



{kind=link}
Добрый день. В данной статье я хотел бы очень крупными мазками обрисовать архитектуру ИТ системы на базе 1С в крупных (более 1 тысячи пользователей) организациях. Она не несет какой либо образовательной цели, это просто попытка показать – «а как у нас».
Часть 1. Архитектура.
Компания владеет крупной сетью магазинов. На текущий момент в сети где то 2700-3000 магазинов со средним количеством рабочих мест 2,4. Значительное количество операций, связанных с обслуживанием клиентов (продажа и замена сим карт, регистрация контрактов, подключение услуг новым абонентам), с товародвижением (приём и отгрузка товара, проведение инвентаризаций), все розничные операции (работа с кассовыми сменами, продажа товара, акционные механики) выполняются в 1С.
Ежедневное количество активных пользователей порядка 7000

количество чеков в пике достигает 300 в минуту, размер базы ~2.6 Тб.
Для обеспечения работоспособности системы создан кластер со следующей архитектурой:
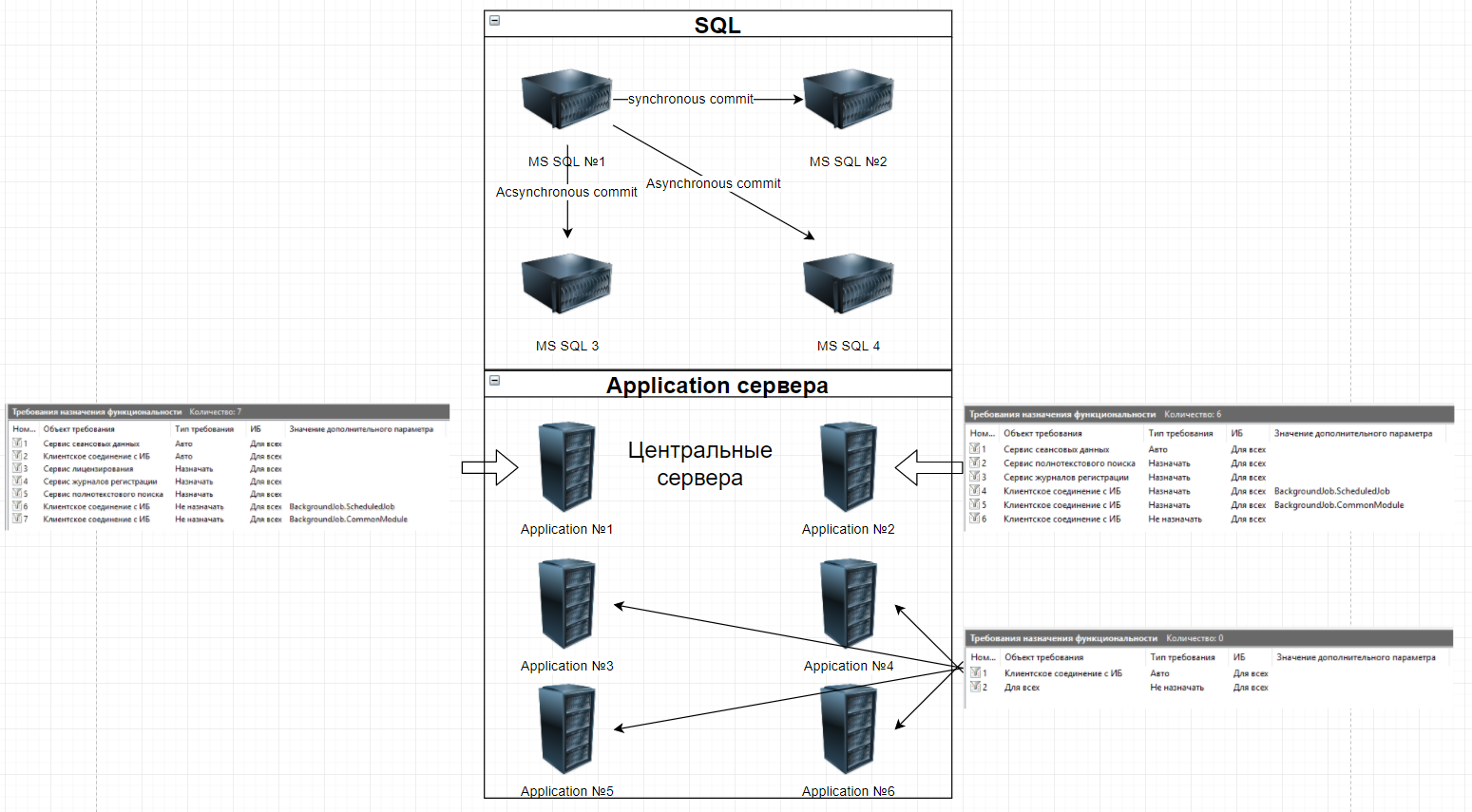
Плюсы решения:
При отказе SQL-сервера активная года автоматически переедет на работающий сервер и работа будет продолжена без прерывания для клиентов (проблему заметят только пользователи, которые запустили транзакцию в момент начала переезда), сам переезд длится порядка 1-2 секунд.
Возможность горизонтального масштабирования application кластера. Добавление нового кластера занимает примерно полдня, но для ускорения процесса в критических ситуациях возможен перевод сервера из тестового стенда в продуктив, на это уйдёт не более 10 минут.
Минусы решения:
Отсутствие полноценной отказоустойчивости. При падении одного из центральных кластеров примерно 50% пользователей получат недоступность системы, им потребуется перезайти в неё.
Особенности:
Дальнейшее я отношу к особенностям решения, а не к минусам, так как изменение архитектуры не может повлиять на ситуацию.
- Практически невозможно в течение дня безболезненно выгнать всех пользователей для срочного обновления. Даже если само обновление конфигурации займет 1 минуту процесс обновления выглядит следующим образом:
- Установка блокировки базы (делается заранее)
- Ожидание, пока все пользователи выйдут из базы (примерно 2-3 минуты с начала блокировки).
- Остановка служб на серверах, где находятся сеансовые данные. (2-3 минуты)
- Очистка сеансовых данных. (1 минута)
- Непосредственно обновление конфигурации. (1 минута)
- Запуск пользователей. (1 минута)
- Стабилизация нагрузки после входа. (3-5 минут)
Таким образом внеплановое обновление занимает в средней 15 минут и всегда связано с высоким стрессом, так как вероятность, что что-то пойдет не так значительно больше нуля, а поправить ситуацию времени нет. Каждая минута — это десятки тысяч рублей недополученной прибыли.
Причина - большой объем сеансовых данных, которые потребуется загрузить одномоментно, в случае если их не очистить (порядка 20 Гб). Практика показала, что система (именно 1С) не справляется с загрузкой такого объема данных за приемлемое время, в результате чего пользователи на протяжении 5-10 минут наблюдают окно с запуском конфигурации.
Для решения данной проблемы мы перешли на 8.3.10 и отказались в конфигурации от режима совместимости (изначально проект стартовал на 8.3.6), так что теперь критичные дефекты выпускаются с помощью расширений, а инциденты закрываются с рекомендацией перезапустить 1С и повторить попытку.
В ближайшее время мы планируем переход на 8.3.12, этим мы хотим закрыть вопрос с падением платформы на клиентах (порядка 2-3 тысяч дампов в день), а также попытаемся с помощью расширений не только исправлять дефекты, но и внедрять новый функционал.
- Зачастую проще оптимизировать нагрузку через создание индексов на уровне SQL, чем пытаться создать их средствами 1С или оптимизировать код. Напоминаю – так делать нельзя, так как это нарушение лицензионной политики 1С.
- Обязательно требуется замерять время обновления, так как несмотря на явный запрет разработчикам добавлять новые реквизиты в большие таблицы иногда всё-таки проскакивают изменения, требующие длительной реструктуризации.
Часть 2. Мониторинг.
Мониторинг мы разделяем на 3 части. 1-ый это стандартный ИТ-шный мониторинг, нагрузка на ЦПУ, занятое ОЗУ, диски, количество таймаутов и дедлоков в единицу времени и прочее-прочее, десятки их.
2 часть – доступность различных внешних ресурсов.
3 часть мониторинга — это бизнес-мониторинг, сюда мы относим:
- Количество чеков в единицу времени.
- Количество замен сим-карт в единицу времени.
- Количество отправленных платежей в единицу времени.
- Среднее время выполнения основных 7 операций.
- Некоторые другие специфические параметры (например отношение ошибочных регистраций контракта к успешным, количество ошибочно подключенных услуг при биллинговых операциях и другие вещи, интересные только внутри компании).
Для сбора информации по 1 и 2 частям мониторинга мы используем конфигурацию «Центр контроля качества», через него же делаем рассылки про основные инциденты, такие как повышенная нагрузка на ЦПУ, появление дампов (падение служб rphost) и пр.
К первой части так же можно отнести сбор логов технологического журнала. Фактически это одно из основных средств для расследования проблем, а также источник данных для сбора части показателей (количество TTimeout и TDeadlock, таймауты и дедлоки на управляемых блокировках, зависание rphost (тут всё достаточно тонко, если будет нужно расскажу дополнительно), среднее (AVG) и общее (SUM) время вызова (CALL и SCALL). Вообще технологический журнал позволяет собирать огромное количество полезной информации, главное научиться парсить многогигабайтные текстовые файлы. У нас за это отвечает отдельный сервис на C#.
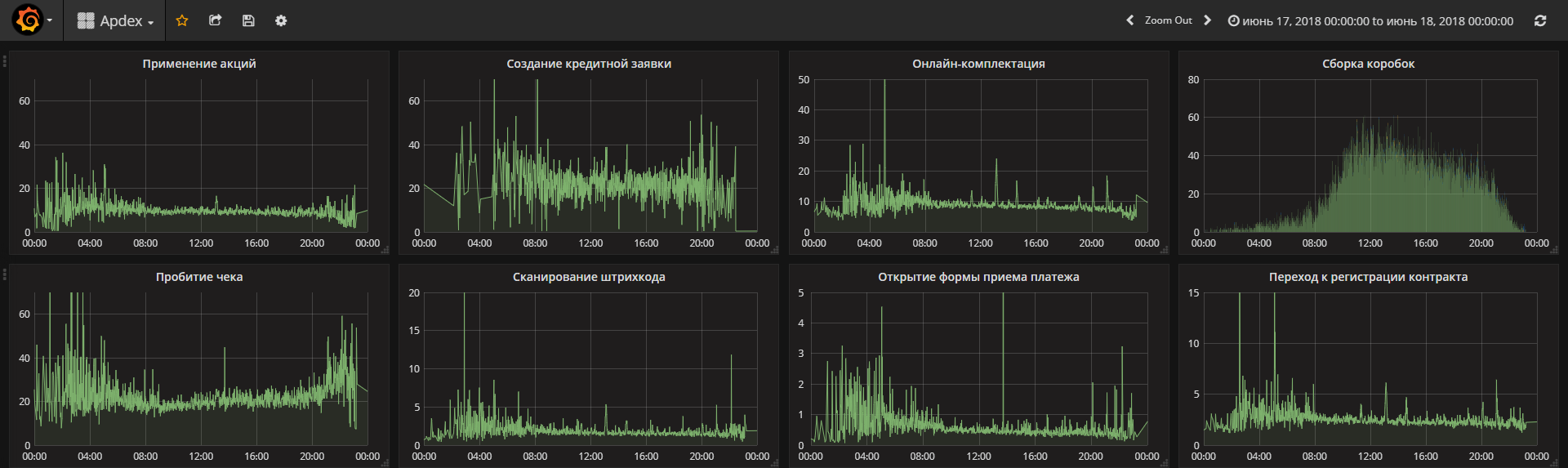
3 часть. Обычно в этой части принято считать apdex, как некий сводный показатель производительности системы, однако мы пришли к выводу что для нас наглядней смотреть просто на среднее время выполнения ключевых операций. Замеры выполняются стандартными средствами 1С и пишутся в регистр сведений, откуда уже читаются прямыми запросами и выводятся в дашборд. Сначала мы пытались изобрести велосипед в части дашбордов, но потом остановились на Grafana. Вот так выглядит график среднего времени выполнения операций за 1 день.

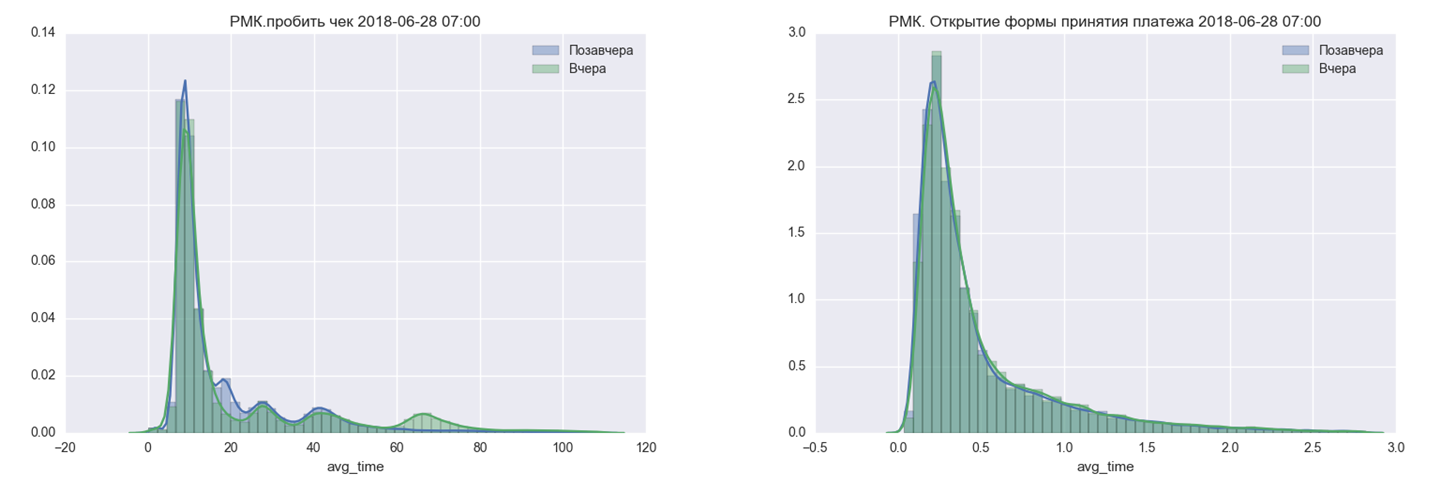
Кроме того ежедневно в почту приходит диаграмма распределения времени выполнения операций за последние два дня, это позволяет быстро понять, не изменилась ли производительность системы.
На этом я закончу вводную часть, если тема интересна – я готов рассказывать некоторые подробности, но так как на проекте уже 3 года информации накопилось очень много, если вы укажете, какое именно направление интересно – я распишу его подробней.