
















{kind=link}
Промо
Кто хочет, чтобы о проблемах производительности сообщалось заранее, до начала падения системы?
Чтобы мониторинг с пристрастием осуществлялся 24 часа в сутки 7 дней в неделю?
Чтобы при наличии сложных ситуаций мы узнавали первыми, а не пользователи?
Кто хочет повысить качество сервиса и перейти на новый уровень?
Зачем разбирать вручную логи технологического журнала и входить в когнитивный диссонанс, когда есть для этого специальный и обученный помощник?
Ответ на эти вопросы и многое другое найдете в этой статье. Ок, Лариса! Поехали...
Введение
Это первая часть по вопросам практики применения искусственного интеллекта и в ней мы рассмотрим применение нечеткой логики (fuzzy logic). В следующих статьях будем двигаться дальше и затронем применение нейронных сетей. И все это на 1С.
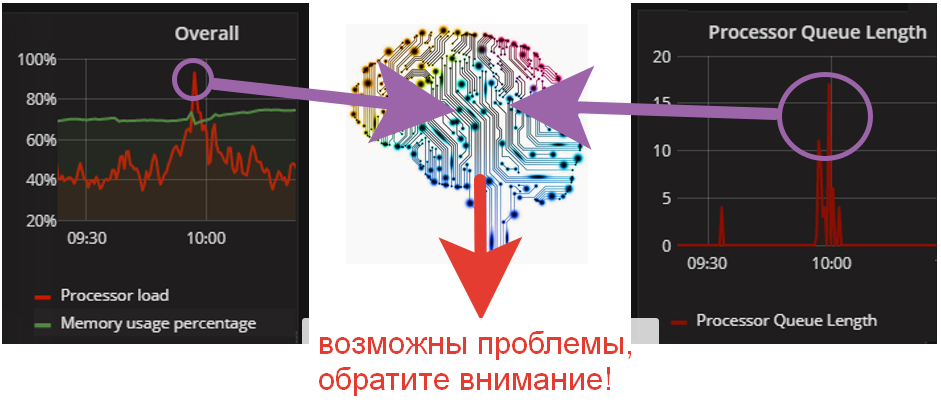
Что будет делать наш AI Лариса? Выполнять сбор данных о производительности, обрабатывать и принимать решение в онлайн режиме, а затем оповещать о проблемах через мессенджер (хотя, она может конечно выполнить и более сложные проактивные действия). Обо всем этом ниже.
Структура статьи
- краткий обзор методологии
- как это работает
- настройка и запуск
- видео-урок
- замечания
Для тех, кто не привык читать и хочет сразу попробовать, предлагаю проследовать к видео-инструкции, а потом вернуться сюда и ознакомится детальнее с тем как это работает под «капотом».
Мы будем использовать открытый Фреймворк "Мониторинг производительности" (https://github.com/Polyplastic/1c-parsing-tech-log).
I) Краткий обзор (на пальцах)
Нечеткая логика ближе по духу к человеческому мышлению и естественным языкам, чем традиционные логические системы. Она обеспечивает эффективные средства отображения неопределённостей и неточностей реального мира.
В нечеткой логике при решении принято оперировать определенными логическими абстракциями - термами, а не цифрами. К примеру, получая информацию о температуре тела, для нас важны понятия "нормальная", "переохлаждение" или "жар". Числовое значение температуры тела мы получаем с применением градусника (фактически датчик сигнала), а затем преобразовываем в понятную для себя систему лингвистических описаний (см. рис. ниже). Этими понятиями в дальнейшем мы оперируем при принятии решений.

Процесс преобразования числовых значений в логические термы называется процедурой фаззификации (fuzzification).
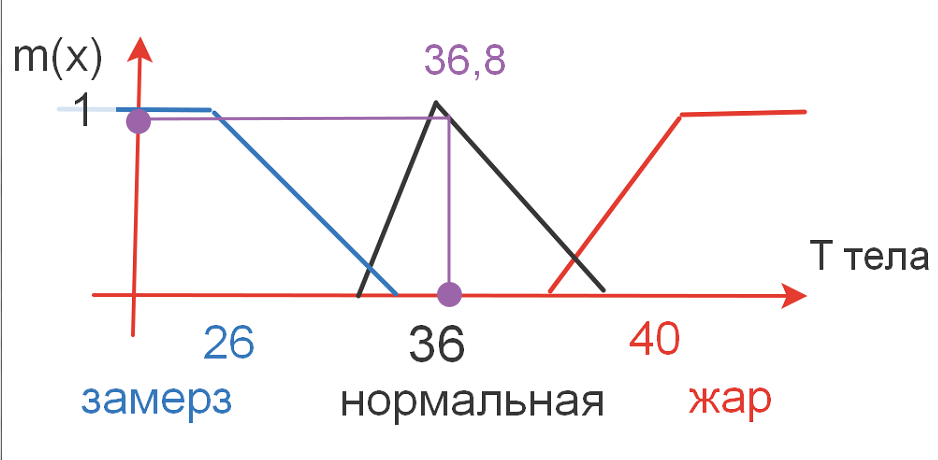
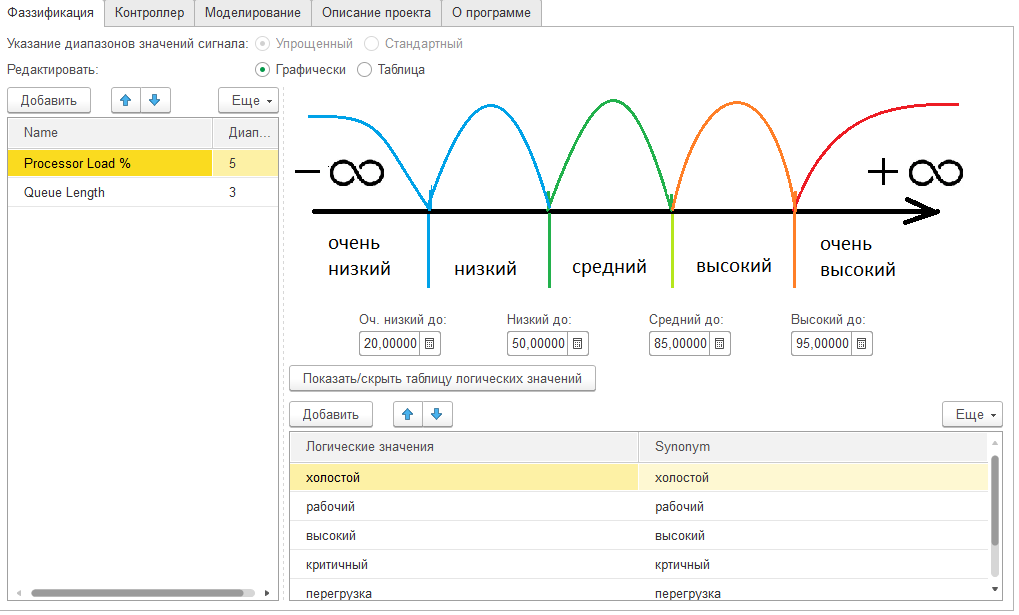
Согласно рисунку у нас получается, что диапазон значений соответствующий терму "замерз" будет (от абсолютного нуля до 35), "нормальная" от 34 до 37, а жар от 37 до максимально возможной.
Теперь поговорим о процессе принятия решений. Но прежде усложним ситуацию и добавим еще один параметр болезнь со значениями "болен" и "здоров". Этот параметр субъективный и может определяться пациентом самостоятельно.
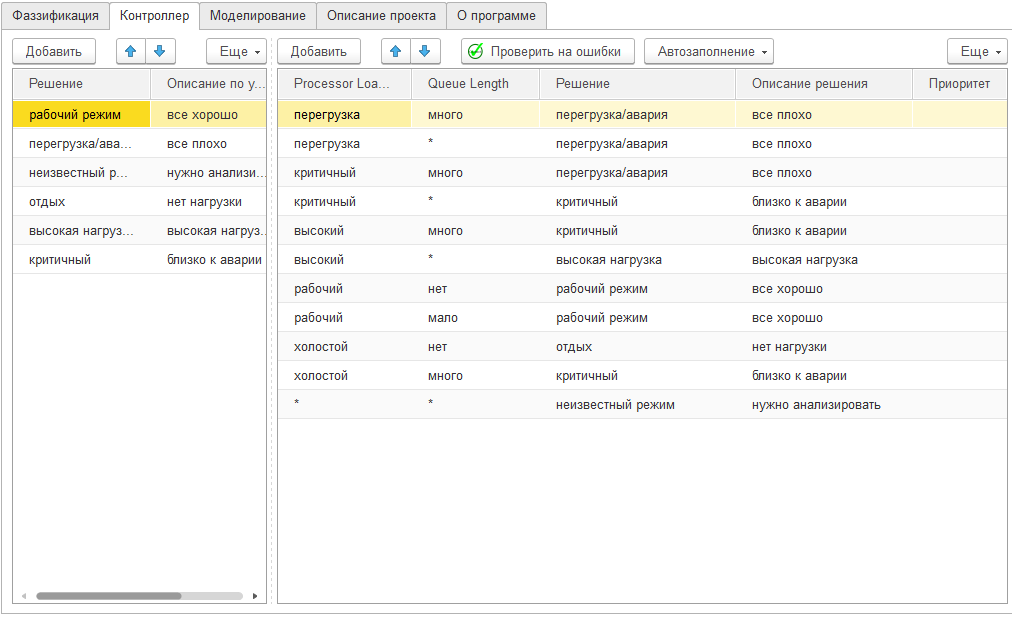
Так как у нас не система управления машиной или краном и не требуется организация управляющего воздействия, а стоит задача в диагностике состояния пациента, то в упрощении процесс принятия решения можно описать комбинацией условий в таблице правил (база знаний).

Как видно из таблицы, то в зависимости от температуры тела и субъективной оценки здоровья, мы можем принять решение что требуется делать. Таблица правил читается следующим образом:
Если температура тела "нормальная" и пациент "здоров" тогда
решение "все хорошо",
Иначе если температура тела "переохлаждение" и "здоров" тогда
решение "необходимо согреться",
Иначе т.д.
Все те же самые размышления мы можем распространить на оборудование:
1. Информацию о правилах и рекомендациях мы можем получить, обратившись к всеобщему разуму, экспертам в области.
В предыдущей статье "За 5 шагов добавляем мониторинг счетчиков производительности серверов MS SQL и 1С" я предоставлял таблицы параметров счетчиков производительности для 1С сервера и MS SQL, в них для каждого элемента приводились оценки допустимых значений и рекомендации.
К примеру, "Buffer cache hit ratio (Коэффициент обращений к буферному кэшу)" рекомендуется чтобы был близок к 100%. Соответственно, если он ниже, то в системе наблюдаются проблемы, а если около 0, то значит скорее все плохо, чем хорошо.
Или счетчик "Свободно мегабайт на диске", должен быть гораздо больше 0 иначе у Вас система просто перестанет работать.
2. Информация на основе текущего опыта для конкретной системы.
Продолжая рассматривать размер диска, нам необходимо понимать какой размер достаточный или критичный для работы - не забываем про существование ограниченности ресурсов (бесконечный размер будет стоить дорого). Эту информацию вы сможете определить, зная параметры своей системы.
Общее понимание работы нечеткой логики в упрощенном представлении у Вас должно появиться и теперь мы готовы двигаться дальше.
В нашем случае (на пальцах) мы должны взять набор показателей, которые являются основными для оценки состояния системы (загрузка процессора, очередь к процессору, количество блокировок, величина свободного места на диске, объем трафика сетевого и т.д.), и как эксперты создать набор суждений, которые будут определять состояние системы "критическое" или "рабочее" в зависимости от комбинаций показателей. Об этом подробнее мы расскажем в отдельной статье и позже.
В качестве демо примера приведена модель (приложение к статье), в котором выполняется суждение о состоянии по двум показателям - "Загрузка процессора %" и "Очередь к процессору". Скачайте и с помощью обработки "нечеткий контроллер" посмотрите подробнее.
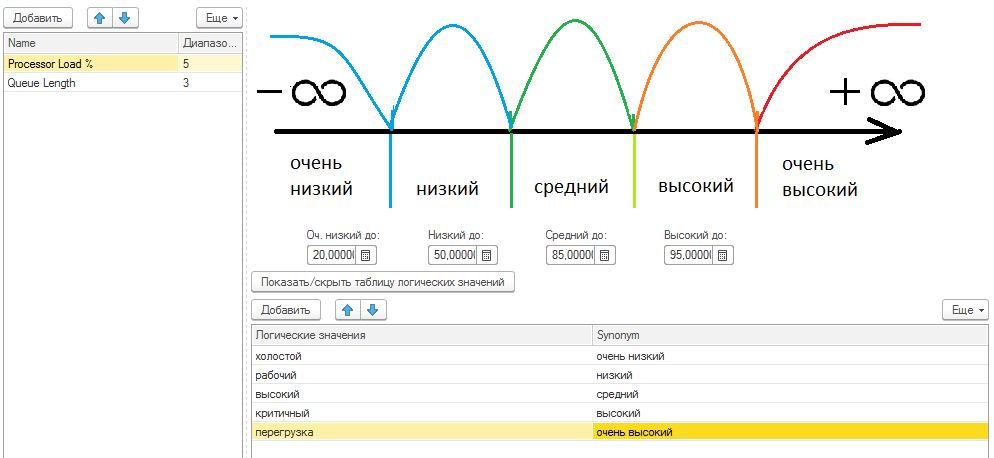
Пример преобразования показателя "Загрузка процессора %" к логическим термам
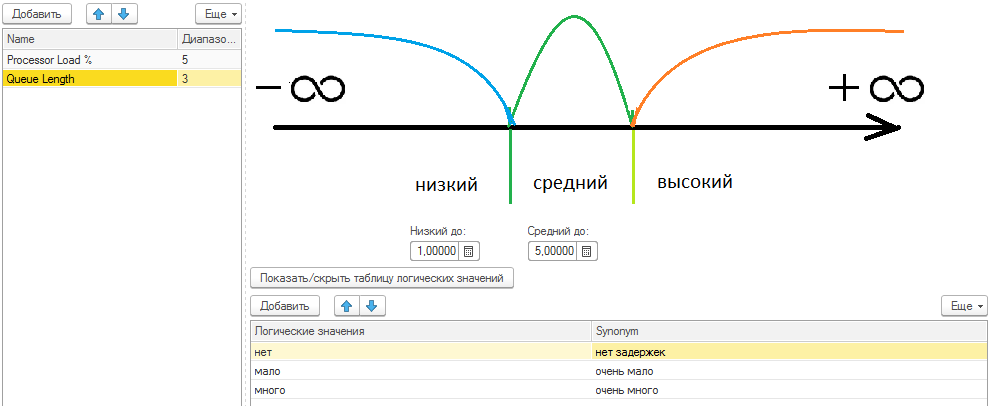
Пример преобразования показателя "Очередь к процессору" к логическим термам
Пример суждения: если загрузка процессора очень высокая и очередь большая, то система находится в аварийном состоянии. Более полная сводка правил на рисунке ниже.

Пример базы знаний - ядро системы ИИ
II) Как это все работает?
Рассмотрим как это реализовано у нас в системе для понимания процесса, что за чем и почему. Ниже на рисунке приведена основная модель.
Как вы можете заметить, то основным звеном в системе является объект "Замеры". А через дополнительные обработки реализуется логика и выполнение проактивных действий.
Ниже приведены четыре основных последовательности действий в хронологическом порядке, которые позволяют достичь желаемого результата, а именно - заставить заработать искусственный интеллект.
Система мониторинга с Ларисой работает в онлайн режиме и реагирует на события/состояние системы возникающие в текущий момент с задержкой на величину интервала запуска регламентного задания. Т.е. если у Вас интервал 60 сек, то актуальность сообщения будет запаздывать на 1 минуту. Но и ставить интервал срабатывания в районе 5 сек не имеет смысла, т.к. любая система обладает инерцией, даже если кто-то начент крушить серверную топором.

Структурная схема описания модели работы мониторинга
1. Загрузка параметров производительности. Входной сырой источник информации для Ларисы - это замеры. Через них мы заводим и доводим до нее данные счетчиков, либо выполняем какую-либо их пост обработку. Это два квадрата – «Замеры технологические» и «Замеры произвольный алгоритм».
О загрузке данных для анализа мы писали ранее: «5 простых шагов и 15 минут на разворачивание инструмента мониторинга проблем производительности базы 1С» и «За 5 шагов добавляем мониторинг счетчиков производительности серверов MS SQL и 1С».
2. Фаззификация. Как было сказано ранее цифры для Ларисы, как для нас китайская грамота, поэтому мы должны выполнить обработку - перевести их из цифровой формы в логические термы. Сказать ей что места на диске мало, или загрузка процессора высокая. На рисунке это блок – «Замеры программные».
Для упрощения мы объединили процедуру выполнения фаззификации и определения решения нечетким контроллером в один блок, но для понимания процесса текущая последовательность важна.
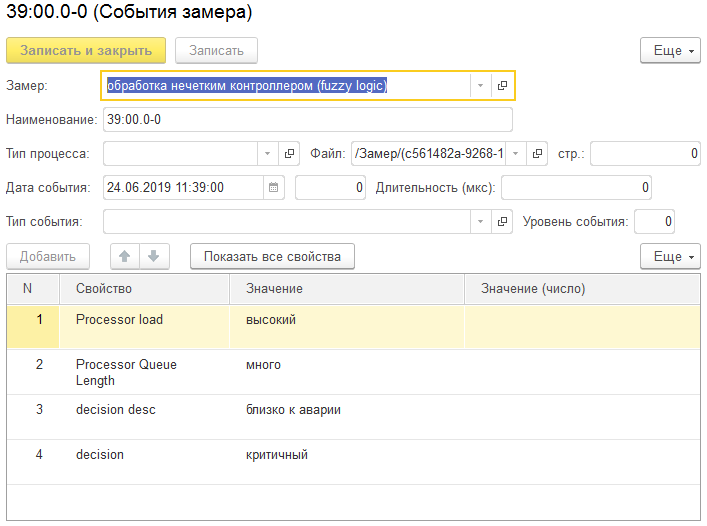
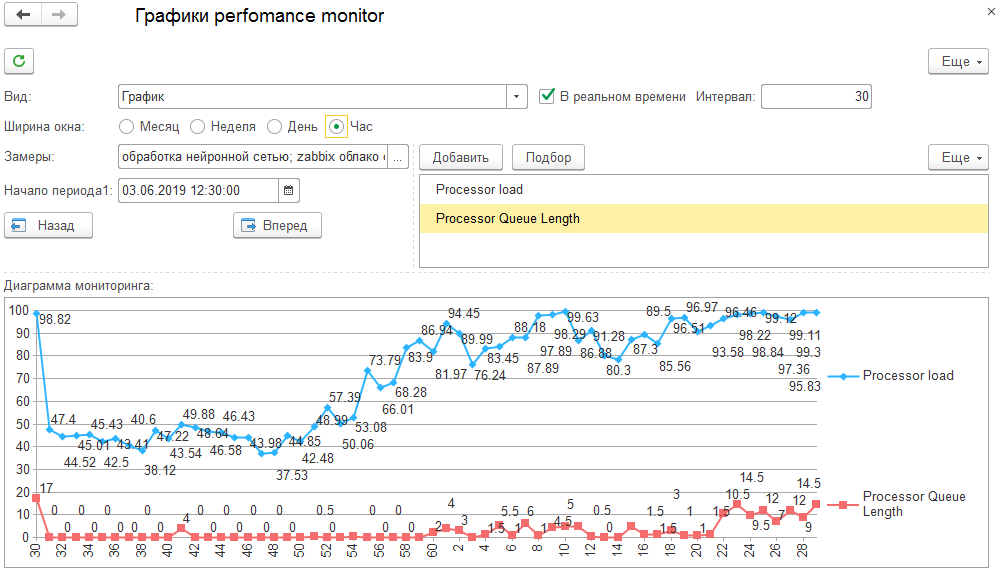
Результат работы фаззификатора и логического контроллера для некоторого события во времени.
3. Обработка нечетким контроллером. Лариса анализирует входную информацию в термах, смотрит в свою базу знаний и принимает решение. Затем записывает это решение в соответствующий замер. На рисунке это блок – «Обработка нейронной сетью».

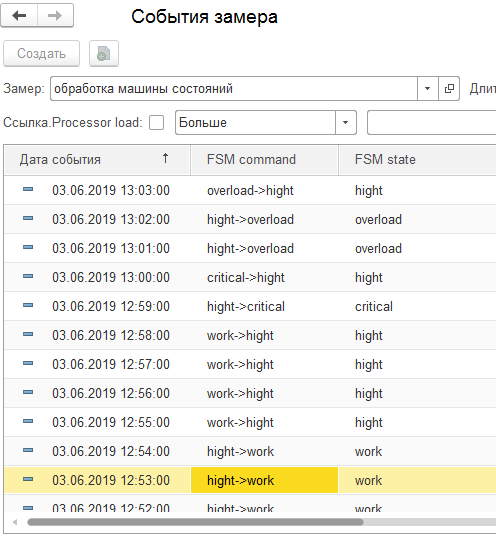
4. Обработка машиной состояний. Теперь, зная состояние системы, она может выполнить, то действие, которое мы описали в наборе дополнительных правил (обычно оповещение). В этом Ларисе помогает машина состояний (FSM – finite-state machine). На рис. это блок – «Обработка машины состояний».
III) Порядок настройки и запуска
0. Подготовка. Загружаем дополнительные обработки:
- "ОбработкаМашиныСостояний.epf", "МашинаСостояний.epf" - обработки "мозги" Ларисы по выполнению действий;
- "НечеткийКонтроллер.epf", "ОбработкаДанныхНечеткимКонтроллером.epf" - обработки "мозги" Ларисы;
- "ОтправкаСообщенийAPI_Skype.epf", "ОтправкаСообщенийAPI_email.epf", "ОтправкаСообщенийAPI_Telegram.epf" - обработки для формирования оповещений.
Настраиваем учетные записи для выполнения оповещения, к примеру, Skype:
- Создаем новую учетную запись и называем ее "Бот Лариса (Skype)" (подсистема "администрирование")
- Далее открываем обработку "ОтправкаСообщенийAPI_Skype.epf"
- Выбираем учетную запись "Бот Лариса (Skype)" и заполняем все параметры для ее работы "IDПриложения", "Пароль", "IDЧата", как их получить можете почитать в этой статье "Отправка сообщений в Skype через Microsoft Bot Framework API".
В подобном режиме настраивается обработка отправки оповещений по почте - "ОтправкаСообщенийAPI_email.epf". Если вы используете другие мессенджеры или приемники информации, то засучите рукава и напишите свой плагин, интерфейс взаимодействия должен соответствовать)
1.Подключаем замеры интересующих параметров и их обработку. Об этом мы рассказывали в предыдущих статьях.
2. Настройка нечеткого контроллера ("электронных мозгов").
2.1. Переходим в подсистему "Оракул" и дальнейшие действия выполняем в этой подсистеме.
2.1. Загружаем демо xml файл модели нечеткого контроллера с сайта "fuzzy.xml" и при необходимости проводим его донастройку с помощью обработки «НечеткийКонтроллер.epf».
2.2. Или создаем новый файл нечеткой логики и пишем свои правила.
2.3. Создаем новый элемент справочника "Нейронные сети", называем его "электронные мозги Ларисы" и загружаем модель - файл xml.
3. Запуск обработки нечеткой системы.
3.1. Открываем форму «ОбработкаДанныхНечеткимКонтроллером.epf» и выполняем настройки
- Указываем ссылку "электронные мозги Ларисы" в поле "Нечеткий контроллер"
- Указываем связь входов модели с замерами и свойствами (замер "загрузка счетчиков производительности" + свойство "Processor Load%" и т.д.). Порядок входов в таблице настройки на форме обработки должен соответствовать порядку входов в модели.
Обратите внимание! В текущей версии обработки дата события (дата вычисления счетчика производительности) выбранных замеров и свойств должны совпадать, т.е., к примеру, дата события "Processor Load%" замера 1 = 26.06.2019 10:07:21 и дата события "Processor Queue Length" замера 2 = 26.06.2019 10:07:21. Если это не так, то нужно провести пост обработку и привести их, к примеру, к началу минуты.
3.2 Создаем новый замер с наименованием "Обработка нечетким контроллером (Лариса)".
- Указываем тип "произвольная обработка", путь к каталогу пишем "не имеет смысла", указываем ссылку на обработку «ОбработкаДанныхНечеткимКонтроллером.epf».
- Ставим в фильтрах дата начала "сейчас" иначе обработает всю историю.
- Настраиваем расписание регламентного задания (мы ставили 60-120 сек) и закрываем.
4. Настройка машины состояний и системы оповещений.
4.1. Выполняем настройку машины состояний с помощью обработки "Машина состояний.epf". Для этого создаем правила вручную или загружаем файл демо примера "finite-state machine.xml" и проводим его донастройку:
- указываем (перевыбираем) учетную запись в таблице настройки действий на "Бот Лариса (Skype)"
- Указываем ссылку на обработку оповещения (у меня были отличные ссылки).
Рекомендуем ставить выполнение оповещения только для переходов из любых состояний в критические. Иначе вы перестанете реагировать на сообщения, их должно быть мало и только в действительно аварийных ситуациях.
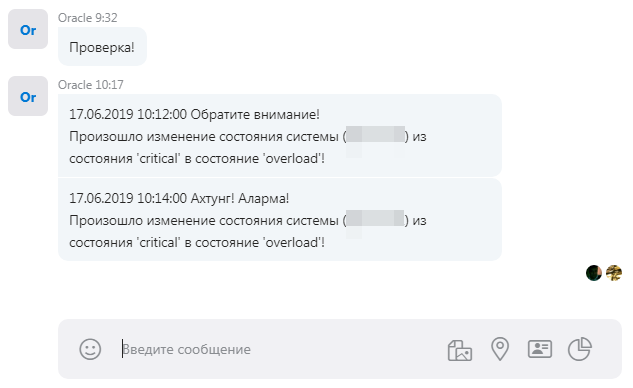
Пример шаблона сообщения:
%ДатаСобытия% %ПриветствиеОпасность% %ПереносСтроки% Произошло изменение состояния системы (%Оборудование%) из состояния '%ПредыдущееСостояние%' в состояние '%ТекущееСостояние%'!
или
%ДатаСобытия% %Приветствие% %ПереносСтроки% (%Оборудование%) находится в состоянии '%ТекущееСостояние%'!
4.2. Создаем новый элемент справочника "Машины состояний" с наименованием "обработка действий Ларисой" и загружаем модель - xml файл.
4.3. Открываем обработку "ОбработкаМашинойСостояний.epf" и выполняем настройку:
- Указываем ссылку на справочник машина состояний "обработка действий Ларисой".
- Указываем ссылку на замер ("Обработка нечетким контроллером (Лариса)") и свойство ("decision", если оно еще не появилось, то можете создать вручную, только потом проверьте все ли ок)
Жмем сохранить и закрываем форму.
4.4. Создаем новый замер с наименованием "Обработка машиной состояний (Лариса)"
- Указываем тип "произвольная обработка", путь к каталогу пишем "не имеет смысла", указываем ссылку на обработку "ОбработкаМашинойСостояний.epf".
- Ставим в фильтрах дата начала "сейчас" иначе обработает всю историю.
- Настраиваем расписание регламентного задания (мы ставили 60-120 сек) и закрываем.
5. Все работает. Получаем профит, наслаждаемся.
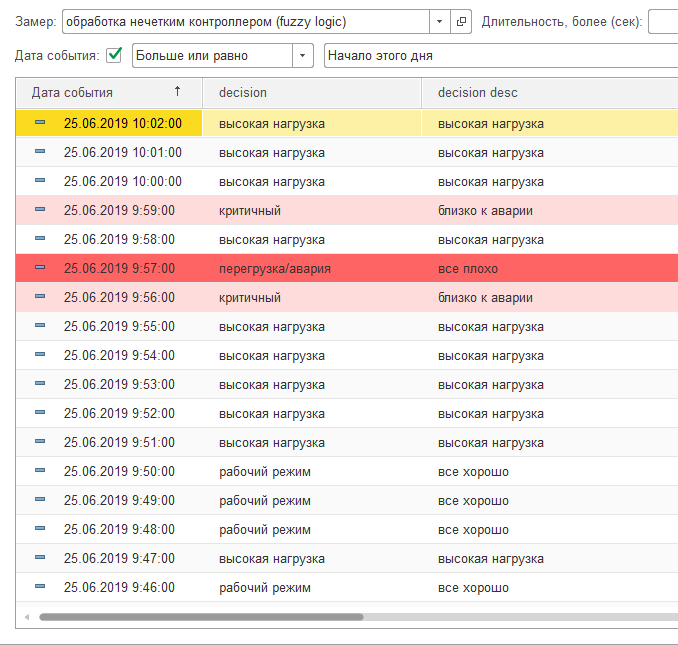
В форме "События замера" можно выбрать последовательно замеры "Обработка нечетким контроллером (Лариса)" и "Обработка машиной состояний (Лариса)" и просмотреть результаты обработки. Если данные отсутствуют, то это значит, что существует какая-либо проблема - проверьте журнал регистрации на ошибки и корректность выполненных настроек.
IV) Видео-урок

V) Замечания
1. Как вы догадались, то можно сделать несколько экземпляров Ларисы, и они могут работать независимо, либо совместно в иерархии.
2. Как вы можете предположить, то для многих сигналов большая детализация даст лучшее предсказание. Но чем больше сигналов мы оцениваем, тем более сложная настройка базы правил получается. К примеру, для двухмерной оценки 5 и 3 градации дадут нам 15 комбинаций, а 3 оценки по 5 диапазонной шкале дадут нам уже 125 комбинаций.
При использовании нейронной сети эта проблема значительно упрощается - она сама будет составлять таблицу. Что делать в текущей ситуации:
а) Рассматривать только рабочие комбинации. Все остальные отмечать, как новизну, аномалии и реагировать на них соответствующим образом, т.е. использовать условие "*" в таблице (это значит любое значение).
б) Использовать иерархию и сжатие, т.е. вначале составить понятие о малом наборе комбинаций, к примеру, 3х, а на выходе будет 1 значение, которое применить на следующем уровне как вход.
3. Как избавиться от всплесков? К примеру, редкие нагрузки для вашей системы явление нормальное, но вот продолжительное воздействие уже не допустимо. Для решения этой проблемы мы должны ввести замер, который будет интегрировать время нахождения в определенном статусе и уже его учитывать при принятии окончательного решения.
4. О тонкостях настройки машины состояний, фаззификации или базы если будет интересно мы можем написать отдельно.
Приложенные файлы проверены на платформе 1С Предприятие 8.3.12.
Вступайте в нашу телеграмм-группу Инфостарт