



Содержание:
Описание расширения интеграции
Получение ключа для расширения интеграции
Введение
Общее увлечение искусственным интеллектом не обошло и меня стороной, и т. к. моя специализация — документооборот, то я решил поискать ответ на вопрос, можно ли сделать систему, которая позволит обрабатывать документы организации с использованием ИИ. Например, подготовить письмо контрагенту на основании всей переписки с ним или обработать и представить в удобном виде некую техническую документацию, да и просто найти файлы в базе 1С:Документооборот, но не по ключевым словам, а по смыслу. Решение этих задач позволит существенно увеличить производительность труда работников, а не в этом ли одна из основных задач программистов?
Немного погрузившись в контекст и выяснив, что задача не решается в лоб (о попытке «срастить» Документооборот и Ollama тут), я решил посмотреть, какие подходы существуют в мировой практике. Оказалось, что уже существуют готовые платформы, которые позволяют решать любые (почти) задачи с использованием ИИ. То есть там и web-интерфейс, и администрирование пользователей, и настройка моделей, и обработка документов, интеграция с поиском, распознавание и синтез голоса, и много чего ещё.
Платформа Open WebUI была выбрана мной для изучения, потому что в ней собраны все актуальные на данный момент технологии ИИ, соответственно, изучая эти технологии, получаешь представление о самых передовых тенденциях. Вот Яндекс на тарифе PRO внедрил персонификацию, а в Open WebUI этот механизм уже давно есть, и автоматическое извлечение персонифицирующей информации делается специальной функцией. Кстати, желающим посмотреть на мегапромт этой функции, рекомендую глянуть тут (в самом низу).
Сначала коротко про интеграцию с Документооборотом, потом уже буду описывать платформу.
Описание расширения интеграции
Документы в Open WebUI можно объединять в базы знаний для совместной обработки (из описания платформы будет понятно, зачем так), поэтому в Документообороте решил использовать категории для объединения документов. Можно использовать существующие, а можно и специальные категории создать для целей интеграции.
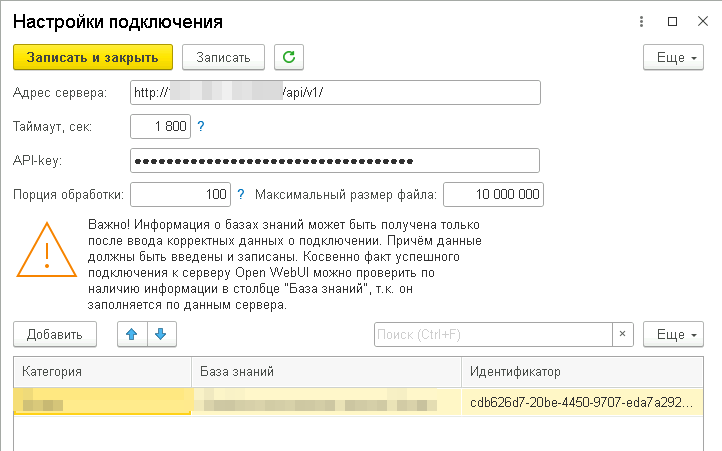
В настройках нужно указать адрес сервера Open WebUI и связать предварительно созданные базы знаний и категории. Доступ осуществляется по API-токену, который находится в настройках пользователя платформы Open WebUI. Очень рекомендую для импорта документов из Документооборота создать отдельного пользователя, это не только вопрос безопасности, но ещё и скорости, а в настройках ограничить доступ данному пользователю только к тем базам знаний, которые соответствуют категориям. Эта рекомендация связана с тем, что платформа при запросе списка файлов в базах знаний возвращает все файлы по всем базам, которые доступны пользователю, соответственно, будет много лишней информации.
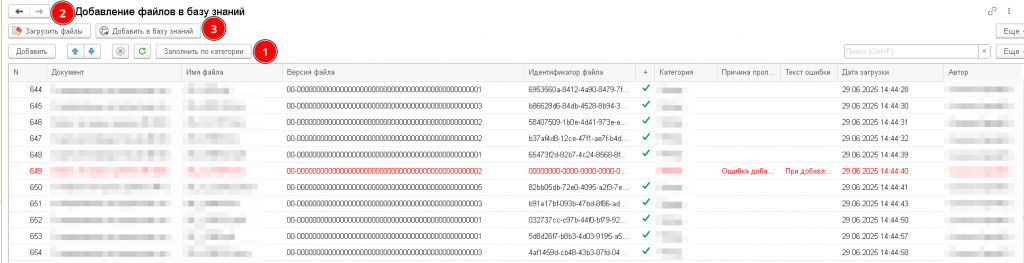
Добавление файлов можно осуществлять вручную с помощью обработки «Добавление файлов в базу знаний», например, можно заполнить таблицу по категории (1), при этом будут показаны результаты предыдущих загрузок, потом загрузить файлы в Open WebUI (2), для них будут получены уникальные идентификаторы, а потом добавить файлы в базу знаний (3).
Основным способом загрузки файлов является регламентное задание «Обновление базы знаний OpenWebUI», которое для каждой категории получает некоторое количество файлов (размер порции задаётся в настройках), загружает их на сервер Open WebUI и добавляет в соответствующую базу знаний. Если у файла появляется новая версия, то старая удаляется, и загружается новая.
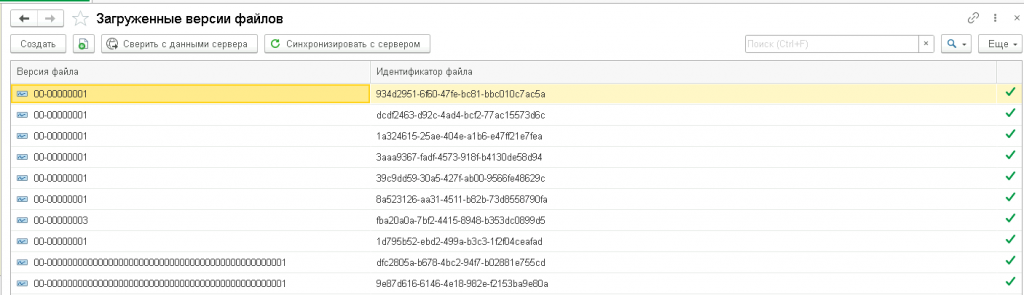
Для ручной синхронизации файлов между 1С:Документооборот и платформой есть специальная форма, у неё две кнопки: сначала сверяем списки файлов, потом синхронизируем, то есть удаляем из регистра те, которых уже на сервере нет и удаляем на сервере те, которых нет в регистре.
Вся остальная работа происходит в интерфейсе платформы Open WebUI, к ней и переходим.
Небольшая вводная часть
Характеристики сервера, установка сервера Ollama и его настройки описаны тут, все остальные сервисы устанавливаются как контейнеры Docker. Постараюсь не повторять официальную документацию, только те вопросы, которые у меня вызвали трудности. Все настройки актуальны для версии Open WebUI 0.6.15 и Ollama 0.6.7. У меня сейчас всё запущено через docker-compose, но т.к. каждый компонент буду разбирать отдельно, то и команды запуска буду писать отдельно для каждого контейнера.
Описание платформы Open WebUI
Установка
Идём на страницу официальной документации, там написано, как скачать и запустить. Единственное, что я не использую передачу параметров платформы через переменные окружения, почти все параметры можно установить в настройках, так нагляднее и не нужно перезапускать контейнер при изменении.
Также не забываем, что по умолчанию все данные подключаемого тома Docker будут лежать в папке /var/lib/docker/volumes/open-webui/_data. Там будут копии загруженных файлов, база самой платформы и векторная база RAG, так что нужно позаботиться о свободном месте. Я ещё удаляю файлы, которые загружены больше месяца назад скриптом через cron.
Администрирование
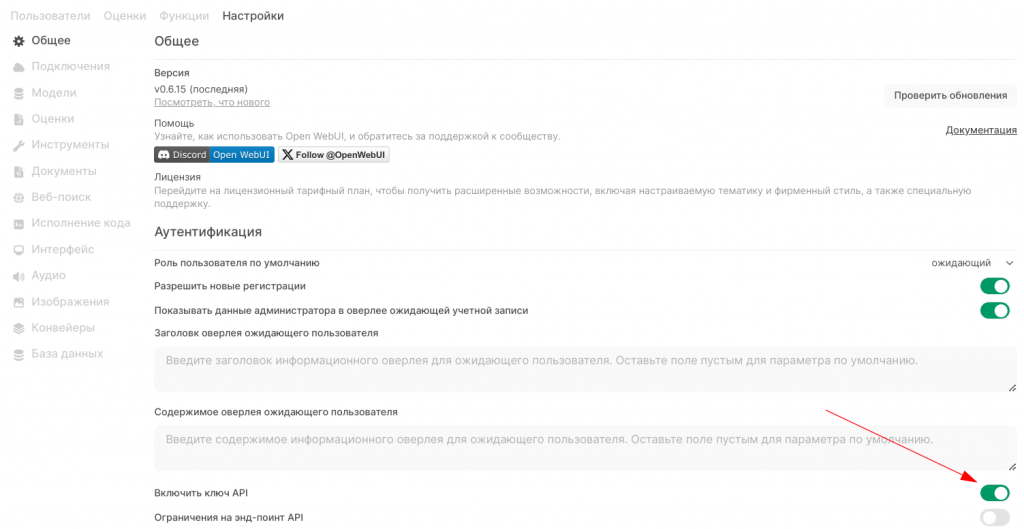
Запускаем, создаём себе логин с паролем, идём в настройки, пункт «Общее», там важно включить «Включить ключ API», только после этого у пользователей появится возможность авторизации по API. Иначе только JWT, что неудобно. На скринах видны мои текущие настройки, они, в основном, понятны. Отмечу только, что тут есть возможность сделать так, чтобы пользователи сами себя заводили, а администратор потом им давал необходимые права. Есть группы пользователей и авторизация LDAP, для использования в корпоративной среде.
В платформе Open WebUI поддерживаются два протокола исходящих подключений, а именно Open AI и Ollama. Сейчас почти все современные системы ИИ поддерживают API от Open AI, исключениями стали (как ни странно) Яндекс и Сбер. У Яндекса API свой, но очень дружелюбная поддержка и есть адаптер, а API Сбера очень похож на «нормальный», но API-токен живёт 30 минут и его необходимо получать с использованием другого токена. Да, и техподдержка не многословная и помогать не собирается. Поэтому я использовал адаптер для подключения к ИИ Яндекса, информация о нём тут, можно собрать свой контейнер, чтобы ни от кого не зависеть. Как получить ключ API от сервисов Яндекса, не буду описывать, но отмечу, что общий ключ подключения получается составной через символ «@», т.е. {FOLDER_ID}@{API_KEY_OR_IAM_KEY}.
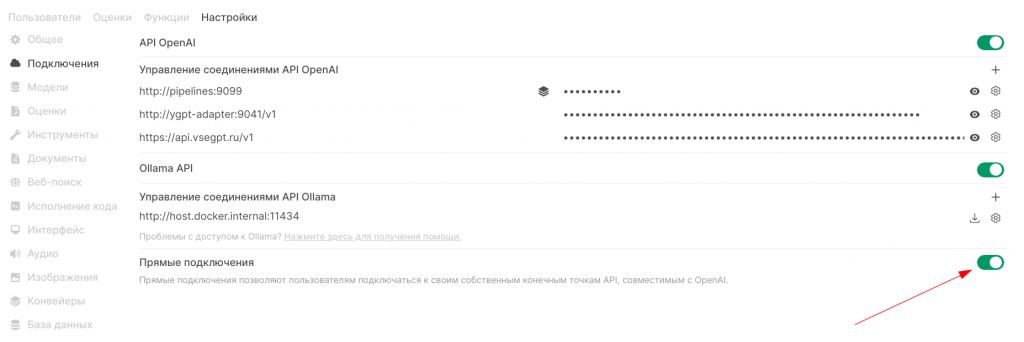
На скрине стрелкой указана важная для интеграции с Документооборотом настройка, чтобы можно было снаружи вызывать функции Open WebUI через протокол Open AI.
У меня добавлены подключения к конвейеру моделей (описание тут), адаптеру API вызовов Yandex.GPT и ещё одному очень хорошему сайту, через который можно получить доступ к разным моделям ИИ.
Ниже в настройках идёт строка подключения к серверу Ollama для использования локальных моделей. Напоминаю, что про работу с этим сервером я уже писал в предыдущей статье.
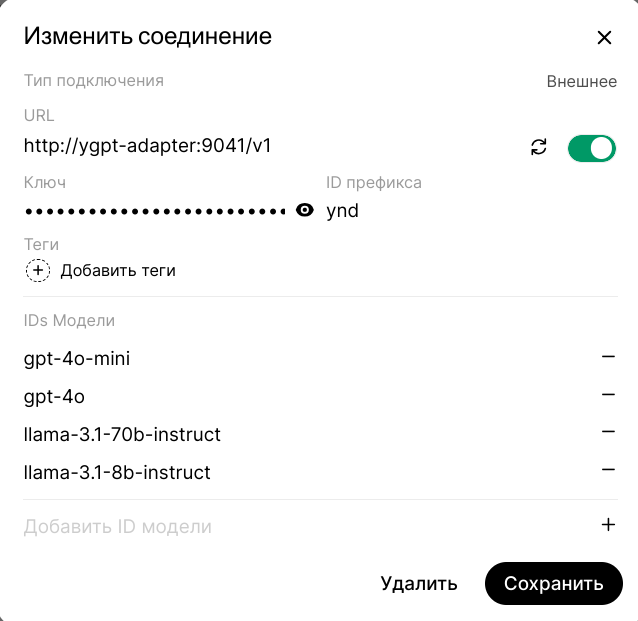
На примере подключения через адаптер к моделям Яндекс покажу, как настройки выглядят внутри. Это важно для случая, когда удалённый сервер не поддерживает получения списка моделей или их очень много и нужно видеть только некоторые. Кстати, обратите внимание, что Яндекс на своих мощностях позволяет использовать не только модели Yandex.GPT, но и от запрещённой Meta, а модель Llama:70B хоть и старенькая уже, но довольно крутая. Пусть имена первых двух моделей не вызывают удивления, в адаптере есть мэппинг с моделями Яндекса.
Pro деньги
Очень хочется, чтобы ИИ был доступен бесплатно и навсегда, но так не получается. Опыты показывают, что обычный сервер на базе Intel Xeon 2200 на 12 ядер и 24 потока не в состоянии решать даже вспомогательные задачи, такие как векторизация текста, формирование заголовков чатов, поисковых запросов и т.д. Если туда ещё добавить функции памяти и тегирование чатов, то всё, туши свет. Точнее, в состоянии, но в однопользовательском режиме, как только к серверу Ollama идёт два и более запросов одновременно, он ложится.
Поэтому для «боевого» использования такой системы варианта всего два:
- основную обработку производить на внешних серверах, а у себя иметь что-то для запуска небольших моделей;
- покупать себе сервер с возможностью запуска больших моделей ИИ.
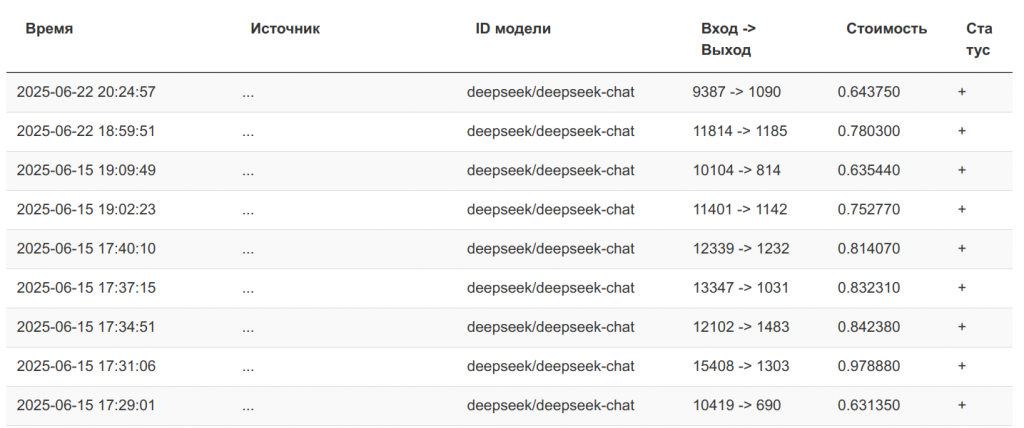
Поделюсь статистикой стоимости запросов на сайте vsegpt.ru. Это я генерировал комментарии для экспортных функций 1С. Кстати, в прилагаемом к статье расширении все комментарии к экспортным функциям сгенерированы ИИ, прошу обратить на это внимание. Видно, что, несмотря на то, что на входе было много данных (передавался промт, обогащение RAG из БСП и текст функции), всё равно стоимость одного запроса не превышает 1 руб. Т.е. не сказать, чтобы очень дорого, особенно для личного использования.
С другой стороны, если запросов много, то может быть выгоднее собрать (арендовать) что-то своё, но нужно помнить, желательно, чтобы вся модель помещалась в VRAM. Я экспериментировал с моделью qwen-coder:14b, так вот при контекстном окне 32k она занимала в памяти больше 45 Гб. Так что нужно две видеокарты с памятью 24 Гб, соответствующая материнка с поддержкой полноценной шины PCI-e x16 на обоих портах, ну и стоить такая система будет соответственно.
Для организаций, которые не хотят, чтобы их данные улетали непонятно куда, могу порекомендовать модели Яндекса или Сбера, для которого тоже можно конвертер написать.
Модели

На вкладке «Модели» представлены базовые модели, т.е. те, которые загружены на сервер Ollama (это локальные модели) или добавлены через пункт «Подключения» (внешние модели). Когда внешних моделей много, то для визуального определения их источника рекомендую использовать «ID префикса», он заполняется в настройках соединения.
Сверху справа команды, позволяющие работать с моделями на сервере Ollama, и управлять общим списком моделей.
Для каждой модели есть отдельное меню настройки, там можно выбрать режим доступа к модели Публичное/Частное и для режима «Частное» есть возможность указать группу пользователей и право доступа. Здесь можно указать базовые модели, на основе которых пользователи смогут создавать свои специализированные модели (или вы будете создавать их для них). Ещё тут можно установить размер контекстного окна и температуру, а также иные параметры. Рекомендую именно тут устанавливать возможности модели, т.е. если это не мультимодальная модель с функцией распознавания текста, то флаг «Видение» нужно снять. Тоже касается возможности «Генерация изображений». Инструменты и функции, на мой взгляд, правильнее настраивать уже для специализированных моделей.
Документы
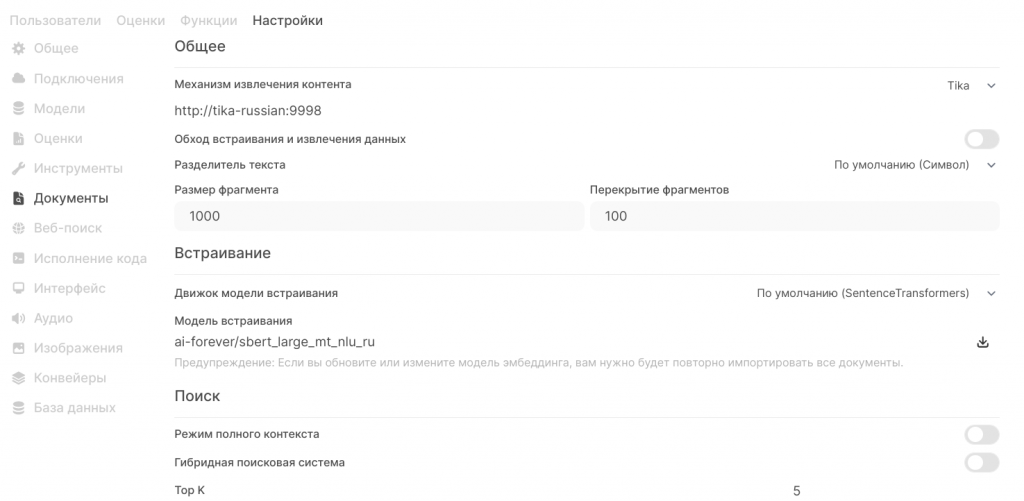
Это самый интересный раздел, от настроек зависит как будет осуществляться поиск информации, дополняющей наш промт. Не буду тут останавливаться на теории обогащения данных с помощью RAG (Retrieval Augmented Generation) в Интернете много информации, опишу реализацию данного механизма в Open WebUI:
- документ нарезается на фрагменты (чанки) по 1000 символов, чтобы избежать того, что будут потеряны части слов, используется перекрытие фрагментов;
- специальной embedded моделью, текст превращается в набор векторов и сохраняется в векторной базе, по умолчанию используется Chroma, но поддерживаются и другие, более мощные векторные СУБД.
- при поиске из базы извлекаются наиболее близкие по смыслу фрагменты текста и добавляются к промту, то есть запрос обогащается внешними данными.
Теперь немного углубимся.
Извлечение контента
У нас в Документообороте и на компьютере много документов различных форматов, а какой формат максимально удобен для обработки с помощью генеративных моделей? Оказывается, что «родным» для LLM (Large Language Models) является язык разметки Markdown. И тут появляется резонный вопрос, а как pdf-документ со сканера, например, сконвертировать в этот формат? Оказывается есть несколько способов. Сама платформа Open WebUI умеет конвертировать документы, но нам такой способ не подходит так как этот механизм не распознаёт кириллицу. Кстати, кириллицу много кто не распознаёт «из коробки».
Внешние on-line сервисы я рассматривать не буду, т.к. не все готовы свои корпоративные документы передавать непонятно куда.
Остаётся два локальных инструмента: Apache Tika и Docling. Оба сервиса можно установить в виде docker контейнера, оба получают на вход произвольные документы, распознают их при необходимости и возвращают в нужном формате. Docling очень крут, он не только распознаёт документы, но и пытается понять, что находится на изображениях и добавляет их описание. Но это требует использования мощной мультимодальной модели, а у меня не позволяет этого аппаратная часть, так что пока только мечтаю.
Сервис Apache Tika тоже не понимает кириллицу, но его можно допилить, дело в том, что для распознавания используется движок OCR Tesseract, я с ним познакомился на этом проекте. Туда можно доставить пакеты русского языка и принудительно выставить языки для распознавания. Готовим файлы.
Режим полного контекста
Когда мы думаем о чем-то, мы из памяти извлекаем фрагменты знаний и используем их для размышлений, аналогично тому, как платформа Open WebUI извлекает текстовые чанки из векторной базы и добавляет их во входные данные генеративной модели. Искусство составления промта как раз и состоит в том, чтобы вытащить необходимую для правильного решения информацию из базы с использованием RAG. Кстати, и модный нынче режим «размышления» у генеративных моделей также имеет целью расширить промт, чтобы в алгоритм обработки поступило больше данных, относящихся к вопросу пользователя, т.к. современные модели имеют большое контекстное окно.
Все файлы, которые загружает в платформу пользователь, проходят подготовку для использования в механизме обогащения данных, однако этот механизм может вызывать странную ситуацию:
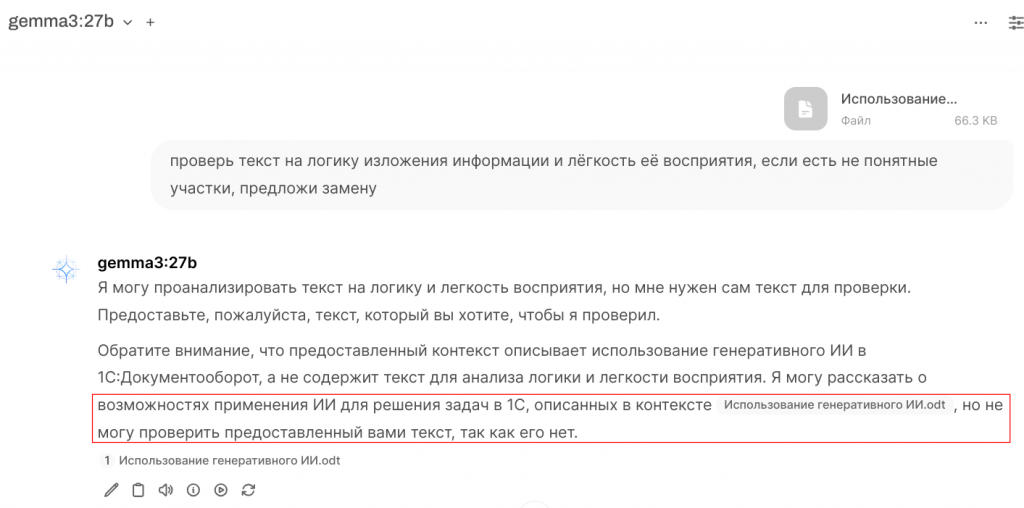 Я открываю новый чат, беру файл с текстом, прошу модель его проанализировать, но получаю ответ, что текста нет. Что произошло? А платформа попыталась обработать файл и получить из него данные на основе промта, но в промте нет тех «крючочков», за которые можно вытянуть данные из файла, промт касается обработки файла целиком.
Я открываю новый чат, беру файл с текстом, прошу модель его проанализировать, но получаю ответ, что текста нет. Что произошло? А платформа попыталась обработать файл и получить из него данные на основе промта, но в промте нет тех «крючочков», за которые можно вытянуть данные из файла, промт касается обработки файла целиком.
До версии 0.6.18 для настройки поведения платформы было два параметра: «Обход встраивания и извлечения данных (Bypass Embedding and Retrieval)» и «Режим полного контекста (Full Context Mode)». Первый просто отключает использование RAG, а второй режим управляет тем, как обрабатываются входные данные, происходит ли извлечение из этих данных фрагментов на основе промта или весь входной текст передаётся в модель. Однако второй режим совершенно не годился в случае использования модели с базами знаний с большим количеством файлов (а именно на это рассчитана интеграция), платформа будет пытаться весь текст из файлов передать в модель, и он, естественно, не поместится в контекстное окно. Для обработки текста документа совместно с базой данных, приходилось его копировать в чат, что не влияло на качество обработки, но делало чат не читаемым.
 А начиная с версии 0.6.18 ситуация радикально поменялась, для каждого файла, добавляемого в чат или группу чатов, можно указать режим контекста, – данные из файла будут извлекаться частично или извлечённый из файла текст будет передан на вход модели полностью. Также, при подключении базы данных к модели можно указать режим поиска, таким образом можно передавать модели с большим контекстным окном небольшую базу данных целиком для обработки.
А начиная с версии 0.6.18 ситуация радикально поменялась, для каждого файла, добавляемого в чат или группу чатов, можно указать режим контекста, – данные из файла будут извлекаться частично или извлечённый из файла текст будет передан на вход модели полностью. Также, при подключении базы данных к модели можно указать режим поиска, таким образом можно передавать модели с большим контекстным окном небольшую базу данных целиком для обработки.
Фрагмент доработан 03.08.2025, описание важного функционала новой версии
Модели встраивания (embedded models)
А это «сердце» нашей системы. Тут необходимо указать, какая модель будет формировать векторное представление наших текстов и наших промтов. Есть встроенный движок и несколько возможных вариантов подключения к удалённым серверам. Все сервисы ИИ, которые поддерживают технологию RAG, имеют свои модели встраивания, модель встраивания всегда только одна, то есть нельзя сформировать векторную базу одной моделью, а получить вектора из промта с помощью другой. Поэтому выбор модели встраивания – крайне важное и ответственное дело. Модель, которая у меня используется в настоящее время, указана на скрине, она не самая лучшая, но достаточно быстрая для CPU и адаптирована под русский язык.
Про выбор модели (и движка) много писать не буду, нужно экспериментировать, выбор большой:
- универсальные мультиязычные модели на официальном сайте.
- рейтинг моделей тут, можно выбрать как универсальные, так и отдельно русскоязычные.
Мы на проекте пробовали закреплять сотрудников за ведением определённых специфических баз, например, баз нормативных документов и публикации этих баз для остальных пользователей. Самым удобным оказался алгоритм, когда сотрудник у себя имел копию документов из базы, тогда при смене модели встраивания было проще обновить файлы.
Веб-поиск
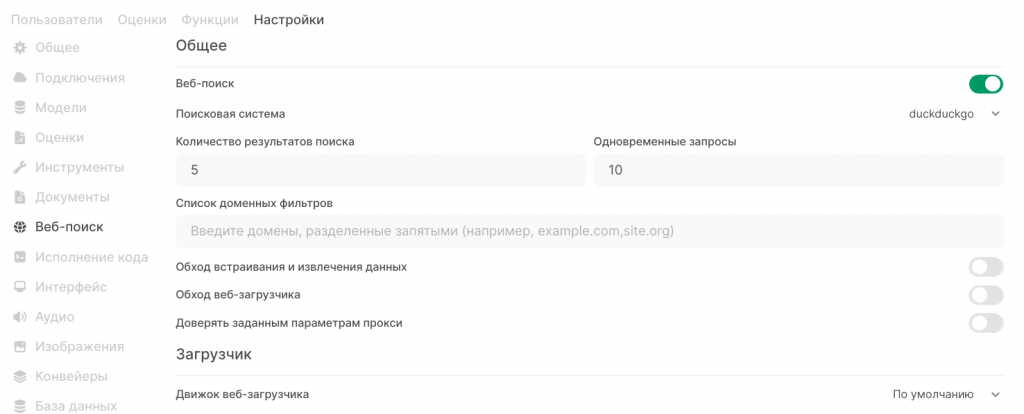
Передать модели для обработки можно не только данные из документов с помощью RAG, но и результаты поисковых запросов. Тут ничего сложного нет, но чтобы сэкономить время настройки, поясню некоторые параметры.
У меня ощущение, что есть все поисковые системы, кроме Яндекса, все требуют ключ авторизации (и деньги). Бесплатно только DuckDuckGo, но и ищет он плохо, особенно в рунете. Выход есть, и он называется External: в документации есть формат запроса и ответа. Для Яндекса можно сделать конвертер, но пока руки не дошли. Плюс данного решения в том, что далеко не все сайты позволяют скачивать данные, то есть самого поиска недостаточно, нужно ещё и страницу получить. Тут у Яндекса есть неоспоримый плюс: можно запрашивать не саму страницу, а её сохранённую копию, что значительно проще.
Также есть отдельный выключатель режима полного контекста «Обход встраивания и извлечения данных», который позволяет передавать все загруженные из Интернета данные в модель, для моделей с большим контекстным окном это может быть предпочтительней, чем RAG.
Интерфейс
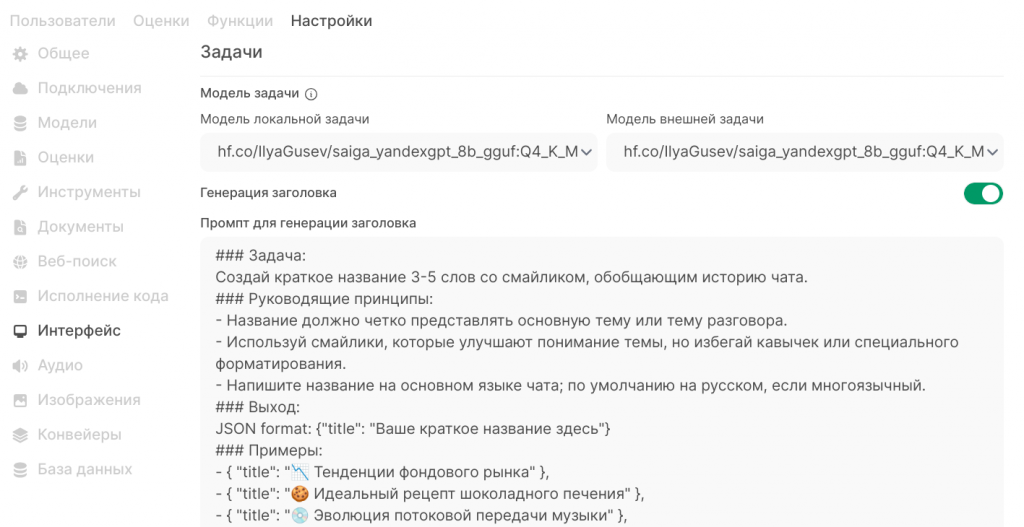
В мире LLM всё управляется промтами, так вот эта страница – промты для выполнения вспомогательных задач. Один промт мы уже видели на странице «Документы», но я про него ничего не написал, потому что его не нужно трогать, а тут находятся промты для:
- генерации заголовков чатов;
- генерации продолжения разговора после ответа сервера (это возможные вопросы для продолжения диалога, пока не очень понял смысл);
- генерации тегов для быстрого поиска (не использую);
- генерации поисковых запросов, то есть по последним 6-ти сообщениям в чате (по умолчанию) генерируется от одного до трёх запросов, результаты загружаются, из них извлекаются данные и передаются в модель;
- генерации автопродолжения (на мой взгляд, просто зло);
- генерации вызова инструментов (очень глубокая тема, выходит за рамки статьи).
Все эти промты обрабатываются быстрой моделью, однако даже такие простые задачи сервер без GPU в многопользовательском режиме не тянет, печаль.
Промты по умолчанию для разных режимов можно поискать тут поиском по слову «prompt».
Аудио
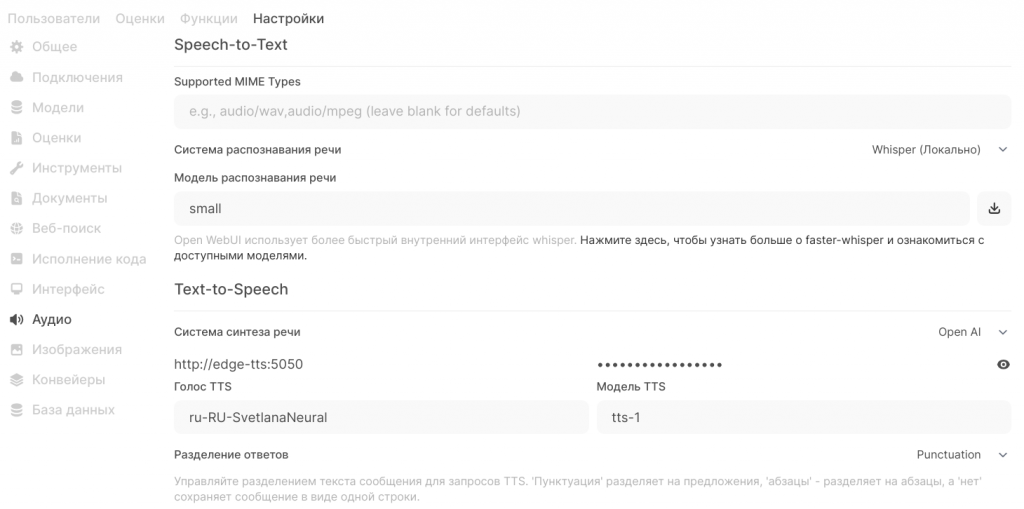
Данный пункт не относится напрямую к интеграции с Документооборотом, но зато позволяет быстро показать руководству пользу от покупки нейроускорителя. Можно записать совещание, как аудиофайл, скормить платформе и получить некое подобие протокола с обсуждаемыми вопросами, итогами и т.д. Не нашёл публичных движков STT, которые умеют различать голоса говорящих, Whisper всё сваливает в одну кучу.
Настройка Speech-to-Text простая: выбираю движок (у меня Whisper), указываею имя модели (small, base, medium, large), нажимаю кнопочку слева, и платформа скачает нужную модель транскрибации. Не заметил большой разницы между small и base, а medium распознаёт текст лучше, но ресурсов требует больше.
Если сервер Open WebUI у вас в сети доступен по протоколу http (что логично внутри организации), то микрофон работать не будет, а чтобы он заработал, нужно сделать, как написано тут.
Если настроить синтез речи по инструкции тут, то с моделью вообще можно общаться голосом в чате.
Рабочее пространство
Ну всё, закончили с настройками платформы, настраиваем базы знаний и модели
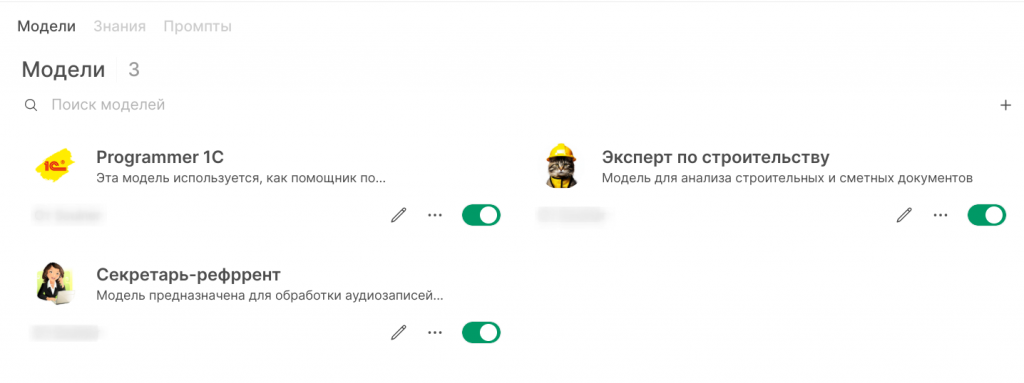
Вот пример списка специализированных моделей у пользователя. У администратора видны все пользовательские модели, и это не всегда удобно: интерфейс тормозит.
Что значит специализация модели? А это системный промт, настройки и подключённые базы знаний, необходимые для решения конкретной задачи. Промт-инжиниринг – это отдельная наука, но как ни странно в этой области здорово помогают «старшие братья», то есть можно спросить «большую» модель написать системный промт для решения конкретной задачи.
По поводу оформления, я решил подходить творчески, и пользователям приятно, когда весёлые картинки у них на рабочем столе, и мне по описанию понятно, под что заточена модель.
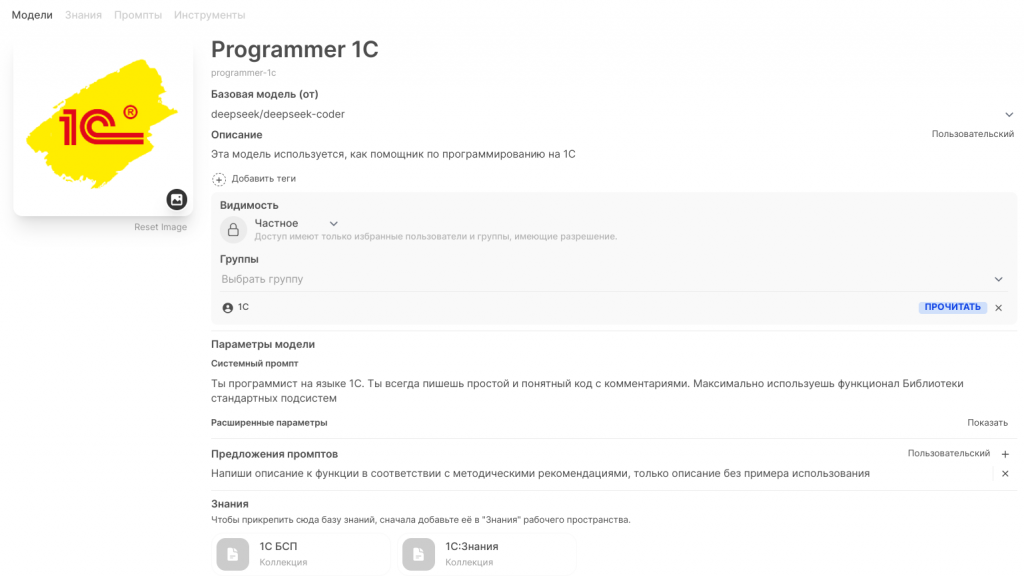
Приведу пример настроек специализированной модели, которую сам использую для программирования. Сверху указывается базовая модель, у меня это DeepSeek, есть небольшой системный промт, в параметрах указана низкая температура (0.2) и большое контекстное окно (128000). К модели подключены две базы знаний: в одной - описание функций БСП 3.1.10, а в другой - скачанные тексты по программированию с разных сайтов. В настоящий момент не в восторге от качества кода, который генерирует такая модель, но причину вижу в модели встраивания. Буду экспериментировать дальше. Комментарии к экспортным функциям модель пишет обалденные, а это уже неплохая помощь.

База знаний – это ещё более простая вещь, некое логическое объединение файлов для поиска в них информации для встраивания. Справа список файлов, слева извлечённый из файла текст. Справа вверху кнопка настройки доступа групп пользователей к данной базе. При создании базы нужно просто придумать название и описание.
Получение ключа для расширения интеграции
Теперь, когда всё настроено, необходимо подключить наше расширение интеграции, для чего создаём пользователя, придумываем ему пароль и логинимся под ним.
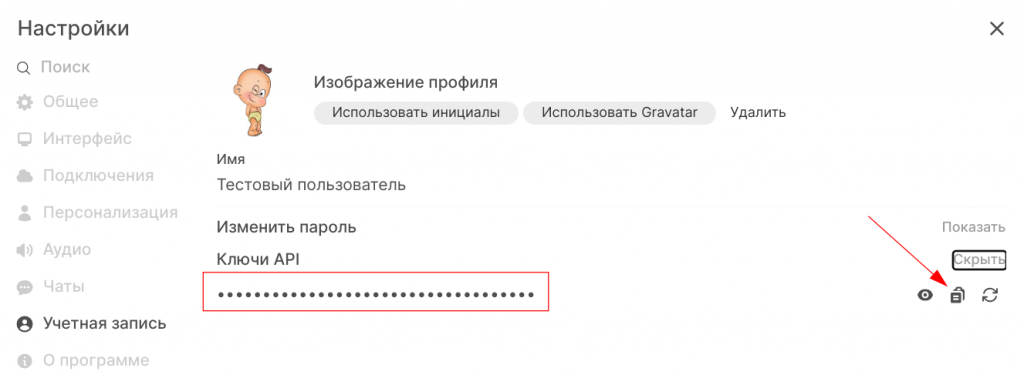
В настройках пользователя копируем ключ и вставляем в соответствующую настройку расширения. Пользователь должен входить в группу, у которой есть доступ на запись к базам знаний, в которые будут выгружаться документы.
Эта статья продемонстрировала процесс интеграции искусственного интеллекта в систему документооборота предприятия с целью повышения эффективности обработки корпоративных документов. Мы рассмотрели практический опыт установки и настройки платформы Open WebUI, позволяющей создавать специализированные инструменты анализа и поддержки принятия решений на основе собственных баз знаний компании, как создаваемых пользователями, так и автоматически загружаемых из 1С:Документооборот. Применение таких технологий открывает новые горизонты для предприятий любого масштаба, снижая временные затраты сотрудников и повышая качество выполняемых операций.
Рассмотрены далеко не все возможности платформы Open WebUI, например, есть функция, которая по данным в тексте может построить график или диаграмму, а есть ещё инструменты, которые позволяют подключаться к другим источникам данных, получать дополнительные сведения для обогащения запросов к моделям. К тому же платформа развивается и скоро появятся новые функции.
Расширение протестировано на ДГУ 2.1.36.3, соответственно и на ДО Корп тоже взлетит, платформа 8.3.24.1548.
Upd. 29.08.2025. У меня похоже получилось сделать файл docker-compose.yml, который соберёт все необходимые образы и запустит уже готовую (почти) систему для работы с нейросетями в организации, с поддержкой CUDA и всеми вкусностями. Как я уже писал, без NVidia A10 24Gb или NVidia GeForce 3090 24Gb нечего и начинать, а настроить всю эту красоту в docker оказалось не просто. Вот ссылка на репозиторий, это не Git, но работает также все инструкции в наличии.
Проверено на следующих конфигурациях и релизах:
- Документооборот КОРП, релизы 2.1.36.3
Вступайте в нашу телеграмм-группу Инфостарт