



Введение
Вычисление нарастающего итога является составной частью большого количества вычислительных процедур в задачах учета и управления /*/. На нем основан расчет себестоимости списаний по партиям, автоматическое распределение сумм оплат по документам движения товаров и многие другие важные алгоритмы в конфигурациях на платформе «1С: Предприятие». Собственно само наличие в платформе механизма итогов регистров накопления (остатков) является следствием необходимости хранения как раз результатов расчета нарастающих итогов из-за того, что их оперативное вычисление сопряжено с существенными затратами вычислительных ресурсов.
Сложность расчета нарастающего итога в запросах обусловлена реляционной природой СУБД, хранящей исходные данные и результаты вычислений. Записи одной и той же таблицы принципиально не связаны между собой, что и порождает проблему их последовательного суммирования в процессе расчета нарастающего итога. О том, что проблема затрагивает не только решения на основе платформы «1С: Предприятие», можно судить по работе[Нарастающий итог сравнение производительности].
Обычный подход к решению задачи получения нарастающего итога в запросе заключается в том, что для каждой строки таблицы находится сумма элементов предыдущих строк. Для примера приведен запрос, подсчитывающий нарастающий итог по таблице «Таб», состоящей из колонки с номером строки «ё» и колонки суммируемого показателя «а»
ВЫБРАТЬ
СУММА(ДоДано.Сумма) КАК Сумма
ИЗ
Дано КАК Дано
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Дано КАК ДоДано
ПО Дано.НомерСтроки >= ДоДано.НомерСтроки
СГРУППИРОВАТЬ ПО
Дано.НомерСтроки
При использовании приведенного запроса расчет по каждой строке делается независимо от результатов расчетов других строк. Это порождает проблему быстродействия данного подхода, так как число элементарных операций, а в итоге и затраты времени оказываются пропорциональными половине квадрата числа строк исходной таблицы. То есть при увеличении числа строк в таблице в десять раз, время расчета увеличивается в сто раз! О квадратичной зависимости свидетельствует следующая схема расчета нарастающего итога в таблице из восьми элементов Фиг.0.
| Дано\ДоДано | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | Сумма |
| 1 | 1 | 1 | |||||||
| 1 | 1 | 1 | 2 | ||||||
| 1 | 1 | 1 | 1 | 3 | |||||
| 1 | 1 | 1 | 1 | 1 | 4 | ||||
| 1 | 1 | 1 | 1 | 1 | 1 | 5 | |||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 6 | ||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 7 | |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 8 |
Квадратичная зависимость времени расчета нарастающего итога от числа элементов в таблице приводит к существенной деградации производительности решений при больших размерах таблиц, особенно в случае файлового варианта информационной базы. Однако на практике проблема не так заметна, так как в большинстве случаев число строк в таблицах относительно невелико. В других случаях можно прибегнуть к постобработке результатов запроса в коде или с использованием функции СКД (Вычислить выражение). Тем не менее, остаются некоторые задачи, в которых необходимо ускорить расчет нарастающего итога непосредственно в запросе.
Для таких особенных задач и предназначен описываемый далее метод. Он не опирается ни на какие технологические ухищрения, а является чисто алгоритмическим. Метод требует, чтобы строки исходной таблицы были пронумерованы. Используется динамическое формирование текста запроса.
Описание метода
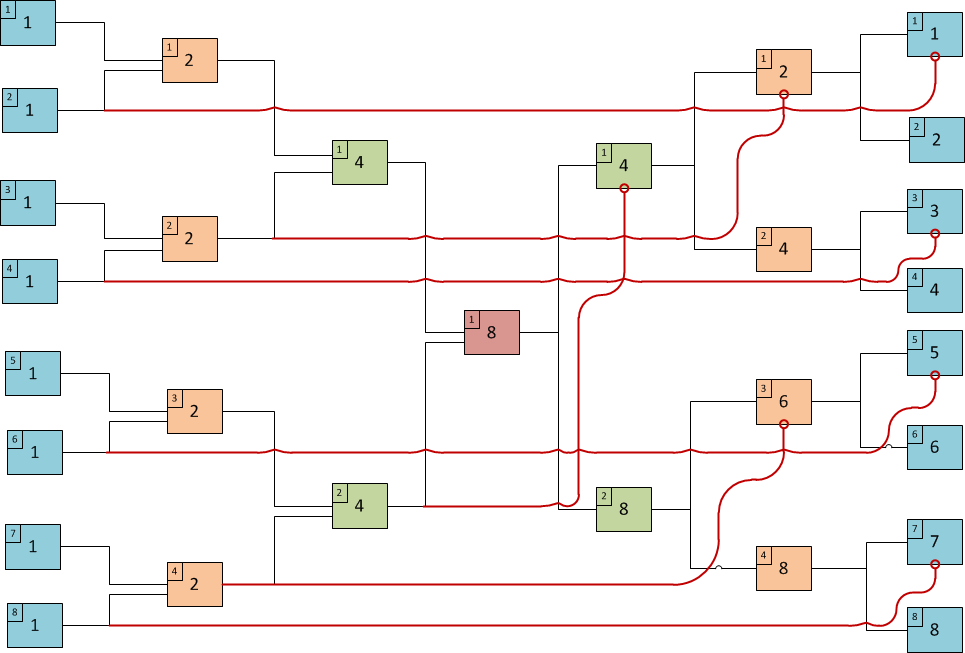
Суть предлагаемого метода описывается следующей схемой (Фиг.1), нарисованной для примера расчета нарастающего итога для таблицы из восьми строк. Схема похожа на бабочку, отсюда и название метода - «баттерфляй».

Первоначально исходная таблица помещается в таблицу «Л1» на левом крыле бабочки. Затем, в соответствии со схемой, производится попарное суммирование соседних строк таблицы «Л1», а результат помещается в таблицу «Л2» из четырех строк. Аналогично по таблице «Л2» строится таблица «Л4», а по «Л4» – таблица «Л8», состоящая по понятным причинам из одной строки. На правом крыле производятся чуть более сложные действия. Единственная строка таблицы «Л8» расщепляется на две строки таблицы «П4». Для этого используется искусственная таблица «Р0», состоящая из двух строк: одна с нулем и другая с единицей. Кроме того (и в этом весь фокус), из верхней строки таблицы «П4» вычитается нижняя строка таблицы «Л4». Это делается затем, чтобы суммы, накопленные в элементе «Л4», не входили в нарастающий итог для строк с меньшим номером. Далее каждая строка таблицы «П4» опять расщепляется на две строки таблицы «П2», а из строк 1, 3 (с нечетными номерами) вычитаются соответствующие строки 2, 4 таблицы «Л2». Ну, и наконец, строится таблица «П1» расщеплением на две строки каждой строки «П2». При этом и строк 1, 3, 5, 7 вычитаются строки 2, 4, 6, 8 таблицы Л1.
Последовательность получаемых таблиц приведена на фиг.2.
| НомерСтроки\Таблица | Л1 | Л2 | Л4 | Л8 | П4 | П2 | П1 |
| 1 | 1 | 2 | 4 | 8 | 4 | 2 | 1 |
| 2 | 1 | 2 | 4 | 8 | 4 | 2 | |
| 3 | 1 | 2 | 6 | 3 | |||
| 4 | 1 | 2 | 8 | 4 | |||
| 5 | 1 | 5 | |||||
| 6 | 1 | 6 | |||||
| 7 | 1 | 7 | |||||
| 8 | 1 | 8 |
Для удобства записи и экономии памяти в запросе таблицы правого крыла «П» сразу же после использования удаляются, а таблицы левого крыла «Л» – переформировываются и тоже удаляются.
Запрос, выполняющий расчеты по приведенной схеме, состоит из повторения одинаковых фрагментов. Вот текст рефрена для левого крыла
ВЫБРАТЬ
ВЫРАЗИТЬ(Л#1.ё / 2 КАК ЧИСЛО(10, 0)) КАК ё,
СУММА(Л#1.Сумма) КАК Сумма
ПОМЕСТИТЬ Л#2
ИЗ
Л#1 КАК Л#1
СГРУППИРОВАТЬ ПО
ВЫРАЗИТЬ(Л#1.ё / 2 КАК ЧИСЛО(10, 0))
А вот текст рефрена для правого крыла
ВЫБРАТЬ
2 * Л2.ё - Р0.е КАК ё,
Л2.Сумма
ПОМЕСТИТЬ П#1
ИЗ
Л#2 КАК Л2,
Р0 КАК Р0
ГДЕ
2 * Л2.ё - Р0.е < = &ЧислоСтрок
ОБЪЕДИНИТЬ
ВЫБРАТЬ
Л1.ё - 1,
-Л1.Сумма
ИЗ
Л#1 КАК Л1
ГДЕ
(ВЫРАЗИТЬ(Л1.ё / 2 КАК ЧИСЛО(10, 0))) = Л1.ё / 2
;
УНИЧТОЖИТЬ Л#1
;
ВЫБРАТЬ
П1.ё,
СУММА(П1.Сумма) КАК Сумма
ПОМЕСТИТЬ Л1
ИЗ
П#1 КАК П1
СГРУППИРОВАТЬ ПО
П1.ё
;
УНИЧТОЖИТЬ П#1
Для восьми строк весь запрос имеет вид
ВЫБРАТЬ 0 КАК е ПОМЕСТИТЬ Р0 ОБЪЕДИНИТЬ ВЫБРАТЬ 1;
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))ё,Сумма(Сумма)Сумма ПОМЕСТИТЬ Л2 ИЗ Л1 СГРУППИРОВАТЬ ПО ВЫРАЗИТЬ(ё/2 КАК Число(10,0));
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))ё,Сумма(Сумма)Сумма ПОМЕСТИТЬ Л4 ИЗ Л2 СГРУППИРОВАТЬ ПО ВЫРАЗИТЬ(ё/2 КАК Число(10,0));
ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))ё,Сумма(Сумма)Сумма ПОМЕСТИТЬ Л8 ИЗ Л4 СГРУППИРОВАТЬ ПО ВЫРАЗИТЬ(ё/2 КАК Число(10,0));
ВЫБРАТЬ 2*ё-е ё,Сумма ПОМЕСТИТЬ П4 ИЗ Л8,Р0 ГДЕ 2*ё-е< =&ЧислоСтрок ОБЪЕДИНИТЬ ВЫБРАТЬ ё-1,-Сумма ИЗ Л4 ГДЕ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))=ё/2;
УНИЧТОЖИТЬ Л4;ВЫБРАТЬ ё,СУММА(Сумма)Сумма ПОМЕСТИТЬ Л4 ИЗ П4 СГРУППИРОВАТЬ ПО ё;
УНИЧТОЖИТЬ П4;
ВЫБРАТЬ 2*ё-е ё,Сумма ПОМЕСТИТЬ П2 ИЗ Л4,Р0 ГДЕ 2*ё-е< =&ЧислоСтрок ОБЪЕДИНИТЬ ВЫБРАТЬ ё-1,-Сумма ИЗ Л2 ГДЕ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))=ё/2;
УНИЧТОЖИТЬ Л2;
ВЫБРАТЬ ё,СУММА(Сумма)Сумма ПОМЕСТИТЬ Л2 ИЗ П2 СГРУППИРОВАТЬ ПО ё;
УНИЧТОЖИТЬ П2;
ВЫБРАТЬ 2*ё-е ё,Сумма ПОМЕСТИТЬ П1 ИЗ Л2,Р0 ГДЕ 2*ё-е< =&ЧислоСтрок ОБЪЕДИНИТЬ ВЫБРАТЬ ё-1,-Сумма ИЗ Л1 ГДЕ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))=ё/2;
УНИЧТОЖИТЬ Л1;
ВЫБРАТЬ ё,СУММА(Сумма)Сумма ПОМЕСТИТЬ Л1 ИЗ П1 СГРУППИРОВАТЬ ПО ё;
УНИЧТОЖИТЬ П1;
Для произвольного количества строк текст запроса формируется динамически на основе заданного параметра с помощью функции
Функция ТекстЗапросаБаттерфляй_(ЧислоСтрок)
ТекстЗапроса = "ВЫБРАТЬ 0 КАК е ПОМЕСТИТЬ Р0 ОБЪЕДИНИТЬ ВЫБРАТЬ 1;";
РефренКрылаЛ = "ВЫБРАТЬ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))ё,Сумма(а)а ПОМЕСТИТЬ Л#2 ИЗ Л#1 СГРУППИРОВАТЬ ПО ВЫРАЗИТЬ(ё/2 КАК Число(10,0));";
РефренКрылаП = "ВЫБРАТЬ 2*ё-е ё,а ПОМЕСТИТЬ П#1 ИЗ Л#2,Р0 ГДЕ 2*ё-е< =&ЧислоСтрок ОБЪЕДИНИТЬ ВЫБРАТЬ ё-1,-а ИЗ Л#1 ГДЕ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))=ё/2;
|УНИЧТОЖИТЬ Л#1;ВЫБРАТЬ ё,СУММА(а)а ПОМЕСТИТЬ Л#1 ИЗ П#1 СГРУППИРОВАТЬ ПО ё; УНИЧТОЖИТЬ П#1;";
Охват = 1;
Пока Охват < ЧислоСтрок Цикл
ТекстЗапроса = ТекстЗапроса + СтрЗаменить(СтрЗаменить(РефренКрылаЛ, "#2", "" + Формат(Охват * 2, "ЧГ=0")), "#1", Формат(Охват, "ЧГ=0"));
Охват = Охват * 2;
КонецЦикла;
Пока Охват > 1 Цикл
ТекстЗапроса = ТекстЗапроса + СтрЗаменить(СтрЗаменить(РефренКрылаП, "#2", Формат(Охват, "ЧГ=0")), "#1", Формат(Охват / 2, "ЧГ=0"));
Охват = Охват / 2
КонецЦикла;
Возврат ТекстЗапроса
КонецФункции
Нетрудно заметить, что общее число всех выполняемых операций на фиг.1 пропорционально 4,5 N (!!!), где N – число строк в исходной таблице. Это существенно меньше, чем 0,5 N^2. Отсюда и высокая эффективность метода. Притом, что все выполняемые операции делаются с помощью низкозатратной операции группировки.
Для примера приведены таблицы и графики сравнительного анализа времени выполнения расчета нарастающего итога исходной таблицы в зависимости от числа строк в этой таблице для файловой базы (фиг.3)

и базы на основе MSSQL (фиг.4)

Видно, что в файловом варианте стандартный метод проигрывает методу «баттерфляй» уже начиная с 200 строк, а в SQL-варианте – начиная с 2000 строк.
Чтобы можно было самостоятельно проверить приведенные данные, к статье приложена обработка. Она позволяет сформировать таблицу из нужного числа строк и проверить время расчета нарастающего итога разными методами. Метод 0 в обработке – получение нарастающего итога в коде, метод 1 – с помощью стандартного запроса "Треугольником", метод 2 – запроса «Баттерфляй».
Где это можно использовать на практике?
Фундаментальный характер исходной задачи предполагает довольно широкую область применения предлагаемого метода. Покажем пока только один конкретный пример использования метода: расчет остатков товаров на каждый день (год, квартал, месяц, час, минуту) в запросе.
Для этого добавим к запросу подзапрос получения исходных данных в виде остатков на начало интервала и оборотов по периодам, на которых они были. Кроме того, добавим группировку по номенклатуре к каждому запросу схемы «бабочка», а также итоговый подзапрос вывода результата. Получим следующую функцию для построения текста запроса.
Функция ТекстЗапросаБаттерфляй(ЧислоСтрок)
ТекстЗапроса = "ВЫБРАТЬ 0 КАК е ПОМЕСТИТЬ Р0 ОБЪЕДИНИТЬ ВЫБРАТЬ 1;";
РефренКрылаЛ = "ВЫБРАТЬ э,ВЫРАЗИТЬ(ё/2 КАК Число(10,0))ё,Сумма(а)а ПОМЕСТИТЬ Л#2 ИЗ Л#1 СГРУППИРОВАТЬ ПО э,ВЫРАЗИТЬ(ё/2 КАК Число(10,0));";
РефренКрылаП = "ВЫБРАТЬ э,2*ё-е ё,а ПОМЕСТИТЬ П#1 ИЗ Л#2,Р0 ГДЕ 2*ё-е< =&ЧислоСтрок ОБЪЕДИНИТЬ ВЫБРАТЬ э,ё-1,-а ИЗ Л#1 ГДЕ ВЫРАЗИТЬ(ё/2 КАК Число(10,0))=ё/2;
|УНИЧТОЖИТЬ Л#1;ВЫБРАТЬ э,ё,СУММА(а)а ПОМЕСТИТЬ Л#1 ИЗ П#1 СГРУППИРОВАТЬ ПО э,ё; УНИЧТОЖИТЬ П#1;";
Охват = 1;
Пока Охват < ЧислоСтрок Цикл
ТекстЗапроса = ТекстЗапроса + СтрЗаменить(СтрЗаменить(РефренКрылаЛ, "#2", "" + Формат(Охват * 2, "ЧГ=0")), "#1", Формат(Охват, "ЧГ=0"));
Охват = Охват * 2;
КонецЦикла;
Пока Охват > 1 Цикл
ТекстЗапроса = ТекстЗапроса + СтрЗаменить(СтрЗаменить(РефренКрылаП, "#2", Формат(Охват, "ЧГ=0")), "#1", Формат(Охват / 2, "ЧГ=0"));
Охват = Охват / 2
КонецЦикла;
Возврат ТекстЗапроса
КонецФункции
Результат запроса подставляется вместо ";" в запрос для СКД, получающий исходные данные и выводящий результат. Он имеет следующий вид
ВЫБРАТЬ
1 КАК ё,
Остатки.Номенклатура КАК э,
Остатки.КоличествоОстаток КАК а
ПОМЕСТИТЬ Л1
ИЗ
РегистрНакопления.ТоварыНаСкладах.Остатки(&НачалоПериода, ) КАК Остатки
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
РАЗНОСТЬДАТ(&НачалоПериода, Обороты.Период, ДЕНЬ) + 2,
Обороты.Номенклатура,
Обороты.КоличествоОборот
ИЗ
РегистрНакопления.ТоварыНаСкладах.Обороты(&НачалоПериода, &КонецПериода, ДЕНЬ, ) КАК Обороты
;
ВЫБРАТЬ
ДОБАВИТЬКДАТЕ(&НачалоПериода, ДЕНЬ, Л1.ё - 1) КАК Период,
Л1.э КАК Номенклатура,
Л1.а КАК Остаток
ИЗ
Л1 КАК Л1
ГДЕ
ДОБАВИТЬКДАТЕ(&НачалоПериода, ДЕНЬ, Л1.ё - 1) < = &КонецПериода
Слово "День" при компоновке результата заменяется на интересующий нас период.
Заметьте, что этим запросом чудесным образом получаются остатки и на даты периодов, в которых не было движений, хотя в исходных данных этих периодов не было! Нужно отметить, что полученный запрос не требует многократного обращения к виртуальному регистру остатков для дат, на которые итоги не хранятся, а вычисляются. Указанным недостатком страдает подавляющее большинство решений, размещенных на Инфостарте /**/. Поэтому запрос крайне эффективен в плане времени выполнения и без труда работает на мелких периодах типа часа и минуты, на которых другие решения крайне не эффективны.
К статье приложена обработка, содержащая данное решение.
Заключение
В заключение необходимо еще раз обратить внимание и подчеркнуть тот факт, что найденный метод получения нарастающего итога в запросе имеет минимально возможную трудоемкость О(N) /***/. То есть трудоемкость метода фактически (с точностью до коэффициента) равна трудоемкости получения нарастающих итогов в коде. Ну и, кроме того, данное решение является чисто алгоритмическим. Оно не привязано жестко к особенностям языка запросов 1С. Поэтому с таким же успехом может использоваться и при решении задачи получения нарастающих итогов, например, непосредственно на языке T-SQL.
Ну и совсем общие выводы заключаются в том, что данная задача и ее решение учат тому, что никогда не следует терять пионерского оптимизма: хотя эпоха великих алгоритмических открытий в целом вроде бы кончилась, но в нашей предметной области еще остались места для исследований и новых интересных находок.
Примечания
*/ Интересно, что вычисление нарастающего итога по сути – это задача численного интегрирования функции, заданной исходной таблицей.
**/ Довольно часто получение остатков на каждый день используется в задаче определения среднедневного остатка, хотя этот показатель определяются гораздо проще непосредственно через обороты как показано в статье [Расчет средних по периодам в запросе - это элементарно!]
***/ Тем, кому предложенный метод кажется слишком сложным, можно порекомендовать ознакомиться с методами построения, например, суффиксного массива, имеющих линейную трудоемкость О(N) [http://habrahabr.ru/post/115346/]. Тогда станет понятно, что такое по настоящему сложные методы достижения линейной трудоемкости.
Приложение
На тему нарастающего итога в запросах на языке платформы «1С:Предприятие» на Инфостарте сломано немало копий:
Отчет по просроченной задолженности/задолженность по интервалам (УПП УТ 8.1, СК
Нарастающие итоги в запросе и методы ускорения его выполнения
SubSys: Просроченная задолженность по срокам (режим - по договорам в целом ФИФО)
Запрос. Нарастающий итог. Как «я» его понимаю.
Запрос. Нарастающий итог. Как «я» его НЕ понимаю (вторая часть).
БП1.6.Просроченная задолженность по 62 сч. Продолжение разго
Запрос. Нарастающий итог. Как «я» его НЕ понимаю (третья часть).
Использование нарастающих итогов в партионном учете и не только
Нарастающие итоги. Объединение двух таблиц с нарастающими итогами

{kind=link}