



Исходная ситуация: несколько самописных конфигураций в автоматическом режиме, блокировки в наличии в угрожающих масштабах, надо как-то ловить.
Способ ловли был выбран следующий: раз в десять секунд делаем снимок select * from master..sysprocesses во времянку, обрабатываем (оставляем инфу по blocked <>0 и процессам, которые сами не заблокированы, но фигурируют в blocked - источники блокировок, headblockers). Выходит что-то вроде //infostart.ru/public/193674/.
Ловля автоматических блокировок:
Подготовка данных (в тестовой бд, или в tempdb)
CREATE TABLE _test(a int, b int, c int)
declare @i int = 0, @j int = 0
while @i < 120 begin
set @j = 0
while @j < 120 begin
INSERT INTO _test(a, b, c) VALUES (@i, @j, 100)
set @j = @j +1;
end
set @i = @i +1;
end
В первом окне запускаем
select count(distinct t1.a) from _test t1 with(updlock) inner join _test t2 on 1=1 inner join _test t3 on 1=1 option(maxdop 1)
Во втором окне запускаем (пока в первом запрос еще исполняется)
select count(distinct t1.a) from _test t1 with(updlock)
И в третьем окне мониторим наши блокировки запросом
select spid, sqltxt = cast(st2.text as varchar(max)), *
from
master..sysprocesses sp
left join master.sys.dm_exec_requests er
on sp.spid = er.session_id
outer apply sys.dm_exec_sql_text (er.sql_handle) st2
where
sp.dbid = 2 -- если tempDB, иначе поменять
and
(0=1
or ( sp.spid > 50 and sp.blocked not in (sp.spid,0) )
or ( exists (select * from master..sysprocesses sp2 where sp2.blocked = sp.spid ) )
)
Наблюдаем что-то похожее на

Видно, что сессия 53 блокирует сессию 54, видно текст блокирующего запроса, статус блокирующего запроса (runnable) и ожидание (SOS_SCHEDULER_YIELD - процессора не хватает, да еще и maxdop зажат). Ну и табличную блокировку видно (TAB) в tempDB (2)
Понятная и прозрачная ситуация.
Несколько видоизменяем первый пример
В первом окне запускаем то, что исполнится, заблокирует, и продолжит висеть, ничего не делая, но и не завершая транзакции.
begin tran
select sum(t1.a) from _test t1 with(updlock) option(maxdop 1)
--commit tran
Во втором окне - все то же
select count(distinct t1.a) from _test t1 with(updlock)
Выявляющий блокировки запрос в третьем окне теперь показывает что-то вроде

Не очень информативно - не видно исполнившийся запрос
Модифицируем выявляющий запрос вот так
select
sqltxt_pred = cast(st1.text as varchar(max)),
sqltxt = cast(st2.text as varchar(max)),
*
from
master..sysprocesses sp
left join master.sys.dm_exec_requests er
on sp.spid = er.session_id
outer apply sys.dm_exec_sql_text (sp.sql_handle) st1
outer apply sys.dm_exec_sql_text (er.sql_handle) st2
where
sp.dbid = 2
and
(0=1
or ( sp.spid > 50 and sp.blocked not in (sp.spid,0) )
or ( exists (select * from master..sysprocesses sp2 where sp2.blocked = sp.spid ) )
)
Теперь картинка гораздо информативней

Таким образом, из master..sysprocesses можно вытащить и текст исполняющегося в настоящий момент запроса, и текст всего пакета.
Собственно, примерно тоже самое можно сделать и с помощью DMV (most_recent_sql_handle в sys.dm_exec_connections и sql_handle sys.dm_exec_requests).
Но, задача была не "следить непрерывно за консолью и при появлении блокировок выяснять - кто автор", а "анализ блокировок за период с ранжированием источников (headblockers)".
Значит, кроме фиксации spid, blocked, sqltxt_pred, sqltxt требуется
1. обработать текст запроса как в https://kb.1c.ru/articleView.jsp?id=76 (Листинг fn_GetSQLHash.. но предпочтительней делать на C# или C++, t-sql все же не лучший выбор для обработки строк)
2. собрать сведения из техжурнала 1С (событие <eq property="name" value="dbmssql"/>) и состыковать со снимками блокировок
Настройка ТЖ вида
<log history="2" location="D:\Server1C\logsLong">
<event>
<eq property="name" value="dbmssql"/>
<gt property="duration" value="10000"/>
</event>
<property name="all"/>
</log>
выдает файлы примерно такого содержимого:
00:16.1966-58122,DBMSSQL,3,process=rphost,p:processName=СклУпр,t:clientID=3208,t:applicationName=BackgroundJob,t:connectID=44967,SessionID=29950,Usr=Фоновое__Обмен,Trans=0,dbpid=457,Sql='INSERT INTO #tt13 (_Q_001_F_000RRef, _Q_001_F_001RRef) SELECT DISTINCT
T1._Reference5235_IDRRef,
T1._Fld6417RRef
FROM _Reference5236_VT6415 T1 WITH(NOLOCK)
WHERE T1._Fld6419 = 0x01',Rows=0,RowsAffected=68785,Context='
ОбщийМодуль.РегламентныеЗадания_Обмен.Модуль : 134 : Результат = ПолучитьРезультатВычисления(Выражение,,,СтруктураВозврата);
ВнешняяОбработка.ВыполнениеКоманд.МодульОбъекта : 1022 : РезультатыЗапроса = ДанныеПоЗапросу.ВыполнитьПакет();'
Имя файла \\SERV1\Server1C\logsLong\rphost_565304\19062412.log
Для связи с конкретной строкой дерева блокировок берем:
- датувремя события (имя файла 19062412.log + первая строка 00:16.1966 = 2019.06.24 12:00:16 ) и длительность 58122 (в данном случае это 5 секунд для 8.2, для 8.3 было бы в микросекундах) - дерево должно укладываться в период "датавремя - длительность" - "датавремя"
- dbpid=457 - должно соответствовать spid = 457 (или session_id = 457 - если берем дерево не из sysprocesses, а запросом из DMV)
- имя сервера 1С, с которого взят лог ТЖ (в примере это SERV1) - должно соответствовать hostname строки дерева
- ID рабочего процесса (из rphost_565304 следует id = 565304) - должно соответствовать hostprocess
3. записать снимок в бд - вместе с датой-временем снимка, текстом запроса и контекстом 1С
И далее просто написать запрос, группирующий по fn_GetSQLHash от текстов запросов (исполняющегося и предыдущего исполненного в данной сессии). И чем суммарно больше жертв - тем больше рейтинг источника блокировок (он же "headblocker", он же "виновник", он же "причина".. кто как обзывает)
Вот ссылка на реализацию (свежая версия - с ловлей блокировок)
Ниже на видео - самый простой случай - долго исполняющийся запрос.
Длительный сканирующий запрос заблокировал регламентное задание переиндексации, переиндексация заблокировала далее кучу сеансов (до 80 в пике)
//infostart.ru/upload/iblock/ac8/ac85c0adb5c12a26c1d28d1df809cbfb.gif
Подробней:
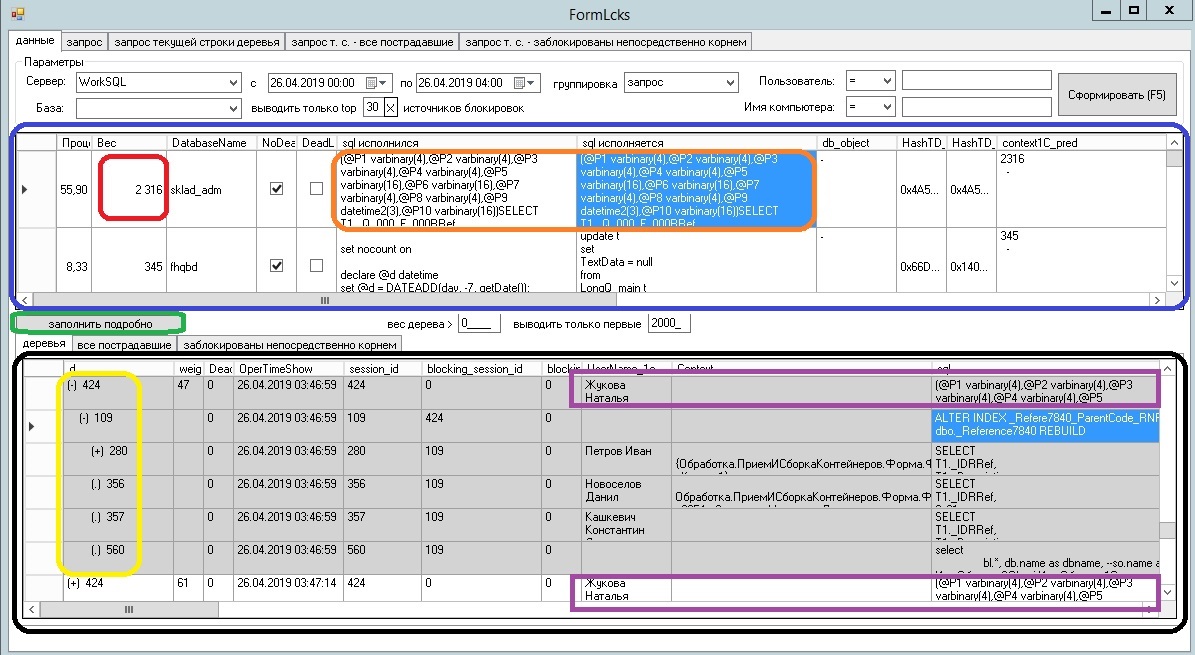 В верхней части указывается sql-сервер и период (26 апреля от полуночи до 4 утра были проблемы на WorkSQL)
В верхней части указывается sql-сервер и период (26 апреля от полуночи до 4 утра были проблемы на WorkSQL)
Первая таблица (выделено синим) содержит источники блокировок за указанный период на искомом сервере. Источники блокировок (headblockers) упорядочены по весу - сверху наиболее тяжелые. В качестве веса (выделено красным) - количество заблокированных сессий суммарно за период. Т.е. если за 4 часа зафиксировано три дерева блокировок, в которых одна сессия блокирует пять жертв - то вес у данного сочетания "sql исполнился = sql исполняется" (выделено оранжевым) равен 15. Отсюда можно примерно вычислить время простоя жертв суммарно (деревья фиксируются раз в 10 секунд - значит, время простоя жертв = 15*10 сек ). Кнопка "заполнить подробно" (выделено зеленым) заполняет нижнюю таблицу - с уже конкретными деревьями блокировок (на удивление, в c# нет стандартного аналога "дерева значений" из 1С.. пришлось изобразить что-то похожее вручную). Деревья можно разворачивать и просматривать информацию о жертвах.
В данном случае видно, что все деревья начинаются с "Жукова Наталья" (позже нашел, что она запускала - запрос из консоли отчетов), она блокирует job переиндексации рабочей бд, переиндексация блокирует далее всех (ну, не всех - но многих).
Подобные проблемы излечиваются чаще оптимизацией длительных запросов (в инструменте реализован переход от дерева блокировки к плану запроса), реже разрывом или устранением транзакции (если явная) / выносом кода из транзакции проведения/записи, еще реже - если это сложные случаи вроде "блокировки через переиндексацию" - рассматриваются индивидуально.
1С просто и незатейливо советует sp_msforeachtable N'DBCC DBREINDEX (''?'')' (или уже есть более свежая статья?). Microsoft настойчиво рекомендует схему "avg_fragmentation_in_percent > 5% and < = 30% - REORGANIZE, > 30% - REBUILD". На infostart.ru светится "10%-30%", "5%-30%".
И практически на всех рабочих серверах, кои мне доводилось видеть - работает то самое 5%-30% - в виде версии от Микрософт, или скрипты шведского товарища Ola Hallengren, или что-то самописное на том же принципе. Реже встречается sp_msforeachtable. На тестовых серверах, как правило, чаще метод "мы забили на регламентное обслуживание"..
Для мелких баз с хорошими технологическими окнами - Ola Hallengren самое то. Работает по ночам, есть не просит.
Но вот для террабайтных высоконагруженных, работающих "24/7/почти 365" - все далеко не так радужно.
Вот с чем сталкивался:
- Само обращение к sys.dm_db_index_physical_stats даже с ''LIMITED'' - весьма неплохо съедает память (буферпул) sql-сервера. Далее возможны задержки непричастных запросов на физ чтениях, пока буферпул опять наполняется "нормальными" данными
- Ошибки вида Msg 9002, The transaction log for database '...' is full due to 'ACTIVE_TRANSACTION'. - иной раз не лезет индекс в данное админом пространство под лог
- Ошибки вида Msg 9002, The transaction log for database '...' is full due to 'LOG_BACKUP' - и, соответственно, реплики на резервных серверах могут становиться сильно неактуальными... Даже без данных завалов из-за массивных переиндексаций может быть отставание реплик в AlwaysOn
- И, самое болезненное - собственно, блокировки на REBUILD. Особенно для редакций Standart - нет with(online = on) и тем более WAIT_AT_LOW_PRIORITY, сам ребилд идет в один поток (и коль заблокирует кого - то надолго). И даже в версии Enterprise с with(online = on) - блокировки все равно в наличии! Будили ночью, любовался. Собственно, в документации оно вполне отражено.
Обычный сценарий блокировок под для Standart - некий кривоватый запрос (даже вне транзакции, с хинтами with(nolock)) блокирует alter index..rebuild , далее alter index блокирует всех. Пробовал бороться с теми самыми "кривоватыми запросами" - легион их. Пробовал писать джоб, убивающий "кривоватые запросы", мешающие переиндексации - работает.. но однажды оно убило весьма важный процесс - отключил. Перенастроил джоб для "самых важных баз", чтобы он убивал саму реиндексацию - аналог WAIT_AT_LOW_PRIORITY ( MAX_DURATION = 1 MINUTES, ABORT_AFTER_WAIT = SELF ) - работает... но, понятное дело - не идеал.
Т.е. стандартная модель переиндексации понемногу перестает устраивать.
Вот и Brent Ozar еще в 2012 сомневался - а тогда еще не было широкого распространения ssd.
В настоящий момент думаю в сторону "реиндексации того, что в текущий момент сидит в оперативке (в буферпуле) - с целью минимизации размера индекса (и память освободим, и чтений меньше)".. также понемногу задираю пороги ("5-30" веду к "40-50") и отслеживаю изменение скорости типовых запросов - посмотрим, что будет..
Опять-таки, Микрософт тоже ощущает, видимо, данную проблему.. Появление WAIT_AT_LOW_PRIORITY в MS SQL Server 2014 и RESUMABLE=ON в MS SQL Server 2017 как бы намекает. Жаль только, что все это не для standart (enterprise дорогой и в наличии далеко не на всех серверах).
Случай посложнее - когда блокировка висит на спящей сессии (поле "sql исполняется" пустое).
Сделан искусственно кодом
НачатьТранзакцию();
запрос = Новый Запрос;
запрос.Текст = " ВЫБРАТЬ С.Ссылка ИЗ Документ.СборкаПродукции КАК С ГДЕ С.Дата > &Дата ДЛЯ ИЗМЕНЕНИЯ Документ.СборкаПродукции";
запрос.УстановитьПараметр("Дата", ТекущаяДата()-60*60*2);
рез = запрос.Выполнить();
выборка = рез.Выбрать();
Предупреждение("ждем..");
ОтменитьТранзакцию();

По REPEATABLEREAD видно, что конфигурация в автоматическом режиме, ДЛЯ ИЗМЕНЕНИЯ трансформировалось в UPDLOCK.
Подобные случаи определяются поиском запроса "sql исполнился" в конфигурации, в транзакциях платформы и в явных. Если вхождений немного - то баг можно найти визуально, изучением последующего за запросом кода. Если много вхождений - вопрос решается логгированием.
Чего только не находилось за последние несколько лет в транзакциях проведения документов или записи набора регистров:
- Предупреждение() или Вопрос() - это самое любимое
- вывод на печать на принтер (ага, прям в транзакции.. и потом появляются претензии "на бумаге написано что в документе одно, а в базу залезешь - там другое" - это при откате таких блокирующих транзакций)
- разнообразные файловые операции
- обращения к другим базам через com-объекты
- обращения к другим базам посредством Новый COMОбъект("ADODB.Connection") (ага, а на соседнем сервере уже запрос через то самое ADODB... тоже висит на блокировке! и такое было..)
- работа с ftp
- обращение к web-сервису
- запуск на исполнение сторонних программ
Отдельно стоит упомянуть эскалацию блокировок на уровне sql-сервера. Неважно, на спящей или на running/runable сессии возникли блокировки - стоит смотреть на поле waitresource (или wait_resource из sys.dm_exec_requests). Если там TAB: (Object()) - то скорее всего мы нарвались на эскалацию. Чаще всеж стоит поправить прочитавший таблицу запрос - с большой вероятностью он кривой и сканирующий .. но иногда можно и выключить эскалацию на уровне таблицы. Если будете выключать - это небезопасно, пару раз у меня вылезала нехватка оперативки для sql-сервера при реструктуризации такой таблицы (саму идею эскалации ведь не просто так придумали).
Итого.
По сообщениям пользователей вида "мы зависли" определялось наличие/отсутствие деревьев блокировок, при наличии - почти всегда обнаруживалась явная причина. И устранялась. Плюс еженедельно просмотр статистики по блокировкам за 7 дней + тоже поиск причин и устранение. И так несколько лет.
В итоге получилось, что несколько конфигураций в автоматическом режиме работают "почти нормально", "почти без блокировок", но есть несколько "но":
- куча случаев вида "запрос к небольшой табличке внезапно стал сканирующим и блокирующим".. и отладить всю эту мелочь - никакого времени не хватит.
- крупные транзакции, запросы в которых уже "вылизаны до блеска", но разорвать их - или никак, или оч дорого.
- много программистов непрерывно добавляют новый / модифицируют старый код, стоит ошибиться в запросе - любом запросе - в транзакции популярного (часто проводимого) документа - и имеем коллапс рабочей бд (да, нагрузочное тестирование релизов - хорошая идея, но его почти нет)
- и вообще, надо уже идти к управляемым блокировкам, ибо "все идут".. ну и реально это поможет облегчить/устранить предыдущие пункты
Переход из автоматического в управляемый режим лучше делать "скачком". Остановили разработку, переписали всю конфигурацию, протестировали, выложили - работаем.
Второстепенные бд так и перевели.
Основная база данных, надо отметить, уже к тому моменту подбиралась ко второму терабайту и тысяче пользователей, и работала "почти 24"/7.
Споткнулись уже на первом пункте. Остановить разработку нельзя, и точка. Много времени разработчиков потратить на переход в управляемый режим - тоже нельзя. "Потихоньку, в свободное от срочного/важного время".
Т.е. оставался перевод конфигурации в режим "Автоматический и управляемый" и переход пообъектно.
В один из релизов и установили в корне "Автоматический и управляемый".
Те, кто попробовал такое на своих продуктивных базах, сейчас наверное начали понимающе улыбаться ).
Нет, мы "перед тем, как" все протестировали, даже с подобием нагрузочного теста (как оказалось позже - подобие было "не очень")
Релиз откатили спустя три часа, после многочисленной ругани пользователей. База висела на блокировках.
Если точнее - источниками блокировок были спящие (sleeping) после выполнения запросов вида
SELECT T1._Период, T1._UseTotals, T1._ActualПериод, T1._UseSplitter, T1._MinПериод
FROM _РегистрНакопления.ОстаткиТоваров(НастройкиХраненияИтоговРегистраНакопления) T1
WHERE T1._RegСсылка = @P1
А технологический журнал, с предусмотрительно настроенным
<log location="C:\LOGS\TLOCKS" history="4">
<event>
<eq property="Name" value="TLOCK"/>
<gt property="duration" value="5000"/>
</event>
<event>
<eq property="Name" value="TTIMEOUT"/>
</event>
<event>
<eq property="Name" value="TDEADLOCK"/>
</event>
<property name="all"/>
</log>
в итоге выдавал по тем спящим сессиям либо длительный TLOCK, либо TTIMEOUT
Каждые десять секунд - обращение к рабочему кластеру 1С через V83.COMConnector и запись снимка сеансов рабочей бд "консоли серверов 1С" в sql-базу. Таким образом, можно связать session_id на sql=сервере с сеансом, соединением и пользователем рабочей бд. Понятное дело, если соединение с субд висело достаточно долго.
Есть еще один способ связать session_id с сеансом/соединением, но он опасен и детально не исследован, и про него я, пожалуй, здесь не напишу.
Т.е. первая сессия блокировала вторую на уровне sql-сервера, а вторая блокировала первую на уровне 1С-сервера управляемой блокировкой. Управляемые блокировки в первой итерации мы не добавляли, это были .. управляемые блокировки при записи наборов регистров.
Если верно помню - регистры не переводили в управляемый режим, блокировки при записи набора в режиме "автоматический и управляемый" появляются у всех регистров разом, даже при флаге "автоматический" в самом регистре.
Соответственно, для нормального разбора проблем фиксацию деревьев блокировок надо модернизировать - добавив управляемые блокировки из техжурнала. Рядом с полем blocked сделать поле blocked_by_ls, и перестроить дерево с его учетом. Если вы имеете в бд снимок блокировок на уровне sql-сервера, снимок сеансов нужной базы из "консоли серверов 1С" и загруженные в sql-таблицу файлы техжурнала с TLOCK - то это возможно. Не сказать, что точность получается идеальная - но для работы вполне хватает.
Ниже иллюстрация подобной ситуации (не связанная непосредственно с началом перехода в "автоматический и управляемый" - тех картинок уж нет, увы..):
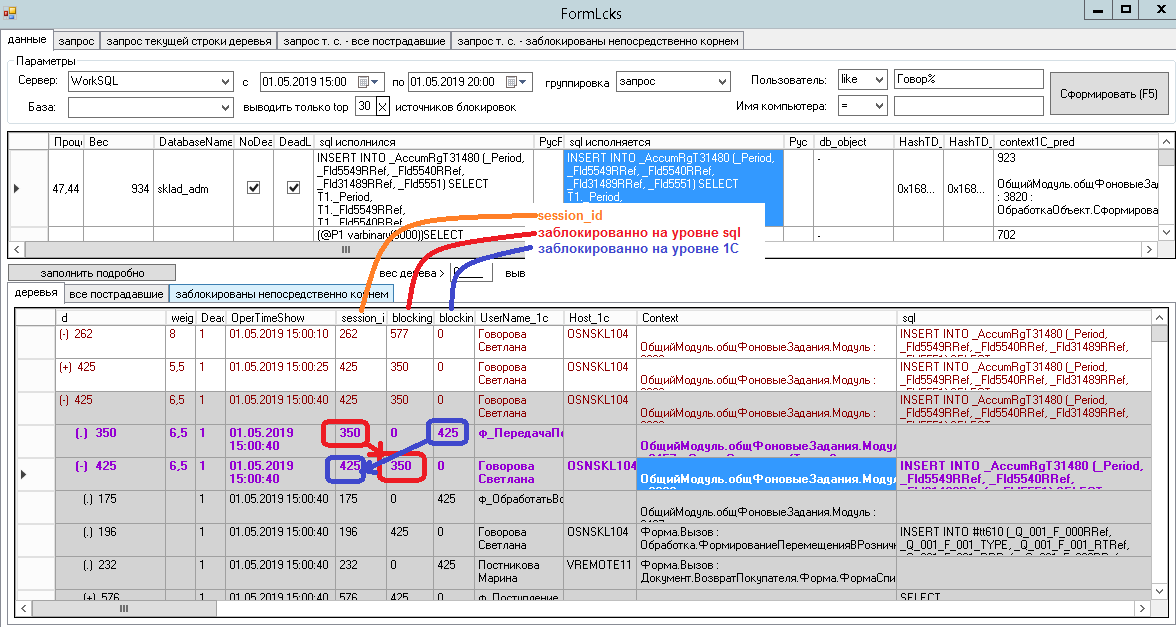

Говорова Светлана запускала "очень важную обработку" и "висела и вылетала" - ниже видно, в чем было дело.
Исходных причин данных дедлоков (а это именно дедлоки - под определение подходят) - было всего штуки три. И имея шесть источников блокировок в деревьях (по два на каждый тип дедлока) - разобраться и сделать индивидуальный костыль под каждую было несложно (заранее прописать соответствующую управляемую блокировку в начале транзакции проведения, убрать у sql-таблицы возможность эскалации, исправить запрос и т.д.).
А далее.. планомерный пообъектный перевод.
Берем регистр А, пишем для него набор потребных управляемых блокировок во всех документах и явных транзакциях, включаем кратковременно (при этом документы по-прежнему в "авто" режиме), удивляемся величине пойманных деревьев, корректируем, включаем опять - работает. Далее в документах, которых двигают только А - можно менять режим с "авто" на "управляемый".
Далее берем регистр Б... в документах, которых двигают только А и Б - можно менять режим.. И до победного конца.
Процесс при этом может занимать годы.
А что же потом?
В полностью управляемом режиме блокировки на уровне sql-сервера (даже в read committed snapshot) не исчезают на 100%. Так что непрерывный мониторинг необходимо продолжать. Пишите свою систему, используйте сервис Гилева или ПерфЭксперт, или мою систему.
1. как минимум System Monitor и счетчик SQL Server: Locks \ Average Wait Time (ms)
2. eXtended Events и событие blocked_process_report - если есть возможность менять настройки sql-сервера ( blocked process threshold ).. более точная штука, чем деревья, но есть пара отрицательный момент.. блокировки ловит отлично, но деревья предоставляют кое-какие возможности и помимо ловли блокировок. пока расшифровывать не буду.
3. eXtended Events и событие Lock:Acquired - покажет, на каких таблицах и у каких пользователей были проблемы. Но вытащит источники блокировок отсюда сложно. Данные за период такой трассы очень хорошо коррелируют с данными в деревьях блокировок.
дополняйте..
Вступайте в нашу телеграмм-группу Инфостарт