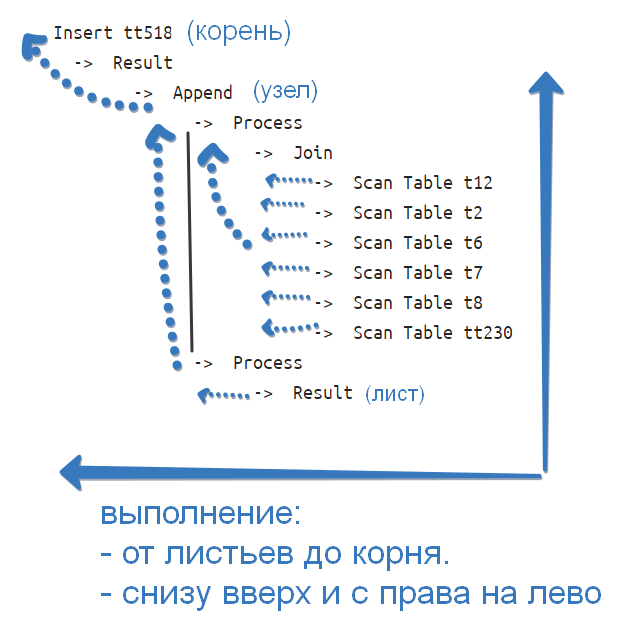































Будем обсуждать, как увидеть или нащупать проблему, как ее попробовать на вкус, понять и решить. По шагам и с картинками рассмотрим весь процесс от диагностики до решения. Приведем критерии оценки проблемы и результаты ее решения. Предлагаемый порядок решения также применим для базы данных на MS SQL Server.
Задача технически сложная, но при структурном подходе вырождается в набор относительно простых и понятных операций, которые можно применить к большинству аналогичных ситуаций. Также рассмотрим неожиданность, с которой столкнулись в процессе. Скажу сразу, на наш взгляд - это платформенныйая баг особенность, которая вынудила нас реализовать «некрасивый» костыль. Ситуация для меня выглядит довольно удручающе при работе в связке 1С+Postgres.
Мы рассмотрим на примере:
- как выполнить поиск проблемы на работающей базе,
- настроить сохранения планов для Postgres,
- анализ планов,
- анализ ошибки самого запроса 1С,
- сравнение поведения запросов на MS SQL и Posgres,
- скрытый баг и экспериментируем,
- пример обхода бага,
- итоговая оптимизация запроса 1С,
- выводы и рекомендации.
Будет познавательно, присоединяйтесь. Готовы… поехали!
Как найти проблему?
Согласитесь, что надо находить проблемы до того, как о них сообщит пользователь, но это не всегда возможно по объективным причинам. Однако, держать руку на пульсе вы просто обязаны. Для выявления этих и подобных проблемных ситуаций мы используем Open Source конфигурацию «Мониторинг производительности». Сейчас, по прошествии нескольких лет ее активного использования, я уже не могу представить себе, что бы я делал без этого замечательного инструмента. Поверьте и проверьте на деле, насколько это удобно - иметь такого помощника в таком сложном и дорогом вопросе.
Открываем базу и в журнале событий замеров ставим отбор по замеру сбора долгих запросов. Если вы вдруг увидели пустой список, не стоит радоваться что у вас в базе все замечательно, такого не бывает. У вас не выгружаются технологические логи, отключены регламентные задания, лежит рабочая база, стоит фильтр по времени замеров, отборы, ошибка разбора или еще что-то. Данные должны быть!
По факту в этом журнале все что заполняется заслуживает внимания и оценки. Но некоторые ситуации обязательны к рассмотрению и обработке. Смотрим на картинку ниже и ищем первую жертву для анализа. Основные критерии поиска — длительность замера, его частота появления, большое количество данных при выполнении запроса.
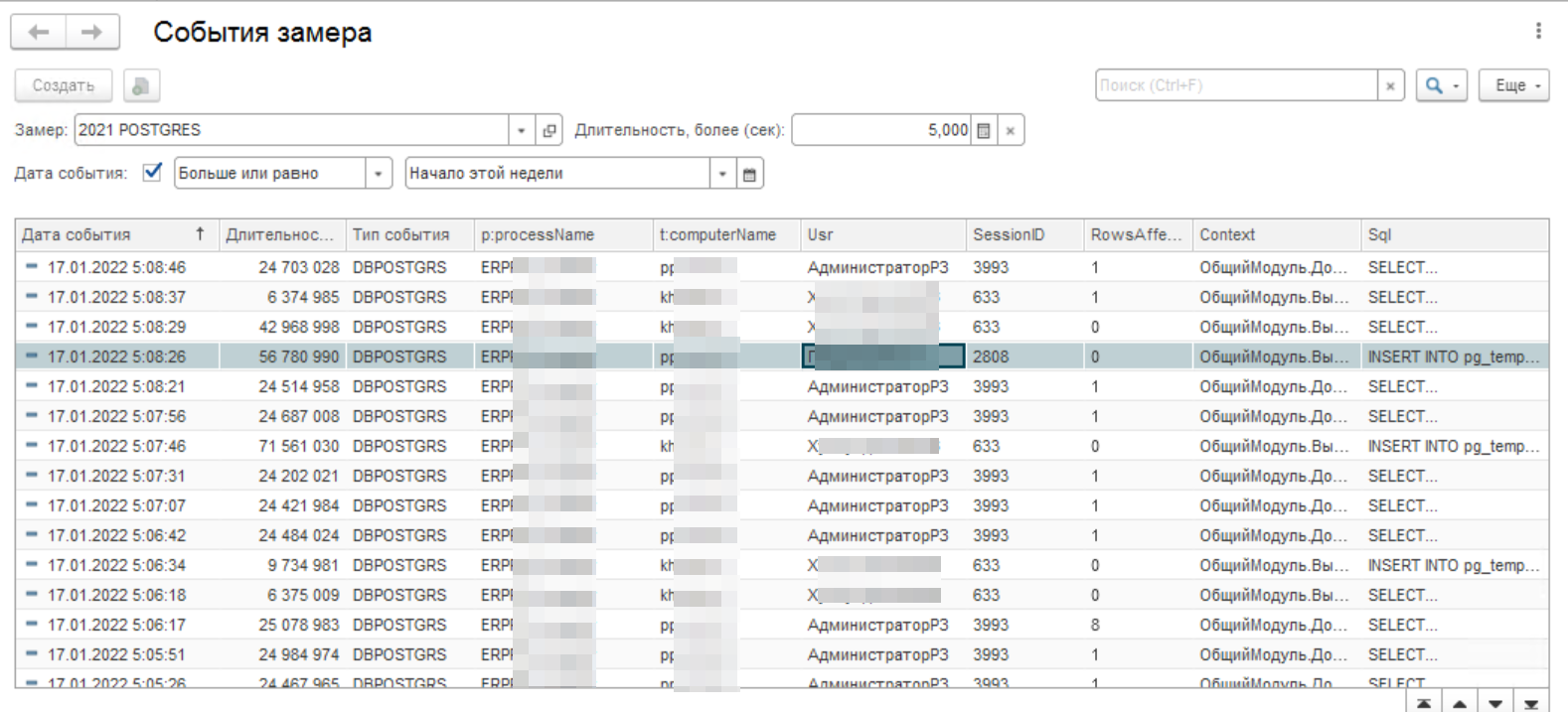
Мы выбрали подозрительную операцию в ~57 секунд длительностью при получении 0 строк.
Следующим шагом узнаем - это случайность или закономерность, т.е. определим частоту ее появления. Сначала на глаз. Для этого откроем контекст ее появления. Двойной клик на поле «Context». И мы получили точку вхождения этой проблемной ситуации — просто, быстро и удобно.

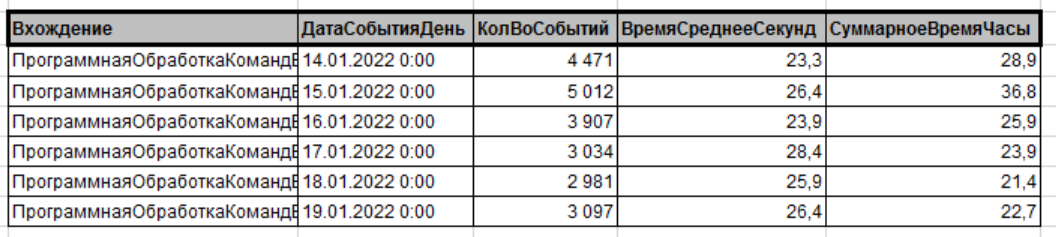
Мы видим, что точка возникновения находится в модуле «ПрограммнаяОбработкаКомандВызовСервера». Теперь добавим отбор на форме по вхождению этого слово сочетания в свойство «Ссылка.Context», как показано на рисунке ниже.
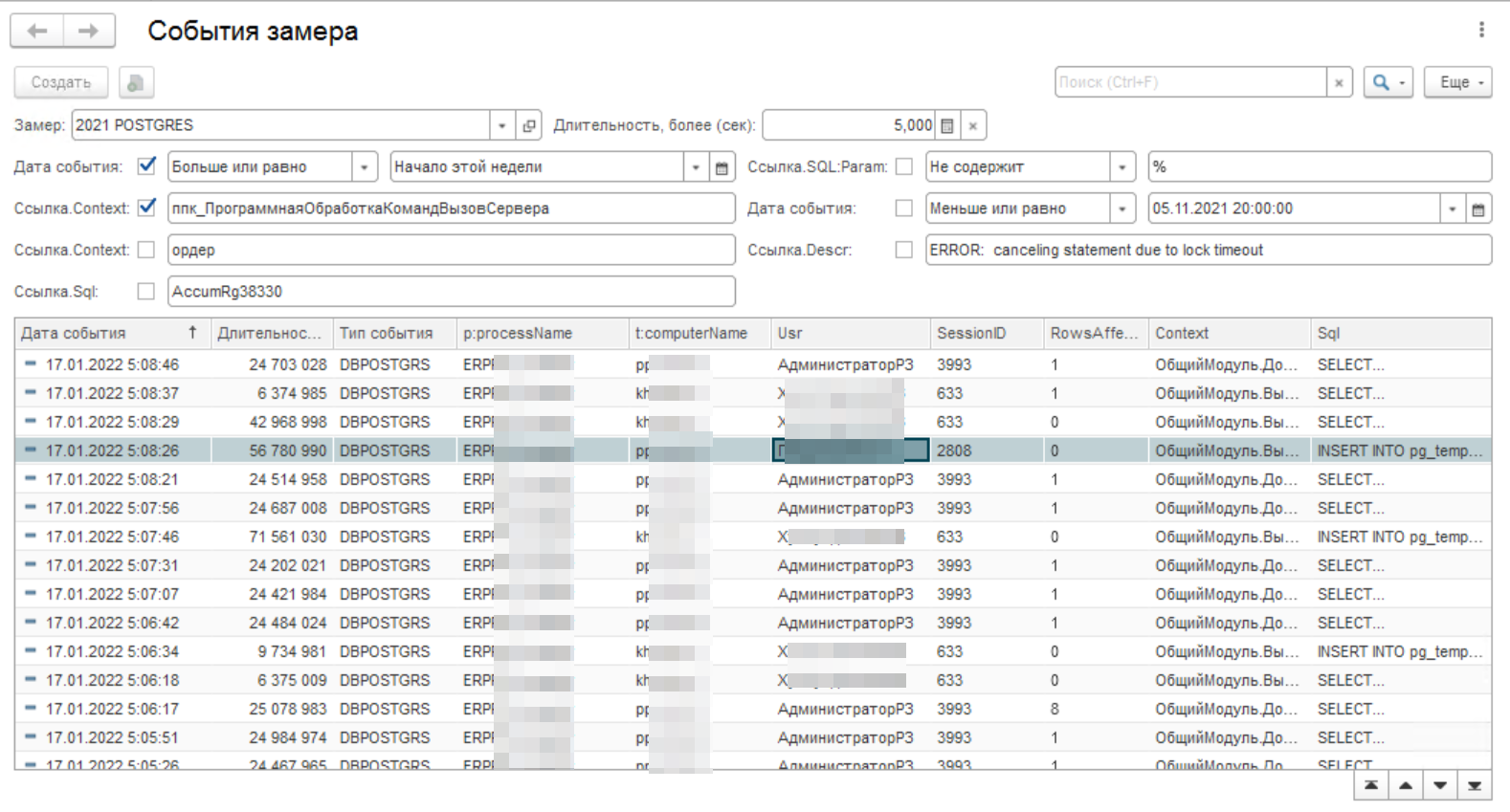
Событий достаточно много. Это не случайны выброс. Мы видим, что время выполнения процедуры не стабильно, повторяется как под пользователями, так и под администратором. У нас явная проблема!

Узнаем временные потери по подобным событиям в событиях замеров. Для этого выполним запрос в консоли запросов (думаю в некотором будущем добавим отчет, но пока консоль). Где замер — это наш замер длительных запросов, свойство - «Context», а значение - «ПрограммнаяОбработкаКомандВызовСервера».
Как мы видим из рисунка ниже, то операция довольно частая и отъедает много процессорного времени.
Мы связались с отделом поддержки пользователей и действительно от пользователей поступали сообщения о замедлении работы в некоторых случаях, которых не было до перехода на Postgres SQL с Microsoft SQL.
Также если присмотреться к данным на списке, то мы видим неестественно долгую работу служебного пользователя. Обратите внимание, что номер сессии (SessionID), один и тот же на протяжении большого промежутка времени. Это подтверждается данными по замерам RAS 1C.
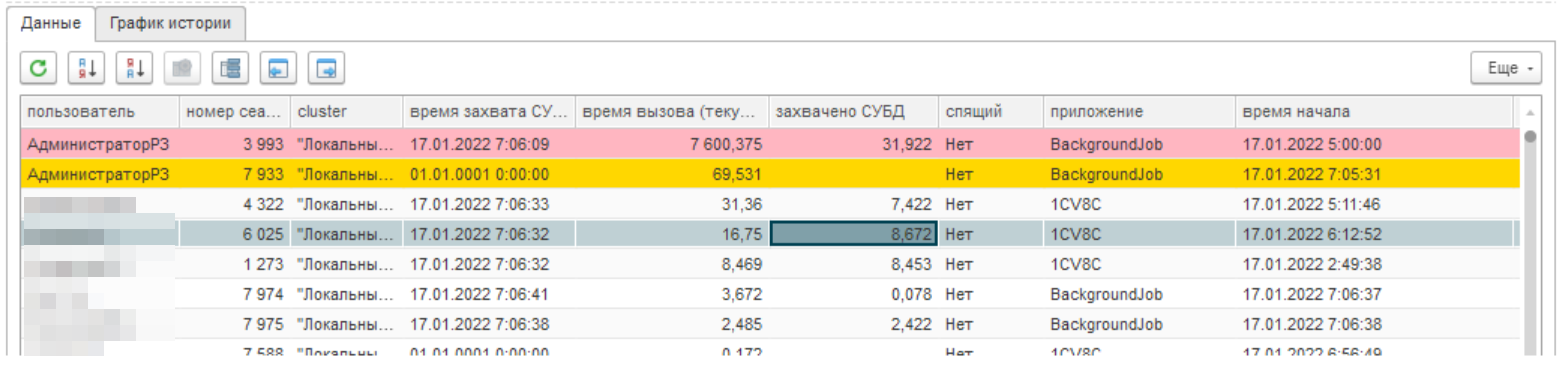
На рисунке мы видим того же пользователя, совпадающий номер сессии и время выполнения, начало сеанса. Время работы неестественно большое — больше 2х часов.
Если вы были внимательны, то должны были заметить, что на списке проскакивали запросы начинающиеся с «SELECT...» и «INSERT...». Откроем второй контекст:

Точки начала проблемы разные, но позиция возникновения одна и та же. Тут у нас пакетный запрос с промежуточными временными таблицами. Давайте двигаться дальше.
Настройка сохранения планов для длительных запросов на Postgres.
Одним из самых быстрых способов увидеть явную проблему — это просмотр плана запроса в графическом представлении. Первым шагом надо получить сам текст плана запроса. Давайте посмотрим как это сделать.
На Postgres увидеть план запроса относительно удобно можно в двух вариантах:
- подключить модуль auto_explain
- выполнить запрос в консоли (pgAdmin) с командой в начале запроса explain analyze.
Второй вариант не всегда просто осуществим, особенно когда у вас сам проблемный запрос использует временные таблицы. Поэтому пока предлагаю воспользоваться первым вариантом.
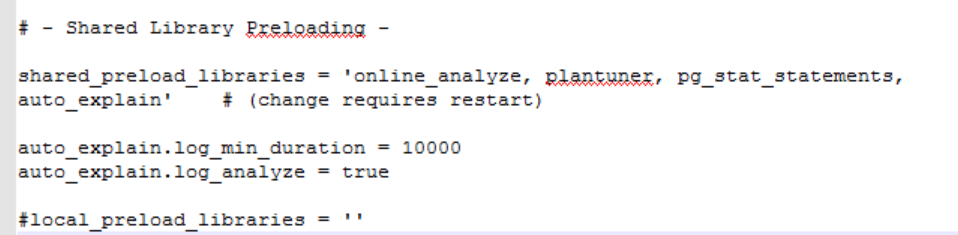
Если у вас еще не настроено, то попросите администратора или сами найдите файл «postgresql.conf» и измените его. Откройте этот файл в редакторе, найдите строку «shared_preload_libraries» и добавьте через запятую необходимость загрузки еще одного модуля - «auto_explain». Далее Вам необходимо еще добавить основные настройки этого модуля:
- длительности «log_min_duration» длительность ловли запросов в мс
- флаг «log_analyze» в истина.
У нас это уже настроено, поэтому мы открываем файл лога и ищем искомый план запроса. Переходим в папку с логами обычно она называется – «pg_log». Ищем файл текущего дня и открываем его в текстовом редакторе, советую использовать «Notepad++». В файле лога интересующая нас текстовая область имеет следующую структуру:
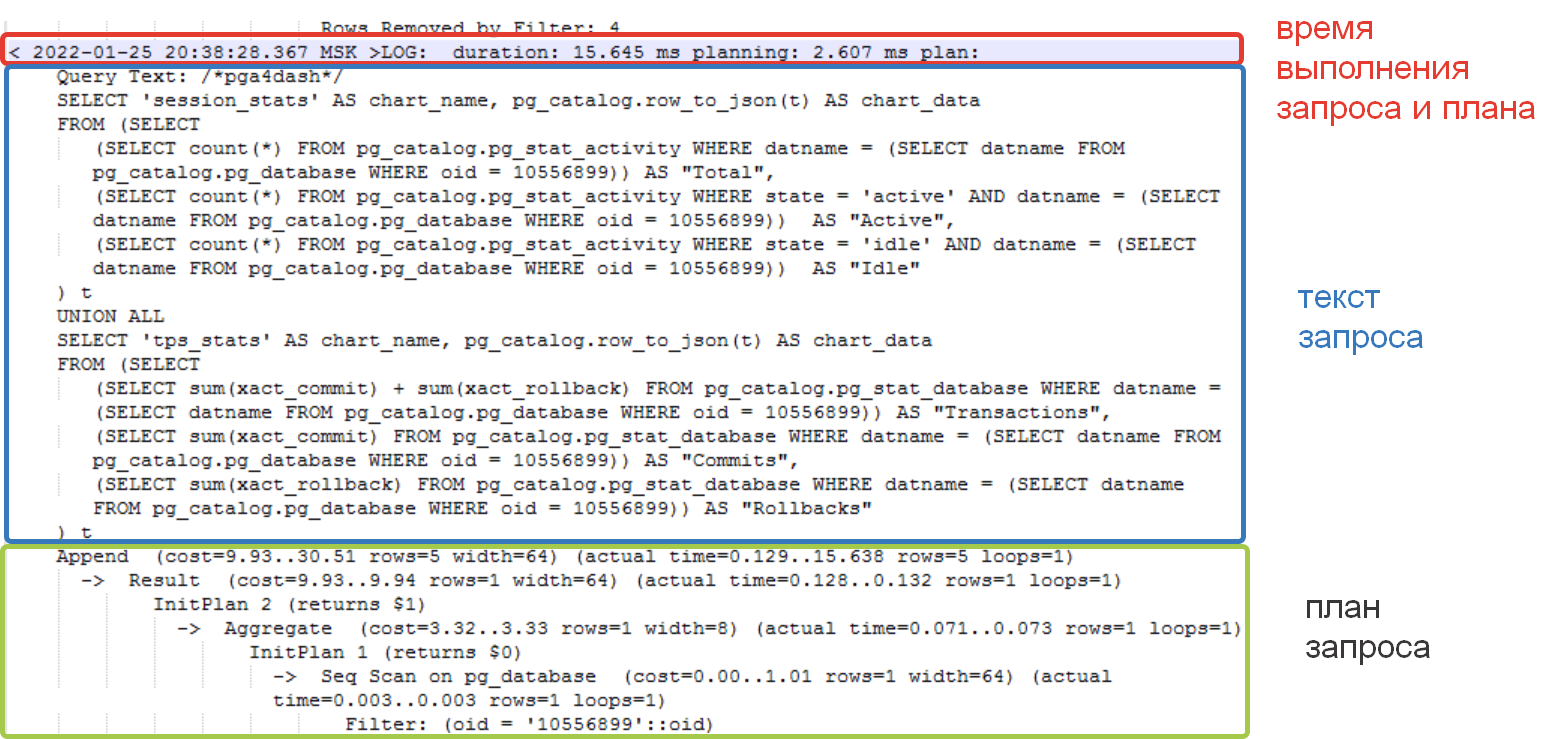
Чтобы найти интересующий нас план можно воспользоваться двумя вариантами — поиск по дате или вхождению в текст запроса. Есть еще третий - установка сервиса разбора лога, но это отдельная тема. Возвращаемся в список длительных замеров монитора. Открываем карточку анализируемого проблемного события производительности и копируем дату, либо часть запроса из SQL поля.
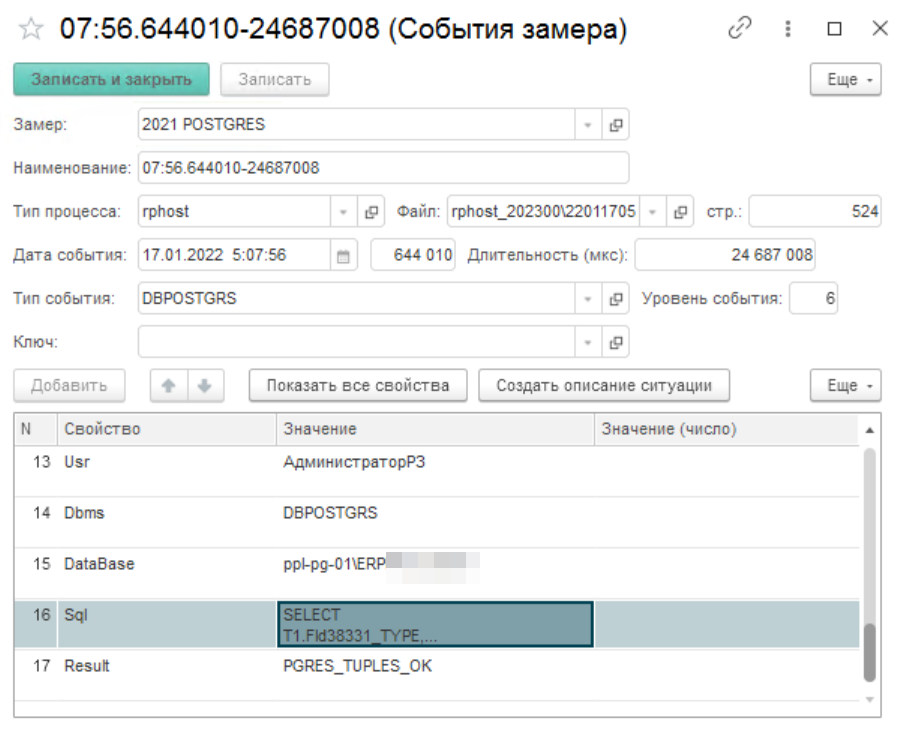
Будем искать план запроса для события с вхождением в текст SQL «SELECT...». При поиске мы воспользуемся датой - «17.01.2022 5:08:21». Начинаем искать по часу и минуте (секунды могут не совпадать).

Время начала и длительность выполнения совпадают. Текст запроса такой же.
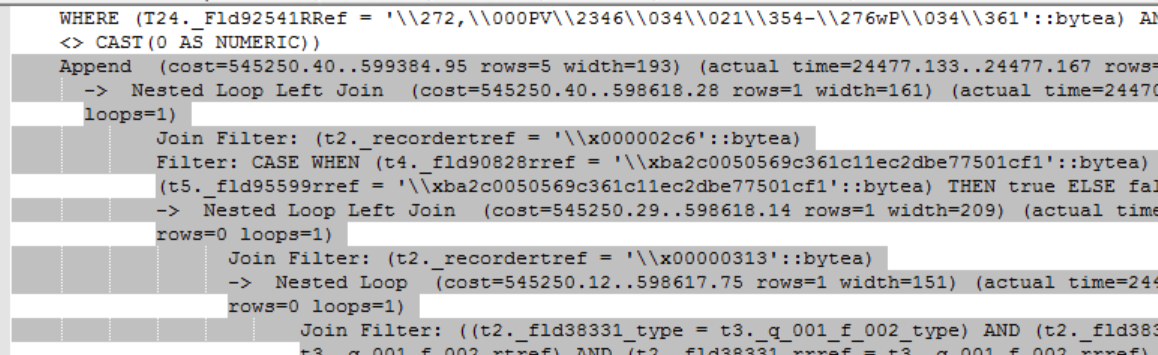
То что мы с Вами тут видим похоже на «китайскую грамоту». Чуть позже мы с этим разберемся. А сейчас копируем план запроса - все то, что имеет вхождение стрелок (это текстовое представление плана запроса). И переходим к началу анализа проблемы.
Анализ плана запроса
У нас есть текст плана запроса — это здорово! Но смотреть и анализировать такое текстовое описание с представлениями таблиц и полей в терминах SQL тяжело, а еще учитываем что в большинстве своем запросы содержат несколько листов текста, то вообще не реально. Привет экспертам 80-го уровня! Я думаю эти парни уже научились компилировать в голове, но мы пойдем другим путем.
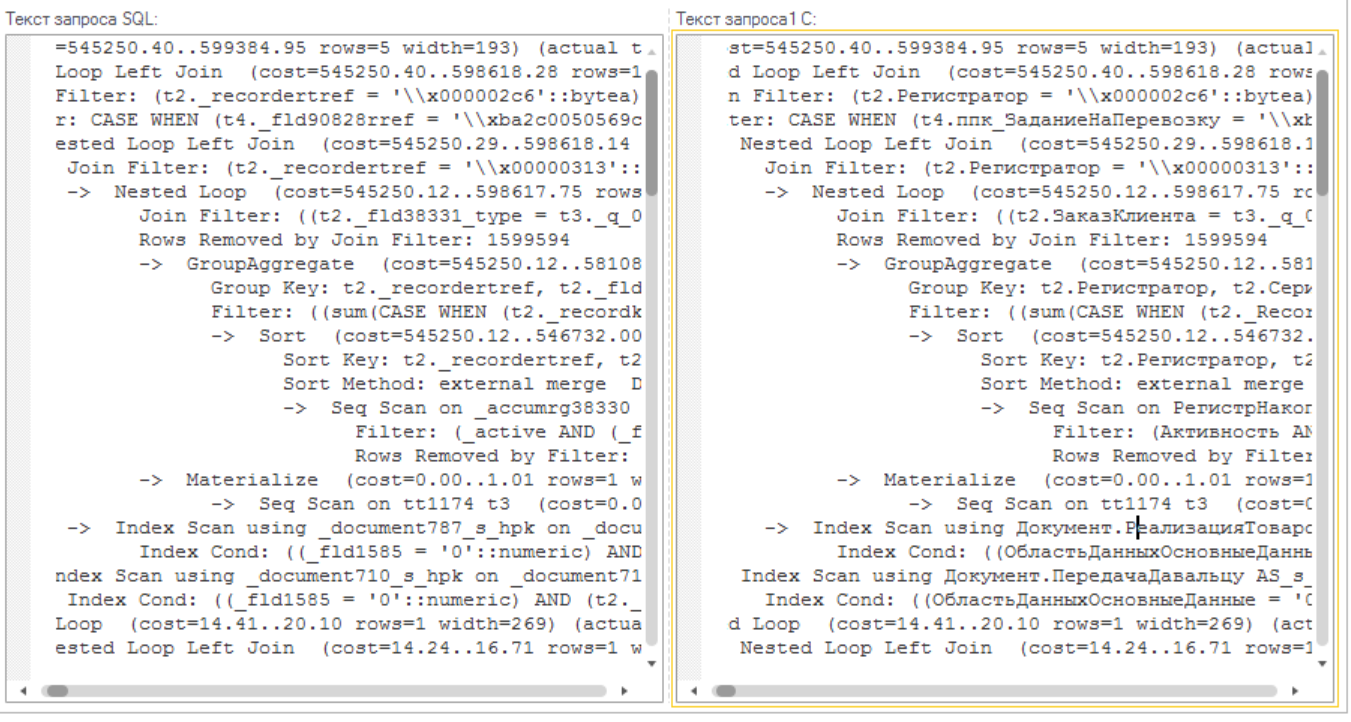
Преобразуем представления таблиц и полей в формат представления метаданных целевой конфигурации 1С. Для этого воспользуемся обработкой «Конвертер запросов SLQ в 1С». С помощью этой обработки мы приведем тексты запросов и сами планы в более понятную форму, а как бонус для Postgres сможем открыть схему плана запроса в один клик.

Посмотрите на картинку преобразования. Согласитесь, что результат с подстановками выглядит гораздо понятнее.

План запроса пока еще непонятный, но проскакивают знакомые названия таблиц метаданных и реквизитов. Еще чуть-чуть терпения, и мы посмотрим готовый результат.
Теперь жмем на кнопку «Explain» для выполнения передачи данных через API на сайт. После появления ссылки жмем по кнопке «Открыть веб адрес» и идем разбираться что у нас получилось.

https://explain.tensor.ru/archive/explain/365dbbcf3d5c1bccc9ced18d3678a0fe:0:2022-02-18#visio
Мы видим следующую картинку (см. ниже). Сайт дружелюбно подсвечивает нам красным цветом проблемные операции. Чем жирнее цвет, тем проблема выражена сильнее.
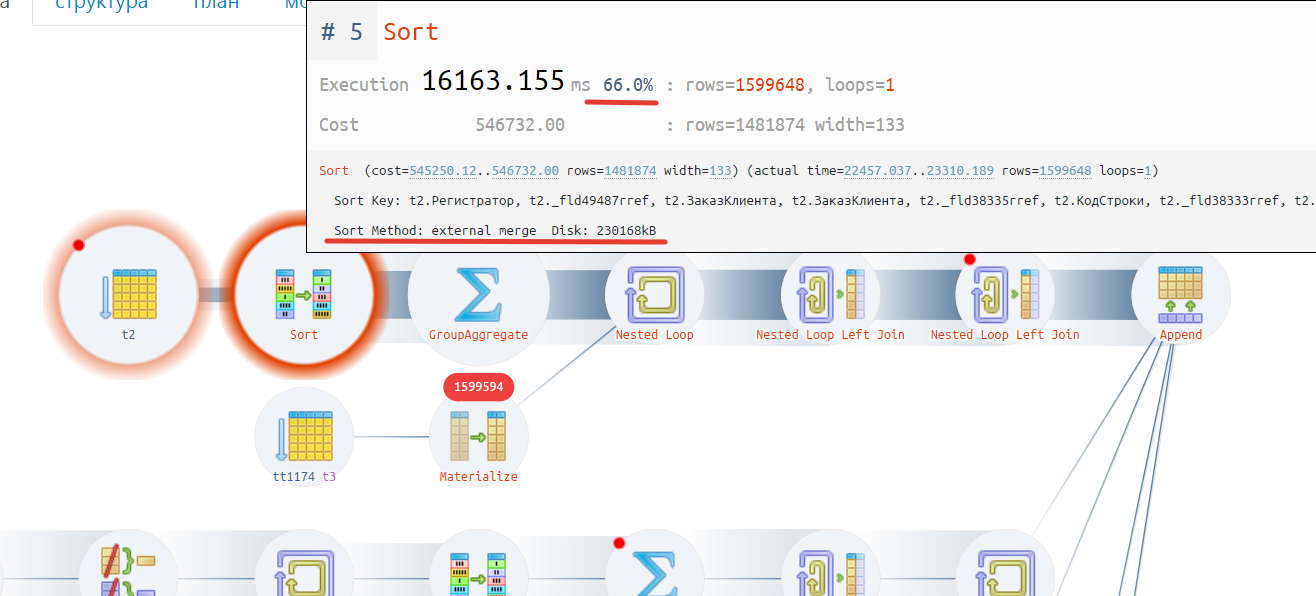
Это два круга — сортировка 66% времени выполнения и сканирование таблицы 29%. Итого из 24 секунд запроса эти два блока занимают у нас 95% времени выполнения. Цель оптимизации определена — снизить накладные затраты на эти два оператора.
На что обращать внимание при анализе плана запроса? Красные и жирные кружки - это понятно, а что они могут сообщать нам?
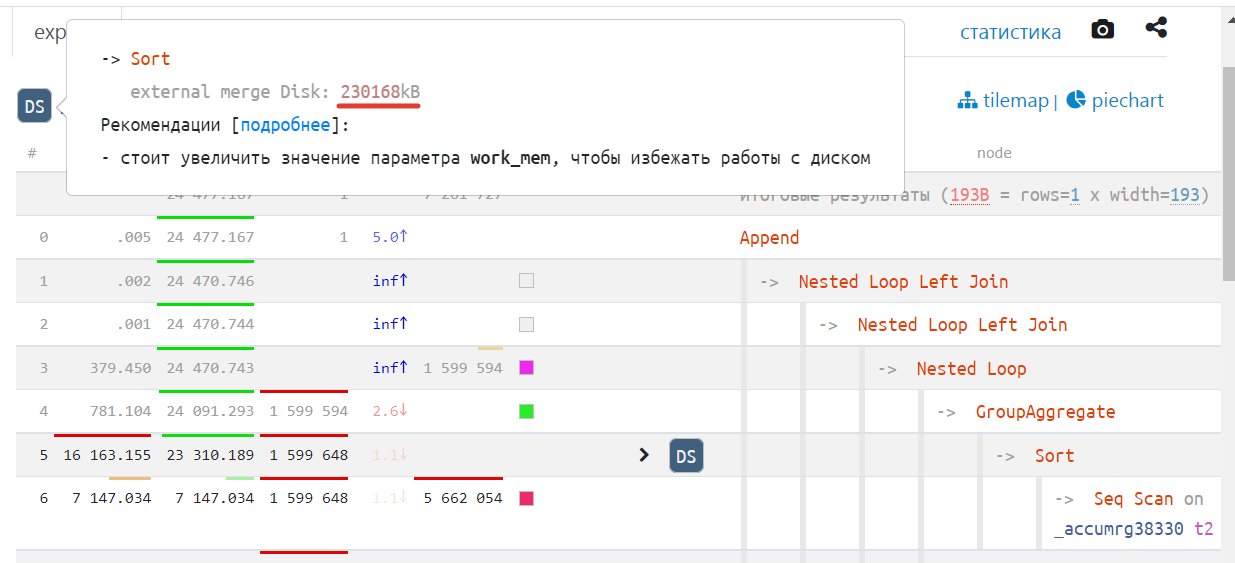
Смотрим дальше и жмем мышкой на оператор «Sort» и автоматически переключаемся на вкладку «explain» (объяснение).
Тут мы видим подсказку. Выполняется сортировка не в памяти, а на диске. Из-за того что выбирается более 200 МБ данных на запрос. Тут надо пойти в настройки у увеличить некоторые рабочие параметры выделения доступной памяти (work_mem), но обратите внимание, что данных у нас выбиралось для пользователя ровно 1 строка (видно на самой схеме) и она явно занимает совсем немного памяти. Поэтому проблема гораздо шире.
Теперь вернемся на диаграмму и посмотрим на второй оператор «Seq Scan».

Согласитесь с представлениями метаданных разбирать план запроса удобно). Обратим внимание, что текущая ситуация не оптимальна, у нас выполнялось сканирование «Seq Scan» («Table Scan» – MS SQL). Было отобрано ~ 1.6 млн записей и отброшено ~5.7 млн записей (RRbF – строк удалено фильтром), а вы помните что в итоге должна остаться 1 запись. По факту для выполнения этого запроса была бессмысленно просканирована вся таблица регистра.
Мы видим что это сканирование и дальнейшая сортировка выполняется по регистру накопления «Заказы Клиентов». Давайте смотреть что у нас с запросом 1С. Что искать нам примерно ясно.
Анализируем запрос на языке запросов 1С
Настало время открыть конфигурацию и посмотреть на внутренности. Вспоминаем описание точки возникновения проблемы - это находится в описание «Context» для выбранного события замера. Открываем необходимый модуль и идем на соответствующую строку «2764» с помощью сочетания клавиш - «Ctrl+G» .
Мы помним, что проблемный кусок кода был связан с регистром накопления «Заказы клиентов». Работа с регистром встречается у нас в одном месте.
//...
ВЫБРАТЬ РАЗРЕШЕННЫЕ
ЗК_Об.ЗаказКлиента КАК Распоряжение,
ЗК_Об.КодСтроки КАК КодСтроки,
ВЫРАЗИТЬ(ЗК_Об.Регистратор КАК Документ.ЗаказКлиента).АдресДоставки КАК АдресДоставки,
вт_ТоварыКДоставке.Склад КАК Склад,
ЗК_Об.Номенклатура КАК Номенклатура,
ЗК_Об.Характеристика КАК Характеристика,
ЗК_Об.Серия КАК Серия,
ЗК_Об.КОформлениюРасход КАК Количество
ИЗ
РегистрНакопления.ЗаказыКлиентов.Обороты(, , Регистратор, ) КАК ЗК_Об
ВНУТРЕННЕЕ СОЕДИНЕНИЕ вт_ТоварыКДоставке КАК вт_ТоварыКДоставке
ПО ЗК_Об.ЗаказКлиента = вт_ТоварыКДоставке.Распоряжение
И ЗК_Об.КодСтроки = вт_ТоварыКДоставке.КодСтроки
И ЗК_Об.Номенклатура = вт_ТоварыКДоставке.Номенклатура
И ЗК_Об.Характеристика = вт_ТоварыКДоставке.Характеристика
И ЗК_Об.Склад = вт_ТоварыКДоставке.Склад
И ЗК_Об.Серия = вт_ТоварыКДоставке.Серия
ГДЕ
ЗК_Об.КОформлениюРасход <> 0
// и т.д. ...
На рисунке ниже я соединил части запроса со схемой, чтобы было более понятно.
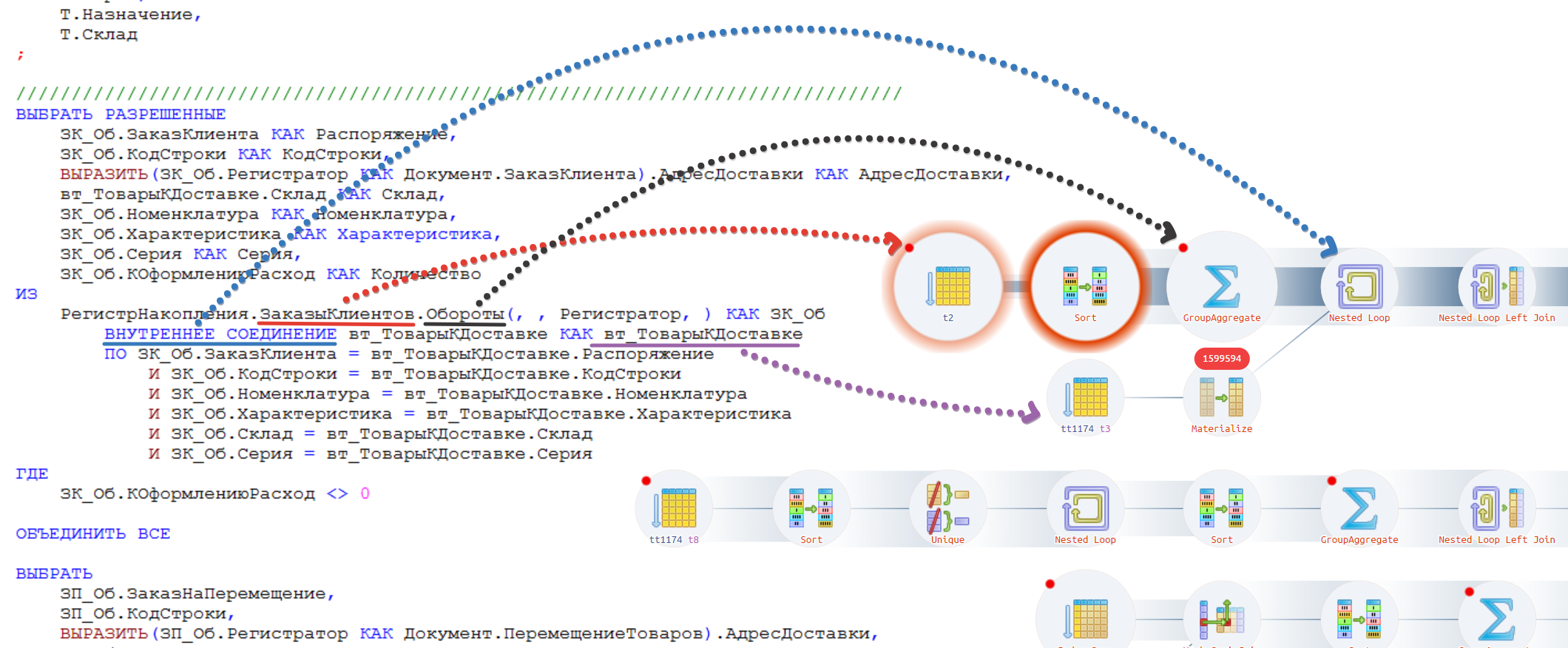
Давайте рассмотрим, что тут происходит:
1. Первая линия показывает как формируется виртуальная таблица оборотов регистра «Заказы клиентов»:
- сначала сканируется вся реальная таблица регистра (красная стрелка),
- потом формируется сама виртуальная таблица — это операции сортировки и агрегирования (черная стрелка)
2. Далее подготавливается временная таблица (фиолетовая стрелка)
3. Они соединяются оператором «Nested Loop» (синяя стрелка)
4. Далее еще накладываются некоторые отборы и соединения, а в конце происходит объединение оператором «Append» (это осталось вне картинки)
1С рекомендует делать отборы внутри виртуальной таблицы, давайте исправим и перенесем соединение внутрь как условие с оператором «В», учитывая, что записей в таблице у нас совсем мало это очень актуально.
Если посмотреть другие таблицы запроса, то мы видим, что там отборы стоят внутри виртуальной таблицы. И представление плана запроса отличается. Давайте исправлять.
Оптимизация запроса
Исправляем запрос в соответствии с рекомендациями и смотрим его выполнения на демонстрационном стенде (нет нагрузки поэтому выполняется относительно быстро). Для этого используем любую консоль запросов. Добавляем отбор по временной таблице внутрь виртуальной таблицы «Заказы клиентов». Для упрощения, мы не стали добавлять в запрос остальные таблицы.
//...
ВЫБРАТЬ РАЗРЕШЕННЫЕ
ЗК_Об.ЗаказКлиента КАК Распоряжение,
ЗК_Об.КодСтроки КАК КодСтроки,
ВЫРАЗИТЬ(ЗК_Об.Регистратор КАК Документ.ЗаказКлиента).АдресДоставки КАК АдресДоставки,
вт_ТоварыКДоставке.Склад КАК Склад,
ЗК_Об.Номенклатура КАК Номенклатура,
ЗК_Об.Характеристика КАК Характеристика,
ЗК_Об.Серия КАК Серия,
ЗК_Об.КОформлениюРасход КАК Количество
ИЗ
РегистрНакопления.ЗаказыКлиентов.Обороты(
,
,
Регистратор,
(ЗаказКлиента, КодСтроки) В
(ВЫБРАТЬ
вт_ТоварыКДоставке.Распоряжение,
вт_ТоварыКДоставке.КодСтроки
ИЗ
вт_ТоварыКДоставке КАК вт_ТоварыКДоставке)) КАК ЗК_Об
ВНУТРЕННЕЕ СОЕДИНЕНИЕ вт_ТоварыКДоставке КАК вт_ТоварыКДоставке
ПО ЗК_Об.ЗаказКлиента = вт_ТоварыКДоставке.Распоряжение
И ЗК_Об.КодСтроки = вт_ТоварыКДоставке.КодСтроки
И ЗК_Об.Номенклатура = вт_ТоварыКДоставке.Номенклатура
И ЗК_Об.Характеристика = вт_ТоварыКДоставке.Характеристика
И ЗК_Об.Склад = вт_ТоварыКДоставке.Склад
И ЗК_Об.Серия = вт_ТоварыКДоставке.Серия
ГДЕ
ЗК_Об.КОформлениюРасход <> 0
//...
Выполняем, преобразуем запрос и отправляем на сайт. Смотрим картинку, смотрим как изменился план запроса.
https://explain.tensor.ru/archive/explain/744b7237f889467e1d08f400507caf27:0:2022-02-21#visio
Мы видим, что фильтр стал ближе к оператору считывания данных из таблицы регистра. Далее выполняется агрегация или создается виртуальная таблица оборотов (см. рисунок ниже).
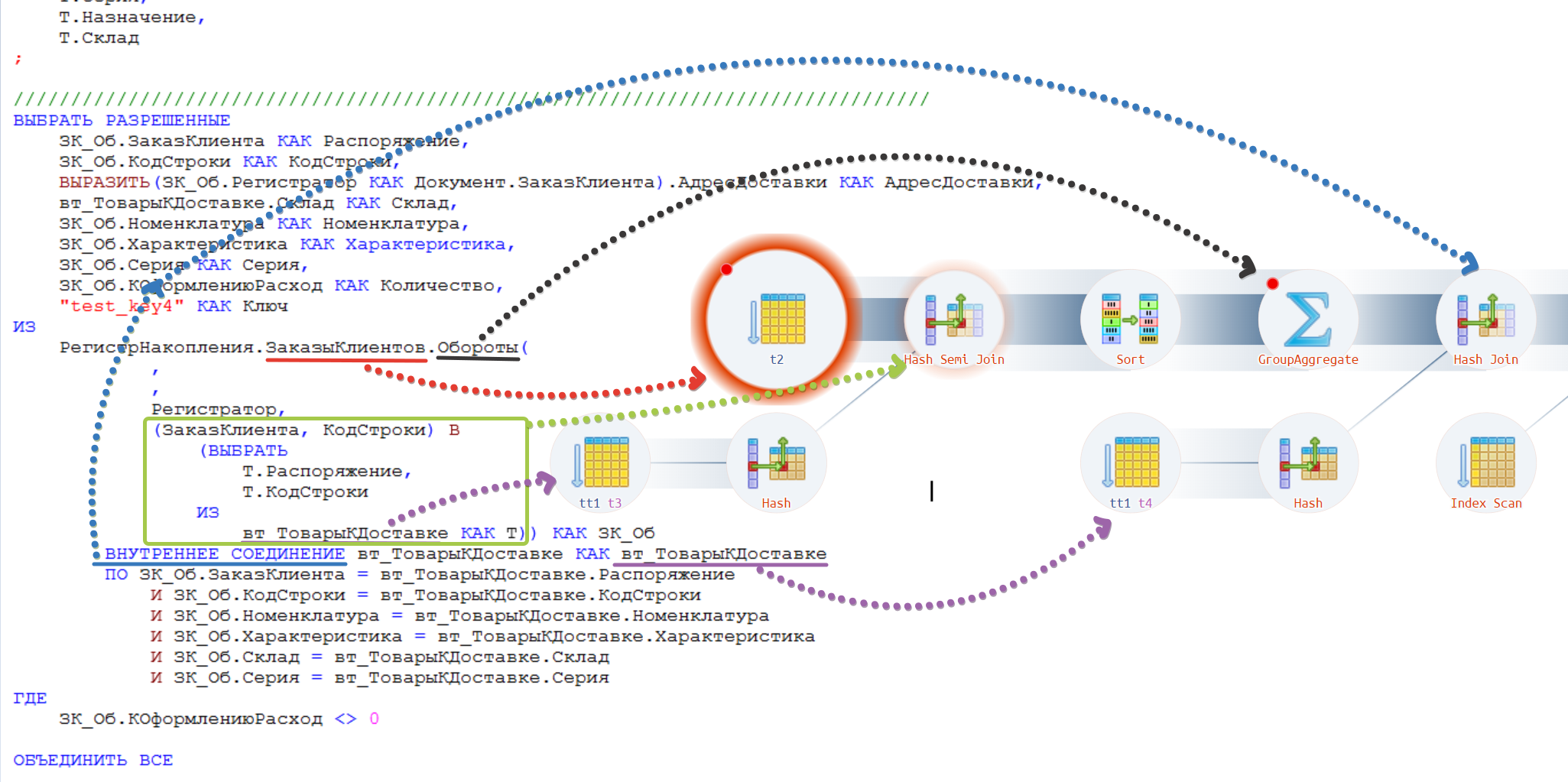
Запрос стал более оптимальным, т.к. мы уже агрегируем не все записи регистра, а только набор искомых строк — в нашем случае всего одну строку. Также исчез оператор сортировки на внешнем диске, теперь она выполняется в памяти.
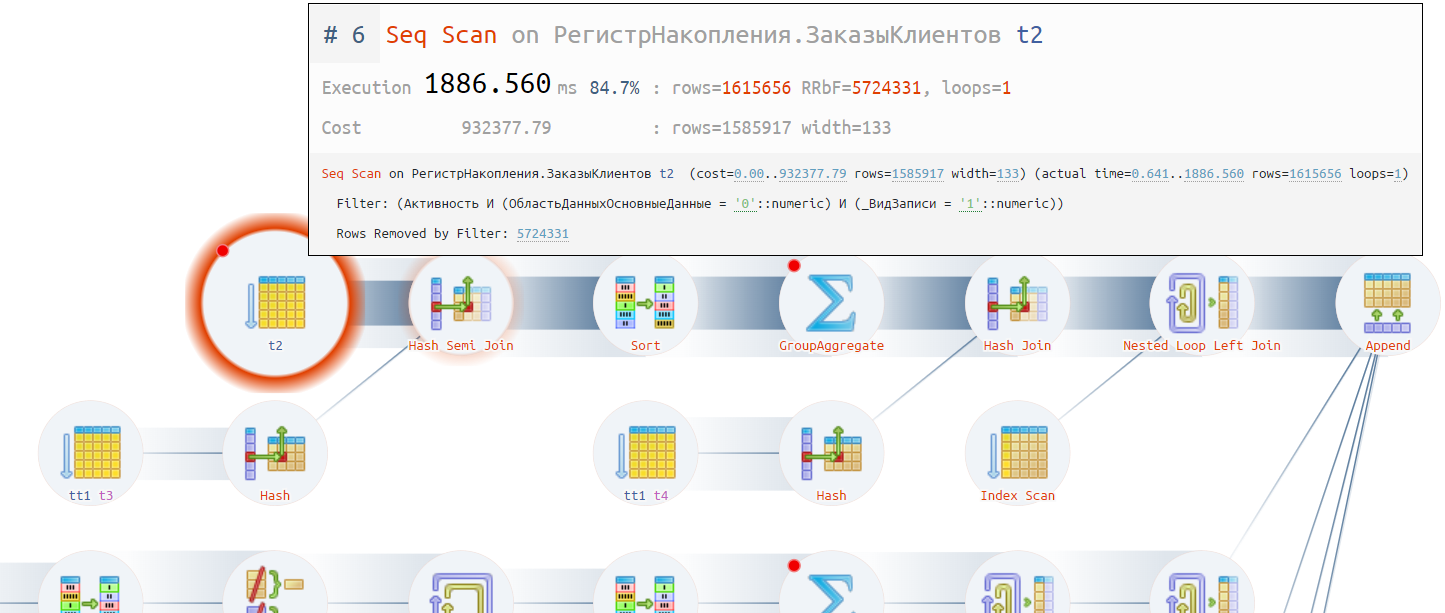
Однако, мы все еще видим большой и красный круг. Сканирование не исчезло (оператор под номером «#6» или t2 на картинке), а осталось. Мы здесь ожидали увидеть уже сканирование по индексу, а не перебор практически всех записей в поисках одного единственного распоряжения. Такое поведение может быть если не хватает таблицы индексов. Идем и смотрим в конфигурацию или конвертер. Убеждаемся, что индекс у нас присутствует по измерению «Заказ Клиента».
Если посмотреть внимательнее на план запроса, то мы видим что существует странный фильтр по полю заказа клиента для оператора под номером «#5» - очень странное условие. Первый маленький звоночек. К этому вопросу мы вернемся ниже в сравнении.
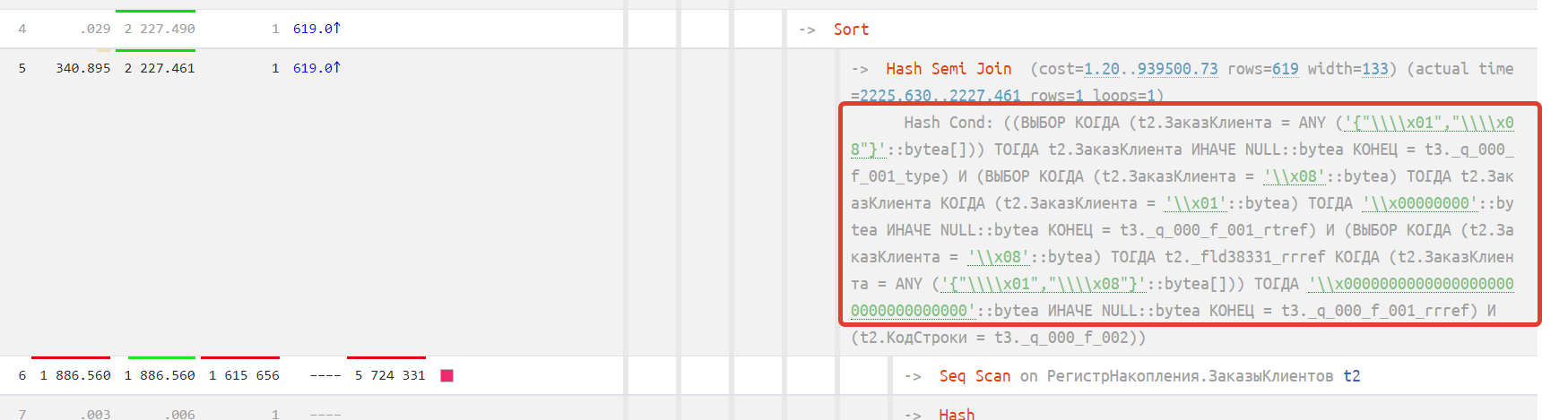
Мы вспоминаем, что в MS SQL у нас запрос выполнялся достаточно быстро. Давайте выполним ту же операцию на другой СУБД, посмотрим тексты запросов и их планы.
Сравнение MS SQL и Postgres.
Запрос выполняем через консоль и ловим через профайлер или расширенные события, мы про это рассказывали ранее.
План запроса мы получили, но он опять сложный и не читаемый. Давайте его сохраним и преобразуем через конвертер. Для этого открываем файл через текстовый редактор, преобразуем и сохраняем обратно.
Открываем в SQL Sentry Plan Explorer и смотрим.
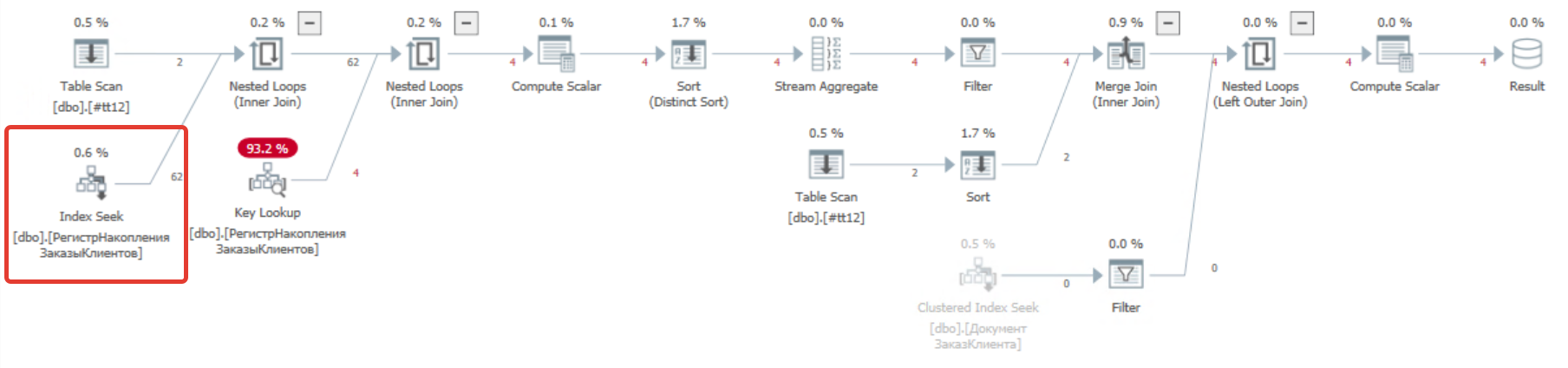
Структурно план запроса похож на план запроса для Postgres. Вместо соединения Hash Join используется Nested Loop. И ожидаемо вместо сканирования таблицы регистра используется оператор Index Seek (красный квадрат на рисунке) по таблице индекса для измерения «Заказ клиента». Ниже на рисунке приведено описание для этого оператора.
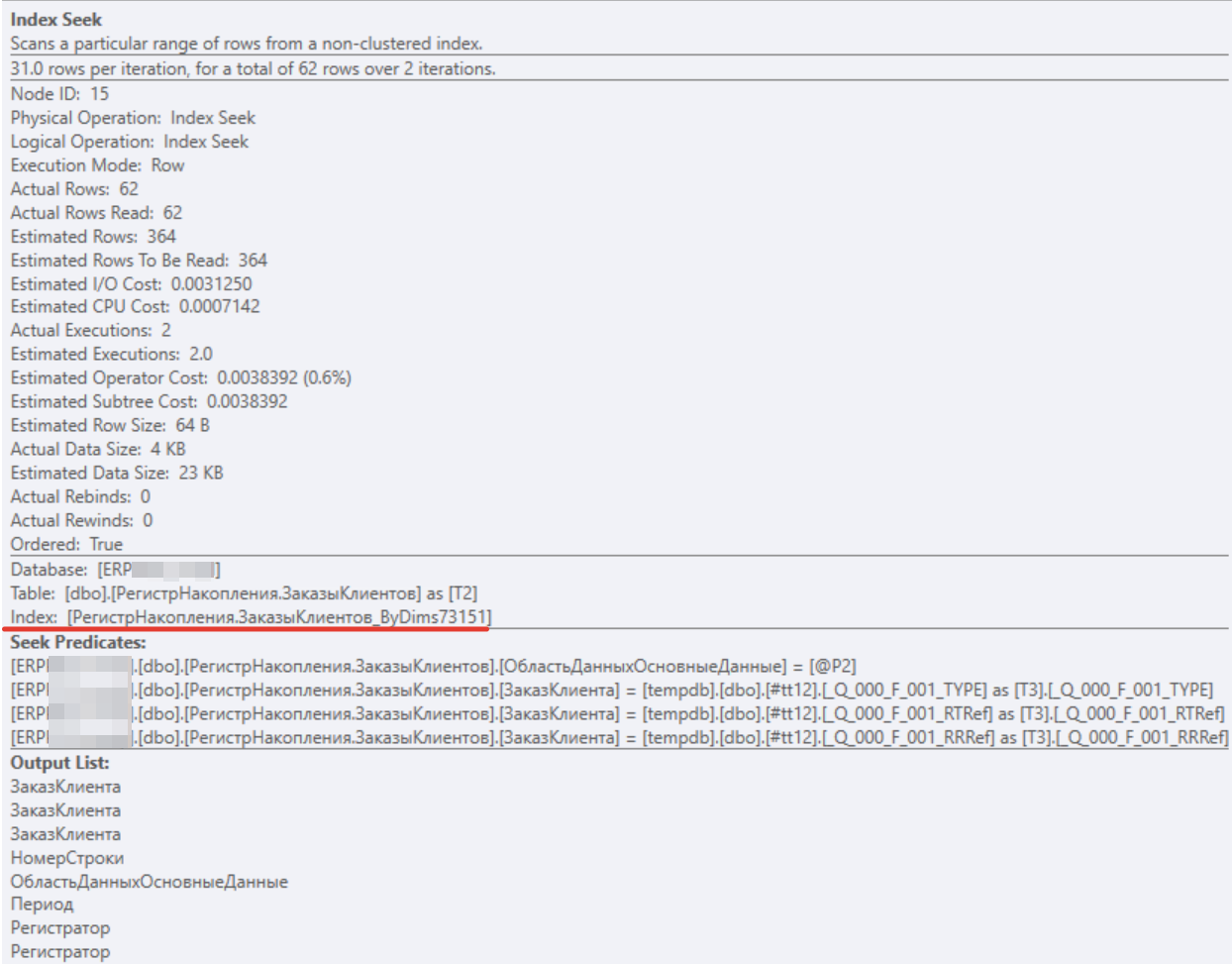
Делаем вывод, что у нас хороший план и хороший запрос.
Самое интересное, что если посмотреть план первоначального не оптимизированного запроса на MS SQL, то он будет выглядеть практически также и даже проще. Это говорит о том, что планировщик от мелко мягких очень умный.

Давайте сравним два текста запроса.
Опять же смотреть тексты запросов тяжело. Преобразуем через обработку и начинаем смотреть интересующий нас кусок запроса. Тот где происходит фильтрация внутри виртуальной таблицы:
Посмотрим на отличия этих двух запросов на картинке ниже.

Отличия следующие:
- в MS SLQ используется «Exist», в Postgres «In». В данном случае эти операторы логически эквивалентны.
- в фильтре для измерения «Заказ клиента» в Postgres стоит непонятное для нас преобразование. По нашим предположениям это преобразование заказа клиента с условием по типу «Неопределенно». Для чего Платформа 1С так делает не понятно, похоже на какие-то старые хвосты в алгоритме.
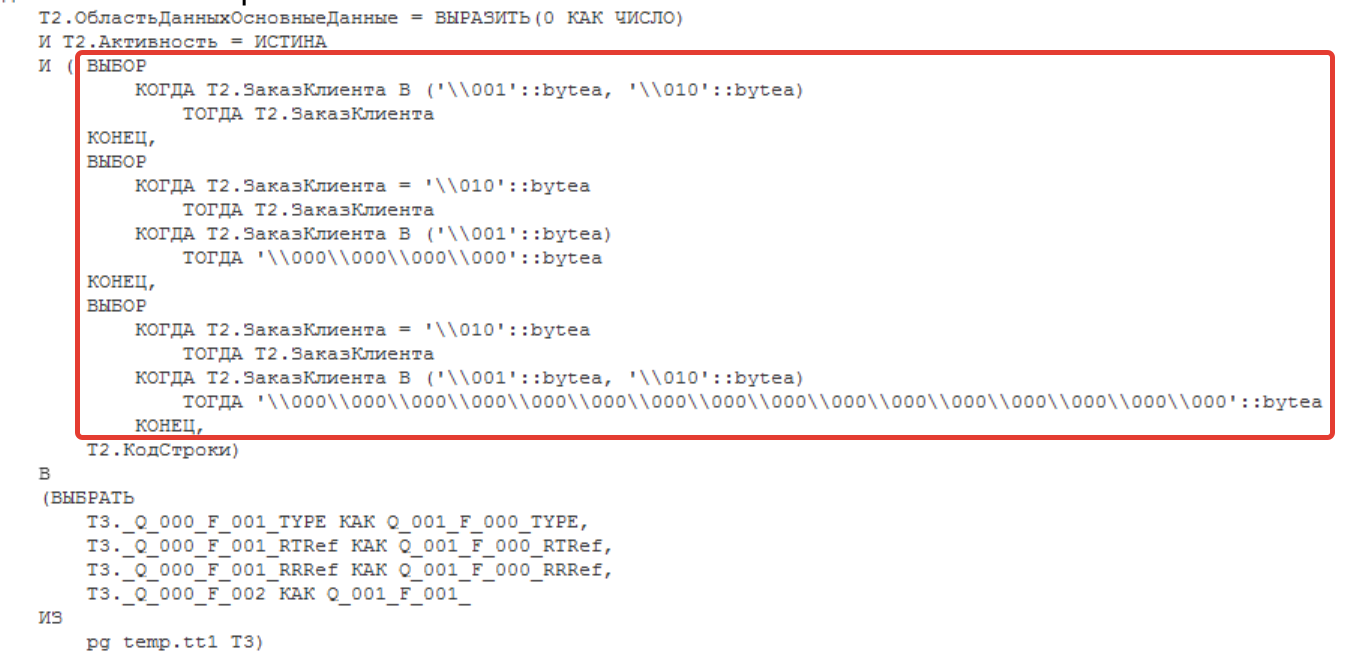
Давайте выполним запрос в консоли PG Admin для Postgres, без этого преобразования. Берем текущий SQL запрос. Добавляем в его начало «explain analyze», чтобы вместо вывода таблицы данных у нас отобразился план запроса. И в начало добавляем создание временной таблицы. Мы поступим хитро и получать данные будем из того же регистра. Идея должна быть понятна, полный код ниже.
Выполняем запрос с использованием explain analyze. И видим следующий план запроса.
https://explain.tensor.ru/archive/explain/c949d73fe2e708db58ab28ac6d39dcad:0:2022-02-22#visio
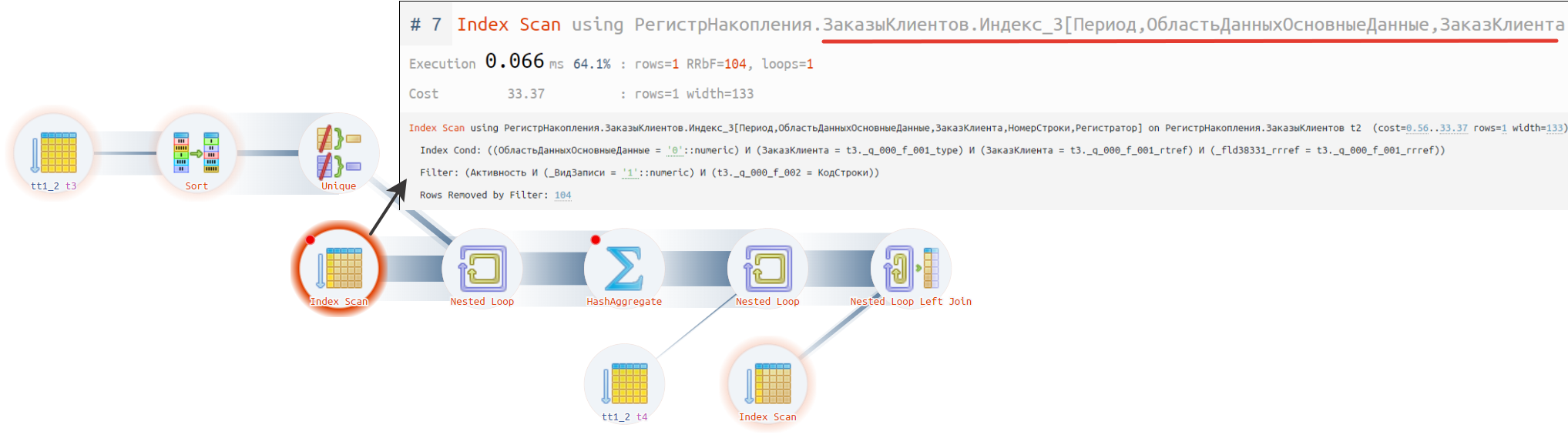
Теперь картинка, та которая должна быть. Используется индекс с отбором по заказу клиента. Время выполнения сократилось с 1860 млс до 0.066 млс - это быстрее почти в ~30 000 раз!
Давайте будем думать, какой нужен костыль или как исправить исходный запрос на языке запросов 1С, чтобы он оптимально работал после преобразования Платформы 1С. Дальнейшие эксперименты распишем ниже.
Смотрим на баг и экспериментируем
Я уже устал набивать текст и делать картинки, поэтому выкладки и планы опущу. Приведу результаты экспериментов для платформы 8.3.16.
1. Если вместо временной таблицы использовать параметр запроса, то поведение оптимальное.
2. При выполнении запроса без временной таблицы, а с использованием реальной показал, что индекс используется. Решение нам не подходит, т.к. текущая временная таблица используется в пяти объединениях.
3. Выполним приведение типов через оператор выразить. Это преобразование необходимо сделать для всех типов документов входящих в составной тип для временной таблицы. Потом обязательно добавить в виртуальную таблицу условие по «И» с выбором составного поля. Работает оптимально, только выглядит не как «костыль», а как «костылище». Если же у вас в таблице должен быть тип «Неопределенно», то беда бедой.
4. Поведение запроса на платформе 8.3.19 изменилось, в случае использования в операторе «В» только одного поля «Заказ клиента» - будет оптимально. При наличии выбора из двух полей, то поведение плохое и не изменилось. Т.е. нам не придется выполнять для временной таблицы оператор «ВЫРАЗИТЬ» для всех типов. Т.е. вот такой код будет работать хорошо:
Запрос изменился, предполагаю таким образом они решили баг медленная производительность оператора «В». Теперь план как у MS SQL, для двух полей опять "беда".
5. Добавить индекс на другие поля не составного типа - Склад, Номенклатура. В этом случае, если в фильтре запроса участвует одно из этих полей, то будет использоваться менее эффективная индексная таблица. Но это решение все же улучшает производительность плана запроса (чем больше уникальных значений - тем лучше) и не требует сложных правок в коде. Достаточно только добавить свойство "Индексировать" у соответствующего измерения, но учтите что это увеличит размеры базы данных и "незначительно" увеличит время при добавлении записи в регистр.
6. Добавить вместо составного типа "Заказ клиента", ссылку на справочник "Ключи аналитик заказов". В этом случае мы уйдем от рассматриваемой проблемы. Однако, данное решение требует переработки архитектуры конфигурации. Думаю, что это решение под силу только основному поставщику рассматриваемого решения.
7. Исправления от вендора. Ошибка зарегистрирована под номером https://bugboard.v8.1c.ru/error/10237455, ждем исправления. А пока выбираем вариант оптимизации в текущей ситуации.
Завершающая оптимизация запроса
Так как система работает на Платформе 1С 8.3.16 было предложено сейчас использовать вариант 3. С последующим скорейшим переходом на версию Платформы 1С 8.3.19. Запрос был переписан в соответствии с рекомендациями и применен на целевую базу через расширение.
//...
ВЫБРАТЬ РАЗРЕШЕННЫЕ
Зк_Об.ЗаказКлиента КАК Распоряжение,
Зк_Об.КодСтроки КАК КодСтроки,
ВЫРАЗИТЬ(ЗК_Об.Регистратор КАК Документ.ЗаказКлиента).АдресДоставки КАК АдресДоставки,
Зк_Об.Номенклатура КАК Номенклатура,
Зк_Об.Характеристика КАК Характеристика,
вт_ТоварыКДоставке.Склад КАК Склад,
Зк_Об.Серия КАК Серия,
Зк_Об.КОформлениюРасход КАК Количество
ИЗ
РегистрНакопления.ЗаказыКлиентов.Обороты(
,
,
Регистратор,
ЗаказКлиента В
(ВЫБРАТЬ
ВЫРАЗИТЬ(вт_ТоварыКДоставке.Распоряжение КАК Документ.ЗаказКлиента)
ИЗ
вт_ТоварыКДоставке КАК вт_ТоварыКДоставке)
И (ЗаказКлиента, Номенклатура, Характеристика, КодСтроки) В
(ВЫБРАТЬ
вт_ТоварыКДоставке.Распоряжение,
вт_ТоварыКДоставке.Номенклатура,
вт_ТоварыКДоставке.Характеристика,
вт_ТоварыКДоставке.КодСтроки
ИЗ
вт_ТоварыКДоставке КАК вт_ТоварыКДоставке)) КАК Зк_Об
ВНУТРЕННЕЕ СОЕДИНЕНИЕ вт_ТоварыКДоставке КАК вт_ТоварыКДоставке
ПО Зк_Об.ЗаказКлиента = вт_ТоварыКДоставке.Распоряжение
И Зк_Об.КодСтроки = вт_ТоварыКДоставке.КодСтроки
ГДЕ
Зк_Об.КОформлениюРасход <> 0
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
Зк_Об.ЗаказКлиента,
Зк_Об.КодСтроки,
ВЫРАЗИТЬ(ЗК_Об.Регистратор КАК Документ.ЗаказДавальца).АдресДоставки КАК АдресДоставки,
Зк_Об.Номенклатура,
Зк_Об.Характеристика,
вт_ТоварыКДоставке.Склад,
Зк_Об.Серия,
Зк_Об.КОформлениюРасход
ИЗ
РегистрНакопления.ЗаказыКлиентов.Обороты(
,
,
Регистратор,
ЗаказКлиента В
(ВЫБРАТЬ
ВЫРАЗИТЬ(вт_ТоварыКДоставке.Распоряжение КАК Документ.ЗаказДавальца)
ИЗ
вт_ТоварыКДоставке КАК вт_ТоварыКДоставке)
И (ЗаказКлиента, Номенклатура, Характеристика, КодСтроки) В
(ВЫБРАТЬ
вт_ТоварыКДоставке.Распоряжение,
вт_ТоварыКДоставке.Номенклатура,
вт_ТоварыКДоставке.Характеристика,
вт_ТоварыКДоставке.КодСтроки
ИЗ
вт_ТоварыКДоставке КАК вт_ТоварыКДоставке)) КАК Зк_Об
ВНУТРЕННЕЕ СОЕДИНЕНИЕ вт_ТоварыКДоставке КАК вт_ТоварыКДоставке
ПО Зк_Об.ЗаказКлиента = вт_ТоварыКДоставке.Распоряжение
И Зк_Об.КодСтроки = вт_ТоварыКДоставке.КодСтроки
ГДЕ
Зк_Об.КОформлениюРасход <> 0
ОБЪЕДИНИТЬ ВСЕ
//...
При виде этого оптимизированного кода у меня в мыслях крутится только одна фраза-картинка.

Теперь давайте еще посмотрим план итогового запроса, убедимся что теперь-то все выглядит "хорошо" и будем завершать процедуру оптимизации и переходить к выводам.
https://explain.tensor.ru/archive/explain/434d9cac929739be9297a71a23daee76:0:2022-02-23#visio
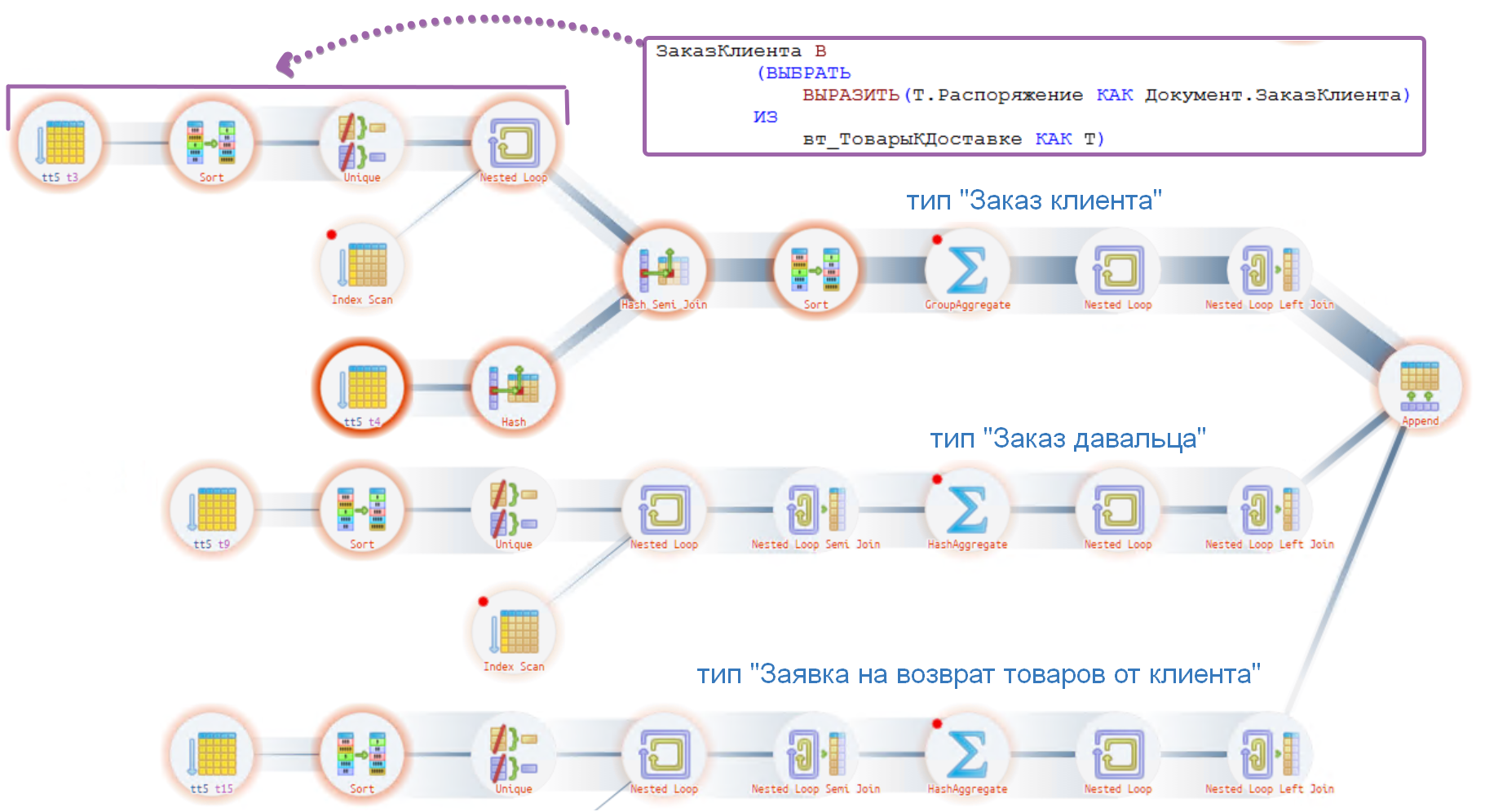
Получение данных из регистра выполняется по индексу - оператор под номером #10. Схема усложнилась за счет трех объединений по типам, но время для каждого из узлов совсем незначительное по сравнению с изначальным планом, поэтому в целом все "хорошо".
Для платформы 8.3.19 исправленный запрос будет выглядеть значительно лучше:
Дальнейшее наблюдение показало отсутствие в логе длительных замеров проблемных запросов. Время выполнения стало меньше времени детектирования длительных запросов в 5 с. По факту время выполнения получилось в районе нескольких единиц-десятков млс. Считаем, что работы по оптимизации быстродействия выполнены успешно.

Если вы не устали или были внимательны, то помните, что у нас было два случая влияющих на производительность рассматриваемого участка кода. Второй случай был связан с RLS, решение этого вопроса мы оставили за рамками текущей статьи. Решен он был через разбиение пакета запроса на две части. И первую часть пакета мы решили выполнять в привилегированном режиме по аналогии с примером рассмотренном в статье: "Решение проблемы быстродействия в ERP на рабочем примере"
А если Вы еще способны делать выводы, то проанализировав изначальный план увидели, что проблема проявляется не только для регистра "Заказы клиентов", а для всех остальных регистров в объединении изначального запроса: "Заказы на перемещение", "Заказы на внутреннее потребление", "Заказы поставщикам" и "Заявки на возврат товаров от клиента". Т.к. количество записей в этих регистрах относительно мало и не оказывает существенного влияния на запрос, а механизм исправления ужасно не удобный, то их исправление было решено отложить.
Выводы
Пишите правильный код. По результатам разбора видно, что код написанный в соответствии с рекомендациями будет работать хорошо везде. По нашей оценке время выполнения оптимизированного кода уменьшилось более чем в 30 000 раз! Это очень хороший результат несмотря на некоторую "костыльность" решения.
Postgres SQL сервер не прощает ошибок, в отличии от MS SQL Server. Если вы перешли на Postgres ожидайте неприятностей (еще больше примеров мы рассмотрим в следующей статье).
Оставайтесь на MS SQL. Кто не хочет проблем и база маленькая, то оставайтесь на MS SQL.
Будьте готовы бороться с проблемами/багами. На платформе 8.3.19 ситуация чуть лучше чем на 8.3.16 и костылить нужно меньше), т.е. если есть возможность переходите на 19-20 версии. Очень похоже, что вендор все же попытался частично решить баг https://bugboard.v8.1c.ru/error/000112349
Запросы с использованием IN
Описание:
При использовании СУБД POSTGRESQL при выполнении запросов с использованием IN наблюдается низкая производительность и повышенная нагрузка на оборудование из-за не оптимального плана запроса.
Обратите внимание на настройку Postgres, обращайте внимание на настройку выделенной памяти процессам. 1С использует обычно достаточно мало процессов, соответственно вы можете выделять больше памяти.
Держите руку на пульсе обслуживаемой системы. Отслеживайте постоянно ошибки, долгие запросы, нагрузку и другие показатели. Для комфортной работы мы рекомендуем использовать конфигурацию "Мониторинг производительности" (по ссылке исходный код конфигурации, описание релизов, плагины и др.). Или можете скачать с текущего ресурса Сборка конфигурации "Мониторинг производительности".
Оценивайте результаты проблемы и оптимизации. Всегда используйте критерии и показатели для оценки уровня проблемы и результатов оптимизации. К одним из основных показателей можно отнести - длительность операции, частоту ее проявления, количество обрабатываемых данных, нагрузку на оборудование мгновенную и среднюю, уровень критичности проблемы для пользователя (как вариант - APDEX). Можно приводить в отчете по проделанной работе данные этих показателей в формате было-стало.
Вступайте в нашу телеграмм-группу Инфостарт