Меня зовут Василий Попов. Хочу рассказать о нашем опыте сбора информации с большого количества баз. Какие у нас были трудности, как мы их решали. Расскажу весь путь развития архитектуры нашего решения, возможно, что-то вы сможете почерпнуть для себя.
Начальные условия
Необходимость извлекать информацию из информационных баз у нас появилась исходя из начальных условий:
-
У нас большое количество баз, вся наша инфраструктура построена на 1С:Фреш. 1С:Фреш основан на технологии мультиарендности – когда в одной информационной базе находится множество разделенных областей данных. Это выглядит так, как будто в одну информационную базу помещены 10 файловых баз, и переключение между ними возможно путем смены области данных. Подобные решения – Битрикс24, amoCRM и прочие SaaS-сервисы.
-
У нас большое количество областей данных: 700 учреждений,1400 областей данных. Мы используем конфигурации «Бухгалтерия» и «ЗУП».
При таких условиях у нас были проблемы. Например:
-
Хотелось иметь возможность консолидировать данные за систему – так как много учреждений, хочется видеть все данные в одном месте.
-
До начала нашего проекта по сбору информации эта проблема решалась с помощью внешних отчетов. Аналитики заходили в информационные базы, запускали отчет, указывали области данных, с которых надо было собирать информацию. Для каждой области данных отрабатывал запрос, который собирал отчет в один табличный документ. Потом этот табличный документ уже обрабатывался в виде Excel – и тут тоже была проблема, потому что приходилось вручную обрабатывать информацию с помощью ВПР в огромных Excel-файлах.
-
Еще одна проблема заключалась в том, что доступ к сбору информации с помощью внешних отчетов был возможен только на тестовом контуре – там можно было зайти в информационную базу и что-то проверить. Но там помимо отчетов проводилось тестирование новых возможностей, и, получается, что эту информацию могли испортить, изменить. Доверять такой информации было тяжело.
-
Помимо этого существовал BI-контур. Но доступ в него был возможен только через SOAP-сервисы, и только на чтение, чтобы ничего нельзя было поменять.
Принцип работы модуля для получения доступа к информации

Доступ к информации из областей данных был реализован с помощью модуля, который мог получать запросы и выполнять их, отправляя результаты в систему, которая его запрашивала.
В этот модуль можно было передать текст запроса. На слайде показан пример передаваемого текста запроса – это пример запроса кредиторской задолженности на дату. Сюда передается параметр даты остатков и накладывается условие с поиском счета по коду через «ПОДОБНО».
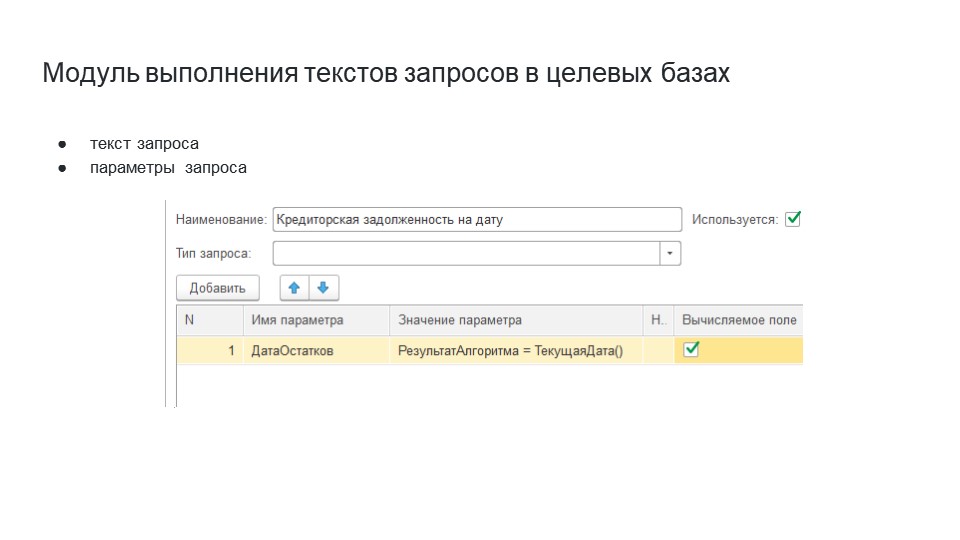
При передаче параметров запроса для случая, когда нам надо было собирать данные по остаткам на сегодня, мы для себя сделали вычисляемое поле, в котором в значении параметра писали:
РезультатАлгоритма = ТекущаяДата()
Тем самым могли получить динамический параметр запроса, который всегда мог изменяться.

В модуле был реализовано несколько вариантов формата возвращаемых данных:
-
ЗначениеВСтрокуВнутр – это внутренний формат платформы 1С;
-
XML;
-
и потом мы еще добавили JSON.
На слайде показано, как выглядел ответ, который пришел из целевой области данных. Здесь приведен вариант ответа в формате JSON, но если в качестве формата возвращаемых данных использовался ЗначениеВСтрокуВнутр, то приходил просто текст внутреннего представления структуры.
В ответе указывались:
-
НомерОбласти;
-
РезультатЗапроса;
-
флаги ПустойЗапрос или ОшибкаВыполнения;
-
и идентификаторы для мониторинга выполнения задания.
Так как у нас множество информационных баз, нам нужно понимать, из какой области данных эти данные прилетели и была ли какая-то ошибка при выполнении этого запроса.
Также в модуль передается адрес для отправки, так как обращение к модулю выполняется асинхронно – мы получаем информацию о том, что задание принято, и уже по информации, которая была передана асинхронно после выполнения запроса, его результат улетает в указанный адрес.
Первая архитектура
В таких условиях мы реализовали первую архитектуру – она была выполнена «в лоб».
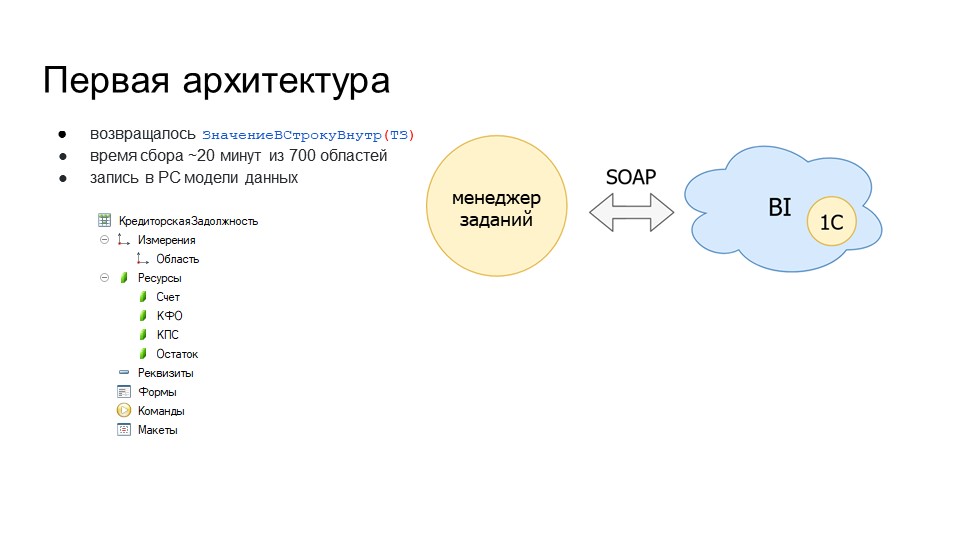
У нас был BI-контур, мы реализовали на 1С менеджер заданий и забирали информацию из BI-контура по SOAP.
-
Мы возвращали таблицу значений результата запроса в формате ЗначениеВСтрокуВнутр(ТаблицаЗначений).
-
Примерное время сбора – 20 минут из 700 областей.
-
Данные мы приземляли в тот же менеджер заданий – в регистр сведений, который мы описали как модель данных. На примере РС КредиторскаяЗадолженность – у нас есть измерение «Область» и ресурсы. «Область» сделано измерением для того, чтобы устаревшую информацию по области можно было перезаписывать – это позволит распараллелить запись из всех заданий и отбирать отдельно по области.
-
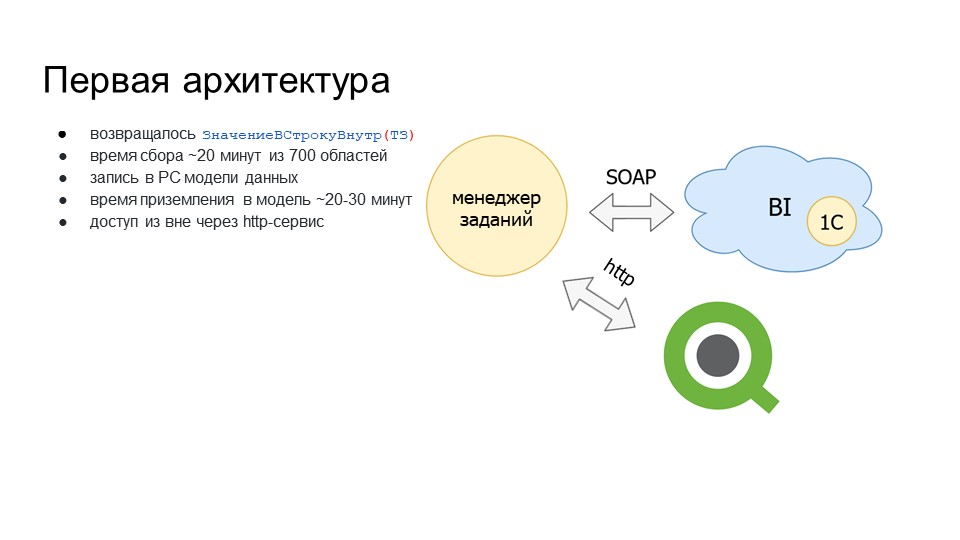
Время приземления данных в модель – 20-30 минут. Я уже говорил, что собранная информация записывалась в регистр сведений, и показал укороченную версию модели данных, но на самом деле у этого РС было 16 ресурсов, поэтому данные записывались довольно долго.
-
Так как данные у нас собираются в менеджере заданий, мы реализовали доступ к этим данным через HTTP-сервис для забора и анализа информации. Наши коллеги-аналитики уже начали использовать для этого Qlik. В Qlik есть возможность забора информации через rest. Мы этой возможностью воспользовались, чтобы аналитики могли забирать информацию из исходной системы и у себя уже как-то анализировать, строить отчет.
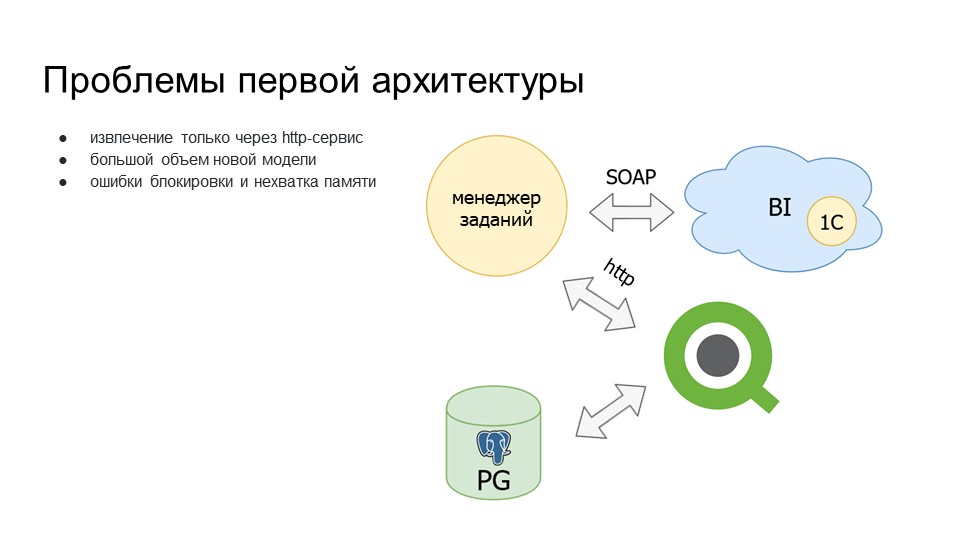
Проблемы первой архитектуры
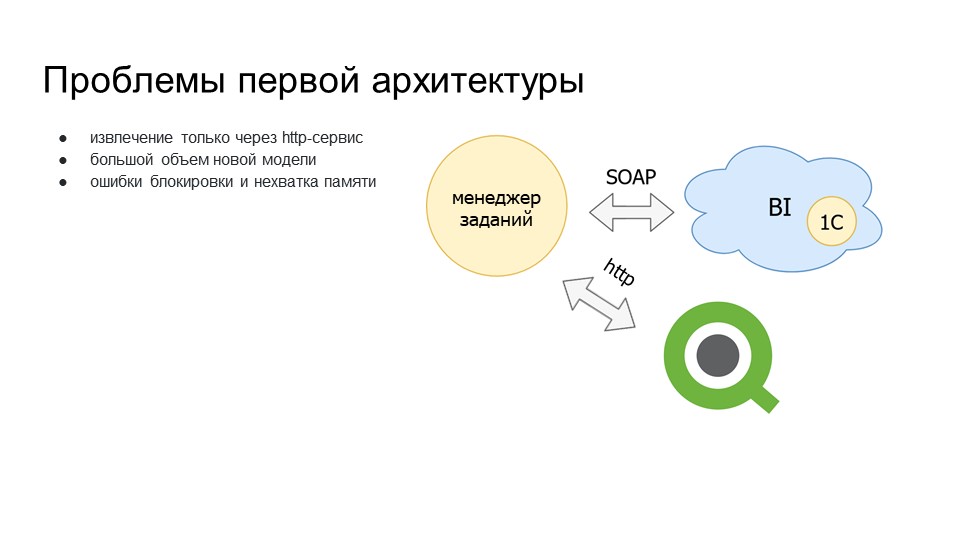
Мы опробовали первую модель, и поначалу все было нормально, но в дальнейшем, когда мы начали развивать эту историю, начались проблемы.
-
Извлечение только через HTTP-сервис было долго по скорости – это нам не очень нравилось.
-
Большой объем новых моделей. На тот момент мы начали строить новую модель, объемы которой были больше, чем объемы первой модели. Если в первую модель при запросе приходило порядка 1 млн записей, то в новую модель приходило информации порядка 3 млн. Это были остатки, и с каждым месяцем объем этой информации увеличивался.
-
Начались проблемы по ресурсам – при записи не хватало мощностей сервера, выскакивали ошибки блокировки и нехватки памяти, процессы рубились. Чтобы приземлить данные в модель, нужно было заново перезапускать процессы.
Тогда наши коллег-аналитики спросили: «Нельзя ли приземлить эти данные не в 1С, а в какую-то другую СУБД, из которой они могли бы забирать данные?»
В качестве другой СУБД они предложили PostgreSQL, потому что на тот момент они уже с ней работали, и им это очень нравилось.
Вторая архитектура
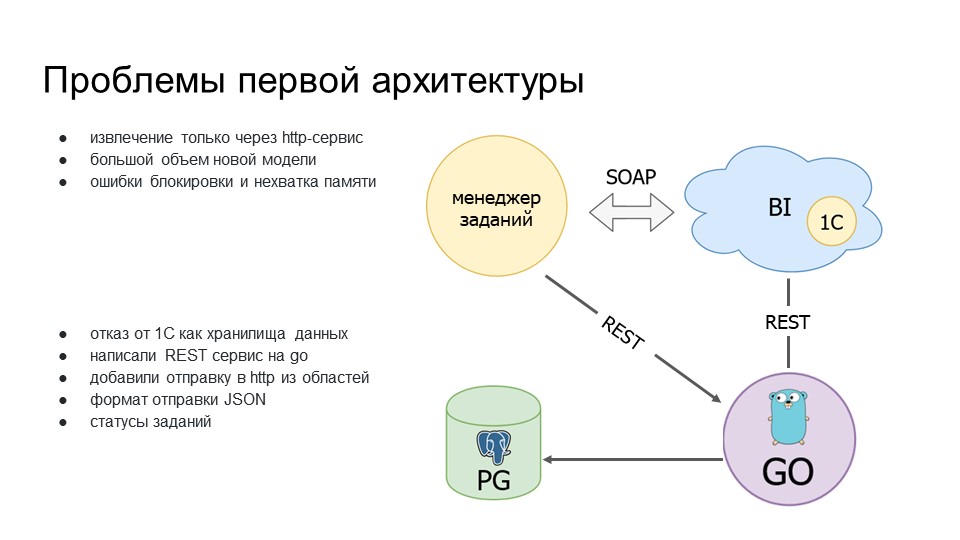
В результате:
-
Мы решили отказаться от 1С как от хранилища данных и все писать в PostgreSQL.
-
Написали REST-сервис на Go, который получал информацию из BI. Допилили модуль, чтобы он мог отправлять не только по SOAP, но по HTTP.
-
Реализовали формат запроса JSON, чтобы можно было приземлять через Go, потому что на Go не было парсера для результата, возвращаемого функцией ЗначениеВСтрокуВнутр().
-
Пришлось реализовать опрос нашего агента о получении информации, что он ее получил и записал, чтобы не пришлось повторно запрашивать ее в BI-контуре.
Получилась вторая архитектура.
Проблемы второй архитектуры
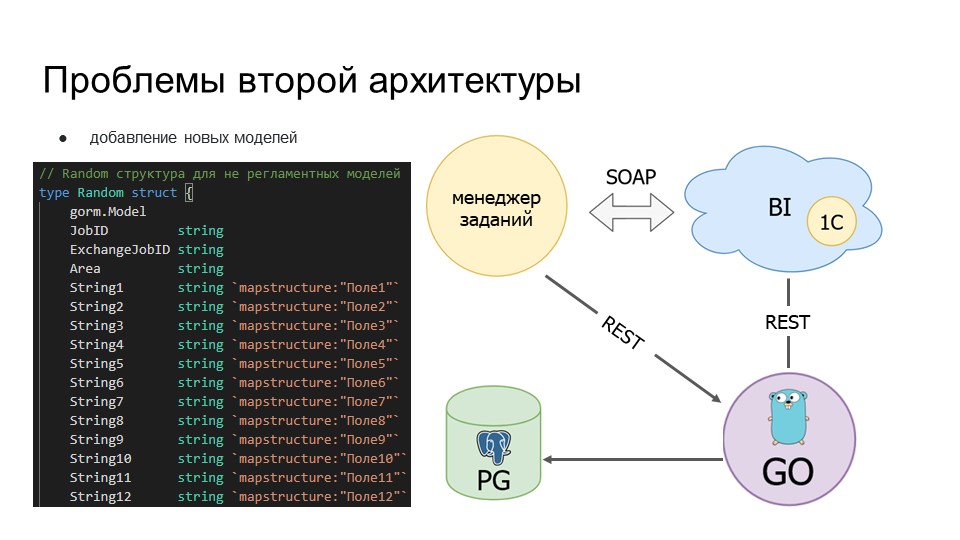
Но после ее реализации у нас в дальнейшем снова возникли проблемы.
Проблема добавления новых моделей. Чтобы добавить новую модель, аналитикам приходилось привлекать разработчиков – только разработчики могли написать модель, скомпилировать ее и доставить на прод.
Поэтому мы решили написать для каждого аналитика песочницу – назвали ее рандом-таблица, для каждого аналитика она была индивидуальной. Сначала в ней было 30 полей данных, потом 70, а сейчас уже под 100 полей. На этих данных аналитики могли обкатывать новые запросы, новые заборы информации.
Когда процесс извлечения этих данных и преобразования их в отчет был полностью отлажен, аналитики формировали задание разработчикам на то, чтобы написать модель уже конкретно под этот набор данных, и эта модель собиралась и доставлялась на продакшн.
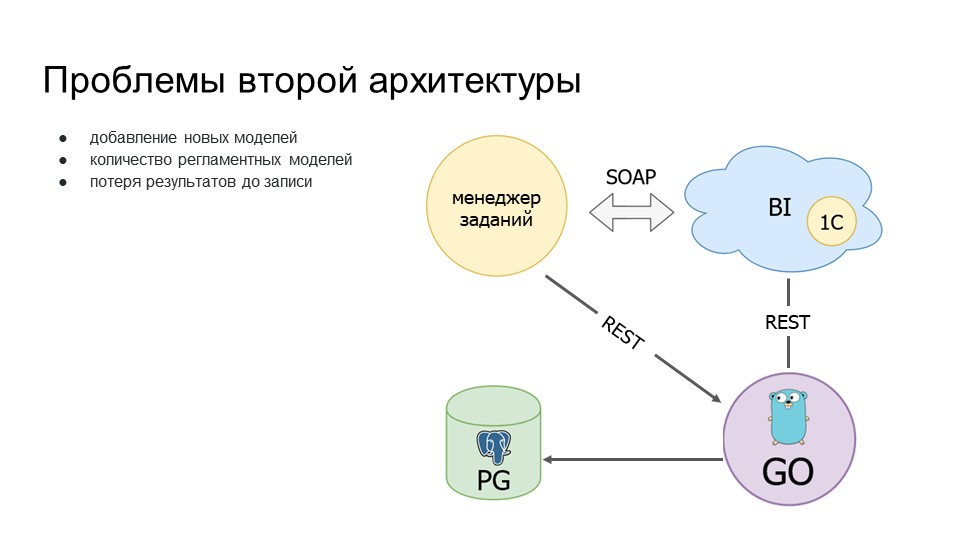
Возросло количество регламентных заданий, с помощью которых мы собираем данные по модели данных и составляем отчеты. Поэтому выросла нагрузка на Go-агента – он стал получать больше сообщений на обработку.
Стали возникать проблемы с потерей данных. Из-за того, что Go-агент принимал все сообщения, накапливался по оперативной памяти, ему не хватало памяти – он просто валился. Те сообщения, которые были накоплены в его внутренней очереди, терялись, не дозаписывались, приходилось их заново перезапрашивать.
Мы подумали, что стоит сделать архитектуру с неким брокером сообщений. Смотрели долго на разных брокеров, остановились на брокере сообщений nsqd.
NSQD
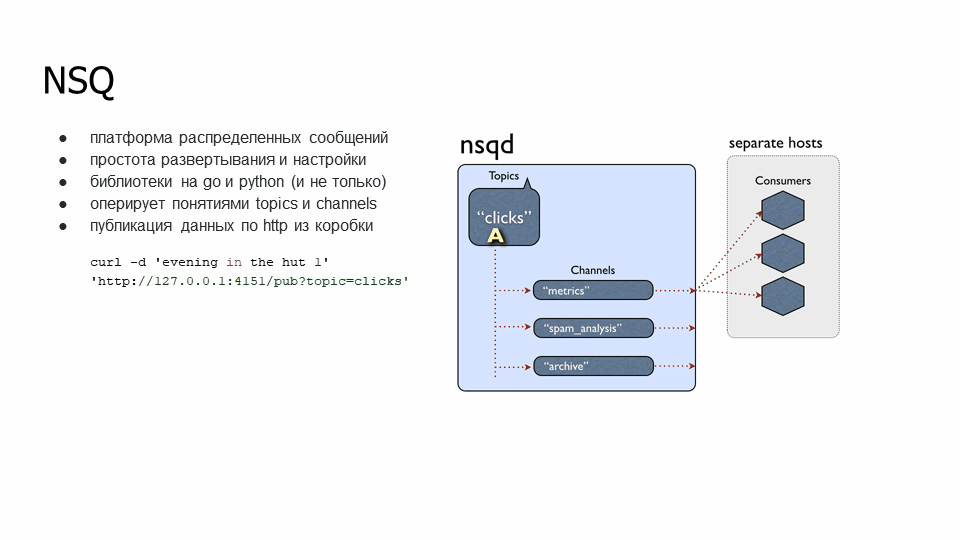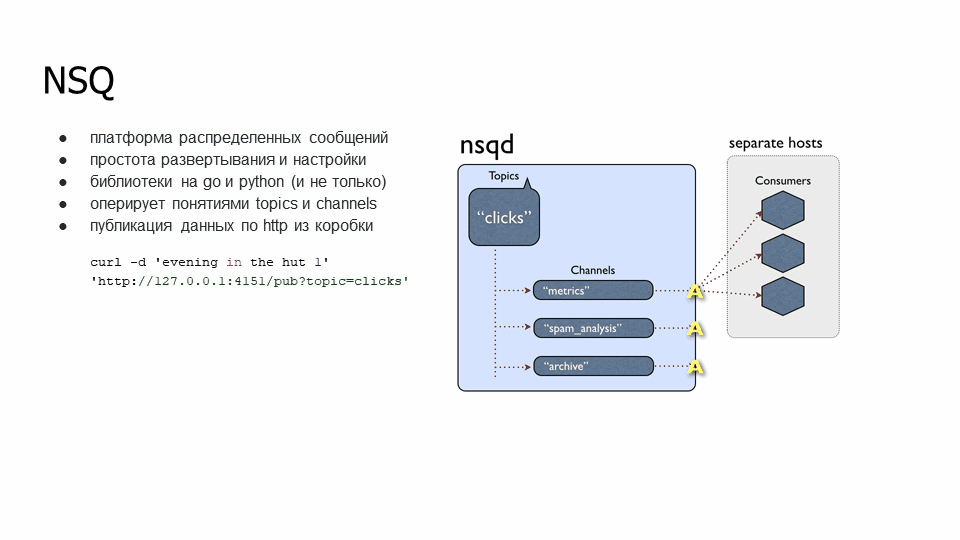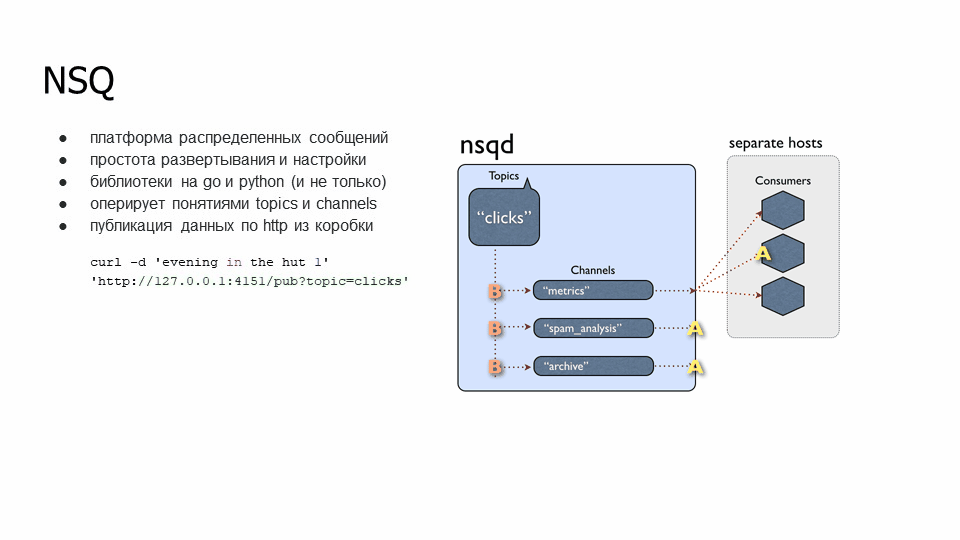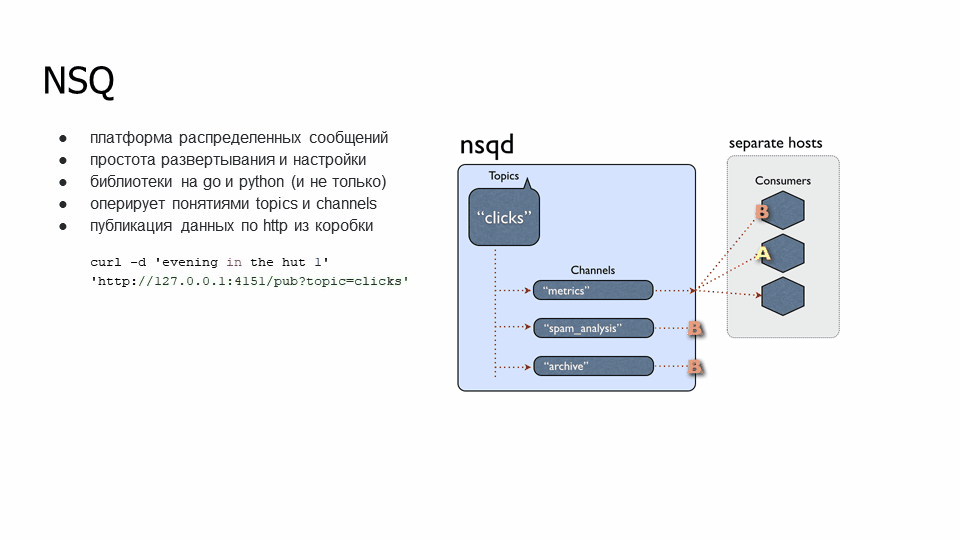
Что такое NSQD и чем отличается от остальных:
-
NSQD – это платформа распределенных сообщений в реальном времени. У нее из коробки есть возможность не хранить данные на дисках для ускорения.
-
Этот брокер сообщений легко развертывать и настраивать. Экземпляр сервера nsqd можно настроить буквально за пять минут – ссылка на официальную документацию и ссылка на мою статью, где переведено то, что написано в официальной документации.
-
NSQD оперирует такими понятиями как topics и channels. Topics – тема, в которую он будет писать, а channels – это группы, которые будут извлекать информацию. У нас есть топик “clicks”, к которому подключены несколько групп, таких как “metrics”, “spam_analysis” и “archive”. У группы есть несколько подписчиков, которые вычитывают информацию конкретно по своей группе. Если пошла информация: сообщение А ушло одному экземпляру канала «metrics», сообщение B – другому экземпляру этого канала (они не перечитывают данные из своего канала).
-
Также в nsqd реализована публикация данных по HTTP из коробки. Это нам понравилось, потому что не нужно делать какую-то компоненту, это может не подойти по безопасности во Фреше: внедрение этой компоненты будет долго тащиться через безопасников. А так – можно просто опубликовать данные через HTTP. Причем есть возможность не подписываться, а именно делать публикацию. Например, как на слайде – мы передаем информацию (тело запроса) и указываем в какой топик мы ее будем класть.
На основании этого мы решили сделать третью архитектуру.
Третья архитектура
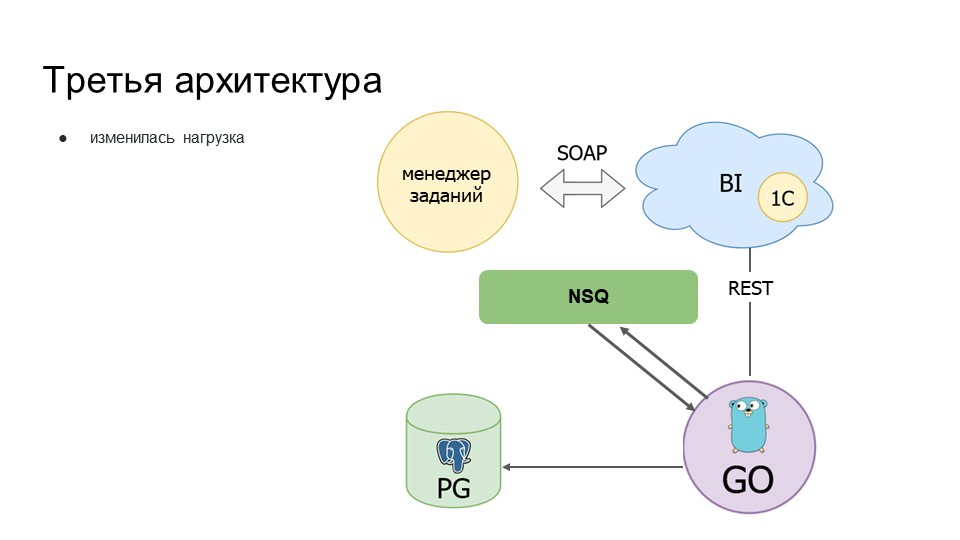
Третья архитектура похожа на вторую, но в нее добавлен брокер сообщений nsqd – при получении данных от BI агент пишет информацию в очередь nsqd.
Также мы разделили агента и того, кто будет получать информацию, подписчика. Если раньше оба этих процесса работали внутри приложения, то теперь подписчик стал собирать информацию из nsqd.
Что это нам дало?
Приложение перестало расти по памяти, перестало падать. Если сообщение уже поставлено в очередь, то его всегда может вычитать другой консьюмер, который подключен к этой очереди.
Единственный недостаток – это незначительная нагрузка на ЦПУ, теперь всегда показывает, что ЦПУ загружено на 50%.
Планы
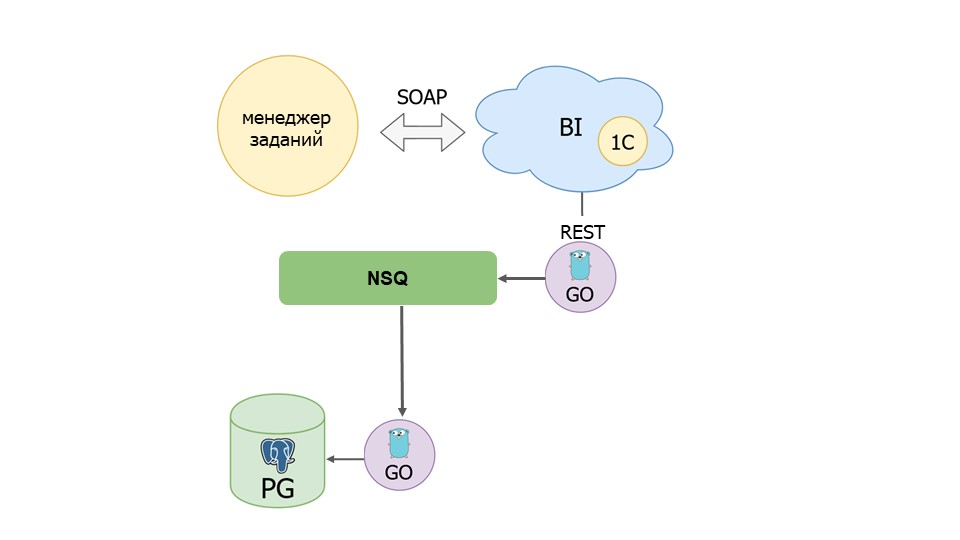
Еще в этом решении нам не понравилось, что в одном приложении у нас реализовано две функциональности: отправка данных и чтение данных из очереди. Мы решили, что в следующей версии у нас будет реализован другой подход, мы разделим нашего агента на две части:
-
одна часть будет получать данные из BI и класть их в очередь,
-
вторая часть – подписчик очереди – то есть, мы ее можем гораздо сильнее масштабировать, получать информацию и класть ее в Postgre.
В дальнейшем мы сможем избавиться от нашего агента – сделать два приложения, которые смогут писать по HTTP в nsqd. Для этого нам нужно будет дописать менеджер заданий и обновить наш модуль обмена.
Вопросы
Расскажите подробнее, что такое NSQ, чем она отличается от RabbitMQ и Kafka, работает ли она через AMQP или у нее какой-то свой протокол?
NSQ больше всего похож на NATS, написан на Go, также как NATS. В нем не нужно тащить себе в инфраструктуру Zookeeper, как это сделано в Kafka. И имеет в архитектуре два приложения – nsqlookupd и nsqd. Экземпляры nsqd хранят в себе информацию о топиках, а nsqlookupd являются для конскьюмеров дискавери до nsqd. Таким образом, мы можем масштабировать у себя и nsqlookupd и nsqd. У нас появится двойная защита в плане отказоустойчивости.
По поводу формата – я особо не вдавался в подробности, какой там формат, потому что у нас реально получилось его затащить и начать использовать за два дня. И пока не было времени вдаваться в подробности, какой там формат. Это был лишь эксперимент. Если в его техническом обслуживании появятся какие-то проблемы, мы его в любое время можем заменить на какое-то более продуктовое решение, которое используется в Enterprise.
Сколько времени заняла реализация всего этого проекта?
Реализация была растянута по времени, было отвлечение на разные моменты. Этот проект у нас длится с 2019 года, он плавно развивается, не особо быстро.
Где производится трансформация в аналитическую модель? В PostgreSQL?
Трансформация производится в Qlik. Забирается информация из разных таблиц и уже аккумулируется в Qlik. Базой Qlik занимаюсь не я, а отдельные аналитики, моя задача – собрать данные.
Рассматривали ли вы архитектуру с использованием выделенной базы 1С, которая содержит актуальную модель данных и аналитику – и наполнение этой базы через событийную интеграцию?
Да, в первоначальной архитектуре мы хранили модели в 1С, но из-за того, что большой объем информации, оптимизировать ее было очень дорого, легче было писать данные в PostgreSQL.
Насколько выходной продукт, написанный на Go, получается быстрее или медленнее по производительности, чем на 1С? Насколько масштабный этот сервис? Или он из пяти строчек состоит?
Он не масштабный, изначально в нем было сделано много, сейчас уже пытаемся привести в порядок код.
В команду Go-программистов входил только ты или у вас еще были специалисты?
Мы стараемся иметь универсальные навыки, разбираться и в Go, и в Python, и в 1С. Мы стараемся растить эти компетенции внутри себя.
Насколько легко у 1С-ников получается осваивать Go, насколько они хотят на нем писать?
Go как второй язык программиста – очень легкий. Основные понятия можно выучить за два дня, посмотрев Go-Tutorial на официальном сайте.
Что, по-твоему, побеждает в холиваре Go vs Java vs Python?
Нам понравился Go, мы попробовали – он зашел. Поэтому был выбран Go. Если для Python есть много возможностей применения – нейросети и т.д., то для Go – это язык для создания инфраструктурных приложений. Писать на нем – красота. Плюс не нужно тянуть никакую Java-машину, они легковесные, Docker-контейнеры там вообще занимают мало места. В плане оптимизации расходов на ресурсы инфраструктуры, Go лучше, чем Java.
А что лучше для написания интеграционных сервисов-прослоек – написать веб-сервис на Python или на Go? Куда лучше вложить силы?
Я думаю, на Go, потому что, если это будет высокая нагрузка, есть смысл делать это на компилируемом языке.
Реализован ли какой-то мониторинг всей этой системы?
Да, это необходимо, мы начинаем это делать. В части агентов – у нас swarm, мы смотрим логи и смотрим на мониторинг swarm.
Оно вообще падает когда-нибудь?
Падает, когда аналитики начинают свои эксперименты во время большой нагрузки – когда они пытаются собрать какую-то свою информацию в период закрытия месяца, когда все вместе начинают все делать одновременно. Скоро это у нас решится добавлением ресурсов, которые мы будем подключать по необходимости. Как раз после распиливания нашего сервиса на агентов и подписчиков мы сможем себе масштабировать подписчиков в зависимости от размера очереди. И тогда у нас в принципе из-за этого проблем не будет – просто будем поднимать или убирать необходимое количество агентов.
Рассматривались ли у вас готовые инструменты для ETL, например, SQL Server Integration Services?
Мы можем ходить только в 1С и не можем ходить в СУБД, в котором лежит 1С. Поэтому у нас такое решение.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Интеграционные решения в 1С".


Вступайте в нашу телеграмм-группу Инфостарт