
Зачем это нужно ?
Существуют различные способы увеличения быстродействия процедуры перепроведения документов по регистру партий. Насколько известно автору , все они предполагают хранение вспомогательной дополнительной ("ускоряющей при проведении") информации. Представленный же алгоритм является решением "в лоб" , т.е. не требующим создания дополнительных структур хранения информации. Преимущества и недостатки такого подхода требуют отдельного исследования.
Постановка задачи .
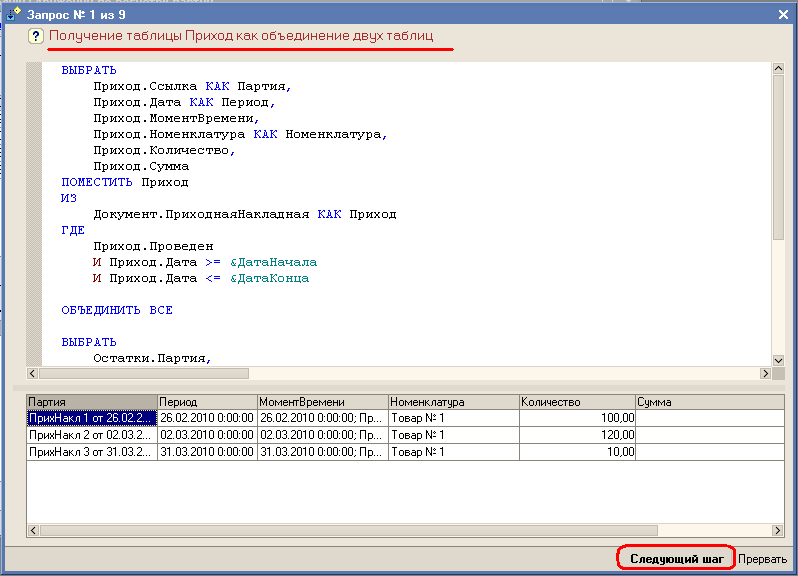
Рассмотрим постановку задачи списания по методу ФИФО в рамках простейшей конфигурации, содержащей справочник Номенклатура, документы РасходнаяНакладная и ПриходнаяНакладная, а также регистр накопления Партии. Период проведения расходных документов определен как [ДатаНачала,ДатаКонца].Получены две временные таблицы Приход и Расход (описание алгоритма будет сопровождаться демонстрационным примером).
Приход
|
Номенклатура |
Партия | МоментВремени | Период | Количество | Сумма |
| Товар № 1 | ПрихНакл №1 | ..... | 26.02.2010 | 100 | 1000 |
| Товар № 1 | ПрихНакл №2 | ..... | 01.03.2010 | 120 |
1200 |
Таблица Приход может быть получена как объединение двух таблиц :таблица остатков партий на ДатаНачала и таблица движений документов ПриходнаяНакладная, полученная за период [ДатаНачала,ДатаКонца].
Расход
|
Номенклатура |
Регистратор | МоментВремени | Период | Количество | Сумма |
| Товар № 1 | РасхНакл №1 | ..... | 11.03.2010 | 80 | 800 |
| Товар № 1 | РасхНакл №2 | ..... | 14.03.2010 |
40 |
400 |
| Товар № 1 | РасхНакл №3 | ..... | 26.03.2010 | 100 |
1000 |
Таблица Расход может быть получена при обращении к таблице Документы.РасходнаяНакладная за период [ДатаНачала,ДатаКонца].
Требуется получить таблицу движений по регистру партий :
|
Номенклатура |
Партия | Период | Регистратор | Количество | Сумма |
Алгоритм решения.
Рассмотрим упрощенный алгоритм получения движений регистра только по количеству. В демонстрационной конфигурации СписаниеПоМетодуФИФО.dt приведено более полное и подробное решение.
Этап I.
Получим таблицы НарРасход и НарПриход , содержащие нарастающие итоги для каждой строки в колонках КоличествоДо и КоличествоПосле.
НарПриход
|
Номенклатура |
Партия | ... | Период | КоличествоДо | КоличествоПосле |
| Товар № 1 | ПрихНакл №1 | 26.02.2010 | 0 | 100 | |
| Товар № 1 | ПрихНакл №2 | 01.03.2010 | 100 |
220 |
НарРасход
|
Номенклатура |
Регистратор | ... | Период | КоличествоДо | КоличествоПосле |
| Товар № 1 | РасхНакл №1 | 11.03.2010 | 0 | 80 | |
| Товар № 1 | РасхНакл №2 | 14.03.2010 |
80 |
120 |
|
| Товар № 1 | РасхНакл №3 | 26.03.2010 | 120 |
220 |
Запросы для получения таблиц НарРасход и НарПриход аналогичны.Приведем текст запроса для получения таблицы НарРасход
ВЫБРАТЬ
Расход.Период,
Расход.МоментВремени,
Расход.Регистратор,
Расход.Номенклатура,
Расход.Количество,
Расход.Сумма,
СУММА(Расход1.Количество) - Расход.Количество КАК КоличествоДо,
СУММА(Расход1.Количество) КАК КоличествоПосле
ПОМЕСТИТЬ НарРасход
ИЗ Расход КАК Расход
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Расход КАК Расход1
ПО Расход.Номенклатура = Расход1.Номенклатура
И Расход.МоментВремени >= Расход1.МоментВремени
СГРУППИРОВАТЬ ПО
Расход.Период,
Расход.МоментВремени,
Расход.Регистратор,
Расход.Номенклатура,
Расход.Количество,
Расход.Сумма
Этап II.
Одного внутреннего соединения таблиц НарРасход и НарПриход достаточно для получения выходной таблицы движений. Здесь мы описываем лишь суть алгоритма , поэтому в нижеприведенном тексте запроса ресурс Сумма не учитывается.
ВЫБРАТЬ
НарРасход.Период,
НарРасход.Регистратор,
НарПриход.Партия,
НарРасход.Номенклатура,
// Следующее поле "Количество" можно определить как
// Мин(НарПриход.КоличествоПосле, НарРасход.КоличествоПосле)
// - Макс(НарПриход.КоличествоДо, НарРасход.КоличествоДо)
ВЫБОР
КОГДА НарПриход.КоличествоПосле < НарРасход.КоличествоПосле
ТОГДА НарПриход.КоличествоПосле
ИНАЧЕ НарРасход.КоличествоПосле
КОНЕЦ - ВЫБОР
КОГДА НарПриход.КоличествоДо > НарРасход.КоличествоДо
ТОГДА НарПриход.КоличествоДо
ИНАЧЕ НарРасход.КоличествоДо
КОНЕЦ КАК Количество
ИЗ
НарРасход КАК НарРасход
Внутреннее СОЕДИНЕНИЕ НарПриход КАК НарПриход
ПО НарРасход.Номенклатура = НарПриход.Номенклатура
И НарРасход.КоличествоПосле > НарПриход.КоличествоДо
И НарРасход.КоличествоДо < НарПриход.КоличествоПосле
И НарРасход.МоментВремени > НарПриход.МоментВремени
Таблица Движений
|
Номенклатура |
Регистратор | Партия | Период | Количество | Сумма |
| Товар № 1 | РасхНакл №1 | ПрихНакл №1 | 11.03.2010 | 80 | -нет |
| Товар № 1 | РасхНакл №2 | ПрихНакл №1 | 14.03.2010 |
20 |
-нет |
| Товар № 1 | РасхНакл №2 | ПрихНакл №2 | 14.03.2010 | 20 |
-нет |
| Товар № 1 | РасхНакл №3 | ПрихНакл №2 | 26.03.2010 | 100 | -нет |
Этап III .
Полученную таблицу движений можно или "подокументно" записать в регистр партий или предварительно сравнить с существующими движениями в регистре и записать только "изменения".
Замечания.
Приведенный в Этапе I запрос нагляден , но чрезвычайно затратен .В практических разработках при вычислении нарастающих итогов возможно применение подхода , описанного в статье "Подведем Итоги.Нарастающие" //infostart.ru/public/61295/. Применение же подхода Шепота - невозможно , потому что он ничего на эти темы не писал.
В демонстрационной конфигурации прикрепленной к теме алгоритм рассматривается по шагам более полно и подробно : полученные движения содержат ресурс Сумма, реализован учет погрешности округления ресурса Сумма, учитывается возможность отрицательных остатков при проведении.
В тексте темы использована разукрашка Aleks-is http://www.infostart.ru/public/19856/
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}