Я хочу поговорить про DevOps – что это такое, зачем он вообще нужен, и почему он сейчас так популярен.
Все уже, наверное, видели этот знак бесконечности с делением на секторы Dev и Ops – это эмблема DevOps, которая в последнее время все чаще встречается.
Но зачем вообще нужен DevOps и действительно ли он необходим?
Давайте разберемся, какой смысл вкладывается в это понятие.
В русской Википедии дано следующее определение DevOps:
Методология активного взаимодействия специалистов по разработке со специалистами по информационно-технологическому обслуживанию и взаимная интеграции их рабочих процессов друг в друга для обеспечения качества продукта.
В то же время в англоязычной Википедии определение следующее:
Набор практик, направленный на сокращение жизненного цикла разработки систем и непрерывной доставки ПО на продуктивную среду, обеспечивающий высокое качество продукта.
Мне больше нравится иностранное определение, из него понятно что: DevOps необходим, потому что он помогает выпускать качественный продукт дешевле – мы быстрее поставляем качественный продукт, соответственно, мы завоевываем рынок.

Сложно ли внедрить DevOps?
На самом деле, DevOps сочетает в себе несколько разных процессов – это:
-
Coding (кодирование, контроль качества)
-
Building (сборка)
-
Testing (тестирование)
-
Packaging (подготовка релиза)
-
Releasing (утверждение релиза, развертывание)
-
Configuring (управление инфраструктурой)
-
Monitoring (мониторинг, работа с пользователями)
Всеми этими процессами мы, 1С-ники, так или иначе, занимаемся. Другое дело, что у нас эти процессы зачастую не автоматизированы (что-то автоматизировано, что-то – нет), но они присутствуют – может быть, не слиты вместе в единую систему. Мы пишем код, изучаем код других участников команды – независимо от того, есть ли у нас обязательная процедура code review. Мы все этим занимаемся.
Почему же сейчас тема DevOps стала так интересна?
Все курсы по DevOps, которые я смотрел, направлены на системных администраторов. Потому что если программисты для своего удобства уже что-то автоматизировали, то у системных администраторов в этом плане тяжело – они вынуждены настраивать кучу разного ПО, особенно, если их работа касается администрирования веб-проектов (Apache, Nginx, Gzip, MySQL). Все это со своими настройками, изменилась версия продукта – нужно все это переставить, поставить что-то другое. У них может использоваться 15 - 20 продуктов, и если ошибиться в версии какого-то из них - все упадет, а может быть и нет. Поскольку для них это очень критично, их этому и обучают. Поэтому все курсы по DevOps, в основном – это автоматизация деятельности сисадминов.
Но все те же самые практики автоматизации рутинных действий можно использовать и для разработки в 1С, несмотря на то, что раньше это было не принято. Мы привыкли, что фирма «1С» загнала нас в рамки своей функциональной платформы, и мы работаем только в этих рамках, не оглядываясь на другие технологии – нам для всего хватает нашего маленького желтого круга. Но сейчас эти границы уже начинают расширяться.
Обзор бесплатных инструментов
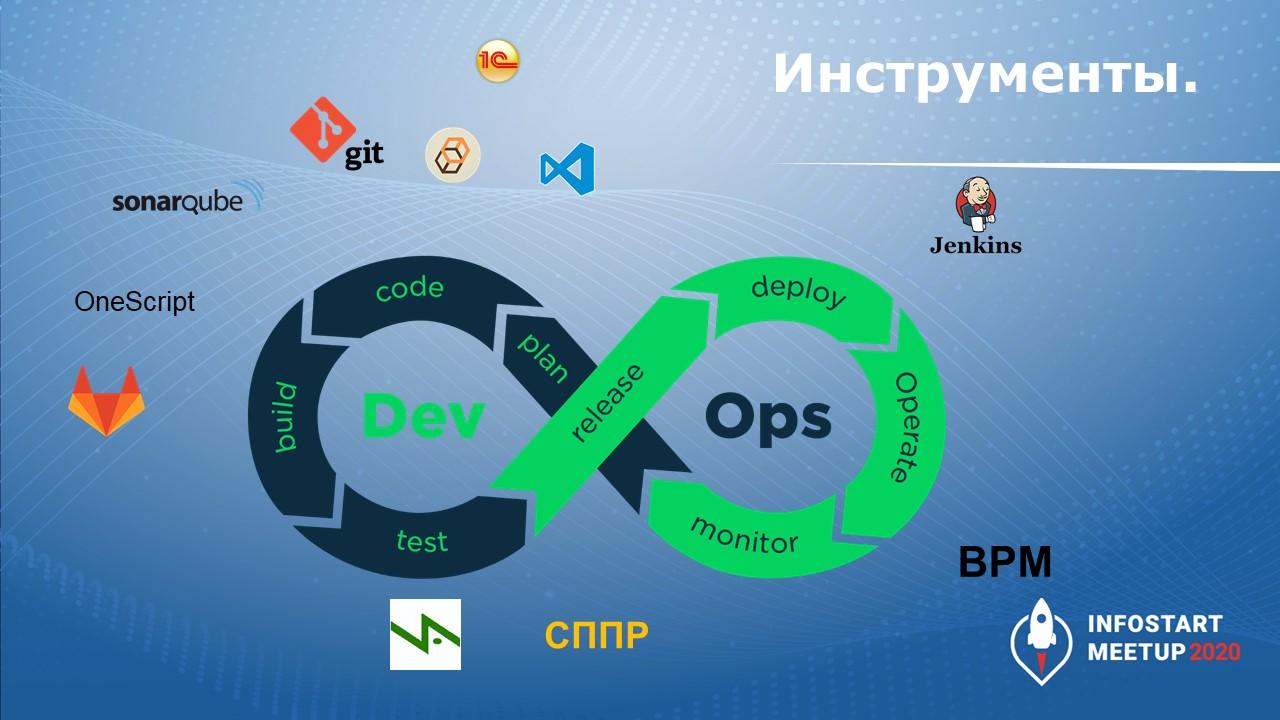
Что мы сейчас используем у себя в компании, чтобы автоматизировать процессы разработки, чтобы мы могли сказать, что у нас есть DevOps, и мы этим занимаемся.
Coding (кодирование, контроль качества)
Разработка – это:
-
Конфигуратор 1С. Одна из наших систем, самая большая, все еще там, потому что она слишком часто обновляется и требует последней версии платформы.
-
Еще есть EDT, на которой по всем своим проектам работаю я, но она кушает достаточно много ресурсов. На моей рабочей машине она работает хорошо, но для этого, пришлось поставить 32 Гб оперативной памяти и SSD. Еще год назад фирма «1С» сказала, что такое количество оперативной памяти – это стандарт рабочего места для программиста.
-
В качестве системы контроля версий фирма «1С» нам предлагает хранилище конфигураций. Это функционально, работает, помогает организовать команду, но есть сложности:
-
Если мы хотим узнать, кто поменял эту строчку кода и что там было до изменения – значит, здравствуй, история! А если история большая, то это будет длительное общение.
-
Если мы хотим доработать процедуру в модуле, с которым работает другой наш коллега (это две разные процедуры в одном модуле), мы ждем, когда он закончит свою задачу, он все это поместит, мы это получим, удивимся и начнем дальше дорабатывать. Мы начинаем ждать, у нас появляются какие-то линии ожиданий. И задача бегает из статуса в статус, но по ней ничего не делается.
-
Либо если мы хотим что-то доработать дома, мы должны выгрузить cf-файл, принести домой – развернуть базу, развернуть cf-файл, начать с ним работать, потом принести обратно, сравнением/объединением загрузить. Если конфигурация большая – это тоже сомнительное счастье. Проще у сисадминов выбить удаленный доступ.
-
-
Какая есть альтернатива? Можно переходить на Git. При этом если мы перейдем на Git даже в минимальном варианте (просто будем выгружать туда историю хранилища), то, продолжая разрабатывать через хранилище, мы уже получим хорошую историю, разбитую по коммитам. И когда мы будем открывать исходники конфигурации на сервере GitLab, мы уже сможем узнать, кто, когда поменял какую строчку, и увидим в качестве комментария коммита то сообщение, которое написал в конфигураторе автор этого изменения. Соответственно, расследование проблем будет происходить намного быстрее.
-
Кстати, по поводу разработки на EDT – когда вы разрабатываете на EDT, 1С хранит конфигурацию в виде набора файлов, среди которых есть – BSL-файлы (это код модулей) и куча XML-файлов, в которых хранится структура, формы и т.д. Там огромное количество папок. Конфигурация КА, выгруженная в файлы, занимает порядка 10 Гб. Из плюсов – вы можете редактировать модули конфигурации не только с помощью EDT, но и из VS Code, потому что в нем тоже много инструментов для работы с текстом модулей. Можно даже не запускать EDT, а править текст модуля в VS Code и коммитить прямо оттуда. Это быстро и удобно. Потом достаточно будет только запустить тестирование, и если тесты прошли, значит, все хорошо.
-
На следующем этапе мы должны проверить качество кода, который мы написали. Я программирую уже 15 лет и всегда думал, что я молодец и пишу код хорошо. Но я смотрю в SonarQube – я не молодец. Все наши договоренности о том, как писать код (как ставить запятые, пробелы, черточки, чтобы все это легче читалось) – это все работает только на бумаге, и в реальности мы получаем совсем не тот код, который мы ожидали. Но если мы проводим ревью кода – мы тратим время, тратим нервы, и мы никак не делаем команду сильнее. Когда твой сосед тебя контролирует и тебя критикует (даже если по делу) – это не команда, потому что все равно накапливается какое-то психологическое противостояние, которое нас отдаляет друг от друга. Это нехорошо. Поэтому пускай проверяет машина – кто будет обижаться на машину? Машина проверяет, мы видим метрики, у нас появляется какая-то история. У SonarQube есть бесплатный плагин для проверки качества кода 1С – на моей машине он спокойно проверяет код КА за 10 минут. АПК эту же КА проверяет несколько часов. Получается, что, запустив проверку в SonarQube, я очень быстро получу ответ – пройден порог качества или нет, хорошо мы написали код в этот раз или плохо. Плюс у меня есть история в цифрах – как развивался мой проект – становился хуже или лучше. А для руководителя цифры важны тем, что есть объективная метрика – он не просто молодец, а он молодец, потому что было 18, а стало 8 – он стал меньше косячить.
Building (сборка)
Обратите внимание, здесь на схеме есть еще значок OneScript – это реализация виртуальной машины 1С, которая позволяет вызывать все команды по работе с конфигурацией (выгрузки базы, сборки релиза и т.д.) с помощью скриптов, написанных на языке 1С. Они работают как обычные батники или скрипты vbscript, но при этом написаны на понятном каждому 1С-нику языке.
Проект OneScript разрабатывается сообществом – любой, кто знает C#, может придумать какую-то новую фишку и реализовать ее в этом решении.
Скрипты, написанные на OneScript, мы используем для сборки и тестирования нашей конфигурации, которая происходит автоматически на сервере GitLab – там же, где мы храним исходники кода. Все изменения, которые мы сделали в коде, отправляются в репозиторий, и сразу после коммита запускается сборка.
Проекты для себя я собираю с помощью GitLab runner. Я что-то написал, запушил, он собрал – у меня появилась тестовая база, в ней запустилось тестирование, и результат этого тестирования я вижу в логах сборки.
Testing (тестирование)
Для тестирования мы используем Vanessa Automation в связке с СППР. В ней мы храним структуру конфигурации и туда же добавляем скрипты тестирования. Там их удобно настраивать и можно комбинировать – написать скрипт, добавить несколько разных сценариев, и СППР будет их запускать.
Packaging (подготовка релиза) и Releasing (утверждение релиза, развертывание)
Для подготовки cf-ника и загрузки его на рабочую базу мы используем Jenkins – это менеджер, который запускает задачи по какому-то расписанию. У него свой скриптовый язык, он запускает задачи и отчитывается, где у нас проблемы.
Monitoring (мониторинг, работа с пользователями)
Мониторинг (контроль того, что, где, как сломалось) – это те же замеры производительности, контроль серверов и т.д.
Дальше идет оперативная деятельность – это работа с пользователями. Здесь мы работаем в нашей внутренней системе по учету заявок, которая называется BPM.
И дальше процесс опять идет по кругу – мы опять планируем свою деятельность, потом пишем код, пытаемся протестировать и т.д.
Особенности инфраструктуры
Обратите внимание, что процессы deploy (он же Releasing) и build должны быть, по сути, одинаковыми:
-
На этапе deploy мы готовим cf-ник, который загружаем на рабочую базу, стартуем базу, и запускается процедура обновления.
-
На этапе build происходит то же самое, только производится загрузка базы на эталонную, после чего на эталонной базе прогоняются тесты. Получается, что тесты – это не только скрипт, но и проверка, создалась ли база, обновилась ли она, нет ли здесь ошибок. Соответственно, тестировать надо на такой же инфраструктуре, что у рабочей базы – хотя бы приблизительно. Нельзя тестировать на файловой базе с платформой 8.3.16, если на продуктиве у вас клиент-сервер с платформой 8.3.13– возможно, вы что-то не протестируете.
Кстати, по поводу выгрузки в XML-файлы. Возможность выгружать модули из базы появилась у конфигуратора в версии 8.0.10 – релиз с этой возможностью состоялся 31 марта 2005 года. Да, эта выгрузка была не полноценной и выгружались только модули и справочная информация, а не вся конфигурация, как сейчас. Но платформа уже тогда была готова к тому, чтобы не отрываться от остальных языков разработки – все понимали, что это нужно, что сообщество будет это использовать. И в статьях 2007-2008 года я видел, что люди уже использовали системы контроля версий для ведения разработки (правда, тогда еще использовался не Git, а другая VCS). Там описывался процесс разработки без хранилища – именно путем выгрузки модулей в файлы.
Начало работы: какие могут возникнуть проблемы и сложности

Как проще всего начать применять DevOps-практики
-
Поставить SonarQube. Это система, у которой есть бесплатная Community-версия. Ставится достаточно просто. Вы можете поставить ее себе на локальный компьютер и просто проверить качество кода на своем проекте – выгрузить конфигурацию в xml руками и батником запустить проверку. Я не призываю вас сразу запускать проверку ERP, потому что, чтобы проверить КА, мне пришлось отдать Java-машине 24 Гб, а ERP будет требовать еще больше оперативной памяти. Но какие-то небольшие проекты можно проверять – просто чтобы узнать, что такое автоматизированная проверка качества. Потому что об этом можно говорить много, но, пока не потрогали руками, не понятно, что же это такое. Поставьте SonarQube на своей машине, посмотрите, что это такое – вас это ни к чему не обязывает.
-
Следующим шагом – поставить GitLab. На Windows он не ставится, поэтому придется развернуть виртуальную машину. Но мы же в 21 веке – есть много инструкций, как развернуть виртуальную машину на базе Ubuntu, это все достаточно просто делается.
-
Дальше – поставить OneScript, С ним будет проще писать, по нему тоже очень много информации – и есть уже готовые скрипты, которые помогут проще выгружать.
-
Установить Git, создать репозиторий и выгрузить в него историю изменений хранилища конфигурации с помощью GitSync (пакета для OneScript). Да, это будет не быстро, потому что выгрузка в Git происходит следующим образом – он берет версию хранилища, выгружает в cf-файл, этот cf-файл загружается в новую созданную базу, оттуда выгружается в XML файлы. Там много шагов, и, если база большая, это, конечно, займет время, но можно будет посмотреть, что такое Git, как выглядит история вашей разработки в Git. Опять-таки, мы пока не меняем базы, не меняем среду разработки, мы просто пробуем.
-
Следующий шаг – скачать Vanessa Automation. Она поставляется в двух вариантах – как единая обработка (в варианте Single) и как комплект обработок. Скачайте VA в варианте Single, запустите и посмотрите, что такое тестирование – как оно работает, что оно умеет. Может быть, это заменит ваших тестировщиков, которые просто прокликивают сценарии использования по вашим доработки, проверяют, открываются ли формы. Может, это просто нужно сделать, чтобы не было проблем, чтобы все гарантировано стартовало. Причем, VA – это тоже фреймворк, который разрабатывается сообществом, вы тоже можете его дорабатывать. Например, когда мы разговаривали с Леонидом, мне было интересно что-то сделать, я предложил: «А давай Vanessa будет несколькими голосами говорить одновременно», он обрадовался: «Давай, сделай!». Я сел и дописал – любой из вас может любую свою идею не просто предложить, а еще и самому реализовать. Почему нет? Протестировали – опять, мы не меняем базу, мы не меняем среду разработки, мы просто посмотрели, что такое тестирование, с чем его едят, а может быть, и отдали нашим тестировщикам, чтобы они наконец-то начали тестировать быстро – не по полгода, не брать на это 8 часов из спринта, а тестировать за час-два.
-
Следующий шаг – организовать автоматический запуск скриптов. GitLab у нас уже есть, и мы просто попробуем сделать так, чтобы GitLab нам что-нибудь автоматически запускал – ту же проверку в Sonar. У GitLab есть GitLab CI, который позволяет запускать скрипты – можно посмотреть, что такое CI, и попробовать поработать с ним, написать батник, который будет вызывать Sonar в нужный момент сам. Простейший код по автоматическому запуску у меня дальше в докладе будет, я покажу, как это.
-
И последний шаг – если позволяет компьютер, поставить все-таки EDT и попробовать разрабатывать в ней. Когда я начал работать в EDT, мне поначалу было очень непривычно, но потом я оценил ее достоинства. У нее есть хорошая темная тема – нет ничего белого, все шикарно, глаза не так устают.
Разработка через хранилище 1С
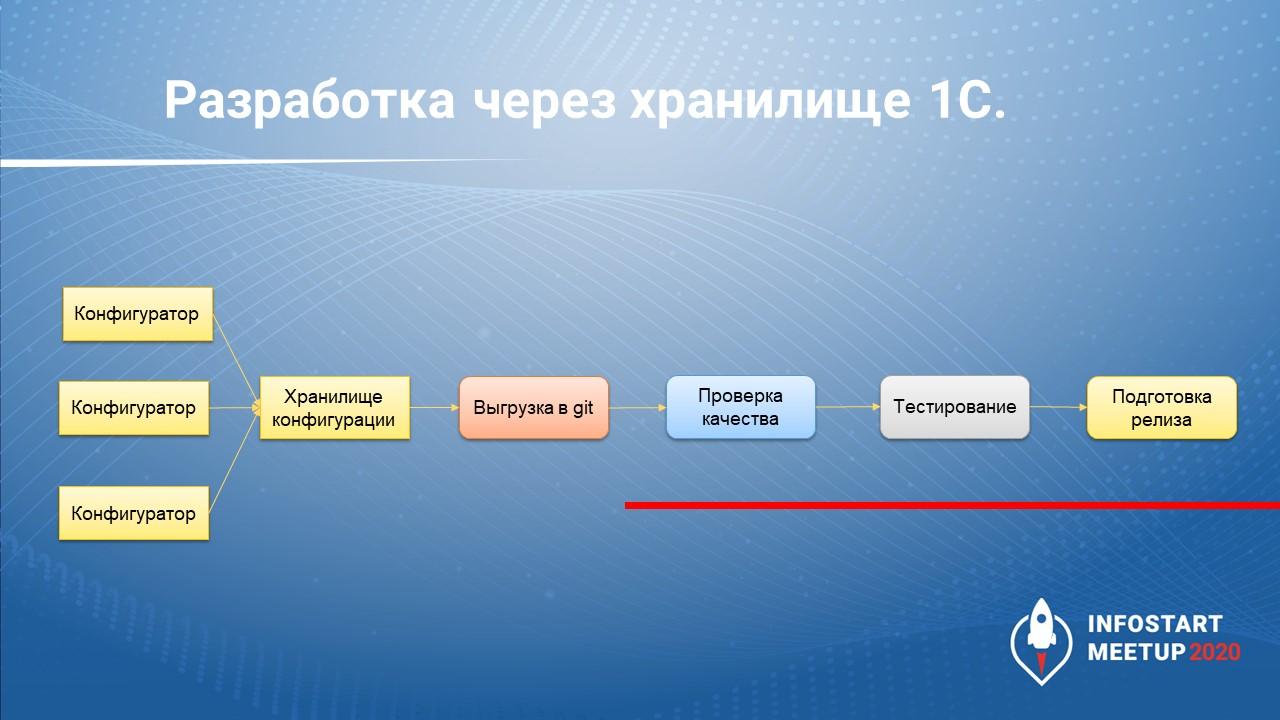
Как выглядит разработка через хранилище? Это ситуация, когда мы не трогаем наших разработчиков – они привыкли разрабатывать в хранилище, и мы их не тревожим.
-
Мы просто выгружаем хранилище в Git с помощью GitSync и уже имеем полноценную историю.
-
Кроме этого, так как у нас база уже в виде файлов, мы проверяем качество кода – уже можем сказать, где есть проблемы. Например, SonarQube может помочь отследить:
-
Одинаковые условия – кто-то копипастом добавил в ИначеЕсли одинаковые условия. Глазами такие места можно пропустить, а SonarQube это покажет, потому что во втором условии нет смысла.
-
Повторяющиеся функции – вы в нескольких разных модулях написали одну и ту же функцию, все хорошо. Когда вы захотите ее поменять – вам нужно будет зайти в пять модулей и поменять пять функций. При этом вы можете не знать, что где-то есть шестая такая же функция. А SonarQube покажет, что таких функций у вас шесть, и предложит это исправить.
-
-
Дальше – тестирование.
-
И подготовка релиза по тому коммиту, по тому срезу, который прошел тестирование и действительно может быть поставлен на рабочую базу.
Разработка через Git
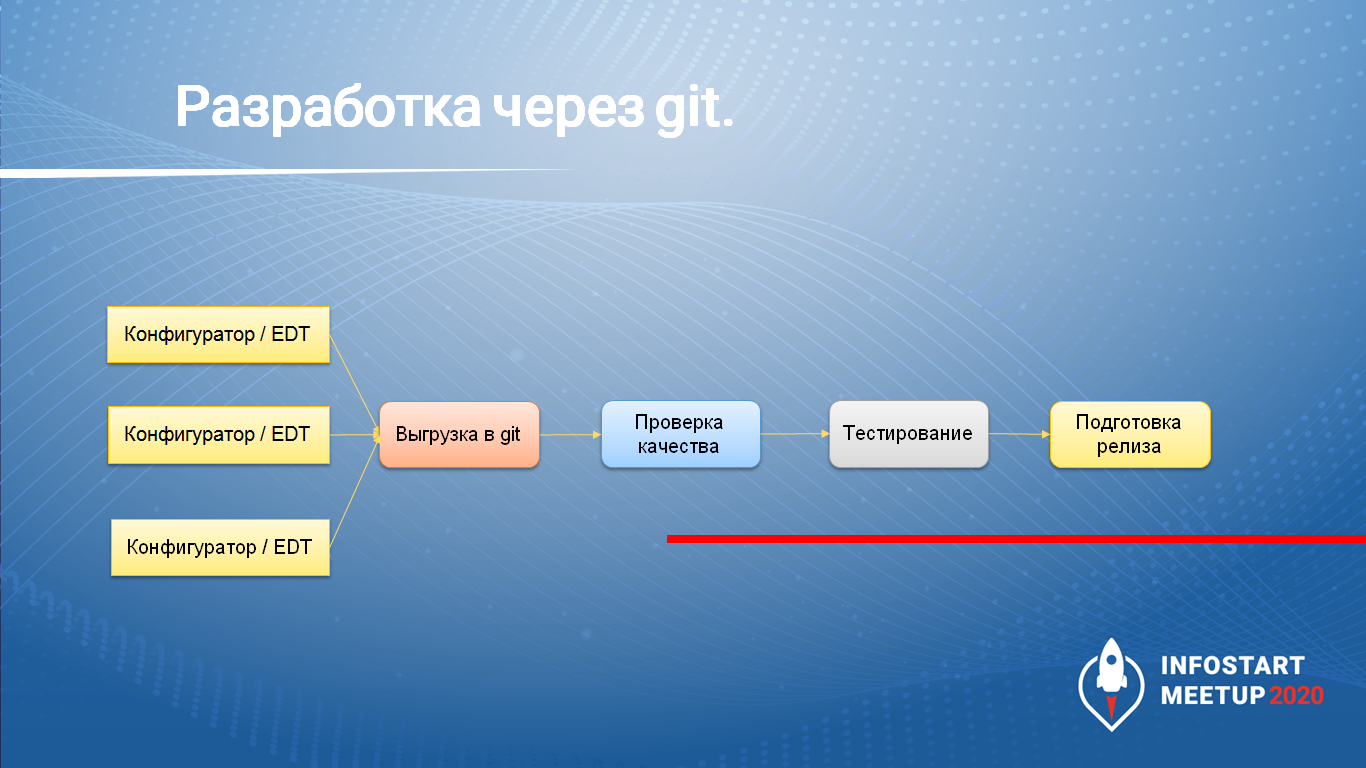
Либо же мы можем разрабатывать сразу с использованием Git, не используя хранилище.
При этом мы можем работать как в конфигураторе, так и в EDT – никто не запрещает нам в этом случае работать в конфигураторе. Но нужно выбрать только что-то одно, потому что структура хранения файлов у EDT и конфигуратора разная.
В EDT все просто – там мы сразу работаем с файлами, которые хранятся в репозитории. Разве что для загрузки конфигурации в базу мы должны дополнительно вызвать команду утилиты ring, чтобы преобразовать файлы из структуры, которая хранится в EDT, в ту структуру, которую понимает 1С.
А если мы работаем в конфигураторе, то просто после завершения работы выгружаем файлы конфигурации в репозиторий Git и точно так же идем по процессу дальше.
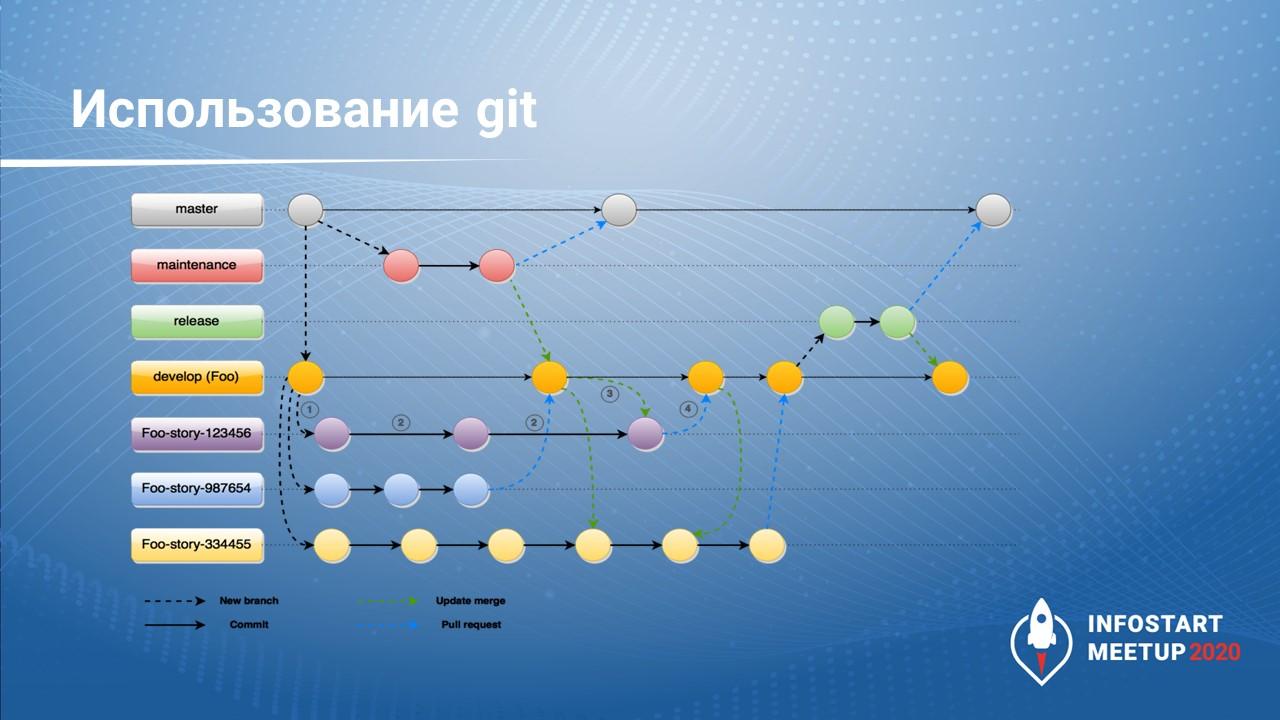
При работе напрямую с Git мы можем поделить нашу разработку на ветки по методологии Git-Flow. Тогда репозиторий по сравнению с выгрузкой из хранилища будет выглядеть иначе. Потому что когда мы выгружаем из хранилища, у нас есть одна ветка, и мы по ней идем, при этом каждый коммит в ветку - это событие помещения части объектов в хранилище конфигурации.
А когда мы разрабатываем по методологии Gitflow, у нас есть:
-
ветка master, в которой находится только рабочий код;
-
ветка maintenance для экстренного исправления багов – если что-то нашли, нужно срочно поправить;
-
ветка develop, в которую стекаются все изменения от разработчиков – в этой ветке проводится тестирование;
-
и ветки для разработчиков (либо по задачам).
Когда у нас появляется новая задача, мы создаем под нее ветку с файлами конфигурации, что-то в них меняем, потом проверяем наши изменения. Если за то время, пока мы работали со своей веткой, кто-то обновил своими изменениями ветку develop, мы помещаем эти изменения к себе, проверяем, что все работает, и только потом отдаем наши доработки.
При помещении доработок в ветку develop их опять нужно протестировать. Это очень важно, потому что даже если все разработчики протестируют изменения в своих ветках, может получиться так, что несколько человек одновременно написали одинаковую функцию или изменили одни и те же объекты, и эти изменения криво объединились, из-за чего на выходе система, работающая в ветках разработчиков, в ветке develop даст ошибку. Поэтому ветки разработчиков тестировать желательно, а ветку develop тестировать обязательно.
На базе протестированных изменений мы можем подготовить релиз – эти изменения мы загружаем в ветку master и подготовленным релизом обновляем продуктив.
Выглядит страшно, но когда начинаете этим пользоваться, кажется, что по-другому и нельзя.
Автоматизируй все: настройка GitLab CI
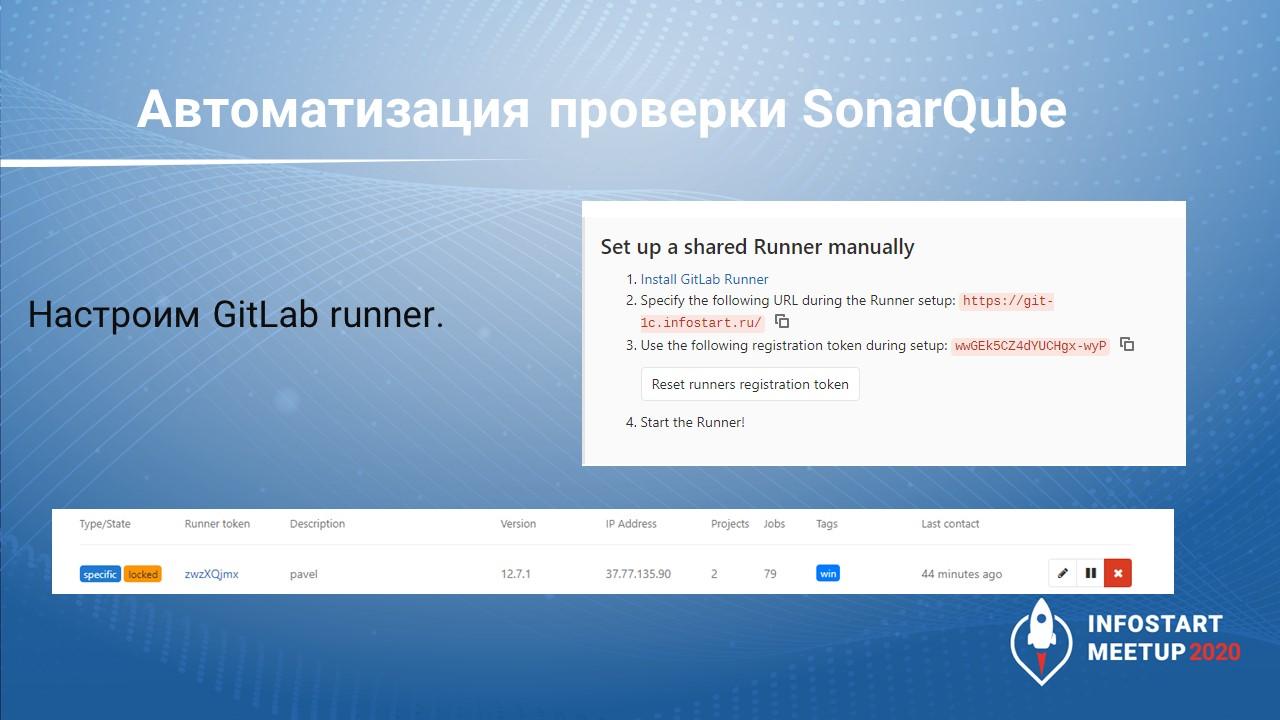
Теперь попробуем настроить GitLab runner, чтобы автоматизировать часть наших процессов.
Первым делом автоматизируем проверку с помощью SonarQube. Вручную эту проверку можно запустить в командной строке с помощью bat-файла, запускающего утилиту sonar-scanner. А мы хотим сделать так, чтобы этот bat-файл запускался с помощью GitLab runner.
Для этого нам в панели управления GitLab нужно посмотреть, как прописываются настройки для установки агентов Shared Runner.
Здесь нам подсказывают – скачайте GitLab Runner, зарегистрируйте его на следующий URL, укажите регистрационный токен и запустите.
GitLab Runner устанавливается как служба и работает на вашей машине.
Из важного – при регистрации нужно сразу прописать теги, по которым он будет искаться потом внутри скрипта.

Дальше – в папке проекта разместим файл настройки sonar-project.properties, в котором укажем:
-
где у нас находится SonarQube;
-
как у нас будет называться проект на SonarQube;
-
где у нас находятся исходные файлы;
-
и какие файлы будем включать – мы берем только bsl-файлы, другие нам не нужны, потому что мы не умеем проверять xml-файлы конфигурации (SonarQube не знает, как их проверять).
Также в папке проекта должен лежать файл check.bat, который будет запускать проверку, вызывая утилиту sonar-scanner (она скачивается с сайта SonarQube отдельно).
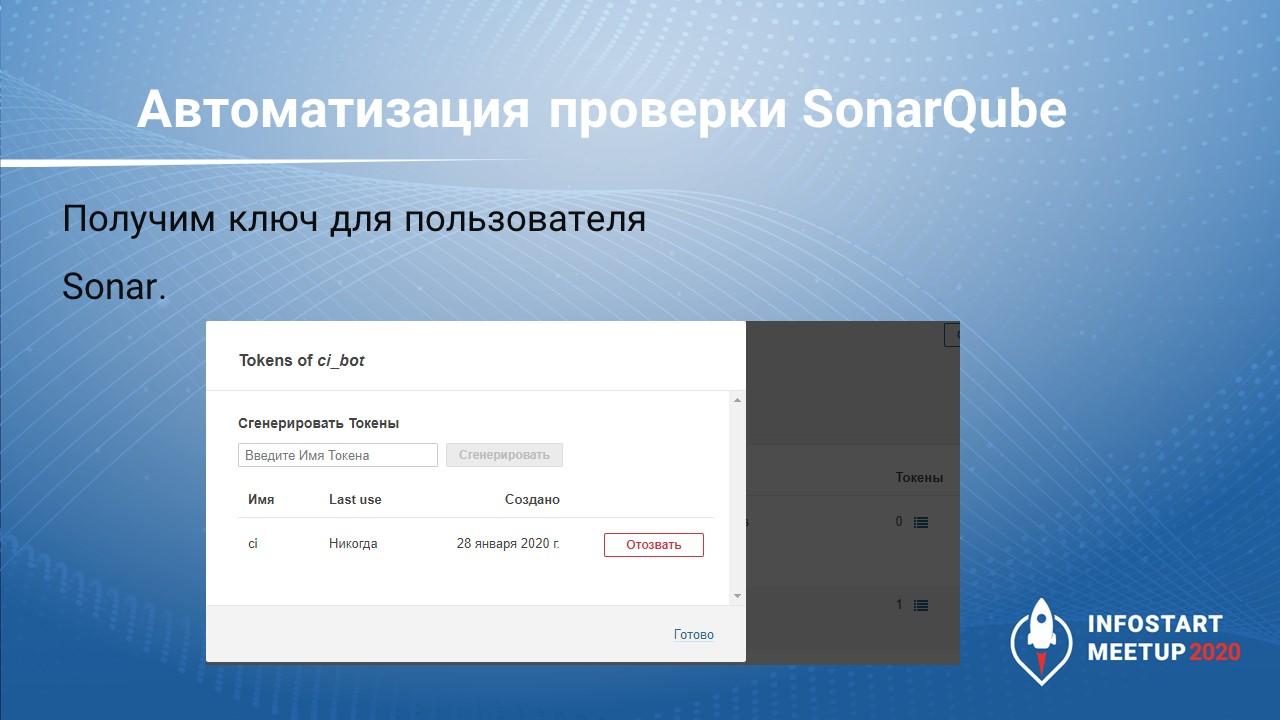
Чтобы авторизоваться на сервере SonarQube, нам нужно в списке пользователей для конкретного пользователя создать токен доступа. Он будет показан только один раз в момент создания. Больше его никак посмотреть нельзя, можно только отозвать.
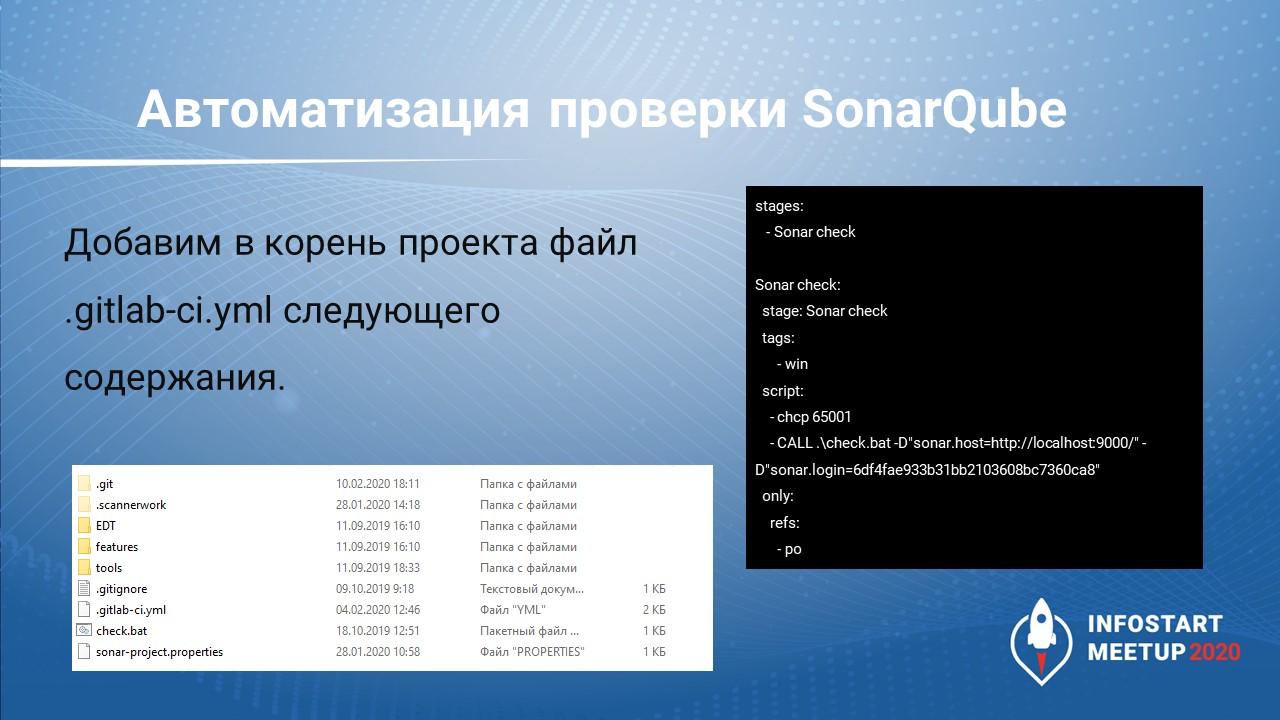
И последний шаг – в корень проекта мы добавим файлик .gitlab-ci.yml, где укажем настройки для запуска проверки:
-
создаем новый этап «Проверка сонаром»:
stages: -Sonar check -
говорим, что будем запускать этот этап только на runner-е с тегом win:
tags -win -
только в ветке с названием po:
only: refs: -po -
в самом скрипте пишем команду chcp 65001, которая переводит кодировку на UTF-8, чтобы мы могли прочитать логи, если там появятся ошибки;
-
и через обертку CALL вызываем батник check.bat с параметрами – адресом сонара и токеном, который мы получили у SonarQube.
Теперь, как только мы что-то помещаем в хранилище, отправляем на сервер GitLab командой push, стартует проверка, и через минуту у нас в SonarQube уже есть отчет о проверке того, что мы поместили в GitLab.

Добавим тестирование, напишем несколько сценариев.
На слайде показан пример сценария – это сценарий из тестирования базы для конференции, который создает новый город в справочнике «Города».
Сценарий тестирования написан на языке Gherkin – это универсальный человекочитаемый язык для написания сценариев.

Дальше – настроим файл VAParams.json для запуска тестирования с помощью Vanessa Automation из командной строки.
В описании репозитория Vanessa Automation https://pr-mex.github.io/vanessa-automation/dev/ есть информация о том, как такие файлы настроек должны выглядеть.
Мы здесь указываем параметры:
-
ИмяСборки
-
ВерсияПлатформы
-
ВыводитьСообщенияВФайл (в каком файле будут выводиться сообщения
-
КаталогПоискаВерсииПлатформы (где находится платформа)
-
СтрокаПодключенияКБазе (где находится база)
-
ПутьКVanessaAutomation (где находится сама обработка Vanessa)
-
КаталогФич (где находятся наши скрипты – сценарии тестирования)
Обратите внимание, что все слеши здесь должны быть заэкранированы, потому что иначе тестирование просто не запустится.

В gitlab-ci.yml добавляем еще один стейдж – Test (секцию Sonar check я со слайда убрал, чтобы не мешалась).
-
Тег у нее тоже win. Если вы не укажите конкретный тег, но при этом будете использовать несколько раннеров, то неизвестно, где этот стейдж запустится – неожиданно для вас он может запуститься на другой машине и сделать то, что не ожидает владелец той машины.
-
Также указываем, что мы тестируем только свою ветку (only refs po).
-
И в секции script указываем команду для запуска Vanessa Automation. Обратите внимание, что здесь у меня используются переменные, которые можно задавать в параметрах GitLab:
-
%Path1C% – чтобы не писать каждый раз путь к 1C;
-
%po_BaseDir% – место, где у меня находится основная папка, в которой лежит весь проект.
-
Соответственно, мы из основной папки запускаем Vanessa Automation и указываем ей путь к файлу настройки VAParams.json, который вы видели на предыдущем слайде.
Теперь каждый раз, когда мы будем пушить свои изменения в репозиторий на GitLab, наш код будет проверяться с помощью SonarQube, после чего будет запускаться тестирование, и мы можем в логах посмотреть – была ли у нас ошибка или все хорошо. Если все хорошо, значит, тот cf-файл, который сгенерировала система, работоспособен, эти изменения можно забирать.
Чем еще интересен файл gitlab-ci.yml?
-
Здесь может быть хоть 200 стейджей, но они будут разделены по тегам, по компьютерам, по веткам, и мы, грубо говоря, в одном файле можем иметь скрипты для всех наших веток, которые используем.
-
Если один из разработчиков захотел протестировать только свою часть – он указывает, что его файлы находятся в такой-то ветке, их проверять нужно с такими-то параметрами.
-
Так как все это представлено в одном месте, нам удобно делиться информацией, как что настраивается – если один уже написал, второй может легко воспользоваться.
-
А так как этот скрипт хранится в Git, для него ведется история – и, если где-то случайно допущена ошибка, изменения можно в любой момент откатить.
Вопросы:
-
Я так понимаю, что при автоматическом развертывании 1С на продуктив нельзя реализовать стратегию нулевого времени простоя (zero-downtime strategies). Но можно минимизировать простой, если использовать стратегию сине-зеленого развертывания (Blue/Green deployment), когда мы в определенный момент переключаем трафик пользователей на новую версию. Как вы поступаете с базой при автоматическом развертывании? Как вы ее готовите? Как в таких случаях поступать с достаточно большими, терабайтными базами?
-
Могу сразу сказать – у нас есть время, когда мы можем обновить базу. У нас нет терабайтной базы, на терабайтной базе мы этого не тестировали. Когда у меня была огромная база, у нас было окно – в неделю у нас было 5-6 часов, когда мы ее обновляли. Вариантов больше не было.
-
То есть сейчас до конечных пользователей вы доставляете изменения вручную? Скорее всего, вы прикидывали, как именно можно автоматизировать доставку конечного продукта?
-
Мы не обновляем КА автоматически, потому что мы хотим, чтобы наша компания спокойно сдала отчетность. Когда отчетность будет сдана, мы продуктивную базу тоже начнем обновлять автоматически по расписанию. Но пока только в ручном режиме.
-
А если приходит бухгалтер и говорит: «Мне очень срочно нужно внести правки в конфигурацию», как у вас получается не отступать от CI/CD процесса?
-
А зачем не отступать? Если это реально срочно и реально нужно прямо сейчас? Нас же никто не неволит – мы можем сделать шаг в сторону, сделать эту правку, а потом внести ее в основной проект. Ситуации бывают разные – если это реально может подождать, то да, подождет. А если не может подождать, если нужно сдать отчетность сейчас – затем создавать напряженность там, где она не нужна? У нас и так тяжелые отношения с пользователями, у них часто завышенные ожидания. Не нужно усложнять себе жизнь.
-
В таком случае у вас появляется человеческий фактор, вы вносите правки не через CI-систему, а потом обязаны их докинуть в ваш основной репозиторий.
-
Жизнь сложнее, чем CI-система.
-
У меня вопрос по схеме разработки через Git. Как вы обновляете конфигурацию поставщика из cfu? Вы готовите свое обновление или же обновляете конфигурацию сравнением-объединением с поставкой 1С? Вы говорили, что разложили свою «Комплексную автоматизацию» на файлики, потом собираете из них cf, заливаете его в базу данных. Когда вышло обновление от 1С – что вы делаете дальше?
-
Обновления от 1С проще накатывать с помощью конфигуратора, потому что разбирать конфликты в сборке Git при обновлении конфигурации при глобальном изменении – это еще то веселье. Потому что он меняет слишком много модулей и разбирать это через текст сложнее, чем в интерактивном режиме через конфигуратор. Дело в том, что, когда изменения мержатся в конфигураторе, он показывает – было так, стало так. И это он добавляет в каждый файлик. Соответственно, ты должен зайти в каждый файлик и поправить – возьми вот это и вот то. Для больших объемов – это очень тяжело. Например, когда мы проверили КА с помощью SonarQube, эти 8 миллионов строк, у нас получилось порядка 70-80 тыс. замечаний. Причем, большая часть из них – это ложные срабатывания, потому что так написана платформа – это нельзя менять. Но это большой процесс.
-
Из личного опыта, когда я попытался через EDT внести правки в типовую конфигурацию, потом все это запихнуть в рабочую базу и накатить изменения с помощью cf-файла, мне вывалило кучу измененных объектов, которые я точно не менял. Будьте готовы, что у вас полезет структура сравнения/объединения.
-
Я EDT начал пользоваться с 13-й версии. До 15-й версии я страдал. Вышла 16-я версия – вроде стало легче. Может быть, они реально поменяли версию Java и что-то переписали, но глюков стало меньше. У меня перестал падать проект – он мог просто упасть и не встать. Приходилось заново выгружать КА, создавать новый проект, потому что он просто не оживает и часть кода теряется. После 16-й версии, по крайней мере у меня, такого больше не случалось, она работает.
-
Скажите, пожалуйста, как у вас реализован процесс тестирования – у вас разработчики проводят какие-то свои юнит-тесты, когда они интегрируют?
-
Так как у нас нет выделенных тестировщиков, у нас разработчики пишут тесты на то, что они написали, сами. Покрытие тестами мы не считаем.
-
А в момент подготовки релиза вы проводите полное регрессионное тестирование? Прогоняете все тесты, которые у вас есть?
-
Все тесты складываются в одну папку и оттуда запускаются. Пока у нас не так много доработок, чтобы нам понадобилось запускать для этого несколько потоков. Можно запустить в одном потоке и дождаться.
-
А вы для каждого теста подготавливаете среду отдельно, как рекомендуют сами разработчики? Или все тесты всегда выполняются на одной и той же базе?
-
Тесты в одной и той же базе – это неправильно. Если я сценарий «Создать город» запущу 10 раз в одной базе, у меня будет 10 одинаковых городов. Это будет не совсем красиво – я испорчу данные. У нас есть эталонная база, которая соответствует рабочей. Она отдельно подготавливается – обновляется из свежего cf-ника, на ней должен пройти весь процесс обновления от и до. А после обновления она сохраняется в dt-ник, который разворачивается в тестовую базу, где и запускается тест.
-
Вопрос про GitLab CI. У вас на слайдах еще был указан Jenkins. Получается, что у вас GitLab CI установлен на пользовательских машинах, а Jenkins запускает тесты уже где-то на сервере?
-
Просто мне понравился GitLab CI, потому что он легко запускается. Я себе его поставил и свою ветку проверяю с его помощью, а основная ветка проверяется с помощью Jenkins на сервере.
-
А где вы просматриваете результаты тестирования? Куда вы их выгружаете?
-
На сервере с Jenkins мы просматриваем результаты тестирования в Allure, а результаты тестирования в своей ветке я смотрю просто в логах, я не стал себе усложнять жизнь.
-
Весь мир заболел DevOps, когда вышла книжка «Проект Феникс». Там одна из фраз мастера, который направлял компанию на путь к DevOps, была такая: «Вы должны делать выкладки в рабочую базу несколько раз в день». Насколько вы приблизились к DevOps по этому показателю?
-
Я не согласен с этим. Выкладки несколько раз в день в рабочую базу для 1С ведут либо к динамическому обновлению, либо к постоянному выкидыванию из базы пользователей. Я не сторонник ни того, ни другого.
-
И второй вопрос – насколько вам удалось размыть эту грань между разработчиками и системными администраторами, чтобы упростить процесс коммуникации между ними?
-
Кстати, когда я объяснял методологию DevOps, я ничего не рассказал про «Инфраструктуру как код», потому что, когда мы включаем сисадминов в цикл разработки, они тоже становятся программистами – они пишут код, чтобы собрать контейнер, в котором запустится все остальное, и этот код тоже хранится в том же в репозитории. Получается, что помимо разработчиков 1С у нас появляются еще и разработчики-сисадмины, которые пишут свой код, и они тоже бегают по этой же восьмерке. Сейчас у нас нет своих серверов, мы их арендуем, и в данный момент ведем переговоры, чтобы арендовать мощности и разворачивать уже полноценные контейнеры – то есть разворачивать тестирование не в терминальном режиме, а с помощью контейнеров. Хотим сделать, чтобы все было хорошо и красиво. Обязательно, как только мы это запустим, мы и расскажем, и покажем, и предложим вам этим воспользоваться.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Krasnodar.


Вступайте в нашу телеграмм-группу Инфостарт
