Поговорим о том, как упростить процесс проведения нагрузочного тестирования. Сократить сроки, но при этом получить качественный результат.
Прежде чем описывать наш подход, расскажу, почему вообще у нас возникла необходимость каких-то дополнительных инструментов для проведения нагрузочного тестирования – что нас не устроило в классическом подходе.
Обычно нагрузочное тестирование проводят, чтобы убедиться, что система выдержит ожидаемую нагрузку – будет под ней работать стабильно. Потребность в проведении нагрузочного тестирования может возникать на разных этапах эксплуатации системы – будь то пилотный проект или полноценно эксплуатируемая база. Мы сегодня будем говорить о проведении нагрузочного тестирования для эксплуатируемой системы.
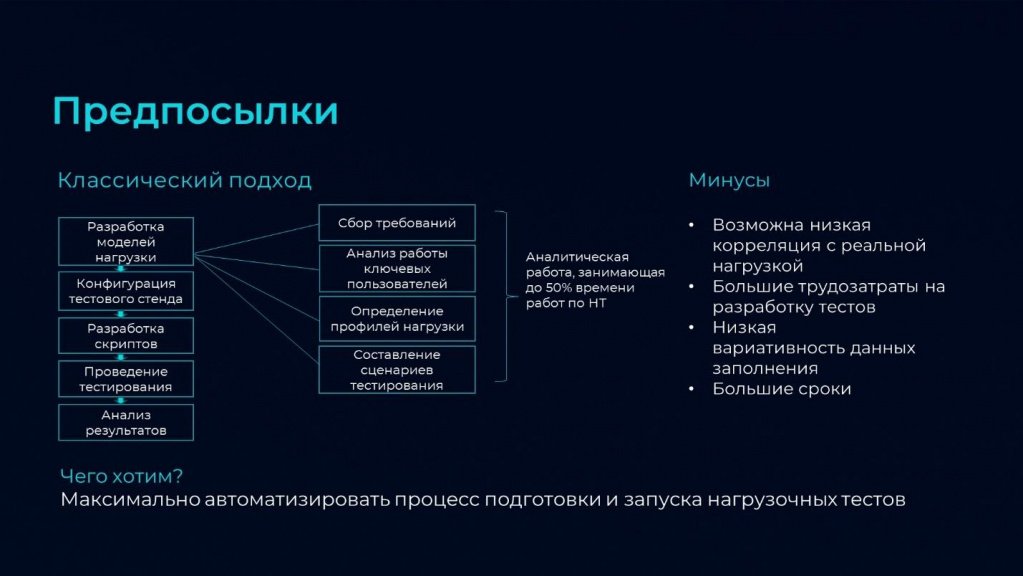
Согласно классическому подходу проект по нагрузочному тестированию всегда начинается с разработки моделей нагрузки, в ходе которой:
-
определяются операции, которые нужно включить в тест;
-
выбирается интенсивность, с которой эти операции будут выполняться;
-
устанавливается целевое количество пользователей;
-
исходя из установленных параметров составляются сценарии нагрузки.
Все это предполагает:
-
Сбор и анализ требований.
-
Длительные этапы согласования с заказчиком.
-
Привлечение дополнительных специалистов – бизнес-аналитиков, которые будут разбираться в процессах заказчика.
В результате этап разработки моделей нагрузки может занимать до 50% времени всех работ по нагрузочному тестированию.
На это накладываются большие трудозатраты по разработке скриптов, потому что каждая операция, включенная в тест, должна быть запрограммирована.
Из-за большого объема аналитической работы при разработке моделей нагрузки и трудозатрат на разработку тестов на проект по нагрузочному тестированию изначально приходится закладывать большие сроки.
Но самое неприятное даже не в сроках, а в том, что у классического подхода есть и другие недостатки:
-
Самой большой проблемой может оказаться отсутствие конкретных требований к системе и низкая корреляция с реальной нагрузкой, потому что бизнес-аналитики или лица, ответственные за моделирование, не всегда понимают, какие требования нужно предъявлять к системе под нагрузкой.
-
Еще одна проблема – низкая вариативность данных заполнения, поскольку для нагрузочного теста обычно берется ограниченный набор данных. Например, тест должен проводить заказы клиентов – для этого берется одна или две ссылки, которые копируются на большое количество пользователей и проводятся. Но в реальной жизни документы могут сильно отличаться по объему данных – у одного в табличной части будет 10 строк, у другого – 10 000 строк. В зависимости от характера данных, могут различаться алгоритмы проведения. Поэтому чем более реалистичные и вариативные данные мы подберем для теста, тем будет большая точность.
В результате мы пришли к мысли о создании набора инструментов, позволяющих максимально автоматизировать процесс подготовки сценариев и проведения нагрузочного тестирования.

Подход проведения нагрузочного тестирования, который мы выбрали, может пригодиться в следующих случаях:
-
При переходе на Linux + PostgreSQL – у вас может быть большая высоконагруженная система, которая годами адаптировалась под MS SQL и отлично работает, но без проведения нагрузочного тестирования сложно предсказать, как она себя поведет на PostgreSQL+Linux.
-
При масштабировании имеющейся системы – например, когда вы запускаете пилотный проект и хотите проверить, как поведет себя система при подключении других филиалов. Или если у вас планируется увеличение интенсивности ввода операций.
-
При подборе оптимальной конфигурации оборудования.
-
При переходе в облако.
-
На проектах по оптимизации производительности, когда нужно зафиксировать исходную производительность системы, а после проведения работ по оптимизации сравнить ее с тем, что получилось.
-
При переходе на новую версию платформы,
-
При снятии режима совместимости и т.д.
Это может быть любой кейс, когда на входе есть эксплуатируемая система и грядут какие-то изменения – нужно проверить, как она будет вести себя после изменений.
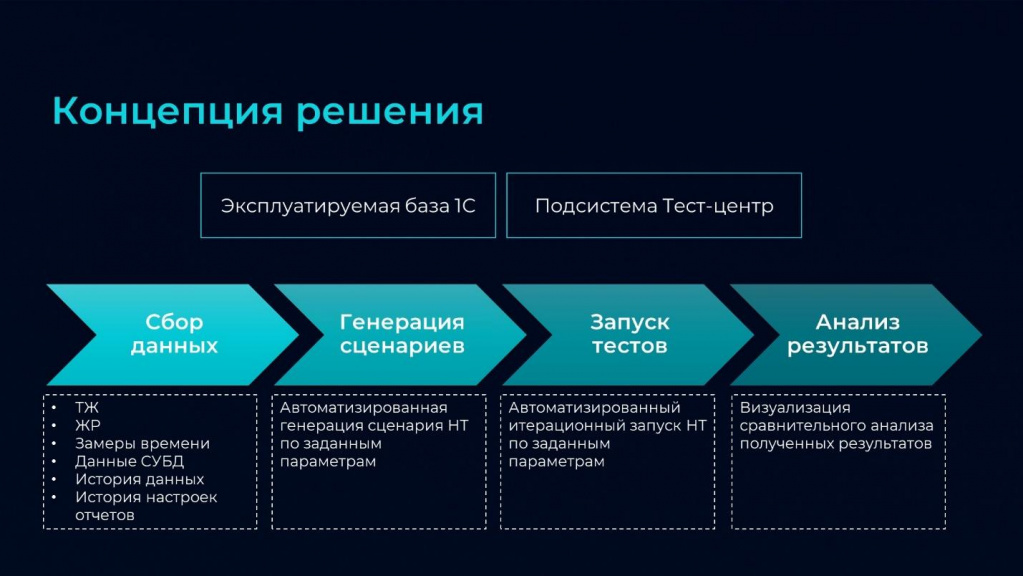
Давайте посмотрим на концепцию нашего решения. На входе у нас есть:
-
эксплуатируемая база 1C;
-
и подсистема Тест-центр, которая входит в состав «Корпоративного инструментального пакета». Тест-центр – это готовый и вполне удобный инструмент. Мы используем его для запуска тестов, при этом забираем автоматизированную подготовку сценариев на себя.
Основные этапы в нашем нагрузочном тестировании:
-
Сбор данных – на этом этапе мы анализируем информацию из большого количества источников, закрывая тем самым весь блок аналитической работы. В результате мы получаем реальные данные о том, что у нас на самом деле творится в системе. Не голословно: «Вроде как должны быть такие процессы, вроде как столько-то документов вводят», а мы снимаем реальную статистику.
-
Генерация сценариев – на основании собранной статистики мы задаем параметры и генерируем сценарии.
-
Запуск тестов – у нас предусмотрен автоматический итерационный запуск.
-
Анализ результатов – мы визуализируем то, что мы получили.

В результате использования нашего решения мы получаем следующие преимущества:
-
За счет автоматизации самых длительных этапов сокращаются сроки подготовки сценариев нагрузочного тестирования.
-
Поскольку мы снимаем реальную статистику с прода, эмулируется нагрузка, близкая к продуктивной системе.
-
За счет автоматической генерации сценариев нагрузочный тест удобно масштабировать. Если мы сняли статистику с пилотного проекта и хотим посмотреть, как себя поведет система под большим количеством пользователей – мы без особых трудозатрат генерируем сценарий на нужное количество пользователей.
-
Автоматический итерационный запуск – еще одно наше преимущество.
-
Нет необходимости привлекать аналитиков для составления сценариев.
-
В нагрузочном тесте используются реальные несинтетические данные.
Сбор данных

Рассмотрим каждый из перечисленных этапов подробнее – начнем со сбора данных.
Первый вопрос, на который нам нужно ответить для сбора данных – какие операции включать в сценарии?
Поскольку у нас нет цели включить в сценарий абсолютно все операции, которые выполняют пользователи системы, мы берем за основу принцип Парето, подразумевая, что 20% операций дадут нам 80% нагрузки. И отбираем только наиболее частые и ресурсоемкие операции. При этом мы ориентируемся на следующие критерии:
-
длительные операции на сервере 1С;
-
операции, которые дают большую нагрузку на процессор сервера 1С;
-
операции, потребляющие больше всего памяти сервера 1С;
-
операции, нагружающие диск сервера 1С;
-
часто выполняющиеся операции;
-
операции, которые приводят к длительным ожиданиям на блокировках;
-
операции, которые приводят к эскалациям на блокировках;
-
и операции, приводящие к сканированию больших таблиц.
Чтобы получить параметры всех выполняемых системой операций, мы используем следующие источники:
-
Технологический журнал – это основной источник, он нам дает очень много информации.
-
Замеры времени из подсистемы оценки производительности APDEX.
-
И данные СУБД.
Парсеры разбирают технологический журнал и записывают данные в базу ClickHouse, откуда запросом мы получаем топ операций и дополнительные параметры для них:
-
целевое расчетное время,
-
частоту выполнения этих операций,
-
пользователей, которые чаще всего их выполняют, и так далее.
Иногда при составлении сценариев нужно опираться не только на нагрузку и производительность. Некоторые операции из тех, что не попали в топ, могут быть критичными для бизнеса – их мы можем добавить в сценарий дополнительно. Т.е. мы автоматически собираем топ операций, и, если нужно еще что-то добавить – добавляем.
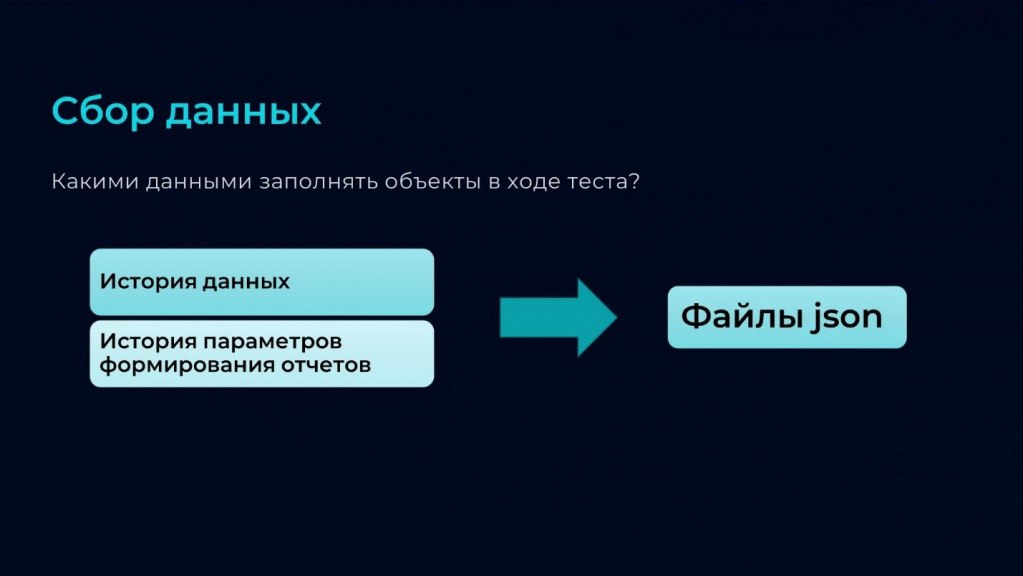
Следующий вопрос, касающийся сбора данных – какими данными заполнять объекты в ходе теста?
Поскольку мы хотим повысить точность теста, мы используем реальные несинтетические данные. Это позволяет нам избежать в ходе теста нехватку прав или проблему с остатками при проведении документов.
Для получения данных для теста мы используем платформенную историю данных.
-
Делаем бэкап продуктивной базы.
-
Включаем историю данных для интересующих нас типов объектов,
-
Ждем, когда накопится необходимый объем данных.
-
И выключаем историю данных – в результате все действия пользователей по интересующим нас объектам сохраняются в истории данных. Все эти действия мы можем воспроизвести на предварительно сохраненной копии – если пользователь в проде смог провести такой документ, мы сможем его провести и в ходе теста, используя те данные, которые мы сохранили с помощью истории.
-
Выгружаем действия из истории данных в файлы JSON и используем их потом при заполнении.
Второй источник данных для заполнения в ходе тестов – это история параметров формирования отчетов. Мы сохраняем настройки, с которыми пользователи формируют отчеты, используя специальный механизм в виде расширения, записывающего эти настройки в регистр сведений.
Причем этот механизм можно использовать не только в целях нагрузочного тестирования, но и, например, для расследования проблем производительности. Чтобы фиксировать, с какими параметрами пользователи формируют отчеты, когда говорят: «Ваш отчет не работает, он зависает».
История параметров формирования отчетов у нас пишется в регистр сведений, и мы потом можем с этими же настройками воспроизвести эту операцию.
Эти настройки тоже выгружаем в файлы JSON и загружаем в нашу базу, в которой будем моделировать нагрузочное тестирование.

С помощью такого подхода мы можем автоматически генерировать следующие виды операций:
-
Проведение документов.
-
Формирование отчетов.
-
Запись элементов справочников.
-
Открытие любых форм – справочников, документов, отчетов, обработок – неважно.
-
Формирование печатных форм.
-
Выполнение команд форм и глобальных команд.
-
Обработчики событий элементов форм.
-
Регламентные задания.
-
Поиск в списках.
-
Прокрутки в списках.
Достаточно внушительный список, позволяющий воспроизвести работу пользователей.
Генерация сценариев
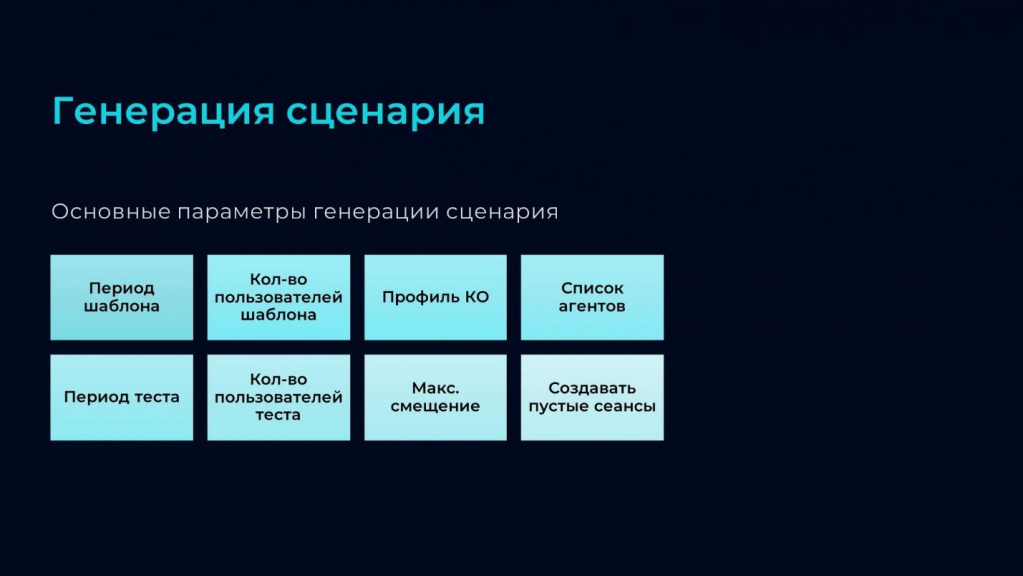
Следующий этап, к которому мы приступаем после получения списка операций и их интенсивности выполнения – это генерация сценария.
На слайде приведены основные параметры, которые мы задаем для генерации сценария.
-
В качестве параметров «Период шаблона» и «Количество пользователей шаблона» мы устанавливаем значения, которые получили из реальной статистики.
-
А для управления масштабированием и интенсивностью меняем пропорции параметрами «Период теста» и «Количество пользователей теста»:
-
Если мы хотим запустить тест на такое же количество пользователей, но увеличить интенсивность, мы уменьшаем значение параметра «Период теста».
-
Если мы хотим сохранить интенсивность, но добавить количество пользователей, мы увеличиваем «Количество пользователей теста», а период оставляем такой же.
-
-
Также мы здесь задаем «Список агентов» – это те машины, на которых будут запускаться клиентские сеансы.
-
И при необходимости устанавливаем параметр «Создавать пустые сеансы». Дело в том, что иногда в продуктивной системе есть сеансы, которые не выполняют активных действий, но у них есть какие-то обработчики ожидания. В некоторых случаях таких сеансов может оказаться больше, чем активных, поэтому просто так выкидывать их из модели нагрузки нельзя – при необходимости можем добавить такие пустые сеансы в наш сценарий.

Процесс генерации сценариев состоит из нескольких этапов:
-
На этапе создания модели нагрузочного теста у нас происходит распределение подобранных ранее операций по пользователям и по клиентским машинам, плюс подбираются данные для заполнения – мы получаем готовый детальный план.
-
Далее мы создаем недостающие ссылки для выполнения операций. Например, если у нас в тесте есть операция «Проведение заказа клиента», и нам, чтобы воспроизвести эту операцию, нужно предварительно создать нового контрагента, мы по файлам истории данных его создаем. И таким образом доводим базу до состояния, когда в ней есть все необходимые данные для выполнения операций теста.
-
Далее мы записываем наш детальный план в регистр сведений, что обеспечивает нам полную повторяемость при разных запусках – чтобы выполнялись одни и те же операции с одним и тем же смещением относительно начала теста.
-
И выполняем настройку пользователей, если в базе используется сложный RLS. Поскольку нагрузочное тестирование запускается под копиями реальных пользователей, сначала создаются копии реальных пользователей, а потом для них нужно настроить доступ на уровне записей. Этот процесс может оказаться весьма длительным, поэтому мы вынесли его в подготовительный этап, чтобы не тратить на это время в процессе самого нагрузочного тестирования.
Результат всего подготовительного этапа – это СУБД-шный бэкап, который мы будем разворачивать перед каждым запуском.
Автоматический итерационный запуск тестов
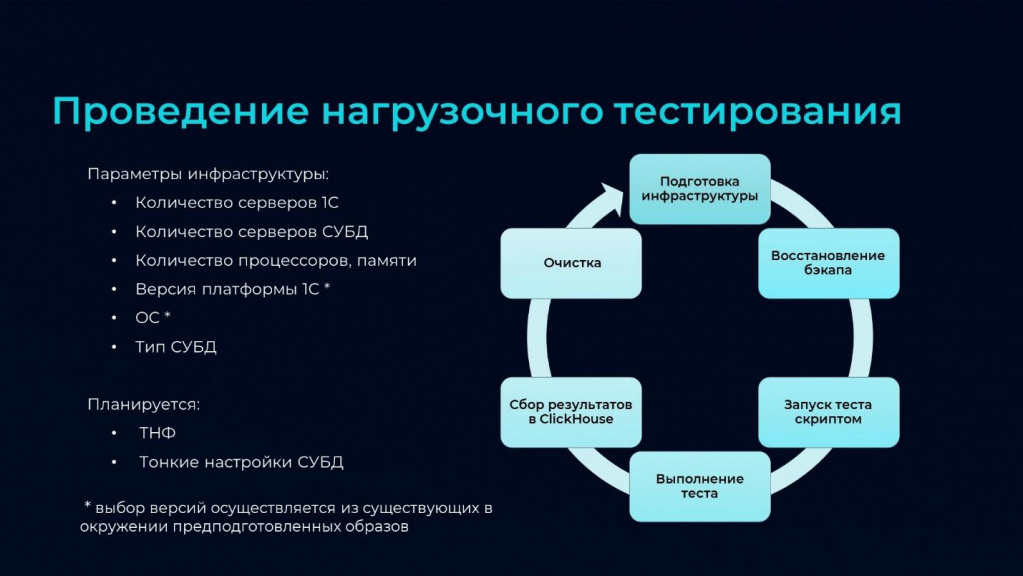
Переходим к процессу запуска.
В зависимости от целей тестирования и разнообразия инфраструктуры могут быть разные сценарии. Допустим, у вас есть 2-3 готовых стенда, на которых нужно прогнать нагрузочный тест, можно запустить его скриптами, забрать результаты и анализировать. Но есть случаи, когда нам нужно большое количество запусков с разными параметрами инфраструктуры – для этого предусмотрен автоматический итерационный запуск.
На слайде представлен цикл проведения нагрузочного тестирования.
-
Начинается все с автоматического развертывания инфраструктуры по заданным параметрам.
-
Можно управлять количеством серверов 1С; количеством серверов СУБД; количеством процессоров, памяти; версией платформы 1С; операционной системой и типом СУБД.
-
Также планируются тонкие настройки кластера серверов 1С и тонкие настройки СУБД.
-
-
После подготовки инфраструктуры восстанавливаем бэкап, который мы сделали на подготовительном этапе.
-
Запускаем тест скриптом. На входе мы передаем настроечный файл, в котором есть информация:
-
какой сценарий запускать;
-
на каких машинах;
-
с каким тайм-аутом и настройками;
-
и формат результата – как записывать.
-
-
Выполняется тест.
-
Забираем результаты в базу ClickHouse. Мы забираем:
-
протокол тестирования;
-
замеры производительности – замеры времени;
-
и метрики операционной системы.
-
-
Очищаем.
-
И переходим на новый круг с новыми параметрами развертывания инфраструктуры.
Анализ результатов
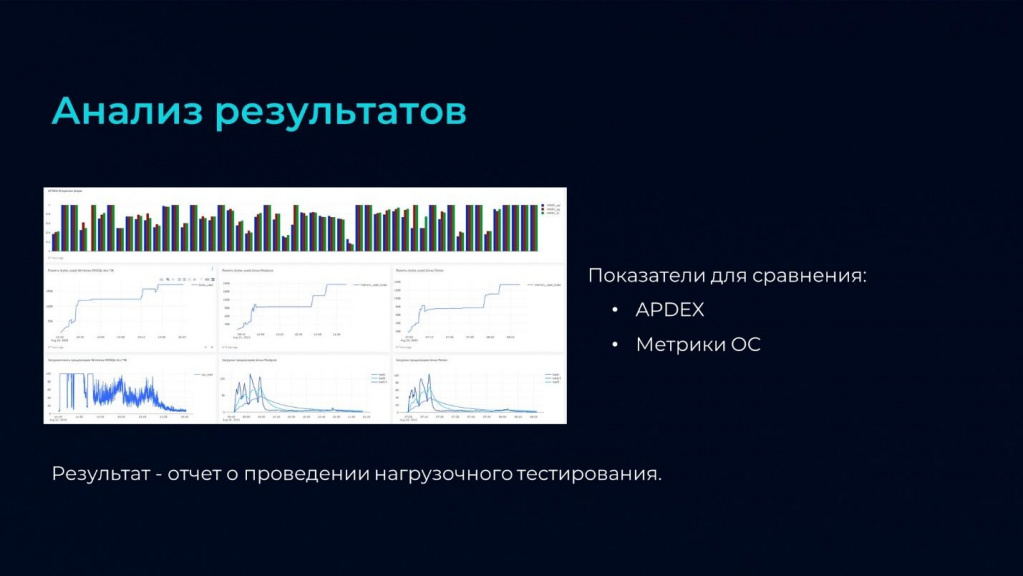
Последний этап – это анализ результатов.
Для удобства визуализации мы используем дашборды Redash. На слайде представлен фрагмент такого дашборда. Мы можем включать в него сравнительные диаграммы, графики, таблицы – все, что нам нравится.
Основные показатели для сравнения – это APDEX и метрики операционной системы.
По APDEX можем смотреть:
-
сводные значения;
-
значения в разрезе операций;
-
группировать по типу операций – например, сравнить, как менялся APDEX именно для проведения документов или для формирования отчетов.
И результат фиксируем в отчете о проведении нагрузочного тестирования.
Нагрузочное тестирование на реальном примере

Теперь давайте посмотрим на пример применения такого подхода. Расскажу, как мы проводили нагрузочное тестирование и какой результат получили.
На входе у нас была конфигурация «1C:ERP Управление холдингом 3.1.5.6» с достаточно большим количеством доработок и расширений.
Версия платформы на тот момент была 8.3.20.19.14. Потом еще проверяли на 8.3.23 – на ней производительность оказалась немного лучше.
Размер базы – более 700 гигабайт.
Количество пользователей – более 500 активно работающих пользователей.
Цель проведения нагрузочного тестирования – проверка возможностей перехода на Linux + PostgreSQL.

Для проведения нагрузочного тестирования было подготовлено два сценария.
Первый – это сценарий длительностью 1 час, эмулирующий ежедневную нагрузку на 500+ пользователей. В состав этого сценария попало:
-
80 видов операций.
-
3500 действий.
-
В результате одного прогона у нас получалось 7800 замеров, в том числе типовых.
-
100% операций этого сценария были сгенерированы автоматически. Ни под одну операцию мы дополнительно не писали код ее выполнения в ходе теста и не зашивали в код какие-то ссылки – эти ссылки с учетом прав доступа подбирались автоматически.
И второй сценарий – для выполнения длительной ресурсоемкой операции «Расчет себестоимости». Для этого сценария был установлен лимит выполнения 24 часа. По истечению этого времени тест завершался – независимо от того, выполнился расчет себестоимости или нет.
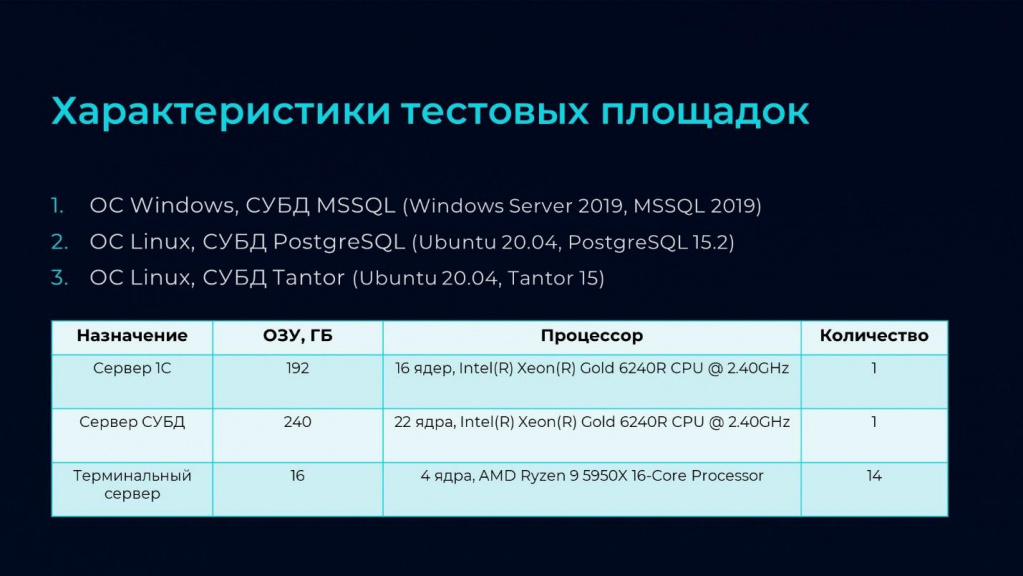
Было подготовлено три площадки.
-
Первая – это ОС Windows СУБД MS SQL (то, на чем сейчас работает заказчик).
-
Вторая – ОС Linux, СУБД PostgreSQL.
-
И третья, для сравнения – ОС Linux, СУБД Tantor.
Характеристики серверов на слайде.

Посмотрим, что у нас получилось.
На слайде приведены сводные значения APDEX по первому сценарию.
-
Лучше всего себя показал PostgreSQL,
-
За ним Tantor – почти такой же результат,
-
И на третьем месте – MS SQL.
Мы также сравнили время запуска и инициализации клиентских сеансов.
-
Тут чуть быстрее оказался Tantor,
-
За ним – PostgreSQL
-
И MS SQL.
Здесь на слайде также приведены фрагменты диаграмм со сравнением APDEX.
-
Синие столбики – это MSSQL.
-
Красные – PostgreSQL.
-
Зеленые – Tantor.
Если в целом анализировать операции первого сценария, то можно сделать вывод, что:
-
Площадки на ОС Linux показали себя лучше или так же, как MS SQL.
-
Только на каких-то единичных операциях производительность была ниже – в основном, лучше или равная.
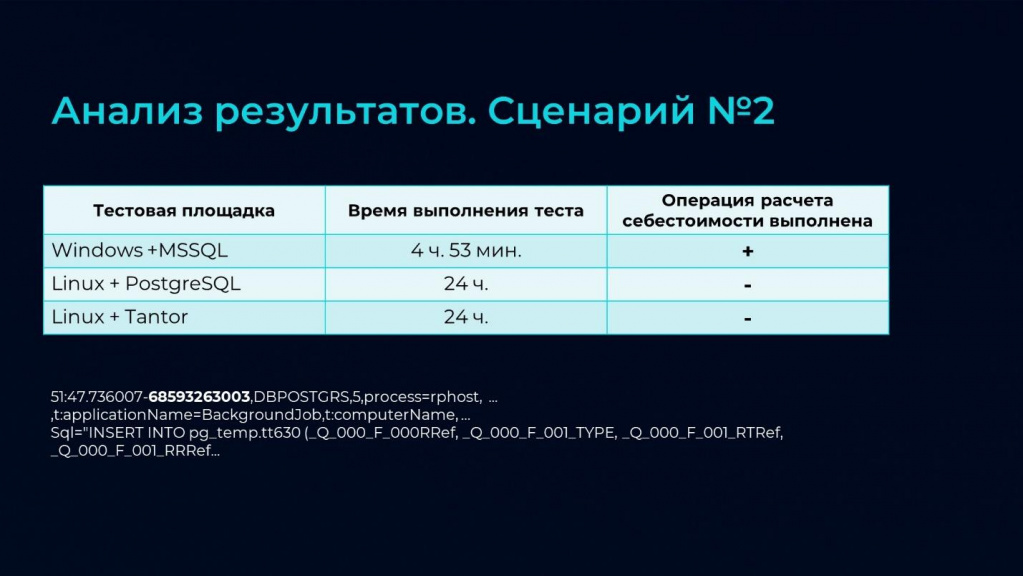
Теперь посмотрим, что показал нам второй сценарий.
Он оказался ложкой дегтя в этом прекрасном повествовании, потому что:
-
На MSSQL расчет себестоимости выполнялся около пяти часов.
-
На Linux + PostgreSQL и на Linux + Tantor расчет себестоимости за 24 отведенных часа не выполнился.
Из этого мы сделали вывод о том, что переход на ОС Linux без предварительной адаптации конфигурации невозможен. Сейчас ведутся работы по адаптации конфигурации.
Например, на слайде приведен фрагмент запроса из ТЖ, который встретился в операции расчета себестоимости – на PostgreSQL он выполнялся 19 часов. За счет настроек СУБД его удалось частично оптимизировать, но время выполнения все равно оставалось неприемлемым – что-то порядка 11 часов.
Но тут стоит оговориться, что у заказчика был не последний релиз конфигурации ERP УХ. И в ходе анализа стало понятно, что некоторые проблемы уже решены в актуальных релизах. В частности, в этом запросе виной всему была большая неиндексированная временная таблица.
В свежем релизе этот запрос уже переписали – после обновления он выполняется 4 секунды. Есть разница, да?
Но, к сожалению, не все проблемы решены даже в свежем релизе. Например, мы заметили значительную просадку производительности операций, использующих в запросе платформенный СрезПоследних. В таких случаях помогает переписать запросы, используя свой алгоритм расчета среза последних.
В заключение своего доклада хочу еще раз повторить, что проведение нагрузочного тестирования является очень важным этапом и может пригодиться на разных этапах эксплуатации вашей системы.
Проверяйте свою систему на прочность и будьте уверены в ее работоспособности и производительности.
Дополнение от Антона Литвинова
Расскажу об этом кейсе со стороны инженера, потому что я – не 1С-ник, а инфраструктурщик, и получив эту «линейку», я начал мерить.
-
Первым делом, когда мы поставили большой кластер, я начал «отстреливать» сервера приложений – смотреть, как оно работает. В результате мы получили неоднозначные результаты, которые привели к тому, что мы поменяли настройки кластера. Это в докладе не совсем отмечено, но мне, как инфраструктурщику, это было очень полезно.
-
Второе дело – сравнение Intel и AMD. Последние AMD побеждают – они реально быстрее работают. Понятно, что мы их купить не особо можем, но если вам из-под полы удалось достать, берите AMD.
-
Дальше – если у вас СХД, переходите на SSD. PostgreSQL очень требовательный к дисковой подсистеме, а СХД дают сильный оверхед на PostgreSQL. Об этом уже говорил Антон Дорошкевич, но я это сам увидел на живой базе, и мы очень удивлялись.
-
Еще один момент. Изначальный подрядчик, который должен был провести нагрузочное тестирование, год кормил нас обещаниями – при том, что мы с ним договаривались тестировать только согласованные ключевые операции, 15 штук. В итоге мы его не дождались и сделали свое нагрузочное тестирование за два месяца – подготовили тесты, провели тестирование и получили результаты. Причем метрик смогли померить гораздо больше. Потому что, когда начали смотреть, чем занимаются пользователи в базе, начали вылезать очень неочевидные вещи. Например, мы думали, что документ открывают два раза в день, а оказалось, что его открывают полторы тысячи раз в день – очень удивлялись, когда увидели это в логах. Потом пошли к пользователям, и действительно оказалось, что они всей толпой открывают этот документ.
Подробнее ознакомиться с решением «Нагрузочное тестирование систем 1С» можно на странице Инфостарта.
Вопросы
Как вы определяете целевое время выполнения ключевых операций?
По технологическому журналу. Мы снимаем реальное время, за которое выполняется операция. Причем берем не среднее время операции, а квантиль 0.8, т.е. время, в которое укладывается 80% операций. Отсекаем слишком большие значения и берем это время как расчетное.
Если нужно скорректировать это целевое время, корректируем.
А как понять – нужно работать над этой ключевой операцией или не нужно? Допустим, у вас проведение документа выполняется 6 секунд, а заказчик хочет 3 секунды. Что вы делаете в такой ситуации?
Желание заказчика по скорости к нагрузочному тестированию не имеет вообще никакого отношения. Результат нагрузочного тестирования говорит о том, что эта система на этом железе и при этих настройках СУБД работает так. Это объективный ответ.
Если он говорит: «А я хочу, чтобы работало вот так» – мы определяем, возможно ли это физически, и говорим, сколько это будет стоить.
Оптимизация и нагрузочное тестирование – это вообще разные процессы. Оптимизация проводится только для тех ключевых операций, скорость которых по результатам нагрузочного тестирования заказчика не устраивает. А после проведения оптимизации опять происходит нагрузочное тестирование с новым кодом.
Нет смысла ориентироваться на целевые цифры от заказчика – если заказчик думает, что эта операция происходит 700 миллионов раз в день, он будет требовать тестировать 700 миллионов операций. Хотя 20 операторов, чтобы выполнить 700 миллионов операций – год должны прожить. Поэтому в любых цифрах – как в целях нагрузочного тестирования, так и в частоте нагрузки – нужно включать хотя бы какую-то логику из жизни. Иначе вы получите фейк.
Если нужно сравнить то, что есть сейчас, и то, что будет после изменений, целевое время не важно. Мы просто покажем – стало хуже или лучше.
А выставлять целевое время – это вопрос именно оптимизации как отдельного процесса.
Мы сейчас рассмотрели вариант, когда система уже есть, люди работают, и мы можем собрать показатели нагрузочного тестирования из ТЖ. Причем это работает и когда мы просто укрупнимся, и когда мы куда-то переходим – эти сценарии понятны. А что делать, когда система новая? Откуда взять информацию, если мы до этого все отчеты рисовали на ватманах на заводе, а теперь будет ERP на 700 пользователей. Они не знают, что такое открытие документа или формирование отчета – у них на ватманах все рисовалось. Что делать?
Это аналитическая работа. На основе экспертного опыта. Если данных нет, готового ответа тоже нет.
Вы упоминали операцию прокрутки списка. Как вы ее имитируете?
У нас есть утилита, которая активирует окно и передает команды, аналогично нажатию кнопок PgUp, PgDn с клавиатуры.
Когда вы собираете платформенную историю данных, вы ее дальше чистите? Или она просто копится, копится, копится?
Конечно, чистим. У нас есть специально написанная обработка, которая включает историю данных по конкретным типам объектов, а потом позволяет очистить то, что мы потом насобирали, чтобы не оставлять это в проде.
Мы ее включаем, допустим, на несколько часов. Накапливаем сколько надо, а потом подчищаем.
Включали на достаточно нагруженной базе – просадки в производительности не заметили.
Можно ли параллельно к тем 80 пользователям, которые генерят нагрузку, включить еще нагрузку от регламентных заданий и интеграции через HTTP-сервисы, например?
Вы можете включить в сценарий регламентные задания и код, который будет эмулировать работу интеграции.
Например, если интеграция запрашивает из вашей базы, это ничем не отличается от работы пользователя – просто код, который выполняется, без интерфейса.
А если интеграция пишет в базу – напишите такое фоновое задание.
Можно сгенерировать эту нагрузку и автоматически по данным технологического журнала – но там нет записи, откуда это прилетело, из какой конкретной шины. Это можно эмулировать, но это уже будет проект под ваши конкретные задачи.
Вы сказали, что используете в качестве целевого времени операции среднемесячное значение времени. Но я думаю, все-таки более интересно моделировать максимальную нагрузку, потому что если во время закрытия периода база будет сильно тормозить, заказчика это будет не устраивать.
Ваш сценарий нагрузки будет зависеть от того, в какой момент вы будете собирать для него данные. Вы можете снять состояние базы в проблемный момент и сделать из этого отдельный дашборд с Redash, чтобы сравнивать смоделированную нагрузку с этими максимальными значениями.
Но закрытие месяца, скорее всего, происходит ночью, и проблема там у 20 кладовщиков. А днем работает 400 кладовщиков – это совсем разные сценарии.
Один сценарий – средненормальный, и второй сценарий – когда сильно плохо. Тогда придется собрать для них два набора данных – при нормальной работе и при максимальной нагрузке в момент расчета себестоимости. И просто прогонять два отдельных сценария. Отдельно – сценарий обычной работы, и отдельно – сценарий расчета себестоимости.
Как вы проводите тестирование в зависимости от изменяемости данных? Например, операция «Расчет себестоимости» будет отличаться по времени, если вы в одном месяце одну единицу продукцию произвели, в другом месяце – тысячу. Конкретно у меня проблема в расчете заработной платы – от месяца к месяцу у людей может меняться состав начислений, и в зависимости от определенных показателей рассчитываться будет либо быстрее, либо медленнее. Вы всегда на каком-то одном тестовом наборе гоняете нагрузочное тестирование?
Если у вас резко меняется характер данных и вы хотите смоделировать эту нагрузку, вы можете в любой момент записать новую порцию истории данных и сгенерировать тест с новыми данными. Так же, как в предыдущем вопросе – отдельно смоделировать среднюю и отдельно – максимальную нагрузку.
Например, вы знаете, что подавляющее большинство сотрудников в июне сваливает в отпуск, и у вас из-за этого будет другой расчет в ЗУПе, вам придется записать несколько наборов – февральский сценарий нагрузки, а потом июньский.
А если у вас настолько неравномерная нагрузка, что вы не можете ее смоделировать, у вас полгода только на сбор данных уйдет. Иначе никак – система же не моделирует несуществующую нагрузку.
Тут вся идея в том, чтобы записать реальную нагрузку, а ее потом прогнать на измененных условиях инфраструктуры – платформа, СУБД, Linux, Windows, и так далее.
А если у вас характер данных абсолютно разный, вам нужно записать три разных характера и провести три тестирования.
Вы в конце говорили, что проводили тестирование на разном железе, и на Intel-овских процессорах это отработало лучше, чем на AMD, а на SSD – лучше, чем на СХД и так далее. Сколько стоит организовать такое тестирование? И где взять деньги на это тестирование?
Где взять деньги – это вопрос к коммерческому отделу вашего предприятия.
Чтобы организовать нагрузочное тестирование, вам нужно рядом с продом развернуть точно такую же среду для нагрузочного тестирования. Ее стоимость должна закладываться в бюджет прода сразу. Если прод на физическом железе – вы должны развернуть для нагрузочного тестирования такое же физическое. Если среда виртуальная – создать вторую виртуальную с теми же параметрами.
Случай из жизни – буквально позавчера в always-on один виртуальный сервер MSSQL переехал на второй сервер, и там все сразу колом встало. Инфраструктурщики бьют себя пяткой в грудь: «Все одинаковое, ваша 1С опять не работает». Оказалось, что хотя железо реально одинаковое, на первом сервере в системе виртуализации – Hyper-V от Майкрософта, а на втором сервере, где все колом встало – VMWare. И там в адаптере для дисков забыли указать, что нужен NVMe. По умолчанию все работало на iSCSI, а она отдавала данные с дисков в 500 раз медленнее. Поэтому повторить все параметры нужно обязательно – это очень важный момент.
А если нет денег, значит, прод на ночь выключается и на нем проводится нагрузочное тестирование. Иначе никак.
Например, вам надо обновить платформу для ЗУП, а вы боитесь, потому что у вас на этом же сервере ERP крутится на старой платформе. И по какой-то религиозной причине вы не хотите ставить две службы на один сервер.
Если вам надо как-то проверить ERP, вы можете собрать сценарий на своем текущем железе, а потом за час проверить, увеличив частоту выполнения операций в ваших параметрах. Т.е. вы можете прогнать всю нагрузку за час в ваше тех. окно ночью на этом же проде.
Но если вы переходите с Windows на Linux, вам уже обязательно нужно будет где-то второй набор брать.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.
Вступайте в нашу телеграмм-группу Инфостарт