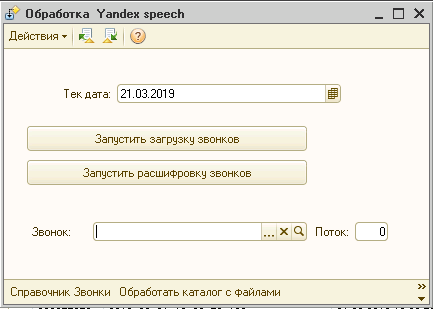


Постановка задачи
Необходимо телефонные переговоры менеджеров преобразовать в текст и подгрузить в 1С в карточку клиента. Настроить поиск по ключевым словам. Создать отчет для сбора статистики работы менеджера (количества звонков, длительность).
Реализация
-
SpRecord
Телефонные звонки записываются с аналоговых линий с помощью системы регистрации и записи телефонных разговоров SpRecord (https://sprecord.ru/). В среднем в день получается около 500 Мбайт информации. Телефонные аппараты - самые простые Panasonic TS2350
SpRecord можно устанавливать в файловом или в серверном режиме. В серверном удобнее вытаскивать дополнительную информацию из SQL сервера по данным звонка. Таблица dbo_Records содержит все необходимые данные:
- Номер линии
- Дата звонка
- Имя файла звонка
- Телефон кому звоним
- Внутренний номер
- Входящий/Исходящий
Прямым запросом к SQL получаем эти данные и заполняем справочник Звонки в 1С.
-
SOX
Для распознавания файлы отправляются по 1 Мб - получается 500 запросов в день. Чтобы нарезать файл на кусочки используется утилита для работы с аудиофайлами SoX (http://sox.sourceforge.net/). Кроссплатформенная утилита для работы через командную строку. Утилита имеет огромные возможности для работы со звуком. Я использовал только:
- Получить длительность файла
sox --i -d 1.wav > res.txt
- Получить частоту дискретизации файла
sox --i -r 1.wav > res.txt
- Нарезка файла по 45 секунд
sox " + ПутьКФайлу + " """ + ПутьКSox + "converted\" + ТекСек + ".wav"" trim " + ТекСек*45 + " 45
-
Распознавание звуковых файлов в текст Yandex SpeechKit Cloud.
Необходимо зарегистрироваться и получить ключ (https://developer.tech.yandex.ru). Первый месяц бесплатно. Можно получить несколько ключей и когда заканчиваются количество обращений на одном, то переходить на другой ключ. Я у себя использую 3 ключа, пока хватает объема. Скорее всего Яндекс обучает свою систему распознавания и ему необходимо больше звуковых файлов для анализа. Поэтому дают бесплатные ключи.
Качество распознавания очень зависит от телефонной гарнитуры и произношения менеджера. Дикторскую речь, которая записана на приветствии в АТС преобразовывает 100% правильно. Речь менеджера, который жует или пьет чай может преобразовывать с ошибками.
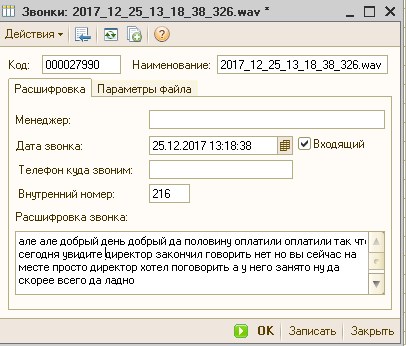
Для примера вот в таком виде вы получите текст разговора:
«але але добрый день добрый да половину оплатили оплатили так что сегодня увидите директор закончил говорить нет но вы сейчас на месте просто директор хотел поговорить а у него занято ну да скорее всего да ладно»
Общий смысл разговора понятен, но много ошибок. Менеджерам предложил сформировать список слов «заказ, счет, перезвонить» который нужно проговаривать медленнее и хорошо выговаривая при разговоре с клиентом. Тогда в дальнейшем можно делать поиск по этим ключевым словам.
-
Доработки в 1С
В 1С создаем справочник Звонки. В нем храним ссылку на *.wav файл разговора, дату, номера кому звонили и с какого внутреннего телефона, а также текст расшифровки звонка. К карточке звонка я подключил проигрывание телефонных разговоров. (//infostart.ru/public/518955/)
В обработке Yandex speech реализована обработка ожидания. Каждые 2,5 часа запускает пакет заданий. Он содержит проверку новых звуковых *.wav файлов в каталоге SpRecord , загрузка их в 1С, далее получение доп. информации о длительности и номерах из SpRecord и далее нарезка файлов по 1 МБ и распознавание их в Yandex SpeechKit Cloud.
-
Скорость работы. Анализ накопленной информации. Проблемы при разработке
- Самое большое время тратится на отправку файла размером 1 Мб в Yandex SpeechKit Cloud и ожидание ответа(несколько секунд на каждый файл). Нарезка программой SOX занимает много меньше секунды. Загрузка дополнительных данных с SpRecord еще меньше. В дальнейшем распаралелить работу с SOX на одном сервере будет проблематично. Будут подвисать файлы. Лучше использовать несколько серверов или виртуальных машин.
- Обнаружил, что в SpRecord файлы писались с частотой дискретизации 44100 Гц, при этом файл занимает довольно много места. Сейчас пишутся с частотой 11025Гц. На распознавание это никак не влияет. В первом случае в 1 Мб помещается 11 секунд разговора, а во втором 45 секунд. Лучше экономить место на диске. В начале каждого файла до 30 секунд занимает дозвон. Можно отрезать его у всех файлов. Пока не придумал, как программно понять, что начался разговор и нужно начинать преобразовывать.
- Поиграл с настройками языковой модели. Лучший вариант получился у «queries».
-
Queries (Короткие запросы(queries) — фразы (3—5 слов) на различные темы, в том числе запросы в поисковых системах (на сайтах).)
-
Maps (Адреса (maps) — адреса, названия организаций и географических объектов.)
-
Dates (Даты(dates) — названия месяцев, порядковые и количественные числительные.)
-
Names (Имена(names) — имена и фамилии, просьбы соединить по телефону.)
-
Numbers(Числа(numbers) — количественные числительные от 1 до 999 и разделители — точка, запятая, тире. Модель подходит для диктовки номеров телефонов, счетов, документов.)
-
Music (Музыка(music) — названия музыкальных произведений и исполнителей. Модель не предназначена для распознавания музыкальных фрагментов. Подходит только для распознавания названий, имен авторов и исполнителей песен.)
-
Buying (Заказы(buying) — фразы, связанные с оформлением заказов в интернет-магазинах (подтверждение заказа и форма доставки).)
- Иногда на сервере подвисала работа с файлами с утилитой SQX. Утилита консольная и все общение с 1С происходит через файлы. То есть запустил SOX и результат читаешь из файла. Бывает, что файл блокируется. В случае плохого результата этот файл будет пропущен и распознается при следующей итерации.
На данный момент накоплено 125 Гб телефонных переговоров. За 3 месяца работы распознано и загружено в 1С 28400 звонков – это около 298 часов переговоров.
После Нового года Яндекс заблокировал один ключ, который я зарегистрировал в ноябре и написал "Необходимо заключить лицензионный договор. Пожалуйста, обратитесь на почту voice@support.yandex.ru." Скорее всего скоро придется платить за пользование сервисом.
Если нужна доп. информация - пишите в комментариях. Отвечу на вопросы.
Обновление 21.03.2019
В феврале 2019 прислали письмо, что SpeechKit переехал в Яндекс.Облако, поэтому мы рекомендуем зарегистрироваться там для использования технологии.
Вам нужно перейти по ссылке https://cloud.yandex.ru, нажать "Подключиться" и авторизоваться через корректный аккаунт @yandex.ru.
Внимательно читаем документацию: https://cloud.yandex.ru/docs/speechkit
Изменилась авторизация, а также формат передаваемого аудио.
Начнем с авторизации:
- регистрируемся в облаке https://cloud.yandex.ru
- Создаем каталог и берем идентификатор каталога
https://console.cloud.yandex.ru/folders/b5gfc3ntettogerelqed7p
b5gfc3ntettogerelqed7p — это идентификатор каталога.
Обратите внимание, что его можно взять прямо из адресной строки. Я вначале ошибочно заходил в каталог и там брал неверный идентификатор сети.
- Получите OAuth-токен в сервисе Яндекс.OAuth. Для этого перейдите по https://cloud.yandex.ru/docs/iam/concepts/authorization/oauth-token
- Обменяйте OAuth-токен на IAM-токен:
Я перестал использовать HTTPЗапрос, который доступны в 1С 8.3. (у меня версия платформы 8.3.8.2197). Функция 1С ОтправитьДляОбработки менее стабильно и быстро работает чем cURL. Возможно это моё субъективное мнение. Скачать cURL можно здесь
Я использовал запуск cURL, которую запускал из bat файла. Далее анализирую ответ полученный в файле результата.
|curl -X POST -d ""{\""yandexPassportOauthToken\"": \""" + OAuth + "\""}"" -H \'Content-Type: application/json\' https://iam.api.cloud.yandex.net/iam/v1/tokens > " + ФайлРезультата;
Каждый 12 часов нужно получать новый IAM-токен, это можно определить по возвращаемой ошибке в распознавании "Not enough rights" или "FORBIDDEN"
Формат передаваемого аудио
Теперь необходимо передавать аудио в формате аудиокодека OPUS в контейнере OGG (OggOpus) или формате LPCM без WAV-заголовка
Я использую формат OGG.
Для подготовки wav файл нарезаю по 55 секунд и далее преобразую в *.ogg
Количество секунд вывел методом проб и ошибок. Для частоты файла 11025 Гц этот размер точно проходит распознавание без ошибок. Если файл будет превышать, то вместо текста в ответ придет INTERNAL_SERVER_ERROR. Причем эта ошибка возвращается не сразу, а спустя пару минут, при этом обмен подвисает в ожидании.
|sox " + ПутьКФайлу + " """ + ПутьКSox + "converted\" + ТекСек + ".wav"" trim " + ТекСек*55 + " 55
|opusenc " + ПутьКSox + "converted\" + ТекСек + ".wav " + ПутьКSox + "converted\" + ТекСек + ".ogg
opusenc это команда для преобразования wav в ogg. В sox нет возможности преобразовывать wav в ogg.
Распознавание в yandex облаке
|curl -X POST -H ""Authorization: Bearer " + token + """ --data-binary ""@" + ПутьКФайлу + """ ""https://stt.api.cloud.yandex.net/speech/v1/stt:recognize/?topic=general&folderId=" + folderId + " > " + ФайлРезультата;
Получаем в Файл результата JSON, который преобразуем в текст и записываем в базу данных.
Служба поддержки SpeechKit Cloud написала, что можно одновременно отправлять 20 потоков распознавания. Я у себя реализовал это через несколько запусков curl, каждый поток обрабатывает свой звуковой файл. Мне хватило 4х потоков.
SpeechKit Cloud теперь платная, некоммерческих тарифов в Облаке нет.
Стоимость использования SpeechKit API для распознавания речи рассчитывается, исходя из длительности аудиофайлов, которые были успешно обработаны сервисом за Отчетный период. Длительность каждого аудиофайла измеряется в отрезках по 15 секунд с округлением в большую сторону.
Тарифы: https://cloud.yandex.ru/docs/speechkit/pricing
Инструкция по установке в типовую УТ 10.3.55.3
1. Добавить справочник Звонки со следующими реквизитами
Менеджер(Строка 30)
ДатаЗвонка(Дата и время)
РасшифровкаЗвонка(Строка неограниченная)
ИмяФайла(Строка 100)
ПолныйПутьКФайлу(Строка 500)
СтрокаОшибок(Строка неограниченная)
Длительность(Число 10,2)
Размер(Число 10,2)
ТелефонКудаЗвоним(Строка 20)
Входящий(Булево)
ВнутреннийНомер(Строка 3)
Контрагент(Справочник Контрагенты)
КонтактноеЛицо(Справочник КонтактныеЛицаКонтрагентов)
РасшифровкаЗвонкаОригинал(Строка неограниченная)
ДлительностьЗвонка(Строка 10)
КатегорияЗвонка (Строка 10)
Обработан (Булево)
Поток(Число 10,0)
Далее скачиваем обработку "Распознавание телефонных звонков с помощью Yandex SpeechKit Cloud:" и запускаем в конфигураторе.
В модуле обработки указываем настройки
1. путь к файлам со звонками
2. Идентификатор каталога yandex
3. OAuth yandex
4. Путь К программе Sox для обрезки звуковых файлов
Далее сохраняем обработку и запускаем в режиме предприятия.
В режиме предприятия нажимаем "обработать каталог с файлами", по этой команде будут созданы элементы справочника Звонки, посчитана длительность звонка, частота дискретизации.
по кнопке "Расшифровать звонки" файлы будут переведены в текст и записаны в элемент справочника Звонки.
Обновление от 07.12.2019
Добавил обработку Распознавание длинных аудио. Это дешевле, так как распознавание работает с небольшой задержкой.
При распознавании коротких аудио часто возникала ошибка "internal server error". Служба поддержки яндекса написала, что они исправят эту ошибку в будущем. ("до применения исправлений, вы можете передавать файл в одном из других поддерживаемых форматов: lpcm 16bit 8k/16k/48k Hz.
Также, вы можете воспользоваться распознаванием длинных аудио")
Чтобы распознать длинное аудио нужно:
1. Создать сервисный эккаунт, назначить роли и права.
2. Создать статический ключ доступа
Эти пункты подробно расписаны в яндекс хелпе:
3. При операциях с распознаванием и работой с файлами yandex storage необходимо получить IAM-токен. Я получал через
yc iam create-token (ссылка на документацию)
Токен действителен 12 часов.
4. Отправить файл на yandex storage
aws --endpoint-url=https://storage.yandexcloud.net s3 cp " + ИмяФайлаopus + " s3://voice/" + ИмяФайлаopus;
5. Получить ссылку на файл yandex storage и дать команду на распознавание файла
6. По ссылке, полученной в пункте 5, скачать распознанный текст.
Скорость распознавания: 1 минута одноканального аудио примерно за 10 секунд. Если файл еще не готов, то в запросе вернется Ложь;
Есть ограничения:
Количество запросов в час 500, проверка статуса операции в час 2500.
7. После распознавания удалить файл из yandex storage
aws --endpoint-url=https://storage.yandexcloud.net s3 rm s3://voice/" + ИмяФайла;
Цена распознавания длинного аудио 100 секунд - 1 руб.
Цена распознавания короткого аудио 100 секунд - 1.7 руб.
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}