


-
Проблематика.
Стандартный метод обмена данными между клиентом и сервером - временное хранилище. На одной стороне мы выполняем вызов "ПоместитьВоВременноеХранилище", получаем адрес, передаем его на другую сторону, там выполняем "ПолучитьИзВременногоХранилища". Есть пара неприятных нюансов.
А именно:
- За один вызов невозможно поместить во временное хранилище больше 4 Гб данных.
- В процессе помещения данных в ВХ (здесь и далее временное хранилище) активно используются временные файлы. Точных данных нет, но в процессе помещения в темпах занимается временными файлами четырёхкратный объём помещаемого файла. Помещаете 4 Гб - потребуется ещё 16 Гб на разделе, где размещен temp. С нескромными аппетитами можно бы смириться (всё таки дисковое пространство - не самый дорогой ресурс в наши дни), если говорить об исключительности ситуаций, когда требуется обмен большими объемами данных. Если же эта операция выполняется регулярно, большим количеством пользователей, то велик шанс, что одновременно потребуется место для 10-100-Х (подставьте любое большое число загрузок, которое вам нравится) одновременных закачек, которые могут израсходовать всё свободное место на диске.
- Из второй проблемы вытекает ещё и третья. Скорость записи на жесткий диск (в том числе во временные файлы) не бесконечна, хоть и ожидается выше скорости обмена по сети. А значит, запись пятикратного объема данных (сами данные и четырёхкратный темп для них) займёт пропорционально в 5 раз больше времени, чем если бы данные записывались ровно 1 раз.
-
Пути решения проблемы.
- Не передавать столько данных. Всерьёз такой способ рассматривать не будем.
- Использовать сторонние ресурсы. Тут уже вы ограничены только собственной фантазией (ftp, webdav, облачные хранилища от различных поставщиков). Все эти способы имеют один общий недостаток. Количество операций ввода-вывода увеличивается вдвое. Один раз данные помещаются в условное облако, и только второй раз по назначению (в зависимости от направления передачи данных). Этот способ в статье рассматриваться не будет
- Разделять файл на более мелкие части, передавать каждую часть последовательно. Вариант предполагает использование временного хранилища, а значит решает только одну из двух проблем - ограничение в 4 Гб.
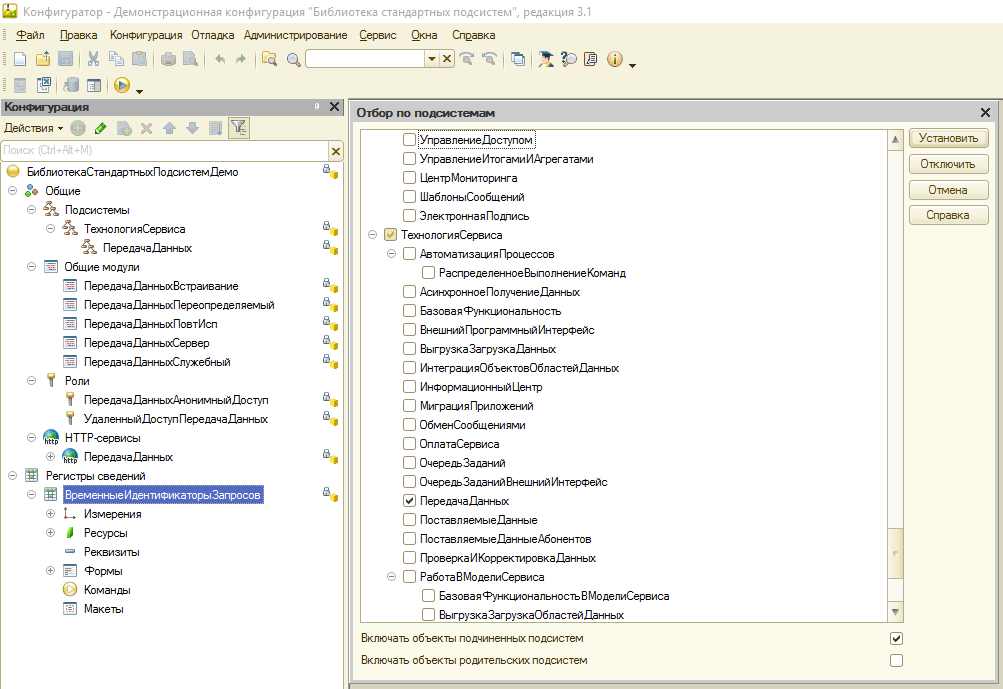
- Использовать альтернативный транспорт, соединяющий напрямую сервер с клиентом (с некоторыми оговорками). Если не уходить в дебри с использованием внешних библиотек, позволяющих открывать TCP сокеты, платформа позволяет нам использовать как довольно гибкий транспорт http соединение с помощью объекта конфигурации http-сервис. А разработчики библиотек компании 1С даже реализовали на основе механизма http-сервисов служебную библиотеку "ПередачаДанных", которая позволяет обмениваться данными серверу 1С Предприятие с различными клиентами (не только родными). На этом способе хотелось бы остановиться более подробно. На тестах по передаче данных объемом до 20Гб средняя скорость получалась примерно в 3 раза выше, чем при передаче через временное хранилище, поддерживалась докачка прерванных загрузок, была теоретическая возможность организовать загрузку в несколько потоков. Описание библиотеки можно найти на сайте ИТС по ссылке. Отдельным пакетом передачу данных не публикуют. Библиотека входит в состав как БСП, так и БТС (из чего следует, что она присутствует во всех типовых, адаптированных для публикации во фреше), которые доступны всем желающим (с подпиской ИТС) на релизах. Библиотека выделена в отдельную подсистему "Передача данных".
-
Как это устроено. Общее описание ландшафта.
Для простоты считаем, что существует сервер предприятия на хосте srv1c, на котором размещена информационная база base1. В базе внедрена библиотека ПередачаДанных. Информационная база и http-сервисы на веб-сервере Apache2.4, опубликованном на хосте srvweb со следующими endpoint-ами:
Адреса методов "ПередачаДанных"
| Endpoint | Наименование | Метод | Описание | Роли | Способ публикации |
|---|---|---|---|---|---|
| /base1 | сама база | Позволяет открыть базу в вебклиенте, в тонком клиенте по WS-ссылке | Зависит от конфигурации | ||
| /base1/hs/dt/storage/{Storage}/{ID} | ХранилищеИИдентификатор | Операции с файлами в логическом хранилище по идентификатору. | |||
| get | Запрос получает токен на скачивание файла из логического хранилища | Полные права, удаленный доступ | Публикация без явного указания учетных данных. Требует аутентификации | ||
| post | Запрос получает токен на загрузку файла в логическое хранилище | Полные права, удаленный доступ | Публикация без явного указания учетных данных. Требует аутентификации | ||
| /base1/hs/dt/volume/{VolumeID}/* | ТомИПутьКФайлу | ||||
| get | Запрос получает токен на скачивание файла из тома | Полные права, удаленный доступ | Публикация без явного указания учетных данных. Требует аутентификации | ||
| post | Запрос получает токен на загрузка файла в том | Полные права, удаленный доступ | Публикация без явного указания учетных данных. Требует аутентификации | ||
| /base1/hs/dt/download/{ID} | Получить | get | По предварительно полученному токену отдает клиенту данные | Полные права, передача данных (анонимный доступ) | Публикация под учетной записью служебного пользователя, которому назначена только роль "Передача данных (анонимный доступ)" |
| /base1/hs/dt/upload/{ID} | Отправить | put | По предварительно полученному токену загружает данные от клиента на сервер | Полные права, передача данных (анонимный доступ) | Публикация под учетной записью служебного пользователя, которому назначена только роль "Передача данных (анонимный доступ)" |
Схема работы:
1. Формируем запрос. Он может быть сформирован как через вызовы методов http-сервиса ХранилищеИИдентификатор и ТомИПутьКФайлу (в этом случае необходимо указать свои учетные данные для аутентификации), так и с помощью серверного вызова: "РегистрСведений.ВременныеИдентификаторыЗапросов.ЗарегистрироватьЗапрос". В этом случае дополнительная аутентификация не нужна, использутся учетные данные текущего сеанса.
2. Ответ на запрос содержит токен. В дальнейшем этот токен используется для анонимного доступа к сервисам "передачи данных". Токен может быть использован только для той операции, которая была запрошена в запросе. Нельзя запросить скачивание файла А, а вместо этого загрузить на сервер файл Б. Токен действителен в течение 10 минут после регистрации запроса. После каждого обращения по токену время его жизни продляется на 10 минут.
3. Запрос может отправлять и получать как данные целиком, так и какую-то порцию. Это поведение регулируется http заголовком Content-Range.
-
Пример реализации загрузки данных на сервер в тонком клиенте
Рассмотрим последовательность действий, которые необходимо совершить для отправки данных из тонкого клиента на сервер. Предполагаем, что http-сервис настроен и опубликован. Считаем, что файл доступен через диалог выбора файла и выбираем его:
АдресВХранилище = "";
ДополнительныеПараметры = Новый Структура;
ОписаниеОповещения = Новый ОписаниеОповещения("ВыборФайлаОповещение", ЭтотОбъект, ДополнительныеПараметры);
Диалог = Новый ДиалогВыбораФайла(РежимДиалогаВыбораФайла.Открытие);
Диалог.Заголовок = "Выберите файл";
Диалог.ПолноеИмяФайла = "";
Диалог.МножественныйВыбор = Ложь;
Диалог.Показать(ОписаниеОповещения);
далее следует неудобная для листинга цепочка якобы асинхронных вызовов, получение размера файла итд. Этот этап пропустим, переходим сразу к загрузке.
&НаКлиенте
Процедура ПоместитьФайлНаСерверПослеОпределенияРазмера(Размер, ДополнительныеПараметры) Экспорт
Попытка
Если Цел(Размер / ДополнительныеПараметры.РазмерЧасти) = (Размер / ДополнительныеПараметры.РазмерЧасти) Тогда
ВсегоЧастей = Цел(Размер / ДополнительныеПараметры.РазмерЧасти);
Иначе
ВсегоЧастей = Цел(Размер / ДополнительныеПараметры.РазмерЧасти) + 1;
КонецЕсли;
СтруктураПубликации = Неопределено;
ИдентификаторЗапроса = Неопределено;
ЗаполнениеПараметровПубликацииНаСервере(ИдентификаторЗапроса, ДополнительныеПараметры, Размер, СтруктураПубликации);
Соединение = Новый HTTPСоединение(СтруктураПубликации.Хост, , , , , ,
?(СтруктураПубликации.Схема = "https", Новый ЗащищенноеСоединениеOpenSSL, Неопределено), Ложь);
Если НЕ СтрЗаканчиваетсяНа(СтруктураПубликации.ПутьНаСервере, "/") Тогда
СтруктураПубликации.ПутьНаСервере = СтруктураПубликации.ПутьНаСервере + "/";
КонецЕсли;
url = СтрШаблон("%1upload/%2",СтруктураПубликации.ПутьНаСервере, ИдентификаторЗапроса);
Запрос = Новый HTTPЗапрос(url);
Файл = Новый Файл(ДополнительныеПараметры.ИмяФайлаНаКлиенте);
Размер = Файл.Размер();
Порция = ДополнительныеПараметры.РазмерЧасти;
Обработано = 0;
Если Размер <= Порция Тогда
Количество = Размер;
Иначе
Количество = Порция;
КонецЕсли;
ФайловыйПоток = ФайловыеПотоки.ОткрытьДляЧтения(ДополнительныеПараметры.ИмяФайлаНаКлиенте);
ОбработаноЧастей = 0;
Пока Размер > Обработано Цикл
ТекстСостояния = НСтр("ru='Идет загрузка файла на сервер (%1 из %2)...'");
ТекстСостояния = СтроковыеФункцииКлиентСервер.ПодставитьПараметрыВСтроку(ТекстСостояния, ОбработаноЧастей, ВсегоЧастей);
ПроцентВыполнения = Окр(ОбработаноЧастей * 100 / ВсегоЧастей, 3);
Состояние(ТекстСостояния, ПроцентВыполнения);
Количество = Мин(Размер - Обработано, Порция);
Буфер = Новый БуферДвоичныхДанных(Количество);
ФайловыйПоток.Прочитать(Буфер, 0, Количество);
ИнтервалТекст = "bytes "+Формат(Обработано, "ЧН=0; ЧГ=0");
Обработано = Обработано + Количество;
ИнтервалТекст = ИнтервалТекст+"-"+Формат(Мин(Размер-1,Обработано-1), "ЧН=0; ЧГ=0")+"/"+Формат(Размер, "ЧН=0; ЧГ=0");
Запрос.Заголовки.Вставить("Content-Range", ИнтервалТекст);
Запрос.УстановитьТелоИзДвоичныхДанных(ПолучитьДвоичныеДанныеИзБуфераДвоичныхДанных(Буфер));
Ответ = Соединение.Записать(Запрос);
Если Ответ.КодСостояния >= 200 И Ответ.КодСостояния < 300 Тогда
ОбработаноЧастей = ОбработаноЧастей + 1;
Иначе
ТекстСообщения = НСтр("ru = 'При загрузке файла произошла ошибка: %1'");
ВызватьИсключение СтрШаблон(ТекстСообщения, Ответ.ПолучитьТелоКакСтроку());
Прервать;
КонецЕсли;
КонецЦикла;
ОтветJSON = Ответ.ПолучитьТелоКакСтроку();
#Если НЕ Вебклиент Тогда
ЧтениеJSON = Новый ЧтениеJSON;
ЧтениеJSON.УстановитьСтроку(ОтветJSON);
ОтветСтруктура = ПрочитатьJSON(ЧтениеJSON);
ИдФайлаВыгрузки = Новый УникальныйИдентификатор(ОтветСтруктура["id"]);
#КонецЕсли
Исключение // По каким-то причинам файл разделить не удалось.
ОписаниеОшибки = ОписаниеОшибки();
Сообщить(ОписаниеОшибки);
КонецПопытки;
КонецПроцедуры
Вызов "ЗаполнениеПараметровПубликацииНаСервере" регистрирует запрос на сервере от имени текущего пользователя, что в дальнейшем позволит анонимно отправлять http запросы без аутентификации. Образец работы с библиотечными вызовами будет приложен в файлах. Далее инициализируются http соединение, запрос уже на анонимный http сервис upload. Открывается файловый поток на чтение и последовательно вычитывается в буфер указанное в настройках количество байт. Запрос дополняется заголовком "Content-Range", используемым на сервере для "склейки" фрагментов передаваемого файла, и отправляется на сервер. Эта процедура циклически повторяется, пока все данные из файла не будут переданы. Последний ответ сервера содержит идентификатор файла в логическом хранилище (для его дальнейшего использования).
-
Пример реализации скачивания данных с сервера в тонком клиенте
Тут всё просто:
- как то находим наш идентификатор
- формируем запрос на скачивание, как в предыдущем пункте
- формируем полный URL загружаемого файла
- делаем гиперссылку с этим URL на форме
На самом деле немного сложнее, но об этом в последнем разделе
-
Пример реализации загрузки данных на сервер в веб-клиенте
В веб клиенте всё сильно сложнее. На момент разработки веб клиент позволял либо выбрать файл и поместить его сразу во временное хранилище (метод "НачатьПомещениеФайла" до платформы версии 8.3.13 не позволял отказаться от помещения файла в ВХ), либо требовал установки расширения для работы с файлами, чтобы показать диалог выбора файла. А после ещё и дополнительно запрашивал разрешения на чтение файла ещё раз. И это даже не самое страшное... Веб клиент не позволяет создавать http запросы в коде.
А вот java script позволяет. Поэтому было принято решение для веб клиента экспроприировать диалог выбора файла прямо из браузера со всеми стилями и использовать его в своих корыстных целях. HTML форма диалога выбора файла позволяет перетаскивать файл(ы) drag'drop-ом, сразу несколько (хотя это и запрещено в примере), показывает полосу прогресса (чего в 8.3.15 так и не сделали), ну и конечно же работает с библиотекой "Передача данных". Более подробно смотрите внешнюю обработку в приложениях к статье.
-
Концепт скачивания данных с сервера в веб-клиенте
Тут нужен небольшой экскурс в непростую историю развития браузеров и стандартов html5 в частности. Для предыдущего пункта использовался достаточно удобный, всеми принятый стандарт FileReader API. А вот для аналогичных операций при скачивании файлов нужен противоположный процесс - запись. А вот с этим из соображений безопасности у браузеров очень туго. File Writer так и не вышел из статуса черновика, был с горем пополам в какой то момент реализован Мозиллой, можно сказать, что его не существует. Однако файл загружать хочется.
Можно это делать тем же способом, как предложено в п.5. Однако тут начинаются неприятные неожиданности на этапе открытия ссылки для скачивания. Браузер непонятно чем занимается, крутит колесико минуту-несколько, потом, возможно показывает диалог скачивания файла, а нередко ошибку 504. Что бы это значило, задумался я?
Проанализировав активность на сервере (дисковую в первую очередь) было выяснено, что файл после запроса начинает бродить по темпам. Сначала его копирует сервер предприятия, потом веб-сервер, потом (в моём случае на внешний мир смотрел ещё 1 слой из nginx в роли reverse proxy) ещё раз это делает nginx. И вот, пока идёт копирование файла во временные, колёсико крутится и мы ждём. Если файл не успевает скопироваться за настроенное время ожидания - привет 504 (Gateway timeout).
На просторах интернета было найдено решение по рекомендации "лучших собаководов". Оно достаточно зависит от используемого веб-сервера.
Методика называется "контролируемая загрузка", состоит в следующем. Клиент запрашивает какой то ресурс. В нашем случае: https://host/ib/hs/dt/download/queryid. Вебсервер передает этот запрос на backend (на сервер предприятия), который добавляет в ответ специальные заголовки, которые говорят вебсерверу, какой файл отдавать. Примеры (правда для php) можно посмотреть в этой статье на хабре. Здесь приведу пример для nginx в режиме reverse proxy.
1. В конфиге нашего сервера объявляем дополнительный "internal" location. Это важно. Доступ к файловой системе, указанной в этом location будет только у сервера, клиенты даже случайно не смогут получить доступа к содержимому каталога или даже самим файлам по прямой ссылке. Возможно использование как локальных файловых систем, так и смонтированных cifs и nfs шар.
location /protected/ {
internal;
root /some/path;
}
2. В коде http-сервиса на стороне сервера предприятия добавляем специальные заголовки к ответу. В отличие от стандартной передачи файла в ответе сервера, в тело ответа не добавляются двоичные данные файла, а используется заголовок "X-Accel-Redirect". В переменной ИмяФайла формируется путь до файла в location, например, если файл фактически находится в /some/path/protected/file1.txt, то в переменной ИмяФайла должно находиться значение /protected/file1.txt. Ознакомиться с документацией по этому механизму можно здесь
Ответ = Новый HTTPСервисОтвет(200);
Ответ.Заголовки.Вставить("X-Accel-Redirect", ИмяФайла);
Ответ.Заголовки.Вставить("Content-Disposition", СтрШаблон("attachment; filename=""%1""", ИмяФайла));
Ответ.Заголовки.Вставить("Content-Type", "application/octet-stream");
Аналогичный инструмент существует для Apache (если вам не нужен reverse proxy) - mod_xsendfile, так же есть (вроде бы) модуль для IIS, но этот вопрос я не изучал, поэтому советовать ничего не буду.
PS: Не судите строго за не совсем ИС тематику публикации. Очень огорчает распространенное мнение, что 1С - это медленно, местячковый продукт для своих целей и своего рынка.
PPS: файл внешней обработки "выдирался" из конфигурации, возможно содержит ошибки. Тестирование проводилось на конфигурации Менеджер сервиса 1.0.83.10. Если будут проблемы, с удовольствием помогу разобраться в комментариях и/или обновлениях статьи.
Вступайте в нашу телеграмм-группу Инфостарт
