7 лет пути
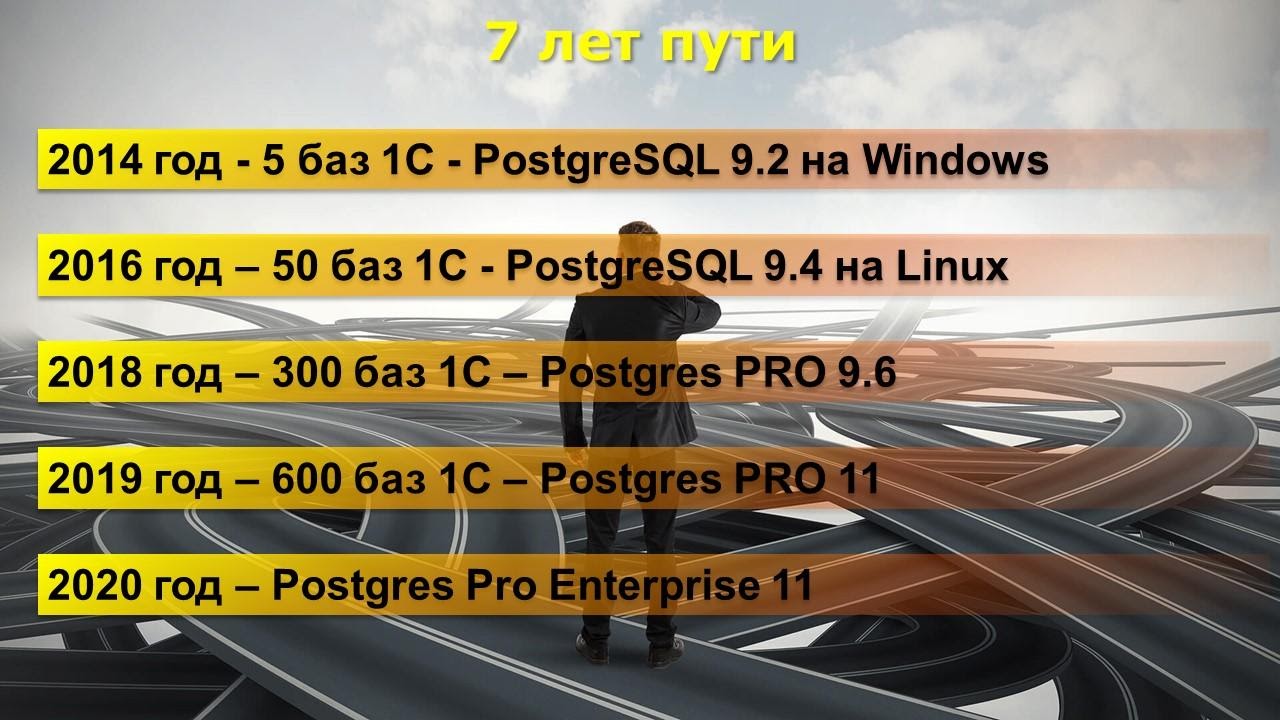
Расскажу для начала, какой путь мы прошли в 1С на PostgreSQL.
- Путь этот начался в 2014 году, мы рискнули перевести 5 небольших баз на PostgreSQL – тогда это была еще версия 9.2. Никакую операционную систему, кроме Windows, мы не могли себе даже представить в связке с 1С. В то время мир 1С состоял только из Windows, Linux всех пугал своими черными экранами с белыми буковками – было вообще ничего непонятно. Первое наше впечатление было: «Ничего себе, оно работает»! 1С-ка запустилась и даже что-то сформировалось.
- К 2016 году мы поняли, что уже не можем переварить на Windows то количество баз, которое нам нужно. К тому времени у нас появилось уже около 50 баз на PostgreSQL. Именно в этот промежуток времени мной и моей командой экспертов был обнаружен первый баг PostgreSQL на Windows, там оказалась блокировка файла при обновлении статистики, которая приводила к тому, что 1С-ка замирала на 15 секунд, не выполняя никаких операций. Пока этот баг правили, мы поняли, что все равно Windows из-за своих особенностей не может удовлетворять наши запросы. Мы рискнули и перешли на Linux. В то время PostgreSQL обновился до версии 9.4,
- До 2018 года мы спокойно жили, пока наш облачный сервис не вырос в 5-6 раз, у нас стало 300 баз 1С. Тут мы вовремя познакомились с командой Postgres PRO, они начали выпускать отличные сборки для 1С. Кроме того, сам ванильный Postgres обновился до серии 9.6. Это была революционная версия – огромное количество изменений, и, как ни странно, для сообщества Postgres эти изменения были почти ни о чем: подумаешь, автовакуум стал лучше работать, стал чуть быстрее, ведь для наших 100 таблиц это ерунда. Для 1С это обновление стало критичным, ведь наша с вами любимая 1С имеет базу данных с тысячами таблиц и десятками тысяч индексов, а еще мы любители развернуть по 100 баз на одном сервере. Поэтому получаем миллионы элементов для СУБД. Для PostgreSQL это тяжело, и версия 9.6 в этом очень помогла.
- В 2019 году количество баз у нас выросло вдвое. И параллельно PostgreSQL стал очень быстро развиваться – раз в год обновляется релиз. Мы проскочили десятую версию и сразу заскочили на одиннадцатую. В 2018-2019 годах мы использовали сборки от команды Postgres PRO, не ванильную версию, не отдельные патчи для 1С, а именно готовые сборки.
- В 2020-м году мы начали использовать Postgres PRO Enterprise. Используем мы его полгода, пока не везде он стоит на продакшн-базах, в своем докладе объясню – почему. Расскажу, что мы накопали, что уже исправили.

- В 2020 году мною был получен сертификат администратора PostgreSQL уровня Эксперт от компании Postgres PRO. Так получилось, что момент получения сертификата совпал с получением доступа к PostgreSQL PRO Enterprise 11 – когда мы начали его активно «ковырять».
Версии Postgres для 1С
Но прежде чем окунуться в Enterprise, сначала напомню, какие версии PostgreSQL для 1С есть. В этом моменте у многих есть недопонимание.
PostgreSQL для 1С – самосборка

Версия №1 – это самосборка PostgreSQL для 1С на основе открытых исходников ванильной версии. Для тех, кто умеет собирать пакеты – это самая теплая ламповая сборка.
В чем ее особенности использования:
- Эта версия PostgreSQL обойдется вам бесплатно, но использовать вы ее сможете только на свой страх и риск. Поддерживать ее даже за деньги вряд ли кто-то возьмется. Если вы обратитесь к кому-то за поддержкой такой «самосборки», скорее всего, вас попросят переустановить PostgreSQL из другого источника.
- Эта сборка не входит в «Единый реестр программ», который действует в рамках стратегии импортозамещения, и не может использоваться ни в одной организации, подчиняющейся приказу Минкомсвязи.
- Техподдержку этой версии вам придется оказывать самим – вряд ли кто-то вам поможет. Это не значит, что решение плохое, но, как и все бесплатное в мире OpenSource – поддерживайте сами. Форумы PostgreSQL и Linux похожи, поэтому, если вы там зададите вопрос – вас 100 раз спросят, зачем вы взялись за эту технологию, если такой “дурак”, а потом отправят учить матчасть. Причем без ссылок, где ее искать. Возможно, попадется один сердобольный специалист, который вам намекнет, где искать ответ. Это жестокая тренировка для тех, кто хочет окунуться в этот мир.
PostgreSQL для 1С – сборка фирмы «1С»

Есть сборка PostgreSQL от фирмы «1С». Она распространяется в двух видах – как дистрибутив и в качестве исходников набора патчей, которые нужно использовать для ванильного PostgreSQL.
В чем ее особенности:
- Собирается она специалистами фирмы 1С. Получить ее можно бесплатно на сайте, где выкладываются обновления платформы 1С. Но использовать вы ее можете так же на свой страх и риск. Впрочем, как и все ПО: ни одно ПО вам ничего не гарантирует, даже за очень большие деньги.
- Эта сборка также не входит в «Единый реестр ПО», запрещена в госорганах.
- Поддерживается фирмой «1С» бесплатно, в рамках партнерского форума и v8@1c.ru через “кровь и боль”.
PostgreSQL для 1С от Postgres PRO

Следующая сборка появилась недавно, в день проведения конференции Infostart Event 2019, от команды Postgres PRO. О ней объявил Олег Бартунов. Это сборка от команды Postgres PRO, скачать ее можно с сайта https://1c.postgres.ru. Это – ванильный Postgres, собранный с патчами для 1С и плюс некоторые улучшения, которые команда Postgres PRO считает важными для 1С и внедряет их.
- Эта сборка полностью бесплатная, лицензий на нее нет, используется на свой страх и риск.
- Она также не входит в «Единый реестр ПО».
- Техподдержку по ней можно получить за деньги.
Postgres PRO Standart

Еще одна такая же сборка с небольшой цензурой Postgres PRO Standart.
Получить ее можно, зарегистрировавшись на сайте Postgres PRO.
- Она может использоваться бесплатно только для разработки, тестирования, экспериментов и изучения возможностей продуктов. То есть как разработчики на тестовых серверах вы ее использовать можете, но продуктивные базы на этой сборке работать могут только после приобретения лицензией. От Enterprise она отличается тем, что тут нет платных фишек Enterprise. Здесь есть некоторые улучшения планировщика, есть PTRACK – маркер для pg_probackup.
- Она входит в «Единый реестр ПО», потому что ее планируют использовать для госучреждений, которые обучают: институты и школы. Лицензия живая, меняется – надо ее изучать и следить за обновлениями.
- Техподдержка осуществляется компанией Postgres PRO за отдельные деньги, а также входит в покупку лицензий в первый год.
Postgres PRO Enterprise

Коммерческая сборка Postgres PRO Enterprise – чем она отличается от версии Postgres PRO Standart:
- Это коммерческий форк Postgres PRO, она отличается набором изменений – их около 100. Причем различий, имеющих смысл для 1С, там гораздо меньше.
- Надо понимать: платная версия не значит, что отчет 1С, который у вас на бесплатной версии выполнялся две минуты, тут будет выполняться две секунды. Это примерно такое же заблуждение, когда файловую базу переводят на клиент-серверный вариант и ждут, что она станет быстрее работать – не будет она быстрее работать в однопоточном режиме. Но по аналогии с тем, как клиент-серверная база 1С по сравнению с файловой будет работать с одинаковой скоростью – и при одном человеке, и при 300-400 пользователях. Так же и Postgres PRO Enterprise оптимизирован для высоких многопользовательских нагрузок – у него нет деградации от количества пользователей, он оптимизирован для больших баз данных.
- Postgres PRO Enterprise имеет сертификат ФСТЭК – его можно использовать в организациях с требованием секретности.
- Эта сборка входит в «Единый реестр ПО».
- Техподдержка осуществляется компанией Postgres Professional – в первый год после покупки бесплатно.
Фишки Enterprise, полезные для 1С

Теперь подробнее поговорим о фишках Enterprise, которые важны именно для 1С.
- Снято так называемое «проклятие 100 сессий». Кто интересовался PostgreSQL немного раньше, тот помнит: ходил слух, что PostgreSQL тормозит. Как про антивирус от «Лаборатории Касперского» говорили, что он тормозит, хотя он уже 15-20 лет не тормозит, если его правильно настроить. Так же про PostgreSQL ходил слух, что он после 100 соединений начинает резко деградировать. На самом деле, современные релизы даже ванильного Postgres не деградируют после 100 сессий – скорость работы может незначительно деградировать, если неправильно подобрано оборудование. В Enterprise эта деградация убрана полностью – тесты Benchmark показывают 20 тыс. соединений без деградации. В этой сборке поменяли взаимодействие между процессами и возможное количество одновременно работающих сессий резко увеличилось.
- Как и в версии Standard, в версии Enterprise есть PTRACK для pg_probackup. На пальцах постараюсь объяснить, что это такое. Мир 1С в большинстве случаев – это MS SQL. Все привыкли в MS SQL к дифференциальным бэкапам. В Postgres дифференциального бэкапа не существует, есть только инкрементальный бэкап. Если вы делали фулл, потом инкремент, то следующий инкремент – это изменения от последнего инкремента, а не фулла, в отличие от дифференциального. Но в чем сложность. Из-за особенностей хранения данных в файлах – не в одном файле, как в MS SQL, а каждое представление в отдельном файлике – очень трудоемко выяснить, какие страницы данных изменились, а если вычислять по времени обновления файлов, то получаем серьезную избыточность бэкапа в объёме. Особенно на базах 1С, где десятки тысяч файлов на одну базу. Поэтому сделали специальный реквизит PTRACK, который помечает: эти данные поменялись. И тогда pg_probackup очень быстро делает инкрементальный бэкап.
- Также тут внедрен важный патч для планировщика: статистика по составным индексам. Ванильный PostgreSQL не умеет делать статистику по составным индексам, а в 1С 100% индексов составные. Вряд ли платформа позволит вам сделать индекс по одному полю, она в любом случае добавит туда разделитель данных, даже если вы его не используете, и составит индексы так, как написано на ИТС, а не так, как вам захотелось. Все индексы в 1С составные, и Enterprise научили ориентировать статистику в том числе и по ним.
- В Enterprise уже внедрено расширение pg_hint_plan. Я о нем чуть позже расскажу, с помощью этого расширения можно изменять поведение планировщика для нужного вам запроса.
- Самая крутая фишка, по моему мнению – сжатие данных на уровне СУБД. В MS SQL это есть, теперь появилась и в Postgres PRO. Фишка хорошая, имеет свои ограничения и свои плюсы, о них тоже расскажу чуть позже.
Все отличия Enterprise от не-Enterprise смотрите по ссылке https://postgrespro.ru/products/postgrespro/enterprise.
Теперь давайте подробнее рассмотрим, как это в жизни работает.
pg_hint_plan

pg_hint_plan – это не фишка Enterprise, это открытое расширение, которое вы можете спокойно внедрять в свои сборки, но в Enterprise оно уже внедрено.
Что оно делает? На просторах интернета можно встретить жалобы на то, что в 1С плохо работает отчет. Но если в настройках join_collapse_limit поставить 1 (вместо 8 или 20 – по умолчанию на разных сборках установлено по-разному), то отчет сразу начинает работать быстро, а вся остальная база «встает колом».
Для решения такого вида проблем есть pg_hint_plan. Вы можете влиять на план выполнения запроса, добавляя в комментариях нужные вам операторы, как показано на слайде.
Конкретно этот пример взят мной из документации. Здесь указано:
- HashJoin(a,b) – таблицы a и b нужно соединить по хэшу.
- SeqScan(a) – в таблице a сделать SeqScan.
Ниже план выполнения, где видно, что Postgres выполняет команды так, как ему сказали.
Таким образом, независимо от того, как отработал планировщик – “Бог” СУБД, вы как программист можете выступить «помощником Бога» и исправить ошибки “Бога” так, как считаете нужным. Не факт, что это будет правильно или быстрее, но эксперты вполне могут себе позволить это делать.

Скорее всего, у вас не получится напрямую засунуть комментарий в код 1С так, чтобы платформа это правильно обработала и передала. Но в этом расширении есть крутая штука – таблица указаний, где вы можете шаблонно указать запрос и что с ним сделать.
Тут надо иметь в виду одну особенность – шаблон запроса это не маска, хоть и называется шаблоном. Чтобы эта настройка сработала, запрос должен прилетать всегда одинаковый.
А с помощью указания Set вы можете на время планирования запроса задать планировщику параметры GUC (например, указать join_collapse_limit=1 на ваш любимый отчет) – получается, что и запрос ускорится и база летать начнет.
Подробно запросы разбирать я не буду, но это незаслуженно забытое расширение, изучите его. Документации по нему много, очень крутая вещь, будущее у нее есть.
https://postgrespro.ru/docs/enterprise/12/pg-hint-plan
Поскольку не всегда мы можем дождаться исправления в платформе 1С, где, по нашему мнению, неправильная интерпретация запросов. А здесь вы можете сами взять и что-то подправить в планировщике.
Сжатие данных на уровне СУБД

Что дает сжатие данных на уровне СУБД:
- Дает экономию места – в документации написано от 3 до 5 раз, на наших тестах от 5 до 8 раз от объема базы.
- Дает еще большее уменьшение деградации производительности при смешанных нагрузках – именно у нас в 1С постоянно смешанные нагрузки OLAP+OLTP. Мы хотим, чтобы у нас мгновенно записывались транзакционные операции в базу, и так же очень быстро все читалось из базы в огромных отчетах, которые соединяют между собой по 200 таблиц. От чего здесь идет уменьшение деградации? Все элементарно – вы уменьшаете нагрузку на диск. В современном СУБД основные тормоза – это диски. Процессоры справляются, память очень дешевая, ее можно добавить, сколько угодно. А диски, даже SSD, все равно тормозят по сравнению с процессорами и памятью. Да, сейчас активно начали использовать NVME, но и они не всесильны, а так же немалую роль играет стоимость 1ГБ места на диске, которую можно уменьшить в разы, используя сжатие. При сжатии на уровне СУБД вы чисто физически уменьшаете объем поднимаемых данных в 5-8 раз. Причем не только данных, но и индексов и временных таблиц тоже – они так же жмутся.
- Еще одна фишка – шифрование данных. Это важная возможность для тех, кто хранит конфиденциальные данные. В этом случае при старте базы данных надо будет указать пароль.
Казалось бы, сжатие – крутая вещь, но когда мы ее начали использовать на 1С, нас начало не по-детски “штормить”.

На тот момент у нас были настройки сжатия, как на слайде. Не было только одной настройки – Compress first segment of relations.
Что это такое? По умолчанию сжатие происходит вообще всех элементов базы данных. Опять же напоминаю, что типовая Бухгалтерия содержит 5,5 тысяч таблиц и 27 тысяч индексов – итого 32 тысячи файлов.
Кроме того, Postgres каждый следующий гигабайт пишет в новый файл. Может быть, что одна наша база данных займет 300 тысяч файлов.
По умолчанию CFS попробует сжать все 300 тысяч файлов.
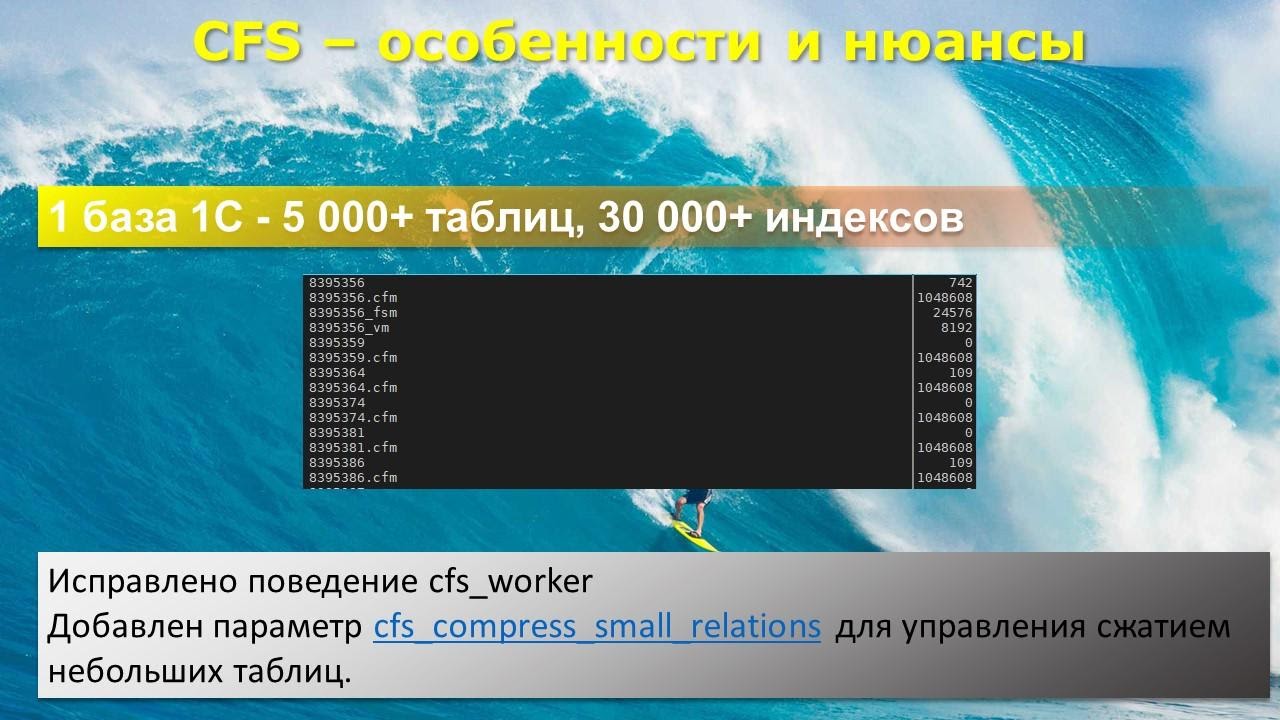
В результате мы получим у каждой базы вот такой файл-отражение со стандартным размером 1 мегабайт, поскольку именно в 1 мегабайте они могут удержать отражение 1 Гб данных.
Postgres не знает, что его сжали, он обращается к номеру страницы на диске, который у него в базе написан.
Система сжатия перехватывает этот запрос, и запрашивает в CFM-файле, где эти данные теперь в реальности находится – мы же сжали файлы, а оригиналы, грубо говоря, удалили, они находятся в другом месте. Это и называется файл-отражение, когда на каждый элемент создается файл размером 1 мегабайт.
В чем случилась беда? Наш первый тест на базе 1С показал следующее: CFS-worker бегает по всем файлам отражения и пытается их дефрагментировать – удалить оттуда то, что мы удалили из данных. Грубо говоря, еще один вакуум еще одного элемента. При таком количестве файлов, как в базе 1С, CFS-worker клали на лопатки любые дисковые системы. У нас система легла на 4 млн файлов – это 150 баз на сервере 1С.
После этих тестов разработчики PostgreSQL:
- добавили параметр cfs_compress_small_relations, чтобы компрессия работала только для файлов больше 1 ГБ;
- и в принципе, исправили поведение CFS-worker – теперь он меньше грузит диски, даже если вы не отключите сжатие всего и вся.

Дальнейшие исследования показали, что нельзя сжать табличное пространство по умолчанию. Изначально Postgres ставится и создает пространство-default. Но сжать уже созданное пространство нельзя, сжатие происходит путем создания пространства с сжатием.
Здесь можно пойти несколькими путями:
- Можно воспользоваться фишкой платформы 1С для Postgres, которая разделяет данные и индексы на разные tablespace. Если платформа обнаруживает, что tablespace вызывает v81c_index или v81c_data – раскидывает данные туда.
- Но здесь опять есть свой подводный камень. Когда вы создадите табличное пространство, вы захотите туда базу перекинуть с несжатого табличного пространства. Скорее всего, будете перекидывать постгрессовым дампом. И дампу не рассказать, куда класть данные и индекс. Как выход из ситуации – создавайте одно сжатое пространство и кладите туда.
- Более того, поскольку вы теперь создаете отдельное пространство, не default, вам надо аккуратнее работать с дампом и рестором. Вам надо подправить все скрипты, чтобы рестор правильно восстанавливал в существующие tablespace, а дамп правильно дампил.
- Ну или просто создать отдельный сжатый tablespace и восстанавливать дамп, указав его утилите restore.

Как я уже сказал, каждый файл отражения весит 1 МБ, но это не реальное место, которое занимает файл на диске, а просто атрибут файла. В итоге можете получить интересный эффект. После сжатия 100-гиговой базы в свойствах Postgres вы обнаружите, что 100-гиговая фаза начала весить 250 гигов. Как же так, мы же сжали? Все просто: у вас образовалось 150 тысяч файлов отражений. Это пока не исправлено, нет отдельной процедуры, которая показывает правильный размер, либо я о ней не знаю.
Реальный размер в Linux проверяется через утилиту du (disk usage) – на слайде приведена командная строка, как проверять. Эта утилита покажет вам реальный размер, который данные занимают на диске, а не размеры, подсчитанные по атрибутам файлов. В pg_admin будет искаженная информация.

Еще одна особенность, обнаруженная случайно: оказывается, утилита pg_repak (по факту vacuum_full без блокировки данных), знает, но не учитывает tablespace у таблиц.
А поскольку при сжатии мы создаем отдельный tablespace, то pg_repack, когда вы натравите его на сжатую базу, перепакует таблицы в несжатое пространство, в default.
Чтобы это исправить, ей при вызове нужно указать параметр -s (маленькая). И указать, в какой tablespace перепаковать – передать идентификатор для переупаковки сжатого tablespace.
При этом при переупаковке индексов у них tablespace учитываются. Но на всякий случай привел вам команду и для индексов -S (большая). Это надо обязательно иметь в виду.
Что изменится в августе
Когда мы это все раскопали, нам показалось, что в целом можно запускаться. Но мы нарвались на две ошибки, которые нам обещают исправить в августе.

Я впервые встречаю вендора, с разработчиками которого можно общаться напрямую на русском языке, и они тебе отвечают в течение одной минуты, не ткнут носом в ошибку, пытаются разобраться и очень быстро и аккуратно исправляют баги.
Итак, когда мы подумали, что все окей, мы, как правильные эксплуататоры СУБД, решили настроить реплику и нарвались там на две ошибки. Эти ошибки нам обещают исправить в августе. Что это за ошибки?
- PS_BaseBackup не умеет определять в файлах отражений, сколько они занимают места на диске. Когда мы попытались нашу сжатую 100-гиговую базу снять PG_BaseBackup’ом, чтобы потом запустить реплику, мы получили на BaseBackup 400 гигов занятого места, поскольку слилось еще 300 тысяч файлов CFS. BaseBackup прочитал атрибут, что ему требуется 1 МБ места, и реально выделил 1 МБ. Это исправлено, но еще нет в релизе. У нас на серверах это уже исправлено.
- Еще в августовское исправление войдет исправление самой реплики. Сейчас реплика «устраивает гонки» (ревнует) с CFS-сжатием. Система репликации не понимает, что работает на сжатой системе и взаимоблокирует два процесса, и в итоге полностью останавливает сервер реплики. У нас на серверах это тоже исправлено. В августе будет выпущено в релиз.
С 1 сентября, когда с нас снимут все карантины, заодно мы получим полностью работающую Enterprise версию PostgreSQL со сжатием данных. Огромное спасибо разработчикам движка базы данных и моей команде 1С-ников, которые все это протестили.
P.S. Все исправления обнаруженных нами проблем со сжатием вошли в версию 12.5.1.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Новосибирск.


Вступайте в нашу телеграмм-группу Инфостарт