



{kind=link}
Полнотекстовый поиск по содержимому всех документов - отличная функция 1С:Документооборот, однако много документов хранится в сканах и их надо как-то распознать. Встроенный механизм базируется на откровенно устаревшей технологии (у CuneiForm последняя версия от 19.04.2011) и имеет очень низкое качество. Частично спасает ситуацию возможность удалённого распознавания на мощностях 1С, но далеко не все готовы отсылать свою переписку куда-то за пределы организации, да и не бесплатная это функция.
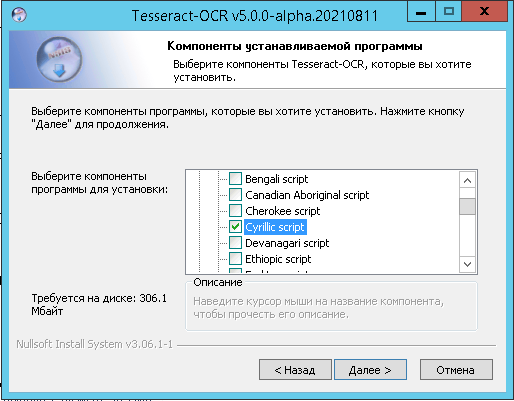
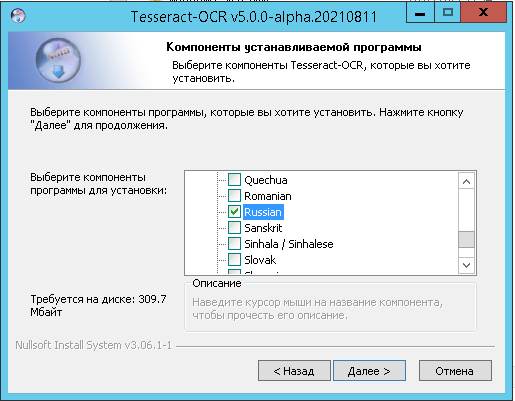
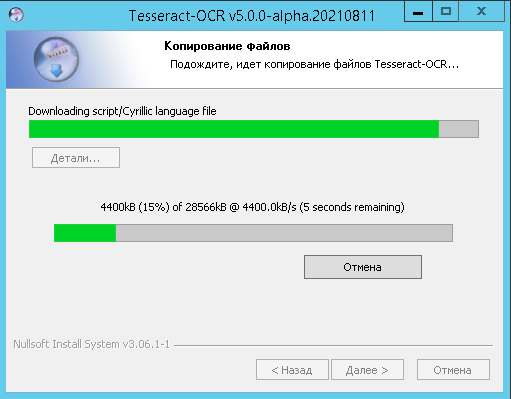
Однако есть выход, причем проект открытый и развивающийся, а потому можно надеяться, что качество распознавания будет расти. Я имею ввиду проект Tesseract OCR. На официальном сайте проекта есть сборка под все ОС, под Windows только alfa-версия, но работает она хорошо. Особенности установки с поддержкой кириллицы и русского языка я показал на скринах.
Неожиданно плохие результаты показало распознавание изображений, полученных из Adobe PDF с помощью утилиты Imagemagick. Часть изображений получается серые, я об этом эффекте уже писал. Нормально работает на изображениях, полученных с помощью утилиты pdftopng от производителя XpdfReader.
Предлагаемое расширение подменяет функцию РаспознатьСПомощьюCuneiForm() общего модуля Распознавание, и корректно работает во всех сценариях, как в ручном, так и в автоматическом.
Программа первым делом производит поиск текстового слоя в файле pdf, для этого используем утилиту pdftotext из Xpdf command line tools. Тут есть один нюанс, в качестве параметра передаётся кодировка текста, который должен быть извлечён из файла, а она изначально неизвестна. Предположительно, чаще всего должна использоваться кодировка UTF-8, но как показывают тесты это не так и вообще часть текста может быть в одной кодировке, а часть в другой. А ещё лист документа может быть перевёрнут, причём в любую сторону. Тесты OCR Tesseract показали, что программа сама пытается выровнять текст. Если подать на вход изображение с текстом и это-же изображение, повёрнутое на 90 градусов, то качество распознавания не изменится. Но вот поворот на 180 и 270 градусов делает распознавание невозможным.
Что делать? Надо как-то понять, что распознанный текст содержит нормальный текст, а не мусор. Я решил, что можно считать долю кириллических символов в тексте, мы же распознаём русскоязычные документы, значит их там должно быть больше половины.
Получился следующий алгоритм:
- пытаемся из файла Adobe PDF получить текст, если получается, то считаем долю кириллических символов, и если их больше 65% возвращаем текст;
- разбиваем файл на изображения и начинаем каждое распознавать, после распознавания снова считаем долю символов, если меньше 65%, то переворачиваем на 180 градусов и пробуем снова.
Все "мысли" программы по поводу получения изображений и извлечения текста пишутся в журнал регистрации, там можно понять почему была выбрана определённая стратегия распознавания.
Настройки программ находятся в начале функции модуля РОТР_РаспознатьСПомощьюCuneiForm() общего модуля Распознавание из расширения, там указываются все пути к программам и разрешение изображений, настройки снабжены комментариями. Есть ограничения на минимальный и максимальный объём изображений, понятно, что они ничем особо не обоснованы, только наблюдения и тесты. Всё ради увеличения быстродействия, т.к. процесс распознавания получается мягко сказать "неторопливым".
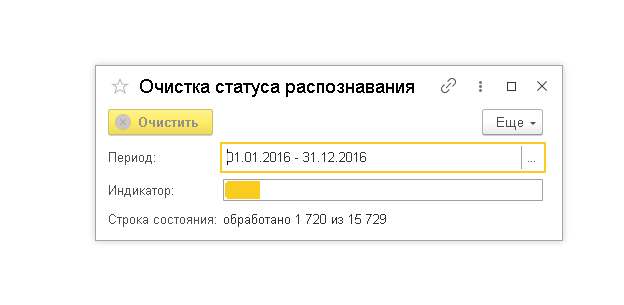
В общем модуле РОТР_ОбщегоНазначенияСервер собраны функции для работы в изображениями и распознавания текста, их можно использовать в собственных проектах, они также снабжены описанием параметров. Также хочется отметить, что процесс tesseract.exe может потреблять очень много оперативной памяти, у меня бывало доходило почти до 1 Гб (один раз), это надо иметь ввиду при внедрении данного механизма. Если раньше файлы распознавались с использованием старого алгоритма, то надо сбросить статус, для чего в расширении есть соответствующая обработка.
Расширение проверено на конфигурации 1С:ДГУ 2.1.29.16 и технологической платформе 8.3.17.1851.
Upd. 16.09.2024. Добавил адаптацию расширения под Linux, тестировал на 1С:ДГУ 2.1.34.1

Распознавание и загрузка сканов в 1С
Решение «Распознавание и загрузка сканов в 1С» — интеллектуальный инструмент, превращающий сканы накладных, счетов, УПД или Excel-файлов в готовые документы 1С. Без ручного ввода и ошибок — с распознаванием даже нечетких фото. Оптимизируйте документооборот и автоматизируйте рутину с помощью ИИ-распознавания.
Проверено на следующих конфигурациях и релизах:
- Документооборот КОРП, релизы 2.1.34.1, 2.1.29.16
Вступайте в нашу телеграмм-группу Инфостарт