
Альтернативная реализация РИБ на RabbitMQ хорошо показала себя на практике. Более того она получила своё развитие. Тем не менее узким местом стала загрузка данных на стороне 1С. Средняя производительность составила приблизительно 1000 сообщений в минуту в один поток (фоновое задание) при среднем размере сообщения равным 3 Кб. В конечном итоге встал вопрос оптимизации загрузки, так как количество входящих сообщений по некоторым типам сообщений (объектам метаданных) составляло в пиках нагрузки несколько десятков, а иногда сотен тысяч сообщений за достаточно короткий промежуток времени.
В данной публикации приводится подробное описание и алгоритм решения проблемы.
Алгоритм рассмотрен на примере параллельной обработки регистра сведений "КурсыВалют".
Тем не менее, всё ниже сказанное в равной степени может быть применимо к ссылочным объектам метаданных и регистрам накопления, учитывая их специфические особенности.
Модификация данных регистра сведений это последовательность операций delete и insert. Асинхронный обмен данными основан на регистрации таких операций в виде отдельных сообщений, образуя упорядоченный поток данных. Нарушение последовательности сообщений в таком потоке может привести к непредсказуемым последствиям с точки зрения согласованности и целостности данных.
Таблица 1. Режим записи набора регистра сведений и команды СУБД.
|
Режим записи |
Примечание |
Команды СУБД |
|
Добавление |
Отбор игнорируется |
insert |
|
Замещение |
НаборЗаписей.Количество() = 0 |
delete |
|
Замещение |
НаборЗаписей.Количество() > 0 |
delete + insert |
Таким образом регистрация изменений, отправка и получение сообщений, содержащих данные таких изменений, а также обработка потока сообщений принимающей стороной должны гарантировать соблюдение строгой последовательности операций.
Данное требование накладывает ограничение на возможность параллельной обработки подобного потока данных, так как в таком случае сообщения могут быть обработаны в произвольном порядке.
Тем не менее, учитывая тот факт, что каждое сообщение обмена это записи набора регистра, которые имеют уникальные ключи, существует возможность параллельного выполнения операций модификации регистра сведений в разрезе этих ключей. Для этого должно отсутствовать требование строгой последовательности обработки операций по разным ключам. Как правило такое требование отсутствует, например, таким образом мы можем параллельно обрабатывать записи регистра сведений "КурсыВалют" в разрезе разных периодов и валют.
Степень параллелизма обработки последовательности ключей зависит прямо пропорционально от количества повторяющихся ключей в этой последовательности. Одинаковые ключи должны обрабатываться строго последовательно.
Тем не менее существует возможность оптимизации обработки последовательности одинаковых ключей путём вычисления конечного состояния (значений реквизитов) объекта данных после применения всех соответствующих операций, соответствующих этим ключам.
Предположим, что мы имеем очередь сообщений, в которой имеются повторяющиеся ключи (на рисунке ниже это ключи со значением 1).

Очередь делится на порции обработки сообщений параллельными потоками выполнения. Обработка сообщений в рамках одного потока выполняется последовательно согласно первоначальному порядку.
Предположим, что потоки нумеруются от 1 до N, при этом потоки, имеющие большее значение N относительно данного, называются старшими потоками, а имеющие меньшее — младшими.
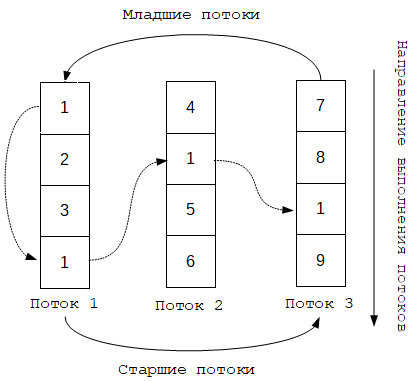
Одинаковые ключи могут попасть в один и тот же поток выполнения или разные. Такие ключи образуют зависимость друг от друга таким образом, что, находясь в одном потоке выполнения, они обрабатываются последовательно и это не является проблемой, но, находясь в разных потоках выполнения, старшие потоки блокируются на зависимых ключах, находящихся в младших потоках, до тех пор пока младший поток не выполнит обработку соответствующего ключа.
На диаграмме 1 пунктирной линией соединены одинаковые ключи, имеющие значение 1, которые образуют строгую последовательность их обработки. Таким образом выполнение потока 2 будет заблокировано на ключе со значением 1 до тех пор, пока поток 1 не обработает все свои ключи с тем же значением 1, а поток 3 - до тех пор, пока ключ со значением 1 не будет обработан потоком 2.
На самом деле, в целях оптимизации выполнения потоков, не обязательно блокировать выполнение старших потоков, а именно потоков 2 и 3, ожидая пока младший поток 1 обработает все свои ключи со значением 1.
Выполнение потоков 2 и 3 можно продолжить, делегировав обработку всей последовательности ключей со значением 1 самому младшему потоку, в котором это значение встречается, а именно потоку 1.
Более того, если последовательность зависимых ключей имеет значительную длину, то имеет смысл создавать дополнительный поток для её обработки. Данное пороговое значение можно регулировать настройками алгоритма выполнения.
Кроме этого, обработку всей цепочки одинаковых ключей можно оптимизировать, обрабатывая только последний ключ цепочки, игнорируя все остальные, так как последнее во всей цепочке сообщение содержит наиболее актуальную версию данных.
Таким образом, можно сформулировать правила работы потоков:
1. Поток обрабатывает только свои, уникальные в пределах всех потоков выполнения, ключи.
2. Поток игнорирует обработку ключа, являющегося частью взаимной зависимости одинаковых ключей, и продолжает обработку со следующего за ним ключа. Из этого правила существует исключение — правило 3.
3. Поток, являющийся самым младшим потоком в цепочке зависимости одинаковых ключей, обрабатывает такую цепочку полностью самостоятельно или создаёт дополнительный поток для её обработки.
Рассмотрим реализацию алгоритма на примере типового для многих конфигураций 1С регистра сведений "КурсыВалют". В качестве очереди сообщений, в которой регистрируются операции модификации данных, используется также регистр сведений, выполняющий аналогичную таблицам регистрации изменений планов обмена 1С функцию.
|
Назначение |
Наименование |
Тип данных |
Функция |
|
Измерение |
МоментВремени |
Число(19, 0) UTC в миллисекундах |
Ключ последовательности |
|
Измерение |
Идентификатор |
Уникальный идентификатор |
Ключ последовательности |
|
Ресурс |
Дата |
Дата (Дата) |
Ключ записи регистра |
|
Ресурс |
Валюта |
Справочник "Валюты" |
Ключ записи регистра |
|
Реквизит |
ТелоСообщения |
Строка JSON |
Данные записи регистра |
Поля табличной очереди делятся на три группы:
- ключи последовательности (определяют порядок сообщений);
- ключи объекта данных (гарантируют уникальность объекта данных);
- данные объекта (фиксированное состояние данных объекта).
Для формирования потоков выполнения и построения графа зависимых ключей объектов данных (можно назвать и вектором версий) используется следующий запрос 1С, в котором выбирается порция из 10000 сообщений для разделения их, например, на 10 потоков по 1000 сообщений в каждом.
ВЫБРАТЬ ПЕРВЫЕ 10000
АВТОНОМЕРЗАПИСИ() КАК Индекс, // Индекс выборки для построения
// графа зависимых ключей объектов
// и разделения выборки на потоки выполнения
МоментВремени, // Ключ последовательности
Идентификатор, // Ключ последовательности
Период, // Ключ объекта сообщения
Валюта // Ключ объекта сообщения
ПОМЕСТИТЬ
ОчередьСообщений
ИЗ
РегистрСведений.ОчередьКурсыВалют
УПОРЯДОЧИТЬ ПО
МоментВремени, // Ключ последовательности
Идентификатор; // Ключ последовательности
ВЫБРАТЬ
Т1.Индекс КАК Порядок, // Индекс выборки
Т1.МоментВремени КАК МоментВремени, // Ключ очереди
Т1.Идентификатор КАК Идентификатор, // Ключ очереди
Т1.Период КАК Период, // Ключ объекта
Т1.Валюта КАК Валюта, // Ключ объекта
Т2.Индекс КАК Вектор // Зависимый ключ объекта
ИЗ
ОчередьСообщений КАК Т1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ОчередьСообщений КАК Т2
ПО Т1.Период = Т2.Период // Ключ объекта
И Т1.Валюта = Т2.Валюта // Ключ объекта
УПОРЯДОЧИТЬ ПО Порядок ВОЗР
ИТОГИ ПО Порядок;
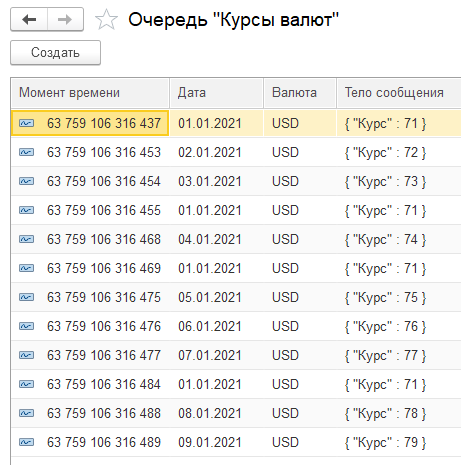
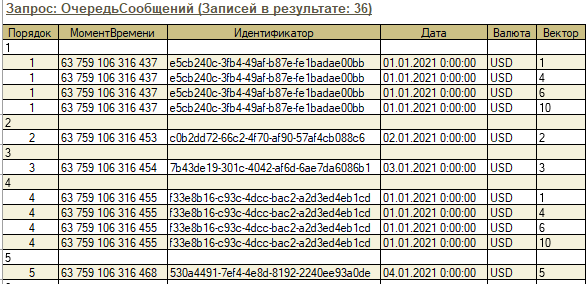
Для деления выборки сообщений на потоки можно использовать поле "Порядок", как индекс массива, а для навигации по графу зависимых ключей можно использовать поле "Вектор". Например, в данном случае, ключ (Период + Валюта) первого сообщения повторяется в сообщениях, имеющих порядковые номера 1, 4, 6 и 10.
Сложным моментом является ситуация, когда для модификации регистра сведений используется усечённый отбор. Такой отбор применяется при удалении записей, например, по одному из измерений. В таком случае соединение по ключу объекта (записи) выше приведённого запроса будет работать некорректно.
Одним из возможных решений этой проблемы может быть регистрация изменений по всем полным ключам, удаляемых записей. Интересно отметить, что именно так работает регистрация изменений в таблицах изменений планов обмена 1С - там всегда региструются только полные ключи.
Второе решение: модификация запроса таким образом, чтобы соединение выполнялось правильно, с учётом логики алгоритма. Условие соединения в запросе можно, например, переписать так (значением параметра &Валюта является пустая ссылка):
ПО Т1.Дата = Т2.Дата // Измерение 1
И ВЫБОР КОГДА Т1.Валюта = &Валюта ТОГДА ИСТИНА // Измерение 2
КОГДА Т2.Валюта = &Валюта ТОГДА ИСТИНА // Измерение 2
ИНАЧЕ Т1.Валюта = Т2.Валюта // Измерение 2
КОНЕЦ
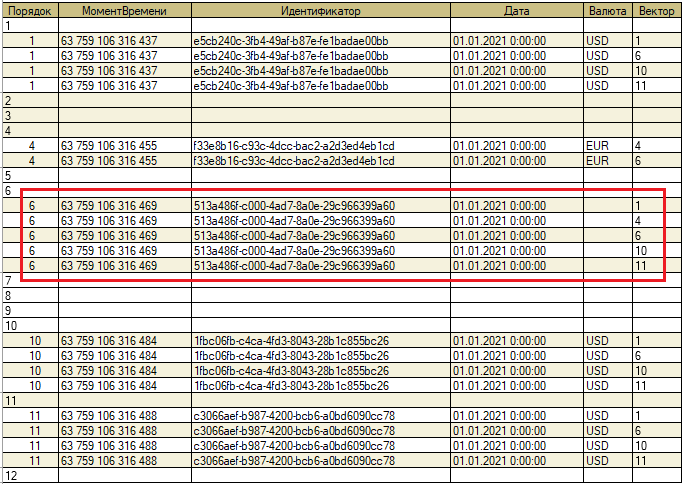
Результат выполнения запроса с таким условием соединения может выглядеть как на рисунке ниже. На этом рисунке операция удаления всех записей по всем валютам на 01.01.2021 при помощи усечённого отбора выделена красной рамкой.
Алгоритм может применяться как на стороне отправителя сообщений, чтобы сократить, передаваемое по сети количество изменений, так и на стороне получателя для увеличения производительности загрузки.
Неудобством алгоритма является то, что для каждого регистра сведений, для которого требуется выполнить оптимизацию параллельной обработки очереди сообщений, необходимо вручную создавать дополнительные специализированные регистры сведений.
Кроме этого следует учитывать степень параллелизма, о которой упоминалось в самом начале — раздел 1 "Описание проблемы". Количество сообщений по разным ключам может сильно отличаться друг от дурга.
Следует отметить ещё один возможный алгоритм обработки последовательности сообщений по ключам. Этот алгоритм основывается на использовании группировки сообщений по ключам объектов.
Идея заключается в том, что сначала из последовательности сообщений выбирается максимально актуальная версия для данного ключа объекта. Все остальные версии отбрасываются, как устаревшие.
Первая часть запроса аналогична запросу первого алгоритма. Вторая часть запроса использует группировку и соединение по индексу.
ВЫБРАТЬ
Т2.МоментВремени, // Ключ последовательности (очереди)
Т2.Идентификатор // Ключ последовательности (очереди)
ИЗ
(ВЫБРАТЬ МАКСИМУМ(Индекс) КАК Индекс // Индекс выборки
ИЗ ОчередьСообщений
СГРУППИРОВАТЬ ПО // Группировка данных по ключу
Дата, Валюта) КАК Т1 // объекта с целью поиска
// актуальной версии данных
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ОчередьСообщений КАК Т2
ПО Т1.Индекс = Т2.Индекс
УПОРЯДОЧИТЬ ПО Т1.Индекс ВОЗР;
Недостатком алгоритма является сложность учёта в запросе случая использования усечённого отбора при удалении записей регистра сведений (см. пункт 3.5 "Сложность реализации алгоритма"). Для того, чтобы учесть усечённые отборы в запросе, потребуется выполнить ещё одну группировку по неполным ключам, а затем снова выполнить соединение с первым запросом, чтобы учесть зависимость полных ключей от неполных и построить соответствующий граф или, другими словами, сформировать вектор версий.
СписокФоновыхЗаданий = Новый Соответствие();
МассивСообщений = ВыбратьСообщенияЗапросомПоВекторамВерсий();
Для НомерПотока = 1 По 10 Цикл
ФоновоеЗадание = СоздатьФоновоеЗадание(МассивСообщений, НомерПотока);
СписокФоновыхЗаданий.Вставить(ФоновоеЗадание.УникальныйИдентификатор, ФоновоеЗадание);
КонецЦикла;
ОжидатьЗавершенияФоновыхЗаданий(СписокФоновыхЗаданий);
РазмерЗадания = МассивСообщений.Количество() / 10;
ИндексНачало = (НомерПотока - 1) * РазмерЗадания;
ИндексКонец = НомерПотока * РазмерЗадания - 1;
Для Индекс = ИндексНачало По ИндексКонец Цикл
ДанныеСообщения = МассивСообщений[Индекс];
Если ДанныеСообщения.ВекторВерсий.Количество() = 0 Тогда
Продолжить;
КонецЕсли;
Версия = Индекс + 1;
Если Версия = ДанныеСообщения.ВекторВерсий[0] Тогда
Если ДанныеСообщения.ВекторВерсий.Количество() = 1 Тогда
ОбработатьСообщение(ДанныеСообщения);
Иначе
ОбработатьВекторВерсий(МассивСообщений, ДанныеСообщения);
КонецЕсли;
Иначе
Продолжить;
КонецЕсли;
КонецЦикла;
Для Каждого Версия Из ДанныеСообщения.ВекторВерсий Цикл
Индекс = Версия - 1;
ДанныеСообщения = МассивСообщений[Индекс];
ОбработатьСообщение(ДанныеСообщения);
КонецЦикла;

