


Погуглив просторы интернета, я нашел подобные решения для 1С. Но все эти разработки требуют пересылку данных на сторонние ресурсы. А передача персональных данных на сторону не такая уж хорошая идея, ведущая к нарушением законов РФ (персональные данные и т.п.).
И таки решил написать такое решение, которое будет работать на вашем ПК (серверах) без всяких там сторонних сервисов. Но так как Python так же, как и 1С, язык программирования некопилированный, то решение подобной задачи стало не такой уж и простой, но вполне решаемой.
В качестве основы был позаимствован репозитарий paSport_eye на GiHub. Данный продукт был адаптирован под Windows и 1С
Данная болванка очень простая, но при этом использует такие библиотеки, как Dlib и CV2, которые довольно-таки хорошо себя показали в распознавании лиц и изображений.
В качестве распознавателя мы используем бесплатный и самый на мой взгляд мощный продукт по распознаванию текста "pytesseract" от компании HP.
Итак, начнем:
1. Для начала установим Python.
Рекомендую ставить версию 3.9, так как с другими версиями могут возникнуть сложности по установке библиотек.
2.Далее открываем командную строку и входим в папку, куда вы установили Python, к примеру
cd c:\pyhton
3. Устанавливаем библиотеки
- Библиотека OpenCV
python -m pip install opencv-python - Библиотека Pillow
python -m pip install Pillow - Библиотека pytesseract
python -m pip install pytesseract - Библиотека rembg
python -m pip install rembg - Библиотека imutils
python -m pip install imutils - Библиотека matplotlib
python -m pip install matplotlib - Библиотека dlib Так как версии выше 22 автоматически устанавливают библиотеки куда, а после чего надо долго танцевать с бубнами и установкой библиотек Cuda - рекомендую ставить версию 19.22.1
python -m pip install -U dlib==19.22.1 - Библиотека tesseract-ocr
pip install pytesseract
4. Далее ставим программный продукт Tesseract. Он необходим для распознавания текста.
Данный продукт распространяется в открытом коде и собрать его под linux очень просто. Но нам нужна Windiws сборка и скомпилить+зарелизить его под Виндовоз не так уж и просто. Поэтому воспользуемся сборкой для win64 от немецких коллег из Мангеймского университета. Ссылка тут - Tesseract-ocr-w64-setup-5.3.0.20221.
1. Установку нужно делать на диск "С:" в папку %Program Files% (по умолчанию). Если сменить папку - то придется допиливать один Python модуль.
2. Необходимо выбрать расширенную установку и выбрать дополнительный набор Кириллических символов для распознавания русского языка.
Поздравляю, у вас теперь установлен прокачанный Python.
Как установить ПО 1С8, думаю, рассказывать не буду и пойдем дальше.
Скачиваем Python модули и разархивируем их, к примеру, в Папку c:\Python\Passp.
Сам архив полностью с открытым кодом(openSource) имеет основной файл passport.py и библиотеки в папке Lib.
Так же вспомогательные файлы для машинного обучения.

Давайте рассмотрим файл passport.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
import cv2
import argparse
import os
from lib.output import OUTput
from lib.rm_bg import RemoveBG
from lib.face_work import FaceWork
from lib.text_recognition import TessRecogn
from lib.search_data_with_cv2 import SDWCV2
from lib.script_return_abs_path import ReturnAbsPathPict
from lib.script_convert_image import ReturnPathConvertImage
def main():
ap = ap = argparse.ArgumentParser(
prog="python3 pasport_eye.py",
usage="%(prog)s -p /ПУТЬ/К/ПАПКЕ/С/ИЗОБРАЖЕНИЯМИ --improved_recognition ON или OFF -o terminal или scv",
description='''
)
ap.add_argument(
"-p", "--path_pict", required=True,
help="Путь к каталогу изображений паспортов!"
)
ap.add_argument(
"--improved_recognition", required=True,
help='''
Метод улучшенного распознования: ON или OFF.
ON - более точное распознавание, но и "выхлоп" от
скрипта более "жирный", так же, медленная работа скрипта.
OFF - все как обычно, но возможно, не точное распознавание.
'''
)
ap.add_argument(
"-o", "--output", required = True,
help = '''
Метод выполнения скрипта: trminal или csv.
terminal - создается папка: название_базы + _recogn,
в ней подпапка pict - лица из паспортов
и подпапка descript - дескрипторы в двоичном формате,
выхлоп распознования - в терминал.
csv - дескрипторы(в формате: float), изображение лиц(в формате: base64),
а так же данные паспортов сохраняются в НАЗВАНИЕ_БАЗЫ_С_ИЗОБРАЖЕНИЯМИ.csv
'''
)
ap.add_argument(
"-f", "--output_file", required=True,
help="путь к результирующему файлу"
)
args = vars(ap.parse_args())
if str(args["improved_recognition"]).lower() == "on" or str(args["improved_recognition"]).lower() == "off":
improved_recognition = str(args["improved_recognition"]).lower()
else:
print("improved_recognition только ON или OFF\nВыход!")
sys.exit()
if str(args["output"]).lower() == "terminal" or str(args["output"]).lower() == "csv":
output = str(args["output"]).lower()
else:
print("output только terminal или csv\nВыход!")
sys.exit()
# получаем правильный путь к файлам с точки срения python
path_pict=os.path.abspath(str(args["path_pict"]).lower())
abs_path_folder, filename = os.path.split(path_pict)
list_abs_path_folder = ReturnAbsPathPict().main(abs_path_folder)
folder = f"{path_pict}"
abs_path_pict = os.path.abspath(folder)
path_output = os.path.abspath(str(args["output_file"]).lower())
#print(abs_path_pict)
#print(list_abs_path_folder)
print(f"Идет распознование изображения: {abs_path_pict}\n")
# возврат полного пути + конвертация изображения в .png
path_cache_pict = ReturnPathConvertImage(abs_path_pict).main(abs_path_pict,list_abs_path_folder)
# возврат полного пути + удаление заднего плана
#path_pict_no_bg = RemoveBG(path_cache_pict, visualization=False).main()
path_pict_no_bg = path_cache_pict
# возврат словаря с данными(изображение без фото лица, само фото лица) + дескрипторы лица
dict_image_no_face_and_cropped_face = FaceWork(path_pict_no_bg, visualization=False).main()
# возврат списка выделенных данных с помощью cv2
data_list_gorizontal, data_list_vertical = SDWCV2(dict_image_no_face_and_cropped_face, visualization=False).main()
# возврат списка распознанных с помощью tesseract данных
list_all_data_gorizontal, list_all_data_vertical = TessRecogn(
improved_recognition,
data_list_gorizontal,
data_list_vertical
).main()
OUTput(
args,
output,
path_output,
dict_image_no_face_and_cropped_face,
list_all_data_gorizontal,
list_all_data_vertical
).main()
if __name__ == "__main__":
main()
Тут, думаю, все понятно:
1. модуль python получает необходимые аргументы - входные данные (изображение и название выходного файла и т.п.), которые нам понадобятся для вызова из 1С.
2. Конвертируем фото в png и меняем размер.
3. Далее распознаем лицо, используя библиотеки Open CV и Dlib на фото, для того чтобы правильно перевернуть фото.
4. После чего по заранее известным координатам получаем обрезки рисунков с необходимыми нам текстами.
5. Далее распознаем текст и выводим его в CSV файл. Easy ;-)
Ну что же, осталось подружить все это добро с 1С.
Пишем обработку на 1С. Тестировалось на Платформе 8.3.22.1750
&НаКлиенте
Процедура Распознать(Команда)
объект.ИмяВыходногофайла= "C:/python/paasport/output" + СокрЛП(Новый УникальныйИдентификатор())+".csv";
КомандаСистемы("C:\Python39\python C:\python\paasport\passport.py --p """+объект.Паспорт+""" --improved_recognition=off -o=csv -f="""+объект.ИмяВыходногофайла+"""","C:\python\paasport\");
Ожидание();
КонецПроцедуры
&НаКлиенте
Процедура Ожидание()
МойФайл = Новый Файл(объект.ИмяВыходногофайла);
Если НЕ МойФайл.Существует() Тогда
ПодключитьОбработчикОжидания("Ожидание",1);
иначе
Текст = Новый ЧтениеТекста;
Текст.Открыть(объект.ИмяВыходногофайла);
Строка = Текст.ПрочитатьСтроку();
объект.данныеПаспорта= Строка;
ОтключитьОбработчикОжидания("Ожидание");
КонецЕсли;
КонецПроцедуры
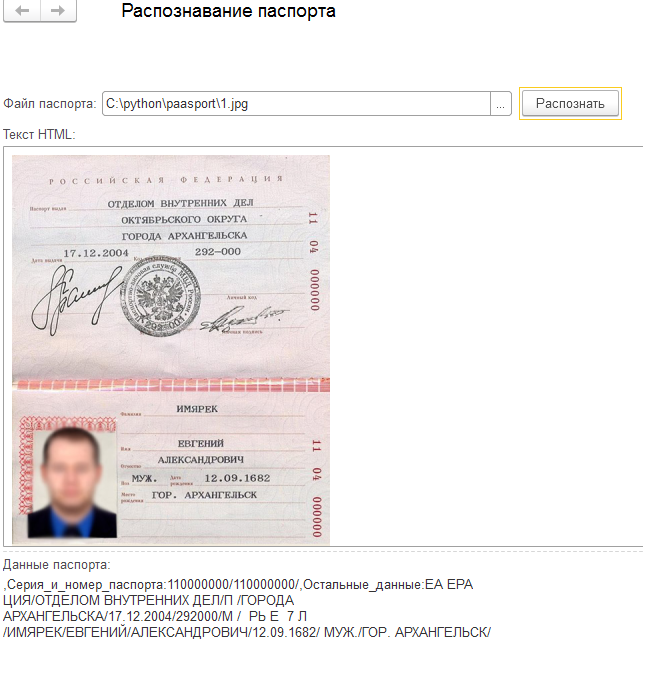
В итоге получаем неплохой результат.

Все получилось...
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}