






Задача была поставлена так:
Есть сервис-инженеры. Они обслуживают какое-то оборудование и в процессе обслуживания расходуют некие материалы. (Далее в тексте названия материалов я заменил на выдуманные мной). Требовалось, чтобы факт расходования материала фиксировался сервис-инженером немедленно и "прилетал" в 1С.
Такая задача прекрасно решается с помощью обычного телеграм-бота с кнопочками. Но хотелось чего-то большего и было решено делать телеграм-бота, который будет понимать, что ему говорят сервис-инженеры. Т.е. на входе у нас не текст и не нажатия на кнопки, а голосовое сообщение. Это голосовое сообщение должно быть распознано, или как это еще называется, транскрибировано, в общем оно должно превратиться в текст. Текст, полученный в результате транскрибирования голосового сообщения обрабатывается большой языковой моделью. На выходе языковая модель выдает нам структурированные данные, а именно: какой материал списывается, в каком количестве и по номеру какого заказа. Далее, из этого уже получается документ в 1С.
Последний шаг для большинства из присутствующих здесь является тривиальным. А вот предыдущие два могут показаться чересчур сложными для такой простецкой задачи. Но лично я убежден, что интерфейсы такого рода очень востребованы. Пользователи хорошо их воспринимают. А специалистам не плохо бы и освоить.
В конце статьи вернемся к этой теме, а пока я расскажу (с техническими деталями) как я это сделал. И надеюсь, что в конце моего рассказа, вам это уже не будет казаться таким сложным.
Поставщик API для большой языковой модели на момент написания статьи один. Это OpenAI. С поставщиками решений для транскрибирования аудио все значительно проще. Их много, и есть из кого выбирать. Но я особо не заморачивался с выбором. Дело в том, что у OpenAI тоже есть модель для транскрибирования Whisper. Она обучена на 680 000 часов аудио. Т.е. это довольно большая модель, а для нейросетей размер имеет значение, причем решающее.
Фрагменты кода будут на Python. Вообще-то я делаю телеграм-ботов и на 1С, но конкретно этот был сделан на Python. Думаю, это непринципиально. Кому это потребуется, тот с легкостью переведет это на 1С.
Для начала я решил, что мне нужно прочитать голосовое сообщение из телеграм, транскрибировать его и оправить результат обратно в телеграм, но уже в виде текста. Сообщения из телеграм читаются так:
api_url = f"https://api.telegram.org/botхххххххххххххххххххххххххххх/getUpdates?offset={offset}"
response = requests.get(api_url)
data = response.json()
Дальше немного заморочено. В ответе мы получаем не сам файл, а его id. По этому id надо получить ссылку для скачивания и уже только потом скачать. Т.е. у нас тут еще два запроса
file_id = data["result"][0]["message"]["voice"]["file_id"]
api_url = f"https://api.telegram.org/botхххххххххх/getFile?file_id={file_id}"
response = requests.get(api_url)
filedata = response.json()
file_path = filedata["result"]["file_path"]
api_url = f"https://api.telegram.org/file/botхххххххххххххххххх/{file_path}"
response = requests.get(api_url)
if response.status_code != 200:
exit(1)
with open('tempvoice.ogg', 'wb') as file:
file.write(response.content)
audio_file = open('tempvoice.ogg', 'rb')
Теперь у нас "на руках" аудио-файл, который можно отправлять OpenAI для транскрибирования. И это будет ровно одна строка
transcript = openai.Audio.transcribe("whisper-1", audio_file)
Здесь я пользуюсь библиотекой от OpenAI (отчасти поэтому еще и был выбран Python). Можно и без библиотеки, через request. Будет на несколько строк больше.
Как бы там ни было, результат "улетает" обратно в телеграм.
myresponse = {}
myresponse["chat_id"] = chatid
myresponse["text"] = transcript["text"]
api_url = "https://api.telegram.org/botххххххххххххххххххххх/sendMessage"
response = requests.post(api_url, json=myresponse)
И оно работает!

Глядя на картинку, вы можете догадаться, что для теста я не придумал ничего другого, как сказать "раз, два, три". Потом "четыре, пять". Ну а "вышел зайчик погулять" уже нельзя было не сказать. Как видите, "вышел зайчик" превратилось в "пришел зайчик". Вот тут важный момент. Какими бы хорошими ни были транскрибирующие модели, ошибки все равно будут (по крайней мере на текущий момент так). Причем, ошибок будет не мало. Это сильно зависит от языка. Для некоторых языков количество ошибок делает процесс бессмысленным. Но с русским языком нам повезло. Он входит в десятку лучших, обгоняя, например, французский.
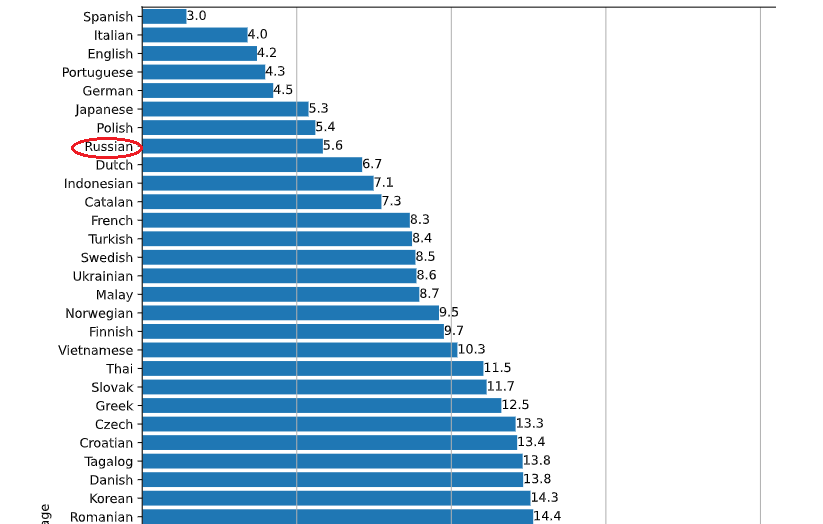
Все-таки почти 6% ошибок означает, что ошибки будут в каждой расшифровке аудио. Я в этом убедился, когда некоторое время назад занимался другим проектом. Это была сеть стоматологических клиник. Было очень смешно, когда "зуб мудрости" упорно превращался в "жуб мудрости". До недавнего времени это было проблемой. Вот получили мы расшифровку. А дальше что с ней делать? Да, человек ее без проблем прочтет, потому что ошибок не так уж много. Но человек в общем случае мог бы и прослушать исходный файл. Все самое интересное должно происходить дальше, при автоматической обработке полученного текста. И тут ошибки начинают сильно мешать. Все изменилось с появлением больших языковых моделей. Зуб или жуб, пришел или вышел - нет никакой разницы. Оно вас в любом случае поймет.
Отправляем расшифровку на обработку языковой моделью.
systempromt = """В распоряжении сервис-инженера имеются следующие материалы
фильтрА12 фильтрБ20 фильтрД100 уплотнитель23 уплотнитель56 фреон120 фреон300"""
userpromt = transcript["text"]+""" На основании этой расшифровки голосового сообщения дай ответ на следующие вопросы
1. Какой материал из имеющихся списывается
2. Количество
3. Номер заказа"""
msg = []
msg.append({"role":"system","content":systempromt})
msg.append({"role":"user","content":userpromt})
responseai = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=msg,
temperature=0,
stop=["#", ";"]
)
Systempromt и userpromt. Можно сказать, что суть работы AI инженера заключается в том, чтобы присвоить правильные значения этим двум переменным. Кажется, что это просто. Ну... иногда это действительно просто.
Обратите также внимание на параметр temperature. Если мы не хотим, чтобы модель креативничала (а мы в данном случае не хотим), тогда в этом параметре надо задать 0. Пробую модель на разных вариантах. От четкого "фильтр D100 одна штука заказ тридцать пять шестьдесят пять". До "значит так... эта... уплотнитель спиши двадцать третий... а нет нет... пятьдесят шестой пятьдесят шестой на заказ десять... да блин че там... двадцать один... ага... две штуки"
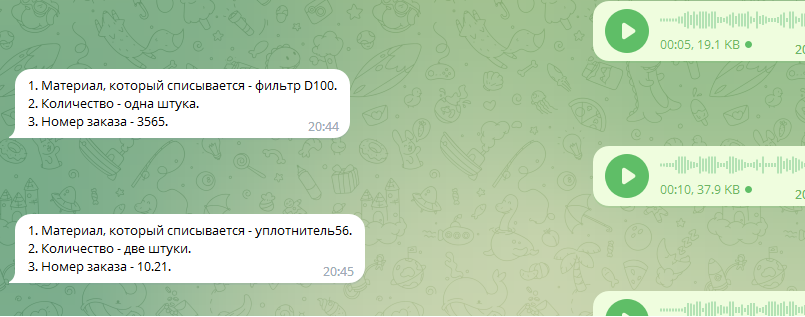
Модель отрабатывает без ошибок. В принципе, из этого уже можно создавать документы в 1С. Но лучше немного поправить promt.
userpromt = transcript["text"]+""" На основании этой расшифровки голосового сообщения дай ответ на следующие вопросы
1. Какой материал из имеющихся списывается
2. Количество
3. Номер заказа
Ответ представь в формате json"""
Для создания документов нам нужны структурированные данные. Поэтому в нашем случае будет логичным попросить модель выдавать структурированные данные.
А она это умеет!

Структурированные данные на выходе нам пригодятся также для обработки крайних случаев. Например, вот что я получил после того, как сказал в микрофон "раз два три четыре пять"
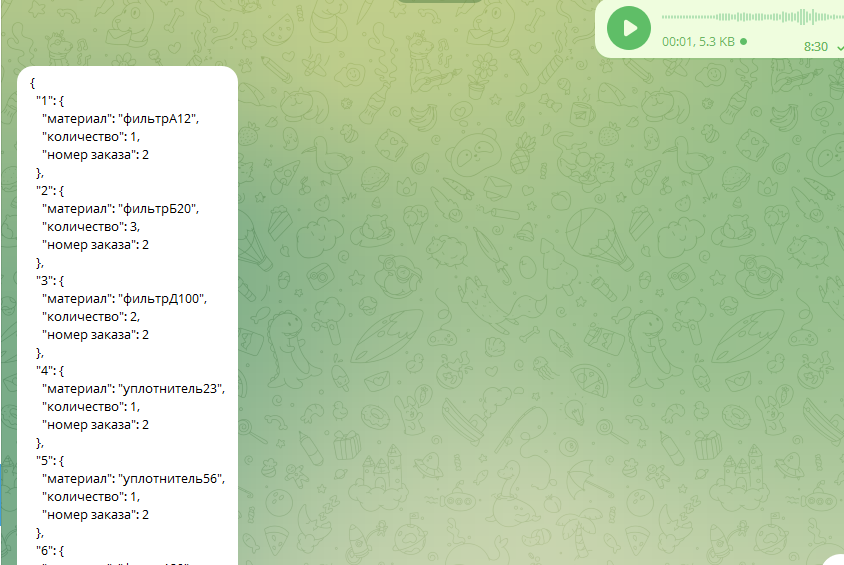
Особенность языковой модели в том, что она суперисполнительна и будет пытаться выполнить работу "изо всех сил". Опция "да ну тебя нафиг, что за ерунду ты тут бормочешь" не то чтобы отсутствует, но встречается очень-очень редко. То, что вы видите на картинке сейчас принято называть "галлюцинациями". Считается, что эти самые "галлюцинации" являются главной проблемой в использовании больших языковых моделей. В нашем случае это никакая не проблема. Мы ожидаем получить структуру из трех элементов без вложенностей. И если мы получаем что-то не то, значит... что-то не то.
Время от времени модель как бы уставала со мной общаться и вместо положенных слов "материал", "количество" и "номер заказа" выдавала скупые 1,2,3

Тут проявляется еще одна особенность больших языковых моделей. Некоторая непредсказуемость их поведения. Но для нас это опять же не проблема. Можно брать значения первого, второго и третьего элементов структуры, не обращая внимания на имена. Также можно обращаться по имени "материал", а если его нет, то по имени "1". Лично я выбрал второй путь.
Эксперименты закончены. JSON уезжает в 1С, чтобы превратиться в документ. А нам надо вывести пользователю "человеческое" сообщение.

Вот тут, кстати можно было бы и кнопочки "да", "нет" прикрутить. Для экономии денег. Но было решено сделать интерфейс только голосовым, без кнопок.
Дело сделано. Поговорим на тему того, а в чем, собственно, прелесть таких интерфейсов. Самое главное, что нам дали большие языковые модели заключается в том, что оно нас понимает. У слова "понимает" может быть много смыслов. Что такое "понимать" с философской точки зрения мы не поймем никогда. Но есть и чисто практический подход. Если что-то может продолжить то, что вы начали, значит оно вас понимает. И этот практический подход работает. А это, в свою очередь, означает, что теперь любой может рассчитывать на то, что компьютер его поймет. Это трудно переоценить. Теперь компьютер будет делать то, что вы хотите здесь и сейчас. Так было и раньше, только для этого надо было быть программистом. А все прочие должны были довольствоваться тем, что компьютер будет делать то, что хотел программист. Большие языковые модели переворачивают эту ситуацию. Думаю, что в скором времени пользователи будут требовать от нас, специалистов, такие интерфейсы, какой я вам здесь продемонстрировал. И только такие.
Надеюсь, что моя статья поможет уважаемым коллегам начать осваивать новую технологию.
Вступайте в нашу телеграмм-группу Инфостарт