Когда мы говорим о любых IT-системах, в большинстве случаев подразумевается, что они создаются для оптимизации, улучшения или повышения эффективности бизнес-процессов. Без выстроенных процессов нормальная работа невозможна – все превращается в хаос. Каждый раз, когда я вижу, как у кого-то все идеально работает, все разложено по полочкам, задачи закрываются вовремя, – я невольно спрашиваю себя: а такое вообще бывает?
Разрыв между ожиданиями и реальностью
Когда начинаешь обсуждать с людьми за кружкой пива, как у них все устроено, обычно слышишь одинаковые истории: процессы не работают, система не работает, ничего не работает. Точнее не работает так, как было задумано. И это правда – не стоит думать, что только у вас все плохо, а у других идеально. Не волнуйтесь, плохо у всех.

Реальные, живые бизнес-процессы почти всегда отличаются от тех, что были запланированы. Как на этой картинке: все красиво, дорожка проложена, но люди находят обходные пути.
Чтобы разобраться, что представляет собой реальный процесс, нужно провести анализ и понять, что на самом деле происходит. Это и есть главная проблема – увидеть реальную картину. Нужно выявить, какие маршруты действительно работают, как пользователи выполняют операции, какие действия являются типовыми, а где происходят отклонения.
Пример из банковской практики
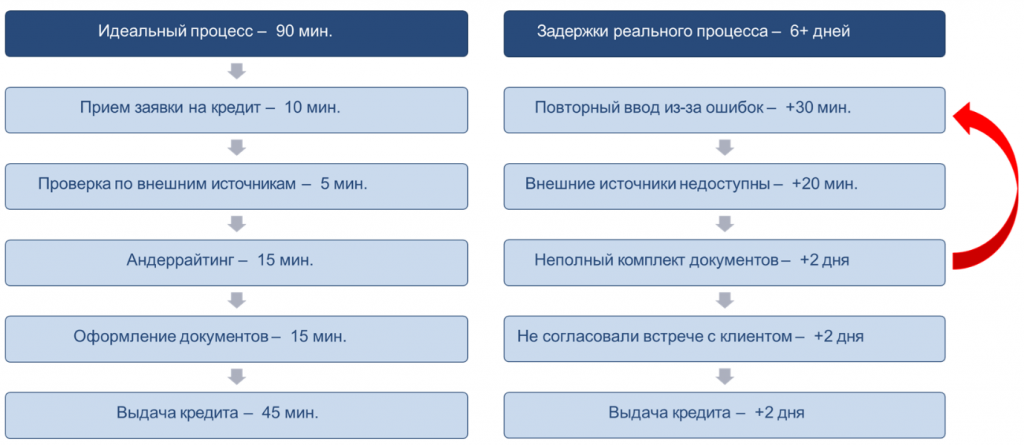
Для примера давайте посмотрим, как это выглядит, скажем, в банке. Я взял самый понятный случай – процесс выдачи кредита. В других направлениях в целом все примерно то же самое.
Если посмотреть на то, как этот процесс запланирован, то в любом банке ипотеку или автокредит должны выдать буквально за полчаса. Вроде бы никаких технических проблем: проверили документы, посмотрели данные, приняли решение – и готово. Но если вы пробовали брать ипотеку, то знаете, что в реальности все происходит иначе.
Живые, реальные бизнес-процессы выглядят так, как на схеме справа: документы прислали не те, при вводе данных допущены ошибки, заявки возвращаются назад, запрашиваются поручители, не согласованы встречи – и так далее. На практике все оказывается гораздо сложнее, чем в теории.
Задуманный бизнес-процесс кажется простым. Но если попытаться разобраться, как он выглядит в реальности – взять фактические действия и связи между ними – получится не стройная схема, а запутанный клубок.
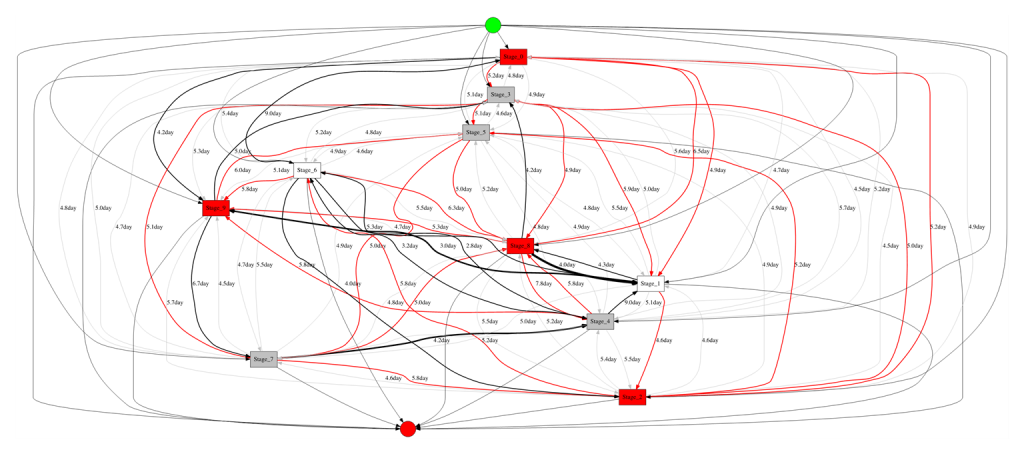
Большинство компаний, внедряя BPM-системы, уверены: «Сейчас мы все наладим». Все с энтузиазмом берутся за работу.
Проходит время, и энтузиазм сменяется раздражением. Команды доходят до предела и говорят: «Всё, больше ничего описывать не будем – это невозможно». Потому что реальные бизнес-процессы выглядят вот так – хаотично, запутанно, хотя действий в них, казалось бы, не так много, всего десяток.
И это еще взгляд издалека. Если приблизиться, всплывают новые детали, нюансы и неожиданные «приколы».
Определение процесс-майнинга
Process Mining – это процесс выявления и анализа бизнес-процессов. Слово «process» здесь не случайно. Самое важное – что все строится на основе цифровых следов.
Можно, конечно, обсуждать процессы «на глазок» – подумать, поговорить с коллегами, прийти к какому-то выводу. Но это не Process Mining. Настоящий процесс-майнинг опирается на реальные данные – на те следы, которые оставляет каждый этап выполнения процесса. И уже на основании этой информации можно принимать решения.
Первый шаг – это анализ текущего состояния: здесь нужно понять, как процесс работает сейчас, сколько на него уходит времени и ресурсов, выполняются ли обязательные этапы и требования. Нужно отделить обязательные шаги от необязательных и увидеть, где происходят отклонения.
Следующий блок – это сравнительная аналитика, или эталонное оценивание. Когда мы можем понять, что, например, в среднем на обработку заявки у сотрудника уходит три минуты, а у кого-то – два дня. Или при разгрузке товара нормальное время одно, а в конкретном случае – в разы больше.
Также проводится анализ нетипичного поведения и отклонений. И это очень важный момент: нестандартное поведение не всегда ошибка – иногда за ним могут скрываться признаки мошенничества или другие аномалии, требующие внимания.
И, наконец, «вишенка на торте» – предсказательная аналитика, когда используются методы машинного обучения для прогнозирования дальнейшего развития процессов.
Этапы реализации проекта процесс-майнинга
Сначала нужно решить вопрос с логированием, то есть зафиксировать те самые цифровые следы. На первый взгляд звучит тривиально – ведь информация вроде бы где-то есть. Но на практике все гораздо труднее. Процессы бывают сложными, они могут проходить через множество участков и систем.
Вот, например – Customer Journey. Нужно понять, как человек у вас покупает. Если задуматься, окажется, что это вовсе не выглядит как простая последовательность действий: зашел на сайт, кликнул и купил. На деле все гораздо разнообразнее. Клиент может сначала прийти на сайт, потом позвонить в офис, потом лично приехать посмотреть товар, а потом еще раз перезвонить и уточнить детали. И так далее.
В большинстве случаев зафиксировать все эти контакты очень сложно. Например, человек позвонил по телефону, не представился и спросил: «Сколько у вас стоит утюг?» Вы ответили: «Две тысячи рублей». Но кто звонил, какой именно утюг интересовал – это нигде не сохранилось. Контакт состоялся, но цифрового следа не осталось.
Следующий этап – консолидация. Нужно собрать всю эту информацию воедино, потому что чаще всего она разбросана по разным системам. Честно говоря, я еще ни разу не сталкивался с ситуацией, когда все данные по процессу находились в одной системе.
Далее идет входной аудит – нужно проверить качество данных, так как в них постоянно встречаются пропуски, аномалии, дубликаты, противоречия и прочие дыры.
После этого наступает, пожалуй, самая интересная и важная часть – воссоздание реального процесса. То есть нужно понять, что же на самом деле происходило.
Дальше следует разведочный анализ. Когда процесс уже восстановлен, нужно понять, что в нем происходит. Разведочный анализ – это как взгляд с высоты: мы смотрим на процесс целиком и отмечаем подозрительные зоны. Например, в каком-то месте слишком много действий, в другом – необычно долгие задержки или чрезмерные расходы.
Следующий этап – первичный анализ. Если разведочный анализ помогает выдвинуть гипотезы, то здесь уже идет проверка этих гипотез на данных. Отслеживается ход процесса, рассчитываются различные KPI, анализируются причины задержек и узкие места.
Иногда в проектах появляется еще один полезный элемент – автооповещения. Это очень удобная вещь. Если мы уже описали процессы и хотим контролировать время их выполнения, система может автоматически уведомлять нас о проблемах. Например, на выполнение этапа выделено пять минут, а прошло три дня – это уже сигнал. Значит, где-то задержка, и нужно разобраться, что произошло.
И наконец, моделирование. Здесь выявляются типовые паттерны, прогнозируются переходы и используется предсказательная аналитика.
Если удается пройти все эти шаги, это действительно очень круто. Потому что это уже зрелый, выстроенный процесс.
Проблема качества и доступности данных
В чем достоинство Process Mining? Это действительно очень крутая штука. Потому что каждый раз, когда люди занимаются анализом данных, все упирается в одно – в наличие самих данных.
Обычно говорят: «Давайте проанализируем клиентов». Хорошо, но давайте посмотрим, какая информация о клиентах у вас реально есть. Загляните в свою информационную систему и задумайтесь – сколько там данных о клиентах? Уверяю вас, там крохи.
И так почти везде. Хотелось бы знать о клиенте многое, но где все это собрано – непонятно. И все прекрасные концепции с машинным обучением часто разбиваются о скалу отсутствия данных.
Кстати, когда вам рассказывают, что где-то успешно применили машинное обучение, обязательно спросите – откуда взяли данные? И, что не менее важно, насколько этим данным можно доверять?
Вот в этом и кроется главное преимущество Process Mining: чтобы начать анализ, достаточно минимального набора данных. В самом простом случае – таблицы всего с тремя колонками.
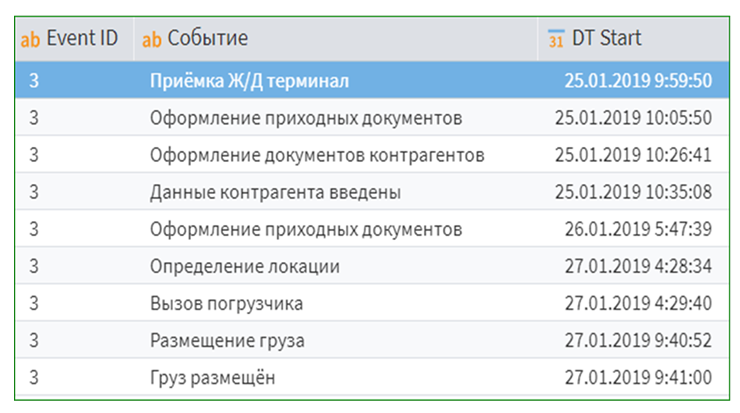
По сути, нужно знать лишь три вещи:
-
Идентификатор процесса – есть какой-то процесс, который идет от начала до конца.
-
Событие – какой этап или действие произошло.
-
Время – когда это произошло.
И уже этого достаточно, чтобы начать анализировать реальные бизнес-процессы.
Когда я впервые столкнулся с Process Mining и увидел, что на вход подаются всего три колонки, я был искренне удивлен. Подумал: ну что вообще можно интересного накопать из трех столбцов?
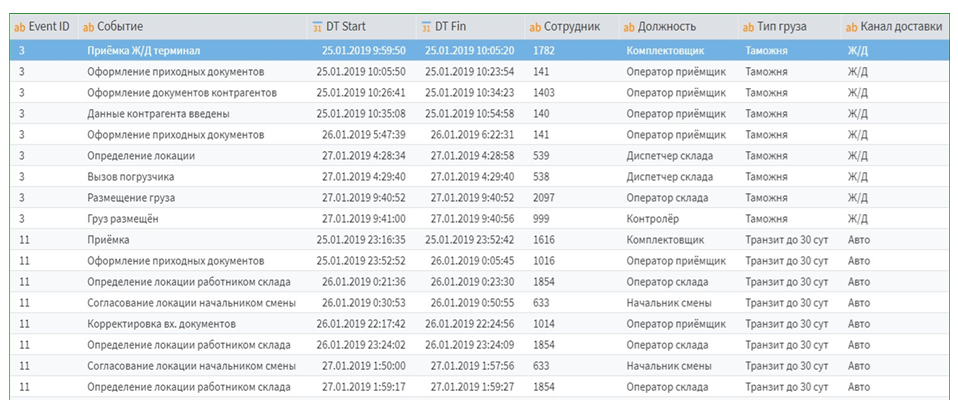
Оказалось – можно накопать огромное количество инсайтов. А если добавить еще немного дополнительной информации – например, время завершения процесса, ответственного сотрудника, подразделение или оборудование, на котором выполнялась операция, – то возможности анализа резко расширяются. С таким дополнительным контекстом можно строить гораздо более глубокую и продвинутую аналитику.
Источники данных для процесс-майнинга
А теперь перейдем к следующему пункту – первичным источникам данных. Откуда берется вся эта информация?
Обычно это различные журналы событий. Однако далеко не во всех информационных системах они есть. Недостаточно, чтобы в учетной системе просто выписывались документы – важно, чтобы фиксировалось время каждого изменения. Например, внесли правку в документ – нужно, чтобы это зафиксировалось в логе. Это есть не везде.
Также полезны логи взаимодействия модулей между собой: кто кому что передал, какие пользователи работали в системе. Если где-то сохраняются комментарии, замечания или переписка, – это тоже ценный источник данных. Даже эмоциональные реакции вроде «ругани» в комментариях могут помочь понять, где процесс буксует.
Отдельный источник – записи переговоров. Сейчас существует множество технологий, которые позволяют оцифровывать речь и превращать аудио в текст. Такие данные тоже могут использоваться в анализе, хотя это уже, конечно, высший пилотаж.
Подготовка данных как основная задача
И следующая очень важная вещь – это первичный контроль данных. Все, кто хоть раз занимался анализом, подтвердят: большая часть времени уходит вовсе не на анализ. Это кажется парадоксальным. Люди приходят в проект, воодушевленные идеей искусственного интеллекта и машинного обучения, думают, что сейчас начнут строить модели и генерировать прогнозы. Они подступаются к этому делу, и вдруг выясняется, что на самом деле 80% времени надо подготавливать данные.
Когда мы только начали заниматься анализом данных, мы тоже были воодушевлены. Казалось, сейчас покорим мир нейросетями и машинным обучением. Где-то, может быть, и покорили, но, честно говоря, не так сильно, как хотелось бы.
Почему так произошло? Потому что, когда мы начали собирать данные, быстро выяснилось – в данных всегда есть проблемы. Ошибки, пропуски, аномалии, дубликаты, противоречия.
На самом деле, про качество данных можно писать отдельную статью – тема огромная, и недооценивать ее нельзя. Все, кто работает с анализом, знают старый слоган: «garbage in – garbage out», или по-нашему – «мусор на входе, мусор на выходе».
Невозможно подать на вход системе хаотичные, грязные данные и ожидать, что на выходе будет нечто волшебное. Нет, мусор просто преобразуется, «пересоберется», и вы получите тот же самый мусор – только красиво упакованный.
Поэтому нужно обязательно объединять данные из разных источников, извлекать сущности, проводить входной аудит и валидацию данных. Потому что анализ данных по умолчанию предполагает невысказанную гипотезу: этим данным можно доверять. А вот это как раз далеко не всегда так.
Подумайте сами: сколько раз вы сталкивались с ситуацией, когда информация вводилась «задним числом»? Например, кто-то пропустил нужные данные, потом вернулся и что-то «дописал» в документ – неизвестно, что именно. А если в системе есть поля, необязательные для заполнения – что в них окажется? Телефон 12345678? Ровно такие телефоны и будут стоять у половины клиентов. Поэтому аудит данных – обязательная часть процесса.
Метрики для анализа процессов
Если мы говорим о систематической работе с данными, то она предполагает, что мы начинаем считать различные метрики. На это стоит обратить особое внимание.
Например, возьмем такую метрику, как чистое время работы. Допустим, у нас есть время начала и время завершения процесса. Первое, что приходит в голову: отнимем одно от другого – и получим время, затраченное на выполнение. Казалось бы, просто.
Но на практике все не так очевидно. Процесс может начаться в пятницу вечером, а закончиться в понедельник утром. Формально получается два дня, но фактически работа заняла всего пять минут. Или такие вещи, как время простоя, а также периоды за пределами рабочего графика – переработки, задержки и т.д. Все это нужно фиксировать и анализировать.
Интересная группа показателей – метрики по графу. Если визуализировать процесс в виде графа прохождения заявки, можно увидеть, например, так называемый пинг-понг – когда документ постоянно «скачет» между участниками. Если в компании ввести KPI, который требует как можно быстрее обрабатывать заявки, то сотрудники начнут просто перекидывать документы друг другу, чтобы не испортить статистику. Документ будет летать, как горячая картошка: один получил – сразу переслал другому. Формально метрика выполнена, а реальной пользы нет.
Далее идут метрики производительности – они показывают, какая нагрузка приходится на каждого сотрудника. Ведь работа часто выполняется параллельно, и один человек физически не может обработать слишком много задач одновременно. И, наконец, самая желанная метрика – оценка стоимости операций.
После этого важно настроить мониторинг. Нужно регулярно отслеживать KPI по процессам – хотя бы базовые: средние значения, отклонения от нормы, динамику изменений. Это уже принесет большую пользу.
Если в системе есть данные о допустимых переходах между этапами, то нужно дополнительно контролировать корректность процесса – чтобы не происходили невалидные переходы. Например, сотрудник принял документ, но не должен сразу отправлять его на отгрузку товара – между этими этапами должны быть промежуточные шаги, такие как комплектация или проверка партии.
Кроме того, стоит обращать внимание на подозрительные операции и ресурсоемкие участки – там, где процесс «проседает» и тратит непропорционально много времени и усилий.
Кодирование процессов: концепция «слова процесса»
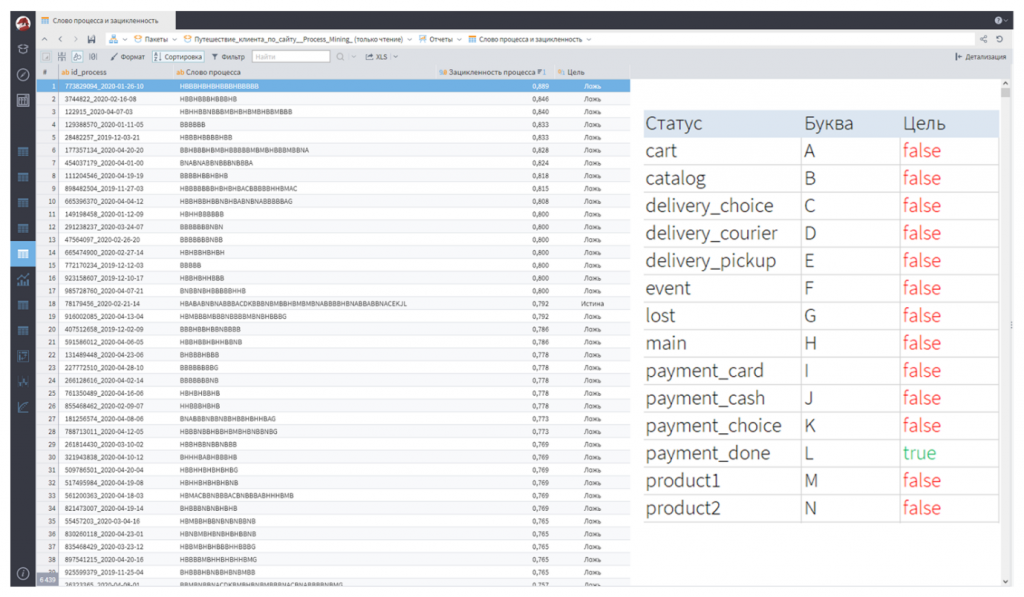
Помните, в начале статьи я приводил «макаронную» схему процесса? Когда смотришь на нее – вообще непонятно, как это все анализировать. Одни узлы связаны с другими, линий – сотни, и разобраться в этом хаосе почти невозможно.
Чтобы это упростить, придумали очень интересный подход. Если в процессе есть этапы, каждому этапу можно присвоить букву. Тогда весь процесс можно представить как последовательность букв – то есть как «слово процесса». По сути, это та же последовательность этапов, только в компактной форме.
Несмотря на кажущуюся простоту, этот метод дает массу интересных инсайтов. Например, сразу видно, какие процессы длинные – у них просто длинное «слово». Это значит, что процесс был сложным, включал много действий и переходов.
Или можно заметить повторяющиеся последовательности. Например, цепочка вроде BHBHBH – это тот самый «пинг-понг», когда один участник передает задачу другому, тот возвращает обратно, и так несколько раз подряд. Сразу видно, где процесс буксует.
Кроме того, можно анализировать, какие процессы завершились корректно, а какие – нет.
Допустим, у вас процесс «отгрузка товара», и он должен заканчиваться событием «клиент получил товар». Если пометить это как финальную букву, то сразу будет видно, какие процессы дошли до конца, а какие «зависли» по дороге.
Что дает такое кодирование:
-
позволяет быстро находить инсайты, вы буквально будете читать эти процессы,
-
помогает выявлять повторы – длинные, короткие, цикличные участки,
-
позволяет видеть шаблоны, когда структура повторяется – это режет глаз,
-
позволяет видеть брак процесса.
Оценка экономического эффекта
Теперь о практической пользе Process Mining. Есть одна сложность: экономический эффект от его применения посчитать непросто. Конечно, его можно оценить, но не всегда точно. Главная проблема – в аллокации расходов: сложно корректно распределить прямые затраты между процессами.
Вы не можете точно посчитать, сколько денег было потрачено на то, что человек просто переложил бумажку с одного стола на другой. Формально – да, ресурсы затрачены, ведь ему за это платят, но сколько именно – непонятно.
На самом деле это не так страшно. Если пытаться высчитать все с точностью до копейки, вы потратите больше времени и усилий на расчеты, чем получите пользы от самой цифры. Иногда достаточно прикидки «плюс-минус километр» – и этого вполне достаточно для принятия решений.
При этом неочевидные эффекты Process Mining заметны гораздо чаще. Например:
-
Повышается лояльность клиентов. Все логично: если вы видите, что процесс регулярно дает сбой, и устраняете причину – клиент доволен.
-
Растет конверсия заявок, обращений, заказов.
-
Увеличивается скорость обработки заявок и доставка товаров.
Есть еще один эффект, который не всегда оценивают в деньгах, но он тоже важен – это исключение бесполезных операций. Многих сотрудников раздражает, когда они делают то, что никому не нужно.
Практические примеры применения
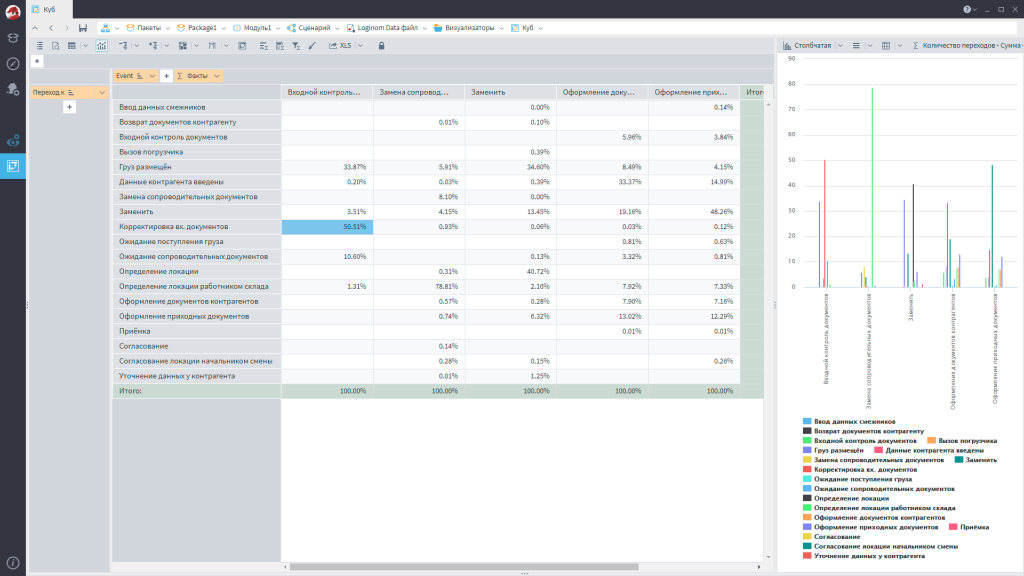
Посмотрите на этот график. В нем есть очень большая цифра – количество передач документа из одного места в другое.
Когда начинаешь разбираться, выясняется, что почти 50% времени уходит просто на то, что документ возвращается из-за ошибок: один исправляет, другой снова проверяет, снова исправляет. И так по кругу.
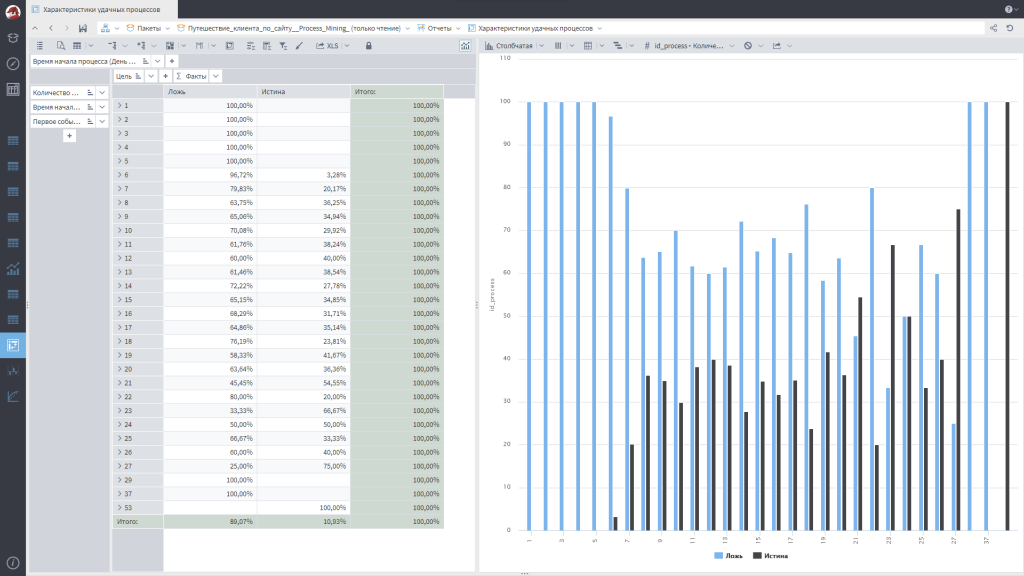
Следующая интересная вещь – сравнение удачных и неудачных процессов. В начале я говорил, что у нас может быть метка – успешный или неуспешный процесс. Если добавить такую метку в данные, можно разложить процессы по этому признаку и увидеть, чем успешные отличаются от неудачных. Может оказаться, что в каком-то отделе системно происходят сбои, или есть сотрудник, который постоянно что-то «ломает», или выявляются другие закономерности.
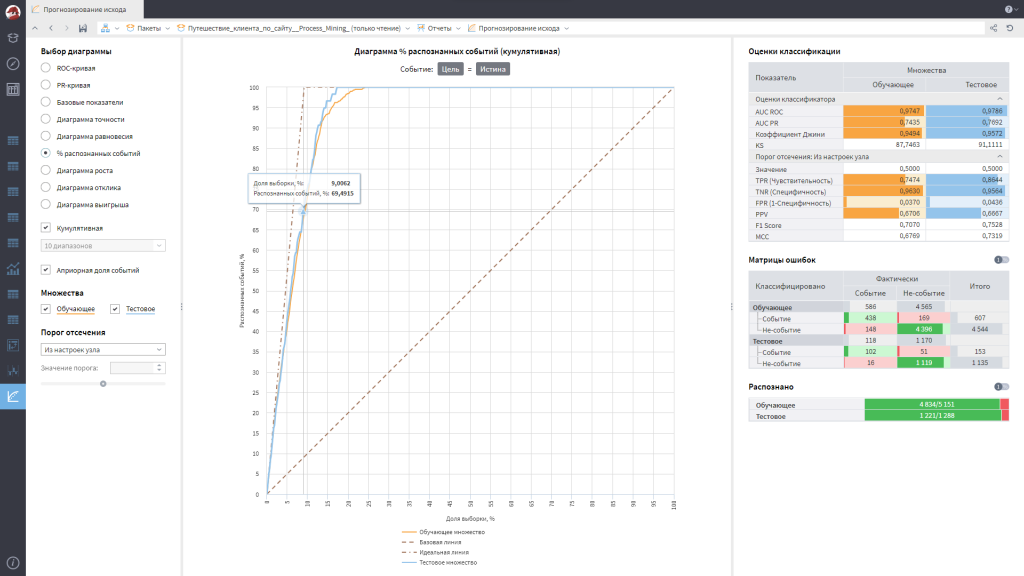
Дальше – машинное обучение. Как оно может помочь? Например, можно предсказывать переходы между этапами или прогнозировать исход операции. У нас есть какие-то действия, а в конце операция закончилась удачно или неудачно: допустим, конверсия клиента, доставка и так далее. У нас есть входные атрибуты и выходное поле – используйте любые модели машинного обучения, чтобы заранее предсказывать, что будет происходить.
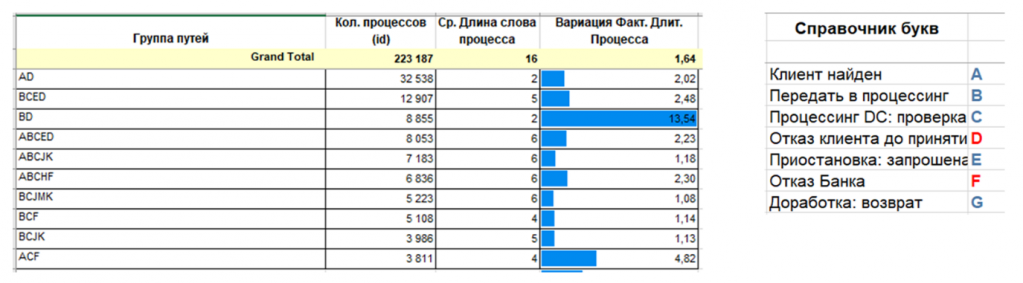
Пример из практики – анализ выдачи ипотеки. Когда провели исследование, оказалось, что у компании около 15 тысяч уникальных путей клиента. То есть почти ни один путь не повторяется. А это значит, что, несмотря на стремление выстроить стабильные, предсказуемые бизнес-процессы, в реальности каждый случай уникален. И такая вариативность сильно замедляет работу и увеличивает затраты.
Интересные выводы были сделаны и по временным метрикам. Например, медианная длительность отказов. Выяснилось, что если клиент ждет ответ по ипотеке дольше двух недель, то вероятность того, что сделка состоится, резко падает. Если посмотреть на график, то по оси X – количество одобрений, а по оси Y – время. Кривая сначала растет, а потом тянется длинным «хвостом» – есть случаи, когда договор согласовывается по полгода. При этом вероятность успешного завершения – меньше 1%. Поэтому один из практических выводов был таким: если процесс выходит за определенный порог по времени, можно смело говорить клиенту «нет». В 99% случаев вы угадаете.
Еще одно интересное наблюдение: наличие любого маркетингового предложения в кредитном деле (например, акция или бонус) повышает вероятность успешной сделки на 34%. Почему – никто толком не знает, но статистика именно такая.
Поэтому было предложено обязательно включать в процесс хотя бы минимальные маркетинговые активности. Например, продаете квартиру – подарите клиенту кепку. Конверсия вырастет на 3–4%, а продажи станут чаще.
Другая важная находка – зацикленность процессов. Оказалось, что примерно треть всего пути клиента – это просто повторения одних и тех же действий. Проблемы возникали потому, что делали одно и то же много раз.
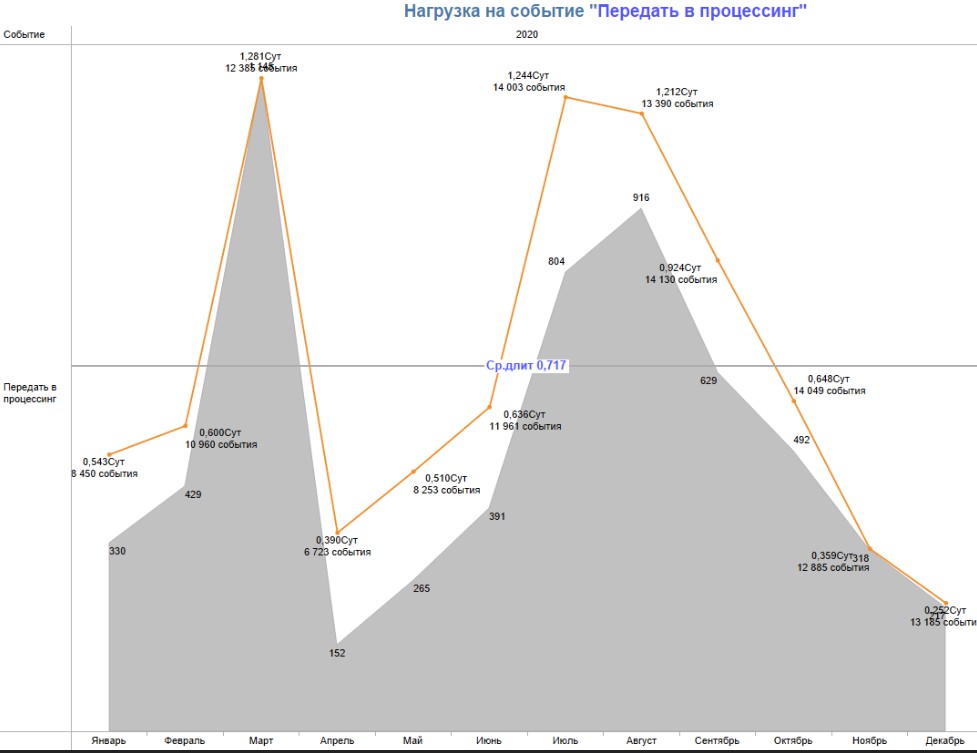
Была изучена и нагрузка на персонал. Когда специалист обрабатывает ипотечные документы, у него есть определенная пропускная способность – сколько задач он может обработать за единицу времени. Если нагрузка превышает этот порог, производительность падает: возникают задержки, ошибки и цепная реакция проблем. Эта зависимость легко рассчитывается математически – можно определить точку, после которой человек физически не справляется с потоком.
Из этого сделали важный вывод: если компания запускает маркетинговое предложение, которое резко увеличивает поток клиентов, то нужно предусмотреть реактивный запас ресурсов, чтобы сотрудники могли обработать этот входной поток. Иначе люди придут, заявки будут обрабатываться месяц или больше, а в итоге они уйдут, что принесет только вред – они будут раздражены, будут зря потрачены деньги и время.
Инструменты и рекомендации
В целом Process Mining можно применять практически везде. Есть разные инструменты, которые позволяют визуализировать и анализировать процессы.
Если у вас сложные, протяженные, ресурсоемкие процессы – то Process Mining крайне рекомендуется. И, к счастью, это не так сложно, как может показаться. Основная причина в том, что для анализа требуется совсем немного данных – фактически три колонки. Если у вас есть чуть больше атрибутов – еще лучше, это позволит проводить более глубокую аналитику.
Сейчас существует множество продуктов для Process Mining, и самый известный из них – Celonis. Из российских решений можно отметить три разработки – Loginom, Proset и Promease.
Существует библиотека Loginom Process Mining. У нее есть бесплатная версия Community Edition. Скачиваете, устанавливаете и можете спокойно пощупать весь функционал.
Если вы правильно подготовите данные (те самые несколько колонок), система автоматически выполнит большинство шагов, о которых я говорил раньше. Она рассчитает, подготовит, проведет валидацию, воссоздает процесс, «слово процесса» и так далее.
Единственное, что не выполняется автоматически – это предсказательная аналитика. Для построения модели машинного обучения потребуется ручная настройка, потому что этот этап все-таки посложнее, чем кажется на первый взгляд.
Так что берите, пробуйте, тестируйте. Loginom – это low-code платформа, здесь вообще не нужно программировать. Главное – подготовьте таблицу, и вы сможете совершенно спокойно анализировать свои процессы.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Анализ & Управление в ИТ-проектах.
