Благодаря стремительному развитию ИТ, оно проникает во все сферы нашей жизни. Ежедневно появляются новые системы и сервисы, существующие становятся все сложнее и умнее – для их работы требуется все больше серверного оборудования и вычислительных мощностей. Эффективное управление такими ресурсами играет важную роль в эксплуатации этих решений.
Расскажу об опыте нашей компании BIA Technologies по созданию решения для управления виртуальными ресурсами и управлению инфраструктурой: как мы шли к этой идее, к чему пришли, с чем столкнулись, и что у нас на данный момент получилось.

По мере роста компании и увеличения числа проектов – как внутренних, так и клиентских – у нас значительно возросла потребность в серверных мощностях.
А поскольку мы, как и многие другие, активно используем виртуальные ресурсы – как в приватных облаках, созданных на собственном железе под управлением различных систем виртуализации, так и у сторонних облачных провайдеров – то в процессе работы мы столкнулись с рядом сложностей, которые требовали решения.
-
Мы четко понимали общие затраты на серверное оборудование, но у нас возникали сложности с тем, чтобы распределить эти затраты по конкретным ЦФО.
-
Ежегодное бюджетирование и планирование расходов на оборудование осложнялось отсутствием точной информации о потреблении ресурсов – мы не понимали, сколько необходимо дополнительно приобрести с учетом тех проектов, которые еще не стартовали, но будут выполняться в следующем году.
-
Информация из разных систем виртуализации и инструментов наших провайдеров предоставлялась в различном формате, поэтому для сбора, преобразования и агрегации этих данных приходилось прикладывать немало усилий. Например, чтобы получить сводный отчет, приходилось запрашивать данные у специалистов отдела ЦОД, но коллеги не всегда могли оперативно ее предоставить, ведь предоставление отчетов все-таки не является их основной функцией.
-
Помимо этого, все инструменты имеют свои пользовательские интерфейсы, у них различные возможности, различные API, что тоже не добавляет простоты в их использовании.
-
Нередко возникали ситуации, когда проект переходил из стадии разработки в промышленную эксплуатацию, а тестовые и разработческие сервера для него продолжали работать просто потому, что о них забыли. Эти «забытые» ресурсы потребляли электричество и занимали мощности, что для нас тоже было неприемлемо.
-
Кроме того, мы хотели сократить количество обращений в различные сервисные департаменты для выполнения таких простых операций, как развертывание стандартизированных серверов в рамках проекта, с учетом тех ресурсов, которые были выделены под проект.
Проанализировав эти и другие нюансы, мы пришли к выводу, что нам необходим инструмент, способный решить все или часть этих проблем.
Сначала мы решили поискать готовый продукт – потому что прежде, чем начинать свою разработку, всегда имеет смысл проверить, не существует ли под эту задачу уже готовое решение на рынке. Однако наши поиски не увенчались успехом.
-
Продукты, которые мы проанализировали, либо поддерживали работу лишь с одной-двумя популярными системами виртуализации, не предусматривая возможности кастомизации – для них нужно было заказывать доработку, а это дорого, долго и неинтересно.
-
Либо представляли собой инструменты для построения собственного облачного провайдера – а это не являлось нашей целью.
Поэтому мы решили попробовать разработать что-то свое.
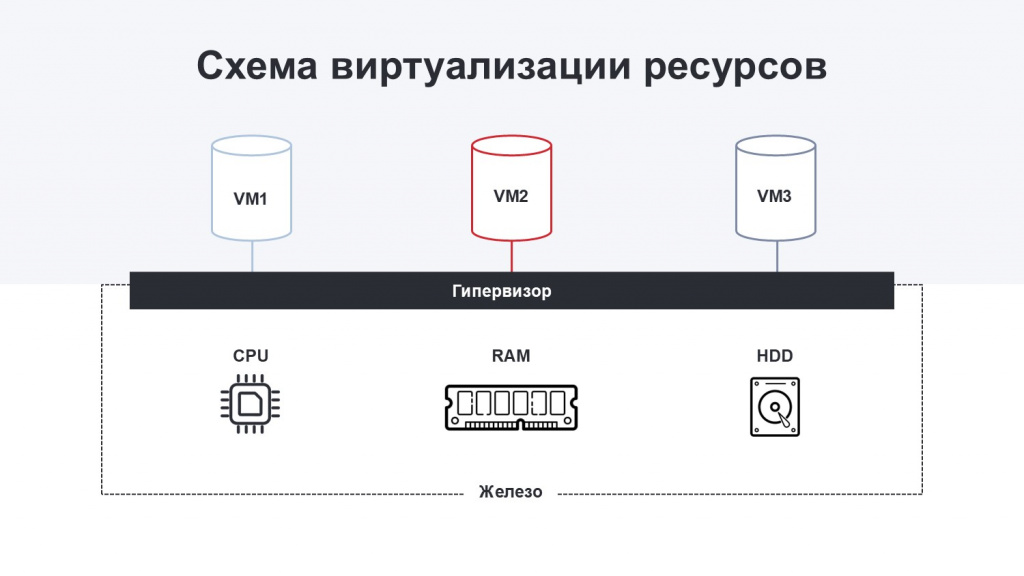
Сделаю небольшое отступление, чтобы пояснить, что именно мы понимаем под виртуализацией.
Виртуализация – это технология, при которой физические сервера управляются специальным программным обеспечением, гипервизором.
Если очень сильно упростить, гипервизоры бывают двух видов.
-
те, которые работают напрямую на «голом» железе и имеют лишь минимальную сервисную операционную систему;
-
и те, которые устанавливаются поверх существующей операционной системы на хостовом железе.
Через собственные API гипервизор предоставляет возможность создавать виртуальные машины, выделяя им необходимое количество вычислительных ресурсов.
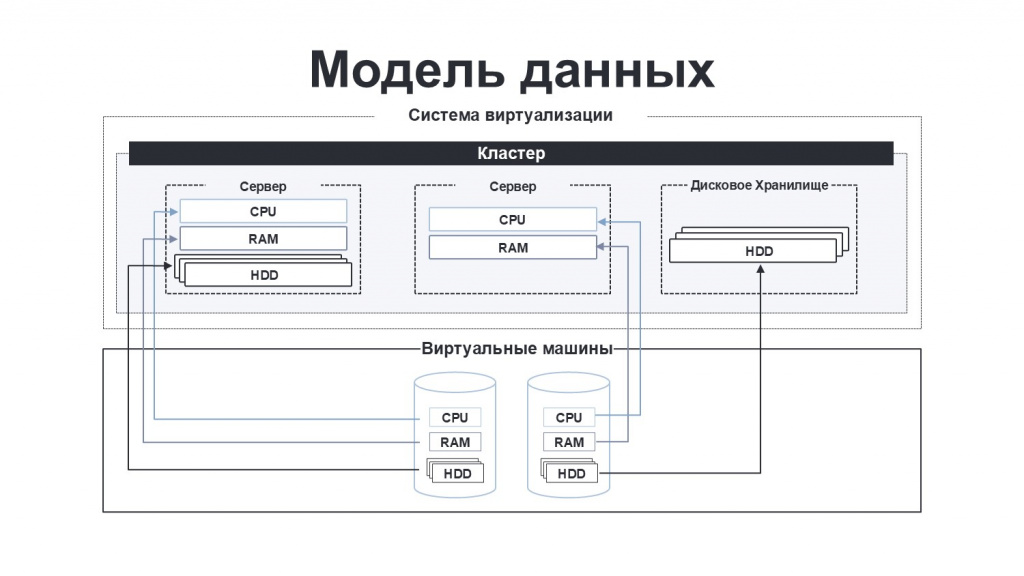
Так как все сразу объять невозможно, мы решили пойти постепенно и начали смотреть на имеющиеся в нашем управлении приватные облака – на тот момент они работали под управлением систем виртуализации VMWare (версии 5 и 6) и Nutanix.
Мы детально изучили, какие логические компоненты предоставляют эти платформы, и на основе этого сформулировали свое представление о модели данных. Например, в каждой системе виртуализации существует понятие виртуального кластера – в такой кластер объединяются физические сервера и их ресурсы, которые затем распределяются уже между виртуальными машинами. При этом физические серверы могут сильно различаться по характеристикам предоставляемых ресурсов:
-
дисковые хранилища (полки) могут предоставлять только дисковое пространство;
-
некоторые серверы предоставляют только процессорные ядра и оперативную память;
-
другие серверы могут дополнительно предоставлять видеокарты и так далее.
Мы для себя выделили три ключевых ресурса – память, процессор и дисковое пространство – и на основе этой модели разработали собственную модель ценообразования:
-
Для каждого из этих трех ресурсов задается тариф.
-
А далее в зависимости от специфики инфраструктуры или проекта эти тарифы можно будет иерархически переопределять – на уровне кластера, сервера или виртуальной машины
Это было необходимо, потому что физические серверы значительно отличаются между собой по параметрам ресурсов:
-
процессоры могут иметь разные тактовые частоты;
-
память может отличаться по скорости и типу;
-
диски могут отличаться по производительности и типу (SSD, HDD и т.д.);
-
ЦОД может находиться географически далеко от места его конечного применения, что влияет на его сетевую доступность;
-
или просто есть особенности ведения проекта и взаимоотношений с конкретным клиентом.
Еще одно лирическое отступление. Важно понимать, что виртуальный кластер не всегда напрямую связан с физическими ресурсами. Такая связь возможна только в случае собственных облаков, когда наши специалисты физически подключают сервер к гипервизору и определяют, какие ресурсы будут доступны для виртуальных машин. При этом некоторые ресурсы сервера могут быть недоступны для передачи на уровень виртуальных машин, поскольку они необходимы для работы самого гипервизора на хосте.
Если же речь идет о ресурсах, предоставляемых облачным провайдером, то, естественно, у нас нет никакой информации о физическом сервере, на котором размещены виртуальные машины. В этом случае все ресурсы отражаются напрямую на уровень виртуального кластера.
В процессе жизни виртуальной машины ее параметры могут меняться:
-
увеличивается объем памяти или количество ядер процессора;
-
добавляются новые диски;
-
выполняется миграция на другой физический сервер.
Поэтому мы также заложили в модель хранения данных возможность фиксировать текущее состояние каждой виртуальной машины и хранить историю изменения доступных для каждой машины ресурсов.
Разработка MVP
Взяв такой первый набор собранной информации, мы решили запустить небольшой MVP-проект, чтобы вообще понять, правильной ли дорогой мы идем, и что вообще из этого получится.
В качестве инструментов на старте мы использовали PostgreSQL для хранения данных и Python-библиотеки для взаимодействия с API гипервизоров. С их помощью мы собирали данные о виртуальных машинах и сохраняли эту информацию уже непосредственно в базу данных.
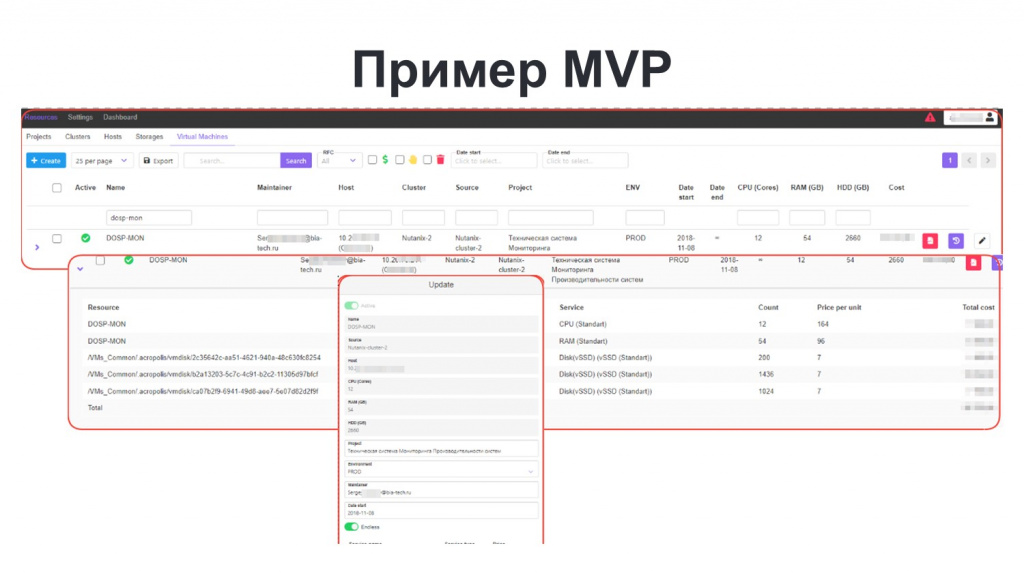
На слайде показан интерфейс, который у нас получился на этапе MVP. Здесь можно увидеть элементы, характерные для всех консолей гипервизоров, потому что часть информации у нас получается непосредственно с самого гипервизора и сохраняется в СУБД. А часть информации вносят пользователи.
Целевой группой пользователей этого MVP стали сотрудники ЦОД, которые непосредственно со всем этим ежедневно и работают.
После некоторого времени эксплуатации мы убедились, что решение действительно полезное, и начали собирать обратную связь: что работает хорошо, что плохо, что стоит доработать, и как дальше развивать систему.

На слайде выделено несколько основных моментов, которые необходимо было учесть в целевом решении.
-
Ролевая модель доступа. Мы изначально мы хотели, чтобы пользователями решения могли быть не только специалисты ЦОД, но и иные сотрудники компании, поэтому нам необходимо было разграничить доступ к данным и функциям решения в зависимости от роли и должности сотрудника.
-
Отчеты. Выгрузка в Excel, конечно, удобно, но неинтересно, поэтому в решении требовалось реализовать полноценную встроенную отчетность.
-
Интеграции. Поскольку часть информации в систему на этапе MVP вводилась вручную, возникали проблемы с агрегацией данных, которые могли вноситься абы как, из-за чего в данных получался некоторый мусор – использовать это в отчетах было сложно. Поэтому мы поняли, что нужна дополнительная интеграция для получения информации с наших МDM-систем.
-
Автоматизация. Чтобы пользователи не превращались в операторов системы, нужно было автоматизировать большинство рутинных действий, чтобы система помогала.
-
Уведомления. Нам было важно, чтобы система могла взаимодействовать с пользователем – предупреждала о необходимости выполнить определенное действие и информировала о событиях.
-
Удобный UI. Необходимо было поработать с UI, чтобы он стал более дружелюбным и подходил для использования широким кругом пользователей, а не только для технических специалистов.
С учетом всего перечисленного и ранее собранных требований, мы поняли, что набором скриптов на Python уже не отбиваемся. По сути, перед нами встала задача создания полноценной сервисной информационной системы с некоторым подобием учета.
В результате в качестве платформы, на которой это решение будет разрабатываться, мы выбрали 1С:Предприятие. Наш выбор был обусловлен следующими причинами:
-
наличие готовых компонентов для учета;
-
гибкие возможности настройки ролевой модели;
-
встроенный механизм отчетности на СКД;
-
и, что немаловажно, кроссплатформенный веб-клиент из коробки, не требующий установки дополнительного ПО на рабочие станции сотрудников.
Реализация. Биллинг
После утверждения концепции мы приступили к реализации. Всю функциональность разбили на несколько блоков и начали с того, что уже было в некотором виде реализовано в MVP – с блока биллинга.
Фактически мы занялись не просто переносом, а полноценной переработкой исходного решения. И в процессе реализации, когда мы начали подключать все имеющиеся у нас гипервизоры и доступные на тот момент облачные платформы, столкнулись с рядом сложностей.
-
Главная сложность заключалась в том, что каждая система предоставляет данные о своих ресурсах в разном виде. Т.е. одна и та же сущность виртуальной машины везде имеет совершенно разный атрибутивный состав, разную связь с кластерами, с ресурсами. Пришлось проделать значительный объем работы, чтобы привести все эти разнородные данные к единой модели, выбранной нами изначально.
-
Еще одна проблема – неточности в документации. В некоторых случаях методы API возвращали не совсем те данные, которые мы ожидали. Либо в документации отсутствовала информация о том, как получить те или иные данные, которые присутствовали в интерфейсе. Нам приходилось выполнять некоторый реверс-инжиниринг: анализировать работу веб-интерфейса системы, чтобы выяснить, какие запросы он выполняет, и где именно в API находится нужный метод.
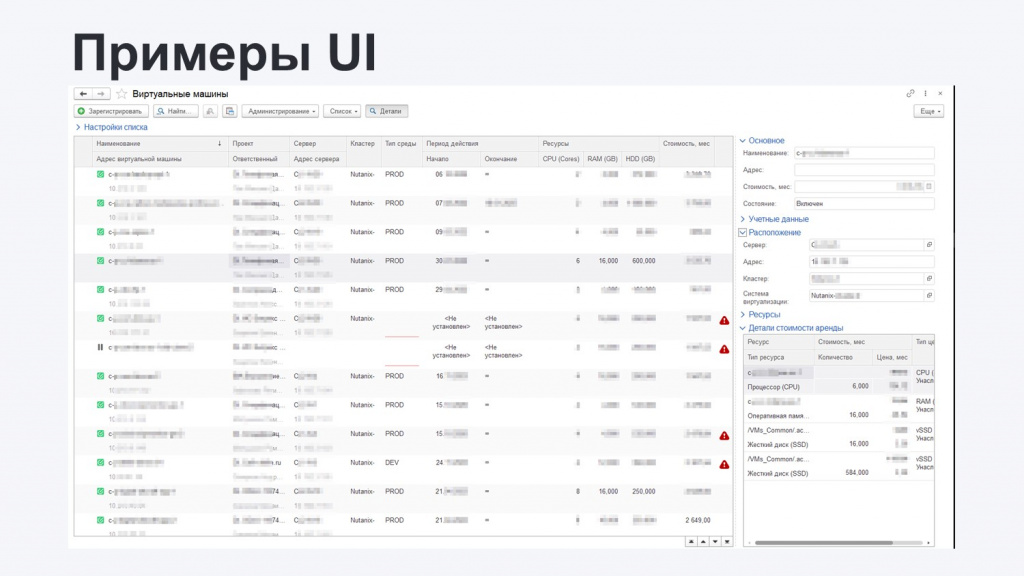
По итогам обсуждений и проектирования интерфейса мы пришли к следующему решению:
На основном рабочем столе отображается список всех виртуальных машин со всей необходимой информацией, чтобы не нужно было никуда проваливаться. Выводятся:
-
идентификаторы;
-
подсети;
-
кластеры;
-
к какому проекту эта машина относится;
-
какие у нее сроки жизни;
-
количество основных ресурсов;
-
стоимость оплаты в месяц и т.д.
И для выделенной машины опять же без открытия карточки можно увидеть расширенную информацию – понять тарификацию конкретных ресурсов, состояние (включено-выключено) и так далее.
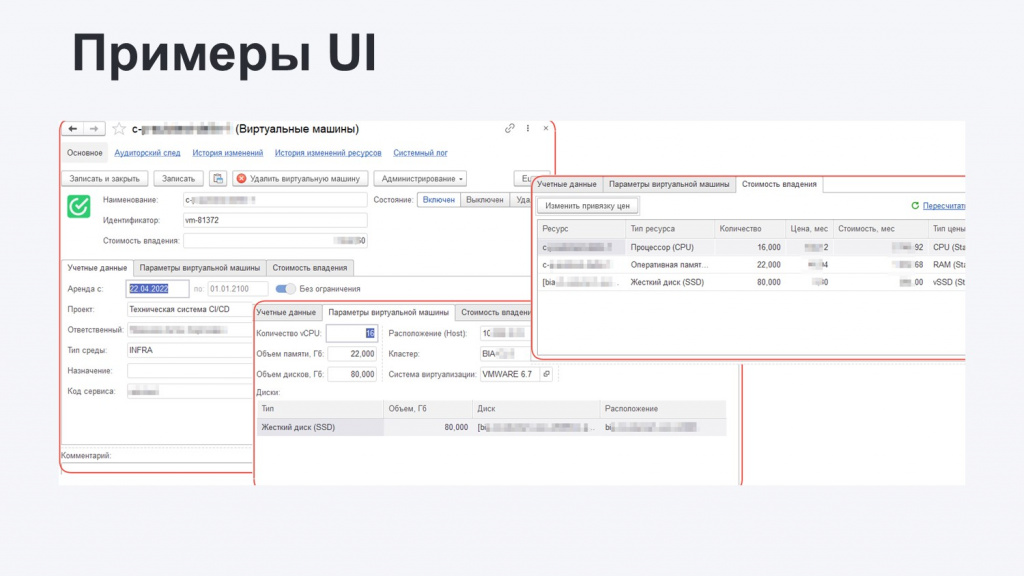
При необходимости можно открыть карточку конкретной машины и посмотреть по ней уже подробную информацию – в том числе, историю изменения каждого из ресурсов (согласование и прочую информацию, которая связана с жизненным циклом ресурсов).
Аналогичные интерфейсы были реализованы и для других компонентов модели
В результате на этом этапе мы уже получили полный биллинг физических ресурсов и с помощью реализованной модели ценообразования смогли их оттарифицировать.
Но это было еще не все: нам же нужно было еще связать все эти затраты с конкретными ЦФО. Это важно, поскольку вся деятельность у нас в компании работает по модели проектного управления, проектного финансирования – все так или иначе связано с тем или иным проектом. Причем проекты могут быть как связаны с ИТ, так и нет.
Информация по ИТ-проектам у нас хранится в Jira, где в карточке проекта всегда есть:
-
название проекта;
-
его руководитель;
-
состав команды;
-
сроки реализации и так далее.
Таким образом мы выполнили еще одну интеграцию и получили эти данные уже непосредственно из Jira. Это нам дополнительно дало дополнительные возможности.
-
Получив информацию о периоде жизни проекта, мы смогли настроить дополнительные уведомления: например, о том, что срок аренды виртуальной машины заканчивается, необходимо ее выводить из эксплуатации.
-
А за счет того, что мы знаем состав команды, мы смогли разделить доступ к имеющейся информации. Например, руководитель проекта имеет доступ к финансовым данным, а DevOps-инженер может каким-то образом получать информацию уже непосредственно о железе.
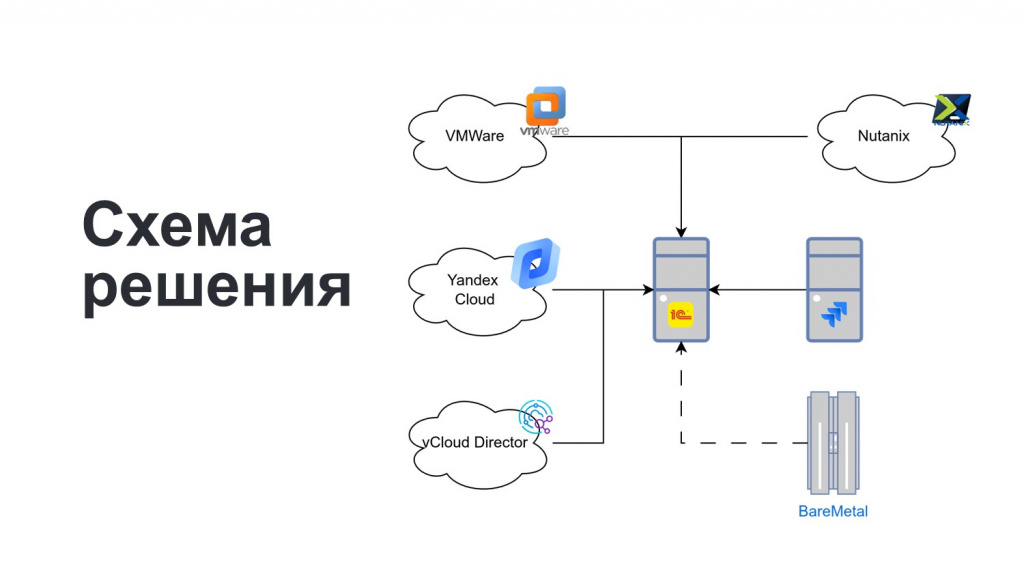
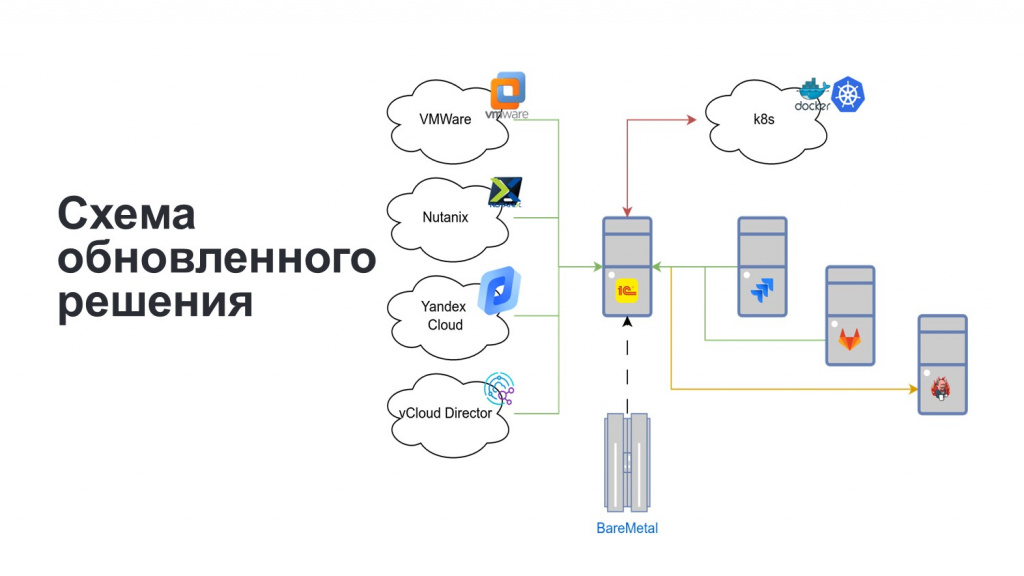
На этом этапе наше решение стало выглядеть следующим образом:
-
в центре находится 1С, которая интегрируется с нашими приватными облаками и облаками наших партнеров;
-
реализована интеграция с Jira;
-
дополнительно мы предусмотрели возможность ввода информации по учету физических серверов (BareMetal) которые используются без виртуализации. Пока данные о них вводятся вручную сотрудниками ЦОД, и дальше мы можем тарифицировать и учитывать ресурсы этих серверов наравне с виртуальной инфраструктурой.
Реализация. Web-публикации 1С
Закончив с реализацией подсистемы биллинга, мы пошли дальше.
На конференции Инфостарта в 2019 году мой коллега уже рассказывал о том, что мы активно используем контейнеризацию Kubernetes для публикации веб-клиента и сервисов 1С на веб-сервере, управляя этими контейнерами с помощью служебной сервисной системы, находящейся в ведении моего отдела.
Со временем число контейнеров значительно возросло, их сопровождение стало требовать все больше ресурсов, и возникло желание перенести их в новое разрабатываемое решение.
Такой перенос позволял достичь нескольких целей:
-
Хотелось снизить нагрузку на наш отдел.
-
Предоставить проектным командам возможность самостоятельно управлять публикациями: создавать, удалять и так далее.
-
Связав контейнеры веб-серверов с проектами, анализировать загруженность – количество, относящееся к тому или иному проекту.
-
Плюс собирать информацию по потребляемым ресурсам на Kubernetes, потому что кластер Kubernetes тоже не бесконечный.
Портирование прошло достаточно просто. Единственной сложностью на самом деле здесь оказалось добавление документации. Так как раньше система была сервисной только для моего отдела, мы особо не уделяли ей внимания. Тут же пришлось эту документацию изготовить, чтобы пользователи, несмотря на обучение и рассказы, могли обратиться к справке и посмотреть, как все это вообще работает.
Плюс, мы максимально спрятали от конечных пользователей упоминания Kubernetes и этих страшных букв, чтобы для них это выглядело достаточно просто.
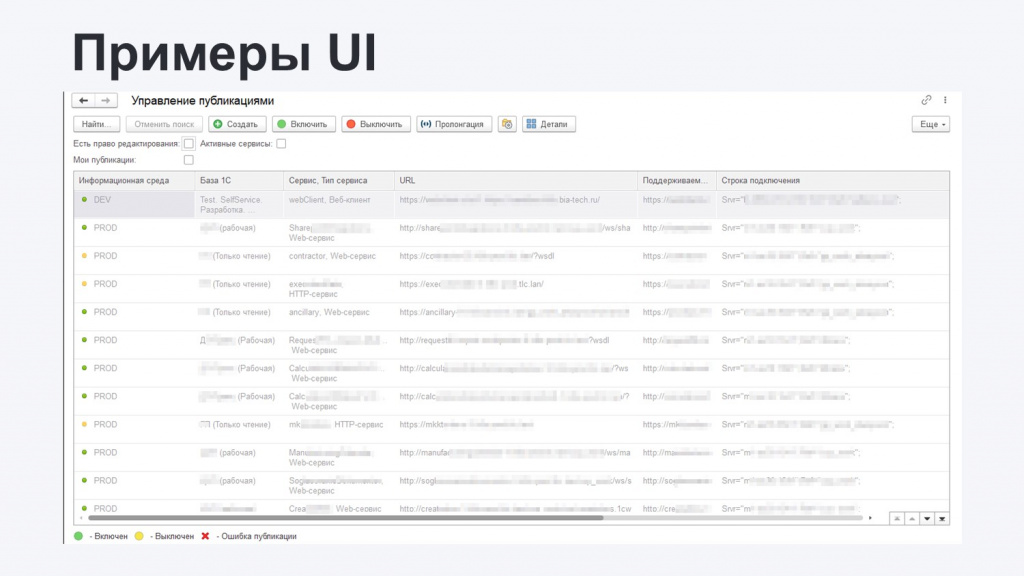
Интерфейс получился примерно похожий на прошлую подсистему – эту стилистику мы протянули по всему решению:
-
На форме выводятся все существующие публикации с текущим их статусом: названия, строки подключения и так далее.
-
В зависимости от прав пользователей ему с помощью мастеров доступна модификация публикаций.
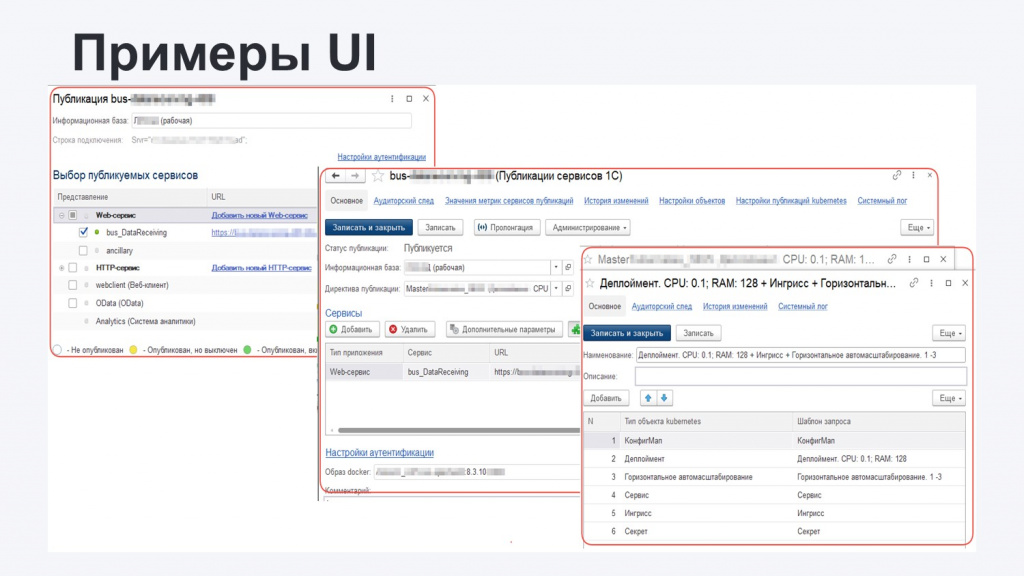
-
Если это прокачанный пользователь с расширенными правами и знаниями, ему доступно выполнение тонких настроек – в том числе, он может поменять параметры публикации непосредственно для Kubernetes, чтобы тот с помощью заданных ему инструкций по-другому скомпоновал поды на кластере.
Поскольку для публикации веб-сервиса необходимо использовать компоненты платформы 1С той же самой версии, что и на сервере приложений, где развернута информационная база, нам нужен был подходящий контейнер.
Есть вариант устанавливать нужную версию платформы при каждом запуске контейнера, но это дорого, долго и неэффективно.
Поэтому мы реализовали процесс подготовки контейнеров заранее – настроили пайплайн на нашем билд-сервере (в нашем случае Jenkins) и посредством API передаем ему команду из системы. Тот билдит этот контейнер, выкладывает его в Docker Registry, и мы оттуда посредством API забираем его обратно в систему.
Все это происходит незаметно для пользователя – он просто выбирает нужный образ, сохраняет изменения, и Kubernetes разворачивает из этого образа новую публикацию.
По завершению этого этапа наше решение усложнилось – появились дополнительные программы. Теперь оно включает интеграции с билд-сервером Jenkins, GitLab и Kubernetes через REST API. Confluence я сюда не выводил, потому что интеграция с ним реализована через URL, поэтому будем считать, что она есть где-то там за облачком.
Реализация. Crafting
Оценив достигнутое, мы поняли, что большинство первоначальных целей уже реализовано. Оставалась «вишенка на торте» – предоставить командам возможность самостоятельно создавать виртуальные машины.
Поскольку мы уже умеем работать с различными облачными платформами и хорошо знаем их API, технически это вполне реализуемо: создаем виртуалку, устанавливаем на нее необходимое ПО (например, через Ansible) и можем пользоваться. Тем более, что последнее время мы активно используем паттерн «Инфраструктура как код» – описываем изменения нашего ИТ-ландшафта из A в B в специальных конфигурационных файлах. С помощью аппрувов и определенных проверок эти изменения определенным образом применяются. Либо не применяются, если были откаты.
Здесь нам необходимо было применить тот же самый подход.
Реализовали мы его следующим образом.
-
Создали специальный репозиторий на GitLab'е для хранения конфига.
-
Настроили CI/CD-конвейер, который анализирует этот конфиг и передает управление Terraform'у.
-
Terraform уже посредством своего API и коннекторов к соответствующим облакам выполняет создание виртуальной машины либо изменение ее характеристик.
-
Результаты возвращаются в билд-сервер, который передает их в систему.
Выбрали решение и пошли его крафтить – поэтому и подсистему назвали Crafting.
На этом этапе мы опять же столкнулись с проблемами в части неточностей в документации и некоторых ошибок в используемом программном обеспечении – в том же Terraform'е. Но мы их преодолели и выдали полученное решение тестовой группе.
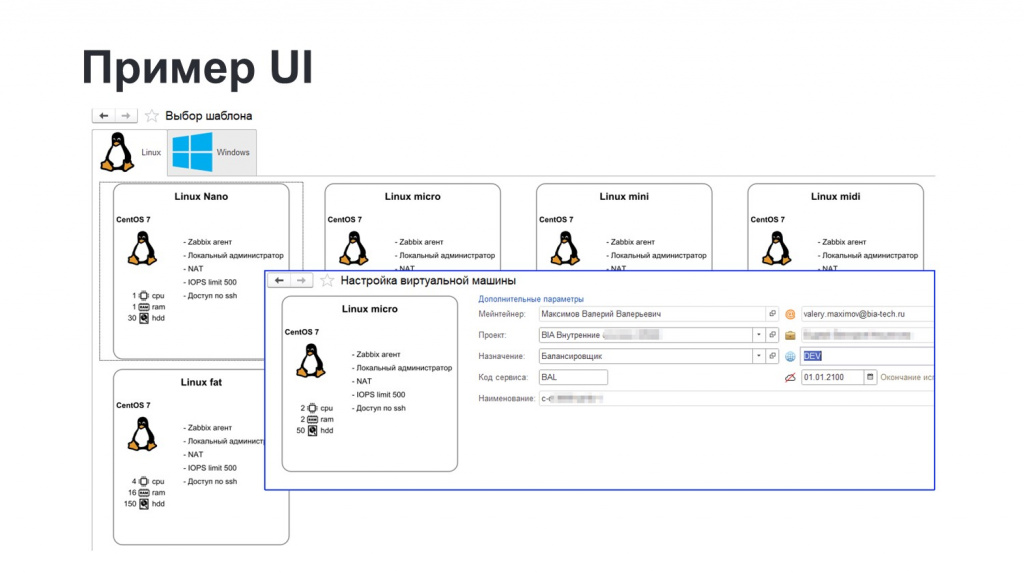
Выглядело это следующим образом:
-
Пользователь видел на экране набор плашек с образами и описанием создаваемых виртуальных машин.
-
При выборе нужной плашки мог отметить там несколько полей – тип создаваемой виртуалки, какая среда, срок действия.
-
По нажатию кнопки запускался процесс валидации требуемых для создания виртуальной машины ресурсов и квоты по проекту (потому что в рамках этой задачи мы добавили квотирование – в каждом проекте указывается, сколько ресурсов ему согласовано, сколько можно использовать самостоятельно).
-
Если все успешно, запускается тот самый пайплайн, о котором я сказал, назад прилетают креды, текущий пользователь получает эти креды и начинает пользоваться виртуалкой. Все это занимает примерно пару минут.
Однако, проанализировав эту реализацию, мы приняли решение пока не запускать ее в промышленную эксплуатацию, потому что возникло некоторое количество нерешенных задач, которые необходимо закрыть, прежде чем система сможет полноценно работать в продакшене.
В частности, у нас есть определенные требования по размещению виртуальных машин в определенных подсетях:
-
Если такой подсети нет, нужно по определенным правилам ее создать, выделив для нее диапазон адресов.
-
А если подсеть уже существует, нужно найти в ней свободный адрес и забронировать его, чтобы избежать ситуации, когда один и тот же IP-адрес будет назначен нескольким виртуальным машинам одновременно – к чему это может привести, думаю, объяснять не нужно.
Из-за этого подсистема пока находится в процессе развития.
В завершение подведу собственно некоторый итог:
-
Практически все изначально поставленные задачи мы выполнили. Мы научились собирать и биллинговать все наши ресурсы – как наши приватные облака, так и партнерские, а также ресурсы физических серверов (BareMetal).
-
Добавление новых облаков теперь не вызывает затруднений. Реализованный интерфейс позволяет быстро создать небольшой модуль с нужным набором интерфейсных методов для подключения нового типа систем виртуализации – можно сразу же это использовать.
-
Разработали кучу новой документации, которую теперь нужно регулярно поддерживать в актуальном состоянии при обновлении системы.
-
Пользователи получили больше возможностей самостоятельно управлять ресурсами, не отвлекая ограниченное количество технических специалистов, которые непосредственно администрируют эти ресурсы.
Вопросы и ответы
Как вы называете этот инструмент у себя внутри?
Система называется Self-Service – система самообслуживания.
Когда пользователь будет выбирать, какую машину ему создать, он увидит, сколько это будет ему стоить?
Именно в рамках этих шаблонов мы ему сейчас эту информацию не показываем. Но вообще идея отображать эту информацию есть. Но опять же, функция, которая есть сейчас, она пока не до конца доделана – это скорее MVP.
План был такой, что создает ее девопс, получает некоторый аппрув на то, что его сконфигурированная новая виртуалка будет стоить столько-то рублей, РП-шник сказал: «Окей, тратим денежку». И после этого пайплайн запускается.
Я так понял, что Self-Service управляет различными системами для выделения ресурсов пользователям. Сколько ресурсов у него в подчинении?
Подсистема именно выделения ресурсов и создания этих машинок у нас сейчас в процессе разработки. Там пока есть ряд нерешенных задач – эта техническая возможность пока еще не доведена до конечного использования.
Планируется, что будет некоторый пул ресурсов, которые будут доступны для управления, и он будет мапиться на те квоты, которые есть в проектах. Условно говоря, если под этот проект выделено законтрактовано 100 ядер, 100 гигов памяти и 1 гигабайт дисков, то есть какой-то здоровый кластер, от которого все это можно отпиливать.
Получается, что вы изначально закладываете ориентацию на то, что ресурсы ограничены, чтобы пользователь не получил то, чего нет.
Да. Чтобы не было такого, что мы создадим сверхресурсоемкую машину, и на ней запустим Apache.
Вы сказали, что используете VMWare. А как решили вопрос с лицензированием? Насколько знаю, в России VMWare больше не поддерживается?
Я разработчик-исследователь, и на этот вопрос вам не отвечу. Я знаю, что от каких-то кластеров на VMWare мы уже отказались. Но как лицензируются те сервера, которые пока еще функционируют, я не готов ответить.
Update: лицензирование VMWare также подразумевает использование бессрочных лицензий. С 2023 года они перестали такие продавать, но ранее проданные клиенты могут продолжать использовать без ограничений, за исключение отсутствия технической поддержки.
А OpenStack у вас используется?
На данный момент, насколько я знаю, на OpenStack никто ничего не разворачивал. VCloud точно есть. Но, как я уже сказал, добавление нового облака для нас – это просто создание нового общего модуля, где реализуются интерфейсные методы. По сути, это условный драйвер, который реализует методы: «Дай мне машину», «Дай мне кластер», «Дай мне еще что-то». Реализуем этот модуль и начинаем использовать.
Если для разных Terraform-провайдеров используются разные адаптеры, получается, что их можно немного доработать и подключить следующие?
Для получения данных с гипервизоров или облаков мы используем их API.
А если говорить непосредственно про создание новых виртуальных машин, то в основном используются либо готовые плагины к Terraform, которые идут с ним в комплекте, либо их доработанные версии.
Например, готовые плагины для Nutanix есть в самом Terraform, потому что я не помню, чтобы мы их создавали с нуля.
Это еще интереснее, поскольку сейчас стало понятно, что Self-Service управляет всеми облаками через Terraform.
Да, в той подсистеме крафтинга, о которой я говорил в конце доклада, при нажатии кнопок мы коммитим в специальный репозиторий конфиг-файл. На эти изменения реагирует билд-сервер и говорит: «Terraform, я тут провалидировал, начинай работать».
Мне показалось, что эта часть доклада была посвящена BareMetal – голому железу.
Нет, это виртуалки, которые создаются на том или ином облаке – на Nutanix или VMWare – посредством команды git commit, дающей пинок Terraform’у.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.
