





Найти, найти, найти
Поиск - одна из самых важных задач, которую решает платформа 1С. Чем больше размер баз ы, массив данных в ней, тем острее эта задача.
ы, массив данных в ней, тем острее эта задача.
Стандартные возможности поиска средствами СУБД (будь это файловая база или SQL Server, PostgreSQL) не всегда работают эффективно, а уж тем более не могут удовлетворять условиям гибкого поиска по текстовому содержимому объектов. Да, поиск по индексированным полям решает множество задач, но вот гибкий поиск по текстовому содержимому на уровне СУБД не всегда работает на нужном уровне, особенно если речь идет о платформе 1С. Тут на помощь приходит полнотекстовый поиск платформы!
В серии из нескольких статей мы коснемся различных аспектов работы полнотекстового поиска в контексте платформы 1С. Разберемся зачем он вообще нужен, как работает, где используется и, самое главное, как мы можем его использовать. И хотя на первый взгляд серию статей нужно было бы начать с теории и простейших примеров, но не в этот раз. Мы начнем с "граблей" и боли. Чтобы было интересней.
Ранее на эту тему публиковался инструмент "Мастер полнотекстового поиска", с помощью которого можно управлять настройками полнотекстового индекса и выполнять некоторые расширенные действия. Теперь пришло время для новых публикаций, где мы глубже копнем в теорию и практику использования полнотекстового индекса и даже выйдем немного за границы платформы. Но всему свое время.
Это первая часть публикации по этой теме. Появление продолжения будет зависеть от Вас. Будет интерес - будет и материал :)
И так, на старт, внимание....
Марш! Начнем с проблемы
Вот простая ситуация. В информационной базе создано почти 1 миллион документов "Заказ клиента". Это не плохо и не хорошо само по себе. Менеджеры по продажам каждый день работают со списком заказов, ищут в нем значения по различным полям, подбирают заказы в реализации или отчеты для отборов. В общем, поиск заказов клиентов - операция, которая выполняется даже чаще, чем их создание.
Если база в каком-то смысле "запущена" и не обслуживается в полной мере, то полнотекстовый поиск в ней может быть просто недоступен. Например, он может быть включен, но регламентные задания обновления и слияния полнотекстового индекса отключены. Или же использование полнотекстового индекса полностью выключено. А бывает еще хуже - полнотекстовый индекс используется, задания обновления индекса не включены, но при этом есть неактуальный индекс многолетней давности. В итоге поиск работает, но не находит все значения.
В списке заказов клиента поиск выполняется несколькими способами (чаще всего). Например, нужно найти заказы клиента, у которых в номере есть "85245" и имя клиента содержит слово "Сириус". Вот как это может выглядеть при выключенном / нерабочем полнотекстовом поиске:
Вот так выглядит стандартный поиск, который сейчас по умолчанию добавлен во все формы списков средствами платформы.
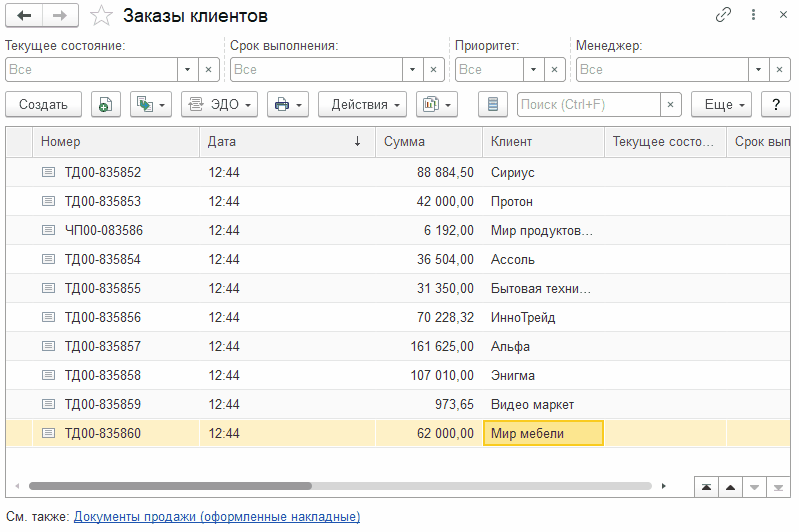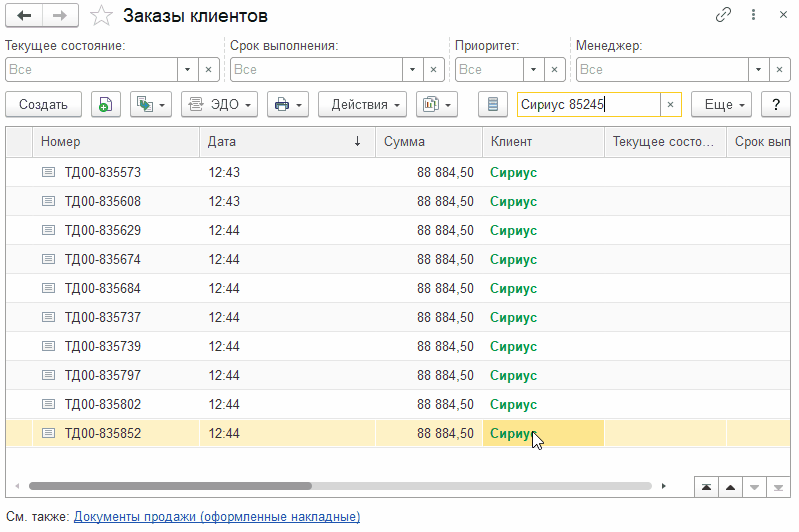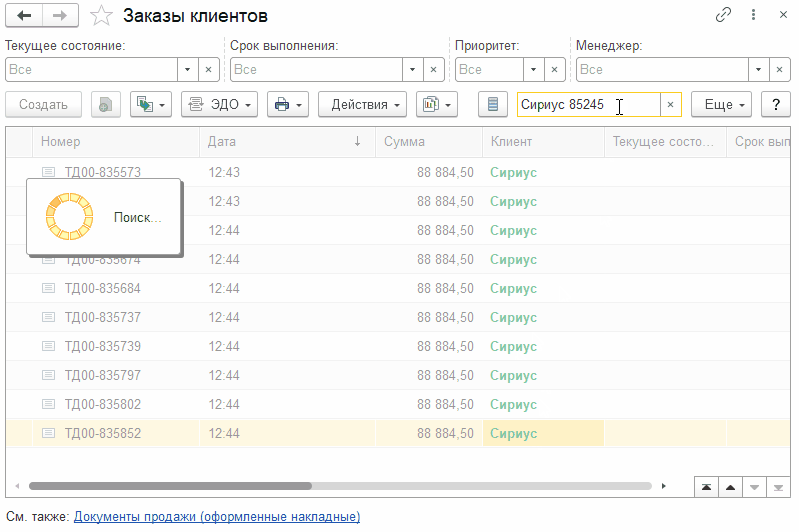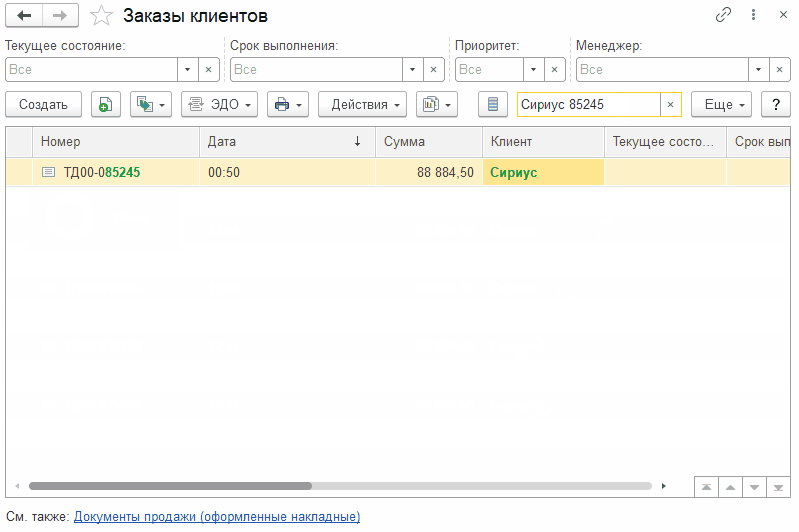 Выглядит достаточно удобно, т.к. искомые значения вводим в одно поле и ждем результата. Да и скорость вроде бы нормальная. Зачем вообще полнотекстовый поиск? К этому мы вернемся чуть позже.
Выглядит достаточно удобно, т.к. искомые значения вводим в одно поле и ждем результата. Да и скорость вроде бы нормальная. Зачем вообще полнотекстовый поиск? К этому мы вернемся чуть позже.
Альтернативный способ, который раньше был основным и вызывался через Ctrl+F - это поиск значений по отдельным колонкам. Да, раньше не было единого поля поиска над списком, но я думаю Вы и так знаете. Вот так это выглядит.
 Этот способ визуально даже быстрее предыдущего. Далее мы также разберем почему. Полнотекстовый индекс в таком варианте никак не используется.
Этот способ визуально даже быстрее предыдущего. Далее мы также разберем почему. Полнотекстовый индекс в таком варианте никак не используется.
Есть и другие способы поиска (через настройку списка, например), но сейчас это не принципиально. Поэтому рассматривать их не будем.
И так, у нас есть два способа поиска, которые на первый взгляд работают быстро и эффективно и, что самое главное, не требуют настройки и обслуживания полнотекстового индекса. Все операции поиска выполняет СУБД. Но, прежде чем радоваться, давайте проверим а что там на уровне базы данных происходит.
Пример №1: Ищем с помощью единого поля поиска
В первом случае, когда мы выполняли поиск через единое поле ввода, платформа 1С сгенерировала очень интересные запросы к базе данных. Да, их было несколько и они очень объемные. Оставил комментарии в той части, которая важна для нашей темы.
И так, платформа 1С сгенерировала аж 4 запроса для поиска по вхождению частей строки "Сириус 85245". Несмотря на то, что SQL-запросы похожи между собой, на самом деле они выполняют разную работу. Вот основные действия платформы в этом случае:
- Платформа формирует SQL-запрос динамического списка и добавляет в него фильтры в соответствии с частями строки поиска.
- Можно выделить основные отборы:
- Отбор по разделителю данных.
- Далее идет отбор по вхождению строки "Сириус" во все строковые поля, которые выводятся в динамический список. Причем это не только поля заказа клиента, но и других таблиц (регистра "Состояния заказов клиента", "Состояние ЭП" и др.
- После идет отбор по вхождению строки "85245" как в строковые поля списка (как в пункте выше), так и устанавливается отбор на числовые поля списка (процент долга, процент оплаты и др.). Причем на числовые поля отборы устанавливаются бессмысленные (значение в полях может быть меньше, равно или больше искомого значения). Есть другие варианты? :)
- Далее в зависимости от 1 из 4 запросов устанавливается особый отбор:
- В первом запросе по определенной дате и ссылке, которая должна быть больше или равна определенного значения.
- Во втором запросе по дате и по ссылке, которая меньше определенного значения.
- Отбора по ссылке уже нет. Только по дате документа, которая должна быть больше определенного значения.
- Отбора по ссылке уже нет. Только по дате документа, которая должна быть меньше определенного значения.
Таким образом платформа 1С пытается разделить получение данных на части:
- Получаем данные на определенную дату вплоть до секунды, но с разными отборами по ссылке.
- Далее получает данные по тем документам, у которых дата больше ранее отбираемого значения.
- На последнем этапе получает данные по документам, у которых дата меньше отбираем значения.
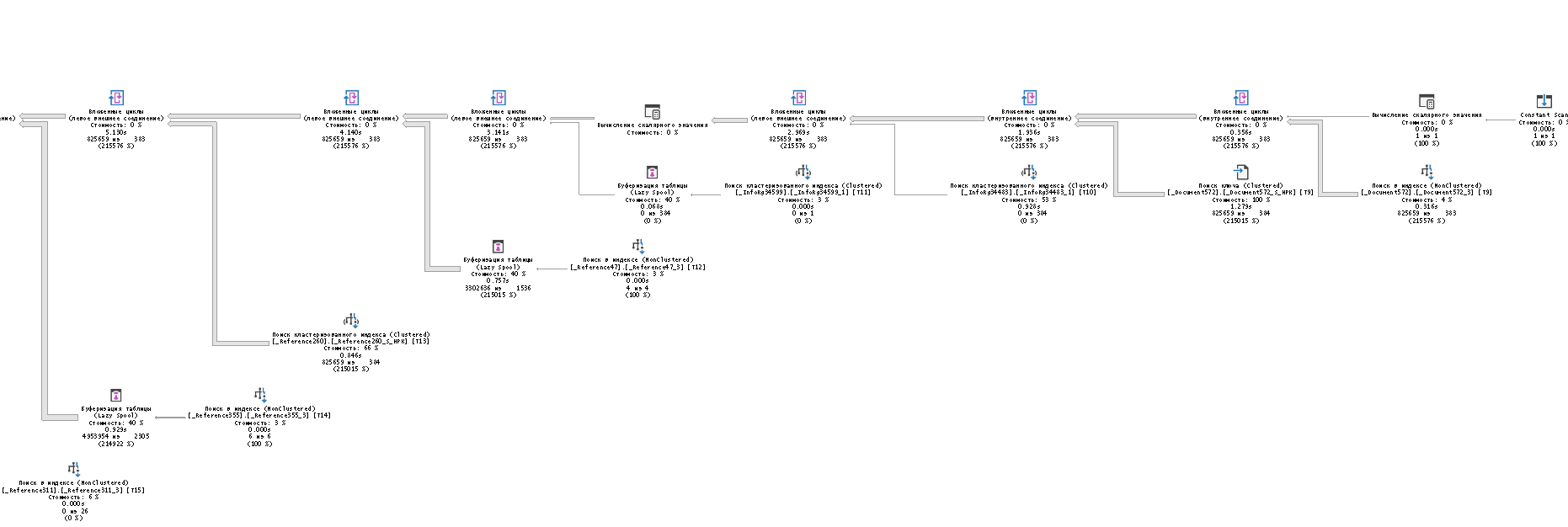
На тех этапах, когда в запросе имеется отбор на равенство конкретной дате документа все в принципе хорошо. Это селективный отбор и индекс по дате документа позволяет получать данные очень эффективно, никаких проблем. Но вот в остальных случаях, когда отбора на равенство по дате нет и вместо него появляется отбор по дате больше (или равно) и меньше определенного значения - тут начинается веселье. Взгляните на монструозный план запроса, который был сгенерирован СУБД для запроса, где дата документа больше определенного значения (см. запрос №3).
Для конкретно нашего примера запрос "съел" весомые ресурсы:
- Выполнялся примерно 8 секунд (CPU 8157 мс).
- Прочитаны все записи таблицы заказов клиентов.
- Использовал 10119361 страниц памяти (reads). А если вспомнить что каждая страница 8 КБ, то...
В общем, как видно стандартный поиск в списках через единое поле ввода может создавать тяжелые по использованию ресурсов запросы, которые могут поспорить со многими тяжелыми аналитически отчетами. Что самое удивительное - в нашем примере платформа 1С сгенерировала два тяжелых запроса: один с отбором по дате больше указанной даты документа, а второй с отбором меньше заданного значения. По затраченным ресурсам они практически не отличаются.
А ведь у нас искусственный пример, где поиск выполнялся одним пользователем. В многопользовательской среде все куда хуже!
Пример №2: Ищем с помощью отборов в отдельных колонках
Тут все значительно проще в части диагностики, чем в первом примере. Если мы устанавливаем отбор по двум колонкам через Altf+F, то платформа также генерирует 4 запроса по тем же принципам, что и выше. Но в этот раз отбор по искомым значениям в SQL-запросе иной. Не буду приводить все сформированные SQL-запросы, остановимся лишь на 1 самом "тяжелом".
Запрос стал проще и вместо страшных комбинаций условий отборов из предыдущего примера у нас появились конкретные условия по номеру документа и имени клиента (партнера). Запрос стал "кушать" меньше ресурсов:
- Время выполнения примерно 2 секунды (CPU 2234 мс)
- Прочитаны все записи таблицы заказов клиентов.
- Общее количество прочитанных страниц 3514415.
Фактически, запрос выполняется в 4 раза быстрее, чем то что было выполнено в примере ранее. Но запрос все равно "съедает" непростительный объем ресурсов, особенно критичный для многопользовательской информационной системы.
Но можно ли такие операции поиска как-то оптимизировать?
Что обычно приходит в голову
Мы еще не добрались до полнотекстового поиска, нужно еще потерпеть. Обычно, когда разработчики сталкиваются с подобными проблемами тяжелых операций поиска, то первое что они предлагают - это ограничить функционал динамических списков и убрать возможность выполнять поиска вышеописанными методами.
Что это значит? Да очень просто:
- Поиск через Ctrl+F и Alt+F больше невозможно выполнить. Стандартное поле поиска вверху списка убирают полностью.
- Также запрещают использовать гибкий поиск через "Все действия -> Настроить список"
- В шапку формы списка выводят несколько полей, по которым можно выполнять поиск. При этом отборы устанавливаются строго определенного типа (равно, начинается с...). Делается это для того, чтобы условия отборов могли использовать индексы. Как известно, условия "ПОДОБНО %<тут значение>%" не используют индексы.
Профит!
Но работает это только в том случае, если бизнес согласен на такое. Тем более нужны будут доработки (даже если это делается расширениями). Да и сделать это во всех списках не всегда возможно, а еще остается поиск при вводе по строке...
В общем, решение может помочь, но чтобы довести его до ума придется потратить время как на разработку, так и на последующее сопровождение.
А вот и полнотекстовый поиск!
Как Вы могли увидеть, гибкий поиск по текстовому содержимому объектов обрабатывается СУБД не самым лучшим образом. И это нормально! Оператор поиска "LIKE" и не предназначен для такой задачи. На стороне СУБД для таких целей есть собственные движки полнотекстового поиска, которые платформа 1С не использует. Вместо этого фирма "1С" пошла своим путем и создала собственный движок для полнотекстового поиска данных, который мы и можем использовать для оптимизации подобного рода операций.
Тем более по умолчанию подразумевается, что поле поиска в тех же динамических списках будет использовать именно полнотекстовый поиск, а не возможности СУБД. Во многих базах (файловых и клиент-серверных) полнотекстовый индекс строится и обслуживается с помощью регламентных заданий и пользователи, разработчики, админы об этом могут просто не знать. Работает - не трогай, как говорится :).
Но чтобы убедиться, что построение и использование индекса полнотекстового поиска исправит наши тяжелые запросы выше - проведем эксперимент. Построим индекс полнотекстового поиска (я использовал инструмент "Мастер полнотекстового поиска", но никто не мешает Вам использовать стандартные обработки платформы). Размер индекса для всей базы с почти миллионом заказов клиента получился равным 7 ГБ.
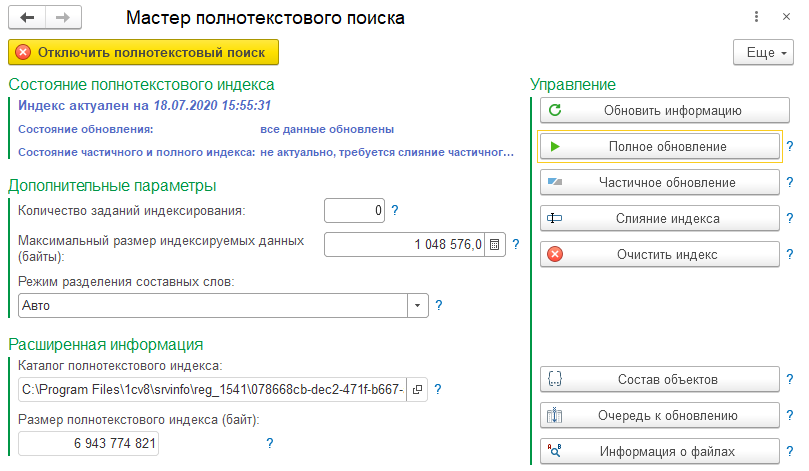 Но рано радоваться, нужно проверить поможет ли полнотекстовый индекс в нашем конкретном случае.
Но рано радоваться, нужно проверить поможет ли полнотекстовый индекс в нашем конкретном случае.
Еще один эксперимент
А теперь выполним поиск через Ctrl+F как это делали ранее и посмотрим что на уровне базы данных. Повторный поиск через Alt+F делать не будем, т.к. поиск по конкретным колонкам всегда выполняется с помощью средств СУБД. А вот поиск через поле поиска - то что нужно.
 Ничего не изменилось! Платформа генерирует те же самые тяжелые SQL-запросы, что в самом первом примере. Полнотекстовый поиск никак не используется! Даже визуально видно, что поиск занимает такое же количество времени. Давайте попробуем кое-что изменить.
Ничего не изменилось! Платформа генерирует те же самые тяжелые SQL-запросы, что в самом первом примере. Полнотекстовый поиск никак не используется! Даже визуально видно, что поиск занимает такое же количество времени. Давайте попробуем кое-что изменить.
Попробуем выполнить поиск только по части номера - "85245". Сразу скажу результат - снова ничего не изменилось. Платформа также настойчиво генерирует "страшные" SQL-запросы и игнорирует полнотекстовый индекс.
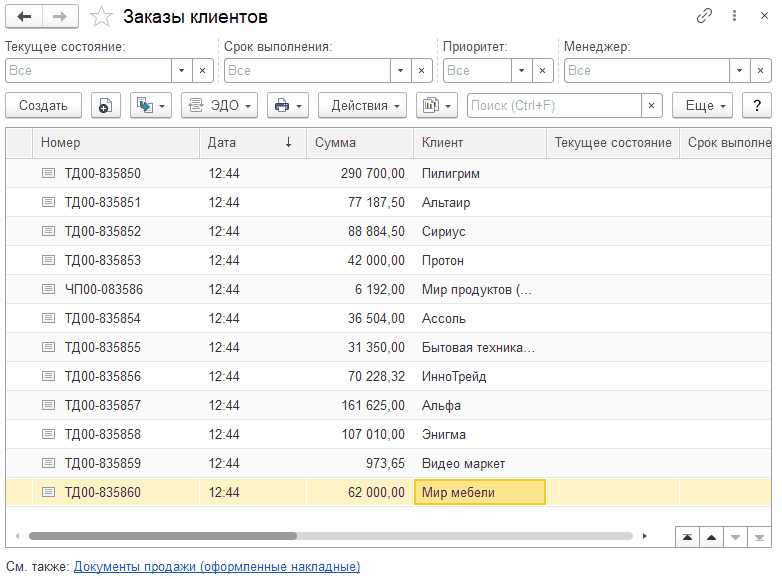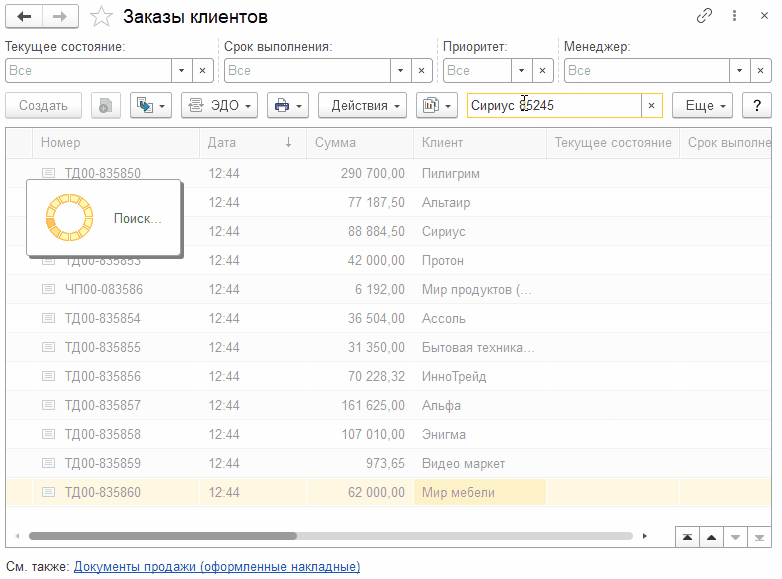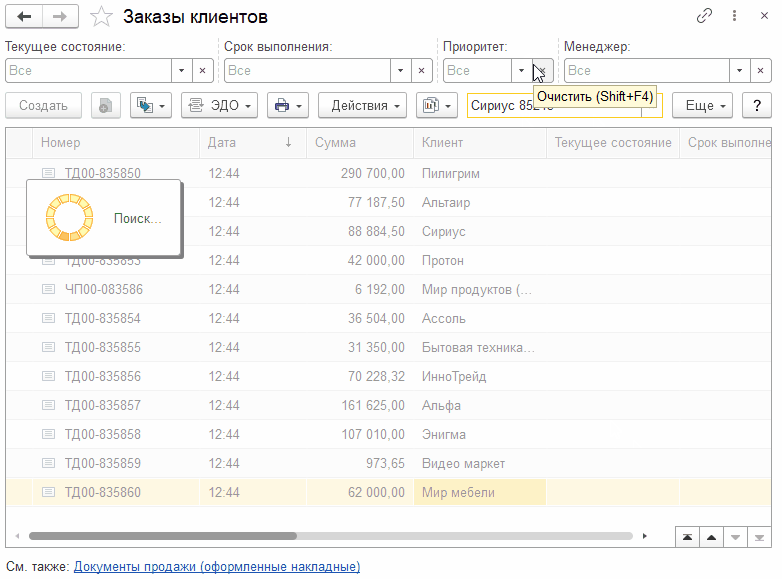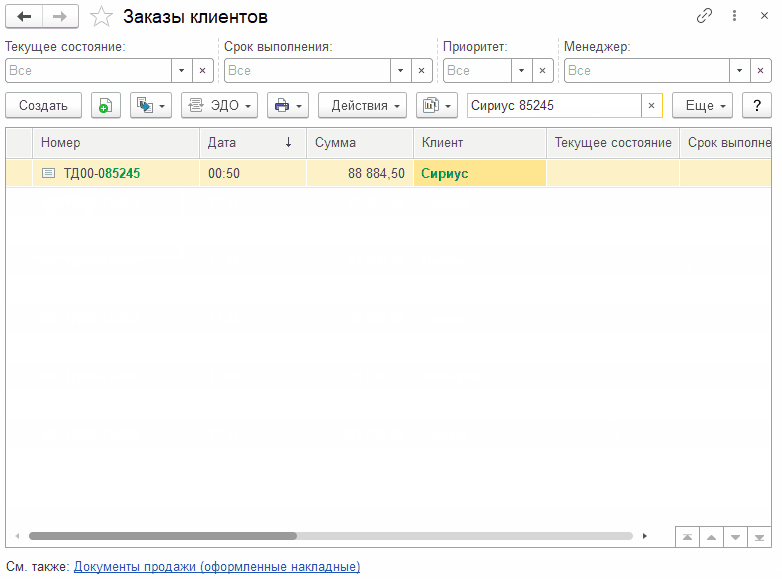
Идем дальше и через "Еще -> Изменить форму" оставляем в списке только колонки "Номер", "Дата", "Сумма", "Клиент". Эти поля 100% есть в составе заказа клиента и не получаются из сторонних таблиц, как например статусы заказа. Пытаемся выполнить поиск еще раз и...
 Поиск отработал практически мгновенно! То, что нам нужно! При этом на стороне базы данных сформированы также 4 аналогичных запроса, но в них появились отборы по ссылкам. Это порции данных, которые были найдены с помощью полнотекстового поиска.
Поиск отработал практически мгновенно! То, что нам нужно! При этом на стороне базы данных сформированы также 4 аналогичных запроса, но в них появились отборы по ссылкам. Это порции данных, которые были найдены с помощью полнотекстового поиска.
А вот если попробовать ввести строку поиска "Сириус 85245", то полнотекстовый поиск снова игнорируется и платформа опять (или снова) лезет с тяжелым запросом к базе данных.
Что все это значит?
В официальной документации сказано, что использование полнотекстового индекса в поиске динамического списка имеет следующие нюансы:
- Полнотекстовый поиск должен быть включен для всех объектов, которые участвуют в запросе списка и могут использоваться в качестве основной таблицы. При этом все поля, выводимые в список, должны также быть с включенным полнотекстовым поиском.
- Полнотекстовый индекс должен обслуживаться должным образом (не забыть настроить регл. задания).
- Поиск выполняется по колонкам, которые отображаются в таблице.
- Поиск по ссылочным полям выполняется по полям представления, которые также должны быть добавлены в полнотекстовый индекс.
- Сначала выполняется поиск по основной таблице. К результатам полнотекстового поиска добавляются все непроиндексированные ссылки из основной таблицы. Результат полнотекстового поиска используется для отборов по ключевым полям.
- При возникновении ошибок полнотекстового поиска режим поиска переключается на стандартных механизм, то есть с помощью средств баз данных.
- Если есть отборы "Равно", то они в любом случае добавляются в финальный запрос с учетом отбора по результатам полнотекстового поиска.
- Строка поиска разбивается на слова (максимум 20) и не должна превышать 1000 символов. Пробел и табуляция - разделители слов. Для каждого фрагмента создается свой набор условий по ИЛИ. Все фрагменты соединяются в И.
Часть из этих правил Вы могли увидеть в примерах выше, в т.ч. разбиение условий на фрагменты в запросах и так далее. Но почему в нашем случае полнотекстовый поиск не срабатывал, если указать имя партнера в строке поиска?
Причина для этого была только одна: в запросе имеются условия соединения и поля с регистрами сведений со статусами заказов и ЭП. Эти таблицы не проиндексированы. Причем эти поля использовались в запросе даже если убрать их из списка выводимых полей через "Изменить форму". Решение - упростить запрос в списке, удалив эти регистры, и все должно заработать. Ну или проиндексировать их.
Все так просто?
К сожалению, нет. Именно в этом примере нам повезло и мы нашли причину. Но бывают ситуации куда сложнее. Ситуация еще может усугубляться особенностями версии платформы и режимом совместимости. Например:
- Платформа 8.3.12 с конфигурацией с совместимостью 8.3.4 в некоторых случаях может вообще не выполнять поиск. Также в этой версии не работает ограничение по метаданным для полнотекстового поиска. Если фильтр установлен, то возвращается пустой результат.
- Также в одной из новых версий платформ не выполнялся полнотекстовый поиск по ссылочным полям, только по непосредственно полям основной таблицы.
Отлаживать такое поведение очень сложно и часто поиск причин выполняется по знаменитой методике "Метод тыка". А самое тяжелое здесь то, что даже типовые конфигурации не гарантируют, что в динамических списках будет работать полнотекстовый поиск. В примерах выше была конфигурация УТ 11. А если там все и работает корректно, то кто знает когда это может сломаться...
В высоконагруженных системах поиск в динамических списках может быть очень опасен, создавая повышенную нагрузку на всю систему в самых непредсказуемых проявлениях. Полнотекстовый поиск то может работать, а может и нет :) Особенно после обновления платформы!
 Только начало
Только начало
Конечно, может стоило начать серию статей по полнотекстовому поиску в 1С с базовых теоретических знаний и примеров. Но на мой взгляд лучше сразу начать с хардкора.
В следующих статьях, если данная тема будет интересна сообществу, мы рассмотрим такие темы как:
- Программная работа с полнотекстовым поиском
- Сопровождение полнотекстового индекса и контроль его работы
- Продвинутая отладка работы полнотекстового поиска в списка и других местах конфигурации
- Как используется полнотекстовый поиск в типовых конфигурациях
- Особенности обновления платформы в контексте полнотекстового поиска
- Полнотекстовый поиск нестандартными средствами
- Несколько кейсов по производительности платформы 1С при работе с полнотекстовым индексом
- Как можно сломать полнотекстовый индекс на пустом месте.
А Вы используйте штатный полнотекстовый поиск 1С? Дайте знать в комментариях :) Любые вопросы, предложения по этой теме приветствуются :)
Другие ссылки
- "Улучшение" поиска в динамических списках в 8.3.5
- Мастер полнотекстового поиска - набор инструментов для работы с полнотекстовым индексом платформы 1С. Стандартные и расширенные возможности.
-
Очистка и обновление индекса полнотекстового поиска (регламентное задание)
-
Возвращение старого поиска в новых релизах Бухгалтерии предприятия 3.0
Авторские разработки
-
Транслятор запросов 1С в SQL - инструмент для трансляции запросов платформы 1С в SQL, а также их диагностики.
-
Просмотр и анализ структуры базы данных (отчет на СКД) - отчет для просмотра и анализа структуры базы данных с поддержкой файловых баз (ограниченный режим), а также баз на SQL Server и PostgreSQL.
-
Просмотр и анализ журнала регистрации (отчет на СКД) - отчет на базе системы компоновки данных (СКД) для просмотра записей журнала регистрации.
-
История работы пользователей (отчет на СКД) - отчет для просмотра истории работы пользователей (СКД, просмотр для любого пользователя).
-
Экспорт журнала регистрации. Набор инструментов (приложения + исходный код) - набор инструментов для экспорта данных журнала регистрации во внешние хранилища для Windows и Linux. Готовые приложения и исходный код.
-
Технические проверки данных регистров бухгалтерии (отчет на СКД) - отчет для технических проверок данных бухгалтерских регистров.
-
Путеводитель по истории релизов - отчет по истории выпуска релизов продуктов фирмы "1С" и анализа информации по обновлениям.
- Помощник работы с идентификаторами объектов - инструмент для расширенного анализа идентификаторов объектов.
-
Информация о пользователях информационной базы (отчет на СКД) - два простых отчета по пользователям информационной базы и информации по ним.
-
Анализ производительности APDEX (бесплатный) - отчет для просмотра и анализа замеров производительности в конфигурациях на базе БСП.
-
Обозреватель криптографии - отчет для просмотра доступных провайдеров и сертификатов криптографии на сервере и клиенте.
-
Пакетная выгрузка / загрузка внешних отчетов и обработок - пакетная выгрузка / загрузка внешних отчетов и обработок для массовый манипуляций с ними.
-
Мастер полнотекстового поиска - набор инструментов для работы с полнотекстовым индексом платформы 1С. Стандартные и расширенные возможности.
-
Командный интерпретатор для 1С - инструмент для выполнения команд CMD / PowerShell из 1С
Вступайте в нашу телеграмм-группу Инфостарт