















Продолжаем
 Продолжаем развивать тему штатного полнотекстового поиска платформы 1С. До этого был представлен инструмент для обслуживания полнотекстового индекса "Мастер полнотекстового поиска" c расширенными возможностями и подробно рассмотрены нюансы работы поиска в динамических списках в публикации "Полнотекстовый поиск в 1С. №1 Грабли в динамических списках".
Продолжаем развивать тему штатного полнотекстового поиска платформы 1С. До этого был представлен инструмент для обслуживания полнотекстового индекса "Мастер полнотекстового поиска" c расширенными возможностями и подробно рассмотрены нюансы работы поиска в динамических списках в публикации "Полнотекстовый поиск в 1С. №1 Грабли в динамических списках".
Но есть и другая сторона - это программная работа с индексом полнотекстового поиска и настройка объектов для включения в его состав.
Сегодня мы как раз и рассмотрим вопросы и проблемы, связанные с разработкой и использованием полнотекстового индекса, а также некоторые нюансы его работы. Начнем с настроек метаданных объектов конфигурации.
Индексировать все
На самом деле арсенал разработчика в части настройки полнотекстового индекса платформы не так велик. Все что мы можем сделать, чтобы повлиять на состав индексируемых данных - это включить индексирование для объекта метаданных и отдельно настроить индексирование для каждого поля (в том числе и для некоторых стандартных реквизитов, о чем иногда забывают разработчики. Еще можно индексировать поля в табличных частях). Например, вот так включено индексирование для справочника "Физические лица".
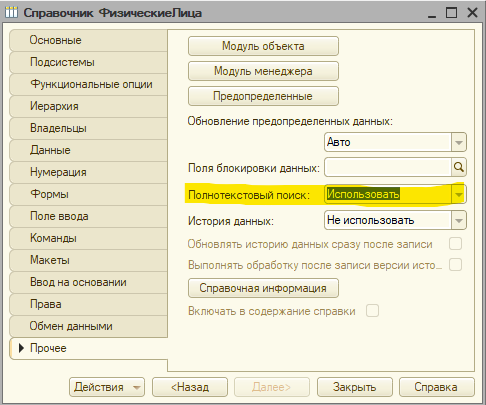
Эта настройка позволяет включить / исключить объект из полнотекстового индекса. При создании объектов по умолчанию поиск включен для всех объектных типов, а для регистров выключен. Настройка доступна почти для всех объектов метаданных.
Также доступно свойство "Полнотекстовый поиск" для отдельных полей (реквизитов, ресурсов, измерений) вне зависимости (почти) от их типа (кроме ссылок на внешние источники данных разве что). Да, полнотекстовый индекс можно использовать даже для регистров, но используется это редко. Какой смысл искать данные через индекс ППД в регистре накопления? Наверное, для регистров сведений еще это как-то можно применить, и то в особых случаях. Например в 1С:Документооборот что-то подобное применялось.

Конфигурация может содержать несколько сотен объектов метаданных и еще больше полей. Посмотреть индексирование может быть не простой задачей - придется все "прокликивать". Можно написать скрипт самому для проверки индексирования или использовать инструмент "Мастер полнотекстового поиска" для просмотра настроек полнотекстового индексирования объектов.
 Кроме этого, есть еще настройки поиска данных при вводе по строке. В разделе настроек "Поле ввода" объектных типов можно найти настройку "Полнотекстовый поиск" для ввода по строке. Эта настройка имеет описание на ИТС.
Кроме этого, есть еще настройки поиска данных при вводе по строке. В разделе настроек "Поле ввода" объектных типов можно найти настройку "Полнотекстовый поиск" для ввода по строке. Эта настройка имеет описание на ИТС.
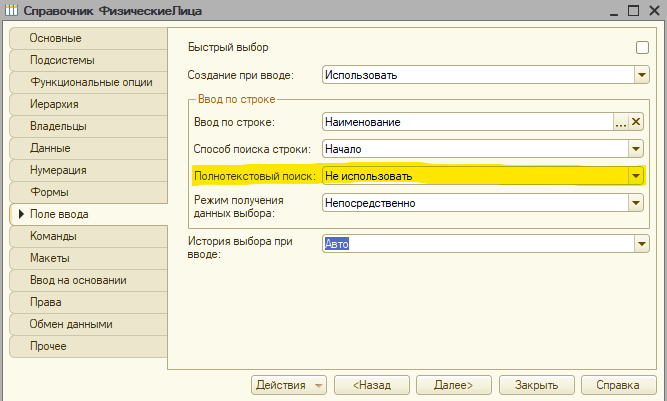 Позволяет выполнять поиск не средствами СУБД, как это делается обычно, а с помощью индекса ППД. Также управлять использованием ППД при вводе можно в событии "ОбработкаПолученияДанныхВыбора" модуля менеджера объекта.
Позволяет выполнять поиск не средствами СУБД, как это делается обычно, а с помощью индекса ППД. Также управлять использованием ППД при вводе можно в событии "ОбработкаПолученияДанныхВыбора" модуля менеджера объекта.
Процедура ОбработкаПолученияДанныхВыбора(ДанныеВыбора, Параметры, СтандартнаяОбработка)
// Отключаем стандартную обработку и включаем полнотекстовый поиск
СтандартнаяОбработка = Ложь;
Параметры.ПолнотекстовыйПоиск = ПолнотекстовыйПоискПриВводеПоСтроке.Использовать;
КонецПроцедуры
Для событий ввода по строке в технологический журнал даже были добавлены события "INPUTBYSTRING" для анализа его работы. Подробнее есть информация здесь.
Пожалуй, это практически все настройки полнотекстового поиска, которые может использовать разработчик для определения состава данных, которые платформа 1С добавила в индекс ППД, а также некоторых действий при поиске.
Первая проблема и обслуживание
Основные настройки мы рассмотрели, но появилась и первая проблема. Если в конфигурации множество объектов, а на стороне базы в этих объектах большое количество записей, то сразу возникает вопрос: а что, если полнотекстовый поиск мне нужно использовать только для одного справочника?
На небольших и средних базах такой вопрос может вообще не возникнуть, но если база "весит" сотни гигабайт или терабайты, то просто так взять и проиндексировать ее штатными средствами платформы 1С практически невозможно. Или же это займет несколько дней, неделю (делайте ставки). Для любознательных: краткое описание процесса поддержки полнотекстового индекса.
Именно на этапе обновления или слияния индекса платформа 1С может значительно "подвиснуть", если данных к индексированию в базе очень много. Не спасет даже многопоточное обновление индекса несколькими фоновыми заданиями, которое появилось в платформе. Именно поэтому в таких случаях нужно выбрать конкретные объекты метаданных, для которых будет использоваться полнотекстовый поиск, а для каких нет.
Но сделать последнее не так просто, ведь групповой обработки изменения свойства "Полнотекстовый поиск" нет, а "прокликивать" каждый объект это та еще задача (хотя определенным образом ее можно решить с помощью EDT, но...). Плюс за всеми изменениями не уследишь. В итоге самым простым способом является отключение полнотекстового поиска для всех объектов через выгрузку конфигурации в файлы и последующее его включение только для нужных объектов и свойств:
- Выгружаем
 конфигурацию в файлы (в конфигураторе команда находится в меню "Конфигурация -> Выгрузить конфигурацию в файлы".
конфигурацию в файлы (в конфигураторе команда находится в меню "Конфигурация -> Выгрузить конфигурацию в файлы". - Ждем.
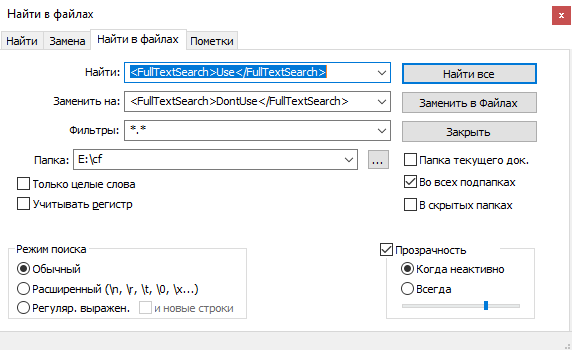
- Затем идем в каталог и, например, с помощью Notepad++ заменяем во всех XML строку "<FullTextSearch>Use</FullTextSearch>" на "<FullTextSearch>DontUse</FullTextSearch>" во всех файлах. Это отключит полнотекстовый поиск не только у объектов, но и у полей.
- Ждем завершения замены.
- И загружаем конфигурацию из файлов в конфигурацию информационной базы (в конфигураторе команда находится в меню "Конфигурация -> Загрузить конфигурацию из файлов...".
- И вручную включаем полнотекстовый поиск для нужных объектов метаданных и их свойств (реквизитов, ресурсов, измерений и т.д.).
На всякий случай это можно сделать на отдельной конфигурации. А позже применить изменения на основную конфигурацию через сравнение / объединение с проверками.
Теперь проблема индексирования всех объектов базы будет решена. Мы оставим в полнотекстовом индексе только те данные, те объекты, которые нам действительно нужны. К сожалению, через расширения изменять настройку использования полнотекстового поиска пока нет возможности, поэтому придется изменять все в самой конфигурации. Но, возможно, это временное ограничение. Идеальным решением была бы возможность настраивать индексирование объектов в режиме 1С:Предприятие, но пока такой возможности также не предоставляется.
Добавлю, что в будущем необходимо следить, чтобы для новых объектов конфигурации устанавливались корректные настройки использования полнотекстового поиска. Как говорилось ранее, для новых объектов метаданных ссылочных типов полнотекстовый поиск включен по умолчанию. Это может быть нежелательным поведением, не зря же мы все отключали до этого. Поэтому можно написать пару unit-тестов и отслеживать корректность настроек индекса ППД с божьей их помощью.
Программный поиск
Мы рассмотрели основные настройки состава индекса ППД и проблему для больших баз данных, немного погрузились во внутренности механизма обслуживания и привели некоторые полезные ссылки. Это то, что точно следует знать разработчику о полнотекстовом поиске для эффективной работы. Теперь рассмотрим примеры программного использования индекса ППД и ключевые возможности функционала.
Внимание!!! Все данные из примеров вымышленные. Любое сходство с реальными людьми случайно :) Для примера было сгенерировано порядка 1 млн. записей в справочнике "Физические лица", который есть во многих типовых конфигурациях.
Итак, поехали!
Самый простой пример
Выполнять операции поиска данных через индекс ППД можно через объект "СписокПолнотекстовогоПоиска", который создается следующим образом:
// Параметры поиска
СтрокаПоиска = "Пагубный";
РазмерПорции = 10;
// Создаем список
СписокПоиска = ПолнотекстовыйПоиск.СоздатьСписок(СтрокаПоиска, РазмерПорции);
В этот момент список не содержит каких-либо результатов поиска. Это лишь служебных объект с установленной строкой поиска и размером порции получаемых данных. Далее можно установить дополнительные настройки, которые не являются обязательными.
// Дополнительные настройки
//
// Позволяет отключить поиск по представлениям объектов
// В старых версиях платформы представление всегда участвовало в поиске
СписокПоиска.ИспользованиеМетаданных = ИспользованиеМетаданныхПолнотекстовогоПоиска.НеИспользовать;
// Ограничения области поиска по объектам метаданных
СписокПоиска.ОбластьПоиска.Добавить(Метаданные.Справочники.ФизическиеЛица);
// Признак получения описания для результатов поиска.
// Можно отключать для оптимизации выполнения поиска.
СписокПоиска.ПолучатьОписание = Истина;
// Признак получения представления для результатов поиска.
// Можно отключать для оптимизации выполнения поиска.
СписокПоиска.ПолучатьПредставление = Истина;
// Содержит порог поиска в процентах от длины слова.
// Если значение = 0, то это обычный поиск.
// Например, длина слова 5, свойство равно 50 (%) - тогда порог равен 2 - т.е.
// 2 буквы в слове могут отличаться.
СписокПоиска.ПорогНечеткости = 0;
С их помощью мы можем установить фильтры на объекты метаданных, по которым выполняется поиск, а также указать использование представления объектов в поиске.
Опции "ПолучитьОписание" и "ПолучатьПредставление" позволяет к результату поиска добавить контекстные данные и представления объектов, но это может снизить производительность. Следует использовать при необходимости. Если установить обе опции в "Ложь", то иногда можно заметно ускорить поиск.
Особый параметр - это "ПорогНечеткости". С его помощью можно выполнять гибкий поиск по словам с указанием процента неточности. В комментариях листинга описан небольшой пример.
Когда все параметры заданы, мы можем получить первую порцию результатов. Есть несколько вариантов:
// Выполняем поиск и получаем первую порцию данных
Попытка
// Получение результатов поиска разными вариантами:
// - Первую порцию
СписокПоиска.ПерваяЧасть();
// - Следующую порцию данных начиная с индекса определенного элемента
//СписокПоиска.ПредыдущаяЧасть(ТекущаяПозиция);
// - Предыдущую порцию данных начиная с индекса определенного элемента
//СписокПоиска.СледующаяЧасть(ТекущаяПозиция);
// - Получить элемент результата поиска по индексу (из текущей порции)
//СписокПоиска.Получить(ИндексЭлементаИзТекущейПорции);
Исключение
ВызватьИсключение
"Не удалось выполнить запрос полнотекстового поиска: "
+ ОписаниеОшибки();
КонецПопытки;
Это может быть получение либо первой порции данных, либо новой порции от предыдущего результат поиска (следующую или предыдущую). Также можно использовать метод "Получить" для получения конкретного элемента результата поиска, который был получен в текущей порции. Фактически эти методы позволяют обходить результаты запроса постранично. Никто, кстати, не мешает обойти результаты текущей порции простым циклом.
Для Каждого ЭлементРезультат Из СписокПоиска Цикл
//ЭлементРезультат.Значение // Найденное значение
//ЭлементРезультат.Метаданные; // Метаданные найденного объекта
//ЭлементРезультат.Описание; // Заполнен, если опция "ПолучатьОписание"
//ЭлементРезультат.Представление; // Заполнен, если опция "ПолучатьПредставление" включена
КонецЦикла;
Когда порция получена, мы можем извлечь дополнительную информацию о результате поиска:
// Информация о результате поиска
//
// Количество найденных элементов в текущей порции
Количество = СписокПоиска.Количество();
// Всего найдено элементов
ПолноеКоличество = СписокПоиска.ПолноеКоличество();
// Индекс первого элемента в порции
НачальнаяПозиция = СписокПоиска.НачальнаяПозиция();
// Если во время поиска платформа 1С остановила поиск принудительно
// и в результат не вошли все результаты, то флаг будет равен ИСТИНА
// Это признак того, что нужно уточнить запрос
СлишкомМногоРезультатов = СписокПоиска.СлишкомМногоРезультатов();
По этим параметрам можно судить сколько данных найдено, сколько вообще порций данных нужно обработать, начало текущей порции и точность результата.
Для получения результата поиска в виде HTML или XML платформа 1С предоставляет метод "ПолучитьОтображение".
// Получает результат поиска в подготовленном виде.
// Позволяет получить в виде HTML или XML. В результате также
// подствечиваются найденные слова или части слов.
ВидОтображения = ВидОтображенияПолнотекстовогоПоиска.HTMLТекст;
// ВидОтображения = ВидОтображенияПолнотекстовогоПоиска.XML;
ОтображениеРезультата = СписокПоиска.ПолучитьОтображение(ВидОтображения);
Именно этим способом в типовых конфигурациях реализуется отображение результата поиска в обработке "ПолнотекстовыйПоискДанных" из БСП. Вот так выглядит эта обработка.

Это практически все средства для программной работы, которые имеет платформа 1С из коробки. Мы не рассматриваем процедуры обслуживания и настройки индекса ППД. Это Вы можете посмотреть в других публикациях, ссылки на которые были пару раз упомянуты выше. Теперь мы рассмотрим еще примеры работы со строкой поиска, чтобы увидеть всю мощь работы полнотекстового поиска.
Магия строки поиска
Строка поиска позволяет указывать как именно этот самый поиск должен выполняться. При этом есть возможность делать как четкий поиск, так и более гибкий с разными допущениями и условиями. Все примеры далее будем делать с использованием стандартной обработки поиска из БСП, которую Вы также можете использовать для изучения работы механизма.
Логические операторы
Строка поиска может содержать логические операторы И (AND или &), ИЛИ (OR или | или ,), НЕ (NOT). Они всегда пишутся в верхнем регистре. Если мы задаем простую строку поиска в виде:
Самоотверженный Валун Кубрикович
то фактически используются операторы И между словами:
Самоотверженный И Валун И Кубрикович
Это стандартное поведение. В результат попадут все объекты, в тексте которых присутствуют все три слова. При этом если поменять местами искомые слова, то результат будет тот же.
Самоотверженный И Кубрикович И Валун
Таким же образом мы можем использовать оператор ИЛИ:
Самоотверженный ИЛИ Валун ИЛИ Кубрикович
Порядок слов в условиях также не имеет значения. В результат попадут все объекты, в текстовых данных которых есть хотя бы одно из искомых слов.
И, конечно же, для поиска можно использовать оператор НЕ, чтобы исключать из результатов те объекты, в текстовых данных которых содержится определенное слово. Например, такой запрос:
Самоотверженный Лемович НЕ Меридиан
найдет все объекты, в которых содержатся слова "Самоотверженный" и "Лемович", но при этом нет слова "Меридиан".
Есть один нюанс: эти операторы не используются как унарные в начале строки поиска. То есть нельзя сделать вот такой запрос:
НЕ Меридиан
Таким образом, с помощью операторов можно выполнять поиск вхождения слов по текстовому содержимому объектов. Вот так выглядят все примеры выше.

Теперь мы можем перейти к следующему оператору.
Рядом
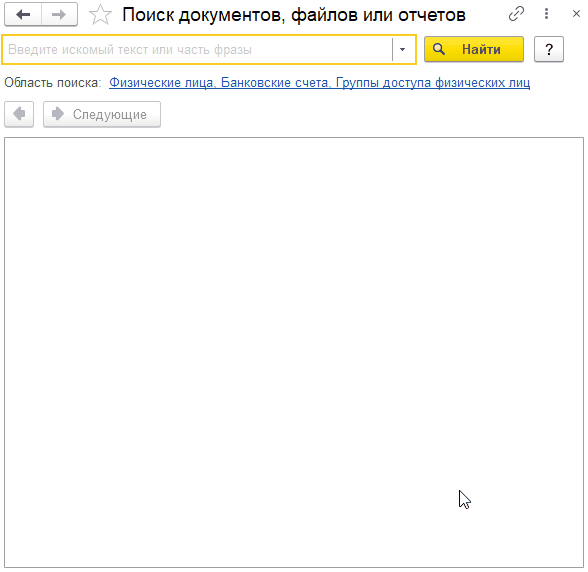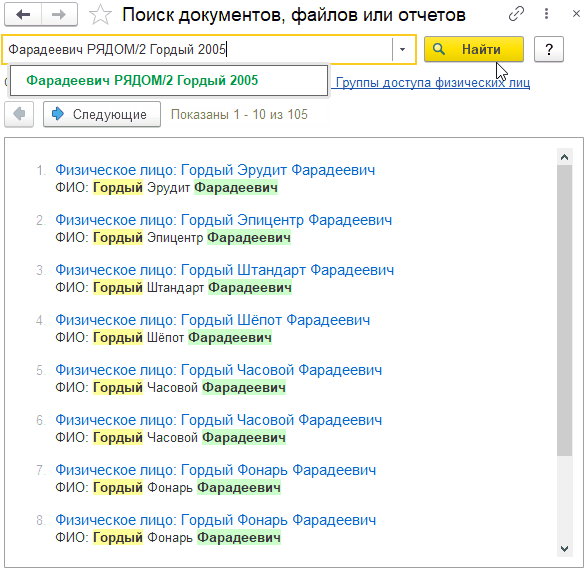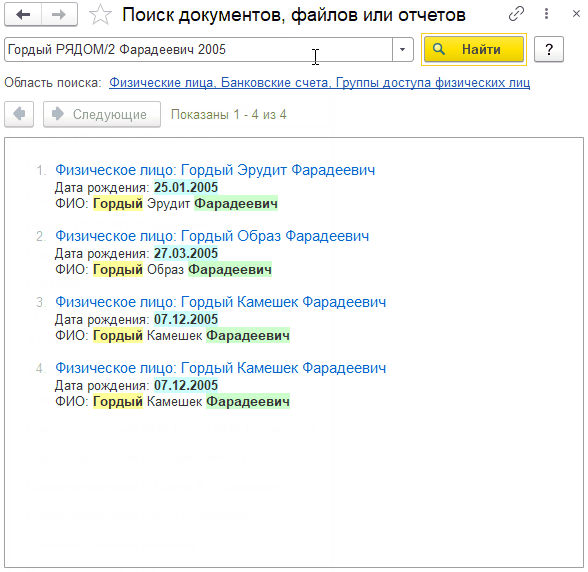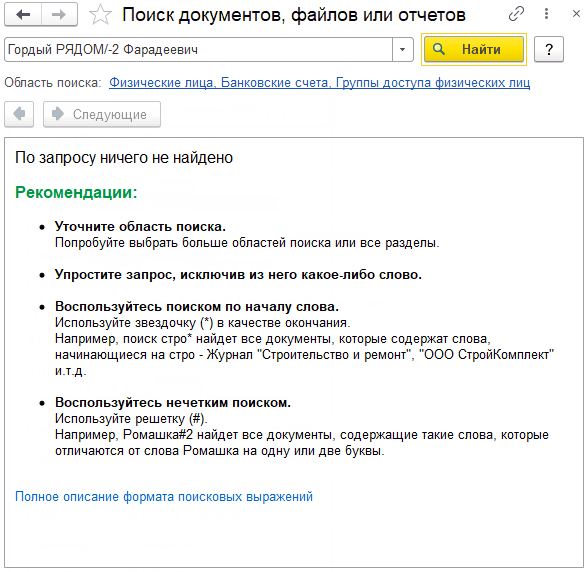
Оператор РЯДОМ/n (NEAR/[+/-]n) - позволяет выполнять поиск указанных слов в одном реквизите с учетом морфологии и расстояния между словами. Расстояние задается с помощью параметра n, где числовое значение указывает дистанцию поиска слова, которое находится не более n слов от указанного. Например, чтобы найти всех физ. лиц с именем "Гордый" и фамилией "Фарадеевич" (ФИО хранится в наименовании, то есть в одном реквизите в нашем случае), нужно выполнить вот такой запрос:
Гордый РЯДОМ/2 Фарадеевич
при этом этот запрос будет эквивалентен:
Фарадеевич РЯДОМ/2 Гордый 2005
Мы найдем все объекты, где после слова "Гордый" через одно слово идет "Фарадеевич". При этом поиск выполняется как в левую, так и в правую сторону. Можно комбинировать поиск с другими операторами. Например, так мы найдем тех же физ. лиц, но с годом рождения 2005.
Гордый РЯДОМ/2 Фарадеевич 2005
Также этот оператор позволяет указывать направление поиска слов. Для это перед параметром n нужно указать знак + (для поиска после первого слова) или - (для поиска до первого слова). Изменим предыдущее выражение:
Гордый РЯДОМ/+2 Фарадеевич
Если же поставить знак -, то результат поиска будет пустым, т.к. нет подходящих записей.
Гордый РЯДОМ/-2 Фарадеевич
Оператор может быть полезен для более точного поиска данных.
Теперь мы можем перейти к другим операторам.
Точный поиск
В случаях, когда нужно найти текст по конкретной фразе, то можно указать это через двойные кавычки. Например, поиск по:
"Валун Сократович"
найдет все значения, в которых есть эта фраза целиком. Если же сделать поиск по:
"Сократович Валун"
то результат поиска будет пустым, т.к. нигде такой фразы не встречается.

Таким образом, если нужен поиск конкретной фразы, то этот оператор в помощь.
Группировка слов
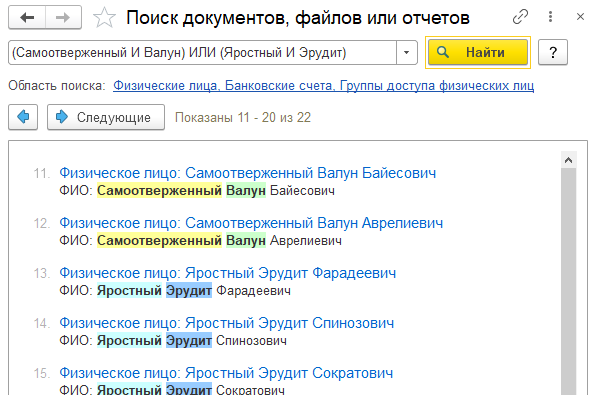
Отдельно стоит упомянуть возможность группировки слов с неограниченным уровнем вложенности с помощью скобок: ( и ). Например, выражение:
(Самоотверженный И Валун) ИЛИ (Яростный И Эрудит)
найдет все объекты, в текстовом содержимом которых есть вместе слова "Самоотверженный" и "Валун" или "Яростный" и "Эрудит". Очень полезно для сложных условий поиска.
 Идем дальше.
Идем дальше.
Групповой символ
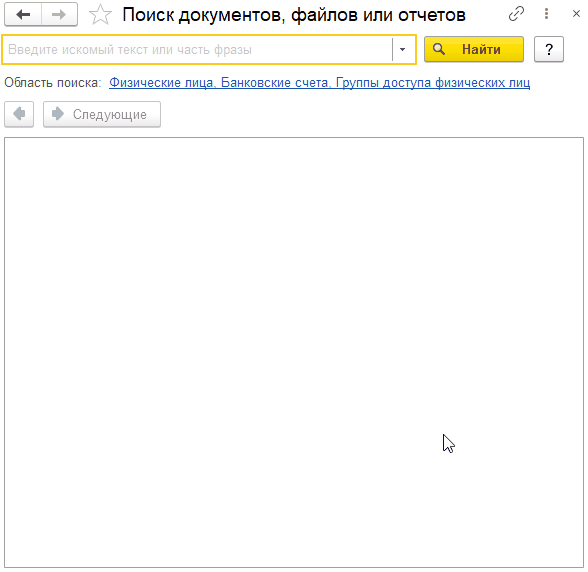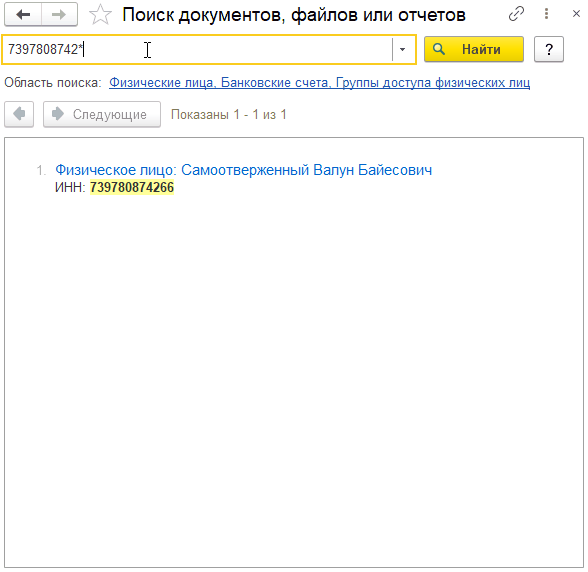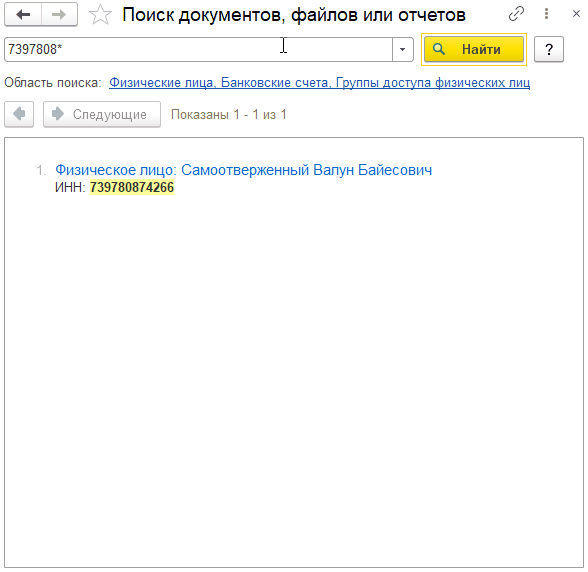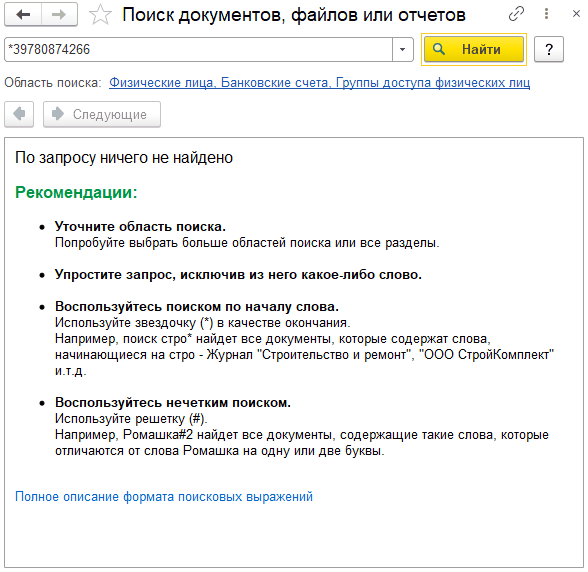
Групповой символ * используется для поиска по началу строки. Например, есть физ. лицо с ИНН 739780874266. Его можно найти явно, указав ИНН, или с помощью выражений:
7397808742*
или
7397808*
или
739780*
Чем меньше значащих символов в начале строки, тем больше подобный поиск может найти данных. А вот такое выражение, как Вы уже поняли, вообще ничего не найдет:
*39780874266
Поиск по началу строки часто может быть очень эффективным инструментом поиска данных.
При использовании этого оператора может быть найдено огромное количество слов, поэтому в платформе 1С реализовано ограничение: максимальное количество слов для группового поиска равно 300.
Следующий!
Еще кое-что
Оператор ~ - нечеткий поиск слов с указанным количеством отличий (по умолчанию равен 1).
Здесь приведу пример из синтаксис-помощника. Например, запрос "~Система" найдет "систама", "сивтема", а запрос "Система~2" найдет "ситтама", "сеттема".
При использовании этого оператора может быть найдено огромное количество слов, поэтому в платформе 1С реализовано ограничение: максимальное количество слов для группового поиска равно 300.
Также движок полнотекстового поиска поддерживает оператор ! - поиск с учетом синонимов. Опять же пример из синтаксис-помощника: поиск "!красный кафель", найдет еще и "алый кафель" и "коралловый кафель".
Еще добавлю, что в корне конфигурации можно настраивать дополнительные словари полнотекстового поиска. Но все это уже другая история.
Кстати, в платформе 8.3.16 добавился поиск с помощью индекса ППД по хештегам (строки вида #Слово, от символа # до первого пробела). Еще не приходилось использовать на практике.
Все это достаточно специфические возможности и на моей практике их приходилось использовать очень редко. Если вообще приходилось.
Подводные камни
Вот так, от вопросов обслуживания и настройки полнотекстового индекса, проблем его использования в самом распространенном кейсе и до вопросов разработки и особенностей работы мы прошли небольшой путь. Так были затронуты почти все вопросы, связанные со штатным механизмом полнотекстового поиска платформы 1С. Но это еще не все!
При работе с ним можно встретиться с некоторыми подводными камнями, о которых стоит знать заранее:
- На работу полнотекстового поиска влияет как версия платформы 1С, так и режим совместимости конфигурации. Подробнее об изменениях проще всего узнавать в официальном описании изменений. Вот, например, список всех изменений до версии 8.3.17. Поэтому старайтесь отказываться от режима совместимости и переходить на новые версии платформы 1С, если полнотекстовый поиск важен для Вас. Таких особенностей очень много. Вот некоторые:
- Начиная с версии 8.3.7 работа полнотекстового поиска подверглась значительным оптимизациям. По опыту приходилось переводить информационную систему с версии 8.3.6 на 8.3.12. Время перестроения индекса ППД изменилось с 18 часов до 3. Это было удивительно :)
- Если у Вас платформа 8.3.12, а режим совместимости 8.3.4, то отбор по области поиска (по объектам метаданных) не будет работать и Вы будете получать всегда пустой результат. Если режим совместимости отключить, то все работает как надо.
- Также при включенном режиме совместимости может некорректно работать сам поиск. Например, он будет искать только по буквам, игнорируя цифры.
- И многие другие "фишки".
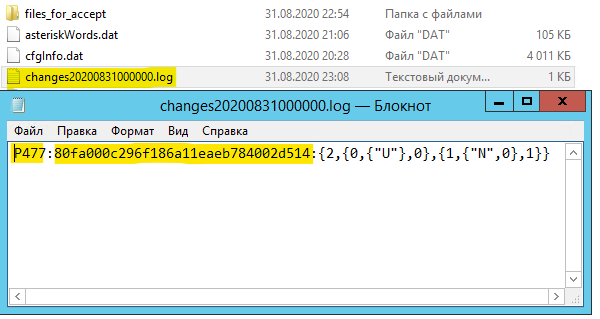
- При переходе с одной версии платформы на другую желательно полностью перестраивать индекс ППД. А иногда даже необходимо удалить файл "cfgInfo.dat" в каталоге "1Cv8FTxt", чтобы полнотекстовый индекс перестраивался с учетом новых функций. Об этом периодически пишут в описании изменений.
- От некоторых проблем не спасает даже перестроение индекса ППД. Например: одна и та же конфигурация, одна версия платформы, но разные сервера. На одном сервере полнотекстовый индекс работает корректно, а на другом нет. Единственным отличием было - настройка региональных стандартов на сервере. На проблемном сервере не было русского языка. Внезапно проблема пришла откуда не ждали.
- Были случаи, когда из-за внезапной перезагрузки сервера (внезапной для сервера 1С) индекс полнотекстового поиска приходил в негодность и переставал работать. Полное перестроение решало проблему.
- Напомню про проблему работы динамических списков с полнотекстовым поиском.
- При очень интенсивном изменении данных в системе, регламентное задание обновления индекса ППД может существенно нагружать систему. Особенно если информационных баз на сервере много, при этом в каждой это задание включено. Представьте - 10 баз и в каждой раз в 60 секунд обновляется индекс. Есть ли на это свободные ядра процессора(ов)?
- В старых версиях платформы можно было отключить индексирование для реквизита "Ссылка", после чего полнотекстовый поиск для объекта переставал работать.
- Бывают ситуации, когда понять проблему работы полнотекстового индекса невозможно. Он просто не работает и все. А нормальных средств диагностики просто нет. Тут поможет только метод "тыка".
- И другие особенности уже более мелкого масштаба.
В общем, полнотекстовый поиск полезен, но нужно быть готовым к решению проблем.
Вместо заключения
Это вторая публикация в серии статей про полнотекстовый поиск, в которой был сделан упор на вопросы разработки и использования индекса ППД и связанные нюансы его работы. Немного поговорили и о сопровождении. Подведем итог и соберем основные плюсы и минусы штатного механизма полнотекстового поиска.
Плюсы:
- Простота использования.
- Элементарные настройки, с которыми разберется каждый.
- Широкие возможности поиска данных.
- Кроссплатформенная реализация, не привязанная к какой-либо СУБД.
Минусы:
- Низкое качество и скудные возможности инструментов диагностики работы.
- Очень ограниченные настройки как для разработки, так и для сопровождения.
- Недостаточная производительность для высоконагруженных систем. Требуются различные хитрости.
А что Вы думаете о штатном полнотекстовом поиске?
В следующих статьях мы подробней поговорим о производительности полнотекстового индекса и практические примеры его использования в рамках оптимизации производительности. Рассмотрим несколько кейсов его применения в рамках highload (да, такое возможно).
Для Вас интересны темы по разработке на платформе 1С и связанные темы по разработке, администрированию? Присоединяйтесь в Telegram-канал, где будет появляться информация о моих новых статьях и разработках на Инфостарт, выходу обновлений, а также некоторые материалы по не1Сной тематике (СУБД, мониторинг, C# и кое-что другое).
Часть материалов, не подходящих сюда по темам, будут выходить на сайте. Там же можно ознакомиться с полным списком разработок для 1С. Думаю, что будет интересно.
Другие ссылки
Авторские разработки (все разработки на одной странице)
-
Транслятор запросов 1С в SQL - инструмент для трансляции запросов платформы 1С в SQL, а также их диагностики.
-
Просмотр и анализ структуры базы данных (отчет на СКД) - отчет для просмотра и анализа структуры базы данных с поддержкой файловых баз (ограниченный режим), а также баз на SQL Server и PostgreSQL.
-
Просмотр и анализ журнала регистрации (отчет на СКД) - отчет на базе системы компоновки данных (СКД) для просмотра записей журнала регистрации.
-
История работы пользователей (отчет на СКД) - отчет для просмотра истории работы пользователей (СКД, просмотр для любого пользователя).
-
Экспорт журнала регистрации. Набор инструментов (приложения + исходный код) - набор инструментов для экспорта данных журнала регистрации во внешние хранилища для Windows и Linux. Готовые приложения и исходный код.
-
Технические проверки данных регистров бухгалтерии (отчет на СКД) - отчет для технических проверок данных бухгалтерских регистров.
-
Путеводитель по истории релизов - отчет по истории выпуска релизов продуктов фирмы "1С" и анализа информации по обновлениям.
ТОП-6 инструментов для разработчика 1С
Подборка лучших инструментов для разработчика 1С включает Toolkit, DCT, OneDebugger, PrintWizard, DataFormWizard и Infostart MCP. Любой инструмент со скидкой 20% при покупке от двух решений.
Вступайте в нашу телеграмм-группу Инфостарт