






{kind=link}
Введение
Судя по статье Что делает "В ИЕРАРХИИ" в запросе?, интерес к теме работы с иерархическими данными в запросах еще не исчез. В то же время, решения, приведенные в статье Уровни, глубина, прародители, циклы и аналоги запросом, нуждаются в уточнениях и дополнениях.
Для этого есть несколько причин. Во-первых, запросы в статье Уровни, глубина, прародители, циклы и аналоги запросом были написаны как пример применения более общего приема "транзитивного замыкания". Но оказалось, что в частых случаях некоторых конкретных задач, таких как определения глубины, уровней и прародителей в справочниках, запросы могут быть реализованы эффективнее. Во-вторых, в исходной статье для удобства были приведены не запросы, а универсальные функции для их построения. Из-за чего у многих сложилось неверное представление, что речь идет об ограниченно используемой или не о чисто запросной технике. Это желательно поправить. В третьих, есть смысл посмотреть на проблему шире, с точки зрения того, как еще можно представлять иерархию. В четвертых, в запросах с того времени появились новые конструкции, одна из которых оказалась полезной при работе с иерархиями.
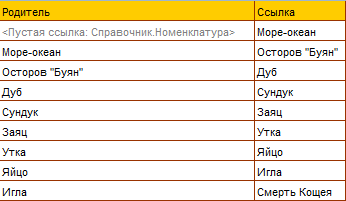
Итак, при представлении иерархических справочников в платформе 1С:Предприятие, хранится только "остов" отношения иерархии, а именно, связь конкретного элемента с его непосредственным родителем. Из-за этого при поиске всех потомков одного элемента на уровне СУБД фактически используется цикл из нескольких последовательных запросов (Что делает "В ИЕРАРХИИ" в запросе?). При этом готовой конструкции, позволяющей выбрать всех предков одного элемента, вообще нет. В литературе способ, используемый в платформе, называется Adjacency List (AL).
Для того, чтобы быстро решать все задачи на иерархию, требуется "развертка" иерархии, где отношение непосредственно определено для любой пары элементов, независимо от того, находятся ли они на смежных уровнях или нет. В теории используется минимум три разновидности "развернутого" представления иерархии: использование полного списка потомков CT (Closure Table), путей к элементам MP (Matherialized Path), вложенных множеств NS (Nested Sets). Есть еще всевозможные модификации перечисленных способов: Реализация иерархии — объединение Adjacency List и Materialized Path через one-to-many, Строим Nested Set дерево без рекурсии.
Естественно думать, что развернутое представление иерархии должно храниться в СУБД. Это порождает проблему усложнения процедуры записи при изменениях в структуре справочника. Например, изменение подчинения группы элементов требует переписывания путей во всех элементах группы. Но, вообще говоря, развернутое представление можно получать и "на лету" - непосредственно перед построением отчета. Это хотя и может несколько замедлить его выполнение, но не требует хранения избыточных данных в СУБД и их перестроения. В дальнейшем основной акцент изложения сделан именно на этом варианте. К тому же, этот способ не исключает первого, то есть того, что при необходимости развернутая иерархия, полученная приводимыми далее запросами, будет сохраняться в СУБД.
1. Использование полного списка потомков (Closure Table)
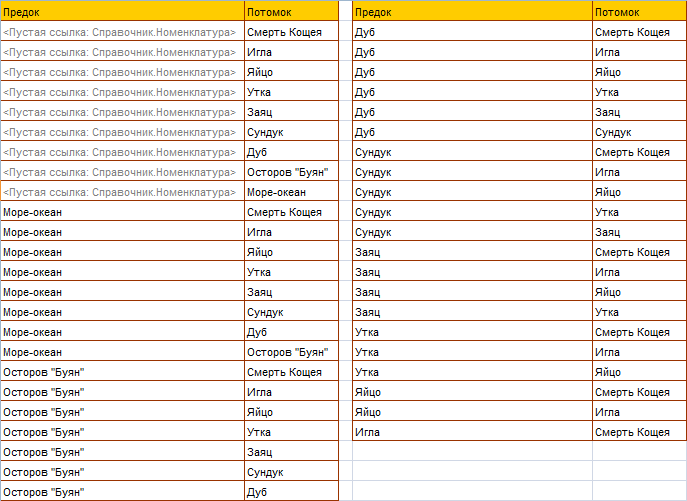
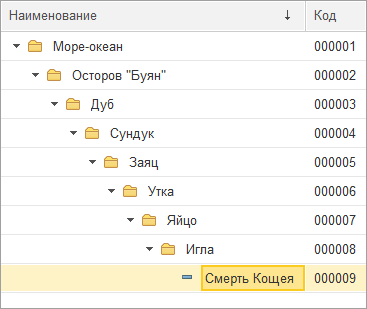
Это наиболее очевидный способ, заключающийся в том, что для каждого элемента иерархии составляется список всех элементов, которые непосредственно и опосредованно ему подчиняются.
Например, для структуры, изображенной на Фиг.1,

AL задается таблицей Таб.1,

а CT - таблицей Таб.2.

Получение таблицы CT по таблице AL одним пакетным запросом было описано в [Уровни, глубина, прародители, циклы и аналоги запросом]. Предлагалось использовать следующий запрос:
К запросу можно сделать следующие комментарии:
В первом запросе пакета существующие связи иерархии дополняются самосоединениями элементов. Это нужно для накопления связей в формируемых временных таблицах. Затем получившаяся временная таблица соединяется сама с собой для нахождения в два раза более длинных связей. И так происходит несколько раз, пока длина найденных связей не превысит максимальный уровень иерархии. Этот уровень лучше задавать с запасом, чтобы каждый раз не менять запрос. Например, приведенный запрос может обработать иерархию, содержащую максимум шестнадцать уровней, что достаточно для большинства практических применений.
Для справочников из большого количества элементов со значительной глубиной иерархии число записей в таблице CT может оказаться довольно большим. Его можно оценить по формуле N*L, где N - число элементов в справочнике, L - средний уровень иерархии. Большое число записей приводит к пропорциональному росту времени соединений в процессе получения таблицы CT. Таким образом, получается, что подход работает для относительно небольших справочников - до нескольких тысяч элементов. Подход работает, но некоторые думают, что "...держать всех родителей на каждую запись — ужас тихий, особенно на глубоких случаях...".
Поэтому рассмотрим способы, свободные от этого недостатка.
2. Использование материализации путей
В этом случае элементы справочника дополнительно содержат строковое поле, содержащее путь к этому элементу от корня дерева иерархии. Для кодирования отрезков пути в большинстве случаев удобно использовать уникальные коды групп и элементов справочника. Для приводимого ранее примера таблица MP будет иметь вид:

Для получения таблицы MP по таблице AL можно использовать следующий пакетный запрос:
Приведенный запрос отличается от предыдущего тем, что временные таблицы хранят только по одному пути в направлении корня для каждого элемента. Для этого в первом запросе пакета добавляется не множество записей - по одной на каждую ссылку, а всего одна запись для корня, которая и будет использоваться для накопления путей.
Способ кодирования пути определяет ограничение представляемой иерархии. Максимальная длина строки, хранящейся в базе, равна 1024 символа. Следовательно, при девятизначном коде и одном разделителе возможно представить иерархию не более чем из 64 уровней. Очевидно, что для практики это несущественное ограничение.
Принцип построения приведенного запроса позволяет примерно в L раз быстрее получить уровни, глубину и прародителей элементов справочника. Вот пример запроса для уровней:
Сокращение до минимума числа записей представления иерархии, наглядность такого представления, возможность построения эффективного индекса по полю "путь" для различных, связанных с иерархией запросов - это все плюсы рассматриваемого представления.
Минус представления MP заключается в его недостаточной компактности по сравнению со способом, рассматриваемом далее.
3. Использование вложенных множеств (Nested Sets)
Этот способ заключается в том, что группы и элементы справочника нумеруются в порядке левостороннего обхода дерева иерархии таким образом, что все подчиненные группы и элементы получают диапазон номеров, входящий в диапазон номеров предков.
Для приводимого ранее примера таблица NS будет иметь вид

Данную таблицу можно построить по таблице MP следующим запросом, опирающимся на недавно появившуюся в запросах функцию АВТОНОМЕРЗАПИСИ().
Необходимо обратить внимание, что суффикс "\" в таблице "Триггер" выбран не просто так, а исходя из того, что он в таблице ASCII старше символа "/", который выбран в качестве разделителя пути. Из-за этого пути исходящих из узла веток будут при упорядочивании размещаться между значениями Путь + "" и Путь + "\", что и дает возможность их правильно пронумеровать. Поэтому при выборе другого разделителя пути следует не забыть выбрать соответствующий суффикс в таблице Триггер.
В принципе, существует возможность и непосредственного построения таблицы NS по таблице AL пакетным запросом, но для его демонстрации нужно было бы пожертвовать наглядностью, что делать не хочется.
Плюсом представления NS является его компактность, так как при этом вся развернутая иерархия справочника реализуется двумя простыми числовыми реквизитами, не требующими много места для своего хранения. Некоторым минусом может быть то, что при этом подходе отдельные редкие задачи будут переводить запросы на иерархию в запросы на интервалы, у которых есть свои сложности с использованием индексов. Хотя и это решается, например, при помощи приема из статьи Простой способ индексирования интервалов.
4. Заключение
В идеале статью можно было бы закончить вопросником, содержащим вопросы типа: "укажите относительную частоту чтения и записи в справочник", "укажите размер справочника", "укажите среднюю глубину иерархии в справочнике", "какую СУБД вы используете" и прочее. И дать потом расшифровку ответов в виде рекомендаций, что использовать: AL, CT, MP или NS. Но это невозможно без более подробных исследований и пока непонятно, насколько такое глубокое и "скучное" (по сравнению с составлением запросов) исследование вообще нужно.
Возможно, в статье также маловато примеров запросов для использования полученных представлений. Их предлагается придумать самостоятельно. А в качестве упражнений можно попробовать решить следующие задачи:
- Запросом определить все группы справочника, не содержащие подчиненных (на любом уровне вложенности) элементов.
- Запросом определить ближайшего общего предка списка заданных элементов.
- Определить число элементов, рекурсивно включенных в каждую группу справочника.
5. Использованные источники:
- Что делает "В ИЕРАРХИИ" в запросе?
- Уровни, глубина, прародители, циклы и аналоги запросом
- Иерархические структуры данных и Doctrine
- Деревья в SQL. Некоторые ответы на некоторые общие вопросы о деревьях и иерархиях SQL. Джо Селко
- Реализация иерархии — объединение Adjacency List и Materialized Path через one-to-many
- Строим Nested Set дерево без рекурсии
- Простой способ индексирования интервалов
Вступайте в нашу телеграмм-группу Инфостарт