
В результате мы переписали программу, чтобы она взаимодействовала с Яндекс.Облаком напрямую:
-
больше не нужно было использовать виртуальный сервер;
-
можно было работать с этими данными сразу в Яндекс.Облаке без всяких промежуточных выгрузок.
Метрики, о которых говорилось выше, стали ещё ценнее: мы могли видеть, как часто обращаются к данным, насколько загружена база, хватает ли ресурсов и пр. – и весь этот огромнейший спектр информации мы получили без привлечения каких-либо технических специалистов.
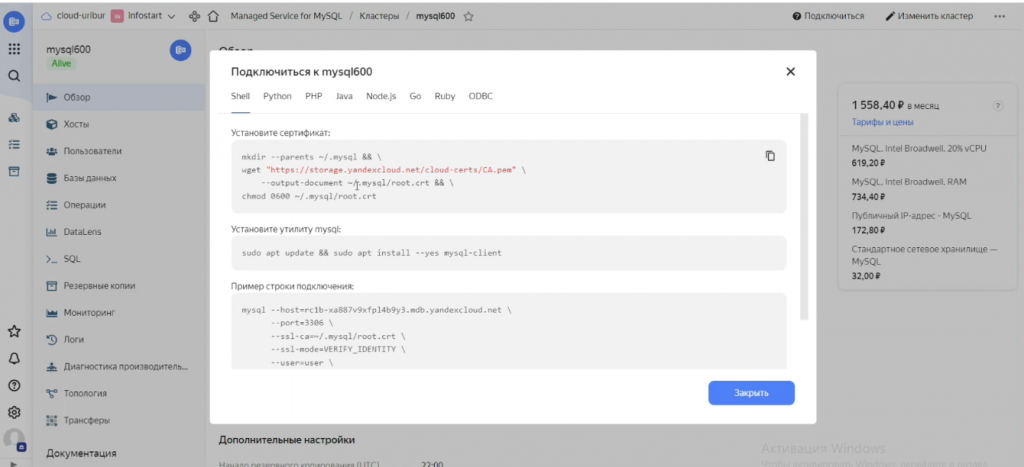
Обратите внимание, каким образом можно подключиться к базе MySQL в Яндекс.Облаке. Справа наверху здесь есть кнопочка «Подключиться», где сразу доступны готовые примеры подключения на разных языках: Shell, Python, PHP, Java, Node.js, Go, Ruby и ODBC. Т.е. даже если у вас нет особых технических знаний, нажав на определенную вкладку, вы уже получаете код, который позволяет вам подключиться к этой базе данных и взаимодействовать с ней. А дальнейшую логику уже дорабатывать на стороне своей программы.
А для анализа в облаке использовать Yandex DataLens

После того как мы перенесли базу нашего микросервиса с виртуального сервера в облако, мы обнаружили, что в Яндекс.Облаке есть шикарный инструмент – Yandex DataLens. Это простой и интуитивный сервис, который позволяет подключиться к вашей базе данных и строить отчёты через визуальный интерфейс без написания кода.
Когда мы начали использовать DataLens, ситуация изменилась кардинально.
-
Ранее у нас было ограничение по времени и ресурсам: 11 программистов не успевали готовить все необходимые отчёты. А благодаря DataLens, аналитик с минимальными техническими знаниями может строить отчёты сам, не привлекая программистов.
-
Более того, отчёты создаются «на лету» – сразу видно результат, и можно оперативно вносить правки.
-
Еще один из важных плюсов DataLens – дашборды. Их можно настраивать под разные роли: руководству – итоговые показатели, отделу продаж – наиболее продаваемые товары, маркетингу – как влияют их активности на объем продаж и т.д. Это позволяет создать индивидуальные рабочие пространства на основе одной и той же базы данных.
-
При необходимости можно доработать детальность выгружаемой из 1С информации и отправлять в облако дополнительные данные, расширяя возможности аналитики.

Теперь давайте посмотрим, как анализировать данные в DataLens.
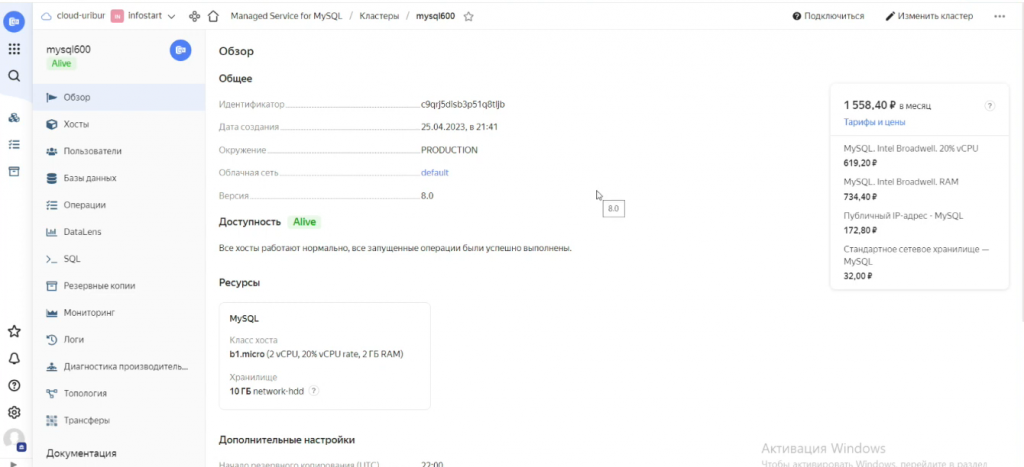
Я заранее подготовил базу данных, на которой мы сейчас протестируем эту работу. Сейчас здесь используется разработческий кластер с производительностью CPU 20%, что обходится примерно в 1500 рублей в месяц. Он работает не очень быстро, поэтому возможны задержки в отклике. В базе содержится около 42 тысяч чеков и порядка 150 наименований товаров.

Теперь перейдем к DataLens. При запуске интерфейса мы видим четыре основные кнопки для работы: подключения, датасеты, чарты и дашборды.

Первым делом необходимо указать подключение к источнику. Это может быть как файл, так и база данных, например, MySQL, как в нашем случае.

Если база находится в Яндекс.Облаке, достаточно выбрать нужный каталог, и система предложит доступные подключения. Все довольно просто – пара кликов.
Обратите внимание, что здесь есть настройка уровня доступа к SQL-запросам – можно разрешить либо запретить. Здесь нужно выбрать «Разрешить подзапросы в датасетах и запросы из чартов», я позже объясню, почему.
После настройки подключения переходим к созданию датасетов. Датасет – это набор данных, которые мы будем анализировать, обычно одна или несколько связанных таблиц.
У меня подготовлены два датасета:
-
список чеков с информацией о точке продаж, сумме, продавце и так далее,
-
и список товаров с чеками.
По факту, это просто вывод данных из тех таблиц MySQL, которые мы создавали ранее.
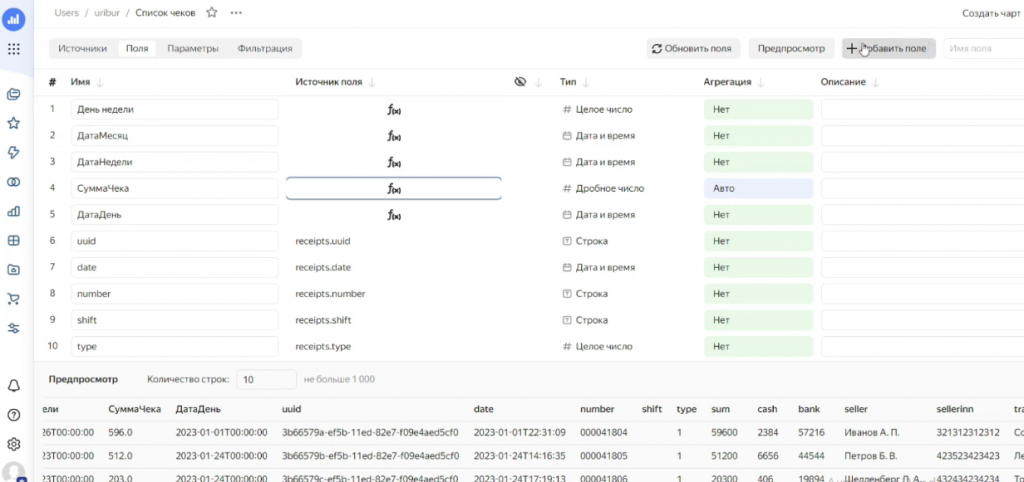
Стоит учитывать, что в некоторых случаях нам в датасете необходимы дополнительные поля. Например, если чеки зафиксированы по секундам, а нам нужно разбить их по месяцам, по дням недели и т.д., можно добавить отдельные группировочные поля.
Кроме того, обратите внимание, что значения суммы здесь хранятся в копейках (у них тип данных int).

Чтобы привести их к привычному виду, нужно создать отдельное поле СуммаЧека, где разделить сумму на 100.

В зависимости от того, какой анализ планируется, необходимо заранее подготовить нужные поля. Настройка дополнительных полей достаточно простая – вы можете использовать агрегатные функции (среднее, максимум), логические или математические операции.
Например, выбираем функцию DATETRUNC, смотрим подсказку и задаем, до какого уровня нужно округлить дату – до часа, дня и т.д. Добавим поле «Час продажи», округлив дату до часа – и оно сразу появляется в наборе данных.
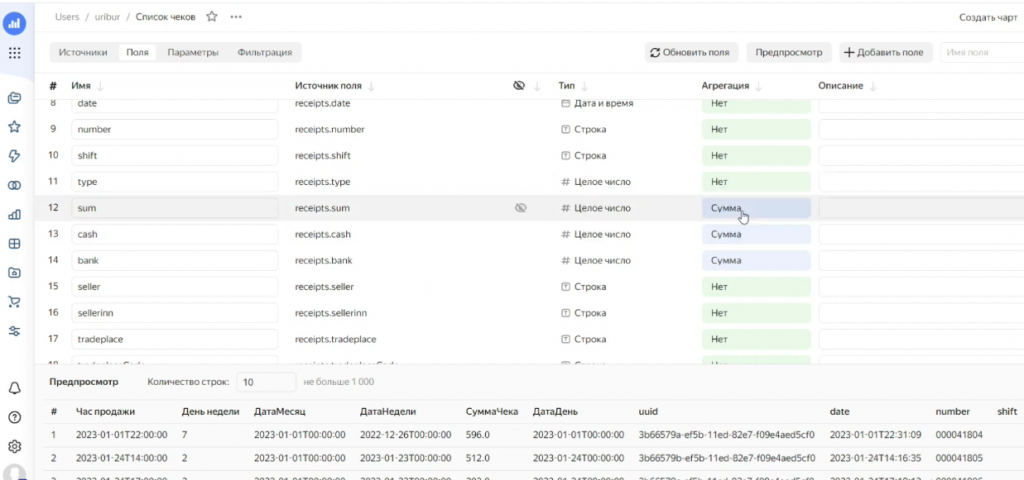
Далее можно просмотреть все поля и указать, какие из них являются агрегатными, а какие просто аналитикой.
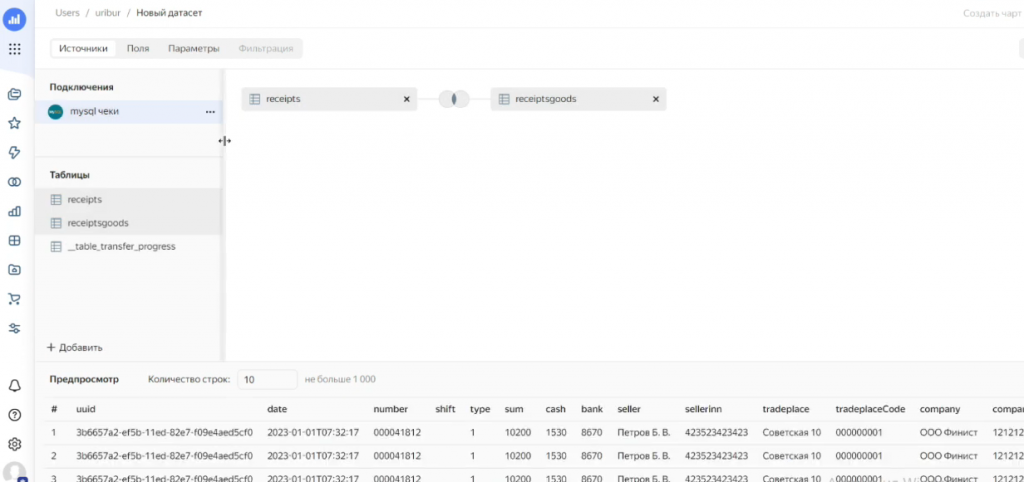
Для примера покажу, как создается датасет из двух таблиц. Создаем новый датасет: выбираем нужное подключение, открываем базу данных и видим список таблиц – у нас есть таблица чеков и таблица товаров по чекам.
При простом перетаскивании табличек в область источников данных датасета система автоматически пытается их связать. Однако часто она делает это неправильно, например, она может попытаться связать их по сумме – что, конечно, нам не подходит.
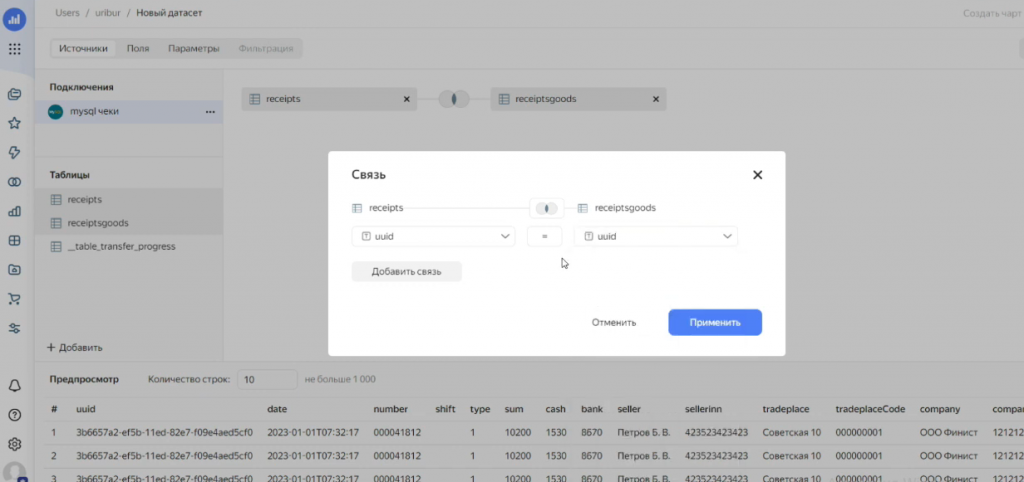
Мы вручную указываем для связи правильное поле – в данном случае UUID – и сохраняем эту связь.
DataLens сразу показывает пример объединенной таблицы – можно визуально проверить корректность связи.
В этот датасет можно подключить и другие таблицы, например, «Сотрудники» или «Организации» – по тем же идентификаторам. Это важно, поскольку в основной таблице могут быть только текстовые имена продавцов и товаров, а это не всегда удобно для масштабной аналитики.
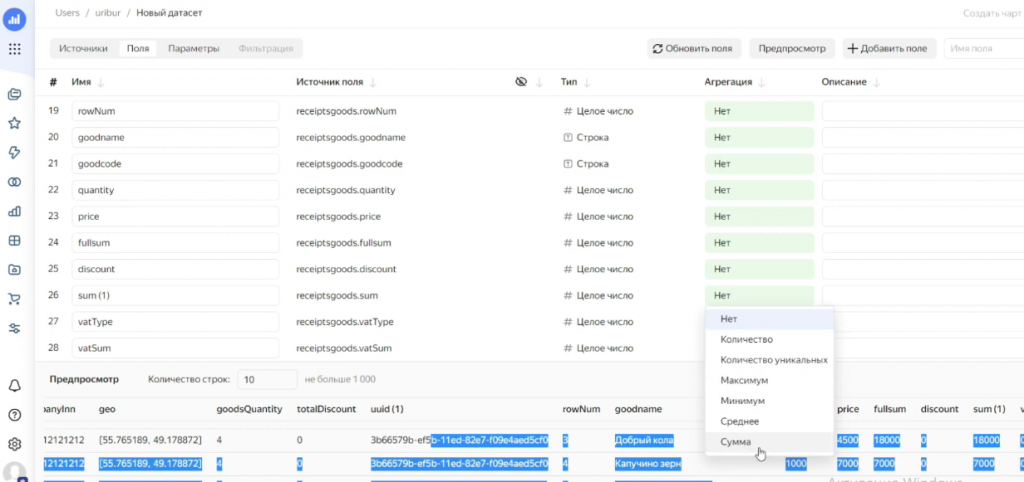
После объединения таблиц мы продолжаем работать с полями: указываем, какие из них агрегируются, какие нет. Здесь принцип работы примерно такой же, как на СКД – для программиста все достаточно понятно.
И при необходимости можно добавить новые вычисляемые поля.
К каждому датасету можно добавить определенные параметры и фильтрацию. Например, если вы хотите ограничить датасет определенными торговыми точками или определенными товарами, вы создаете отдельный датасет с нужными ограничениями – он и будет использоваться для визуализации.
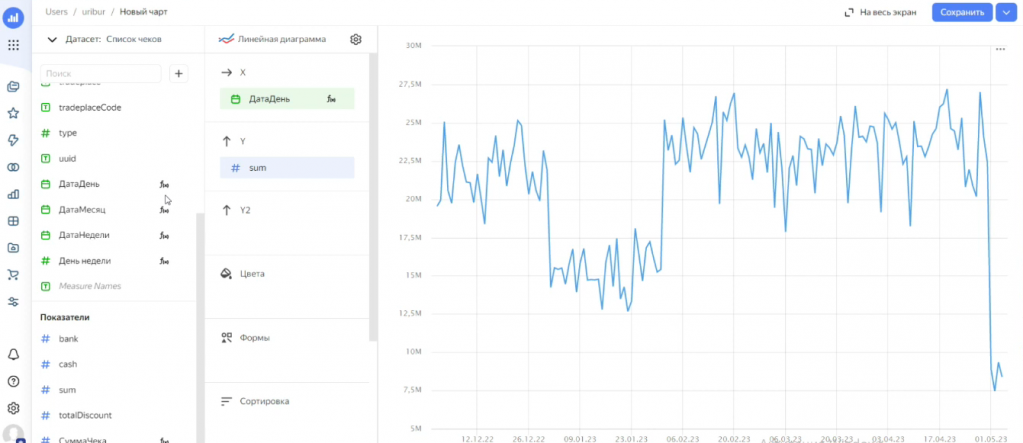
Следующий этап – создание чартов (графиков). Это может быть таблица, диаграмма или другие визуализации. Все просто: выбираете нужный датасет и тип графика. Например, можно построить линейную диаграмму по продажам на каждый день. Указываем сумму в качестве оси Y, и поле «ДатаДень» в качестве оси X – и DataLens сразу формирует график.
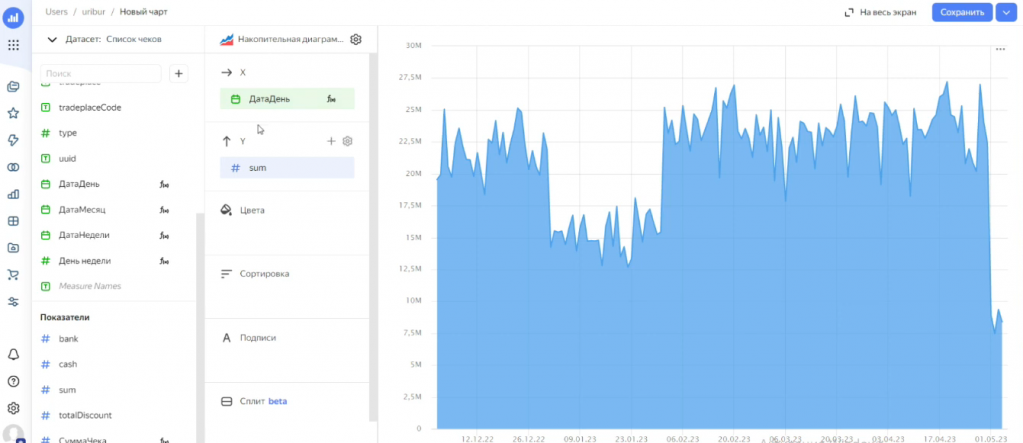
Если хочется другой тип графика – например, накопительную диаграмму – можно поменять.
В датасете есть поля, которые агрегируются (показатели), и есть поля, которые являются измерениями (аналитикой) – по ним показатели можно красиво детализировать.
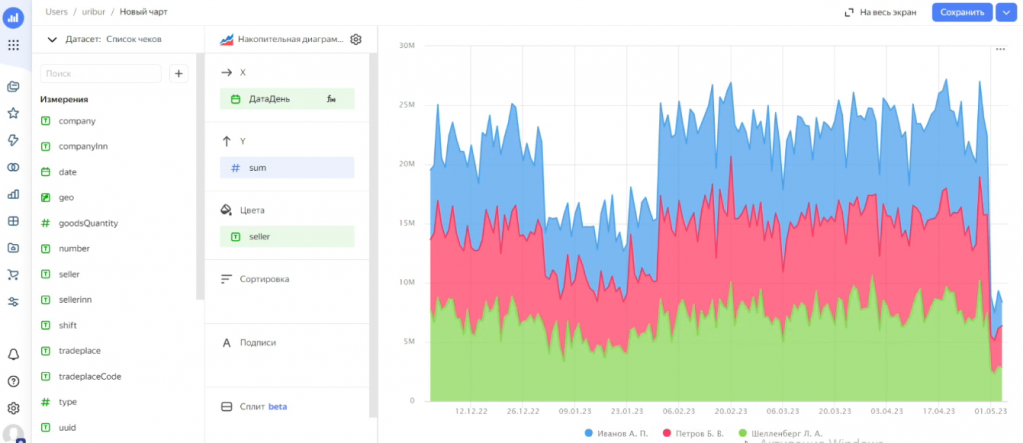
Можно использовать цветовую сегментацию – добавить в секции «Цвета» поле seller (продавец).
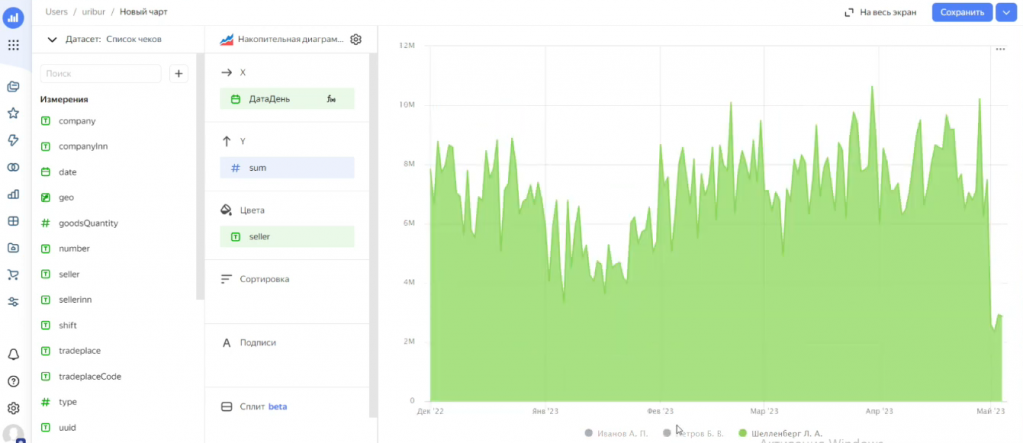
Можно интерактивно работать с графиками – это одно из ключевых преимуществ DataLens. Вы можете прямо в интерфейсе выделять интересующие вас сегменты, настраивать фильтрацию и сравнение без привлечения программистов. Доступна интерактивная фильтрация – например, можно управлять отображением данных, устанавливая фильтр по конкретному продавцу прямо в чарте.
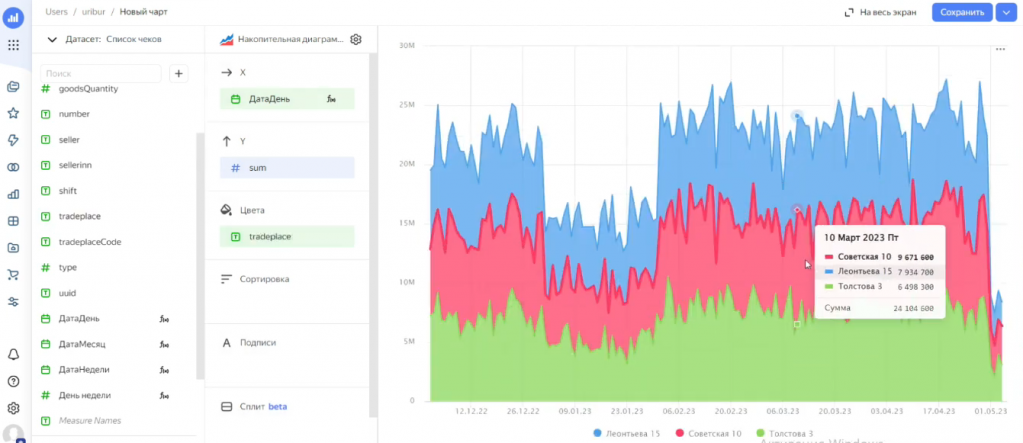
Если хочется посмотреть продажи по торговым точкам – меняем поле в секции «Цвета».
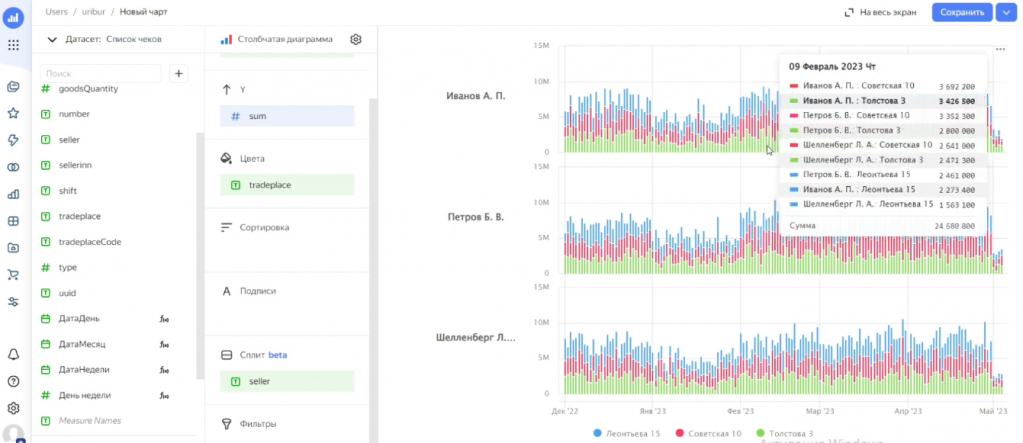
Также можно использовать функцию сплита. Сплит – это разбиение одного графика на несколько по выбранному признаку, например, по продавцу. В результате видим, как каждый продавец работал по точкам на разные дни.

Вариантов визуализации очень много. Если вы знаете встроенный язык выражений или хорошо ориентируетесь в формулах Excel, то можете создавать сравнительные графики или графики с временным смещением – например, текущие продажи рядом с показателем продаж месяц назад.
Таким образом на основании одной базы данных можно сформировать произвольный набор абсолютно различных графиков, которые позволяют оперативно оценивать текущую ситуацию. Причем руководителю не нужно ни у кого запрашивать этот отчет – ему достаточно просто перейти по ссылке и сразу все увидеть.
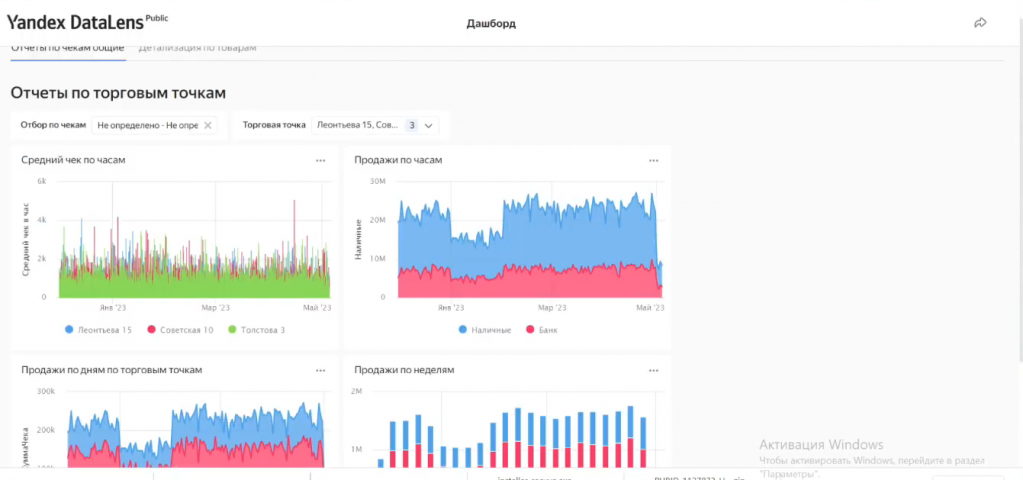
Когда мы уже подготовили датасеты и чарты, переходим к дашбордам. Дашборд – это совокупность созданных чартов, объединенных в единое пространство.

Их можно удобно группировать, добавлять заголовки, текстовые блоки, переключатели и вкладки – например, я здесь разделил визуализации для двух датасетов по различным вкладкам.
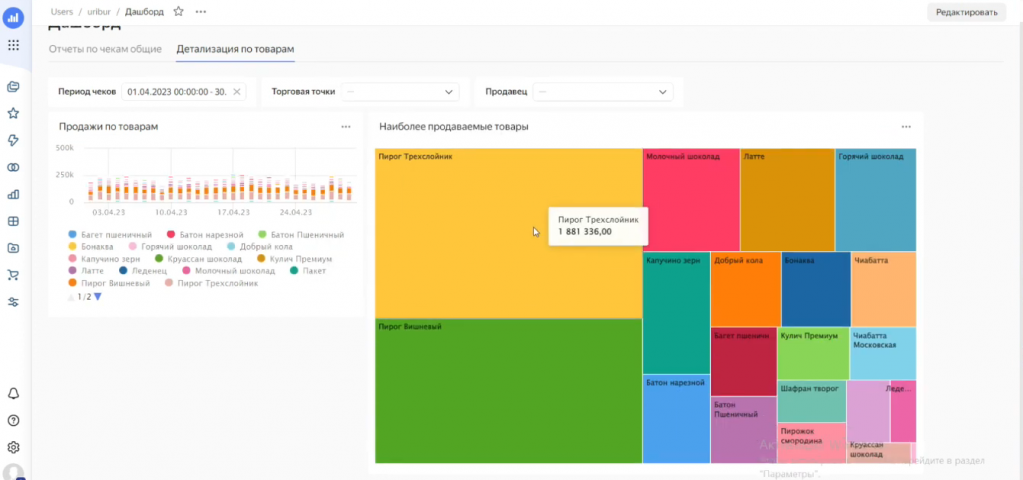
Можно настроить привязку каждого селектора (фильтра) к конкретному графику или оставить их общими – например, здесь я выбрал в селекторе апрель, и система отобразила данные только за этот период.

DataLens также позволяет анализировать производительность отчетов – можно посмотреть, как долго загружаются данные, и на основе этого оптимизировать структуру запросов или базы данных. В частности, если отчеты «тяжёлые», имеет смысл добавить индексы через Workbench или пересмотреть архитектуру таблиц.
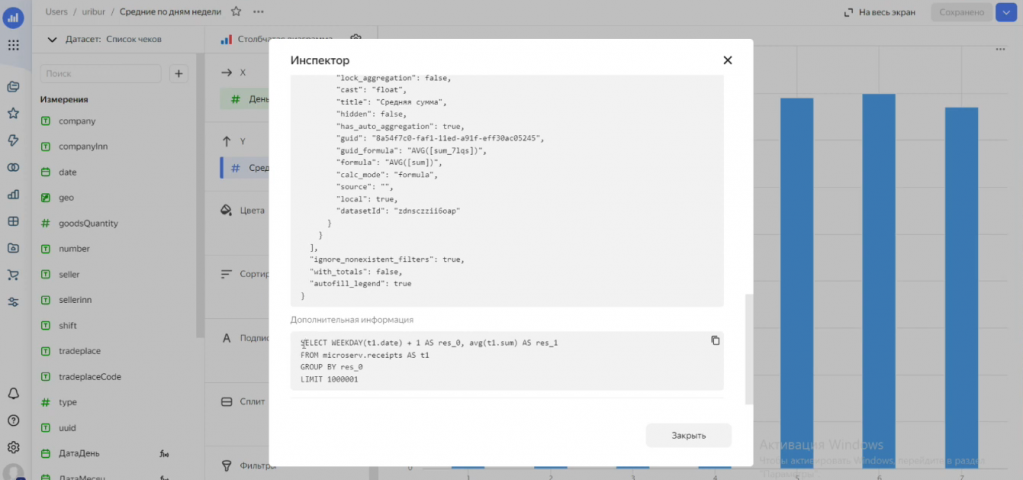
Вы можете раскрыть данные в инспекторе и посмотреть, какой SQL-запрос формирует система к вашей базе данных – разобрать его, повторить и подумать, можно ли изменить структуру базы так, чтобы он выполнялся быстрее.
Архитектура для построения отчетов и дашбордов без участия разработчиков. Нюансы
В целом, DataLens – это простой и доступный инструмент для аналитиков. Он позволяет формировать полноценные отчеты и дашборды без участия разработчиков. В моем опыте это сильно сократило нагрузку на программистов и ускорило принятие решений.
Более того, в процессе работы часто происходило выявление новых значимых показателей. С помощью визуального анализа можно было быстро подтвердить гипотезы и понять, какие данные действительно важны. Это дало основания для разработки дополнительных отчетов и сбора новых данных. Некоторые показатели, ранее не отслеживаемые, начали фиксироваться и использоваться для оперативного мониторинга и выявления проблем на торговых точках.
Такой подход стал более обоснованным: отчеты создавались не «на всякий случай», а на основе анализа и фактов. Аналитики получали инструменты для аргументированной приоритизации – какие отчеты важнее, какие данные действительно влияют на бизнес-процессы.

При этом есть несколько важных нюансов, которые следует учитывать.
-
В нашем случае данные отправлялись из одной программы, однако в более сложных системах данные могут отправлять несколько источников. И здесь уже необходимо заранее проанализировать, как поведёт себя система при массовой одновременной выгрузке данных от нескольких соединений: не возникнут ли конфликты, не начнётся ли перегрузка, и справится ли база данных с таким потоком.
-
Также важно учесть безопасность паролей и использование сертификатов шифрования для сервера. В нашем случае речь шла о малом и среднем бизнесе, где данные не представляли особой ценности, поэтому мы подходили к вопросам безопасности довольно просто. Но в случае работы с корпоративными клиентами на это нужно обратить серьезное внимание.
-
Также важно помнить о производительности. На начальном этапе у нас была относительно простая таблица в MySQL, и все работало быстро. Но со временем, когда объем данных значительно вырос, некоторые отчеты стали строиться медленно. Поэтому под каждый отчет нужно анализировать структуру MySQL – насколько эффективно он собирается. И если отчет используется регулярно – оптимизировать его выполнение: добавлять индексы, переписывать SQL-запросы, улучшать структуру таблиц.
Вопросы и ответы
Вы давали прямые ссылки на дашборды или встраивали их в имеющиеся личные кабинеты?
Мы либо размещали дашборды в открытом доступе, чтобы их мог видеть каждый. Например, наш руководитель публиковал по ссылке специальный дашборд с информацией о потребностях в сырье, чтобы потенциальные поставщики, которые хотят поставлять нам этот ресурс, могли с нами связаться.
Либо мы предоставляли доступ конкретным пользователям вручную. У каждого ответственного руководителя был свой аккаунт в Яндекс.Облаке и через него предоставлялся доступ к нужным дашбордам.
Вы сказали, что у вас в демонстрационной базе MySQL 42 тысяч записей. А насколько объем данных влияет на скорость вывода на дашборды? Как это будет работать, если объемы доходят до сотен миллионов записей?
В данном случае мы формируем датасет в BI-системе просто через запрос в MySQL. Но я согласен, что с большими объемами MySQL может не справиться – тогда эти данные нужно либо заранее агрегировать в отдельную таблицу, либо переходить на ClickHouse – он для таких ситуаций, наверное, больше подходит.
Наша история происходила в небольшой компании (малый, средний бизнес), у которой ресурсы – это Яндекс и небольшая программа на Go.
Вы забирали информацию для дашбордов из регистров накопления? Можно ли использовать в качестве источника журнал бухгалтерских проводок? У нас госучреждение, и много информации собрано именно в бухгалтерии.
В нашем случае мы забирали из базы 1С просто документы чеков. Они не были связаны ни с какими регистрами накопления, ни с какими регистрами сведений – мы могли их просто выбросить из базы и удалить. Мы выгружали их из системы, удаляли и при необходимости загружали заново.
В случае, если вы просто хотите что-то анализировать, вы можете сформировать в 1С таблицу с нужными вам данными и выгружать ее в BI.
Но здесь есть нюанс – в нашем случае у каждого чека был свой уникальный UUID и при повторной отправке мы могли контролировать отсутствие дублирования данных по UUID.
В вашем случае, наверное, тоже надо что-то придумать, чтобы каждая запись гарантированно была уникальной. Например, агрегировать данные в каком-то документе и в привязке к этому документу пробрасывать их в таблицу. И затем, если в этом документе что-то поменялось, эти данные удалять и переписывать заново. Наверное, так.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Анализ & Управление в ИТ-проектах.
