



Данная статья касается особенностей выполнения операций над строками в языке программирования платформы «1С: Предприятие» и проблемы медленной конкатенации строк, возникающей, если эти особенности не учитываются. Приводятся две новые полезные функции, позволяющие обходить указанную проблему.
Для примера рассмотрим следующую простую задачу: дана строка, из которой требуется исключить ненужные (повторяющиеся) пробелы. Эту операцию можно назвать «отжим пробелов».
Первое, что приходит в голову, для решения этой задачи, это использовать стэйт-машину в виде функции на подобие следующей
Функция ПростойОтжим(Текст, Ответ = "", Было = "") Экспорт
Для ё = 1 По СтрДлина(Текст) Цикл Стало = Сред(Текст, ё, 1); Ответ = Ответ + ?(Было + Стало = " ", "", Стало); Было = Стало КонецЦикла;
Возврат Ответ
КонецФункции
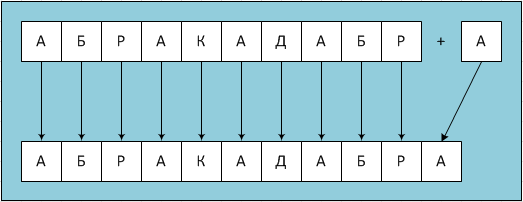
На первый взгляд кажется, что никакого подвоха в этом коде нет. Однако на самом деле на длинных строках такая функция работает невероятно долго. Дело в том, что в цикле здесь используется простая по виду конструкция, которая дописывает справа к получаемой строке один значащий (не пробельный) символ. По замерам времени выполнения можно заключить, что в 1С такая конструкция работает примерно так: выделяется область памяти на один символ длиннее, чем строка, накапливающая результат, затем ВСЕ содержимое этой строки копируется в новую область, а добавляемый символ записывается справа. Следовательно, при удлинении всего на один символ строки длины в тысячу символов в оперативной памяти придется перенести целый килобайт данных (или два, если речь идет о юникоде)! А эта операция выполняется в цикле, повторяющемся для каждого символа новой строки! Последовательная посимвольная конкатенация в процессе накопления строки иллюстрируется следующей схемой:
В качестве доказательства существования проблемы приводится график зависимости времени конкатенации от длины строки, накапливающей результат.

График получен в результате работы следующей процедуры:
Процедура ТестВремениКонкатенации()
Текст = "";
Для ё = 1 По 32 Цикл
Старт = ТочноеТекущееВремя();
Для ж = 1 По 16384 Цикл Текст = Текст + "а" КонецЦикла;
Сообщить("" + 16384 * ё + ":" + (ТочноеТекущееВремя() - Старт))
КонецЦикла
КонецПроцедуры
Анализируя график, можно сделать еще один интересный практический вывод: обработка строк, длиннее, чем примерно 262144 символа производится платформой существенно дольше, чем обработка более коротких строк. Возможно, такие строки размещаются непосредственно на диске (есть и другие предположения).
Тем не менее, существует простое решение, позволяющее обойти при решении рассматриваемой задачи указанную проблему медленной конкатенации строк. Это решение имеет определенную аналогию с ранее предложенными приемами построения запросов и представлено следующей функцией «отжима пробелов»:
Функция ДвойнойОтжим(Знач Текст) Экспорт
Для ё = 1 По Log(СтрДлина(Текст)) / Log(2) + 1 Цикл Текст = СтрЗаменить(Текст, " ", " ")
КонецЦикла;
Возврат Текст
КонецФункции
В этой функции каждая итерация цикла уменьшает длину цепочки пробелов в два раза. Поэтому даже если строка состоит из одних пробелов, на ее «отжим» понадобится не больше чем ] log2(N) [ итераций цикла, где N – исходная длина строки. Работа функции иллюстрируется следующей схемой:

На длинных строках такая функция работает приемлемое время, что показывает отчет, приложенный к статье. Строку из миллиона символов функция обрабатывает примерно за 200 миллисекунд. Скачавшие отчет смогут замерить (если хватит терпения) и время выполнения более очевидной функции «простого отжима» в зависимости от длины текста и процентного содержания пробелов в нем.
Кроме того, возможно, в коде отчета окажется интересным прием генерации «случайного» тестового текста с использованием «таблицы хаоса» из статьи "Порождающий запрос" [//infostart.ru/public/90367/].
Нужно сказать, что предлагаемая функция «двойного отжима» более известна в виде функции «условного отжима»:
Функция УсловныйОтжим(Знач Текст) Экспорт
Пока Найти(Текст, " ") Цикл Текст = СтрЗаменить(Текст, " ", " ")
КонецЦикла;
Возврат Текст
КонецФункции
Хотя, кажется, что такая функция должна работать несколько быстрее предлагаемой в данной статье, на самом деле, из-за того, что проверка наличия двойных пробелов тоже отнимает время, разницы в быстродействии между функциями практически нет. Особенно в случае, если пробелы сосредоточены в правой части строки. В этом также можно убедиться с помощью прилагаемого отчета.
Размышляя над отмеченной проблемой, можно прийти к выводу, что в 1С также трудно решаются любые задачи, в которых требуется синтезировать длинные строки. Например, первоначально было затруднительно получить длинную строку со случайным расположением пробелов для проверки предлагаемых функций, так как при этом также на первый взгляд требовалось использовать посимвольное наращивание строки.
Тем не менее, выход есть. Для решения таких задач предлагается первоначально работать с такими длинными строками как с массивом символов, а затем преобразовывать массив символов в результирующую строку с помощью второй предлагаемой в статье функции
Функция Строчка(Массив, От, До)
Возврат ?(От = До, Массив[От], Строчка(Массив, От, Цел((От + До) / 2)) + Строчка(Массив, Цел((От + До) / 2) + 1, До))
КонецФункции
Эта простая рекурсивная функция работает существенно быстрее последовательной посимвольной конкатенации из-за того, что требуется перемещать меньшие объемы данных при меньшем общем количестве необходимых конкатенаций. Работа функции построена на рекурсивном объединение строк из половинок обрабатываемого массива. Этот принцип отражает следующая схема:

Например, массив из миллиона символов преобразуется в строку примерно за 20 секунд. ВНИМАНИЕ! Эта запись функции предполагает, что параметр «От» всегда меньше или равен параметру «До».
Однако здесь следует сказать, что для преобразования массива символов в строку существует несколько более быстрый способ. Он основан на использовании функции «ЗначениеВСтрокуВнутр»
Функция ВСтроку(Массив) Экспорт
Возврат Сред(СтрЗаменить(ЗначениеВСтрокуВнутр(Массив), """}," + Символы.ПС + "{""S"",""", ""), 53 + СтрДлина(Формат(Массив.Количество(), "ЧГ=")), Массив.Количество())
КонецФункции
В этом варианте записи функции считается, что все элементы массива – это строки длиной в один символ. Ограничение длины легко преодолевается при чуть более сложной записи, а вот если в массиве могут оказаться данные разных типов, то, возможно, выгоднее будет применять рекурсивную функцию.
Для быстрого преобразования исходной строки в массив для ее обработки в таком виде можно использовать прием из статьи «Порождающий запрос»[//infostart.ru/public/90367/]. Там этот прием использовался в задачах подсчета частоты символов и подсчета частоты слов в тексте.
В результате комбинация всех этих приемов позволяет решить, например, задачу быстрой транлитерации большого текста, представление текста первыми буквами всех его слов и тому подобные задачи, не решаемые комбинациями стандартных операций над строками.
В заключение хочется выразить надежду, что
- обозначенная проблема медленной конкатенации строк и показанная зависимость времени обработки от длины строк будет учитываться в практике программирования для платформы «1С: Предприятие»;
- приведенные функции окажутся востребованными, так как сокращают время выполнения часто используемых операций над строками;
- по аналогии с приведенными функциями и на их основе будут построены другие полезные функции обработки строк;
- анализ приведенных функций позволит лучше понять преимущества методов из статей «Порождающий запрос» [//infostart.ru/public/90367/], «Транзитивное замыкание запросом»[//infostart.ru/public/158512/], поскольку предлагаемые приемы и контрприемы имеют общую математическую основу.
Вступайте в нашу телеграмм-группу Инфостарт


{kind=link}