Платформа, релиз, конфигурация – абсолютно любые. Из инструментов только штатный Замер производительности. Все примеры сделаны на управляемых формах, но с обычными ровно то же самое.
Это, можно сказать, просто лайфхак. Способ проверять гипотезы, когда нужно бороться за скорость.
&НаКлиенте
Процедура Тыц(Команда)
ТыцНаСервере();
КонецПроцедуры
&НаСервере
Процедура ТыцНаСервере()
Для Счетчик = 1 По 50 Цикл
Метод1();
Метод2();
КонецЦикла;
КонецПроцедуры
&НаСервере
Процедура Метод1()
//Какой-то код
КонецПроцедуры
&НаСервере
Процедура Метод2()
//Какой-то код
КонецПроцедуры
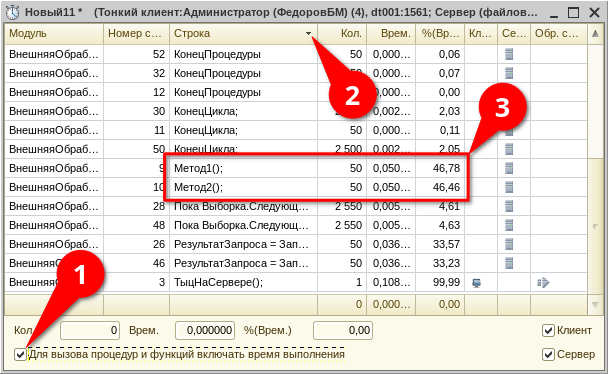
Два алгоритма, которые нужно сравнить, помещаем в Метод1 и Метод2. Потом запускаем Замер производительности. Когда открывается окно с результатами, ставим там галку Для вызова процедур и функций включать время выполнения (1). Ещё установим сортировку по строкам модуля (2) и вот они, наши процедуры, как на ладони (3):
Штука здесь в том, что методы вызываются в цикле. Это нужно, чтобы минимизировать влияние сторонних факторов (что-то где-то кэшировалось, процессор отвлёкся на что-то своё, ещё какая-то из 100500 причин...).
Для Счетчик = 1 По 50 Цикл
Метод1();
Метод2();
КонецЦикла;
Собственно, это всё. На скрине выше результат, когда процедуры идентичны. Так что метод, в принципе, работает. Результат не то, чтобы абсолютно одинаковый, но почти. Будем считать, что погрешность где-то в районе процента – это вполне нормально.
Дальше для иллюстрации приведу несколько типичных ситуаций, когда все всё понимают, но не хотят говорить. Одно дело просто утверждение, другое — цифры, которые можно потрогать руками.
Запросы одинаковые, но в одном случае реквизит берётся из выборки, а в другом – из ссылки. Сравните: ИНН = Выборка.КонтрагентИНН и ИНН = Выборка.Контрагент.ИНН. 31% и 64% соответственно. Это потому, что чудес не бывает. Платформе здесь (неявно) приходится делать обращение к БД. В общем, повод лишний раз убедиться: запрос в цикле – это плохо

Соединения влияют на быстродействие, 54% когда в запросе есть соединение против 39%, когда нет.

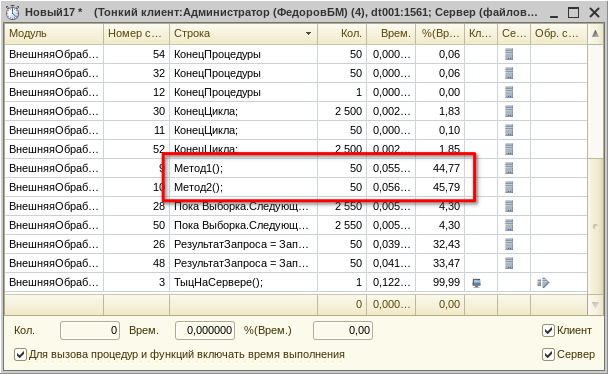
Кстати, совсем банально (когда я писал статью, долго думал, куда поставить это самое «Совсем банально»: здесь, в общем-то, многое банально). В конечном счёте запросы к БД всё равно будут одинаковыми, поэтому явное это соединение или нет, разницы почти никакой, 45% и 46%:
Соединение по полю, по которому есть индекс – это нормально (в частности, разыменование превращается в соединение по Ссылке, а Ссылка гарантировано индексирована). Мало какой хороший запрос можно написать вовсе без соединений.
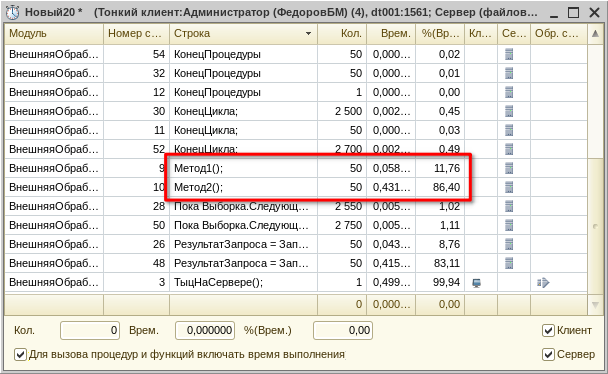
Однако всё меняется, когда в запросе (причём, не только в соединении!) используется какая-то сложная функция и движок не может использовать существующие индексы. Если вам интересны подробности, можно поинтересоваться у Гугла и Яндекса насчёт, примерно, такого: «сканирование таблиц при соединении в запросе sql». Например, посмотрите здесь: https://its.1c.ru/db/metod8dev/content/5842/hdoc
Тут становится совсем грустно, поэтому нужно крепко думать:
Вступайте в нашу телеграмм-группу Инфостарт