Для кого эта статья?
В первую очередь я хочу обозначить людей, которым может быть полезна эта статья.
- Так как источником технического долга у нас являются разработчики, то им это будет полезно в первую очередь.
- Также руководителям проектов или руководителям продуктов будет полезно вынести из статьи какие-то темы, которые можно воспринять, как руководство к действию.
- А в случае, если той концепцией, про которую я сегодня расскажу, станут пользоваться заказчики, они получат эффективный инструмент мониторинга и контроля над разработкой программного обеспечения для себя.
Что такое Технический долг?
Есть такое каноническое определение, что технический долг – это работа, оставленная «на потом».
- Это может быть какая-нибудь плохо спроектированная архитектура, слабоструктурированный или слишком запутанный код. На момент, когда мы его написали, мы понимаем, что это такое, но остается ощущение, что что-то здесь не так и что-то надо исправить.
- Условно, с точки зрения разработчика, количество технического долга при просмотре некачественного кода можно охарактеризовать, как количество воскликов «Что же здесь происходит?» в час.
- Очень часто, когда разработчики разбираются в сложном и запутанном коде, они долго не могут понять, что делает этот код, и тратят свое время на повторное укладывание в голове происходящего. Тем самым, тратят свои (и заказчика) деньги. Примерно посчитав, сколько времени тратит разработчик на каждый такой случай, мы можем определить общий объем технического долга в часах и перевести его в деньги, например, умножив на часовую ставку программиста.
Зачем управлять техническим долгом?
- Поскольку при увеличении технического долга время на разработку новой функциональности увеличивается, то и стоимость поддержки при развитии системы с течением времени тоже будет увеличиваться. И чем больше у вас будет этого технического долга, тем сложнее и дороже вам будет разрабатывать новую функциональность и исправлять ошибки в текущей.
- Так как разработчики – люди не идеальные, и бизнес требует, чтобы изменения происходили быстро и стремительно, то долг постоянно растет. Очень редко во время обычного цикла разработки можно заметить тренды снижения технического долга – в абсолютном большинстве случаев идет постоянное увеличение.
- Если не следить за архитектурой, структурой и кодом приложения, то, в конце концов, это приведет к тому, что его будет невозможно улучшать дальше. Разработчики будут заняты только исправлением очередных найденных ошибок, и, пробираясь сквозь плохой код, будут тратить много времени на понимание, что же здесь происходит.
Игра «в долгую»
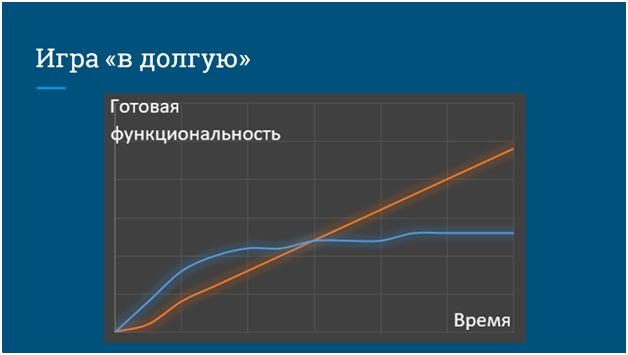
Управление техническим долгом – это так называемая игра «в долгую». На этом слайде вы можете видеть два «джедайских меча» – оранжевый и синий. Они олицетворяют два подхода к разработке:
- Синяя команда (с синим графиком) не следит за своим техническим долгом, не считает его, и в короткой перспективе может быстро реализовывать новую функциональность и быстрее приносить пользу бизнесу (так называемый Time to Market).
- А оранжевая команда с самого начала своей работы пытается следить за тем, насколько качественно она разрабатывает, устраняя утечки своего технического долга параллельно с выпуском новой функциональности.
В долгосрочной перспективе наступает такой момент, когда:
- Команда, которая не следила за качеством, попадает в ситуацию снижения производительности из-за накопившихся в процессе разработки ошибок – время у нас идет, а количество новой, полезной функциональности не увеличивается.
- Оранжевая же команда, изначально следившая за своим качеством разработки, планомерно, в том же самом темпе, в котором и начинала, продолжает наращивать функциональность.
Семь смертных грехов разработчика
Есть такая концепция «семи смертных грехов разработчика». Это некие плохие процессы, которые в итоге приводят к появлению технического долга и удорожанию системы. За этими смертными грехами можно следить и пытаться как-то нивелировать их влияние или вообще стараться этого не допускать.
Первый смертный грех, который могут допускать разработчики, это – ошибки и потенциальные ошибки.
- Например, это могут быть ошибки проектирования, заключающиеся к неправильной реализации той функциональности, которую от нас хочет бизнес.
- Либо это могут быть какие-то ошибки в коде, которые приводят к «страшным красным надписям» при работе заказчика.
- Либо в коде могут оставаться какие-то потенциальные ошибки – непротестированные участки, которые на данный момент времени из-за текущих настроек системы не вызываются, но в будущем, при изменении бизнес-процессов этот код начнет выполняться, и пользователи уже потом будут получать эти «красные надписи».
Для отслеживания таких ошибок служит два показателя – надежность и безопасность. Это количественные показатели того, сколько алгоритмических ошибок и уязвимостей есть сейчас в нашей системе.
Самый распространенный вариант уязвимости в коде 1С – это выполнение строки кода, заданной в качестве параметра экспортной процедуры, которую можно вызвать из любого места системы (чаще всего даже подключившись через COM). Например:
Процедура ВыполнитьКод(ПроизвольнаяСтрока) Экспорт
Выполнить(ПроизвольнаяСтрока);
КонецПроцедуры
Наличие такой уязвимости в худшем случае может привести к очистке всех данных и полному разрушению базы – это очень плачевно скажется на бизнесе.
Второй смертный грех – это нарушение стандартов разработки.
- К сожалению, мало кто из разработчиков знает, а еще меньше применяет стандарты разработки, рекомендованные компанией 1С. Они опубликованы на ИТС – там довольно большой раздел, в котором описано, как правильно писать код, причем не только с эстетической точки зрения, но и для того, чтобы его потом было проще поддерживать и дорабатывать.
- Помимо общепринятых стандартов, поставляемых вендором, у команды разработки могут быть свои внутренние стандарты кодирования. Если они у вас есть, то им тоже нужно следовать. Иначе, когда ваши партнеры по команде будут разбирать ваш код, им будет менее комфортно с ним работать, и они опять-таки, будут тратить на это больше времени.
Для контроля над этим смертным грехом используется показатель сопровождаемости. Так как требования к качеству написания кода более-менее стандартизированы, мы можем посчитать все случаи отклонения от идеального поведения и сформировать некий показатель сопровождаемости. В него входит, например, такая метрика, как отношение количество строк плохого кода к общему количеству строк кода. Это очень важная метрика, потому что на ее на основании мы можем рассчитать, насколько больше нам нужно заложить времени на разработку какой-то новой функциональности или изменения старой.
Третий смертный грех – это дублирование кода.
- Я думаю, многие из вас при разборе какого-то алгоритма встречали в одном и том же модуле целиком скопированные участки кода, которые просто просятся, чтобы их вынесли в отдельную процедуру для повторного использования. Тем самым, можно сократить количество кода, а также увеличить сопровождаемость в случае обнаружения какой-либо ошибки.
- Хуже того, иногда разработчики копируют код в два места, а при обнаружении в них ошибок исправления вносят неодинаково – в одном месте исправляют одни ошибки, в другом – другие, хотя это один и тот же код, но в разных местах.
- Либо бездумно копируют кусок кода, чтобы модифицировать его под какие-то новые требования. Правильнее было бы попытаться реализовать некий универсальный алгоритм, учитывающий различные варианты применения и повторно его использовать - тогда последующим разработчикам было бы уже проще.
За это отвечает показатель дублирования. Чтобы его вычислить, мы можем посчитать количество таких дублирующихся участков и строк в них по отношению к общему количеству кода. Это позволит узнать, насколько наша конфигурация состоит из так называемого «копипаста» и сколько у нас уникального кода в конфигурации.
Четвертый грех – это недостаток тестирования.
- Если вы не пишете автоматические тесты или не прогоняете ручные по какому-то заранее сформированному комплекту проверок, это приводит к тому, что вы не понимаете, насколько ваша система надежна и насколько безопасно вы можете изменять те или иные участки кода. Потому что опять-таки, программисты – люди не идеальные и при доработке функциональности они могут внести новые ошибки, сломав, таким образом, что-то, что работало раньше. Это приведет к регрессии системы.
За этот смертный грех отвечает показатель покрытия. Мы можем посчитать, сколько процентов нашего кода покрыто автоматическими или ручными тестами, и таким образом, сформировать некий показатель уверенности нас, как пользователей и как заказчиков в том, что код работает правильно.
Следующий смертный грех – это излишняя цикломатическая сложность, которая характеризуется запутанностью кода той или иной процедуры и определяется количеством в ней условий, циклов и каких-то непонятных переходов.
- При большой цикломатический сложности в лучшем случае мы можем наблюдать в коде какие-то огромные процедуры, которые сложно читать, сложно понимать – приходится тратить время.
- В худшем случае это приводит к так называемому «спагетти-коду», когда программист открывает какую-то одну огромную процедуру, которая делает 50 процентов логики всей системы, долго-долго листает ее в конфигураторе, ему постоянно приходится перемещать редактор кода слева направо, потому что он выглядит как спагетти, который разместили на столе. Опять-таки, затрудняется понимание при дальнейшей разработке и поддержке.
Показатель здесь – это сложность системы. Его тоже можно посчитать.
Помимо сложности кода у нас еще есть сложность самой архитектуры.
Если вы используете какое-то многомодульное приложение (а 1С – это, условно говоря, трехкомпонентная система, состоящая из: визуальной части; серверной части, за которую отвечает сервер приложения; и непосредственно СУБД), и у вас в коде смешана работа с разными компонентами, то модифицировать все это потом будет опять-таки сложнее.
Показатель здесь тот же самый, это – сложность.
И седьмой смертный грех – это недостаток или излишнее количество комментариев.
- Некоторые сложные алгоритмы (даже если они структурированы, разбиты на какие-то маленькие функции) приходится комментировать просто в силу их сложности и непонятности неподготовленному человеку. Особенно это касается программного интерфейса для экспортных процедур и функций. Например, когда я, как разработчик, хочу использовать библиотеку подключаемого оборудования, я не хочу разбираться в том, как она работает на аппаратном уровне с конкретными сканерами штрихкодов или печатью этикеток. Я хочу просто получить список доступных процедур и функций, описание того, что они делают, и, в идеале, пример их использования. Но чтобы я смог это понять, эти процедуры и функции должны быть определенным образом закомментированы.
- Второй недостаток – это излишнее комментирование. Есть каноничный пример, когда в коде объявляется переменная и в комментарии пишется, что «я объявил переменную и присвоил ей такое-то значение». Я думаю, что все понимают, что это делать не надо, однако, к сожалению, так периодически делают.
Показатель, который нам здесь поможет – это документирование. Мы можем посчитать процентное соотношение количества строк комментариев к общему количеству кода и тоже этим управлять.
Зачем нужны показатели качества кода?
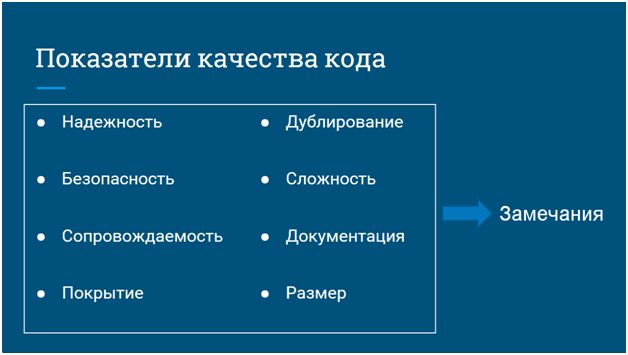
Если мы посмотрим на показатели качества, характеризующие нашу систему в целом, и добавим сюда показатели размера (будем знать, сколько у нас всего модулей, процедур и функций, строк кода в них), то мы сможем понимать, куда нужно бросить усилия для того, чтобы исправить ту или иную ситуацию:
- Например, если мы знаем, где наша система не покрыта тестами, мы можем реализовать это покрытие.
- Или, если у нас слишком много дублирования кода, мы можем ставить задачи на рефакторинг.
- А в целом, мы можем формировать замечания по исправлению нашего кода.
Какие есть подходы к управлению техническим долгом?
Я назову четыре. Я думаю, с первыми тремя из них вы более-менее знакомы.
- Первый подход – это контроль качества внешними аудиторами. Вы можете разрабатывать конфигурацию, потом собрать этот cf-ник, отдать его в какую-то внешнюю компанию с громким названием (обычно, с фамилиями) – они будут долго и упорно смотреть на ваш код, а потом сформируют вам огромный отчет по поводу недостатков вашей конфигурации. Этот подход имеет право на жизнь, но он имеет минусы, о которых я расскажу чуть позже.
- Второй подход – это визуальная проверка кода разработчиками (или code-review). Обычно у нас есть некий абстрактный стажер, и наставник, который дает этому стажеру задачу. Стажер задачу решает, приносит код своему наставнику, тот смотрит на этот код и дает своему стажеру некую обратную связь. Если вы пользуетесь какими-то более сложными, чем хранилище, серверами по контролю версий (например, Github, Gogs или Gitlab), то у вас есть возможность точечного просмотра измений каждого помещения (коммита) или формировать запросы на слияние кодовой базы, где разработчики могут более подробно и более детально изучать, какие же были изменения в вашем коде.
- Третий подход – это разовые автоматизированные отчеты о качестве кода. Например, у вас есть некая система, в которую вы загружаете весь свой код, она вам долго-долго его анализирует, а потом опять-таки выдает огромный отчет. Вы смотрите на этот отчет, но так как у вас перед этой системой нет никаких обязательств, и вы ее запустили именно разово, для того, чтобы увидеть, насколько у вас все плохо, то чаще всего, вы откладываете этот отчет в дальний ящик стола и продолжаете кодировать дальше.
- А четвертый подход – это непрерывная инспекция. Именно о ней я и собираюсь рассказать чуть подробнее.
Continuous Inspection – ключевые принципы
Что же вообще такое Continuous Inspection (непрерывная инспекция кода), какие у нее ключевые принципы и из чего она состоит?
- Основной ее постулат заключается в том, что качество – это общая задача всей команды разработки и результат выполнения этой задачи зависит непосредственно от самих разработчиков, потому что они производят код, за который несут ответственность.
- Второй ключевой принцип – это актуальность информации. Если мы проверяем нашу систему и получаем о ней какие-то качественные показатели, мы должны их получать регулярно, чтобы у нас под рукой всегда была актуальная информация о текущем состоянии нашей кодовой базы.
- Данные о качестве (как показатели, так и какие-то списки замечаний), мы должны получать не только в абсолютных значениях, но и в разностных. Мы должны понимать, а что же у нас изменилось за неделю с выхода прошлой версии, за день и т.д.
- Проверка качества должна быть автоматизированной, и мы в идеале должны исключить каких-то конечных людей (внешних аудиторов либо самих разработчиков в плане ручного code-review), чтобы проводить эти проверки автоматически.
- И еще один ключевой принцип – стандарты качества должны быть едиными для всех проектов. Часто бывает ситуация, когда какая-то команда уже 8 лет внедряет УПП, а теперь начала внедрять УТ 11 на управляемых формах. И в головах возникает такое отношение – проекту по УПП уже 8 лет, 1С этот продукт уже давным-давно не поддерживает, там уже в принципе все плохо и за его качеством можно не следить. А вот для УТ 11 в плане контроля качества еще можно что-то сделать, поэтому следить будем только за ним. Это – неправильно. Не смотря на то, что УПП – это система, которая разрабатывается давным-давно, стандарты качества к ней точно такие же. Просто здесь на первый план выходят не абсолютные показатели (когда мы знаем, что за 8 лет разработки у нас накопилось 10 лет технического долга), а именно относительные – когда мы разрабатываем новую версию функциональности, мы должны быть уверенными в том, что мы ее сделали качественно.
- Последний ключевой принцип – это то, что все новые замечания, особенно критические, должны иметь ответственного. И если у нас несколько человек в команде, то каждое выявленное замечание по качеству должно относиться на конкретного разработчика. Может быть, он уже уволился – это неважно, но в принципе, мы должны понимать, кто привел к конкретной проблеме.
Сравнение подходов.

Аудит, если он проводится вручную, и код-ревью имеют под собой некий человеческий фактор.
- Люди чаще всего имеют склонность пропускать какие-то замечания, у них может «замылиться» глаз. Аудиторы на этой ниве работают уже много лет, они какие-то моменты могут случайно упустить, и в результате мы, выполняя задачу контроля качества, можем не получить полную картину того, что у нас происходит.
- А в случае применения неких автоматизированных систем (либо разово, либо в непрерывном варианте), влияние человеческого фактора уходит, потому что все эти проверки проводятся автоматически, и код у нас анализируется на основании каких-то алгоритмов.

Следующая проблема, которая бывает при контроле качества – это актуальность нашего анализа.
- Чаще всего аудит выполняется долго, и пока отчет не готов, мы продолжаем разрабатывать. Когда мы этот отчет получаем, у нас уже и код поменялся, и состав модулей другой. Получается, что та конфигурация, которую изучал аудитор, и то, что у нас в кодовой базе сейчас – это в принципе, два разных программных продукта.
- С код-ревью получше, он производится либо в момент сдачи функциональности, либо в момент влития изменений в основную ветку, поэтому там с актуальностью все более-менее хорошо.
- И разовые проверки (в случае, если вы сразу исправляете свой код) также могут быть полезны. А если вы откладываете их исправление «в долгий ящик» – пользы не будет.
- Continuous Inspection предполагает частую автоматическую проверку вашего кода. Причем, когда я говорю «частую», это не значит, что раз в неделю или раз в месяц. Проверяется каждое ваше изменение при помещении в хранилище, либо коммит в Git (если вы пользуетесь системой контроля версий). И на каждое изменение вы получаете отчет о качестве.

Следующая проблема заключается в том, что аудит имеет свойство некоего психологического давления на команду разработки.
- Приходят какие-то «левые дядьки» из фамильной компании, приносят нам стопку «косяков» в нашей системе (это я как разработчик сейчас говорю), говорят, что мы не правы! Первая реакция у разработчиков – сами вы нехорошие люди, ничего мы с вашим отчетом делать не будем.
- Если же качество проверяется где-то внутри вашей компании, то ситуация становится получше.

То же самое касается распределения ответственности.
- В случае если аудит проводится внешними специалистами, они занимаются только проверкой качества, а самой кодовой базой владеете вы. В результате аудиторы не имеют никакого реального контроля над разработчиками, не могут оказывать на них полезного давления, и таким образом, общая полезность этой проверки тоже падает.

А если у вас используется код-ревью, и ваш код проверяет какой-то более опытный коллега (или наставник), то это предполагает, что вы тратите время более опытного, более дорогого разработчика на то, чтобы проверить свой не очень опытный код. Чаще всего для вас это оправдано и приносит пользу, но на этом можно сэкономить.

Также для всех перечисленных разовых подходов характерно отсутствие динамики.
Когда вы периодически, но нерегулярно проверяете код, вы не понимаете, как ваша система менялась с течением времени на коротком промежутке (в идеале, при помещении в хранилище одного изменения).
Что такое Continuous Inspection с точки зрения разработки?
Каждый день каждое изменение в хранилище должно сопровождаться результатами контроля качества.

Вы должны каким-то образом получать отчет о проверке. Например, это может быть письмо на почту о том, что вы написали код и своим небольшим изменением добавили 2 с половиной часа технического долга. Это реальный отчет, который мне пришел на одном из проектов.
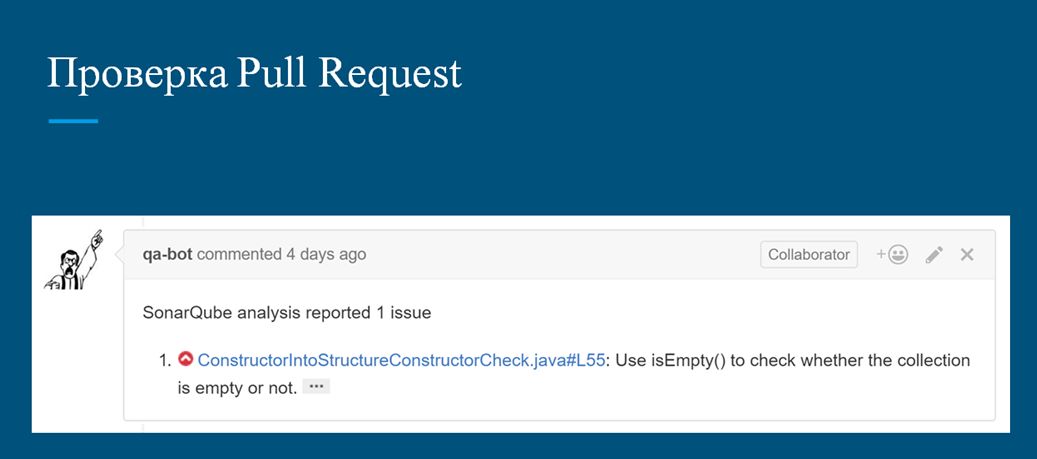
Второй вариант – если вы используете Git-flow и Pull-request-ы (программисты знают, что это такое), то можно оценивать и сами изменения кода – только то, что поменялось в конкретном предложении на влитие в основную ветку. И тоже получать об этом отчет.
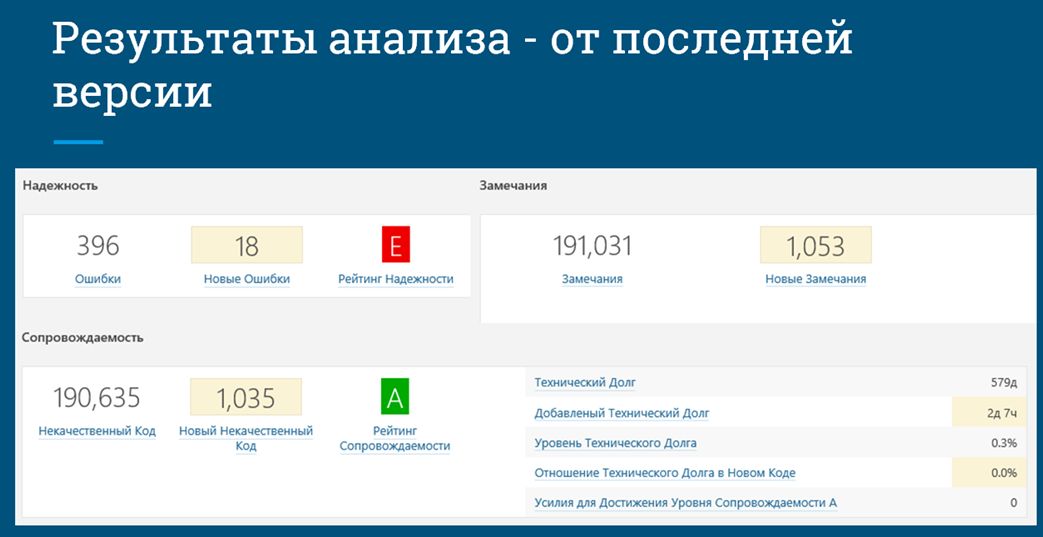
Результаты анализа должны быть инкрементальны не только относительно вашего текущего изменения, но и от последнего релиза вашего продукта. На данном слайде вы видите в левой части количество зафиксированных ошибок, а посередине (где написано «Новые ошибки», «Новый некачественный код») – именно то, что у нас изменилось с прошлой версии. Это – уже инструмент для релиз-менеджера, чтобы он мог видеть, что же у нас происходит с кодовой базой и насколько наш релиз готов к выпуску. В данном случае, вы видите рейтинг надежности E (наихудший). Это потому, что одна из этих 18-ти новых ошибок – блокирующая, и ее нужно срочно исправить.
Каждое замечание должно иметь ответственного.
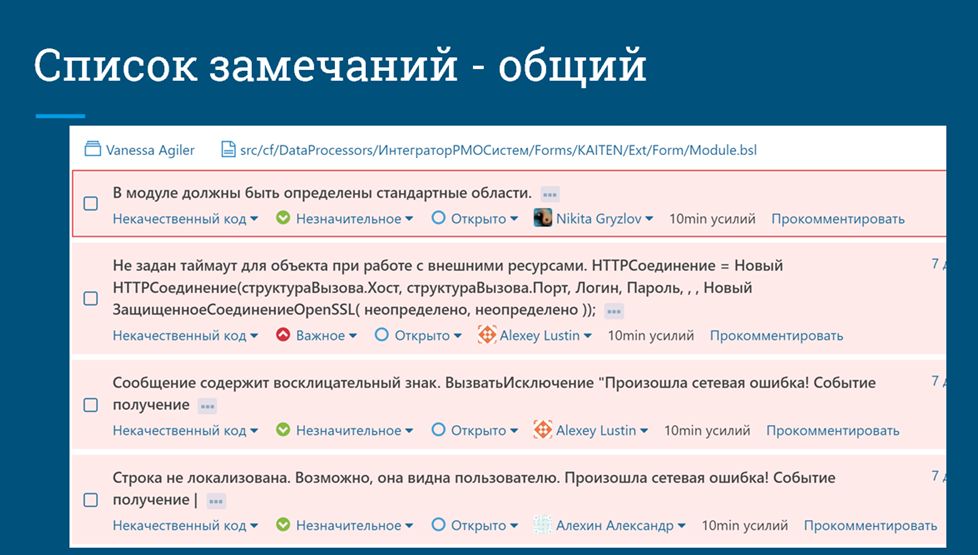
Мы должны иметь возможность посмотреть общий список зафиксированных ошибок, чтобы понять, что у нас происходит в системе. Заметьте, здесь каждая ошибка назначена на конкретного человека: что-то на меня, что-то на уважаемого Алексея Лустина и т.д.

Помимо этого, ошибки должны быть доступны для просмотра сразу из кода, чтобы разработчики не «рвали контекст».
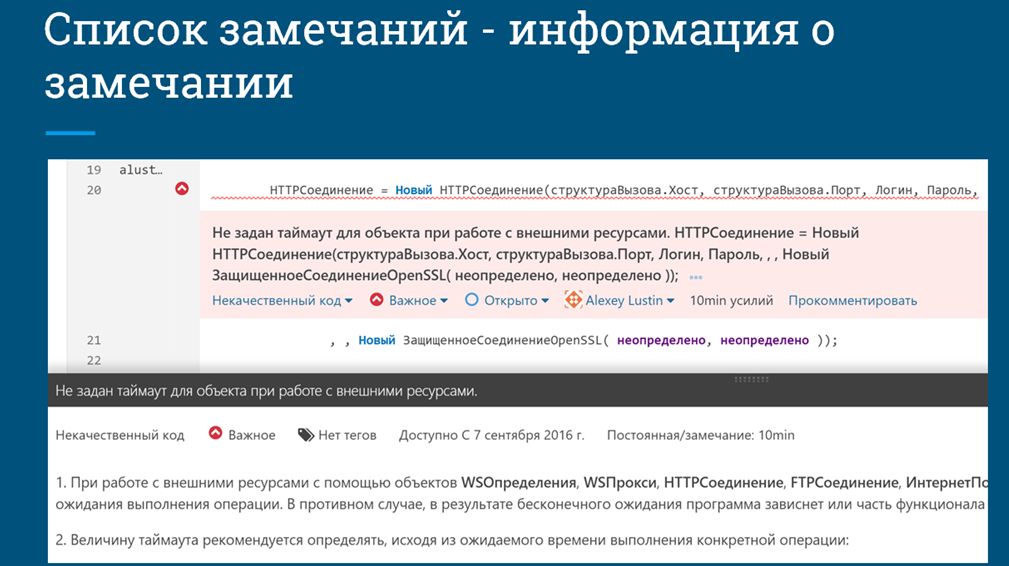
Так как проверки кода у нас автоматизированы, мы можем сразу накапливать некую информацию не только о том, что у нас плохо, но и почему это плохо, предоставляя методические материалы о том, как это нужно исправить, со ссылкой на те же самые стандарты ИТС. Здесь в нижней части скриншота как раз и представлен текст с ИТС об этой конкретной ошибке.

Мы можем видеть, насколько у нас все плохо не только в конкретном проекте, но и во всех наших проектах. Для собственного перфекционизма и желания все делать хорошо это тоже может быть полезный показатель.
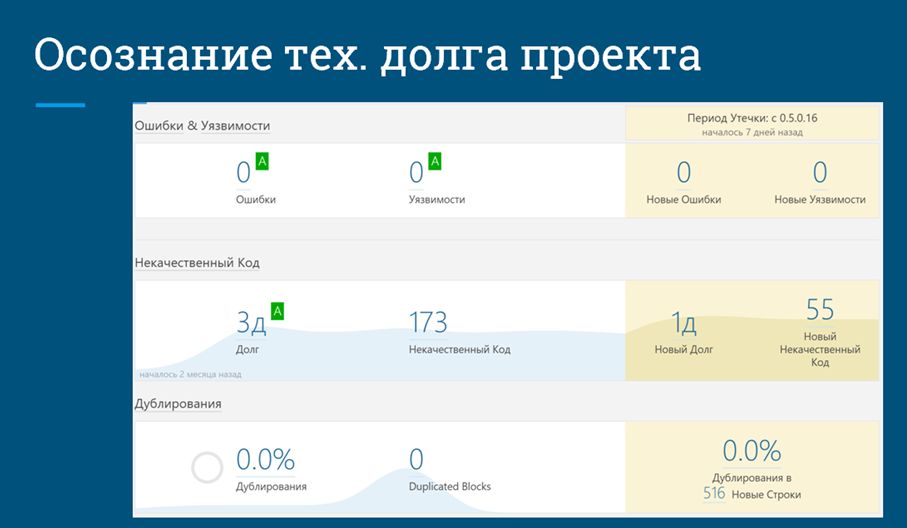
Скриншот с техническим долгом проекта я вам уже показывал, а это – его расширенная версия. Здесь на средней полоске как раз виден график тренда увеличения или уменьшения нашего технического долга.
Важной концепцией для релиз-менеджера является порог качества. В качестве него мы можем настроить некоторые очень объективные показатели.
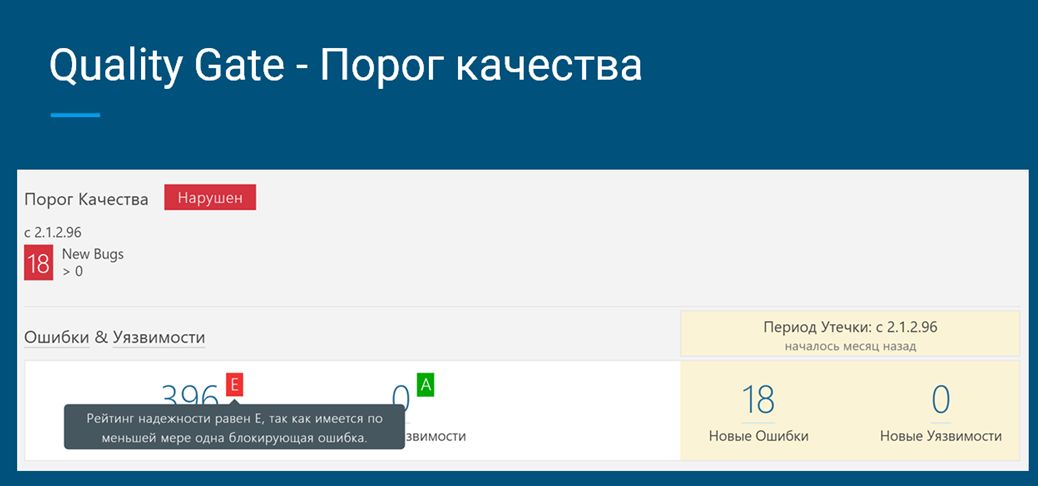
Например, в качестве порога качества мы можем принять, что у нас не должно быть новых зарегистрированных ошибок кодирования, а отношение плохого кода к хорошему не должно быть более 5 %. На основании этого мы можем принимать решение – выпускать новый релиз или не выпускать.
И последнее, что я хочу сказать – это то, что список наших ошибок в идеале мы должны получать еще на этапе кодирования, до того, как мы поместили наши изменения в хранилище. В других языках такие вещи уже давно поддерживаются на уровне редакторов кода, а для 1С такие инструменты только начинают появляться. Например, это есть в Eclipse, на базе которого построен EDT, а теперь такие инструменты появились и для VSCode.
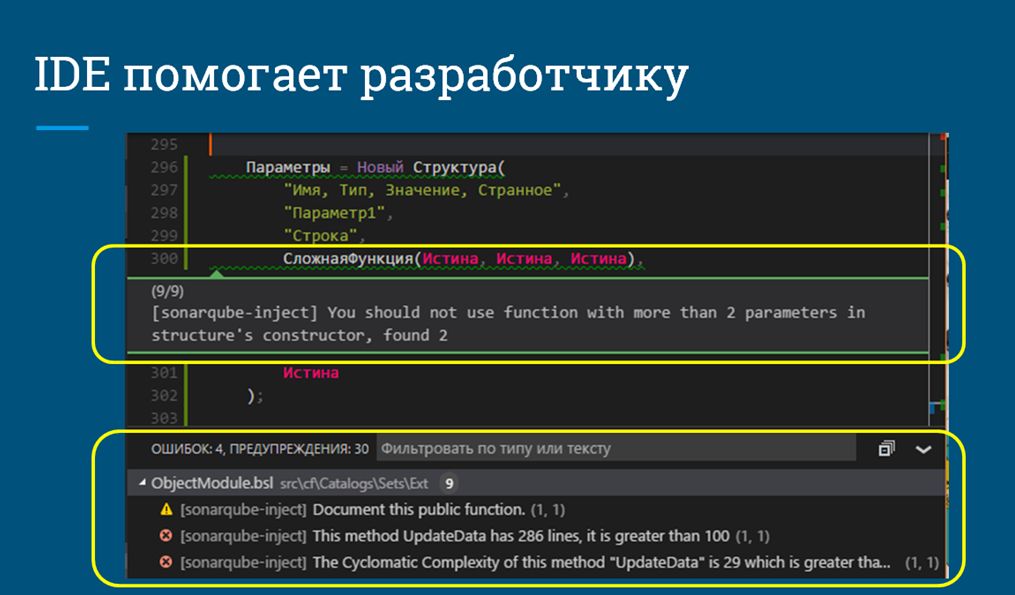
На скриншоте показано, как это может выглядеть: в случае, если вы пишете некачественный код и сохраняете его в файл на диске, то сразу получаете от системы уведомление о том, что что-то не так. При этом вы также можете оценить общую картину того, что у вас происходит не только в этом файле, но во всей системе в целом.
Данная статья написана на основе доклада, представленного автором на конференции Infostart в 2016 году.
Вступайте в нашу телеграмм-группу Инфостарт