Есть один секрет DBA, который всегда работает. Я узнал этот секрет на вебинаре, лично убедился в его эффективности и давно хотел сделать публикацию, но толчком послужило видео. Автор видео (и вебинара) – Виктор Богачев. Он занимается реальной просветительской деятельностью для тех, кто хочет расти и развиваться.
Для каждого видео стараюсь составлять короткий конспект: интервал в минутах и краткое описание. Так удобно искать, пересматривать избранные места.
0-3 Поиск недостающих индексов в представлении sys.dm_db_missing_index по фрагментам запроса
3-6 Покрывающий индекс, MS SQL Index include columns
6-9 Добавить непериодический регистр, создающий нужный индекс
9-12 Индексирование с дополнительным упорядочиванием
12-14 Пример соединения по полю "КлючСвязи"
В нашей базе поиск недостающих индексов мы проводим регулярно, запрос (почти) такой же как на видео.
SELECT TOP 10
[Total Cost] = ROUND(Stat.avg_total_user_cost * Stat.avg_user_impact * (Stat.user_seeks + Stat.user_scans),0),
Stat.avg_user_impact,
TableName = Detail.statement,
[EqualityUsage] = Detail.equality_columns,
[InequalityUsage] = Detail.inequality_columns,
[Include Cloumns] = Detail.included_columns
FROM sys.dm_db_missing_index_groups Groups
INNER JOIN sys.dm_db_missing_index_group_stats Stat
ON Stat.group_handle = Groups.index_group_handle
INNER JOIN sys.dm_db_missing_index_details Detail
ON Detail.index_handle = Groups.index_handle
ORDER BY [Total Cost] DESC;
Подробнее о MS SQL представлениях можно посмотреть в статье, первоисточником которой является наш знакомый вебинар и документация.
Последний пример актуален для всех, кто использует типовую конфигурацию УТ11, документы «ЗаданиеНаПеревозку» поэтому рассмотрим его подробнее, используя технологический журнал:
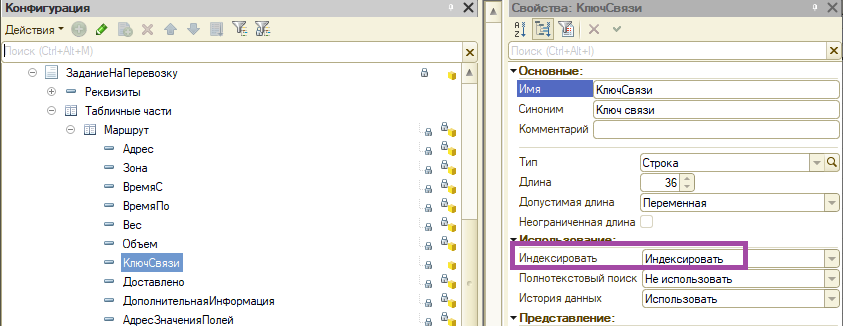
Шаг первый: С помощью функции ПолучитьСтруктуруДанных() найдем имя в СУБД поля «КлючСвязи», в нашей базе:
Имя таблицы хранения Имя поля хранения Метаданные
Document515.VT3776 Fld3784 Документ.ЗаданиеНаПеревозку.ТабличнаяЧасть.Маршрут.Реквизит.КлючСвязи
Document515.VT3788 Fld3790 Документ.ЗаданиеНаПеревозку.ТабличнаяЧасть.Распоряжения.Реквизит.КлючСвязи
С точки зрения 1С табличная часть – дочерний объект, поэтому в тексте запроса события SDBL пишется Document515.VT3788, а с точки зрения SQL – отдельная таблица, поэтому в тексте запроса события DBMSSQL пишется Document515_VT3788
При анализе недостающих индексов в MS SQL в нашей базе поле Fld3784 (КлючСвязи) попадало в TOP по стоимости.
Шаг второй: настроить logcfg.xml с отбором по содержимому запроса и планом DBMSSQL (Кстати, на сайте Infostart до сих пор не было примера настройки like property)
<?xml version="1.0"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log location="C:\Log\Logs\UT" history="24">
<event>
<eq property="name" value="DBMSSQL"/>
<like property="sql" value="%Fld3784%"/>
</event>
<property name="all"/>
</log>
<plansql />
</config>
Шаг третий: собрать и расшифровать технологический журнал до изменения
Описание числовых столбцов находится на ИТС:
- Rows
- Executes,
- EstimateRows,
- EstimateIO,
- EstimateCPU,
- AvgRowSize,
- TotalSubtreeCost,
- EstimateExecutions,
- StmtText.
Ниже фрагмент журнала, содержащий поле Fld3784 (КлючСвязи):
47, 49, 1, 0, 0.0542, 103, 1.69, 1,
Nested Loops(Left Outer Join, WHERE:([ut-main].[dbo].[_Document515_VT3788].[_Fld3790] as [T3].[_Fld3790]=[ut-main].[dbo].[_Document515_VT3776].[_Fld3784] as [T5].[_Fld3784]))
Поле Fld3784 (КлючСвязи) используется при соединении табличных частей, оператор Nested Loops, обработано 47 строк, загрузка CPU 0.0542, стоимость 1.69.
Контекст запроса Обработка. ГрафикТранспортаИСервиса.Форма.Форма.Модуль.ОбновитьСписокРаспоряженийНаДоставку
По контексту найдем запрос, фрагмент ниже:
Выбрать
...
ИЗ Документ.ЗаданиеНаПеревозку.Распоряжения КАК ЗаданиеНаПеревозкуРаспоряжения
ЛЕВОЕ СОЕДИНЕНИЕ Документ.ЗаданиеНаПеревозку.Маршрут КАК ЗаданиеНаПеревозкуМаршрут
ПО ЗаданиеНаПеревозкуРаспоряжения.КлючСвязи = ЗаданиеНаПеревозкуМаршрут.КлючСвязи
Одно условие соединения.
Шаг четвертый: Добавим индекс по полю Fld3784 (КлючСвязи), соберем журнал
План запроса изменился, фрагмент ниже
52, 52, 1.01, 0.00313, 0.000158, 33, 0.108, 35.9,
Index Seek(OBJECT:([ut-main].[dbo].[_Document515_VT3776].[_Document515_VT3776_1] AS [T5]), SEEK:([T5].[_Fld1420]=[@P3] AND [T5].[_Fld3784]=[ut-main].[dbo].[_Document515_VT3788].[_Fld3790] as [T3].[_Fld3790]) ORDERED FORWARD)
Поле Fld3784 (КлючСвязи) используется при соединении табличных частей, оператор Index Seek, обработано 52 строки, загрузка CPU 0.000158, стоимость 0. 108.
Контекст запроса Обработка. ГрафикТранспортаИСервиса.Форма.Форма.Модуль.ОбновитьСписокРаспоряженийНаДоставку
При сопоставимом объеме данных загрузка CPU уменьшилась в 343 раза, стоимость в 15 раз.
Конечно, не все запросы СУБД можно оптимизировать таким способом, но загрузка CPU уменьшается ощутимо. В моем случае, загрузка уменьшилась от 70 процентов до 40 процентов в пике. Просто не нужно покупать новый сервер.
Шаг пятый: используем штатный индекс табличной части. На нашем знакомом вебинаре я узнал: чтобы улучшить запрос, его нужно сделать более конкретным. Отключим созданный индекс по полю Fld3784 (КлючСвязи), а в запрос добавим условие по ссылке, фрагмент ниже:
Выбрать
...
ИЗ Документ.ЗаданиеНаПеревозку.Распоряжения КАК ЗаданиеНаПеревозкуРаспоряжения
ЛЕВОЕ СОЕДИНЕНИЕ Документ.ЗаданиеНаПеревозку.Маршрут КАК ЗаданиеНаПеревозкуМаршрут
ПО ЗаданиеНаПеревозкуРаспоряжения.КлючСвязи = ЗаданиеНаПеревозкуМаршрут.КлючСвязи
И ЗаданиеНаПеревозкуРаспоряжения.Ссылка = ЗаданиеНаПеревозкуМаршрут.Ссылка
Два условия соединения. Этот способ позволяет не создавать индекс, но влияет только на один запрос.
План запроса изменился, фрагмент ниже
47, 47, 1, 0.00387, 0.000169, 88, 0.215, 54.9,
Clustered Index Seek(OBJECT:([ut-main].[dbo].[_Document515_VT3776].[_Document515_VT3776_SK] AS [T5]), SEEK:([T5].[_Fld1420]=[@P3] AND [T5].[_Document515_IDRRef]=[ut-main].[dbo].[_Document515_VT3788].[_Document515_IDRRef] as [T3].[_Document515_IDRRef]), WHERE:([ut-main].[dbo].[_Document515_VT3788].[_Fld3790] as [T3].[_Fld3790]=[ut-main].[dbo].[_Document515_VT3776].[_Fld3784] as [T5].[_Fld3784]) ORDERED FORWARD)
Поле Fld3784 (КлючСвязи) используется при соединении табличных частей, оператор Clustered Index Seek, обработано 47 строк, загрузка CPU 0.000169, стоимость 0. 215.
Контекст запроса Обработка. ГрафикТранспортаИСервиса.Форма.Форма.Модуль.ОбновитьСписокРаспоряженийНаДоставку
Оператор Clustered Index Seek имеет параметры SEEK и WHERE, то есть сначала использует индекс, для поиска по полю «Ссылка», потом происходит частичное сканирование для поиска по полю «КлючСвязи».
Если сравнивать три плана запроса, то при сопоставимом объеме данных последний план гораздо ближе к оптимизированному плану, чем к первоначальному плану. Еще одна возможность.
Как мы видели, отсутствие необходимых индексов приводит к сканированию таблиц и чрезмерному использованию CPU. До сих пор мы искали недостающие индексы по данным MS SQL. Однако, возможен другой подход: искать в технологическом журнале события, когда СУБД из-за нехватки индексов вынуждена применять сканирование. Перечислим основные преимущества такого подхода:
- Анализируется использование временных таблиц.
- Методика может применяться для других СУБД.
- Виден контекст выполнения (место вызова) запроса.
- Не нужен доступ к серверу СУБД.
Соберем технологический журнал с настройками
<?xml version="1.0"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log location="C:\Log\Logs\UT" history="24">
<event>
<eq property="name" value="DBMSSQL"/>
<like property="planSQLText" value="%Nested Loops%"
</event>
<property name="all"/>
</log>
<plansql />
</config>
Для анализа технологического журнала применим скрипт
time egrep -e '^[0-9]{5,9}.*((Nested Loops)|(Clustered Index Seek.*WHERE))' -h -R --include '21030909.log' \
| sed "s/\bT[0-9][0-9][0-9]\b/.+/g; s/\bT[0-9][0-9]\b/.+/g; s/\bT[0-9]\b/.+/g" \
| sed "s/Join,/Join./g; s/Nested/,Nested/g; s/Clustered/,Clustered/g" \
| sed 's/\],/../g; s/\]/./g; s/\[/./g' \
| sed -e 's/),/../g' \
| sed -e 's/)/./g' \
| sed -e 's/(/./g' \
| awk -F',' '{Cpu[$10]+=$5; if ($1>100) {Rows[$10]+=$1}; Text[$10] = "^[0-9]{4,9}.*"$10"$"} \
END {for (i in Text) {printf "\n%15d\t%15d\t%90-s", Rows[i], Cpu[i], Text[i]}}' \
| sort -rnb \
| head -n20 > result.txt
1. Начинаем замер времени, выбираем из каталога файлы по маске, фрагменты плана запроса содержат Nested Loops или Clustered Seek.*WHERE и начинаются с числа большего 999. То есть оператор обработал большое количество строк запроса. Подробнее смотрите Шаг третий.
2. Имена временных таблиц заменяем на .+ чтобы унифицировать текст запросов.
3. Расставляем запятые, чтобы удобно разбирать awk
4. - 7. Заменяем символы скобок на точки
8. Оператором awk группируем строки плана по оператору, суммируем количество строк запросов и CPU.
9. Группированные строки выводим в таблицу, но добавляем специальные символы до и после фрагмента плана $10
10. Сортируем по убыванию количества строк
11. Выводим первые 20 строк в файл result.txt, например
486080 0 ^[0-9]{4,9}.*Nested Loops.Inner Join. OUTER REFERENCES:..Expr1030.. .Expr1031.. .Expr1032...$
455114 0 ^[0-9]{4,9}.*Nested Loops.Inner Join. OUTER REFERENCES:...+..._Fld18379_TYPE.. ..+..._Fld18379_RTRef.. ..+..._Fld18379_RRRef...$
373088 0 ^[0-9]{4,9}.*Nested Loops.Inner Join. OUTER REFERENCES:...+..._IDRRef.. .Expr1037.. WITH ORDERED PREFETCH.$
156234 0 ^[0-9]{4,9}.*Nested Loops.Inner Join. OUTER REFERENCES:..Expr1027.. .Expr1028.. .Expr1029...$
128007 0 ^[0-9]{4,9}.*Nested Loops.Inner Join.$
114289 0 ^[0-9]{4,9}.*Nested Loops.Inner Join. OUTER REFERENCES:..Expr1012.. .Expr1013.. .Expr1011...$
Как видите, фрагменты строк содержат много точек. Это сделано для того, чтобы фрагмент плана можно было найти в файле технологического журнала с помощью notepad++ используя регулярные выражения. Даже минимальный фрагмент определяется корректно благодаря символу конца строки.
Если файл слишком большой, разбейте его на меньшие файлы bash split. Лично меня количество строк запросов, обработанных за час Nested Loops шокировало. Буду создавать индексы или индексировать временные таблицы. Посмотрю по комментариям: дополнять эту статью или оформить отдельную.
Если Вы дочитали до конца, Вы весьма настойчивы. Не сомневаюсь, что Вы сможете применить свои знания на практике и представить вашу победу нужным людям в нужном свете.
Удачи всем !
P.S. Удалось получить разрешение от Виктора Богачева на публикацию, см. комментарий № 18.
Вступайте в нашу телеграмм-группу Инфостарт