В предыдущей статье я начал рассказывать об использовании простейших конечных автоматов (КА) для синтаксического анализа. Там был рассмотрен КА для чтения CSV-файла.
В этой статье мы изучим возможности оптимизации КА с целью повышения его производительности.
Повторю здесь в почти неизменном виде диаграмму состояний КА из предыдущей статьи:
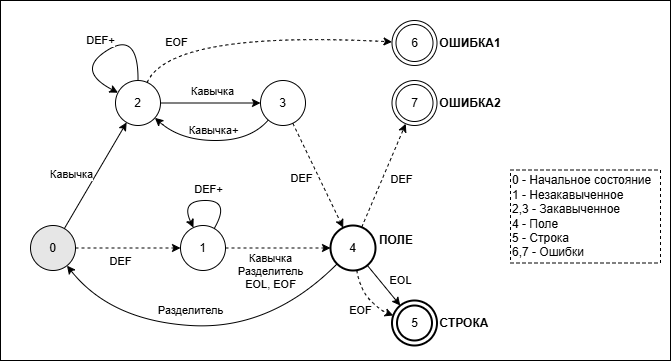
(В сравнении с предыдущей версией здесь есть одно небольшое изменение в переходах между состояниями 4 и 5, ниже станет понятно, для чего.)
Текст функции ЧтениеСтрокиCSV из предыдущей статьи я не буду здесь повторять.
Тестирование исходной версии
Для тестирования использовался файл, содержащий 30 тыс строк таблицы, что, с учетом наличия многострочных полей, составило порядка 180 тыс текстовых строк. Размер файла в кодировке cp866 – около 4.5 Мб. Файл был создан путем размножения в Excel’е одной исходной строки данных. Кодировка OEM 866, разделитель ";".
Текст процедуры чтения CSV-файла:
Процедура ПрочитатьФайлCSV(Знач ИмяФайла, ТабДок)
Перем ОписаниеОшибки;
ЧтениеТекста = Новый ЧтениеТекста(ИмяФайла, "cp866");
Стр = 0;
Старт = ТекущаяУниверсальнаяДатаВМиллисекундах();
Пока Истина Цикл
Поля = ПрочитатьСтрокуCSV(ЧтениеТекста, ";", ОписаниеОшибки);
Если Поля = Неопределено Тогда
Если НЕ ПустаяСтрока(ОписаниеОшибки) Тогда
Сообщить(ОписаниеОшибки);
КонецЕсли;
Прервать;
КонецЕсли;
Стр = Стр + 1;
Для Инд = 0 По Поля.ВГраница() Цикл
ТабДок.Область(Стр, Инд + 1, Стр, Инд + 1).Текст = Поля[Инд];
КонецЦикла;
КонецЦикла;
Финиш = ТекущаяУниверсальнаяДатаВМиллисекундах();
Сообщить(СтрШаблон("Время выполнения: %1 сек, количество строк: %2",(Финиш - Старт)/1000, Стр));
КонецПроцедуры
Время выполнения составило 14 сек, а при холостом чтении (без записи в табличный документ) – 12 сек.
Посмотрим, можно ли улучшить этот результат.
(Если захотите повторить, то важно запускать тест НЕ в режиме отладки, т.к. под отладчиком выполнение замедляется примерно на порядок.)
Оптимизация
Язык 1С является интерпретируемым языком. Поэтому, по сравнению с компилируемыми языками, программы на 1С выполняются чудовищно медленно.
Теоретически, алгоритм нашего КА должен выполнить итераций не меньше, чем есть символов во входном потоке. На самом деле итераций будет даже больше, т.к. в диаграмме присутствуют переходы без сдвига. И никакими средствами количество итераций невозможно уменьшить.
Но мы можем попробовать сделать так, чтобы значительная часть итераций выполнялась не на языке 1С, а внутри методов платформы, которые скомпилированы в машинном коде, и потому быстрые.
Давайте посмотрим на диаграмму состояний, а точнее – на состояния 1 и 2. У них есть переходы DEF, замкнутые сами на себя, фактически не изменяющие текущего состояния. И при том большую часть времени КА проводит именно в этих циклах. Как мы можем этим воспользоваться?
Наш КА может «заглянуть вперёд» во входном потоке и попытаться найти ближайший символ, который должен выводить КА из текущего состояния. Все символы до этой позиции отвечают определению DEF и могут быть добавлены в накопительный буфер единым блоком. Это означает, что в незакавыченном поле мы «прыгнем» сразу в конец поля, а в закавыченном поле – до ближайшей кавычки. Что избавит нас от посимвольного перебора всего содержимого поля.
Для поиска символа мы будем использовать метод СтрНайти, который сработает значительно быстрее, чем посимвольный перебор в цикле на языке 1С. А добавление в накопительный буфер сразу целой подстроки за раз даст нам дополнительное ускорение.
Для реализации такого подхода наш КА должен иметь свой собственный входной буфер, в котором он мог бы «заглядывать вперёд». В принципе, в предыдущей реализации он уже имеет такой буфер, т.к. читает файл построчно при помощи метода ЧтениеТекста.ПрочитатьСтроку. Но это означает, что многострочные поля будут читаться кусочками, что снизит эффективность «прыжков». Хочется, чтобы многострочное поле могло присутствовать в буфере целиком, тогда в лучшем случае можно будет «прыгнуть» сразу к закрывающей кавычке (в худшем случае – наткнуться на сдвоенную кавычку или конец буфера, но это всё равно лучше, чем посимвольное чтение).
Поэтому мы изменим способ формирования входного потока: будем читать файл блоками фиксированного размера. Блок должен быть достаточно большим, чтобы в него целиком помещалось хотя бы одно многострочное поле (но даже если целиком не поместится, то ничего не сломается, хотя время выполнения может несколько увеличиться). И он не должен быть слишком большим, т.к. это всё же текстовая строка, а в 1С строки копируются при присваивании, что также занимает время (спойлер: на практике оказалось, что разница между размерами блока, например, 4Кб и 64Кб не оказывает измеримого влияния на время выполнения).
Определим специальную функцию НайтиСимвол. Она будет выполнять метод СтрНайти, но несколько отличаться от него по возвращаемому значению: если символ не найден, то возвращается не 0, а позиция за последним символом строки. Так нам будет удобней, ниже станет понятно, почему.
Функция НайтиСимвол(Текст, Поз, Символ)
ПозСим = СтрНайти(Текст, Символ,, Поз);
Возврат ?(ПозСим > 0, ПозСим, СтрДлина(Текст) + 1);
КонецФункции
Придется усложнить механизм чтения. Мы теперь читаем файл блоками, недочитанный буфер чтения и текущая позиция в буфере должны сохраняться между вызовами функции ПрочитатьСтрокуCSV. Обернем объект ЧтениеТекста в структуру КонтекстЧтения, в которой будем хранить всё необходимое.
Функция Новый_КонтекстЧтения(Знач ЧтениеТекста, Знач РазмерБлока)
КонтекстЧтения = Новый Структура;
КонтекстЧтения.Вставить("ЧтениеТекста", ЧтениеТекста);
КонтекстЧтения.Вставить("РазмерБлока", РазмерБлока);
КонтекстЧтения.Вставить("Буфер", Неопределено);
КонтекстЧтения.Вставить("Поз", 0);
Возврат КонтекстЧтения;
КонецФункции
И, наконец, новая функция чтения строки CSV
// Читает одну строку таблицы из файла CSV.
//
// Параметры:
// КонтекстЧтения - см. Новый_КонтекстЧтения
// Разделитель - Строка - Символ-разделитель полей
// ОписаниеОшибки - Строка - В случае ошибки здесь возвращается описание ошибки, иначе пустая строка.
//
// Возвращаемое значение:
// - Массив из Строка - Массив значений полей при успешном чтении.
// - Неопределено - Конец файла или ошибка (см. ОписаниеОшибки)
//
Функция ПрочитатьСтрокуCSV2(Знач КонтекстЧтения, Знач Разделитель, ОписаниеОшибки = "")
Поля = Новый Массив;
Буфер = "";
Если КонтекстЧтения.Буфер = Неопределено Тогда
КонтекстЧтения.Буфер = КонтекстЧтения.ЧтениеТекста.Прочитать(КонтекстЧтения.РазмерБлока);
КонтекстЧтения.Поз = 1;
Если КонтекстЧтения.Буфер = Неопределено Тогда
Возврат Неопределено;
КонецЕсли;
КонецЕсли;
Текст = КонтекстЧтения.Буфер;
Поз = КонтекстЧтения.Поз;
Состояние = 0;
Пока Истина Цикл
Сдвиг = 1;
Сим = ""; // EOF
Если Текст <> Неопределено И Поз <= СтрДлина(Текст) Тогда
Сим = Сред(Текст, Поз, 1);
КонецЕсли;
Если Состояние = 0 Тогда // Начальное состояние
Если Сим = """" Тогда
Состояние = 2;
Иначе
Состояние = 1;
Продолжить;
КонецЕсли;
ИначеЕсли Состояние = 1 Тогда // Незакавыченное
Если Сим = """" ИЛИ Сим = Разделитель ИЛИ Сим = Символы.ПС ИЛИ Сим = "" Тогда
Состояние = 4;
Продолжить;
Иначе
ПозСим = Мин(НайтиСимвол(Текст, Поз, """"),
НайтиСимвол(Текст, Поз, Разделитель),
НайтиСимвол(Текст, Поз, Символы.ПС));
Буфер = Буфер + Сред(Текст, Поз, ПозСим - Поз);
Сдвиг = ПозСим - Поз;
КонецЕсли;
ИначеЕсли Состояние = 2 Тогда // Закавыченное
Если Сим = """" Тогда
Состояние = 3;
ИначеЕсли Сим = "" Тогда
Состояние = 6;
Продолжить;
Иначе
ПозСим = НайтиСимвол(Текст, Поз, """");
Буфер = Буфер + Сред(Текст, Поз, ПозСим - Поз);
Сдвиг = ПозСим - Поз;
КонецЕсли;
ИначеЕсли Состояние = 3 Тогда // Закавыченное
Если Сим = """" Тогда
Буфер = Буфер + Сим;
Состояние = 2;
Иначе
Состояние = 4;
Продолжить;
КонецЕсли;
ИначеЕсли Состояние = 4 Тогда // Поле
Поля.Добавить(Буфер);
Буфер = "";
Если Сим = Разделитель Тогда
Состояние = 0;
ИначеЕсли Сим = Символы.ПС Тогда
Состояние = 5;
ИначеЕсли Сим = "" Тогда
Состояние = 5;
Продолжить;
Иначе
Состояние = 7;
Продолжить;
КонецЕсли;
ИначеЕсли Состояние = 5 Тогда // Строка
Возврат Поля;
ИначеЕсли Состояние = 6 Тогда
ОписаниеОшибки = "Неожиданный конец файла";
Возврат Неопределено;
ИначеЕсли Состояние = 7 Тогда
ОписаниеОшибки = "Недопустимый символ";
Возврат Неопределено;
Иначе
ВызватьИсключение "Ошибка алгоритма";
КонецЕсли;
Поз = Поз + Сдвиг;
КонтекстЧтения.Поз = Поз;
Если Текст <> Неопределено И Поз > СтрДлина(Текст) Тогда
КонтекстЧтения.Буфер = КонтекстЧтения.ЧтениеТекста.Прочитать(КонтекстЧтения.РазмерБлока);
КонтекстЧтения.Поз = 1;
Текст = КонтекстЧтения.Буфер;
Поз = КонтекстЧтения.Поз;
КонецЕсли;
КонецЦикла;
КонецФункции
Что изменилось по сравнению с предыдущей версией:
-
Файл читается не построчно, а блоками фиксированного размера. Структура КонтекстЧтения хранит текущее состояние входного потока.
-
Поскольку символы EOL теперь не отсекаются, нет нужды их имитировать. Из-за этого изменился тип перехода EOL между состояниями 4 и 5 – теперь он выполняется со сдвигом.
-
Появилась переменная Сдвиг. Теперь сдвиг указателя чтения может выполняться не только на 1 символ, но и на несколько символов.
-
В состояниях 1 и 2, там, где раньше выполнялось
Буфер = Буфер + Сим;
теперь выполняется конструкция такого вида:
ПозСим = Мин(
НайтиСимвол(Текст, Поз, """"),
НайтиСимвол(Текст, Поз, Разделитель),
НайтиСимвол(Текст, Поз, Символы.ПС));
Буфер = Буфер + Сред(Текст, Поз, ПозСим - Поз);
Сдвиг = ПозСим - Поз;
Тестирование новой версии
Новая процедура чтения CSV-файла:
Процедура ПрочитатьФайлCSV2(Знач ИмяФайла, ТабДок)
Перем ОписаниеОшибки;
ЧтениеТекста = Новый ЧтениеТекста(ИмяФайла, "cp866");
КонтекстЧтения = Новый_КонтекстЧтения(ЧтениеТекста, 4096);
Стр = 0;
Старт = ТекущаяУниверсальнаяДатаВМиллисекундах();
Пока Истина Цикл
Поля = ПрочитатьСтрокуCSV2(КонтекстЧтения, ";", ОписаниеОшибки);
Если Поля = Неопределено Тогда
Если НЕ ПустаяСтрока(ОписаниеОшибки) Тогда
Сообщить(ОписаниеОшибки);
КонецЕсли;
Прервать;
КонецЕсли;
Стр = Стр + 1;
Для Инд = 0 По Поля.ВГраница() Цикл
ТабДок.Область(Стр, Инд + 1, Стр, Инд + 1).Текст = Поля[Инд];
КонецЦикла;
КонецЦикла;
Финиш = ТекущаяУниверсальнаяДатаВМиллисекундах();
Сообщить(СтрШаблон("Время выполнения: %1 сек, количество строк: %2",(Финиш - Старт)/1000, Стр));
КонецПроцедуры
Время выполнения на том же файле данных и том же компьютере составило 5.3 сек, а при холостом чтении (без записи в табличный документ) – 3.4 сек.
Поскольку механизм записи в табличный документ мы никак не изменяли, то сравнивать будем время холостого чтения. Ускорение в 3.5 раза – неплохой результат!
Вывод
Мы выяснили, что алгоритмы КА обладают некоторым потенциалом оптимизации производительности, причем, что главное, – оставаясь в рамках исходной математической модели (т.е. оставаясь всё тем же КА).
Вступайте в нашу телеграмм-группу Инфостарт